
一类基于多特征的模糊加权人脸识别算法
2010-08-29 13:28刘丽娜
山东理工大学学报(自然科学版) 2010年4期
刘丽娜
(山东理工大学电气与电子工程学院,山东 淄博 255049)
计算机人脸识别是由计算机分析人脸图像,从人脸图像中提取出有效的识别信息,用来“辨认”身份的一门技术.通常识别处理后可得到包括人脸的位置、尺度和姿态基本等信息.利用特征提取技术还可进一步抽取出更多的生物特征(如:种族、性别、年龄…).人脸识别技术有着广泛的应用背景,可以应用于公安系统的罪犯身份识别、驾驶执照及护照等证件照片与实际持证人的核对、银行及海关的监控系统以及一些保密单位的自动门卫系统等.
本文在基于PCA的人脸识别方法的基础上对其进行了改进,采用基于多特征的模糊加权识别算法进行分类.所谓多特征的模糊加权识别算法即将Eigenface,Eigenupper,EigenTzone以及二阶特征脸法四种方法的初步识别结果先模糊化,然后用模糊综合函数加权组合后获取新的距离函数进行人脸识别.EigenUpper、EigenTzone的采用将能补偿Eigenfaces在表情、光照方面的鲁棒性,二阶特征脸将突出细节特征在人脸识别中的作用.针对Yale和ORL数据库的实验结果证明了该方法明显优于传统特征脸识别方法,值得重视.
1 基于PCA的人脸识别
1987年Sirovich和Kirby为减少人脸图像的表示采用了PCA(Principal Component Analysis)方法,即主成分分析方法.1991年Matthew Turk and Alex Pentland最早将PCA应用于人脸识别[1].PCA(Karhunen-Loeve变换)的主要思想是在原始人脸空间中求得一组正交向量,并以此构成新的人脸空间,使所有人脸的均方差最小,达到降维目的.
1.1 人脸空间的建立
假设一幅人脸图像包含N个象素点,它可以用一个N维向量Γ表示.这样,训练样本库就可以用{Γi|i=1,…,M}表示.然后求取M幅人脸图像的平均人脸图像(即平均脸),进而得到每张人脸图像 Γi相对平均脸 Ψ的均差Φ,并构造训练样本集的协方差矩阵C.协方差矩阵C的正交特征向量就是组成人脸空间的基向量,即特征脸.把特征向量按特征值从大到小的顺序排列,提取前M′个向量形成向量空间,即人脸空间.
1.2 人脸识别
对于一新的人脸图像 Γ,将其投影到人脸空间得向量Ψ;将每个人的图像Γk投影到人脸空间得到M维投影向量Ψk.求出 Ψ到每一类的距离:

其中Nc为人脸图像的类别数.
然后,采用最小距离法进行分类.
2 基于多特征的模糊加权人脸识别
特征脸方法只考虑了人脸的整体特征,图像中的每个象素点被赋予了同等重要的地位,因而它忽略了人脸的局部特征(如:眉毛、眼睛、鼻子、口等),识别中识别率不高.将整体特征与局部特征结合起来是特征脸法的一种改进方法.文献[2]采用基于多特征组合和支持向量机的实时人脸鉴定方法,取得了较好的效果,文献[3]提出了一种融合两种主成分分析的人脸识别方法,在进行融合时用到了模糊的概念效果也不错.本文将EigenUpper、EigenTzone、Eigenfaces以及二阶特征脸法四种方法进行模糊加权组合.EigenUpper、EigenTzone法详细请参考文献[4].在Yale和ORL数据库上的识别实验结果表明它比单纯使用Eigenfaces效果要好的多.
2.1 多特征提取
(1)Eigenfaces 采用文献[1]的特征脸方法.
(2)EigenUpper 根据心理学和生理学的研究成果,在识别中人脸的上半部特征比下半部特征起的作用要大.因此实验时提取人脸的上半部分,嘴所在的下半部分区域去掉,作PCA分析.实验中部分EigenUpper如图1所示.

图1 实验中部分EigenUpper
(3)EigenTzone 在人脸检测中人眼的定位很重要,鼻子在人脸图像中通常是个亮点.因此将人脸的Tzone分割出来,作特征脸分析.Tzone的分割,采用灰度投影图方法.首先通过实验选择合适的阈值将原始图像进行二值化;然后得到二值化图像的水平投影图和垂直投影图;如图2所示,依据投影图可以确定眉毛、嘴巴以及人脸左右边界的粗略位置;最后根据各特征点的位置确定Tzone.同样的作PCA分析.实验中部分EigenTzone如图3所示.
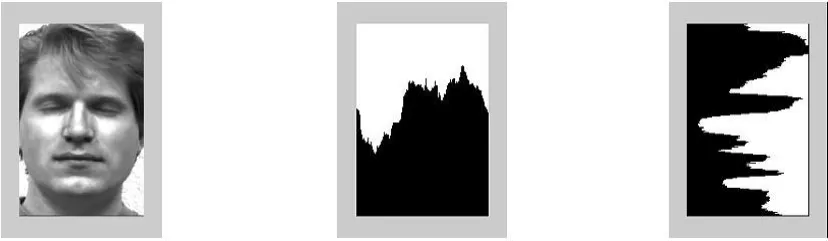
图2 二值化图像的水平投影和垂直投影图

图3 实验中部分EigenTzone
(4)二阶特征脸法 特征脸方法在一定条件下可以有效的识别人脸,但是在某些条件下特征脸不能满足人们对正确识别率的要求.比如:光照变化较大的情况下,特征脸中的主成分(即对应较大特征值的特征脸)主要反映的是人脸图像中的光照变化.在这种情况下,特征脸不能有效的表示人脸图像的身份特征信息,这将大大影响这些特征的识别效果.为了解决此问题,Wang和Tang[5]提出了二阶特征脸方法,该方法通过丢弃传统特征脸方法得到的前数个反应光照信息的特征脸来克服光照干扰的影响.该方法不仅采用原始人脸图像的特征脸,还采用人脸图像余像的特征脸——二阶特征脸,所谓余像是指原始人脸图像与基于特征脸的主成分重构的人脸图像的差.人脸余像空间的建立过程,请见文献[5].
将每个人的余像Γ′i投影到人脸余像空间得M维投影向量Ψ′k.对于一新的人脸图像 Γ,将其投影到人脸空间和人脸余像空间得向量Ψ和Ψ′.定义新的距离函数

其中,α1和α2为权重系数,分别反映了一阶和二阶特征脸的重要程度.则输入图像就可按最小距离法进行分类.
2.2 基于模糊加权的人脸识别算法
在对测试样本用上述四种方法进行初步分类后,用Zadeh提出的著名模糊集合论把识别结果模糊化,本文中的距离函数反映隶属度的含义,在上述各种识别中,如果初步把测试样本判为第k类是正确的话,则修改它们之间的距离为极小值,使测试样本属于第k类的隶属度最大为1.0;如果是错误的,则修改它们之间的距离为极大值,使测试样本属于第k类的隶属度最小为0.0.这样就可以得到四组“模糊”的识别结果.然后采用模糊综合函数将四组“模糊”识别结果进行融合,模糊综合函数取算术平均值,即

最终依据融合所得的距离结果按最小距离法获取识别结果.
3 测试实验与结果分析
由于ORL人脸数据库是目前应用最广泛的人脸识别数据库,其结果可比性较强.另外,它的显著特点是无需对人脸图像进行检测定位和尺寸归一化等处理.为了检验本文所提出的识别算法的正确性和有效性,选择ORL数据库中的20人每人5幅作为训练样本,该20人的其他100幅图像作为测试样本,并将二者的识别结果进行比较.为了进一步突出模糊加权识别算法的优越性,将其与一般的平均加权法进行对比.上述实验的识别结果见表1.
其中,选取的特征向量数目为42,该数据是通过实验和相关经验公式确定的前M′个最大特征向量[6].在二阶特征脸法的识别实验中,α1和α2为权重系数选择为0.6和0.4,亦是通过实验和相关经验确定的[6].

表1 正确识别率 %
各种识别方法的识别结果表明多特征模糊加权人脸识别算法要明显优于传统特征脸方法,且比多特征平均加权人脸识别算法要好一些.
4 结束语
采用的基于多特征的模糊加权人脸识别算法简单有效,计算量较小、耗时不多.多特征的识别方法补偿了特征脸在表情、光照方面的不足,同时考虑了眼睛、鼻子在识别中的作用,达到了整体与局部特征相结合的目的.
本文所采用的ORL数据库为小型人脸库,如能采用更多更大的人脸数据库,增加训练样本的数量,将会进一步体现本文所提出方案的优越性.
[1]Matthew A T,Alex P P.Vision and modeling group,the modelinglaborato ry.FaceRecognitionUsingEigenfaces[J].CH2983-5/91/1991 IEEE,586-591.
[2]Kim D H,Lee J Y,Soh J,Chung Y K.Real-time face verification using multiple feature combination and a support vector machine supervisor[J].0-7803-7663-32003 IEEE.145-148.
[3]徐倩,邓伟.一种融合两种主成分分析的人脸识别方法[J].计算机工程与应用.2007,43(35):195-197.
[4]刘丽娜,乔谊正.基于多特征的人脸识别[J].中国科学技术大学学报(自动化专辑).2005,35:131-136.
[5]Wang L,Tan T K.Experimental results of face feature description based on the 2nd 2order eigenface method[R].ISO/IEC/JTC1/SC21/WG11/M6001,Geneva,2000.
[6]刘丽娜.基于特征脸和多特征的人脸识别算法研究[D].济南:山东大学控制科学与工程学院,2006.
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
应用数学(2020年2期)2020-06-24
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
数学物理学报(2018年6期)2019-01-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
动漫星空(2018年9期)2018-10-26
