
基于时空关系和关联规则挖掘的上下文信息缺失插补研究
2010-05-18 08:49:48王玉祥乔秀全李晓峰孟洛明
电子与信息学报 2010年12期
王玉祥 乔秀全 李晓峰 孟洛明
(北京邮电大学网络与交换技术国家重点实验室 北京 100876)
1 引言
在上下文信息处理机制中,由于现实世界的复杂性、多变性以及人类自身认识的局限性和主观性,使得人们获得的上下文信息中含有大量的不确定、不准确、不完全、不一致的地方。上下文信息存在缺失的原因可能是传感器之间时钟同步错误,传感器断电,传感器失效,通信传输错误,人为攻击等,这在上下文信息处理机制中是不可避免的。传感器数据的缺失,往往导致挖掘的信息知识准确性存在偏差,严重的会产生错误决策,导致系统瘫痪,造成重大的损失。因此,上下文信息的缺失插补方法是上下文信息处理机制的关键技术之一,数据的完备性是推理高层上下文信息从而形成智能决策的前提基础。
当前,比较常用的数据缺失插补方法有线性回归插补[1],最近邻插补[2],热板、冷板插补,期望最大EM(Expectation Maximum)[3]算法,最大可能性插补[4,5],多重插补方法[6,7],贝叶斯网络(Bayesian Network)统计分析法[8]等统计学方面的插补方法,但是这些方法并没有考虑到传感器流数据的特点。传感器数据最突出的特点:一是数据之间有很强的关联性;二是传感器数据之间具有明显的时空特性。另外,最近较多的是采用数据挖掘的方法,特别是基于关联规则的挖掘方法[9,10],这些方法虽然考虑了数据之间的关联特性,但是没有涉及传感器数据的时空特性。文献[11,12]也只是研究了传感器数据的时空特性去进行数据缺失插补,但是没考虑数据之间的关联特性。因此以往的研究方法都存在着不太全面的弊端,缺少全面综合而又满足实时应用的数据缺失插补方法。
为了更加准确地对传感器数据缺失进行插补,本文针对传感器数据这一类上下文信息,根据传感器数据的关联性和时空特性两大特点,提出了基于时空关系和关联规则挖掘的上下文信息缺失插补方法,全面综合讨论了数据插补方法,提高了传感器数据缺失插补的准确性。
本文第2节首先介绍了关联规则挖掘的基本概念和基本步骤。第3节提出了基于时空关系和关联规则挖掘的上下文信息缺失插补方法,并详细阐述基于时空关系和关联规则挖掘的上下文信息缺失插补的详细过程。第4节通过仿真实验验证了基于时空关系和关联规则挖掘的上下文信息缺失插补方法的高效性和合理性。最后给出结论和未来的工作。
2 关联规则挖掘
2.1 关联规则挖掘的相关概念
定义1 数据项:在传感器采集数据的过程中,传感器X和Y采集到的数值可以根据用户的不同要求,即颗粒度的要求不同离散成不同区间的数值,离散化后的数值称之为传感器的数据项。若干个数据项的集合就构成数据项集。数据项集所包含的数据项的个数称为该数据项集的维数,长度为m的数据项集,定义为m维的数据项集。
定义2 支持度:在无线传感网络中,传感器X和Y在某一段时间区间内采集的数据项中相同的个数和传感器X和Y在这一段时间区间内采集的数据项的总的个数的比值称之为关联规则X→Y的支持度。数据项集合D的支持度通常记作supp(D),关联规则X→Y的支持度通常记作supp(X→Y)。
定义 3 信任度:在无线传感网络中,对于传感器X和Y,在某一段时间区间内,传感器X采集到的数据项而同时传感器Y也能够同时采集到相同数据项概率可能性的大小,称之为关联规则X→Y的信任度,由信任度的定义可知信任度可以用支持度来表示成为supp(X→Y)/supp(X)。
定义 4 最小支持度:在实际的应用系统中,根据用户对系统的要求不同确定的关联规则支持度需要满足的最小的数值,它是满足用户最低需求的支持度的数值,称之为最小支持度,通常记作minsupp。
定义 5 最小信任度:在实际的应用系统中,根据用户对系统的要求不同确定的关联规则信任度需要满足的最小的数值,它是满足用户最低可靠性保证的数值,称之为最小信任度,通常记作minconf。
定义 6 频繁数据项集:对于用户给定的最小支持度minsupp,传感器X采集到的数据项D支持度如果大于该最小支持度minsupp,则称数据项D为频繁数据项集,同时称传感器X为频繁节点集。
2.2 关联规则挖掘概念
在上下文信息采集网络中,对于传感器X和Y,形如蕴含式X→Y称之为关联规则,其中传感器X和Y都是独立采集的。关联规则是统计学中简单而又实用的一种推理规则,也是数据挖掘研究热点领域,特别适用于分析传感器采集的大量数据项之间频繁出现的模态关联性,从而对传感器采集的数据缺失进行插补。
支持度与信任分别大于用户定义的最小阈值minsupp和minconf的规则通常称为强关联规则。关联规则挖掘的目标就是从给定的传感器节点所采集的所有数据项中找到所有的强关联规则节点,分析出传感器节点所采集的所有数据项的规律,从而挖掘出各节点之间关联性、相关性,进一步可以对节点数据项进行推理、预测。
2.3 关联规则挖掘的基本过程
由关联规则挖掘的形式化定义可知,通常情况下,对于关联规则挖掘问题可以划分成两个基本的过程:
(1)频繁传感器节点的查找 对于用户设定的最小支持度 minsupp,从传感器网络系统中查找所有的频繁传感器节点集合,即满足支持度大于等于minsupp的传感器节点集合。实际上,这些频繁传感器节点集合或许具有一定的推出关系。不失一般性,我们通常只考虑那些不被其它传感器节点集合所推出的频繁最大传感器节点集合。这些频繁大传感器节点集合是形成强关联规则前提。
(2)强关联规则的形成 对于用户设定的最小信任度 minconf,在频繁最大传感器节点集合,根据一定的具体方法来生成信任度大于等于 minconf的关联规则,从而形成蕴含式的强关联规则,进一步可以推理出传感器节点之间的关系,为传感器数据项缺失的插补奠定基础。
在关联规则挖掘的两个基本过程中,其中第(1)个基本过程是关联规则挖掘算法设计的关键基础,频繁传感器节点的查找效率的高低直接影响该挖掘算法有效性,这一步骤也是计算密集型过程,一般要通过并行分布式计算来处理该过程。而第(2)个基本过程仅仅是根据生成的频繁传感器节点的集合按照一定生成规则来创建相应蕴含式强关联规则的过程,不是计算密集型过程。因此,目前关联规则算法设计关键问题主要是围绕怎样来生成最大传感器频繁节点集合展开的。
3 基于时空关系和关联规则挖掘的上下文信息缺失插补方法
为了更加准确进行上下文信息缺失数据插补,使数据缺失插补更加接近实际应用,本文引入时间新鲜度的概念。对传感数据采样序列回合号(round_number)进行加权,按照指数级np(p≥1)对采集到的传感器数据进行时间序列化,时间新鲜度大的数据在插补的过程中占有更大的权重。因此,更加准确、真实反映传感器数据的实际使用。本文还对支持度和信任度重新进行了定义,主要是考虑了时间新鲜度的概念,在本文中分别命名为加权支持度和加权信任度:
定义 7 加权支持度:在无线传感网络中,传感器X和Y在某一段时间区间内采集的数据项中相同的带有序列号加权权重个数和传感器X和Y在这一段时间区间内采集的数据项的总的带有序列号加权权重个数的比值称之为关联规则X→Y的加权支持度。数据项集合D的加权支持度通常记作 wei_supp(D),关联规则X→Y的加权支持度通常记作wei_supp(X→Y)。
定义 8 加权信任度:在无线传感网络中,对于传感器X和Y,在某一段时间区间内,传感器X采集到的带有序列号加权权重的数据项而同时传感器Y也能够同时采集到相同带有序列号加权权重的数据项概率可能性的大小,称之为关联规则X→Y的加权信任度,由加权信任度的定义可知加权信任度可以用加权支持度来表示成为 wei_supp(X→Y)/wei_supp(X)。同理,可以定义最小加权支持度和最小加权信任度,本文不再赘述。
对传感器数据采用时空关系处理后,得到的传感器数据再进行关联规则挖掘,本文采用无冗余的闭频数据项集关联规则挖掘的方法,节省计算的时间和内存空间的占用,提高传感器数据插补的效率和准确性,有利于实时性系统的应用。
定义9 闭数据项集:在无线传感器网络中,传感器节点采集到的数据项集合设定为S={s1,s2,…,sm}是m维的传感器数据项的序列号,U={u1,u2,… ,un}是n维数据项数值,则数据项可形式化为P=S.U., 设A,B为数据项序列号S的子集,A的个数为k的称A为k数据项集,传感器采集的数据流序列b为P的子集。则闭数据项集是满足以下的函数f和g的传感器数据序列:对于f(B)={i∈P|b∈B,i∈b}以及g(A)={b∈S|i∈A,i∈b},函数f表示返回所有包含在传感器采集数据序列B中的数据项集合,而函数g表示的返回的是包含给定数据项集A的数据序列集合。数据项A是闭数据项及当且仅当下式成立g(f(A))=f(g(A))=f⋅g(A)=A,H=f⋅g称作闭运算或者称作闭操作符。
定义10 闭频数据项集:设P首先是闭数据项集,如果它的加权支持度大于或者等于用户定义的最小加权支持度,则P为闭频数据项集。
对采集到的传感器数据进行序列号(回合号)加权,并引入了时间新鲜度。而对于传感器数据之间的空间位置关系,主要是进行空间相似度计算,即是采用Pearson(皮尔森)相关系数的方法,找到空间上最相近的传感器数据,然后再进行关联规则的挖掘。
关联规则挖掘算法是计算密集型的算法,为了减小计算的复杂度,提高上下文信息缺失插补的准确性,结合集合传感器数据的特点,首先要对数据进行时空化处理。
本节根据关联规则挖掘的两个步骤,结合传感数据的时空特性,提出基于时空关系和关联规则挖掘的上下文信息缺失插补的基本过程可分为4步:
第1步 传感数据空间化 对采集到的传感数据首先计算其空间的相关度。本文采用Pearson相关系数法。Pearson相关系数法是计算两个变量X和Y之间相关度常用的方法,其数值在[-1,1],用户定义阈值,比如选择 Pearson相关系数大于等于 0.5的那些传感器作为关联规则挖掘的传感器S1,S2,…,。空间化后降低计算复杂度,利于实时性的应用,也大大提高了数据插补的准确性。
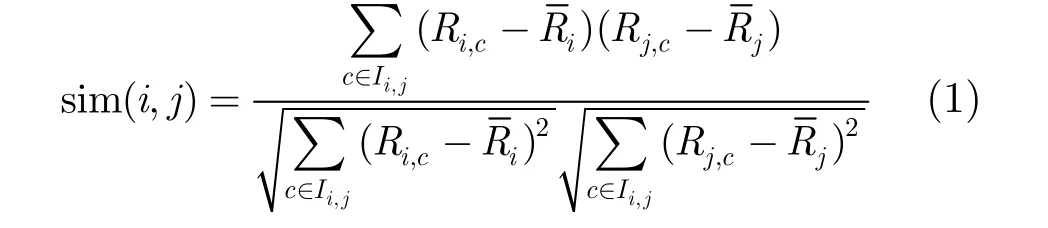
通常是采用相关相似度度量公式即Pearson相关系数度量各传感器之间的相关度,设传感器i和传感器j共同采集的数据集合为Ii,j,则传感器i和传感器j的相似度sim(i,j)为其中Ri,c表示传感器i对数据c的采集,和分别表示传感器i和传感器j对数据的平均值。注意,数据的平均值是指两个传感器有共同采集数值的平均值。求得和相关相似性系数的范围是[-1,1],相关系数越大,则表示这两个传感器的采集数据越接近,其采集的准确率就越高。
第2步 传感数据时间序列化 对采集到的传感数据按照回合进行加权处理。使采集到的数据和时间进行相关联。每个传感器数据前面加上相应的回合权重系数。在此基础上计算最小加权支持度和最小加权信任度。对传感器数据时间序列加权的方法可采用各种不同的方法。要根据具体的问题具体分析,主要是考虑数据对时间的敏感程度大小,小的可以采用线性增长的趋势y=a⋅x,对时间敏感程度高的数据可以采用指数增长的方式,例如y=a⋅pn(p≥1)的方式,其中p为调整参数,其数值根据具体数据特点而定。
第 3步 查找频繁数据项集 通过用户给定的最小加权支持度wei_minsupp,找出所有频繁数据项集合,也就是满足加权支持度大于等于 wei_minsupp的数据项集。实际上,这些频繁数据项集可能具有推出关系。不失一般性,我们只考虑那些不被其它频繁数据项集所推出的频繁大数据项的集合。而这些频繁大数据项集是形成强关联规则的前提基础。
以温度传感器采集的温度数据为例,如表 1。假设有4个传感器S1,S2,S3,S4,假定p=3且第4回合数据出现缺失。
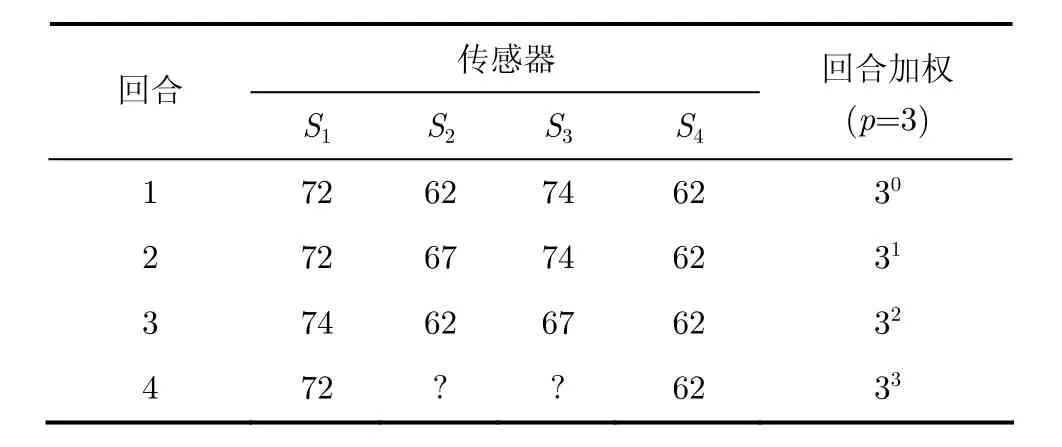
表1 4个温度传感器采集的温度数据及其缺失情况
假设最小加权支持度 50%,最小加权信任度50%。由表 2可知,闭频数据项集及其最小加权支持度分别为{S1.72,S3.74,S4.62}=2,{S1.72,S4.62}=3, {S2.62,S4.62}=2, {S4.62}=4。
第 4步 生成强关联规则 通过用户给定的最小加权信任度 wei_minconf,在每一个最大频繁数据项集合中,生成加权信任度大于等于 wei_minconf的强关联规则。

表2 闭频数据项集及其最小加权支持度
产生关联规则的具体操作过程如下:
(1)对于每一个频繁数据项集P,产生所有的P的非空、真子集合。
(2)对于P的每一个非空、真子集Q,如果supp(P)/supp(Q)大于等于最小加权信任度,则输出强关联规则Q→(P-Q)。
对于上例来说,可以得出:规则1:{S1.72,S4.62}→S3.74,加权支持度为 1/2,加权信任度为 2/3。规则 2:S4.62→S2.62,加权支持度为 1/2,加权信任度为1/2。
因此,对于第4回合采集到的数据,S2缺失的数据66.7%可能是62,S3采集到的数据50%可能是74。
4 仿真实验及结果分析
4.1 实验环境
硬件配置如下:CPU: Inte1Pentium 2.8G;内存:DDR512M;
软件环境如下:操作系统:windows XP;数据库:MySQLserve:5.0;编程语言:R PROJECT。
4.2 仿真实验及结果分析
本文实验数据来自于美国三菱电子研究实验室MERL(Mitsubishi Electric Research Labs)公开的一个大规模传感器数据集,实验数据可以从网站http://www.merl.com/wmd通过 FTP获得:ftp://wmd@ftp.merl.com/,username:wmd passwd:w0rksh0pWMD,MERL主要是利用了200个传感器来记录实验室两层建筑物办公人员一年内的不同时间不同位置的活动情况。为了简化起见,本文实验取了其中的部分实验数据,包括100个不同位置不同时间段的温度传感器数据,使用温度传感器采集的 20个回合数据来进行实验。本文利用 SQL SERVER数据库存储传感器数据,并利用 R PROJECT软件对传感器数据进行统计分析处理,R PROJECT是一个有着统计分析功能及强大作图功能的开源软件系统。
实验 1 缺失数据插补的准确性比较 为了比较各种插补方法的准确性,本文采用常用均方根误差RMSE(Root Mean Square Error)进行比较,其公式如下:

其中iA是传感器实际值,Ei是传感器插补值,n为缺失的数量,N是采用数据集子集数量,最终结果可以取几个子集的平均值,均方根误差RMSE越小,表示插补方法越准确。
本文提出的STARM方法与传统简单线性回归(SLR),EM 算法,WARM(Window Association Rule Mining)方法,CARM(Closed Association Rule Mining)方法,FARM(Freshness Association Rule Mining)方法进行比较如图1所示。
从图 1可以看出,数据插补准确性,STARM要优于传统的统计方法和其他的关联规则挖掘方法。
实验 2 缺失数据插补所用的时间比较 本文提出的对传感器数据空间化减小了计算的复杂性,而同时采用回合权系数法引入的时间新鲜度又增加了计算的复杂度,最后的综合结果需要通过仿真实验进行实际性能评估。
本文采用平均插补时间 AIT(Average Imputation Time)即每个回合平均占用的数据插补的时间,其仿真结果如图2所示。
从图2可以看出,EM和SLR由于算法的简单性所用的时间最少,而与其他算法比较中 STARM效率较高,所用时间较少,从而节省了系统时间开销。
实验3 缺失数据插补所占用内存空间比较
本文还采用了缺失数据插补过程中所占内存空间大小来衡量STARM算法的高效性。其仿真结果如图3所示。
从图3可以看出,EM和SLR由于算法的简单性所占用的内存最小,而与其他算法比较中STARM 效率较高,占用内存较小,从而节省了系统空间开销。
5 结束语
本文依据传感器数据这一流数据的关联性和时空特性,引入了时间新鲜度的概念,并依据传统的关联规则挖掘的基本过程,提出了基于时空关系和关联规则挖掘的上下文信息缺失插补方法(STARM),较传统的缺失数据插补方法具有更高的准确性,并且减小了时空开销。实验证明此方法的在数据插补准确性优于传统的统计方法和其他关联规则挖掘方法,验证了算法的合理性和高效性。
由于对传感器数据进行时间序列化,如果采用指数加权,其数值会呈指数级递增,数据有可能会溢出,如何进行控制数据的溢出,是本文未来进一步的研究工作。

图1 SLR,EM,WARM,CARM,FARM,STARM之间RMSE值的比较
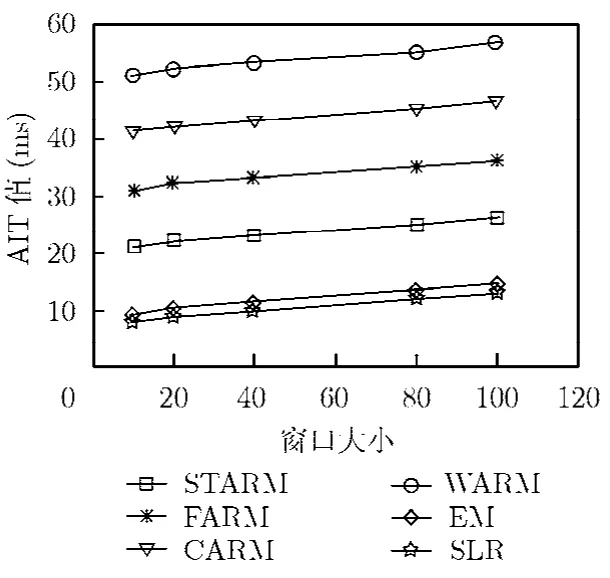
图2 SLR,EM,WARM,CARM, FARM,STARM之间AIT值的比较
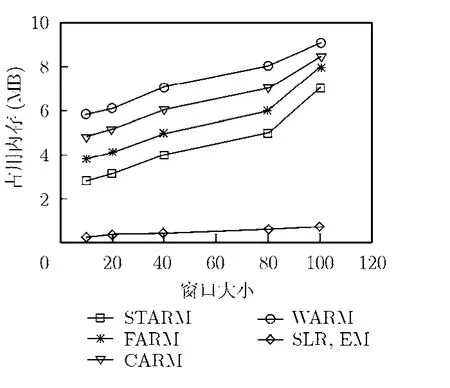
图3 SLR,EM,WARM,CARM,FARM,STARM之间占用内存的比较
[1] Cool A L. A review of methods for dealing with missing data[C]. Paper presented at the Annual Meeting of the Southwest Educational Research Association, Dallas, TX,2000: 1-34.
[2] Shao Jun and Wang Han-sheng. Confidence intervals based on survey data with nearest neighbor imputation [J].Statistica Sinica, 2008, 18(1): 281-297.
[3] Gu Dong-bing. Distributed EM algorithm for Gaussian mixtures in sensor networks [J].IEEE Transactions on Neural Networks, 2008, 19(7): 1154-1166.
[4] Allison P D. Missing data [D]. Thousand Oaks, CA Sage,2002.
[5] Qin Yong-song and Zhang Shi-chao. Empirical likelihood confidence intervals for differences between two datasets with missing data [J].Pattern Recognition Letters, 2008, 29(6):803-812.
[6] 庞新生. 分层随机抽样条件下缺失数据的多重插补方法[J].统计与信息论坛, 2009, 24(5): 19-21.Pang Xin-sheng. Multiple imputation for missing data in stratified random sampling [J].Statistics&Information Forum, 2009 24(5): 19-21.
[7] 金勇进, 邵军. 缺失数据的统计处理. 北京: 中国统计出版社,2009: 155-161.Jin Yong-jin and Shao Jun. Statistical Analysis with Missing Data [M]. Beijing: China Statistics Press, 2009: 155-161.
[8] Deshpande A, Guestrin C, Madden S, Hellerstein J, and Hong W. Model-driven data acquisition in sensor networks[C]. Proceedings of the 30th VLDB (Very Large Databases)Conference, Toronto, Canada, 2004: 588-599.
[9] Le Gruenwald, Hamed Chok, and Mazen Aboukhamis. Using data mining to estimate missing sensor data[C]. Proceedings of the Seventh IEEE International Conference on Data Mining Workshops, Norman, USA, 2007: 207-212.
[10] Nan Jiang. A data imputation model in sensor databases [C].High Performance Computing and Communications, Third International Conference, HPCC 2007, Houston, USA,September 26-28, 2007: 86-96.
[11] Li Y and Parker L E. Classification with missing data in a wireless sensor network[C]. IEEE Southeast Conference,Huntsville, Alabama, April 2008: 533-538.
[12] Li Y and Parker L E. A spatial-temporal imputation technique for classification with missing data in a wireless sensor network[C]. 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Acropolis Convention Center Nice, France, Sept. 22-26, 2008: 3272-3279.
猜你喜欢
四川党的建设(2022年8期)2022-04-28 21:29:35
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
作文大王·低年级(2018年10期)2018-12-06 06:22:44
环球时报(2018-01-23)2018-01-23 05:25:53
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
计算机工程(2015年4期)2015-07-05 08:27:45
IT经理世界(2014年5期)2014-03-19 08:34:52
