
将关联规则挖掘算法应用于警校学员队信息管理
2010-01-03 01:00:58汤钰涵
中国人民警察大学学报 2010年5期
●汤钰涵
(公安海警高等专科学校,浙江宁波 315801)
一、引言
随着 Internet的迅猛发展,当今社会已进入网络时代,计算机信息技术广泛深入到人类社会的各个领域并发挥着越来越重要的作用,各种信息管理系统应运而生。在大背景的带动下,现在部队信息化建设也开展得如火如荼,办公自动化、部队信息化日趋完善。公安海警高等专科学校作为培养公安现役边防学员的高等学府,更要与时俱进,加强信息化建设。为解决部队院校学员队队务管理信息化建设问题,针对公安海警高等专科学校学员队军事化管理的特点,拟将关联规则数据挖掘技术应用于学员队信息管理中,把管理人员从繁琐的数据计算处理中解脱出来,对促进学员队管理工作的科学化、正规化具有十分重大的意义。
二、关联规则挖掘、基本思想
数据库中知识发现(KDD)是从目标数据集合中提取出有效的、可信的、潜在有用的以及最终可理解的模式的非平凡过程。在此描述中:数据是一系列事实的集合(例如数据库中的实例),模式是使用某种语言对数据集合一个子集的表述,过程是在 KDD的步骤(如数据的预处理、模式搜索、知识表示及知识评价等),非平凡是指它已经超越了一般封闭形式的数量计算,而将包括对结构、模式和参数的搜索。对于数据挖掘,比较公认的数据挖掘定义是 W.J.Frawlev.Gpiatetsky-shapiro等人提出的:数据挖掘就是从大型数据库的数据中提取出人们感兴趣的知识。这些知识是隐含的、事先未知的潜在有用信息,提取的知识表示为概(Coneepts)、规则(Rules)、规律(Regularities)、模式(Patterns)等形式。而更广义的说法是:数据挖掘意味着在一些事实或观察数据的集合中寻找模式的决策支持过程。这样,数据挖掘的对象不仅可以是数据库,也可以是文件系统,或其他任何组织在一起的数据集合,例如 WWW信息资源。关联规则挖掘是数据挖掘的一个重要研究方向,也是数据挖掘中最成熟、最活跃的研究领域。它表示的是数据库中一组对象之间某种关联关系的规则(例如“同时发生”或“从一个对象可以推出另一个”),形式如 AB⇒CD(95%),用例子表示就是“购买了项目 A和 B的顾客中有 95%的人又买了 C和D”。挖掘的一般对象是事务数据库。这种数据库的一个主要应用是零售业,条码技术的发展使得数据的收集变得更容易、更完整,从而存储了大量的交易资料。关联规则就是辨别这些交易项目之间是否存在某种关联关系。利用这些信息可以进行商品销售目录设计、商场布置、生产安排、针对性的市场营销等。
关联规则的基本思想:一是找到所有支持度大于最小支持度的频繁项集,即频集。二是使用第一步找到的频集产生期望的规则。其核心方法是基于频集理论的递推方法。
三、警校学员队信息管理现状
目前,随着学校的不断建设和发展,越来越多的学员进入学校学习和深造,学校编制不断扩大,学员队日常管理信息不断积累。而学员队各项信息记录不够详细和具体,记录格式不规范或过于简单,而且纸质资料容易损坏或丢失,查询和上报信息时存在着诸多不便。因此,加强学员队队务信息管理,加速信息化进程、提高学员队队务信息管理水平变得越来越重要。一般的信息管理系统,其基本特征是“联机事务处理”,一般着眼于后台管理,缺少直接面对用户的系统功能,并且不适用军事院校这种比较特殊的单位。
四、关联规则的经典算法
Agrawal等在 1993年设计了一个基本算法——Apriori算法,关联规则的一个重要方法,这是一个基于两阶段挖掘思想的方法,挖掘算法的设计分解为两个子问题:
1.找到所有支持度大于等于最小支持度的项集(Itemset),这些项集称为频繁项目集 (FrequentItemset)。
2.使用第一步找到的频集产生期望的规则。
在这里,第二步相对简单一点。如给定了一个频集 Y=I1,I2,…,Ik,(K≥2),Ij∈I产生只包含集合{I1,I2,…,Im}中的项的所有规则(最多 K条),其中每一条规则的右部只有一项,(即形如[Y-Ii]⇒Ii,∀1≤i≤k),这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。
为了生成所有频集,使用了递推的方法。其核心思想如下:
L1={Large l-Itemsets}:
For(K=2;Lk-1≠Φ;K++)Do
Begin
Ck=Apriori-Gen(Lk-1);//新的候选集
For All Transaetions T∈D Do
Begin
C1=Subset(Ck,T);//事务 T中包含的候选集
For All Candidates C∈CtDo
C.Count++;
End
Lk={C∈ Ck(C.Count≥Minsup)}
End
End
Answer=∪Lk
首先产生频繁 1-项集 L1,然后是频繁 2-项集L2,直到有某个 R值使得 Lr为空,这时算法停止。这里在第 K次循环中,过程先产生候选 K-项集的集合 Ck,Ck中的每一个项集是对两个只有一个项不同的属于 Lk-1的频集做一个(K-2)连接来产生的。Ck中的项集是用来产生频集的候选集,最后的频集Lk必须是 Ck的一个子集。Ck中的每个元素需在交易数据库中进行验证来决定其是否加入 Lk,这里的验证过程是算法性能的一个瓶颈。这个方法要求多次扫描很大的交易数据库,即如果频集最多包含 10个项,那么就需要扫描交易数据库 10遍,这需要很大的 I/O负载。
APriori_Gen()函数的参数为 Lk-1,结果返回含有 K个项目的候选项目集 Ck,事实上它由两步构成:Join连接步和 Prune修剪步。Jnin步通过对 Lk-1自连接操作生成 Ck*,然后对任意的 C∈Ck
*,删除Ck
*中所有那些(K-1)子集不在 Lk-1的项目集,得到候选集合 Ck。具体算法描述如下:
APriori_Gen的 Join算法步骤:
Ck=Φ
For All Itemsets X∈ Lk-1,And Y∈Lk-1Do
If X1=Y1∧ …∧ Xk-2=Yk-2∧ Xk-1<Yk-1Then
Begin
C=X1X2…Xk-1Yk-1;
End;
Apriori_Gen的 prune算法步骤:For All Itemsets C∈Ck
For All(K-1)-Subsets SOf CDo
If(S∉Lk-1)Then
Delete C From Ck;
End
End;
在 Join步中,将 Lk-1自连接生成 Ck*,若上面的算法描述中没有 If条件,那么将出现很多重复项。因为约定项目集中的项目是按照字母顺序排列的,所以,通过使用 If条件,可以避免产生重复的项。另外 Prune步骤是用来删除 Ck中的非频繁项目集的。
举例说明如下:L3={(A,B,C),(A,B,D),(A,C,D),(A,C,E),(B,C,D)},通过 Join操作后得到:C4={(A,B,C,D),(A,C,D,E)},修剪后得到C4=(A,B,C,D),因为{C,D,E}∉ L3.
APriori算法首先扫描数据库并计算其中的每一个项目 I的支持度,产生大 1项目集 L1,然后再扫描数据库计算大 2-项目集 L2,…,直到有个 R值使得Lr为空,这时算法停止。在第 K次循环中,由两步组成:
(1)从大(K-1)项目集 Lk-1中产生出候选集合Ck;
(2)扫描数据库计算 Ck中每一个候选集的支持度;
候选集的产生过程是从大(K-1)项目集中计算出潜在的大 K-项目集,一个新的 K候选集由两个大 K-1项目集构成,这两个大项集的前(K-2)个项目是相同的(假设项目都是按照字典序排列的)。产生候选集 Ck后,要返回去检查它的(K-1)子集是否频繁,子集不频繁的候选集就被修剪掉。此步之后,就需要对他们计数来确定它们是否频繁,这一步很关键,它影响着算法的效率,由于候选集合可能会很大,APriori采用 Hash-Tree来存储这些候选集。Apriori算法中 Subset函数就是用 Hash-Table结构来发现交易中包含的候选项目集的,对于每一项交易,若候选项目集在其中出现了,就相应的给此项集的 Counts加 1。检查完数据库后,滤掉那些小的候选集,把剩下大的加入到 Lk中。
举个例子,考虑表 1中的交易数据库,假设支持度为 40%,也就是说一个项目集至少由两个交易支持它,第一遍扫描之后,L1=(A,B,C,D),APriori Gen函数计算出 C2={AB,AC,AD,BC,BD,CD},扫描数据库计算支持度后,得出 L2=(AB,AC,AD,BD)。用 L2产生 C3=(ABC,ABD,ACD),但 ABC的子集 BC不在 L2中,所以修剪掉它,同样也可以修剪掉 ACD。扫描数据库产生 L3{ABC}。C4为空,算法停止。
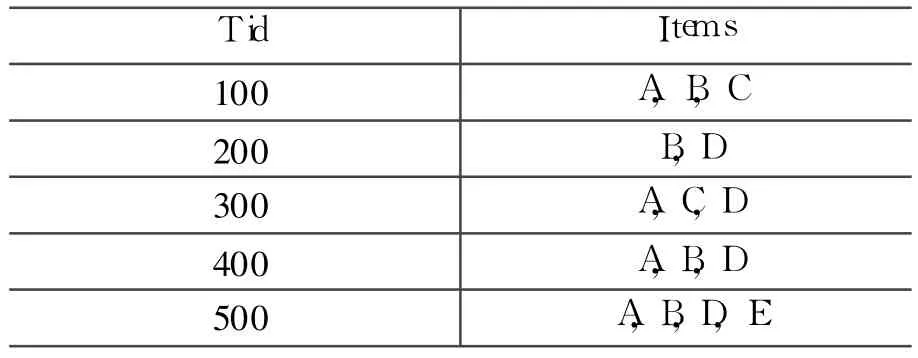
表1 交易数据库
五、结束语
将关联规则应用于警校学员队信息管理是笔者的一个设想,目的就是提高学员队日常管理工作的效率,节省更多的时间和人力,一个实用的管理系统将为决策提供支持,使数据获取过程变得更加方便,更有根据,数据分析更加全面,但是数据挖掘只是一个强大的工具,永远不能替代有经验的管理人员所起的作用,警校如果想在以后的学员队管理过程中走向科学,需要数据挖掘工作者与管理者的配合。
[1]R AGRAWAL,T IMIELINSKI,A SWAMI[C].Mining Association Rulesetween Sets of Items in Large Databases.Proceedings of the ACM SIGMOD Conference on Management of Data,1993.
[2]A SAVASERE,E OMIECINSK I,S NNAVATHE[C].An efficient Algorithm for Mining Association Rules in Large Databases.Proceedings of the 21st International Conference on Very large Database,1995.
[3]JSPARK,M SCHEN,PS YU[C].An Effective Hash-based Algorithm for Mining Association Rules.Proceedings of ACM SIGMOD International Conference on Management of Data,1995,(5):175-186.
[4]刘韬,楼兴华.SQL Server 2000数据库系统开发[M].北京:人民邮电大学出版社,2004:16-90.
[5]叶子青.ASP网络待发入门与实践[M].人民邮电出版社,2006:78-136.
[6]郭常圳,李云锦.ASP.NET网络应用开发例学与实践[M].北京:清华大学出版社,2006:3-99.
[7]蔡伟杰,杨晓辉,等.关联规则综述[J].计算机工程,2001,27(5):31-33,49.
猜你喜欢
铁道建筑技术(2021年4期)2021-07-21 05:33:42
科技进步与对策(2020年15期)2020-08-18 08:08:30
中国交通信息化(2016年2期)2016-06-06 07:27:47
军事体育学报(2015年2期)2015-02-27 16:01:51
军事体育学报(2015年2期)2015-02-27 16:01:46
中国人民警察大学学报(2015年11期)2015-01-29 22:18:33
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
土木建筑工程信息技术(2013年3期)2013-10-17 03:15:00
网络安全与数据管理(2010年1期)2010-05-18 07:28:54
