
基于Yolov7_Pose的轻量化人体姿态估计网络
2024-11-30 00:00:00黄健胡翻展越
现代电子技术 2024年23期






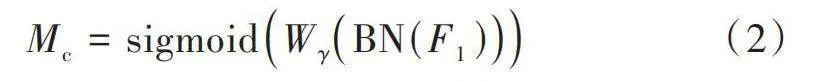





摘" 要: 人体姿态估计在计算机视觉、人机交互与运动分析等领域广泛应用。当前人体姿态估计算法往往通过构建复杂的网络来提高精度,但这带来了模型体量和计算量增大,以及检测速度变慢等问题。因此,文中提出一种基于Yolov7_Pose的轻量化人体姿态估计网络。首先,采用轻量化CARAFE模块替换原网络中的上采样模块,完成上采样工作;接着,在特征融合部分引入轻量化Slim⁃neck模块,以降低模型的计算量和复杂度;最后,提出了RFB⁃NAM模块,将其添加到主干网络中,用以获取多个不同尺度的特征信息,扩大感受野,提高特征提取能力。实验结果表明,改进后网络模型的GFLOPs和模型大小分别降低了约18.1%、22%,检测速度提升37.93%,并在低光环境、小目标、密集人群和俯视角度下表现出了较好的性能。
关键词: 人体姿态估计; Yolov7_Pose; 轻量化; 上采样; CARAFE; Slim⁃neck
中图分类号: TN911.1⁃34; TP391" " " " " " " " " " 文献标识码: A" " " " " " " " " "文章编号: 1004⁃373X(2024)23⁃0098⁃07
Lightweight human pose estimation network based on Yolov7_Pose
HUANG Jian, HU Fan, ZHAN Yue
(College of Communication and Information Engineering, Xi’an University of Science and Technology, Xi’an 710600, China)
Abstract: Human pose estimation is widely used in computer vision, human⁃computer interaction (HCI) and motion analysis. Current human pose estimation algorithms often improve accuracy by constructing complex networks, but this brings increased model size and computation, as well as slower detection speed. Therefore, this paper proposes a lightweight human pose estimation network based on Yolov7_Pose. A lightweight CARAFE module is used to replace the up⁃sampling module in the original network to complete the up⁃sampling first, and then a lightweight Slim⁃neck module is introduced in the feature fusion section to reduce the computation and complexity of the model. Finally, the RFB⁃NAM module is proposed and added to the backbone network for acquiring feature information at multiple different scales, expanding the receptive field, as well as improving the feature extraction capability. The experimental results show that the computational burden and model size of the improved network model have been reduced by about 18.1% and 22%, respectively, and its detection speed has increased by 37.93%. In addition, it shows better performance in low⁃light environments, detection of small objects, dense crowds, and perspective of overlooking.
Keywords: human pose estimation; Yolov7_Pose; lightweight; up⁃sampling; CARAFE; Slim⁃neck
0" 引" 言
人体姿态估计是计算机视觉领域的一个关键研究方向,通过机器学习和深度学习技术实现对人体姿态的精准识别和分析[1]。然而,随着检测精度的不断提升,现有算法的复杂性也随之增加,导致模型参数量和计算量急剧上升,难以满足有实时性要求的任务。因此,如何轻量化人体姿态估计网络,既要保证检测精度,又要降低网络的计算量以及提高检测速度成为主要问题。人体姿态估计可分为单人人体姿态估计和多人人体姿态估计两个方面[2]。
单人人体姿态估计指的是在一张图片或视频中检测和识别单个人的身体姿势或动作,并标注出各个关节点。文献[3]提出了DeepPose网络,首次采用深度神经网络进行特征提取和关键点坐标回归,但其精度不稳定,特别是在遮挡情况下,难以提供准确的检测结果,而且网络收敛速度较慢。文献[4]提出了Hourglass网络结构,通过堆叠多个Hourglass模块逐步提取和整合特征。
多人人体姿态估计方法可以分为自顶向下和自底向上两种[5]。
自顶向下方法首先利用目标检测算法识别出每个个体,然后利用单人姿态估计方法对所有人进行姿态估计。该方法通常具有相对较高的姿态估计准确性,但其准确性与目标检测器精度相关,并且检测速度随着人数增加而降低。文献[6]提出了区域多人姿态估计网络(RMPE),结合对称空间变换网络(SSTN)、参数化姿态非最大值抑制(NMS)和姿态引导的样本生成器(PGPG),有效提高了关键点的检测效果,但该网络存在计算成本高和运行时间长的问题。文献[7]提出了级联金字塔网络(CPN),通过GlobalNet金字塔网络学习特征来解决遮挡和不可见关键点的检测问题,利用基于困难样本挖掘的RefineNet网络解决难以检测的关键点,但仍然存在计算成本高和耗时长的问题。文献[8]提出高分辨率网络(HRNet),该网络通过并行连接这些特征图来维持高分辨的信息,有效地提高了关键点的定位精度。然而,为了保持高分别率,使得模型的计算量增加。
自底向上方法是先检测到图像中所有人体关键点,然后通过聚类算法将关键点聚类到每个人。该方法不受检测人数的影响,并且检测速度相对恒定,但需要各种复杂的后处理来提高网络精度。文献[9]提出了OpenPose网络,采用多阶段的网络结构,其中每个阶段由两个分支组成,分别用于热图估计和人体姿态关键点的组合。然而该网络检测速度较慢,难以满足实时检测任务需求。文献[10]提出了PiPaf网络,该方法使用部分强度场(PIF)定位身体部位,并使用部分关联场(PAF)将身体部位与其他部位关联起来形成完整的人体姿态,但该网络结构复杂,导致了较高的计算量。综上所述,如何在人体姿态估计网络的精度和速度之间取得平衡,成为一个主要的研究方向。
本文针对现有算法的不足,提出了一种基于Yolov7_Pose的轻量化人体姿态估计网络,具体内容包括:
1) 使用轻量化CARAFE模块替换原网络中的上采样模块,完成上采样工作;
2) 使用轻量化Slim⁃neck模块对特征融合部分进行改进,以进行网络轻量化;
3) 提出了RFB⁃NAM模块,将其添加在主干网络中,用来获取多个不同尺度的特征信息,扩大感受野,提高特征提取能力。
实验结果表明,本文方法实现了人体姿态估计网络的轻量化,同时在部分复杂条件下的人体关键点检测具有较好的性能。
1" Yolov7_Pose网络
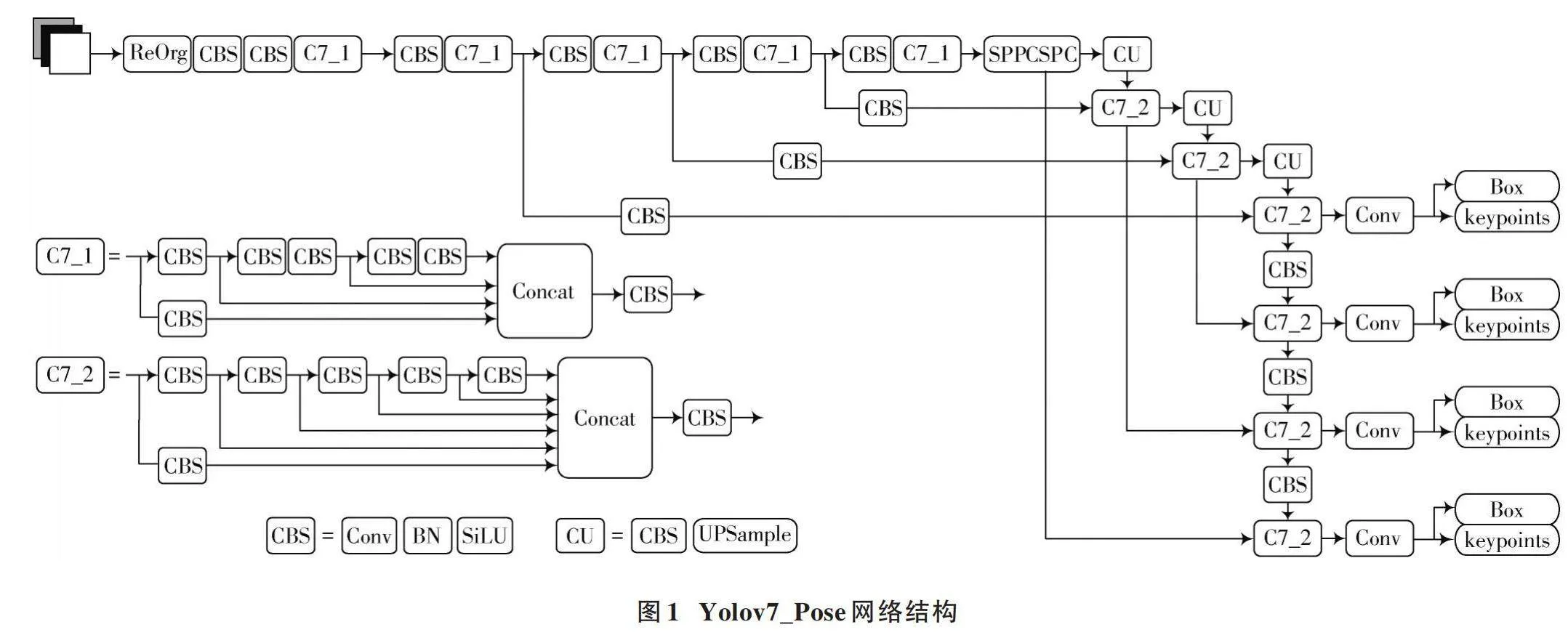
Yolov7_Pose网络是将Yolov7目标检测和姿态估计结合在一起的端到端模型。该网络包括四个主要部分,输入端(Input)、主干网络(Backbone)、颈部网络(Neck)和检测头输出端(Head)[11]。通过输入端接收图像数据并进行预处理,然后通过主干网络提取图像的特征,再通过颈部网络将不同尺度的特征图进行信息融合和特征增强,最后通过检测头输出端生成目标检测与关键点检测的结果。Yolov7_Pose网络结构如图1所示。
2" 改进Yolov7_Pose网络
2.1" 融合GSConv和VoV⁃GSCSP的Slim⁃neck模块
Yolov7_Pose网络是由标准卷积堆叠而成。在标准卷积中每个卷积核仅能提取一个特征图,为了获取更多特征,需要增加卷积核的数量,这将导致网络体量的增加和检测速度的降低[12]。因此,本文在特征融合部分引入了轻量化Slim⁃neck模块[13],其基于GSConv模块和VoV⁃GSCSP模块。通过将原网络Neck层中标准卷积替换为GSConv,再结合VoV⁃GSCSP模块,以降低网络的计算量,同时提高网络的检测速度。
2.1.1" GSConv卷积
GSConv卷积是一种用于目标检测任务中的轻量化卷积模块。GSConv的计算步骤如下。
1) 输入特征先经过一个标准卷积,其输出通道数变为输入通道数的[12]。
2) 经过深度可分离卷积对每个通道独立进行卷积。
3) 将普通卷积输出与深度可分离卷积的输出拼接。
4) 经过通道混洗操作重新排列通道特征,提高特征之间的信息流动。
5) 输出的特征图具有与输入相同数量的通道。GSConv卷积操作过程如图2所示。
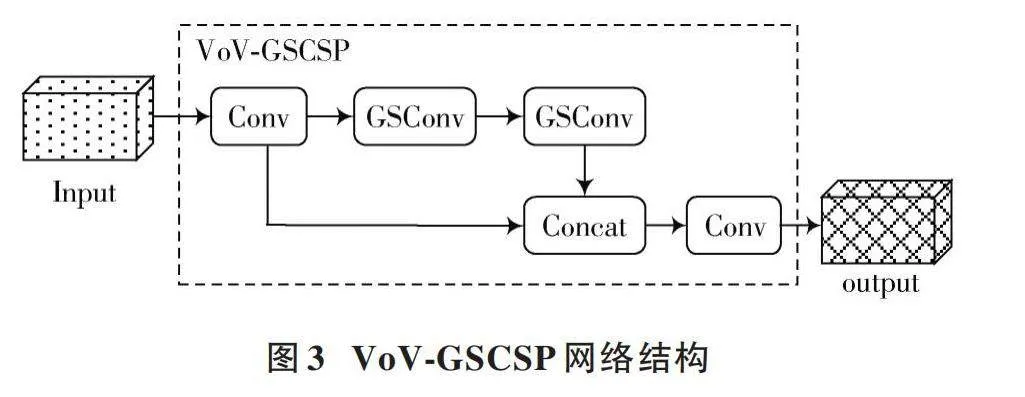
2.1.2" VoV⁃GSCSP模块
VoV⁃GSCSP模块是一种利用一次性聚合方法设计的跨阶段部分网络模块,旨在有效地融合不同阶段的特征图之间的信息。VoV⁃GSCSP网络结构如图3所示。VoV⁃GSCSP网络中,采用GSConv替代传统的卷积操作,并将两个GSConv模块串联起来。本文利用VoV⁃GSCSP替换特征融合层中的C7_2模块,对主干网络提取的特征进行增强融合,以确保每个特征层能够充分捕获深层特征的语义信息和浅层特征的细节信息。
2.2" 轻量级上采样算子CARAFE
在Yolov7_Pose网络中,上采样通常使用最邻近插值法,基本原理是在目标图像的每个像素位置,找到原始图像中最接近的像素,并将其值赋予目标图像对应位置。尽管这种方法实现简单,但它只考虑最近的像素,而不考虑周围像素的影响,这可能导致不能获取更加丰富的语义信息。
本文针对最邻近插值法的不足,使用轻量级上采样算子CARAFE替换原网络中的上采样模块。CARAFE模块[14]是一种基于内容感知的特征重组上采样方法,通过对输入特征图进行分块处理,并利用卷积操作对每个分块进行特征重组,从而增强感知范围,融合更多的上下文信息。CARAFE模块结构如图4所示。CARAFE算子作为一种轻量化上采样模块,具有更高的参数效率,这使得在保持模型轻量化的同时具有更好的性能。
2.3" 融入NAM注意力的RFB模块
2.3.1" NAM注意力模块
基于归一化的注意力模块(NAM)[15]作为一种高效且轻量化的注意力机制,融合了CBAM模块思想,对通道和空间注意力子模块进行了重新设计。
在通道注意力模块中,利用批归一化(BN)的缩放因子,通过式(1)反映各个通道的变化大小,进而表示该通道的重要性。简单来说,缩放因子类似于BN中的方差,方差越大表明通道变化越显著,因此该通道中包含的信息也更为丰富和重要,而那些变化不大的通道则包含的信息较单一,重要性较小。
[Bout=BN(Bin)=γBin-μBσ2B+ε+β] (1)
式中:[μB]为最小批次的均值;[σB]为最小批次的方差;[γ]和[β]为可训练的参数;[Bout]和[Bin]分别为输出特征和输入特征。
通道注意力模块如图5所示,该模块的输出计算公式如式(2)所示:
[Mc=sigmoidWγBN(F1)] (2)
式中:[Mc]表示输出特征;[F1]表示输入特征图;[γ]是每个通道的缩放因子。
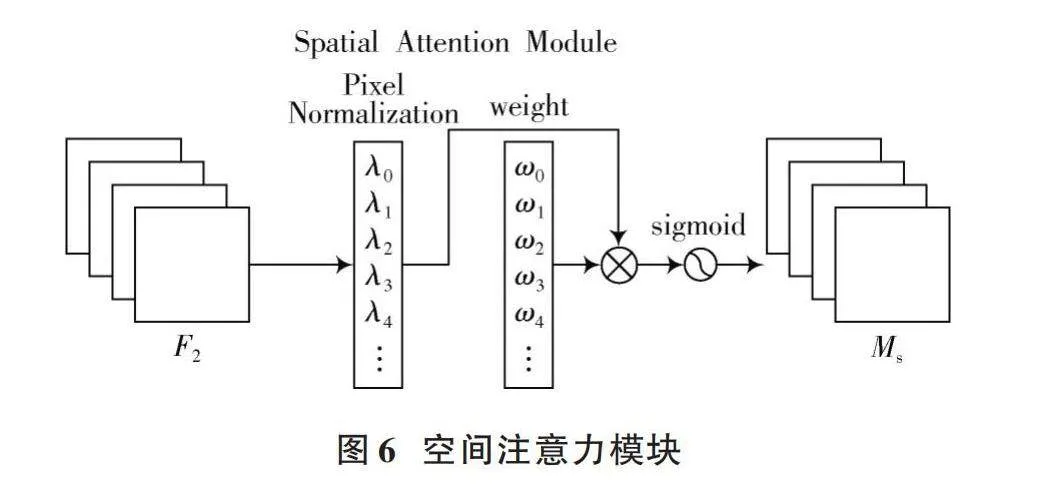
在空间注意力模块中,同样将BN中的比例因子应用于空间维度,以衡量每个像素的重要性,形成像素归一化。空间注意力模块如图6所示,其输出计算公式如式(3)所示:
[Ms=sigmoid(Wλ(BNs(F2)))] (3)
式中:[Ms]表示输出特征图;[F2]表示输入特征图;[λ]是缩放因子。
2.3.2" 融入NAM注意力的RFB模块
Yolov7_Pose网络主要由卷积、C7_1、C7_2、SPPCSPC以及其他模块构建而成,尽管这些模块提供了强大的特征提取能力,但在处理小尺寸目标时存在一些局限性。人体姿态估计任务中输入图像通常会包含小目标。针对小目标,网络需要更精细的特征提取能力以准确地定位和识别目标,因此,本文引入RFB(Receptive Field Block)模块,通过扩大感受野使模型可以在更广泛的范围内捕获相关特征,从而对小目标的识别更加准确。
RFB模块是通过模拟人类视觉的感受野来增强网络的特征提取能力[16]。该模块借鉴Inception网络的多分支结构,并在此基础上引入空洞卷积,通过增大空洞卷积的膨胀率,RFB模块有效地扩大了感受野范围。RFB模块分别在三个分支上使用了1×1、3×3和5×5的卷积操作,随后使用三个3×3卷积,分别设置膨胀率为1、3和5,以提取不同尺度的特征。接着,将三个不同尺度的分支进行有效特征拼接,并通过1×1卷积调节特征维度,实现了不同尺度特征融合。尽管RFB模块通过多分支捕获了多尺度的特征,但其缺乏区分和增强全局或局部重要特征的能力,也缺乏对冗余特征的抑制。为改善RFB模块,本文在RFB模块拼接操作前的每个分支上融入NAM注意力模块,以增强重要特征的同时抑制冗余特征。改进后的RFB模块称为RFB⁃NAM,其结构如图7所示。
在RFB⁃NAM模块中,每个分支获取的特征信息都会经过NAM模块。NAM模块能够动态地调整不同位置特征的权重,从而捕捉更加丰富的上下文信息。通过学习,NAM赋予不同区域特征的不同权重,以便关注更主要的特征信息。总的来说,NAM模块的融入不仅使网络更专注于有用的特征,提高在姿态估计任务中关键点定位能力,还能减少不重要特征的计算,提高网络的效率。
2.4" 改进后的网络结构
本文在Yolov7_Pose的基础上进行改进,以解决现有人体姿态估计网络存在的问题。改进后的轻量化网络结构如图8所示。
3" 实验结果及分析
3.1" 数据集
本文实验采用的数据集是COCO2014数据集。该数据集主要用于目标检测、分割任务和人体关键点检测。在COCO2014数据集中,人体关键点检测任务包括17个关节点的标注,涵盖了鼻子、眼睛、耳朵、肩膀、手肘、臀部、膝盖和脚踝等部位。
3.2" 实验环境与评价指标
实验环境采用Ubuntu 20.04系统,GPU为NVIDIA GeForce RTX 4060 Ti(16 GB),CPU为Intel[Ⓡ] Xeon[Ⓡ] CPU E5⁃2696 v3 @2.30 GHz ,配置环境为Python 3.9,PyTorch 1.13.1,CUDA 12.2。模型初始学习率为0.01,训练批次大小为16,训练总轮数为200。
实验的主要评价指标有:平均精度(mean Average Precision, mAP)、计算量(GFLOPs)、速度(FPS)。准确率(Precision)、召回率(Recall)、mAP的计算公式如下:
[Precision=TPTP+FP] (4)
[Recall=TPTP+FN] (5)
[mAP=i=1NAPiN] (6)
式中:TP(True Positive)表示被正确划分为正例的个数;FP(False Positive)表示被错误划分为正例的个数;FN(False Negative)表示被错误划分为负例的个数。
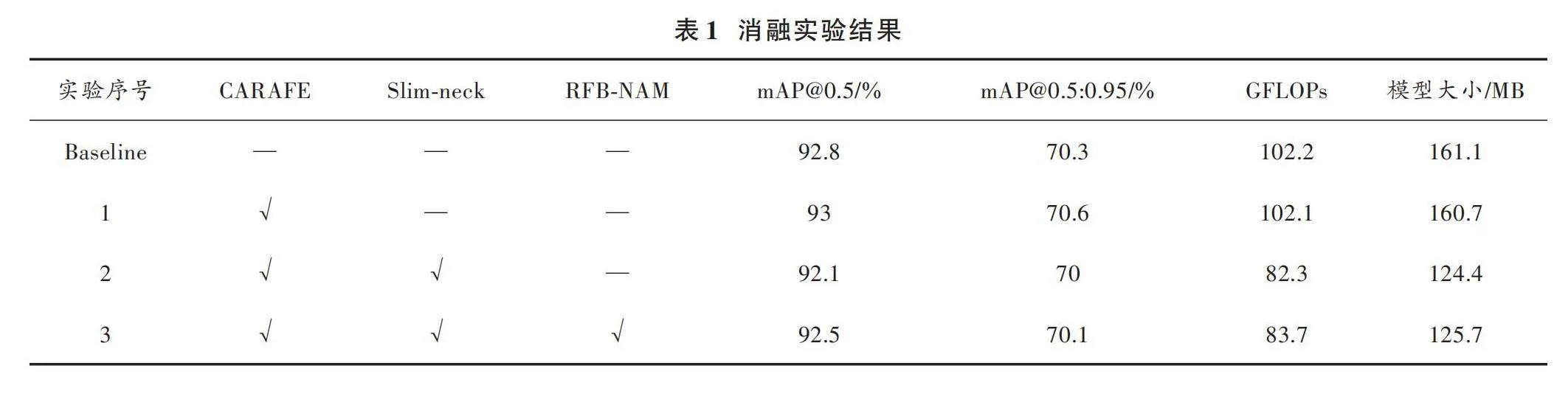
3.3" 消融实验
为了验证每种改进点对网络模型的增益,本文在COCO2014数据集上进行消融实验,采用Yolov7_Pose作为基础模型,并逐步对其进行改进。实验过程中保持了参数和环境的一致性,所有输入图片大小均为640×640。实验结果如表1所示。
根据表1的实验结果:轻量化CARAFE模块的引入,模型的mAP值提高约0.22%,但模型大小只降低约0.25%;接着,加入轻量化Slim⁃neck模块,mAP值降低约0.75%,但GFLOPs变为82.3,降低约19.47%,模型大小变为124.4 MB,降低约22.78%;最后,引入RFB⁃NAM模块,mAP值降低约0.32%,但GFLOPs变为83.7,降低约18.1%,模型大小变为125.7 MB,降低约22%。
综上所述,通过对Yolov7_Pose网络的改进,在保持精度影响不大的情况下,实现了计算量和模型体量的显著降低,达到了网络轻量化的目的。
3.4" 不同算法对比
为检验本文算法模型的有效性,在相同数据集和实验环境下,将本文方法与其他主流算法进行对比实验。使用mAP和FPS作为评估指标,输入图像大小为640×640。实验结果如表2所示。根据实验结果,本文算法相比于基础算法Yolov7_Pose,在精度上略微下降,但检测速度提高了约37.93%。同时,与其他算法相比,本文算法在检测精度和检测速度上都优于其他算法。
3.5" 姿态估计检测效果对比
为了验证改进后算法模型的效果,选择了在部分复杂条件(低光环境、小目标、密集人群和俯视角度)下进行改进前后的网络模型效果对比,检测结果如图9 所示。
图9a)是在低光环境中,原网络未能检测到躺着的男子,并且对蹲着的两位男子的腿部关键点也未能检测到。而改进后的网络不仅检测到了躺着的男子,还成功检测到了蹲着的两位男子的腿部关键点。图9b)是在小目标条件下,可以看出原网络的检测效果不佳,只检测到了两个人,而改进后的网络检测到图像中所有小目标人体的关键点,体现出了模型对小目标检测有较好的性能。图9c)是在密集人群中,相比于原网络,改进后的网络能够更好地检测出圈中被遮挡男子的关键点。图9d)是在俯视角度条件下,原网络对图中左下角坐着的男子未检测到,并对已检测出的两位男子的关键点检测不完整,而改进后的网络,不仅检测出了左下角坐着的男子,而且比较完整地检测到三位男子的关键点。综上所述,在轻量化的基础上,本文算法能够在部分复杂条件下较好地检测出人体关键点位置,证明了本文算法模型具有较好的性能。
4" 结" 语
本文针对人体姿态估计网络模型大小与计算量大的问题,提出基于Yolov7_Pose的轻量化人体姿态估计网络。首先,使用轻量化上采样算子CARAFE替代了原网络中的上采样操作,在不影响精度的情况下略微地降低了模型参数;其次,在特征融合部分引入融合GSConv与VoV⁃GSCSP的Slim⁃neck模块,显著降低了模型大小与计算量;最后,在主干网络中引入RFB⁃NAM模块来获取多个不同尺度的特征信息,扩大感受野,提高特征提取能力,增强对小目标的检测能力。实验结果表明,改进后的网络模型大小和计算量明显降低,检测速度明显提高,同时保证了模型的准确度,并在复杂条件(低光环境、小目标、密集人群和俯视角度)下改进后的网络模型表现出了较好的性能,这在实际应用中具有一定的优势,如将轻量化模型部署到嵌入式设备中。
注:本文通讯作者为胡翻。
参考文献
[1] 张国平,马楠,贯怀光,等.深度学习方法在二维人体姿态估计的研究进展[J].计算机科学,2022,49(12):219⁃228.
[2] 乔迤,曲毅.基于卷积神经网络的2D人体姿态估计综述[J].电子技术应用,2021,47(6):15⁃21.
[3] TOSHEV A, SZEGEDY C. DeepPose: Human pose estimation via deep neural networks [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2014: 1653⁃1660.
[4] NEWELL A, YANG K Y, DENG J. Stacked hourglass networks for human pose estimation [C]// Proceedings of European Conference on Computer Vision. Heidelberg: Springer, 2016: 483⁃499.
[5] 曾文献,马月,李伟光.轻量化二维人体骨骼关键点检测算法综述[J].科学技术与工程,2022,22(16):6377⁃6392.
[6] FANG H S, XIE S Q, TAI Y W, et al. RMPE: Regional multi⁃person pose estimation [C]// IEEE International Conference on Computer Vision. New York: IEEE, 2017: 2353⁃2362.
[7] CHEN Y L, WANG Z C, PENG Y X, et al. Cascaded pyramid network for multi⁃person pose estimation [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2018: 7103⁃7112.
[8] SUN K, XIAO B, LIU D, et al. Deep high⁃resolution representation learning for human pose estimation [C]// IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 5693⁃5703.
[9] CAO Z, HIDALGO G, SIMON T, et al. OpenPose: Realtime multi⁃person 2D pose estimation using part affinity fields [J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 43(1): 172⁃186.
[10] KREISS S, BERTONI L, ALAHI A. PifPaf: Composite fields for human pose estimation [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019). New York: IEEE, 2019: 11977⁃11986.
[11] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag⁃of⁃freebies sets new state⁃of⁃the⁃art for real⁃time object detectors [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2023: 7464⁃7475.
[12] 张晓晨.煤矿井下行人检测方法研究及应用[D].太原:太原科技大学,2023.
[13] LI H L, LI J, WEI H B, et al. Slim⁃neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles [EB/OL]. [2024⁃10⁃06]. https://doi.org/10.48550/arXiv.2206.02424.
[14] WANG J Q, CHEN K, XU R, et al. CARAFE: Content⁃aware ReAssembly of features [J]. 2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 3007⁃3016.
[15] LIU Y C, SHAO Z R, TENG Y Y, et al. NAM: Normalization⁃based attention module [EB/OL]. [2021⁃11⁃26]. https://arxiv.org/abs/2111.12419.
[16] LIU S T, HUANG D, WANG Y H. Receptive field block net for accurate and fast object detection [C]// 15th European Conference on Computer Vision. Heidelberg: Springer, 2018: 404⁃419.
[17] CHENG B W, XIAO B, WANG J D, et al. HigherHRNet: Scale⁃aware representation learning for bottom⁃up human pose estimation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 5385⁃5394.
[18] NEFF C, SHETH A, FURGURSON S, et al. EfficientHRNet: Efficient scaling for lightweight high⁃resolution multi⁃person pose estimation [EB/OL]. [2020⁃07⁃22]. https://arxiv.org/abs/2007.08090.
作者简介:黄" 健(1977—),男,陕西西安人,副教授,硕士生导师,研究领域为深度学习和计算机视觉。
胡" 翻(1999—),男,陕西西安人,硕士研究生,研究领域为图像处理。
展" 越(2000—),女,山东济宁人,硕士研究生,研究领域为图像处理。
猜你喜欢
作文·小学中高年级(2022年8期)2022-04-12 00:00:00
精密成形工程(2022年2期)2022-02-22 05:44:14
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
学生天地(2020年3期)2020-08-25 09:04:16
智富时代(2019年2期)2019-04-18 07:44:42
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
专用汽车(2016年1期)2016-03-01 04:13:19
专用汽车(2015年4期)2015-03-01 04:09:07
