
数字时代人口监测中的多源数据应用
2024-09-29 00:00:00郭涛吴康李栋刘涛戚伟
人口与经济 2024年5期

收稿日期:2024-01-18;修订日期:2024-07-19
基金项目:国家自然科学基金项目“网络视角下城市增长与收缩的测度与机理研究”
(42171216);首都经济贸易大学重大培育项目“双碳目标下纵深推进以人为核心的新型城镇化研究”
(ZD202302)。
作者简介:郭涛,经济学博士,首都经济贸易大学城市经济与公共管理学院博士后;吴康(通讯作者),理学博士,首都经济贸易大学城市经济与公共管理学院教授,博士生导师;李栋,理学博士,清华大学中国新型城镇化研究院高级研究专员;刘涛,理学博士,北京大学城市与环境学院研究员,博士生导师;戚伟,理学博士,中国科学院地理科学与资源研究所副研究员。
摘 要:人口监测是开展人口规划、统计、预测及预警等
的基础性工作,是政府科学决策的基石。我国人口监测的传统数据仍存在漏报重报、质量不高、时效不强、属性不全、融合不深等问题,难以实施有效的人口精细化管理,也限制了监测数据在人口学研究中的广泛应用。随着信息技术的快速发展及移动终端的进一步普及,手机信令、互联网、遥感信息等一系列可直接或间接捕捉“人口行为”的新型数据大量涌现并应用于人口监测,与人口普查、调查等传统数据采集手段互为补充,有望通过交叉协同形成更加全面、更为实用的人口监测多源大数据基础。
从人口监测的传统数据、新型数据及新老数据融合三方面入手,系统梳理了数字时代用于人口监测的多源数据。
首先,通过梳理传统人口监测的分类及相关应用研究,总结了传统数据的主要优势、瓶颈与不足,进而明确了融合新型数据的需求靶点和必要性。
其次,从数据分类及优缺点对比、应用研究等角度对新型数据的相关文献进行梳理,重点分析现阶段应用新型数据的机会和挑战。
最后,通过总结传统数据与新型数据融合应用的优势,提炼了有待进一步研究的议题,
为应用多源数据实现人口动态监测,推进流动人口统计信息化、规范化和精细化,支撑政府政策制定和人口学研究建立了理论基础。
关键词:多源数据;人口监测;人口行为;人口研究;调查普查
中图分类号: C921.2
文献标识码: A
文章编号:1000-4149(2024)05-0063-15
DOI:10.3969/j.issn.1000-4149.2024.00.045
一、引言
人口是影响我国经济社会发展的基础性变量,对人口动态变化进行精准
监测是调整人口政策、优化经济社会结构的基石,也是开展人口战略研究、解决当下人口问题和前瞻性应对未来人口问题的基础性工作。
《中共中央国务院关于优化生育政策促进人口长期均衡发展的决定》
明确提出,应“加强人口监测和形势研判,健全完善国家生命登记管理制度,健全覆盖全人群、全生命周期的人口监测体系,密切监测生育形势和人口变动趋势”。当前,我国人口发展已进入低出生率、低死亡率、负增长率的新阶段,
必将对我国未来经济社会发展路径、收入分配和资源配置等
产生深远影响,也对完善我国人口监测体系提出了迫切要求。
《人口与经济》2024年第5期
郭 涛,等:
数字时代人口监测中的多源数据应用
人口监测旨在基于普查、调查、行政记录等方法,对国土范围内全量或特定人群开展定期监测,包含数据采集、处理、评估、汇总等多个阶段。经典人口学理论认为,人口既包含性别、年龄等自然构成,又具有经济构成和社会构成。传统人口监测重点关注人口的自然构成,如出生、死亡、迁移与流动等,并产生了人口普查、调查及行政记录等常规人口监测数据,这类数据构成政府决策和人口研究最重要的数据基础。近年来,随着数字化和信息技术的普及,人口监测数据的范畴正逐渐向经济社会构成延伸,表现为“人口行为”数据的日益丰富,大大提高了人口监测的时效性和
数据
属性的丰富性。因此,广义上的人口监测可进一步延伸至监测数据的后续开发应用,包括在出生率和死亡率估计、流动人口分析、人口预测等经典人口学研究领域及经济学、公共卫生、地理学、城市规划等与人口研究密切相关的交叉领域的应用,为新时期制定精细化、高质量的人口政策提供了数据支撑。这类新型数据主要来源于互联网、物联网、基于位置的服务(LBS)、遥感导航、地理信息等产业用户在应用服务过程中产生的海量行为记录,对完善传统人口监测数据提供了重要补充,也为实现对人口特征全面、准确、实时的监测提供了新契机。
当前,各国学者针对传统数据、新型数据以及两类数据的融合应用展开了丰富的研究,但尚未有文献在多源数据的统一框架下梳理我国人口监测的数据。本文基于人口监测及其延伸的广义应用范畴,分别从传统数据、新型数据及新老数据融合的多源数据三方面系统梳理了我国人口监测体系的整体演进及监测数据开发应用的相关研究,并提炼有待进一步研究的议题,为构建基于多源数据的人口动态监测体系提供理论支持和实践借鉴。
二、人口监测的传统数据:实践与经验
传统人口监测采取普查为主、抽样调查和专项调查为辅的形式开展,具有强制性、结构化和覆盖全等特点,但也存在长时滞、成本高、数据重报漏报等问题[1]。因此各国在实践中逐渐引入行政记录数据进行补充[2],通过对人口相关行政记录的“统计化操作”生成普查可用的指标信息[3]。传统人口监测数据广泛应用于出生率及死亡率估计、预期寿命及人口预测等对数据覆盖范围及连续性要求更高的研究中。
1. 传统监测数据的分类
人口普查及抽样调查是我国目前实施的、以立法确认的最基本的人口数据获取方式。近年来,随着信息化水平不断提高,普查与调查数据的获取过程也出现了新变化,第七次全国人口普查(简称“七普”)开始全面采取电子化方式登记,并鼓励通过手机等移动终端自行填报,在质量控制环节针对电子化登记记录设置了700余条校验规则[4],发现问题可及时核实,大大提高了人口普查的数据质量,减少数据重报、漏报问题。
考虑到部分政策主要针对特定区域和重点人群,政府、高校和科研机构也会开展定期或不定期的人口专项调查,以获取更及时、更具针对性的特殊群组人口相关信息。这类专项调查数据对普查数据形成了重要补充,在政策设计和效果追踪中发挥着越来越重要的作用。虽然专项调查数据也存在不同数据库难以相互匹配、调查时间不连续、覆盖样本少等缺点,但其仍为分析特定人口问题提供了关键数据支撑,是传统人口数据的重要组成部分。
居民人生各阶段在行政部门的登记、报告、审批、检查等活动,保存了大量人口行政变动信息,其具有数据质量高、收集成本低等特点,逐渐被用于辅助进行人口普查或调查[3]。尤其2016年以来,随着中央加快统筹推进政务数据共享和应用工作,县级以上行政单元电子政务已实现100%覆盖,海量的低成本数字化行政记录数据为提高普查数据质量、降低人口数据获取成本提供了重要支持。例如“七普”通过将普查对象与联网行政记录进行比对,显著提升了普查工作的事前摸底效率,减少了覆盖误差。借鉴发达国家人口普查的演变趋势,未来随着全国一体化政务大数据体系的建设,不同部门间行政记录数据的标准化、规范化和共享水平会不断提高,行政记录数据将逐渐成为传统人口数据不可或缺的组成部分。
2. 传统监测数据的应用研究
(1)人口监测体系的国内外对比与优化。
部分研究从方法、方式、指标、预测等方面对比国内外人口监测体系的异同,为我国健全人口动态监测体系提供了重要借鉴。从监测方法来看,国外人口监测正逐步从“人口普查”的传统模式向“以人口普查为主,行政记录为辅”的组合模式和“仅使用行政记录”的完全模式过渡,而我国目前仍主要采取传统模式,但正逐步向“组合模式”转变。从监测方式来看,部分国家选择以建筑物普查、社区调查等替代普查长表,逐年采集人口的特征、家庭、移民、居住、教育等信息,监测周期更短,而我国的普查仍采取长短表结合的方式,且更注重人口素质、人群结构和空间分布等基础内容的获取,监测周期更长。从监测指标来看,除基本人口特征外,国外的监测指标还包括家庭结构、工作收入、居住条件、卫生保障等多方面,能全面覆盖居民的经济社会生活,且指标选取更加科学,而国内监测指标的覆盖内容
相对较少,且存在指标选取不合理、编码依赖人工等问题。从人口预测来看,国外短期及中长期人口预测方法和实践已较为成熟,预测结果广泛应用于支撑人口政策制定,国内人口预测则实践不足,尤其缺乏准确有效的中长期人口预测方法[5]。综上,未来人口监测可通过加大行政记录数据的应用、以逐年调查替代普查长表、
普查及调查指标选取和编码方式科学化、加快开发适应我国人口发展特征和阶段的预测模型等手段,进一步降低数据采集成本,提高人口监测的效率和准确度。
(2)传统人口监测数据质量评估与改善。
由于数据获取方法和目标各不相同,不同类型的传统数据存在异质性,准确评估及改善
数据质量
是进一步应用数据开展分析的前提。对于人口普查数据,漏报、重报和误报是其面临的主要挑战,尤其是特定群组的重报、漏报问题。现有文献在对普查数据整体质量评估和校正的基础上,重点讨论了低龄人口、高龄人口、青年人口、外国移民等特定群组的重报、漏报问题,普遍使用的方法包括事后抽样调查法、双系统估计量法、队列存活率法、普查数据分析法、惠普尔指数法、普通最小二乘法及不同方法的综合运用。方法的选择需综合考虑评估对象、比对数据质量和评估准确度。
金城(Kaneshiro)使用普通最小二乘法估计美国1990年人口普查的净漏报,发现男性、新移民和年龄在15—44岁之间的人群相对净漏报比例更高[6]。基于Brass-Logit、Coale-Demeny、联合国模型、DCMD模型等的生命表技术是修正普查数据最常用的方法。总体而言,现有针对普查数据质量评估和改善方法的研究已较为成熟,但在实际应用过程中还需重点考虑方法的选择和不同方法的综合利用。
调查数据的误差主要来源于抽样过程,不合理的抽样方案、实施过程中的无回答现象、频繁的人口流动等都会影响样本选择的随机性和代表性。抽样的精度通常采用对比相对误差、标准误差、变异系数等方法来判断。加权控制法是处理抽样数据估计误差的重要方法,现有文献重点探讨了抽样中权数的获取、调整、评估和不同群组的权数设计等问题,为抽样调查结果的纠偏和准确的统计推断提供了技术支持。如贝克尔(Becker)和
卡拉马尔(Kalamar)提出了一种基于DHS抽样方案的扩展夫妇成对权重估计方法,发现应用该权重可以使估计的
大部分中位数百分比偏差小于3%[7]。可以发现,目前针对抽样调查数据质量评估的研究相对较少,评估方法有待进一步优化。
考虑到行政记录数据的采集并非以支持人口监测为目的,应用此类数据亟须实现全社会政府部门的数据共享和跨部门统计化。但我国在此过程中尚存在各部门登记口径不统一、规范性差、大量重复记录、数据互不衔接、生命登记系统不完善、行政寻租等问题,导致不同来源的行政记录数据质量参差不齐、处理难度较大。以生命登记系统为例,目前我国登记出生人口信息的部门既有各区县的妇幼保健机构,又有负责户籍登记的公安机关,两部门的统计时间、渠道和目的均有不同,统计的出生人口平均差值高达2.7%[8]。死亡登记也存在农村和高龄死亡漏报、部分地区虚报等问题,基于《死亡医学证明》的死亡登记覆盖率有待提升。现有文献中常用的行政记录数据质量评估方法包括行政记录比对法、事后抽样调查法、常规调查比较法、三维度评估法等[2]。同时,现有文献还从构建行政记录数据质量评估框架、统一行业分类及指标口径、加强全国统一行政记录共享平台建设、加强立法等方面提出了改善行政记录数据质量、加快数据跨部门共享的政策建议。行政记录数据
在人口监测体系中发挥着越来越重要的作用,而现有对行政记录数据质量的讨论多为定性研究,缺乏定量和方法的讨论,这与现阶段行政记录数据较低的开放程度有关。
(3)传统人口监测数据的应用研究。
在确保数据质量的基础上,现有文献从出生率和死亡率估计、人口迁徙、人口预测等人口学经典问题及老龄化、健康、教育、住房等与人口密切相关的领域,多维度开展了丰富的应用研究。出生率和死亡率估计是人口科学的重点问题,现有文献主要从估计方法、数据校准、结果分析及特定群组估计等方面展开研究[9]。随着人口流动的日益频繁,现有文献基于传统数据,重点探讨了我国流动人口的口径界定、规模测度、时空演变特征、社会融入和居留意愿等问题。周皓基于“七普”数据分析了我国现阶段人口流动的距离、模式、方向等特征,认为“七普”数据应公布重报率和其他误差率,以便真实评估流动人口规模[10]。高质量的人口数据也是开展人口预测的基础。目前,国内学者正尝试探索适用于我国的
人口
预测模型,并应用数学统计预测、队列因素法、概率人口预测等方法对人口总量和生育率等变量的变化趋势进行预测。老龄化是当前我国经济社会发展面临的重要问题,部分学者基于传统数据探讨了老龄化的时空演变特征及其通过负担效应和寿命效应对储蓄率、经济增长、劳动力供给、技术进步等的影响[11]。此外,考虑到普查和专项调查还收集了人口的住房条件、受教育水平等丰富的经济和社会特征,这些数据也为从微观层面研究我国居民住房需求的变化及其影响因素、教育机会均等化等重要问题提供了机会。
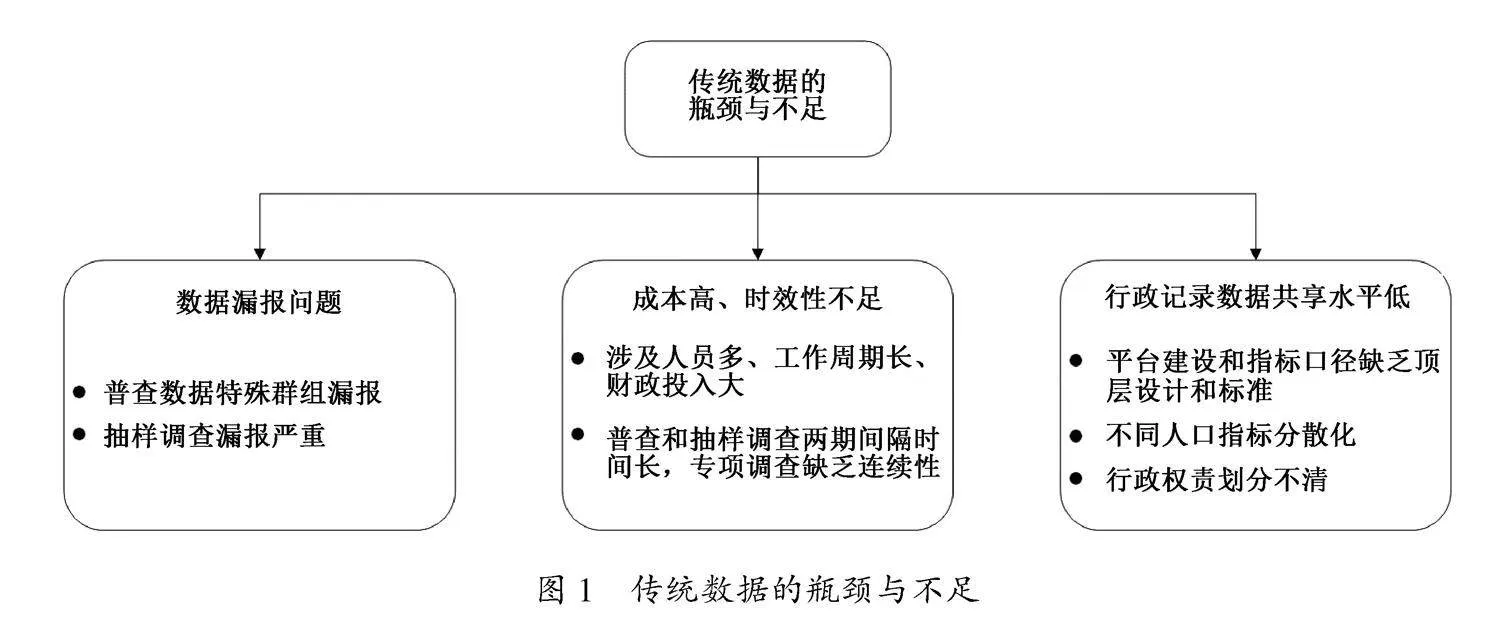
3. 传统数据的优势、瓶颈与不足
传统人口监测数据具有连续性强、覆盖性广和可获取性高等优势,但也在以下几个方面存在瓶颈与不足(见图1)。
第一,普查数据中特定群组的漏报问题仍有待改善。随着“七普”的信息化转型,人口漏报率达到历史新低的0.05% 数据来源:国家统计局,http://www.stats.gov.cn/sj/zxfb/202302/t20230203_1901089.html,但现阶段技术仍无法解决由于生命登记系统不完善、个人填报意愿等导致的漏报问题,尤其是特定群组的出生人口和死亡人口的漏报。李婷等通过综合多种模型生命表并利用国际比较法对“七普”各年龄段分性别的死亡水平进行估算,并与“七普”死亡数据进行比对,发现“七普”婴儿男女性死亡漏报率分别高达75.3%、76.61%,中低龄老人(60—79岁)男女性死亡漏报率分别为
51.93%、34.63%[12]。特定群组的死亡人口漏报问题既影响对整体死亡水平的估计,也不利于准确预估未来平均寿命和整体人口发展趋势。此外,也需警惕“数据鸿沟”及“数据歧视”等问题催生的个人信息的谎报和瞒报等[4]。
第二,非普查年份抽样调查数据漏报严重。抽样调查数据的误差主要来自抽样方法本身的随机性、推算误差及调查填报等工作产生的操作误差等。以“七普”数据回推,2011—2014年普查和抽样调查的出生人数年均相差235万,出生登记的漏报
严重[13]。将抽样数据与公安部门的户籍登记数据进行交叉比对,发现2012年国家统计局公布的出生人口与户籍登记的实际出生人口误差高达300万人[14]。通过估计和比对历次抽样调查的死亡漏报率,发现2015年1%人口抽样调查中除1—4岁年龄组外,其余各年龄组均存在较严重的死亡漏报问题[15]。可以发现,抽样调查数据的低龄人口和死亡人口的漏报问题尤为严重,原因之一是我国尚未建立完善的以《出生医学证明》和《死亡医学证明》为基础的生命登记系统。
第三,获取成本高,时效性和连续性较差。随着政府对各类指标的需求扩大、人口流动性提高及个人对隐私信息的重视,获取传统数据的难度和成本进一步提高,这给中央和地方财政带来较大压力。尤其我国是人口大国,开展普查不仅需要聘请和培训大量的普查员和普查指导员,而且前后需经历多个环节,涉及人员多、工作周期长、财政投入大,如何在保证数据质量的同时进一步压缩成本是未来面临的重要挑战。同时,由于普查和抽样调查分别每十年和每五年开展一次,且数据获取和整理的时间都较长,各类专项调查数据也多为非连续数据,各年之间指标统计口径还存在差异,这些因素都会导致传统人口数据的时效性较差、连续性不强,无法及时有效地支持政策调整,也增加了开展各类人口研究的难度。
第四,行政记录数据的共享水平低,在普查和调查中应用不足,获取困难。现阶段,我国各省市电子化行政记录平台多由省内牵头建设,缺乏国家标准和顶层设计,部门间指标记录的口径、时间不统一,难以实现跨部门、跨地区的数据整合。不同部门人口指标的记录分散化、孤立化和单向化,部门间既有重复又有空白,产生行政资源的浪费。部门间的协同工作机制尚不明确,权责划分相对模糊,缺乏涉及个人隐私信息的保护制度,进一步降低了行政记录数据应用于人口普查和调查的效率。以流动人口监测为例,目前,国家统计局、公安部、
国家卫生健康委员会、人力资源和社会保障部、农业农村部等多部门均开展了流动人口调查,但“流动人口”的定义口径存在差异且统计指标各有不同,且人员基础信息统计不全,这些问题都限制了不同部门和地区数据的整合。此外,由于行政记录数据涉及人的身份、健康、居住、经历等多重隐私信息,将其应用于人口研究会面临较大的法律和伦理挑战,这也限制了部分研究的开展和数据价值的深入挖掘。
三、人口监测的新型数据:机会与挑战
近年来,随着数字化和信息技术的普及,大量与人口相关的新型数据,例如手机信令数据、物联网数据、卫星遥感数据等,直接或间接记录和反映了人口的行为特征,能够在更小的时空粒度上反映人口变化,为实现人口实时、动态、精准监测提供了数据支撑,也为解决传统数据时效性不强、采集成本高、数据漏报、缺乏共享等问题提供了新契机。新型数据获取的实时性和低成本使其
广泛应用于人口流动分析等对数据时效性和动态性要求更高的领域。
1. 新型数据的分类及优缺点对比
以是否直接反映人的行为为标准,新型数据包括直接行为数据和间接行为数据(见图2)。
直接行为数据是直接记录人口行为的数据,常用的包括手机信令数据、物联网数据、
基于位置的服务(LBS)数据等。手机信令数据是新型人口数据中最具代表性的一类,因其具有
高覆盖率、高持有率、高准确性等特点,目前广泛应用于估算出行流动、空间分布、职住特征、交通条件等研究,同时也为收集和校验传统监测数据提供了技术和数据支撑。但应用该数据时还存在老人和儿童手机持有率低、一户多号、非实名、人机分离、多运营商融合困难等难题,亟须通过算法优化重点突破。物联网技术通过将不同的传感设备应用于城市交通、安全监控、环境卫生、能源管理、健康医疗等各个领域,也可以获取大量记录人的行为的非结构化数据,
这类数据也被
应用于相关人口研究。但目前应用物联网数据进行研究的文献还较少,数据获取困难、隐私安全等问题限制了此类数据的应用。LBS数据融合了移动通讯、互联网、空间定位、位置信息、大数据等多种信息技术。相较手机信令数据,LBS数据的获取更依赖用户对服务的消费,但也能提供除用户位置之外的与偏好及消费习惯等相关的更为丰富的行为数据。因此,大量文献应用LBS数据进行人口消费和行为分析、公共情绪分析及人口空间化研究,如有学者基于腾讯约8亿用户的LBS数据进行城市级总体制图,精度高达88.9%,高于基于遥感数据的制图精度[16]。LBS数据的使用部分缓解了手机信令数据依赖基站信号强度、泰森多边形覆盖不全等问题,能辅助提高对人口分布空间异质性的刻画。
间接行为数据不直接记录人的行为,但可用于对人口行为特征的间接推断,常用的包括卫星遥感(RS)数据、地理信息数据、兴趣点(POI)数据等。随着遥感技术的快速发展,夜间灯光、土地利用等遥感数据越来越被广泛应用于人口及相关研究。考虑到这类数据通常与人的活动高度相关,在放宽准确度要求的前提下,遥感数据为反推人口行为特征提供了重要的数据支撑。遥感数据的优势在于获取难度低、连续性强、数据易处理,且能在更小的空间维度对人口分布进行模拟。此外,基于遥感数据获取的人口估计和预测数据也更容易与地理信息数据相匹配,进而被应用于城市中心识别、公共安全等领域的研究。地理信息数据包括道路、坡度、河流、区划等反映地区资源分布与城市规划特征的信息,这类数据通常不单独
被用于人口估计,而是通过与遥感数据、手机信令数据等结合,为人口空间分布估计和预测提供资源分布和规划特征方面的依据,增强估计的准确性和精细化水平[17]。近年来,POI数据因其具有丰富的空间语义信息,常被用于城市功能区划分、中心(边界)识别和业态集聚分析等研究。相较于仅能间接反映人口活动特征的遥感数据,POI数据与人口经济社会活动关联更密切、认知度更高[17],相较于记录个体行为轨迹的LBS数据,POI数据更能反映不同类型的场所对人口分布的影响,因此可用于更加精细的随城市功能规划的人口分布特征的研究和预测。
如有学者使用POI和房地产数据对新加坡不同区域的居民数量和平均年龄、老年人比例等人口特征进行预测,发现公交车站、委员会中心和儿童保育设施等POI数据对人口特征预测的贡献最大[18]。
尽管受限于个人信息保护与企业数据安全政策,研究者一般无法直接访问这些新型数据,但也有部分互联网公司提供了其用户地理位置、使用记录、使用内容等信息的下载通道,研究者可通过数据共享协议访问过去、当前和最新(甚至每秒)的数据,使应用手机信令数据、LBS数据等新型数据进行人口监测及相关研究成为可能。
2. 新型监测数据的应用研究
(1)出生率估计。
网络搜索数据、LBS数据等为监测难以达到的人群的生育模式和短期内生育率变化提供了一种可靠和准确的手段。部分研究尝试基于用户对“怀孕”、“育儿”、“堕胎”等与生育相关话题的主观搜索频率来推测当地短期内的生育相关指标。
例如雷斯
(Reis)和布朗斯坦
(Brownstein)探究了美国50个州与堕胎相关的搜索量和该州堕胎率及堕胎限制政策之间的关系,发现堕胎的搜索量与堕胎率呈反比,这表明禁止堕胎政策驱使人们转向互联网寻求堕胎服务[19]。
又如比拉里(Billari)等提出了一种基于谷歌搜索的生育率监测方法,发现使用该方法预测的出生人口误差比人口普查局的
低35%[20]。需要注意的是,使用网络搜索数据进行人口统计分析的前提是网络搜索总量和个人意图之间相关性的持续。也有研究使用LBS数据(如Twitter等)研究孕产妇和生殖健康的相关问题,以及对
特殊人群的行为和情绪进行分析。
例如有学者使用Twitter帖子来量化分析分娩前后376名母亲在社会参与、情感、社交网络和语言风格等维度上的变化[21]。
(2)死亡率估计。
部分研究使用互联网、手机信令、LBS等数据来推测人口的死亡率及相关信息。
有学者使用来自WikiTree网站的在线系谱数据集来识别过去几个世纪中人类人口寿命分布的变化,并构建了人类寿命的预测模型[22]。
有学者发现在难以接触到的人群中,手机可能被用作进行远程解剖和了解死亡情况的工具[23]。
有学者基于对Twitter网站上近100万条信息的情感分析,研究了不同的人口统计学特征(年龄、性别和职业)对自杀率的影响[24]。有学者通过对在线讣告的自动收集和文本挖掘,得到美国癌症死亡的年龄分布、地理空间分布和时间趋势[25]。还有学者利用8600万份在线扩展族谱数据分析了家族分散过程,获取了高度可靠的人口统计数据集[26]。
(3)人口流动及特征分析。
考虑到LBS数据和手机信令数据等能实时捕捉人口位置的空间变化,因而被广泛应用于人口迁移和流动研究。
有学者使用四年共计150万条卢旺达人的移动通信数据集,描述了卢旺达人口国内移徙的动态轨迹、主要原因和后果[27]。有学者使用Twitter约50万用户的LBS数据来评估这些用户在国家内部和国家之间的地理移动,提出了一种使用倍差法减少样本选择偏差的方法,并预测移民趋势的转折点[28]。
还有学者通过分析领英的数百万份LBS和职业历史数据集,调查了专业人士的国际移民趋势及特征[29]。此外,还有部分文献应用新型数据研究了其他多种人口特征的分布和变化,包括性别、年龄、民族等。
例如有学者基于Twitter数据,使用机器学习模型从用户生成的内容中推断粗粒度的情绪和心理人口学特征,包括性别、收入、政治观点、年龄、教育程度、乐观程度和生活满意度等[30]。
通过对数据的清洗和处理,并采用多种方法处理样本代表性等问题,新型数据使搭建一种成本低、时效性强、准确度高的人口动态监测体系成为可能。
3. 应用新型数据的机会与挑战
新型数据打开了个体活动的内部世界,数字技术的发展使用户的每一个动作都可以被存储、存档并分析,这大大丰富了研究的范围及可能。但这类数据的滥用也可能带来一些问题与挑战。只有充分了解新型数据的优势和不足,才能为解决不同数据的问题、更好地结合传统数据与新型数据提供理论支撑,引导研究方向。
(1)机会分析。
新型数据的出现创造了社会科学研究的一种新的数据收集范式,其体现出的一些独特的性质与特征使其在人口监测中能发挥强大优势,主要包括以下几方面。
第一,提高数据采集效率,降低成本并提高时效性。互联网每分每秒都能产生大规模的用户访问痕迹、社交网络和行为信息数据,大大提高了人口数据的收集效率并降低了成本,使研究人员得以使用连续的人口数据进行实时的人口监测、流动分析及预测预警。
第二,数据可跟踪记录并存档。新型数据所提供的信息并非针对特定人群的一次性信息,
而是能够对用户一段时间内的各种活动轨迹进行跟踪,并对产生的数据痕迹加以储存和归档,避免了传统调查由于受访者选择性回忆和统计人员的回忆偏差所产生的数据误差[31]。存储下来的数据也可以
被反复地审查和处理,以提炼出核心真实的信息。
第三,覆盖样本更全面。尽管新型数据并非全样本覆盖,但仍能以更低的成本覆盖更大范围的人群,甚至使研究者能获取传统调查无法到达的或者代表性更低的群体信息,提供针对某一重点人群更加深入的侧写和分析。
(2)挑战分析。
新型数据的滥用也可能引入新的风险和挑战,主要包括以下几个方面。
第一,数据需有选择地使用。由于新型数据的收集并不以服务人口监测为目的,因此这类数据必须有选择地使用,研究者需从海量指标中筛选出与自身研究目的最为相关的指标,通过清洗和处理,使之能更加合理和准确地反映所需信息。进一步地,新型数据的引入也使得研究过程由理论驱动转向数据驱动,亟须研究人员调整研究范式。
第二,样本选择性偏误问题。由于新型数据仅覆盖部分群体,同时独特的数据收集过程或
平台设计逻辑也会导致在使用该数据时引入样本偏差[32],使得推测的统计特征与总体特征发生偏离,因此需重点考虑在应用新型数据时的样本纠偏问题。
第三,不利于开展定性研究。数据体量过大使得研究人员很难逐个分析每一条数据,而现有的文本分析等自动化分析方法又不可避免地存在信息遗漏等问题,不利于研究人员开展定性研究。如何在海量数据中发现隐藏在其中的丰富内涵是未来应用此类数据的研究重点。
第四,伦理问题。一方面,源于互联网的个人数据可能包含个人未授权的隐私信息,导致在应用数据时产生对个人权利的侵犯及连带的法律责任,隐私数据的泄露也可能引发对弱势群体的数字歧视;另一方面,为避免不必要的法律争议,很多互联网公司并不向研究者提供包含人口基本特征的原始数据,而这些数据正是进行人口监测及人口学研究的核心数据基础,新型数据的伦理问题进一步限制了其被广泛应用于人口研究。
第五,存在技术壁垒。新型数据存在大体量、非结构化等特点,数据的获取、清洗、分析和管理过程都需要用到较为专业的大数据及计算机技术,人口等社会科学研究者未经过专业的
数字
技术培训,应用此类数据往往存在较大的技术壁垒。
总体而言,尽管将新型数据应用于人口监测尚存在不少挑战,但这些挑战也为通过克服它们以加快人口实时监测体系的构建创造了机会。
四、传统数据与新型数据的融合:多源数据人口监测
考虑到传统数据与新型数据各有利弊,将二者融合形成多源数据或许能取长补短,进一步提高人口监测的质量和效率。需要注意的是,多源数据的构建并非简单地将两类数据合并,其重点在融合,即通过整合不同类型的数据,既可保留传统数据连续性强、覆盖范围广的优点,又能充分发挥新型数据时效性强、获取成本低的优势,以实现在更小的时空粒度上对人口总量、结构及相关指标的实时监测,并不断拓宽数据的应用范围。目前,相关研究多聚焦于对人口结构、人口流动、贫困人口等的监测及人口空间化分析,研究综合性人口监测体系构建的文献较少。
1. 多源数据的优势
通过以上分析可以发现,传统数据的优势主要在于数据的连续性强、覆盖范围全面且可获取性更高,但也存在数据漏报、高获取成本和时效性较差等缺陷。与之相对应的,新型数据存在高时效、低成本、可跟踪以及可覆盖难以到达的人群等优势,但样本选择偏误、数据爆炸、伦理问题及高技术壁垒等问题也带来了巨大的挑战。通过融合传统数据与新型数据形成多源数据,主要具有以下两方面的优势。
首先,在传统数据中引入新型数据,可以丰富传统数据在指标、研究维度和时效性上的不足。考虑到传统人口监测的高成本,且可获取的人口指标有限,尤其缺乏人口主观和行为特征的指标,另外个体
为保护
隐私信息所发生的谎报和漏报也会对数据质量产生影响。通过使用新型数据辅助传统数据研究,能进一步丰富可用于研究的指标和维度。手机信令等数据的获取不受人的主观意愿的影响,且时效性更强,结合此类数据与传统数据进行人口流动等分析能进一步提高分析的准确性和时效性。此外,尽管传统人口监测能覆盖最全面的人口范围,但仍可能存在难以到达的人群未能统计。新型数据的辅助应用为估计这类人群的特征提供了可能,能进一步补充完善应用传统数据进行的出生率、死亡率等估计。
其次,在新型数据中引入传统数据,可以为应用新型数据开展分析提供基本数据保障。间接行为数据仅能反映人群的分布、活动等特征,而无法直接捕获人口行为,将其应用于人口分析和人口特征推断时必须
由传统数据提供数据基础。而传统数据也无法在更细的时空维度上量化人口的空间分布。因此需要通过结合两类数据,以实现在更精细化的时空维度上的人口数据网格化。
2. 多源数据的应用
(1)人口结构分析。
对人口结构变化的分析是人口监测的一项重要内容,人口结构不仅包括年龄、性别结构,还包括空间、社会结构等。传统数据对人口结构的监测主要基于人口普查、出生登记、死亡登记等数据,例如通过出生性别比推断人口整体性别比例的变化。近年来,随着移动终端的普及及用户登记的规范化,用户在购买手机卡、使用微信等社交软件时登记了基本人口特征信息,因此手机信令及部分LBS数据中也包含了人口结构的相关变量,将两类数据结合可用于监测人口结构的动态变化和社会分异等现象。
如陈晓萍等基于手机运营商登记信息中的用户性别数据,研究不同性别人群出行道路网的社会分异现象[33]。
汤姆林森(Tomlinson)等通过给移动设备发送短调查的方式,追踪难以接触到的农村人口的性别及年龄结构变化[34]。此外,还有大量文献基于多源数据研究了人口空间结构的变化。多源数据的应用大大提高0OLS2AiDi6koyrk3W9JWgw==了人口结构监测的时效性,为进一步分析人口结构变化与其他社会学和经济学变量的关系提供了可能。
(2)流动人口分析。
应用多源数据的流动人口监测可从政府、学界和企业三方视角展开。从政府实践来看,
国家卫生健康委员会基于大数据、云计算等技术来构建流动人口数据平台,实现了多源人口及社会经济数据的整合,加快了数据的分析和共享。北京、云南等省份
均尝试结合传统统计、遥感和手机信令数据来实现大数据动态人口监测
海淀区利用移动通信大数据、卫星遥感影像等高科技手段进行人口动态监测的网页:https://zyk.bjhd.gov.cn/ztzl/kjcx/ywdt/201810/t20181027_3897405.htm。从学术研究来看,部分学者也尝试基于多源数据对人口流动的时空特征进行分析。林文棋等利用以手机信令数据为主的多源时空数据,使用贝叶斯模型刻画了北京市朝阳区居住人口的时空变化[35]。
另有学者构建了一个手机信令数据的分析框架,解决了应用该数据时在数据收集、轨迹构建、数据噪声去除、数据存储和用户移动性分析方法等方面存在的问题,为大规模分析用户长时间运动轨迹提供了方法借鉴[36]。从企业实践来看,各大提供LBS服务的互联网公司也积极构建基于多源数据的人口迁徙实时监测平台,例如百度迁徙大数据、谷歌迁徙数据等,监测的指标主要包括人口的迁入地、迁出地、迁徙时间、迁徙数量等,并实现了人口迁徙的动态可视化。多源数据的应用丰富了对流动人口的分布特征、位置变化、通勤习惯、消费活动等指标的逐日、逐月的监测。
(3)人口空间化分析。
人口空间化是应用多源数据进行人口研究的一个重要方向,旨在基于传统人口数据,结合地理信息数据、遥感数据、手机信令数据、POI数据等新型数据,在更精细化的时空维度上实现人口数据的网格化,便于人口数据同经济、环境、资源等微观数据的整合和跨学科研究。现有研究探讨了在不同空间尺度下应用多源数据进行人口空间化的多种方法,包括插值法、遥感数据估算法、移动基站数据估算法、多源数据估算法等。
有学者基于从移动网络中被动收集的呼叫详细记录和移动管理信号数据开发了一个双峰模型,更好地估计了城市尺度上的实时人口分布[37]。何艳虎等融合人口统计数据、土地利用类型遥感数据、POI数据、DEM数据、河流道路数据等多源数据,构建栅格单元的人口分布模型,对珠江三角洲人口分布进行估计和预测,并实现了较为精确的估计结果[17]。
基于遥感数据、地理信息数据、POI数据及传统人口数据,研究机构还使用人口空间化的多种方法研发了覆盖全球的网格化人口数据集,影响较为广泛的包括美国能源部橡树岭国家实验室开发的LandScan人口数据集及南安普顿大学的WorldPop数据集等。其中,LandScan人口数据集能提供1998年至今1km分辨率下的全球网格化人口数据,而WorldPop数据集的分辨度在部分地区更是能达到100m。现有文献也基于这类网格化人口分布数据集,从各个层面针对数据质量控制、复杂地形人口密度估计、城市规模识别、能源消费等问题开展了更全面的研究。
(4)其他人口相关领域应用。
除人口研究外,基于多源人口监测数据并融合深度学习等先进技术的应用还推广至公共卫生安全风险防控和精准扶贫等与人口密切相关的领域,并形成了一系列研究成果。
在公共卫生安全风险防控方面,现有研究基于多源数据,综合使用深度学习和网络分析等新方法,重点研究了疫情扩散的时空动态、趋势预判、公众情绪、防控措施评估等问题,并探讨了疫情对经济社会的影响。如顾嘉等基于传统SEIR流行病传播模型,设计开发了考虑人口迁徙的vSEIdRm模型,并使用中国联通智慧足迹的人口迁徙数据,验证了人口迁徙和交通管制对疫情扩散的影响[38]。
另有学者通过分析2020年4月发布的348933条推文,分析了新冠疫情期间公众经历的特定情绪和人们关心的话题[39]。公共卫生安全风险防控相关研究要求数据的实时性和准确性,多源数据的引入有助于基于人口动态流动准确识别疫情扩散的时空变化及其影响。
近年来,多源数据还应用于贫困治理领域,为实现精准扶贫创新及动态防返贫预警提供数据支持。用于精准扶贫的大数据主要包括贫困登记、各部门行政记录、资源和空间地理信息等,重点收集了贫困家庭基本情况、致贫原因、帮扶责任人、帮扶计划、帮扶成效以及脱贫评估等基本指标。为评估脱贫政策效果,部分研究还对九项精准扶贫措施的实施效果进行了调查[40]。此外,多源人口大数据还可应用于防脱贫研究,如孙壮珍和王婷以四川省L区为例,分析了如何基于电网大数据构建防返贫预警机制[41]。
五、有待进一步研究的议题
近年来,为满足经济社会发展需要,人口监测的对象正逐渐从人口的自然构成向“人的行为”延伸。本文从人口监测的传统数据、新型数据及新老数据融合三方面对国内外相关研究进行系统梳理,研究发现:一方面,目前传统数据还存在特定群组及抽样调查数据漏报、数据采集成本高、时滞长和行政记录数据缺乏共享等不足,不利于人口实时动态监测体系的构建;另一方面,引入新型数据时机会与挑战并存,机会在于新型数据的获取效率更高、成本更低、时效性更强、覆盖相对全面且能长期跟踪记录,这些优势在一定程度上弥补了传统数据的不足,但新型数据同样产生了新挑战,包括研究范式的转变、样本选择性偏误问题、定性研究困难、伦理问题和技术壁垒等,
解决
这些挑战为构建
人口实时动态监测体系提供了新契机;进一步地,传统数据和新型数据的融合促进了两类数据取长补短,共同构成人口监测的多源数据基础,大大提高了人口监测的实时性、准确度及效率,并降低了监测成本。
目前,我国基于多源数据的人口监测研究与实践仍处于探索阶段,未来在以下几个方面仍有待于进一步加强研究。
第一,传统数据和新型数据的深度融合研究。未来可通过系统梳理不同类型数据的结构和内容特征,探究应采取何种方式
充分发挥数据间的互补优势,综合各数据的长处,以差异化方式促进传统数据与新型数据的深度融合,为整合形成多源人口监测数据库提供理论支撑。
第二,应用多源数据进行人口监测的新算法研究。多源数据融合了传统数据和新型数据,不同数据的处理方式存在异质性,既有方法并不能完全发挥多源数据作为融合数据的优势,需要进一步探索适用于多源融合数据的人口监测新算法。这类算法旨在在改善不同数据质量问题的基础上,优化传统数据与新型数据的匹配和融合方式,有选择地保留不同数据的优势信息,避免由于指标重复所产生的数据冗余、低效率等问题。
第三,数据获取和隐私计算问题研究。
获取问题是当前应用多源数据面临的核心议题之一,而改善数据获取的方法之一是应用隐私计算技术。通过制定统一的隐私计算规则,实现多源数据的“可见、不可见”,在确保个人隐私数据安全性的前提下,使研究者能够应用反映人口特征的相关变量进行分析。如何合理地针对多源数据进行隐私计算是未来相关研究需要关注的一个重要问题。
第四,明确监测的应用方向。现有文献尚缺乏对监测之后应用方向的讨论,无法实现以应用为导向的数据采集及监测分析。未来可尝试从理论和政策评估的目的出发,通过精心设计的社会实验或者准社会实验,研究不同条件变化下人口的变化及政策实施的效果,从而更加清晰和深入地分析导致这些现象产生的内在机制与改进方向。
参考文献:
[1]胡桂华,漆莉,迟璐婕.人口普查中遗漏人口数的估计[J].数量经济技术经济研究,2022(1):132-153.
[2]WALLGREN B, WALLGREN A. Register-based statistics: statistical methods for administrative data[M]. New York: John Wiley & Sons, 2014:121-146.
[3]徐蔼婷,杨玉香.基于行政记录人口普查方法的国际比较[J].统计研究,2015(11):88-96.
[4]“北京大学人口研究所人口普查质量评估”课题组,陈功.论人口普查信息化:新特征、新挑战与新路径[J].调研世界,2021(7):59-66.
[5]盛亦男,顾大男.概率人口预测方法及其应用——《世界人口展望》概率人口预测方法简介[J].人口学刊,2020(5):31-46.
[6]KANESHIRO M. Missing minorities? the phases of irca legislation and relative net undercounts of the 1990 vis--vis 2000 decennial census for foreign-born cohorts[J]. Demography, 2013, 50(5):1897-1919.
[7]BECKER S, KALAMAR A. Sampling weights for analyses of couple data: example of the demographic and health surveys[J]. Demography, 2018, 55(4):1447-1473.
[8]赵莉,樊延军,王媛媛,等.基于《出生医学证明》构建我国出生人口基础信息库的思考[J].人口研究,2019(3):57-64.
[9]赵明,王晓军.我国人口死亡风险异质与混合模型研究[J].统计研究,2023(3):139-150.
[10]周皓.中国人口流动模式的稳定性及启示——基于第七次全国人口普查公报数据的思考[J].中国人口科学,2021(3):28-41,126-127.
[11]王广州.新中国70年:人口年龄结构变化与老龄化发展趋势[J].中国人口科学,2019(3):2-15,126.
[12]李婷,郑叶昕,闫誉腾.第七次人口普查数据死亡水平估计[J].中国人口科学,2022(5):2-16,126.
[13]张现苓,明艳.第七次全国人口普查年龄数据准确性分析[J].人口研究,2022(4): 27-39.
[14]翟振武,刘雯莉. 七普数据质量与中国人口新“变化” [J]. 人口研究, 2021(3): 46-56.
[15]李成,米红. 中国1982年后人口普查和抽样调查中死亡漏报的估计——基于Bayesian分层回归模型 [J]. 人口研究, 2022(1): 19-36.
[16]XU Y, SONG Y, CAI J, et al. Population mapping in China with Tencent social user and remote sensing data[J]. Applied Geography, 2021, 130:102450.
[17]何艳虎,龚镇杰,林凯荣.基于地理大数据和多源信息融合的区域未来人口精细化空间分布模拟研究——以珠江三角洲为例[J].地理科学, 2022(3): 426-435.
[18]SZARKA N, BILJECKI F. Population estimation beyond counts-inferring demographic characteristics[J]. PlosOne, 2022, 17(4):e0266484.
[19]REIS B Y, BROWNSTEIN J S. Measuring the impact of health policies using Internet search patterns: the case of abortion[J]. BMC Public Health, 2010, 10:1-5.
[20]BILLARI F, D’AMURI F, MARCUCCI J. Forecasting births using Google[C]. 1st International Conference on Advanced Research Methods in Analytics, 2016:119.
[21]DE CHOUDHURY M, COUNTS S, HORVITZ E. Predicting postpartum changes in emotion and behavior via social media[C]. The SIGCHI Conference on Human Factors in Computing Systems, 2013: 3267-3276.
[22]FIRE M, ELOVICI Y. Data mining of online genealogy datasets for revealing lifespan patterns in human population[J]. ACM Transactions on Intelligent Systems and Technology, 2015, 2:1-22.
[23]TAMGNO J K, FAYE R M, LISHOU C. Verbal autopsies, mobile data collection for monitoring and warning causes of deaths[C]. 15th International Conference on Advanced Communications Technology (ICACT), 2013:495-501.
[24]FAHEY R A, MATSUBAYASHI T, UEDA M. Tracking the werther effect on social media: emotional responses to prominent suicide deaths on Twitter and subsequent increases in suicide[J]. Social Science & Medicine, 2018, 219:19-29.
[25]TOURASSI G, YOON H J, XU S. A novel web informatics approach for automated surveillance of cancer mortality trends[J]. Journal of Biomedical Informatics, 2016, 61:110-118.
[26]KAPLANIS J, GORDON A, WAHL M, et al. Quantitative analysis of population-scale family trees using millions of relatives[J]. Science, 2018, 360(6385): 171-175.
[27]BLUMENSTOCK J E, EAGLE N. Divided we call: disparities in access and use of mobile phones
in Rwanda[J]. Information Technologies & International Development, 2012, 8(2):1.
[28]ZAGHENI E, GARIMELLA V R K, WEBER I, et al. Inferring international and internal migration patterns from Twitter data[C]. The 23rd International Conference on World Wide Web, 2014:439-444.
[29]STATE B, RODRIGUEZ M, HELBING D, et al. Migration of professionals to the US: evidence from Linkedin data[C]. Social Informatics: 6th International Conference, 2014: 531-543.
[30]VOLKOVA S, BACHRACH Y. On predicting sociodemographic traits and emotions from communications in social networks and their implications to online self-disclosure[J]. Cyberpsychology, Behavior, and Social Networking, 2015, 18(12):726-736.
[31]CESARE N, LEE H, MCCORMICK T, et al. Promises and pitfalls of using digital traces for demographic research[J]. Demography, 2018, 55(5): 1979-1999.
[32]LAZER D, KENNEDY R, KING G, et al. The parable of Google Flu: traps in big data analysis[J]. Science, 2014, 343(6176):1203-1205.
[33]陈晓萍,周素红,李秋萍,等.广州城市道路网的社会分异——基于轨迹大数据的出行分布性别差异[J].地理研究,2021(6):1652-1666.
[34]TOMLINSON M, SOLOMON W, SINGH Y, et al. The use of mobile phones as a data collection tool: a report from a household survey in South Africa[J]. BMC Medical Informatics and Decision Making, 2009, 9(1):1-8.
[35]林文棋,陈会宴,谢盼,等.基于多源数据的北京市朝阳区人口时空格局评估与预测[J].地球信息科学学报,2018(10):1467-1477.
[36]QIAO Y, CHENG Y, YANG J, et al. A mobility analytical framework for big mobile data in densely populated area[J]. IEEE Transactions on Vehicular Technology, 2016, 66(2): 1443-1455.
[37]FENG J, LI Y, XU F, et al. A bimodal model to estimate dynamic metropolitan population by mobile phone data[J]. Sensors, 2018, 18(10): 3431.
[38]顾嘉,陈松蹊,董倩,等.基于vSEIdRm模型的人口迁移以及离汉交通管控对新冠肺炎疫情发展的影响分析[J].统计研究,2021(9):114-127.
[39]ZHANG X, WANG Y, LYU H, et al. The influence of Covid-19 on the well-being of people: big data methods for capturing the well-being of working adults and protective factors nationwide[J]. Frontiers in Psychology, 2021, 12: 681091.
[40]汪磊,许鹿,汪霞.大数据驱动下精准扶贫运行机制的耦合性分析及其机制创新——基于贵州、甘肃的案例[J].公共管理学报,2017(3):135-143,159-160.
[41]孙壮珍,王婷.动态贫困视角下大数据驱动防返贫预警机制构建研究——基于四川省L区的实践与探索[J].电子政务,2021(12):110-120.
Multi-source Data for Population Monitoring in the Digital Age:
Current Situation and Prospects
GUO Tao1,2, WU Kang1,2, LI Dong3, LIU Tao4, QI Wei5
(1.School of Urban Economics and Public Administration, Capital University of Economics
and Business, Beijing 100070, China;2.Beijing Key Laboratory of Megaregions Sustainable
Development Simulation, Beijing 100070, China;3.Institute for China Sustainable
Urbanization, Tsinghua University, Beijing 100084, China;4.College of Urban and
Environmental Sciences, Peking University, Beijing 100871, China;5.Institute of
Geographic Sciences and Natural Resources Research, Chinese Academy of
Sciences, Beijing 100101, China)
Abstract: Population monitoring is the basic work to support the party and the state to carry out multiple goals such as population planning, statistics, prediction and early warning, and is the cornerstone of scientific government decision-making. At present, the traditional data of population monitoring in China still have some problems, such as missing and rereporting, low quality, weak timeliness, incomplete attributes, and insufficient integration. It is difficult to implement effective and fine population management, and also limits the wide application of monitoring data in demographic research. With the rapid development of information technology and the further popularization of mobile terminals, a series of new data such as mobile phone signaling, Internet and remote sensing information that can directly or indirectly capture
“population behavior” have emerged in large numbers and been applied to population monitoring, complementing traditional data collection methods such as census and survey. It is expected to form a more comprehensive and practical multi-source big data foundation for population monitoring through cross-collaboration. This paper systematically combs the multi-source data used for population monitoring in the digital era from three aspects: traditional data, new data and the fusion of traditional and new data. Firstly, by combing the classification of traditional population monitoring and related application research, it summarizes the main advantages, bottlenecks and shortcomings of traditional data, and then clarifies the demand targets and necessity of fusion of new data. Secondly, from the perspective of data classification, comparison of advantages and disadvantages, and application research, the relevant literature of new data is reviewed, focusing on the opportunity and challenge of applying new data at the present stage. Finally, by summarizing the advantages
of fusion application of traditional data and new data, the issues to be further studied are refined. This study establishes a theoretical basis for using multi-source data to realize population dynamic monitoring, promote the informationization, standardization and refinement of floating population statistics, and support government policy making and demographic research.
Keywords:multi-source data;population behavior;population data;demographic studies;survey and census
[责任编辑 崔子涵]
