
基于数字孪生的交通运输多源数据融合架构研究
2024-12-31 00:00:00占斌
佳木斯职业学院学报 2024年7期

摘"要:本文研究基于数字孪生的交通运输多源数据融合架构,旨在实现交通运输领域多源数据的规范化融合,推动异构系统间的协调与连接。针对交通运输系统中存在的数据离散、多源异构以及可视化差异等问题,本文结合交通运输数据的特点,包括数据量大、多样性、实时性、关联性和价值密度低,设计了基于数字孪生技术的数据融合路线,涵盖了数据准备、接入、转换和集成等关键环节,构建交通运输数字孪生的基本架构体系,为交通行业数字化建设提供高效、稳定且可靠的解决方案,推动交通运输领域的智能化发展。
关键词:交通运输;数据融合;多源异构;数字孪生
中图分类号:TP391;U495文献标识码:A文章编号:2095-9052(2024)07-0140-04
引言
我国信息化建设总体上处于由网络应用向集约化整合与协同应用过渡的阶段,按照国家战略部署要求,应“大力发展智慧交通。推动大数据、互联网、人工智能、区块链、超级计算等新技术与交通行业深度融合”"[1]。要实现这些,关键是实现信息世界和物理世界无缝连接,在虚拟空间模拟真实场景,解决实际交通问题。这就需要交通系统可以进行实时数据的收集、分析和重组,然而,不同交通数据采集传感器之间存在不同的标准,这就使得处理好异构系统间的协调和连接,将多源的数据进行规范化的融合,成为亟待解决的问题。本研究将针对多源异构数据的融合,构建交通运输数字孪生的技术框架和实施途径。
一、文献综述
近年来,学者们围绕智能交通领域的数据处理,展开多层次多角度的分析研究。钱红波"[2]深入分析了美国交通数据共享的规范和制度;朱小杰"[3]在整合数据交换共享并深度挖掘方面提出建设方案;安健等"[4]指出我国在开放共享交通信息数据方面的不足并提出数据驱动的治理思路;龙莎"[5]提出针对开放交通数据的数据治理框架,并构建相关体系;方昕"[6]从大数据角度分析交通数据特点和已有数据共享技术,提出了适合智能交通数据共享的数据处理模型,并详述其关键技术路线;李燕妮"[7]研究大数据技术在智能交通领域的特点与架构,并在异构环境构建多元化管理系统的具体应用。这些研究中都尚未应用数字孪生技术解决数据融合问题。
基于已有研究,笔者发现较多学者将交通系统的“数字孪生”等同于系统状态可视化,使得数字孪生应用主要体现为数据采集与可视化,忽视了数据建模、预测与优化等关键能力的研究与开发。
二、现状分析
智能交通已经成为我国智慧城市建设需要突破的重要领域。智能城市交通市场规模占比最高,占到48.85%,智能高速公路占比为28.36%,其他智能交通占到22.8%。2023年9月,交通运输部在“十四五”中期发布顶层设计文件《关于推进公路数字化转型 加快智慧公路建设发展的意见》,在公路交通领域全面推进数字化转型升级;同年,云南交投集团研发了“云通数聚”系列数据产品,并在上海数据交易所成功挂牌,挂牌首日完成交易超1000笔。
目前,数据资产化、数据交易在我国还处于早期发展阶段,在国际上也没有很成熟的经验借鉴。对于交通行业,数据资产化、数据交易的发展已成为不可忽视的重要课题。先前必须在现实中不停实验并修正的工作逐渐向虚拟世界转移,最终达到数字孪生管控的数字化阶段,大部分交通管理决策均可在虚拟环境中试错并得到决策,旨在将虚拟世界中的管控决策实时同步至现实中,有效提升交通决策时效性。
三、存在的问题与原因
在交通行业中各种管理系统从感知数据到最终形成数字孪生体的过程中,主要遇到如下问题。
(一)数据管理复杂困难
采集的数据呈现出离散和存储分散的特点,这导致数据管理变得复杂困难。传统的数据接入和计算方式已经无法满足现代数据管理的高效需求,尤其是在面对大规模数据集时,传统的关系型数据库的查询性能往往无法达到用户的期望。
(二)数据异构融合存在问题
在数据接入方面,阿里云和华为云都提供了多种方法和技术来支持不同协议的数据接入。然而,这些方法往往需要进行大量的开发工作,包括编写适配器、解析协议、处理数据格式等。对于数据异构融合问题,用户不能直接处理数据,需要在接入数据之前,开发代码对数据进行清洗、转换和标准化等操作,以确保数据的质量和一致性"[8]。
(三)数据可视化运维成本问题
在数据可视化方面,阿里云使用DataWorks"[9]进行数据查询和输出图表、报表;华为云通过代码开发能直接从数据实时分析实例生成图表,增加了运维成本和周期。
四、交通运输数据特征
交通运输数据具有多个显著的特征,这些特征对于理解和应用交通数据至关重要。首先,交通运输数据量大:涉及人、车、路、环境等多个方面。其次,交通运输数据具有多样性特点,包括结构化数据如车辆信息、道路信息等,非结构化数据如视频监控、图像、声音等。第三,交通运输数据具有实时性特点,数据动态变化,例如,交通流量、道路拥堵情况等都会随时变化,需实时监测和响应。第四,交通数据运输数据具有关联性特点,数据之间存在关联性,不同数据之间补充与印证。例如,车辆行驶轨迹可以与道路状况、天气情况等数据进行关联分析,体现运行状态。第五,交通运输数据价值密度低,在巨大的交通数据中需要提取有价值的信息,以支持交通管理和决策。
为了高效地管理和利用这些数据特征,建设一个有效的数据库系统显得尤为重要。这个系统通常包括空间数据库、非关系型数据库、关系型数据库以及Redis等四类数据库。目前现有的研究多倾向对传统单体架构的管理平台数据进行整合或对跨系统的服务数据的处理和挖掘,对不同层级或不同区域数据的汇聚不够高效及实质意义。
五、交通运输数字孪生模型的构建
交通运输数据融合致力于将最新采集的传感器数据、互联网信息与现有的业务系统数据进行深度融合,从而构建一个内在相互关联、外在统一协调的数据生态体系。在数字孪生的基础上,结合BIM(建筑信息模型)与GIS(地理信息系统)技术,通过图像采集设备和先进的实体建模技术,能够广泛收集并分析不同区域的数据,进而迅速生成并展示整个区域的多层次、多维度数据全景。
构建一个精准且高效的交通运输运行数据框架,首先要明确用户的需求,确定数据融合能给用户提供的原数据。在此基础上,设计数据框架的结构,细致划分二级数据来源,并制定切实可行的数据采集策略,以满足不同用户的多样化需求。通过深入分析这些二级数据采集区域,系统能够深入挖掘数据的独特属性和潜在价值,从而为交通运输系统的动态优化提供有力支持。
此外,系统还能够通过深入分析多个区域传感器所感知的数据间关系,充分发挥数据的实时调控作用。在物理数据区域的划分上,本文将运用矩阵关联分析法,结合细粒度优化技术,确保从物理世界采集的数据与数字孪生世界中的数据之间能够实现精确映射。这将有助于系统更准确地应用这些数据,进而提升交通运输系统的运行效率和可靠性。
六、数据融合的研究与应用
(一)数据融合的方法
交通运输数据融合是一种多源信息处理技术,旨在将来自不同获取数据方式和不同数据源的信息进行融合,以提供更准确、全面和实时的交通情况描述和预测。主要有基于统计学、基于机器学习、基于深度学习、基于多智能体系统四种方法。本研究主要使用如下数据融合方法:
1.基于深度学习的数据融合方法
使用深度学习模型对多源交通数据进行自动特征提取和融合。例如,可以使用卷积神经网络对交通图像和视频数据进行处理,提取交通流、车辆类型等有用信息,并将其与其他传感器数据进行融合。
2.基于多智能体系统的数据融合方法
将不同交通数据源看作是不同的智能体,通过智能体之间的协作和信息共享来实现对交通情况的全面感知和预测。例如,可以使用基于多智能体系统的协同过滤算法对来自不同交通方式的数据进行融合和预测。
(二)数据融合设计
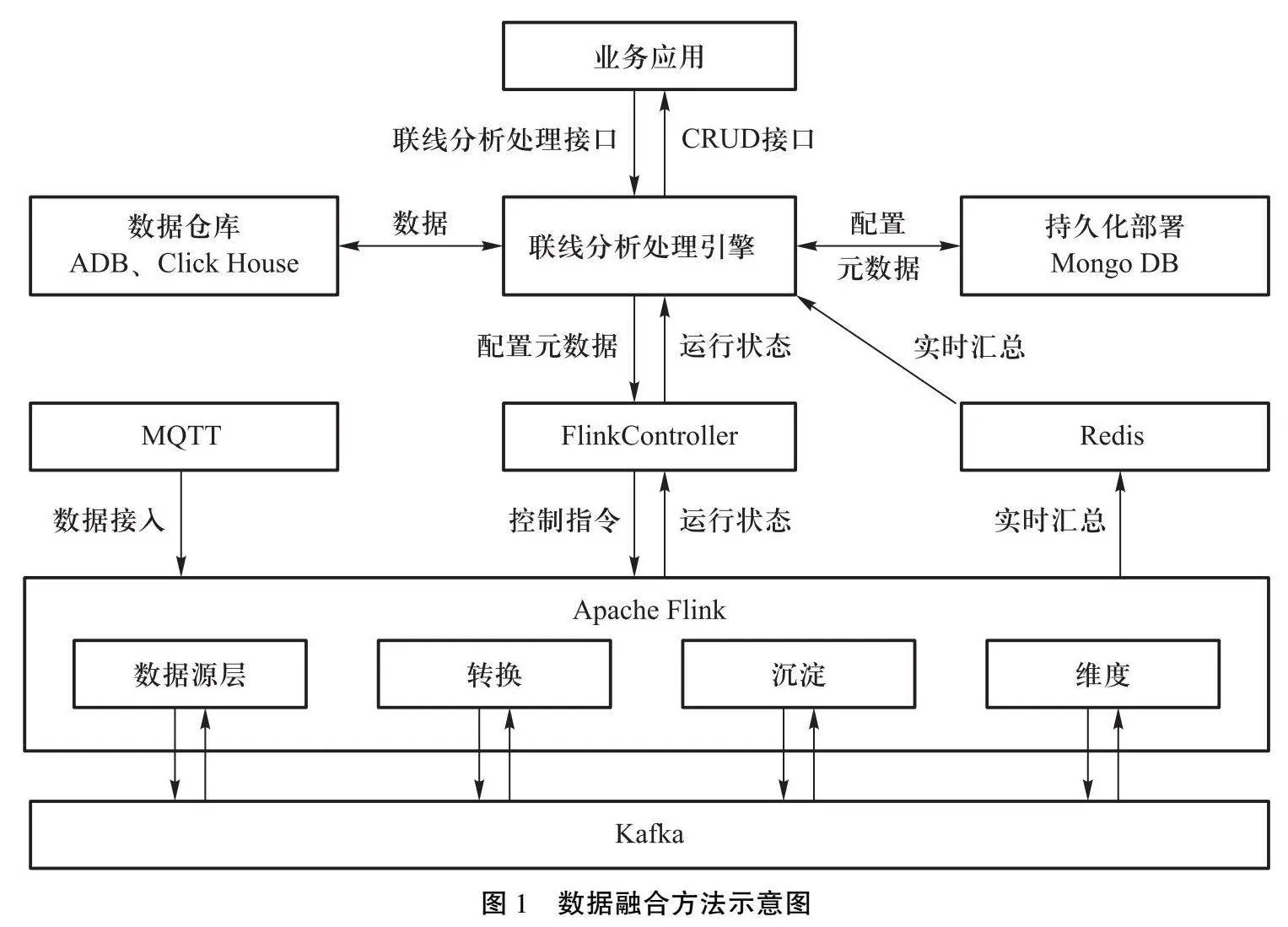
数字孪生平台融合数据集设计的重点在于全生命周期的数据应用与海量动态数据处理。设计融合数据集,对数据类型进行划分,选取适用于动态、静态属性表达的数据格式,构建统一的数据库,对结构化数据、BIM模型及各类文件数据进行集中管理。选用JSON(JavaScript Object Notation)作为数据交互和存储的标准格式,这不仅有助于各系统间异步数据的高效传输与接收,还显著提升了数据处理速度。如图1所示。
在数据处理方面,基于OLAP引擎的数据处理架构,融合了数据查询分析、数据存储和数据可视化三大核心功能。本文选用ClickHouse( Click Stream, Data WareHouse)作为多维数据的列式存储方案,它对于流式计算后的数据存储尤为高效。此外,OLAP引擎支持的上卷、切片、聚合和钻取等操作,使得数据查询与分析更加灵活便捷。结合MongoDB的GridFS API分布式文件存储特性,我们实现了数据的跨服务器和数据中心分布,确保了系统的高可用性、可扩展性和数据持久性。在数据可视化环节,采用无代码配置的方式,用户可以轻松创建自定义图表,直观地展示数据。同时,通过实时数据接口,OLAP引擎能够获取Redis(远程字典服务)中的最新数据。这些数据经过流式计算引擎的数据转换层处理后,以数据立方体的形式将热点数据存储在Redis中,通过消息接口将沉淀层的数据最终由联机分析处理引擎反馈给业务应用。这样的设计使得运维数据的接入、转换和融合更加高效、灵活可视化。
流式计算引擎作为数据处理的核心组件,基于Kappa架构进行了优化设计,使其能够灵活处理不同类型的数据,并优化调整数据结构。在数据转换的过程中,Flink维度表关联完成数据维度连接,保证参与计算数据的准确。同时,应用Flink的窗口机制快速聚合数据,实现了数据的快速聚合,为实时数据分析和快速决策提供了有力支持。在众多流式计算引擎框架中以Flink为例,其任务被精细划分为四类(如表1),这些任务相互衔接,构成了完整的数据接入和处理流程。在Flink的架构中,FlinkController作为核心组件之一,通过REST API或CLI接收并解析客户端提交的任务,负责任务调度和资源管理,确保数据处理的稳定性和高效性。FlinkController中的JobManager和TaskManager进程相互协作,精密管理着整个流式计算过程,保障数据的实时性和精确性。
此外,系统引入Kafka作为消息中间件,连接数据源层和数据转换层,实现数据的实时传输和缓冲。这种设计不仅大幅提升了数据处理的速度和准确性,还有效降低了运维成本,为用户的科学决策提供了有力支持。通过流式计算引擎的优化和FlinkController的高效管理以及OLAP引擎的强大数据分析能力实现了数据的实时处理、深入分析和可视化展示,为数字孪生平台的全面数据应用提供了坚实的技术支撑。
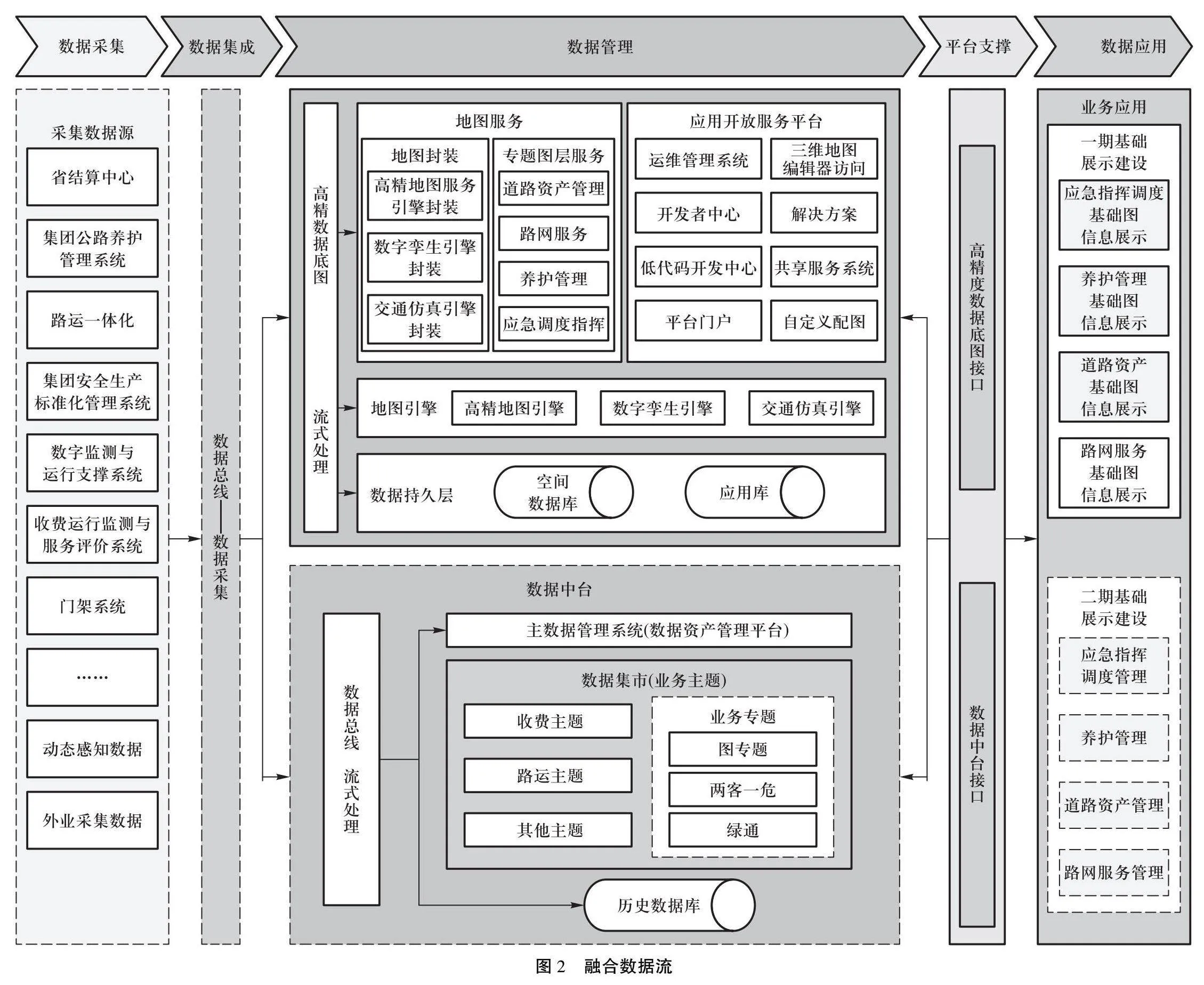
(三)数据融合数据流
如图2所示,数据采集源包含集团公路养护管理系统、路运一体化等业务数据,通过数据总线实现汇聚。其中,收费数据、路侧感知数据等实时数据采用流计算的方式进行传输;其他数据按照传统方式进行传输,最终进入数据中台和高精度数据底图平台。进入地图平台的数据,依托高精地图引擎、数字孪生引擎、交通仿真引擎形成基于地图的分析结果,进入应用系统;接入数据中台的数据,采用大数据分析技术,形成收费主题库、路运主题库以及其他主题库,进入应用系统。在数据分析方面,支持数据解析、模型分析和模型获取结果等流程。实现对流入数据进行毫秒级实时分析引擎,集成JMS, Kafka等平台兼容多种消息格式或数据格式,可进行多种复杂流式SQL查询。
结语
本文主要结合BIM技术和GIS技术,将交通大数据分割成低价值密度的小数据,同时将传感器获取的数据及各区域的存储信息与流式数据进行映射,再依靠数据可视化引擎,结合无代码的方式,实现跨区域各类数据的直观展示,同时,将实时数据的治理、仿真与管控优化的融合,挖掘数据潜在价值,将分散的技术加以调整改进,形成较为有效的交通运输系统数字孪生模型,为实施的交通决策提供有力支持。
参考文献:
[1]伍朝辉,徐建达,符志强等.交通强国建设视域下公路交通数字孪生体系架构、关键技术与实践案例[J].交通运输研究,2023,9(04):104-124. 9931.2023.04.010.
[2]钱红波.美国交通数据资源共享对我国的启示[J].中国公路,2015(23):80-82.
[3]朱小杰.城市交通综合数据中心系统研究和实现[J].交通世界,2017(29):37-39.
[4]安健,徐韬,朱启政.面向交通治理的信息公开与数据共享策略研究[J].交通与运输,2020,33(S2):179-184.
[5]龙莎. 基于数据治理的开放交通数据发布流程优化及质量控制[D].大连海事大学,2021.
[6]方昕.大数据下的智能交通数据共享与处理模型[J].信息技术,2015(12):94-97.
[7]李燕妮.大数据技术在智能交通领域的应用[J].西部交通科技,2021(07):143-146.
[8]巢佳媛. 面向序列标注问题的异构数据融合[D].苏州大学,2018.
[9]杨昊,余芳强,高尚等.基于数字孪生的建筑运维系统数据融合研究和应用[J].工业建筑,2022,52(10):204-210+235.
猜你喜欢
软件工程(2019年12期)2019-12-24 01:13:28
山东工业技术(2019年6期)2019-03-27 00:57:30
大飞机(2018年6期)2018-05-14 15:59:10
图书与情报(2017年6期)2018-03-12 19:13:41
电子技术与软件工程(2016年22期)2016-12-26 23:28:33
价值工程(2016年31期)2016-12-03 00:01:51
人间(2016年26期)2016-11-03 17:00:07
科学与财富(2016年28期)2016-10-14 21:10:06
科技视界(2016年14期)2016-06-08 13:24:00
科技视界(2016年3期)2016-02-26 19:57:53
