
基于回归模型的共享单车需求预测
2024-07-01 10:06张山山鲍蓉马玉婷
中小企业管理与科技·上旬刊 2024年4期
关键词:随机森林
张山山 鲍蓉 马玉婷


【摘 要】为了准确掌握城市共享单车投放量,论文提出了一种以随机森林为基础的预测方法。首先,通过随机森林模型筛选出符合条件的共享单车影响因素;其次,将单车变化量和影响因素分别作为神经网络参数,建立共享单车需求投放模型;最后,以公开数据集为对象,对其工作日及节假日间的单车投放量进行预测。在随机森林模型下,预测得分为84.48,选出权重最高的6个影响因素分别为温度、小时、太阳辐射、是否是工作日、湿度、降雨量。然后建立LSTM神经网络模型,以这些特征训练网络,得到预测得分为82.48,在大幅减少特征维度、降低计算量的情况下,预测结果与其实际出行特征基本吻合,较好地验证了该模型的实用性和普适性,具有一定的实际参考价值。
【关键词】共享单车需求预测;随机森林;LSTM网络;Python
【中图分类号】F713.36;F570 【文献标志码】A 【文章编号】1673-1069(2024)04-0038-03
1 引言
随着城市化进程的日益加速,共享单车作为一种新兴的绿色出行方式,正逐渐改变着人们的出行习惯。它既提供了灵活便捷的交通选择,减轻了城市交通拥堵,又符合现代社会对可持续发展和环保的需求,成为越来越多人短途出行的首选[1]。与此同时,共享单车供需不平衡的问题日渐凸显,因此,对其需求进行准确预测成为提升人们出行效率和单车使用率的关键[2],更有助于优化车辆调度,提高运营效率,有效缓解城市交通压力,推动城市的可持续发展。
共享单车需求预测是一个跨学科的复杂问题,受到众多因素的影响,包括时间、地点、天气、节假日、政策调整等。这些因素相互交织,使得共享单车的需求变化呈现出高度的复杂性和不确定性。因此,构建一个准确且有效的需求预测模型,成为共享单车行业亟待解决的重要问题。回归模型作为一种经典的统计分析方法,在需求预测领域具有广泛的应用。它通过建立自变量和因变量之间的数学关系,实现对因变量的预测。在共享单车需求预测中,回归模型可以根据历史数据和相关特征,构建需求预测模型,并通过训练和优化模型,实现对未来需求的准确预测。
尽管国内外学者在共享单车需求预测方面已经取得了一些研究成果[3-5],但现有的研究仍存在一些不足之处。部分研究在数据处理和特征提取方面存在局限,导致预测精度不高。同时,一些研究缺乏对模型性能的系统评估和优化,使得模型的泛化能力和稳定性有待提升。
鉴于此,本研究通过回归模型,关注天气、环境等多因素,旨在深入了解这些因素对共享自行车需求的影响,进而挖掘数据中真正的影响因素。本项研究致力于建立一个简洁而可靠的神经网络预测框架,为优化共享自行车系统提供科学支持,推动城市交通的可持续发展。
2 随机森林模型
随机森林是一种集成算法,它通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能[6]。随机森林使用了CART决策树作为弱学习器,它是一种在原始数据集上通过又放回抽样重新选出k个新数据集来训练分类器的集成技术,它使用训练出来的分类器的集合来对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即最终标签[7]。
对于一般的决策树,假如总共有K类,样本属于第k类的概率为:pk,则该概率分布的基尼指数为公式(1),其可以取得不错成绩,主要归功于“随机”和“森林”,一个使它具有抗过拟合能力,一个使它更加精准。基尼指数越大,说明不确定性就越大;基尼系数越小,不确定性越小,数据分割越彻底、越干净。
在遍历每个特征的每个分割点时,当使用特征A=a,将D划分为两部分,即D1(满足A=a的样本集合)、D2(不满足A=a的样本集合)。则在特征A=a的条件下D的基尼指数为公式(2)。随机森林中的每棵CART决策树都是通过不断遍历这棵树的特征子集的所有可能的分割点,寻找Gini系数最小的特征的分割点,将数据集分成两个子集,直至满足停止条件为止。
3 神经网络模型
神经网络是一种受到人类大脑结构启发的计算模型,由大量的神经元以及他们之间的连接组成。神经网络可以通过学习和调整连接权重来进行模式识别、回归等任务。神经网络中,每一层都由多个神经元组成,通过前向传播和反向传播来不断优化模型以适应给定的任务。
长短期记忆网络(Long Short-Term Memory,LSTM)是一种特殊的循环神经网络(Recurrent Neural Network,RNN)架构,用于处理序列数据。LSTM的设计目的是解决传统RNN在处理长序列时存在的梯度消失或爆炸问题[8]。本文使用的神经网络模型为双向长短期记忆网络(Bidirectional Long Short-Term Memory,BiLSTM),它是在LSTM的基础上进行改进的一种架构,用于处理序列数据,网络的完整结构见表1。与传统LSTM不同的是,BiLSTM同时考虑了序列数据的过去和未来信息。它包含两个方向的LSTM层:一个按照时间顺序处理输入序列(正向),另一个按照时间逆序处理输入序列(反向)。通过这种方式,BiLSTM可以同时捕捉到序列数据的过去和未来信息,从而更好地理解序列中的上下文和依赖关系,提高模型的性能和泛化能力[9]。
4 实例应用
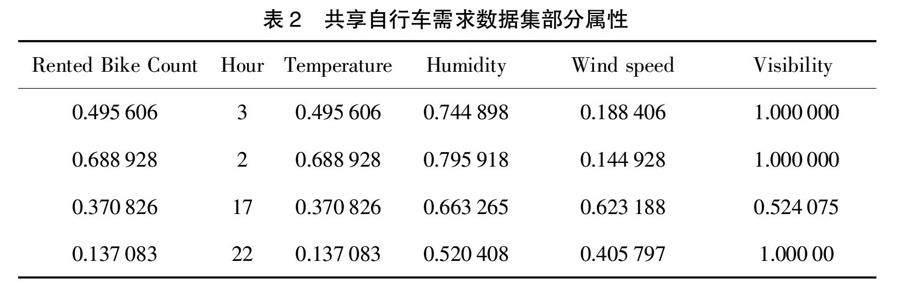
选取UCI上公开的首尔共享单车数据集作为研究对象[10]。该数据集包含2017年12月1日至2018年11月30日的共计8 760条数据,每条数据包含13个自变量:Date(日期)、Hour(小时)、Temperature(温度)、Humidity(湿度)、Wind speed(m/s,风速)、Visibility(10 m,能见度)、Dew point temperature(露点温度)、Solar Radiation (太阳辐射)、Rainfall(下雨量)、Snowfall(下雪量)、Seasons(季节)、Holiday(是否假期)、Functioning Day(是否工作日),以及1个目标变量Rented Bike Count(每小时单车使用量)。因为每小时单车的使用数量是与所在城市的气候以及环境监测相关的,所以可以推广到所有拥有共享单车系统的城市。本文使用随机森林方法进行研究,随机选取其中70%的样本作为训练数据集,剩下30%作为测试数据集。首先,对每一条样本数据提取年、月、日添加进数据集,然后对数据集的数值型变量进行预处理——归一化操作,处理后的数据样本见表2。
经过预处理后,初始化随机森林,为了取得最优效果,使用scikit-learn库中的GridSearchCV模块来遍历搜索最优参数组,搜索算法见算法1,其中N为样本数,T为时间,V为特征数。最终经过搜索取树最大深度为20,最大叶子节点数为100,决策树的数量为40。
算法1:最优随机森林搜索算法
1: 给定训练数据X∈RT×V和初始化随机森林α
2: 初始化搜索最优参数n_estimators、max_depth等
3: for k=1,2,...,遍历n_estimators(k)、max_depth(k)等网络参数 do
4: GridSearchCV:训练网络
5: GridSearchCV:计算网络分数
6: end for
在最优森林下对训练数据进行拟合,得到测试集分数为84.48,RMSE为0.057,将预测值与实际值绘制成图1,可以看到,预测值与实际值是相对接近的,即结果是可靠的。将影响预测的前6种因素按权重输出,分别是温度、小时、太阳辐射、是否是工作日、湿度、降雨量。
经过随机森林特征选择,使用被选择的属性训练神经网络,以减轻模型计算量。与随机森林不同的是,由于使用的是LSTM神经网络,因此需要对数据再次进行处理。设置窗口大小为4,LSTM中隐藏单元的个数为10,将原始特征转化为适合神经网络输入的X'∈RN'×W×V,其中W为窗口大小,训练迭代次数为300次,批处理大小设置为4,最终得到的R2分数为82.48,损失变化见预测结果与真实值如图2所示,可得出结论,神经网络使用更少的数据量,更小的计算量达到了与随机森林模型相近的准确性,由于数据输入模式更真实,因此具有更好的泛化性。
5 结语
通过对共享自行车需求预测任务进行随机森林分析,得到了84.48的分数,并获得影响该预测任务最重要的6个因素,这与前期相关性分析得到的结果基本保持一致。接下来只选择这些特征,将数据输入设计的神经网络中,预测得分为82.48,与使用全部数据的随机森林预测作对比,发现使用更低的特征维度,更少的计算资源达到了相近的预测结果,提高了模型的泛化性,为共享单车的需求预测任务提供了有效的参考。
使用回归模型来预测共享单车的需求可以为共享单车行业的运营和管理提供科学依据。主要体现在以下几个方面:首先,准确预测共享单车需求有助于优化车辆调度。通过了解不同时间和地点的需求分布,共享单车运营商可以更加精准地安排车辆的投放和调度,从而提高车辆利用效率,降低运营成本。其次,需求预测有助于提升用户体验。通过预测用户的需求变化,共享单车运营商可以提前做好车辆维护和保养工作,确保车辆的安全性和可用性。同时,根据需求预测结果,运营商还可以调整收费标准和服务策略,更好地满足用户需求,提升用户满意度和忠诚度。最后,本研究有助于推动共享单车行业的可持续发展。通过深入研究共享单车需求预测问题,可以为行业的健康发展提供理论支持和实践指导,促进共享单车行业的长期稳定发展。
【参考文献】
【1】杨鑫宇.基于机器学习的地铁站区域共享单车需求预测[J].石家庄铁道大学学报(自然 科学版),2023(36):92-98+126.
【2】谢光明.基于改进时空图神经网络的共享单车流量预测[D].上海:华东师范大学,2023.
【3】Gregory R. Krykewycz,Christopher M. Puchalsky,Joshua Rocks,et al.Defining a primary market and estimating demand for major bicycle-sharing program in philadelphia, pennsylvania[J].Transportation Research Record Journal of the Transportation Research Board,2010,2143(-1):117-124.
【4】徐叶冉子,沈瑾.基于圆分布法和时间序列模型的公共自行车需求量分析[J].工业工程,2014(2):55-63.
【5】何流,李旭宏,陈大伟,等.公共自行车动态调度系统需求预测模型研究[J].武汉理工大学学报(交通科学与工程版),2013,37(2):278-282.
【6】韩成成.基于数据挖掘任务的分类方法综述[J].软件,2023,44(06):95-97.
【7】方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(03):32-38.
【8】杨丽,吴雨茜,王俊丽,等.循环神经网络研究综述[J].计算机应用,2018,38(S2):1-6+26.
【9】徐先峰,黄刘洋,龚美.基于卷积神经网络与双向长短时记忆网络组合模型的短时交通流预测[J].工业仪表与自动化装置,2020(01):13-18.
【10】UCI Machine Learning Repository.Seoul Bike Sharing Demand[EB/OL].https://doi.org/10.24432/C5F62R,2020-02-29.
猜你喜欢
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
电脑知识与技术(2016年23期)2016-11-02
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
