
基于一种改进的监督流形学习算法的语音情感识别
2010-05-18 08:49张石清李乐民赵知劲电子科技大学通信与信息工程学院成都610054杭州电子科技大学通信工程学院杭州310018台州学院物理与电子工程学院台州318000
电子与信息学报 2010年11期
张石清 李乐民 赵知劲(电子科技大学通信与信息工程学院 成都 610054)(杭州电子科技大学通信工程学院 杭州 310018)(台州学院物理与电子工程学院 台州 318000)
1 引言
情感计算,作为当前人工智能、信号处理等领域研究的一个新的热点课题,目的就是要赋予计算机类似于人一样的观察、理解和生成各种情感特征的能力,最终使计算机像人一样能进行自然、亲切和生动的交互[1]。语音作为人类最重要的交流媒介之一,携带着说话者丰富的情感信息。因此,从语音信号中分析和提取情感特征,让计算机自动识别出说话人的情感状态方面的研究就显得尤为重要。该研究在新型人机交互[2]、电话客服中心[3]、智能机器人[4]等领域具有重要的应用价值。
近年来,文献[5,6]发现语音信号中的特征数据位于一个嵌入在高维声学特征空间的非线性流形上。这使得以寻求蕴含在高维数据集中的内在结构信息为目标的流形学习算法开始得以应用于语音特征数据的非线性降维处理,如语音低维可视化[6]和语音识别[7]。降维的主要目标是获取最优的低维嵌入判别特征,丢弃无关或次要的信息,减小数据的维数。其中,用于非线性降维的两种代表性流形学习算法是局部线性嵌入[8](Local Linear Embedding, LLE)和等距映射[9](Isometric Mapping, Isomap)。尽管这两种流形学习算法能够有效实现语音数据的低维可视化,但用于语音识别时表现不佳,甚至不如传统的线性主成分分析法[10](Principal Component Analysis, PCA)。主要原因是这两种流形学习算法都属于非监督方式的降维,没有考虑对分类有帮助的已有数据点之间的类别信息。
为了克服非监督流形学习算法模式识别方面的不足,Ridder等人[11]通过使用考虑数据类别信息的监督距离修改LLE算法中的邻域点搜索,提出了一种代表性的监督式的局部线性嵌入(Supervised Locally Linear Embedding, SLLE)算法。SLLE算法具有较好的模式识别性质,已经广泛应用表情识别[12]、人脸识别[13]等领域。然而,这种 SLLE算法仍然有3个缺陷。(1)SLLE采用的监督距离是线性的。这会导致所希望的数据点之间的类间距增大时,其类内距也同样保持同步增大,从而削弱了 SLLE产生的低维嵌入数据的判别力,不利于数据的分类。(2)SLLE算法以批处理方式运行处理已有的训练样本数据,不能有效解决新测试样本数据的泛化问题,因为SLLE从已有的训练样本提取的低维嵌入判别数据对新测试样本数据的输入不能直接给出合理的嵌入输出,即所谓的泛化能力的缺失。(3)在构成SLLE算法中的监督距离中的常数因子对 SLLE的泛化性能有着极其重要的影响。然而,对如何最优化SLLE距离中的常数因子,已有的研究[11-13]大多采用在某一特定目标维度(如本征维度)上执行繁琐而重复的人工搜索试验而取得该常数因子的经验最优值,然后固定其值不变,在不同目标维度上都进行降维使用,但实际上该常数因子的最优值很容易受到不同的降维目标维度的影响。因此在某一目标维度上取得的常数因子的最优值对于其它降维的目标维度并不是最优的。为此,本文提出采用一种能增强低维嵌入数据的判别力的非线性监督距离替代SLLE中的线性监督距离,并发展一种在不同维度上能够自动最优化常数因子的算法,进而构造出具有最优泛化能力的改进 SLLE算法,简称Improved-SLLE(Improved Supervised Locally Linear Embedding, Improved-SLLE)。利用Improved-SLLE对较高维度的语音情感特征参数进行非线性降维,提取判别力增强的低维嵌入特征,从而在低维嵌入特征空间实现语音情感识别结果的改善。在建立的自然情感语音数据库的试验结果表明了该算法的有效性。
2 Improved-SLLE算法
2.1 算法步骤

其中'Δ是结合数据点类别信息计算后的距离,Δ是忽略数据点类别信息的原始欧氏距离。参数β用来防止指数函数中的Δ增长过快,尤其当Δ本身就相对比较大,β作用更明显。因此,参数β与数据集中的数据密集程度密切相关,一般取所有成对数据点的欧氏距离的平均值。而参数α(0≤α≤1)是一个常数因子,用来控制不同类别数据点的距离,在某种概率上接近或者小于同种类别数据点距离的程度。
与Improved-SLLE相比,原始的SLLE算法在计算点与点之间的距离时,采用的线性监督距离公式如下:

其中max(Δ)是表示最大欧氏距离,而常数因子α(0≤α≤1)也是用来控制距离计算时数据点类别信息的结合数量程度。
为了更好理解Improved-SLLE算法中采用的非线性监督距离的优越性,图1举例说明了,当原始欧氏距离Δ在指定区间[0,3]呈线性规律增长时,比较了Improved-SLLE和SLLE两种算法的距离曲线的不同变化特点。这两种算法的常数因子α都设为0.3。

图1 两种不同算法的距离曲线比较
由图1 (a) 可见, Improved-SLLE采用了非线性监督距离,不同类别数据点的类间距呈指数快速增长,而同种类别数据点的类内距被控制在[0,1]缓慢增长。这样会使得类间距尽可能增大,而类内距尽可能小,保持在区间[0,1]内。类间距和类内距之间的比值随着距离的增大而增大,使得低维嵌入数据的判别力也会随着距离的增大而增强。这种特点非常有利于嵌入数据的分类。相反,SLLE算法由于采用线性监督距离,则没有这种好的性质。如图1 (b)所示,当类内距快速增长时,类间距也同样保持同步增长,使得类间距和类内距之间的比值不变。这会削弱低维嵌入数据的判别力,不利于数据的分类。
为了使得Improved-SLLE对新测试样本具有较好的泛化能力,本文采用 Nystrom 方法[14]构建Improved-SLLE的泛化算法。
2.2 Improved-SLLE常数因子的自动最优化算法
Improved-SLLE距离中常数因子α的最优值,应该由Improved-SLLE对测试样本获得的最优泛化性能来决定。训练样本一般是预先已有的,而测试样本是未知的,如实时性处理。因此,为了获取常数因子α的最优值,可以把已有的训练样本拆分成两部分:一部分用于训练,一部分用于测试。这样就可以根据从训练样本拆分出来的测试样本的最低识别错误率来选择最优的常数因子α,具体算法步骤如表1所示。对SLLE常数因子α的最优化,也可采用表1的算法实现。

表1 Improved-SLLE常数因子的自动最优化算法
3 语音情感识别实验研究
为了检验 Improved-SLLE的语音情感识别性能,将采用PCA,LLE,Isomap,SLLE和Improved-SLLE分别应用于提取的语音情感特征数据的降维,然后比较这5种方法在不同维度上降维后的语音情感识别结果。
3.1 自然情感语音数据库
目前,国内外研究者大多采用人工模仿的模拟情感语音数据库进行语音情感识别的研究,但这种模拟数据库中的语音的情感自然度跟现实真实情感还有差距,备受质疑。因而,对人类现实生活中真实情感语音的识别研究更接近实际,更有意义。为此,本文建立了一个包含说话人自然情感的汉语语音数据库。我们通过从20个电视访谈对话节目视频素材中建立一个与说话者无关的自然度较高的 800句大小的汉语情感语音数据库。每一个访谈对话节目中,有至少2个人自然和随意性地讨论一些当代的典型社会现象,家庭冲突或感人事迹等话题。这些人物谈论话题时,一般预先没有讲稿,自发地进行即兴讨论。因此,这些人物讨论时情感的表达是非常真实的。由于讨论话题范围的限制,生气、高兴、悲伤和中性4类常见的情感类型的视频片段数量较多。采用专业音频编辑软件 CoolEdit(http://www.mp3-converter.com/cool_edit_2000.htm)从整个视频中提取语音文件,剔除其中人物情感表达不明显,背景音乐等杂音较多的语音片段,然后从较理想的语音片段中切分出不同人物在某一短时间内完整的一小句情感语音,作为情感分析语料。最终提取到 53人(女性 37,男性 16)的采样率为 16 kHz,16 bit的单声道WAV格式的 800句数据库。其中,生气、高兴、悲伤和中性各200句。最后请4个听众随机听取测试,对于情感特征不是很明显的语句进行了删除和重新提取。
3.2 语音情感特征参数提取
目前,研究者普遍发现与说话人发音时密切相关的情感特征参数,主要包括发音语调和轻重相关的基音频率、振幅(或能量)、发音持续时间等韵律特征[3,16],以及发声方式相关的共振峰、频谱能量分布,谐波噪声比等音质特征[17,18]。因此,本文对自然情感语音数据库的每一句语音,提取能够表达情感信息的韵律特征和音质特征参数,共48个,如表2所示。
3.3 实验测试及结果分析
实验时,全部特征参数数据归一化到[0,1],分类器采用KNN分类器。KNN是一种基于样本学习的传统无参数分类器,运算快,采用一个最近邻训练模式(K=1)时用于语音情感识别的性能比较好[3]。
为了提高识别结果的可信度,识别中采用10次交叉检验技术。即所有语句被平分为10份,每次使用其中的9份数据用于训练,剩下的1份数据用于测试。这样的识别实验相应重复10次,最后取10次的平均值作为识别结果。每次交叉检验时, 对Improved-SLLE和SLLE的常数因子α的自动最优化算法也相应执行一次。
实验1 对提取的原始48维语音特征数据不作任何降维处理,直接进行情感识别实验,识别结果如表3所示。
由表3可得,生气和中性的识别结果较为令人满意,正确识别率分别达到了83%和86%。4类情感的总体平均正确识别率为75.13%。但高兴和悲伤的正确识别率略低,其中高兴为70%,悲伤为61.5%。主要原因是,高兴和生气发音时的韵律特征相似,而悲伤和生气发音时的音质特征相似,从而导致高兴与生气、悲伤与生气这两对情感相互之间较易混淆[17]。
实验2 采用PCA,LLE,Isomap,SLLE和Impoved-SLLE及相应的泛化算法分别应用于原始48维语音特征数据的降维,然后对降维后的低维判别特征数据进行情感识别测试,并比较识别结果。LLE,Isomap和 SLLE的泛化算法的实现类似于Impoved-SLLE。而PCA的泛化算法则可以直接通过从训练样本得到的线性映射矩阵与新测试样本相乘得到。降维的目标维度范围取2 ≤d≤ 2 0。LLE,Isomap,SLLE和Impoved-SLLE的近邻数取k=12时的性能较好[5]。每次交叉检验时,每一维对应的Improved-SLLE和SLLE常数因子α的最优值,采用常数因子α的自动最优化算法取得。表 4和表 5分别列出了 10次交叉检验中所取得的每一维对应的Improved-SLLE和SLLE常数因子α最优化的平均值。由表4和表5可见,不同维度的Improved-SLLE常数因子α的最优化平均值大小一般不超过0.5,比较稳定,而SLLE常数因子α的最优化平均值大小变化明显。主要原因是Improved-SLLE采用的非线性监督距离中存在另一参数β。该β的取值是所有成对数据点欧氏距离的平均值,因而β能对α的变化起到一定的平衡作用。

表2 语音情感特征参数

表3 原始特征数据不降维时的语音情感识别结果
图2给出了5种不同降维方法取得的每一维的语音情感识别结果。表6列出了在不同维度上各种方法取得的最好性能的比较。其中,“Original”方法表示对原始 48维特征数据不作任何降维所取得的识别结果(见表3)。
由图2和表6的结果,可以得知:(1)与其它方法相比,Improved-SLLE经过泛化和常数因子α最优化后,取得了最好的情感识别性能。Improved-SLLE仅利用较少的9维嵌入特征就取得了90.78%的最高正确识别率,比Original,PCA,LLE,Isomap和 SLLE 5种方法分别高出了 15.65%,18.28%,26.13%,22.01%和10.03%。原因是Improved-SLLE算法中采用了非常有利于嵌入数据分类的非线性监督距离,使得产生的低维嵌入特征数据具有最好的泛化能力和判别力。(2)SLLE经过泛化和常数因子α最优化后,取得的识别性能高于 PCA,LLE和Isomap。作为一种监督降维方法,所以SLLE能够比非监督的PCA,LLE和Isomap 3种降维方法性能更好。值得指出的是,当直接利用没有经过泛化的SLLE算法进行情感识别时,识别效果很差,只能取得 22.45%的最高正确识别率。(3)与 LLE和Isomap相比,PCA取得了更好的识别结果。这说明位于非线性流形上的语音特征数据的非线性程度并不是很高,使得线性PCA方法仍然可以提取到比非线性方法LLE和Isomap具有更强判别力的低维嵌入特征数据。另外一个原因是,LLE和 Isomap都属于非监督方式的降维,不能有效发挥出它们的最佳性能。(4)对于LLE和Isomap两种方法,Isomap比LLE表现更好。Isomap是一种全局降维方法,嵌入时保留数据点的全局结构信息。而LLE是一种局部降维方法,嵌入时只保留数据点的局部结构信息。实验表明嵌入时保留全局信息比局部信息更有效。(5)所有降维算法的识别性能刚开始随着维度的增加而显著提高,但当维度更高时,他们的性能反而会有所下降,最终趋向于稳定。这归咎于嵌入在48维声学特征空间数据的内在结构信息的本征维数刚好位于维度范围[2, 20]之间。这也说明实验时降维的维度范围取[2, 20]是合理的。
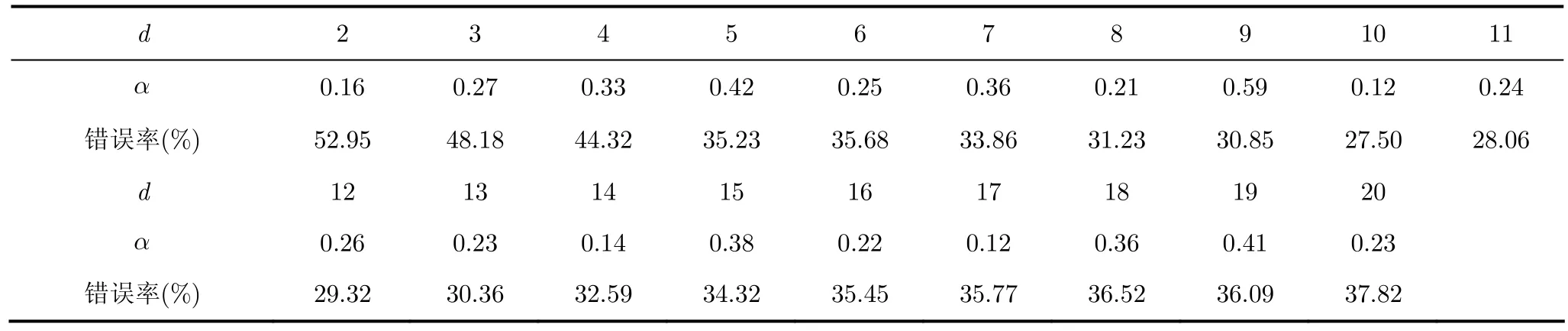
表4 不同维度的Improved-SLLE常数因子α的最优化平均值

表5 不同维度的SLLE常数因子α的最优化平均值

表6 不同方法取得的最好性能比较

图2 不同降维算法取得的语音情感识别结果
4 结束语
本文在克服SLLE算法的不足基础上提出了一种改进的监督局部线性嵌入算法Improved-SLLE,同时发展了Improved-SLLE的泛化算法和距离中常数因子的自动最优化算法。利用Improved-SLLE实现对48维语音情感特征参数数据的非线性降维,提取相应的低维嵌入判别特征进行语音情感识别,取得了90.78%的正确识别率。与其它使用方法相比,Improved-SLLE的识别性能最好。当前,语音情感识别的研究还处于初级阶段,发展比 Improved-SLLE更强的新型监督流形算法,对以后的语音情感识别的研究具有重要意义。
[1] Picard R. Affective Computing[M]. MIT Press, Cambridge,MA, 1997: 1-24.
[2] Jones C and Deeming A. Affective human-robotic interaction[C]. Affect and Emotion in Human-Computer Interaction, Springer, 2008, Lecture Notes in Computer Science, 4868: 175-185.
[3] Morrison D, Wang R, and De Silva L C. Ensemble methods for spoken emotion recognition in call-centres[J].Speech Communication, 2007, 49(2): 98-112.
[4] Picard R. Robots with emotional intelligence[C]. 4th ACM/IEEE international conference on Human robot interaction,California, 2009: 5-6.
[5] Errity A and McKenna J. An investigation of manifold learning for speech analysis[C]. 9th International Conference on Spoken Language Processing (ICSLP'06), Pittsburgh, PA,USA, 2006: 2506-2509.
[6] Goddard J, Schlotthauer G, and Torres M,et al..Dimensionality reduction for visualization of normal and pathological speech data[J].Biomedical Signal Processing and Control, 2009, 4(3): 194-201.
[7] Yu D. The application of manifold based visual speech units for visual speech recognition[D]. [Ph.D.dissertation], Dublin City University, 2008.
[8] Roweis S T and Saul L K. Nonlinear dimensionality reduction by locally linear embedding[J].Science, 2000, 290(5500):2323-2326.
[9] Tenenbaum J B, Silva Vd, and Langford J C. A global geometric framework for nonlinear dimensionality reduction[J].Science, 2000, 290(5500): 2319-2323.
[10] Jolliffe I T. Principal Component Analysis[M]. New York:Springer, 2002: 150-165.
[11] De Ridder D, Kouropteva O, and Okun O,et al.. Supervised locally linear embedding[C]. Artificial Neural Networks and Neural Information Processing-ICANN/ICONIP-2003,Springer, 2003, Lecture Notes in Computer Science, 2714,333-341.
[12] Liang D, Yang J, and Zheng Z,et al.. A facial expression recognition system based on supervised locally linear embedding[J].Pattern Recognition Letters, 2005, 26(15):2374-2389.
[13] Pang Y, Teoh A, and Wong E,et al.. Supervised Locally Linear Embedding in face recognition[C]. International Symposium on Biometrics and Security Technologies,Islamabad, 2008: 1-6.
[14] Platt J C. Fastmap, MetricMap, and Landmark MDS are all Nystrom algorithms[C]. 10th International Workshop on Artificial Intelligence and Statistics, Barbados, 2005:261-268.
[15] Aha D, Kibler D, and Albert M. Instance-based learning algorithms[J].Machine Learning, 1991, 6(1): 37-66.
[16] 赵力, 将春辉, 邹采荣等. 语音信号中的情感特征分析和识别的研究[J]. 电子学报, 2004, 32(4): 606-609.Zhao Li, Jiang Chun-hui, and Zou Cai-rong,et al.. A study on emotional feature analysis and recognition in speech[J].Acta Electronica Sinica, 2004, 32(4): 606-609.
[17] Zhang S. Emotion recognition in Chinese natural speech by combining prosody and voice quality features[C]. Advances in Neural Networks - ISNN 2008, Springer, 2008, Lecture Notes in Computer Science, 5264: 457-464.
[18] Zhao Y, Zhao L, and Zou C,et al.. Speech emotion recognition using modified quadratic discrimination function[J].Journal of Electronics(China), 2008, 25(6):840-844.
猜你喜欢
车主之友(2022年4期)2022-08-27
数学年刊A辑(中文版)(2021年1期)2021-06-09
海峡姐妹(2019年12期)2020-01-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
新高考·高一物理(2016年3期)2016-05-18
火控雷达技术(2016年1期)2016-02-06
燕山大学学报(2014年1期)2014-03-11
