
基于Prompt 和文本嵌入的刑事卷宗特征提取与信访风险评估模型的构建
2024-06-26 07:52:14申强
电脑知识与技术 2024年13期
关键词:风险评估
申强


摘要:在刑事案件办理过程中,如何自动且有效地提取非结构化卷宗数据中的特征信息,是提升信访风险评估模型精度的关键问题。本研究提出利用自然语言处理技术,基于Prompt方法对卷宗提取特征文本,并采用文本嵌入模型对提取的特征进行向量化处理及相似度归一化,进而训练出风险评估预测模型。实验结果表明,该方法能够显著提高特征表达能力,并提升评估模型在检测信访风险中的性能。未来,可以构建端到端的混合模型,以实现完全自动化的特征提取与风险预测。
关键词:风险评估;特征工程;文本嵌入;文本相似度
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2024)13-0034-03 开放科学(资源服务)标识码(OSID) :
0 引言
在刑事案件办理中,信访风险评估是一项重要的任务。非结构化卷宗数据往往难以准确归纳和定义特征参数,这给风险评估模型的训练带来了挑战。本研究旨在提出一种解决方案,利用基于Prompt的文本抽取、文本嵌入向量化和相似度归一化等技术辅助完成特征工程,从而实现对信访风险的准确评估,协助发现信访隐患,完善刑事案件办理中的风险评估理论体系。
1 文献综述
1.1 刑事案件办理中的信访风险评估
信访风险评估是指在刑事案件办理过程中对可能引发信访问题的因素进行分析和评估。信访风险评估具有很强的时间性和动态性,需要及时、准确地识别和处理。
1.2 非结构化卷宗数据的提取
非结构化卷宗数据是刑事案件办理中的一种重要数据类型,具有数据量大、格式多样、内容复杂等特点。
1.3 特征工程在风险评估中的重要性
特征工程是将原始数据转换为适合机器学习模型输入的特征的过程。在信访风险评估中,特征工程的质量直接影响模型的预测效果。提取有代表性的特征、减少特征维度可以提高风险评估模型的准确性。
1.4 文本嵌入模型和其在特征提取中的应用
文本嵌入模型将文本转换为向量,可以有效地提取文本特征,在文本相似度检测和向量数据库检索中具有广泛的应用。本文着重研究利用文本嵌入模型辅助计算相似度来实现特征归一化。
2 方法概述
2.1 当前特征数据的主要提取方法
当前的风险评估最广泛的做法仍是在全连接神经网络中进行的监督学习预测,训练数据集中的X表示输入特征数据,如职业、年龄、受教育程度等特征属性值。Y表示目标变量标签,代表风险等级或者风险具体评分值。因为全连接预测更依赖输入的特征数据的准确性和归一分布合理性,所以多数是通过信息登记卡等结构化数据来作为主要特征来源。人工登记有识别准确、分布均匀以及能识别难度较大复杂特征的优点,如可将工作单位从具体的单位名称归纳为机关事业单位、大型国有企业、个体经营等,具有更加科学合理的特征数据归一化基础,也能保证训练中的参数相关性。不过人工登记标注工作量太大,效率低,无法及时增补更多的特征数据,每次调整特征数据都要面临历史数据的补录任务,严重制约预测模型的进化[1]。
2.2 文本信息提取模型的选择和使用
基于提示词Prompt+文本的通用自然语言理解信息提取模型在命名实体、关系抽取、时间抽取、片段抽取上能力不断提升,完全可以应用在卷宗抽取特征数据上。之所以在LLM大模型时代仍然使用小模型来处理单一信息抽取任务,是因为在风险评估这种全连接任务中,特征工程仅需要单一的信息提取能力,大语言模型推理成本太高,而且低资源消耗的场景下,基于生成式的大语言模型信息提取效果不一定比参数量在100~300M的Encoder-only小模型好。
依照期望特征来组织Prompt的schema入参,构建特征工程的基础数据。命名实体:{人物、归属地、作案地、组织机构等};关系抽取:人物:{出生年月、受教育情况、工作单位、职业、身份、婚姻状况、羁押地、前科情况等};事件抽取:罪名:{时间、地点、事件等};文本分类:领域:{民生、养老金、医疗卫生、教育、工程、金融诈骗等}[2]。调整Prompt来抽取不同的特征数据进行多轮训练评估,直到找到最优特征组合,既不受制于人工标注的效率,也不担心初期的特征选取不科学和不完整。
2.3 文本嵌入模型的选择和使用
信息抽取得到的是一组离散且没有经过人工的归纳和编码化的特征数据,不能直接满足于全连接网络输入要求,比如工作单位是一组单位的中文名称,如果不进行基本的聚类,无法在结果拟合时有任何相关性支撑和延展性帮助,没有任何实际训练价值。本研究尝试通过文本嵌入模型来处理这些特征数据,将中文文本向量化并作为基础。中文文本嵌入模型与信息抽取模型一样,已经日渐成熟。其中,一些开源的离线模型如text2vec、m3e、bge等,都具备微调功能,并在中文文本向量化方面表现出色。
2.4 特征向量化和相似度归一化的方法
连续的线性特征值如年龄、金额等可以利用最小最大归一化或标准化均值方差归一化,但是经过文本信息提取的特征数据向量化后,仍然是一组离散的向量值,需要为每个特征做归一化,全连接要求归一化时相似的数值表述相似的特征意义,想要利用这些自动提取的特征数据,还要进行相似度聚类。以工作单位来说明,涉案人员工作单位性质在信访风险评估时是重要的参考量,以往在人工登记案件信息卡或标注特征时,需要人工将工作单位登记为不同的单位性质、身份、职业等。而自动提取特征的做法中,工作单位只是一个单位名称,并无单位性质、身份、职业等附加特征,相似度归一化可以在一定程度上模拟人工分类[3]。通过计算工作单位之间的相似度,将相似的工作单位聚集在一起并进行归一化。这样,具有相似特征的工作单位将在归一化后的向量空间中更接近,具体可以通过以下步骤实现:
1) 收集工作单位数据集,包含工作单位的文本和嵌入模型转换的向量值。
2) 使用相似度度量方法(如余弦相似度、欧氏距离等)计算工作单位之间的相似度。
3) 使用聚类算法(如K-means、层次聚类等)将相似的工作单位聚集在一起形成不同的类别,这样相似的工作单位将被归为同一类别。
4) 归一化聚类中的嵌入向量,计算每个类别中所有样本的均值向量,并将其他样本的嵌入向量映射到该均值向量[4]。
3 训练设计和实验结果分析
3.1 训练集设计
本次准备5万件案件卷宗原始数据,仅含有起诉书和判决书等诉讼文书卷制式文书,核算每个案件的信访风险评估评分值作为目标参数输出。风险评估评分值标准分50分,分值越高,风险越大。去除极端目标值后,5万件案件的最终评分大体分布在47到52 之间,超过49.5分即可视为有发生信访风险。计算方式大致如下:
1) 5万件样本数据中有3 500件涉访,风险评估评分值默认加1分。
2) 信访数据中含类型、信访人数和方式等再次加权增加0.1~1分评分值。
3) 案件数据也根据是否未上诉、是否有认罪认罚具结书、是否简易程序、是否为缓刑等加权降低风险评估评分值。
选用评分这种线性目标值而非风险等级分类,是基于历史测试数据的考量。在实际情况中,信访风险评估的正例,即真实发生信访的案件比例,通常低于5%,这意味着训练集失衡,多分类预测的中高风险等级召回率和F1值都非常低,且很难提升。尤其在特征值基于灵活自动抽取的训练模式下,优先关注的应该是特征参数的选取和迭代,线性目标值更适合作为模型评价。
3.2 特征工程
特征工程设计有多轮对比,因此信息提取的模型选用RexUniNLU-base。模型体积较小,在抽取任务中对比RexUIE能力损失有限,推理速度则有很大优势。由于本研究一个重要目标就是灵活调整特征数量和意义,推理速度更重要。特征值通过Prompt的提示词灵活选取,优先选取数据集中办案环节早期诉讼文书提取特征参数,使模型在办案环节早期就具备预测条件,及时得到评估结果,辅助办案人员消除后续信访隐患。
1) 特征值:涵盖罪名、嫌疑人和被害人的性别、年龄、绰号、户籍地、作案地、工作单位、受教育程度、职业、身份、强制措施(羁押/取保候审)、婚否、作案经过(事件抽取)、领域(文本分类)、前科、扣押款物、审查结论[5]。本次准备四组,分别为16、18、20、22个,四组特征差异主要是在文书中提取出来的一些法定和酌定情节,如自首、被害人有过错、积极赔偿、弱势群体等。
2) 向量化:特征参数向量化选用的文本嵌入模型是bge-large-zh-v1.5,对比几个向量化的模型在相似度分析中表现基本雷同,选此模型的主要原因还是效率较高。
3) 相似度:以工作单位特征参数为例,任意两个工作单位之间都使用向量计算余弦相似度,构建相似度矩阵,使用K-means聚类算法设置类族数目,将相似的工作单位聚集到一起形成不同的类族。如图1所展示,12个工作单位基于相互之间的文本相似度自动被聚类为4组,大体拟合了企业、行政、政法、金融四组,有较高的现实还原度。
4) 归一化:对于每个聚类中的工作单位,可以计算该聚类中所有样本的均值向量,并将其他样本的嵌入向量映射到该均值向量。
3.3 训练和预测
数据集划分:X是输入层特征数据,Y为目标变量风险评估评分值,数据集分层随机选取70% 为训练集,剩余30% 为测试集,设定随机数种子,确保多轮训练和评估时随机结果可重复性。
全连接神经网络:使用Keras框架构建神经网络,选用Adm优化器,均方差损失函数。输入层设置30 个神经元,ReLU激活函数,16~22个输入特征数量。4 个隐藏层,ReLU激活函数,神经元数量分别是40、20、10和5。输出层只有1个神经元,线性激活函数。
3.4 评估指标
均方误差MSE:计算预测评分值与真实评分值之间的平均平方差。平均绝对误差MAE:计算预测评分值与真实评分值之间的平均绝对差。与MSE不同,对异常值更加鲁棒。R平方:度量了线性模型对评分值变异性的解释能力。Loss曲线:训练过程中每个ep?och的损失值随时间的变化,评估收敛情况。
3.5 实验结果
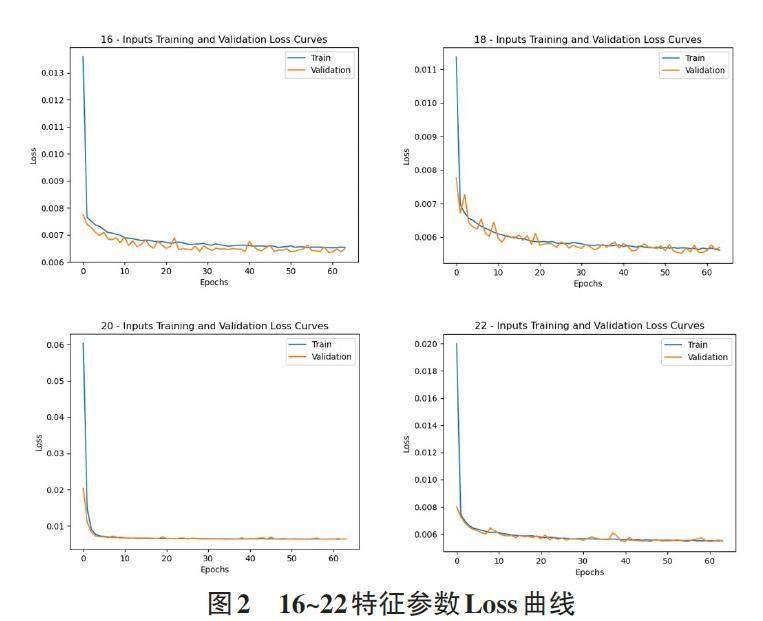
分4次训练,输入层分别为16、18、20、22个特征参数,结果如图2所示。
图2显示,模型在训练集和验证集上的损失和平均绝对误差都较小,说明模型在这些指标上表现良好。表1显示,均方误差和平均绝对误差的值也较小,模型的预测结果与实际值相对接近。22特征输入时,R平方的值为0.724 4,说明模型可以解释目标变量约72.4% 的变异性,这也表示模型的预测能力较好。
3.6 动态调整特征数量和意义的影响分析
上述4种特征组合的评估结果表明,提升特征参数数目可以提升模型质量,从Loss曲线可以看到训练和验证曲线比较符合,20特征参数时Loss值有升高,说明20特征选取训练收敛力度不够。对应的评估指标也可以看出,20特征反而比18特征表现要差些,这也更加说明动态调整特征数量在训练中的重要性,通过Prompt辅助快速组织特征参数的研究有很大意义。
4 结束语
基于Prompt和文本嵌入提取卷宗特征,降低了人工依赖,提高了特征提取的效率。相似度归一使得筛选过程更加灵活,多轮训练对比评估使得筛选过程更加客观。更丰富的特征参数可以提供更多有用的信息,从而改善模型的预测能力。后续会继续扩展应用,将文本提取模型、文本嵌入模型和预测模型混合拼接成一个完整的mix模型,输入卷宗+Prompt提示词直接输出预测结果,并对整个模型进行训练和优化。这种文本特征提取和相似度归一化的方法在多个领域都具有广泛的应用前景。
参考文献:
[1] 安震威,来雨轩,冯岩松. 面向法律文书的自然语言理解[J]. 中文信息学报,2022,36(8):1-11.
[2] 刘晓蒙,单清龙,周萌枝,等. 基于涉诉信访案件风险识别的知识元自动抽取技术[J]. 法制博览,2021(19):19-21.
[3] 刘栋,杨辉,姬少培,等. 基于多模型加权组合的文本相似度计算模型[J]. 计算机工程,2023,49(10):97-104.
[4] 王有华. 基于归一化压缩距离的文本谱聚类算法研究[D]. 贵阳:贵州大学,2016.
[5] 董红松. 司法诉讼案件文本挖掘若干关键技术研究[D]. 太原:中北大学,2021.
【通联编辑:代影】
猜你喜欢
现代营销·学苑版(2016年10期)2016-12-12 14:52:44
合作经济与科技(2016年24期)2016-12-07 02:39:46
时代金融(2016年27期)2016-11-25 16:27:13
人间(2016年24期)2016-11-23 19:17:33
电子技术与软件工程(2016年18期)2016-11-14 01:43:44
电子技术与软件工程(2016年18期)2016-11-14 01:40:31
价值工程(2016年29期)2016-11-14 00:22:34
企业技术开发·中旬刊(2016年10期)2016-11-12 17:10:23
时代金融(2016年23期)2016-10-31 13:25:28
中国科技博览(2016年19期)2016-10-19 12:32:12
