
基于随机森林模型的个人信贷风险研究
2024-10-05 00:00许迩璇
审计与理财 2024年9期
【摘要】本文选用随机森林模型研究个人信贷风险,该模型较传统风险评估模型具有抗噪声能力强、防止过拟合、运算快速等特点。本文选取Lending Club平台2020年Q1耀Q3的5551条样本数据构建基础数据集以训练模型,建立个人信用体系和评估模型。本文在预处理数据并筛选特征变量后,基于随机森林算法建立了个人信用风险评估模型,并对比Logistic回归模型,得到随机森林模型的个人信用风险评估能力明显优于Logistic回归模型的结果,进一步证实随机森林模型高度适用于个人信用风险评估并具备较强有效性。
【关键词】个人信贷风险;风险评估;机器学习;随机森林
一、研究背景和意义
二十世纪后,个人信贷逐渐融入生活并蓬勃发展,成为我国经济体系内不可或缺的组成部分,它因巨大潜在市场价值和吸引力在当今金融市场极受关注,在此基础上,推动个人信贷业务增长优化被视为金融机构长期发展的战略环节。随经济发展与金融市场深化,个人借贷需求持续上升,个人信贷业务规模稳步扩大,但贷款拖欠及坏账现象也屡见不鲜,金融机构面临越来越高的贷款风险,个人信贷管理亟需高效化,需对金融机构进行业务优化升级,提升信贷业务稳健性,建立准确的个人信贷风险评估模型。
随着国内金融机构日益完善,一些机构已初步搭建较成熟的操作系统和信息管理平台,储存与处理的的数据量爆发式增长。为顺应大数据时代需求,机器学习技术高速发展,帮助我们探究各类型数据和个人信贷风险间的联系。个人信贷风险评估涉及分类和预测,需将借款人据其特征划分到合适类别,预测个体未来信用表现,并深入研究对违约风险影响较大的因素,构建更有效的风险量化指标。而随机森林作为成熟的机器学习算法,在解决分类和预测任务方面表现出色,可挖掘大量数据,适于建立个人信用评估模型。
然而,国内网贷平台信息披露不充分,而国外平台交易数据更易获取,所以本文计划采用美国在线借贷平台Lending Club开放的借贷数据集,通过随机森林算法建立信用风险评估模型。模型目的是精准识别潜在高风险违约客户,提取关键数据,量化借款人信用状况,以有效降低风险、尽可能规避损失,在此前提下追求更大投资回报。
二、国内外研究现状
现阶段,国内外信用风险评估研究都已经历一段时间发展,众多学者应用各种机器学习方法于该领域,大大提升信用风险评估效率。
Martin采用Logistic回归模型构建用于银行风险评估与预警的系统。Crook J.等应用SVM技术,结合大规模信用卡数据评估客户信用。Stjepan等结合遗传算法和神经网络技术,基于克罗地亚信用数据分析风险。Tong等开发了利用Spark分布式计算框架构建的优化版C4.5决策树混合模型,应用价值显著。随机森林模型理论提出以来已成为机器学习领域内最经典的算法之一,被广泛应用于各领域。Aksakalli、Malekipirbazari协助借贷平台建立用于借方客户信用打分的随机森林模型,证实它在高信用借款人辨识上表现出色。
我国在该领域起步较晚,但新世纪以来国内学者在基于机器学习方法对信用风险的研究上也取得了一定进展。王春峰等以判别分析为基础融合统计学与神经网络综合预测风险并展开实证分析。马威采用决策树CHAID和C5.0算法构建模型分析小额贷款公司信用风险,认为CHAID算法更适合预测个人客户,C5.0算法更适合公司客户。闫静用SMOTE算法解决数据集不平衡问题,并用卷积神经网络模型评估信用风险,证明其准确性高于Logistic回归模型。何姿娇等用C5.0决策树和XGBoost模型分别分析UCI德国信用数据集和金融诈骗数据,构建个人信用评估模型和风险控制模型。
随机森林随技术发展逐渐也被应用到我国信用风险研究中。徐婷婷运用加权随机森林算法构建P2P网络借贷平台借款公司风险模型,成效显著。梁佩用随机森林方法分析银行信贷数据,得到模型预测精度高、泛化能力强。何静建立了基于SMOTE均衡化改进数据集的随机森林模型,并对比得出其分类性能优于Logistic回归模型和SVM模型。
综上,国内外对个人信贷风险评估均已进行大量研究,评估方法多样且仍不断发展。作为一种优秀的机器学习方法,随机森林算法已被广泛应用且成效显著。然而个人信用评估领域使用随机森林算法的学者仍较少,因此本文借鉴相关文献及研究成果,基于Lending Club平台公开数据,采用随机森林算法评估个人信贷风险,旨在建立全面的个人信用风险评估指标体系并建立模型。
三、基本理论概述
1.个人信用风险概述
个人信用是构成社会信用体系的核心要素。市场参与者本质是个体的集合,所有市场交易和经济活动都与个人信用状况联系密切。若个人行为缺乏必要约束导致失信,不仅影响个人声誉,还可能触发集体信用危机。
信用风险成因多种多样,最常见的是交易对手履约能力或履约意愿存在问题。度量个人信用风险时往往依据这两种成因。其中,对前者的度量一般有充足数据支撑,而履约意愿的评估更为困难,通常只能依赖违约次数等过往交易记录。量化相关数据并从经验概率角度评估,是信用风险评估的重难点。因此,除基础信息外,借款人历史违约记录等也与个人信贷风险评估密切相关。同时,贷款用途和真实性、市场状况、政策变化等也应纳入分析考量。
2.随机森林基本理论
随机森林模型由Leo Breiman(2001)提出,属于集成学习,由多个独立并行的决策树模型组合而成。这些决策树为随机森林基分类器,它利用Bagging生成一系列相异的训练数据集,本质是对标准决策树的优化,通过集成众多决策树增强整体预测力。
随机森林模型中每棵决策树的构建都遵循最小基尼指数标准,通过递归的从根节点向下分裂的方法实现。具体流程包括:(1)通过Bootstrap重抽样,从原始训练集中有放回地随机抽取n个样本,同一样本可多次选中;(2)随机选取k个特征变量,基于这些特征对①中样本构建单棵决策树模型;(3)M次迭代上述两步骤,构建M棵独立决策树并集合建立完整的随机森林模型;(4)每棵树给出样本分类结果,最终分类基于所有预测结果投票得出。这种评估方式综合多个决策树决策结果,大大增强模型稳定性和准确性。

其中[p(j | t)]为在节点t上时类别j的概率。若节点t上的样本均属同一类别,概率[p(j | t)]取值为1,基尼指数为最小值0;若节点t上样本类别均匀分布,概率[p(j | t)]降至最小,此时基尼指数最大。
个人信用风险评估实质是一项二分类任务,它将客户依偿还贷款可能性分为履约者和违约者。评估时需分析的特征变量同时包括连续型和离散型,所用数据集往往规模庞大,包含大量噪声。随机森林作为一种先进的二分类技术展现出强大的数据处理能力,能有效适应不同数据特性处理复杂数据集,并具有出色的抗噪声性能,在处理大规模数据集时特别有效,分类精度高,且具备高自动化水平和快速计算能力,在理论和实际中都显示出对个人信贷风险评估的高适用性,能帮助金融机构做出更适宜的信贷决策。
四、数据准备与个人信用风险评估指标体系构建
本文数据来自Lending Club官网公开的经过脱敏的数据,数据集包括2020年Q1~Q3的贷款数据(因2020年底Lending Club关闭其个人对个人信贷平台,无后续更新的数据),已完成数据共5551条,进行中的贷款记录不予考虑。
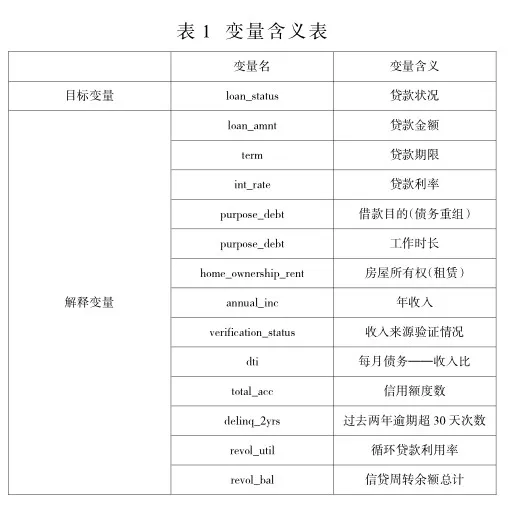
首先通过数据清洗将冗余变量、低信息量变量及高比例数据缺失变量清除,并经数据转换将用文本分类的特征变量的类别属性转化为数值。据此对个人信用风险评估的特征变量初步筛选得出24个变量,其中变量loan_status表示当前贷款状况,为本文目标变量。
经初步选取后涉及变量仍较多,若所有变量纳入分析,可能引入大量无关噪声,造成误差。本文采用Spearman相关性检验初步评估解释变量与目标变量间的相关性,选择与目标变量显著相关的变量进行后续分析。根据结果剔除不相关变量后仍剩余19个特征变量。但直接将这19个变量用于模型构建仍会导致过拟合,因此需进一步筛选特征。
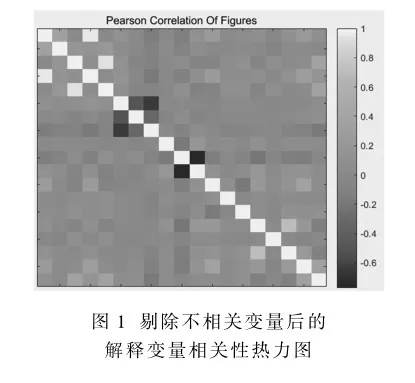
参照皮尔逊相关性热力图,除去相关系数绝对值高、相关性极强的部分特征,修正解释变量间的高相关性。最终选出变量如下表:
五、实证分析
本文基于Lending Club平台2020年Q1~Q3借款人数据中已完成贷款记录5551条,其中违约记录1323条,履约记录4228条,均用于训练样本。用上述筛选出的特征变量训练模型,通过IBM SPSS Modeler 18.0可视化建模,实现随机森林算法预测。
1.随机森林模型实证分析
在IBM SPSS Modeler中,随机森林构建每棵决策树使用的算法是C&RT。在SPSS Modeler创建数据流文件,导入预处理后的信贷数据集,基于此建立随机森林模型以对目标变量贷款状况分类,并输出建模结果与分析。
生成结果后可得到各解释变量的重要性排序,其中“delinq_2yrs”“home_ownership_rent”“term”重要性程度最低,与生活常识基本相符。删去这三个特征变量,最终选择“loan_amnt”“int_rate”“purpose_debt”“emp_length”“annual_inc”“verification_status”“dti”“total_acc”“revol_util”“revol_bal”这10个解释变量,通过SPSSModeler建立随机森林模型,得出模型训练结果。
2.Logistic回归模型实证分析

在SPSS Modeler中创建数据流文件,导入信贷数据,选用表1中的13个解释变量,基于数据集建立Logistic回归模型,对客户贷款状况采用向前步进法进行二元分类,输出得到分类预测结果与分析。
3.实证结果
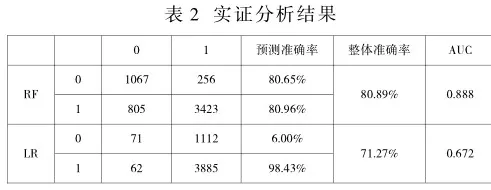
根据随机森林模型预测结果,其总体准确率达80.89%,其中违约样本分类准确率约80.65%,未违约样本分类准确率约80.96%,均达较高水平。其召回率约57.00%,F-mean值约0.67,G-mean值约0.68,AUC值约0.89,可见该模型分类性能较强,稳健性也较高。
在使用Logistic回归模型时,个案中一旦存在缺失值,将输出为“$null$”,无法得出预测结果。其总体准确率为71.27%,对未违约样本分类准确率高达98.43%,对违约样本分类准确率却仅有约6.00%。其召回率约53.38%,F-mean值约0.11,G-mean值约0.18,AUC值约0.67,均低于随机森林模型,据此认为该模型分类性能较弱。
对比显示,随机森林模型整体分类效果更佳,且它在预测正负类样本时无明显偏差,分类精度相近。虽然Logistic回归模型总的以及正类样本的预测准确率较高,但负类样本准确率低至6%,这种结果是数据不平衡导致的预测误差,可见Logistic回归模型受不平衡数据影响大。对信贷机构来说,对违约借款人的预测不够准确将导致难以通过收取利息盈利甚至难以收回本金,会增加坏账率和相关成本,使信贷机构承担巨大损失。因此,无论从准确率还是对抗不平衡数据与缺失值的能力上来看,随机森林模型预测个人信贷风险的表现都更胜一筹。
六、政策建议
1.建立科学全面的个人信用风险评估指标体系
当前,我国尚未建立统一标准的个人信贷评估指标体系。各金融机构依各自需求和数据库信息,用机构内部标准评价借款者信用风险状态。构建完善、规范的个人信贷风险评估指标体系尤为紧迫。构建统一指标体系时,应确保涵盖的领域广泛且科学,便于公共数据库信息存储和使用,包括财务状况、历史记录、流动性状况等。同时,可通过随机森林算法建立模型,筛选显著影响分类结果的关键指标整合纳入模型。
2.搭建完整的个人信用风险管理数据库
我国个人信贷市场信息存在高度不对称,妨碍了我国个人信用风险研究进展,带来重大挑战。创建标准化、集中化的个人信用信息数据系统将是解决该问题的有效方案。系统可收集、整理和储存个人信用信息,向大众开放,协助大众掌握个人信用情况。我国商业银行虽然会搜集部分客户个人数据,但往往不愿公开共享以维护数据价值与自身利益。因此,建立国家级银行间信用数据库以实现信息共享能有效削弱信息不对称。各信用机构也需建立个人信用数据库,并确保其能接入互联网,以方便用户查询信息。另外,还应制定相应制度并完善相关条例,要求相关机构部门定期供给数据,以构建健全的个人信用风险管理数据库,逐步消除信息不对称。
3.建立健全信用风险管理体系
信息技术在信用领域中应用愈加广泛,为保信用风险管理体系健康运行,行业规则的制定至关重要。在个人信贷行业中,信息共享有着迫切需求。其实现能大幅减少借款人审核成本,各机构应定期报告,促进机构间信息互通。机构内部需制定相应规范、加强规章制度建设、加大行业自律监管力度,以处理潜在风险,促进个人信贷业务健康发展,共同构建个人信贷安全环境。
政府对行业的外部监管是管理架构的基石。目前我国针对个人借贷的法律法规尚未成熟,全面性和监管强度仍有不足,政府应增强监管力度。首要任务包括完善法律法规,清晰界定监管机构和责任主体,并注意保持平衡,确保既能有效防范风险,又不过度制约发展。另外,个人信用评估不止属于社会经济活动,它触及人权和个人隐私等敏感领域。因此,这一过程应严格遵循法律法规,需要明确的法律条文区分涉及个人隐私的与合法的数据信息,尊重个人合法权益。
4.进一步挖掘更适用的模型
本文通过比较随机森林、Logistic回归两个模型,得出随机森林模型分类性能更优越。在个人信用评估时,选择不同模型会使预测准确度和稳定性不同,我们评估个人信贷风险时,挑选合适的模型是关键一环。在未来个人信用风险评估研究中,应努力探索更多适用性较高的模型,例如采用组合模型等。相信,机器学习技术及其在个人信贷风险管理中的应用也必将成为该领域深入挖掘和进一步发展的重要未来。
········参考文献·····················
[1]Martin Daniel.Early warning of bank failure:A log it regressionapproach[J].Journal of Banking &Finance,1977,1(3):249-276.
[2]Tong Z,Chen X.P2P net loan default risk based on Sparkandcomplexnetworkanalysisbasedonwireless network element data environment[J].EURASIP Journal on Wireless Communications and Networking,2019(1):1-7.
[3]王春峰,万海晖,张维.基于神经网络技术的商业银行信用风险评估[J].系统工程理论与实践,1999(9):24-32.
(作者单位:东北大学秦皇岛分校)
