
数据起源安全模型研究
2010-08-29 13:28:04李秀美王凤英
山东理工大学学报(自然科学版) 2010年4期
李秀美,王凤英
(山东理工大学计算机科学与技术学院,山东 淄博 255049)
数据起源是新兴的研究领域,可用来判断数据的来源、质量和可靠性.数据起源在电子商务、医学、科学和法律环境下的数字文档中的应用变得非常重要.迄今为止,对数据起源的研究主要集中在建模、计算、存储、查询等工作上,对确保数据起源信息安全方面的研究极少.随着电子数据可信度重要性的日趋增强,确保数据起源信息安全的需要比以往更加重要.随着数据起源不断地用于数字版权保护、DNA检测、药物试验、企业财务和国家情报等领域,起源信息也面临着越来越严重的安全威胁,包括来自敌方的主动攻击.攻击者主要动机是根据科学数据的价值来更改数据起源记录历史.科学数据的价值依赖于哪个数据被创建以及由谁来创建等起源信息.用户需要信任与数据相关的起源信息能够准确地反映数据被创建和被转化的过程.但是如果没有适当的保护措施,随着数据经历不同应用层或不可信的环境,与数据相关的起源信息可能会遭到意外破坏,甚至更容易遭到恶意篡改.
例如,为了提高商品的产销率,公司基层人员Alice按照目的和需要来收集购买者有关信息,如购买者个人信息、所购买商品的种类及数量等,然后将收集的信息移交给工作人员Bob来分析,作出判断,形成结果,提高信息的使用价值.最终将处理过的信息传输给管理人员Carlin以作出合理决策,调整商品结构,促使供求平衡.在这个过程中形成了数据起源链(PA|PB|PC),如图1所示.收集信息的质量,即信息的真实性、可靠性、准确性、机密性,决定着能否达到预定的目的和能否满足需求从而提高企业的经济效益.因此,企业内部人员和外部敌人很可能有明显的动机去更改数据记录历史.如果工作人员Bob对某一商品的购买量作出不合理的判断,从而导致错误的销售策略.为了不影响他的业绩考核,他可能会通过修改与其操作相匹配的起源记录来隐藏他的错误行为.
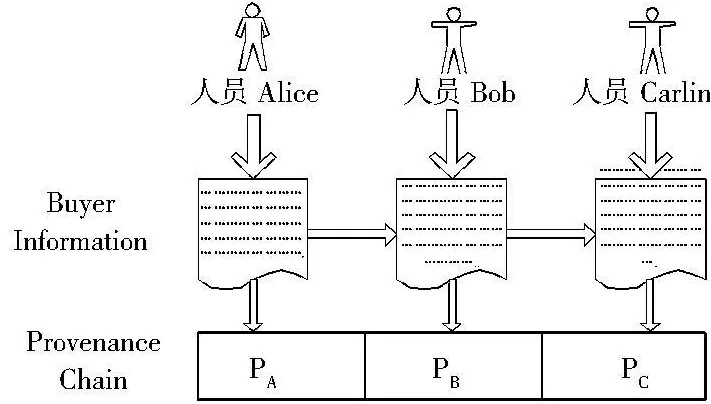
图1 起源实例
随着数据及其起源信息在不可信环境中经过不同用户和任务时,数据起源信息极易被非法更改,为起源提供完整性、机密性保障变得非常重要.
1 数据起源的相关工作
数据起源描述了在数据的整个生命周期中数据当前状态以及对数据被创建、修改、转化的过程.数据起源的计算已不是新问题了,Cui等人首先提出了追踪数据起源的问题[1],首次提出“逆查询”方法,Buneman等人将其称为why-provenance[2],同时又提出了where-provenance,正是利用数据起源的这种where-provenance类型来决定标注从哪里并且如何传播来的.数据起源是与视图更新密切相关的问题,而标注逐渐成为科学计算的最有用的方法.根据文献[3],[4]中首次提出的关系数据上可以放置标注的想法,文献[5]对关系数据库设计并执行了标注管理系统.这是首次对关系数据库实施标注管理系统,在这个系统中,允许用户指定标注传播方式.标注也可以用来描述一条数据的质量和安全级别,因为标注是随着查询的执行被传播的,可以聚集查询结果中的标注来确定输出信息的质量或敏感度.使用标注来描述各种数据项的安全级别或指定细粒度访问控制策略已有所研究.然而,实际操作是侧重于收集存储信息而不是起源的安全性和可信性,这并不满足起源信息的机密性、完整性和隐私的各种挑战.
到目前为止,为了收集和保存起源记录已经提出了各种系统架构:有些系统收集关于数据修改的信息并且以标注的形式储存起来,附加到数据本身[5-6];有些把起源信息存放在一个或多个数据库中[7-8].因此,针对不同的存储模式,根据其对安全的不同需求,采取不同的安全保护措施.Rigib等人在文献[9]中的研究工作致力于文件系统中追踪和存储起源时的安全问题(完整性和保密性),但是文中没有使用时间戳技术,文档存在日期和时间不可确定的问题.文中是基于固定审计用户数量而建立的密钥树,无法为新的审计员分配密钥.因此,本文提出了新的数据起源安全模型,该模型可以有效的解决上述问题,目前对此研究甚少.
2 数据起源模型的建立
本节对在数据起源链传播过程中,起源记录可能遭到的威胁进行讨论,提出了威胁模型,描述了数据起源的基本概念,提出了新的数据起源安全模型,并对该模型进行了定义、描述.
2.1 威胁模型
当数据经过应用层或组织边界,经过不可信的环境时,其相关的起源信息很容易受到非法篡改.访问控制是不能完全阻止这种篡改的,因为非法用户可能实际控制着驻留数据的机器.如果数据起源没有特殊的安全保障,非法用户很容易修改数据并篡改相关的起源信息,甚至可能删除起源链中相应的起源记录,或者将伪造的起源记录存储在起源链里,并且这些操作很难被发现.
本文在Ragib等人描述模型[9]的基础上提出了威胁模型和安全保障.假设在一个安全域中,用户是读写文档及其元数据的主体.每个组织有一个或多个审计员,他们被授权访问并且验证与文档有关的起源记录完整性的主体.无论是否有访问文档及其起源链的权限只要想不当地修改这些信息的个人或组织称为攻击者.
假设起源信息P准确地反映了文档D的转化,但是一个或多个攻击者想通过修改D或P来伪造历史.因此,根据图1中起源链在形成过程中可能遭到的攻击,列出了关于安全起源所需的以下保障:
S1 攻击者不能有选择地修改起源链中任何用户(包括自己)的起源记录.如图1中所示的工作人员Bob不能通过修改他的起源记录来隐藏他的错误行为.
S2 攻击者不能有选择地移除起源链中任何用户(包括自己)的起源记录.
S3 攻击者不能在起源链的开始或中间添加起源记录.
S4 用户不能否认对起源链添加起源记录.例如图1中,员工Bob不能对自己的错误行为及写入起源链的相应起源记录进行恶意的否认,以推卸自己应承担的责任.
S5 攻击者不能宣称与一个文档相关的起源链属于其他文档.
S6 攻击者不能只修改文档而不将正确描述这次修改的起源记录添加到起源链中.
S7 起源链本身不能被修改,也就是攻击者不能破坏起源纪录的先后次序.
S8 两个同谋攻击者不能在他们之间插入非同谋参与者的起源记录.
S9 两个同谋攻击者不能有选择地移除他们之间非同谋参与者的起源记录.例如,在图1中,员工Alice和Carlin不能移除Bob的起源记录.
S10 审计员不用访问起源链的任何机密性组件的情况下就可以验证起源链的完整性,未授权审计员不能访问机密性起源记录.
值得注意的是,如果攻击者实际完全控制着机器,他就完全可以删除起源链,使用户无法正常使用这些信息,因此这需要有可信硬件的支持.另一方面,攻击者可能通过手动地或自动地复制文档声称他们是创作者,从而伪造创作者的身份.因此,我们构造模型的目的是发现篡改,防止恶意攻击者破坏部分起源链.
2.2 数据起源安全模型
为了有效地防止攻击者非法篡改起源链中的起源记录,综合考虑可能存在的威胁的安全因素,提出了数据起源安全模型,如图2所示.使用文档这个词代替包括文件、数据库元组、信息流,网络数据包在内的数据对象,而数据起源正是为该文档而收集的.数据的起源信息是在该文档的生命周期中对文档的修改行为的记录,每一次访问文档D都可能产生起源记录P,而非空的起源记录P1|···|Pn按时间顺序排列组成了数据起源链.文档从一个用户移到另一个用户,如同电子邮件附件,FTP传输,或其他方式.起源链随着文档一起移动.当用户修改一个文档时,描述这次修改的新的起源记录被附加到数据起源链上,而且用户允许审计员或其子集读取新的起源记录.根据起源链可以回溯文档的演化过程,追踪文档产生时的来源、在文档生命周期中的修改过程.起源链中的每个起源记录描述了文档的当前状态,如访问文档的用户名、进程序号、访问行为(读或写操作)、相关数据(文档的字节大小)以及对行为发生环境的描述(包括访问的主机号、IP、日期时间),以及与完整性、机密性相关的安全组件,例如校验和、加密签名、密钥材料、数字时间戳.对文档的每个操作都以起源记录的形式被记载,文档被删除后,它的起源信息不再有意义.
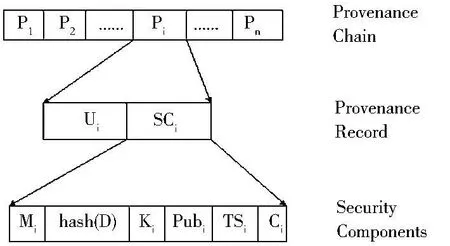
图2 数据起源安全模型的结构
2.3 安全模型中相关要素的描述
该模型包括三层组件:第一层是起源链,每条起源链至少含有一个起源记录;第二层是起源记录,其中包括起源记录描述字段Ui和安全组件字段SCi;第三层是安全组件和起源记录要素.起源记录是起源链中的最基本单元,每个起源记录Pi汇总了一个或多个用户在文档D上执行的一系列操作,将起源记录定义成如下形式:
Pi=<Ui,Mi,hash(Di),Ki,TSi,Ci,Pubi>其中,Ui是用户的明文或密文标识符,包括以下要素:访问文档的用户名Uidi,进程序号Pidi,访问行为Actioni,文档的字节大小Bytei,IPi,访问的主机号Hosti,Timei.将Ui字段定义为Ui=<Uidi,Pidi,Actioni,Bytei,IPi,Hosti,Timei>.如果Ui是敏感的,那么它要以密文的形式存储.
例如,在员工业绩评估实例中,允许甚至是鼓励员工经常去看他们的业绩评估结果,以督促他们达到工作业绩标准的要求,但是员工不能读取谁对他们的工作业绩做出了评价,因此员工只能够读取业绩评估文档而不是文档的数据起源.在这种情况下,描述文档当前状态的用户标识符就应该用会话密钥加密形成密文.
Mi是用户执行的一系列增加,删除,修改等操作(简称修改日志)的密文或明文表示形式.
hash(Di)是文档当前内容的单向散列值.
[3]For all the recent debate,early signs are that the supply-side shift may not amount to a serious change of course.(2016-01-02)
Ki是密钥材料,包括审计员可以用来解密被加密字段的密钥.
TSi表示时间戳,对需要加时间戳的文档摘要和DTS收到文档的日期和时间进行数字签名.
Ci包含了由用户签名的起源记录的完整性校验和.
Pubi是用户Ui的加密的或明文公钥证书.
3 数据起源安全模型需求
3.1 起源链的完整性
用户在修改文档时,同时对文档进行单向散列hash(Di).并对此散列值、修改日志、密钥材料、用户标识符以及用户的公钥证书进一步散列,使用用户的私钥对后一次散列结果、时间戳以及前一个起源记录Pi–1的检查和Ci–1进行签名形成完整性校验和,我们将完整性校验和字段定义如下:

为了增加签名的安全性,引入了时间戳技术,用户将需要加时间戳的用户标识符用Hash加密形成消息摘要,然后将该消息摘要发送到数字时间戳服务中心DTS,DTS对消息摘要和收到消息摘要的日期时间信息再加密(数字签名),然后送回给用户,如图3所示.将时间戳和完整性校验和存储在起源记录相应字段中.时间戳具有唯一性和不可逆性,因此起源记录被人改动则不能通过验证.时间戳字段定义如下:


图3 数字时间戳
审计员获得由起源记录提供的信息,他可以通过计算校验和来判断数据的来源,验证在传输过程中是否被恶意地修改.为了验证起源链的完整性,审计员从起源链的第一个记录开始,从记录中提取用户标识符Ui和Pubi字段,并验证Pubi是用户Ui的公钥证书,审计员从中找到用户的公钥对校验和进行解密,得到hash(Ui,Mi,hash(Di),Ki,Pubi).审计员再对当前记录中的Ui,Mi,hash(Di),Ki,Pubi字段进行散列得到hash',如果hash=hash'则说明起源信息没有被修改.
简要说明威胁模型中针对完整性的安全保障:
(1)如图1的用户Bob想修改起源记录或信息文档,这必定会引起hash(Ui,Mi,hash(Di),Ki,Pubi)的值的改变,因为每次被修改的信息都是被单向散列的.如果外部攻击者想修改起源记录而不被发现,那么他需要得到其他用户的签名,或者找到哈希碰撞,因此S1的安全是有保障的.
(2)如果攻击者想插入或者删除起源记录也是可以被发现的,因为每个起源记录中的校验和Ci都包含前一个起源记录的校验和,这足以保证S2、S3、S8、S9的安全.
(3)函数hash具有无碰撞性,以及文档当前内容的hash值保存在每个起源记录中,因此通过比较文档与起源链中最新起源记录的各字段,便可以验证S5所述的起源链是否被声称属于不同的文档.
(4)授权审计员对校验和Ci进行解密,依次验证起源记录中hash(Di),Mi字段,如果发现hash(Di)与当前状态文档内容不匹配,审计员能够验证S6攻击者只修改文档而没有将起源记录添加到起源链中.
(5)S4的不可否认性由起源链校验和中的签名来保障.
(6)可以通过验证每个起源记录中的时间戳来保证S7中起源纪录的先后次序没有遭到破坏.
3.2 起源信息的机密性
在起源信息相对于数据更敏感的系统中,为了保证起源信息的机密性,需要使用会话密钥对修改日志进行加密,并使用不同安全级别审计员的公钥来加密用户密钥.在这个过程中,只有某一可信审计能够解密相应的用户密钥,并使用该密钥来解密敏感字段.
为了使不同可信审计能够安全有效地访问起源链中相应敏感字段,用户需要产生N个会话密钥复本,分别使用N个审计员的公钥加密密钥复本,然后存放在Ki字段中,因此起源链中的密钥存储量为O(N).随着文档的不断传播,导致起源链本身急剧增大,这将影响到起源链的存储与传播.因此,为了减少起源记录Pi中Ki字段存储的密钥数量,文中借鉴广播加密方案[10]构造密钥树.密钥树是以密钥为结点的二叉树,每个结点包含PKI中的公/私钥对,叶子结点相当于审计员,每个审计员都知道从叶子结点到根结点的私钥,而把树中所有的公钥给用户.
如果存在用户同时信任属于不同子树的任意叶结点时,便出现了如何选取密钥的问题.对于这一问题,我们选择审计员的一个子集,给子集中的所有审计员一个公用的解密密钥,这样可以有效地控制授权审计员子集数量的增加,减轻用户对敏感字段加密和起源链传输的负担.在以审计员为叶结点的二叉树中,设中间结点ki,kj,其中ki是kj的父结点,子集Si,j表示包含以ki为根而不包含以kj为根的所有结点的集合.如图4中,在以k1为根结点,以审计员A、B、C、D为叶子结点的密钥树中,子集Sk1,k6表示被授权的审计员子集包括A、B、D三个,通过判断可知,A、B属于同一个根结点,因此将这个子集中分成两个不相交的差分子集,并计算这些差分子集对应的密钥.这样做好处是密钥字段中只存储一个加密的会话密钥复本,有效减少存储空间和提高起源链的传播效率.相比之下,多叉密钥树中同一根结点的叶子数量相对很多,而随着叶子结点数量的增加,审计员的子集划分不断增多,而使用二叉密钥树可以有效地减少审计员子集划分数量.

图4 密钥树
当用户信任某审计子集时,他会使用审计所属的子集的公钥加密会话密钥.审计员必须能够推断出他所属的子集的所有公私钥对,也就是从叶结点到根结点的所有子集.所有这些子集中的审计员都被授权访问起源链.加密起源链修改日志的目的是允许授权审计访问并验证起源链,所有这些审计员都是某一子集的成员,因此他们拥有属于这一子集的密钥.
在加密阶段,用户使用会话密钥ki加密修改日志mi,即3.1中所定义的字段Mi=Eki(mi),如果此字段对某一可信审计员子集Si可信,用户会选择与这一子集相关的密钥kSi加密会话密钥的复本,即3.1中的密钥材料字段Ki=Eksi(ki),然后将加密的密钥存放在Ki字段中,加密次数为子集的个数.由于私钥是由审计员保存,而用户只使用公钥进行加密,因此不可能泄露审计员的私钥.
3.3 动态密钥树
由于审计用户数量可能存在动态增加的情况,而传统的密钥树存在无法扩展审计员数量的问题,因此需要在不影响原有审计数量的基础上动态地扩展审计端.
假设扩展审计端前的密钥树为T,以新加入的审计员为叶结点建立密钥树T'.第t次扩展以T为左子树,T′为右子树将其结合成一棵新密钥树T″,根结点为kt.保持左子树的密钥系统不变,为右子树及根结点分配密钥[11].为了更好的理解密钥树扩展问题,给出一个简单的例子.如图5所示,保持原有密钥树的密钥分配不变,以新加入审计员E、F为叶子结点构造一棵二叉树,并分配密钥,扩展后的密钥树的根结点为k8.如果用户只信任审计员A,那么用户只需用结点k4的公钥加密会话密钥;如果用户信任C、D、E、F四个审计员,那么会产生两个差分子集,分别对应的密钥是k3,k11;相应地,如果用户信任所有的审计员,那么只需使用结点k8的公钥加密即可.
对于扩展了t次审计员的密钥树中,每次新加入的审计员集合的密钥分配同未扩展之前的审计端的密钥分配是一样的,审计员的密钥存储量与该审计员所处的扩展端的个数相关.
4 结束语
本文分析了现有数据起源相关安全问题,对威胁模型进行改进,确保攻击者不能更改起源记录的顺序;针对机密性需求中的加密方案存在的问题,引入广播加密树再生长的思想构造密钥树;为了增加签名的安全性,引入了时间戳技术,构建新的数据起源安全模型.但对这种模型的研究还处于初始阶段,还要进行不断的完善.比如随着数据的不断传播,起源链也不断增长,如何在不影响审计员对起源链完整性、机密性的验证的情况下压缩起源链等问题将是下一步研究的重点.
[1]Cui Y,Widom J,Wiener J.T racing the Lineage of View Data in a Warehousing Environment[J].ACM T ransactions on Database Sy stems(TODS),2000,25(2):179-227.
[2]Buneman P,Khanna S,Tan W.Why and Where:A Characterization of Data Provenance[C]//In Proceedings of the 8th International Conference on Database T heory(ICDT),2001:316-330.
[3]Buneman P,Khanna S,Tan W.On Propagation of Deletions and Annotations Through Views[C]//In Proceedings of the ACM Symposium on Principles of Database Sy stems(PODS),Wisconsin,Madison,2002:50-158.
[4]Wang-C T.Containment of relational queries with annotation propagation[C]//In Proceeding s of the International Workshop on Database and Programming Languages(DBPL),Potsdam,Germany,2003:109-110.
[5]Bhagwat D,Chiticariu L,Tan W,etal.An Annotation Management System for Relational Databases[C]//In Proceedings of theInternationalConferenceonVeryLargeDataBases(VLDB),2004:900-911.
[6]Buneman P,Chapman A,Cheney J.Provenance management in curated databases[C]//Proceedings of the 2006 ACM SIGMOD international conference on M anagement of data,2006:539-550.
[7]Chapman A,Jagadish H V,Ramanan P.Efficient provenance storage[C]//Proceedings of the 2008 ACM SIGMOD international conference on Management of data,2008:993-1006.
[8]Davidson S,Cohen-Boulakia S,Eyal A,et al.Provenance in scientific workflow sy stems[J].IEEE Data Engineering Bulletin,2007,32(4):1-7.
[9]Ragib Hasan,Radu Sion,Marianne Winslett.T he case of the fake picasso:Preventing history forgery with secure provenance[C]//In Proc.of the 7th USENIX conference on File and Storage Technologies,2009.
[10]Halevy D,Shamir A.T he LSD broadcast encryption scheme[C]//Lecture Notes in Computer Science,2002:47-60.
[11]武蓓,王劲林,倪宏,等.一种广播加密机制的树再生长方法[J].计算机工程,2007,33(22):169-171.
猜你喜欢
中国集体经济(2024年16期)2024-06-07 17:10:03
理财·市场版(2024年2期)2024-04-09 17:58:31
统一战线学研究(2022年6期)2022-12-06 00:19:58
小学科学(学生版)(2021年12期)2021-12-31 03:22:22
小学科学(学生版)(2020年7期)2020-07-28 08:00:54
中外文摘(2019年15期)2019-11-13 01:43:40
疯狂英语·初中天地(2019年4期)2019-10-17 02:07:12
数学物理学报(2018年1期)2018-03-26 08:16:42
中国漫画(2017年4期)2017-06-30 13:06:16
电子设计工程(2014年12期)2014-02-27 11:58:23
