
面向动态学习环境的自适应学习路径推荐模型
2024-06-09 07:19:05范云霞杜佳慧张杰庄自超龙陶陶童名文
电化教育研究 2024年6期
范云霞 杜佳慧 张杰 庄自超 龙陶陶 童名文

基金项目:国家自然科学基金2023年青年项目“基于认知过程挖掘的教师实践性知识演进机制研究”(项目编号:62307017);2021年华中师范大学国家教师发展协同创新实验基地建设研究项目“自适应教师培训资源设计与开发”(项目编号:CCNUTEIII 2021-04)
[摘 要] 自适应学习路径作为实现个性化学习的一项关键技术,受到研究者广泛关注。近年来,强化学习成为自适应学习路径推荐的主流方法,但在动态学习环境表征的完整性和学习路径的适应性方面仍存在不足。基于此,文章提出了融合领域知识特征的自适应学习路径推荐模型。首先,模型将知识点概念覆盖和难度两个特征引入动态学习环境中,使对动态学习环境的表征更完整。其次,采用深度强化学习算法实现学习路径的推荐,提升学习路径的适应性。最后,开展技术对比实验和应用实验。技术对比实验表明,该模型提高了学习路径的有效性和适应性。应用实验表明,该模型可以准确地判断学习者的薄弱知识点概念,并能为学习者推荐适合其认知特征的自适应学习路径。
[关键词] 自适应学习路径; 强化学习; 领域知识特征; 知识点概念覆盖; 个性化学习
[中图分类号] G434 [文献标志码] A
[作者简介] 范云霞(1992—),女,山西长治人。博士研究生,主要从事自适应学习理论与方法研究。E-mail:1134527434@qq.com。童名文为通讯作者,E-mail:tmw@ccnu.edu.cn。
一、引 言
近年来,规模化的个性化教育成了新时代的教育理想和诉求[1]。自适应学习作为实现规模化的个性化教育的重要途径,引起了研究者的广泛关注。学习路径推荐是自适应学习的一项关键技术,能够帮助学习者实现认知状态与学习对象的精准匹配[2],提高学习者的学习效率和满意度[3]。自适应学习路径作为学习路径的一种类型,可根据学习过程中学习环境的变化实时地调整学习路径。关于自适应学习路径推荐的研究逐步由“半动态”向“动态”发展[4],其中,基于强化学习的自适应路径推荐成为动态路径推荐的一种重要方法[5]。但是现有研究多为强化学习的简单迁移,缺乏对复杂真实学习情境的分析和建模,具体表现在:(1)动态学习环境表征不完整;(2)学习路径适应性不强。有研究表明:在领域知识特征中,对下一题知识点概念覆盖预测可以准确定位学习者的薄弱知识点[6]。对学习对象难度值的动态追踪可以实现高适应性的推荐[7]。因此,本研究基于强化学习框架提出了一种融合领域知识特征的自适应学习路径推荐模型(Adaptive Learning Path Recommendation Model,ALPRM),该模型将知识点概念覆盖和难度两个核心特征融入动态学习环境表征,然后对强化学习模型的核心组件进行重新设计,旨在推荐主动适应学习环境动态变化的学习路径。
二、相关研究
学习路径是指利用学习者特征、领域知识特征等信息,为学习者定制的符合教育认知规律、能实现其既定学习目标的最优学习单元序列[8]。自适应学习路径是学习路径的一种类型,它是根据学习环境的变化,可动态调整的学习路径。经典的学习路径只关注推荐结果的个性化,具有静态性,而自适应学习路径注重学习路径在学习过程中的调整,具有动态性。近年来,关于学习路径推荐的研究主要集中在自适应学习路径推荐。自适应学习路径推荐研究主要包括动态学习环境表征和自适应学习路径推荐技术两个方向。
(一)动态学习环境表征研究
在动态学习环境表征研究中,主要是对学习者个性特征和领域知识特征进行提取与计算[9]。学习者个性特征分为 “为什么学”的特征、“学什么”的特征、“怎样学”的特征[10]。“为什么学”的特征是说明学习者学习目的特征,用于设计和规划学习过程,一般可以从学习环境中直接获取,属于显性特征,如学习目标、职业目标和学习动机。“学什么”的特征是说明系统给学习者推荐的路径节点需要依据的特征,是以往研究中挖掘最多的隐形特征,如学习能力、认知状态和理解水平等。“怎样学”的特征是说明为学习者推荐什么资源类型的特征,如学习风格、学习偏好。领域知识特征分为静态特征和动态特征。静态特征是指与推荐相关的,并且在学习推荐过程中特征值不发生改变的特征,如学习对象的描述性特征(学习对象格式类型、媒体格式、交互方式、知识粒度、所属章节、涉及知识点概念)。而动态特征是指在学习推荐过程中特征值发生改变的特征(如难度),常用来实现学习对象的动态分类和交互信息的动态更新[9]。动态学习环境表征更多关注的是学习者特征中的“学什么”的特征和领域知识特征中的动态特征。
(二)自适应学习路径推荐技术研究
在自适应学习路径推荐技术研究中,已有推荐技术呈现出“半动态路径推荐”和“动态路径推荐”两种类型。“半动态路径推荐”是根据初始的学习环境信息,为学习者推荐一条完整的路径,并且在整个学习过程中学习环境变量值保持不变,这类研究大多先用聚类、K近邻或决策树等技术对学习者个性特征进行聚类并初始化环境信息,然后再利用广度优先搜索[11]、关联规则[12]或长短期记忆网络(Long-Short Term Memory,LSTM)[13]等算法推荐学习路径。“动态路径推荐”是多阶段为学习者推荐自适应学习路径,学习环境变量会随学习过程的进行而动态变化,实现“一步又一步”的推荐,这类研究主要使用强化学习算法实现。
(三)基于强化学习的自适应学习路径推荐技术研究
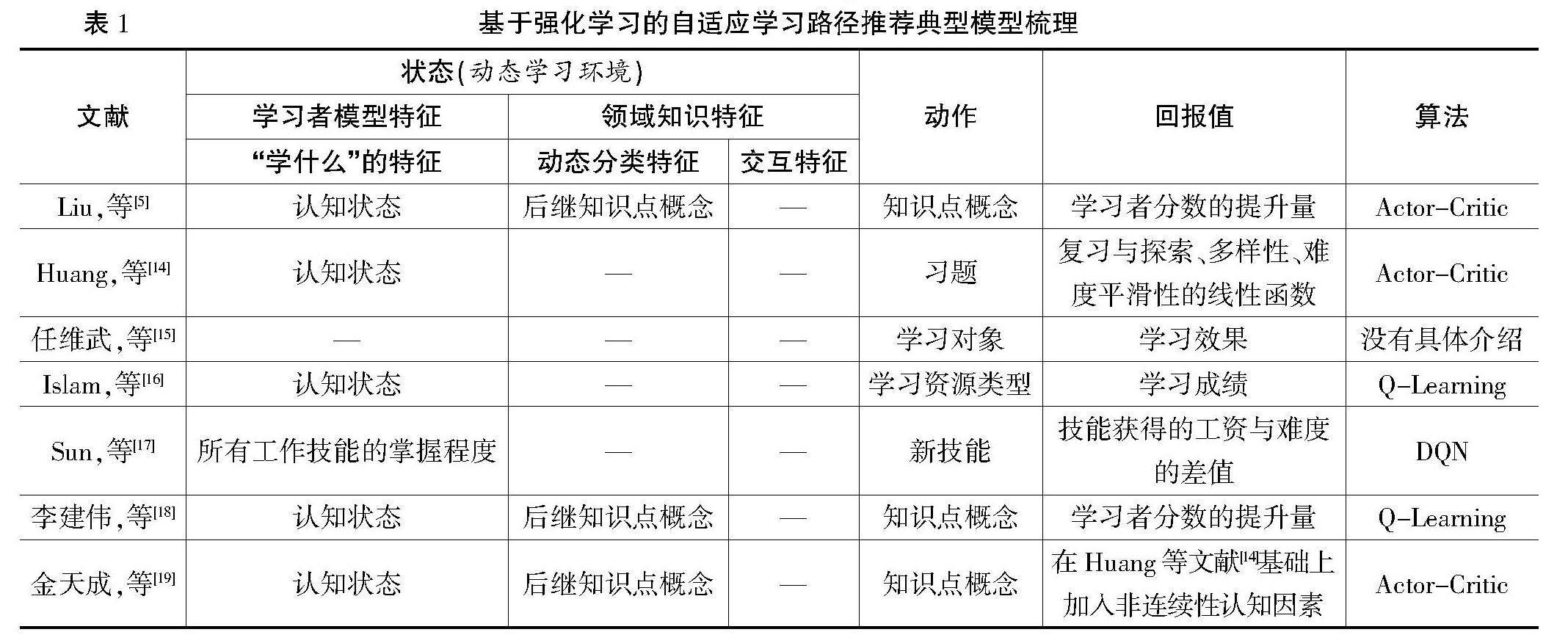
目前,强化学习已经成为实现自适应学习路径推荐的主流方法,研究者普遍将自适应学习路径推荐问题建模为最优化問题,将推荐过程视为马尔可夫决策过程(Markov Decision Processes,MDP),结合教育情境对强化学习的核心组件(状态、动作、回报值)重新定义来实现推荐过程[5]。表1为基于强化学习的自适应学习路径推荐典型模型梳理。现有研究在“状态”的定义方面,研究者通常将动态学习环境定义为强化学习的状态,最多的表征特征是学习者模型中的认知状态特征,少数研究使用了领域知识特征,但只考虑使用后继知识点概念来定位知识点,这种方式只能促使学习者学习新的知识点概念,无法捕捉到真正薄弱的知识点概念。此外,现有研究忽略了领域知识的交互特征,这也是影响学习对象推荐准确性的一个重要原因。在“回报值”的定义方面,现有研究的设计思想有固定回报值设计、多元线性函数设计、直接使用学习成绩(或提高程度)作为回报值等。此外,现有研究中常用的强化学习算法有Q-Learning、Actor-Critic、DQN等。
综上所述,强化学习算法在自适应学习路径推荐领域已取得丰富的研究成果,但还存在以下问题:(1)动态学习环境的表征不完整,突出表现在没有严格分析领域知识的动态特征。(2)学习路径适应性不强,表现在无法准确定位薄弱知识点概念,学习对象推荐的准确性不高。本研究提出融合领域知识特征的ALPRM,并对相关算法进行实现,以期解决上述问题。
三、融合领域知识特征的自适应
学习路径推荐模型构建
(一)自适应学习路径推荐模型构建
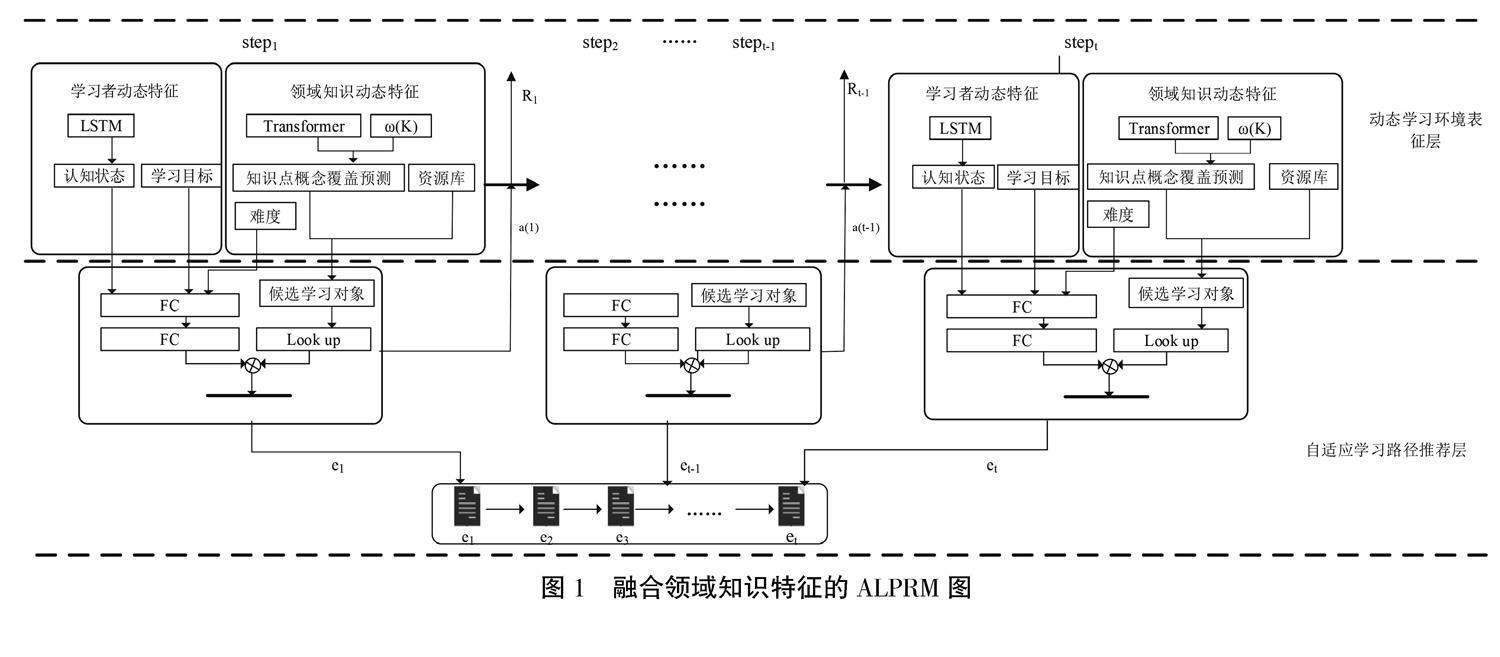
本研究基于强化学习框架构建了如图1所示的ALPRM图。该模型由动态学习环境表征和自适应学习路径推荐两层组成。(1)在动态学习环境表征层,提取学习者个性特征和领域知识特征中的核心动态特征来表征动态学习环境。具体来说,由学习者认知状态、学习目标、知识点概念覆盖、难度共同表征。学习者认知状态可以实时追踪学习者知识点概念掌握情况;学习目标可以指明自适应学习路径的方向;知识点概念覆盖预测不仅可以帮助学习者定位薄弱知识点概念,还能根据这些预测的知识点概念从资源库中检索候选学习对象,减少智能体的搜索空间;难度的动态表征可以更准确地获取同一学习对象在学习者不同学习状态时的难度水平。这样的表征方式使自适应学习环境表征更完整。(2)在自适应学習路径推荐层,对MDP的主要组件进行重新定义,将“状态”定义为动态学习环境的表征模型,将“动作空间”定义为候选学习对象,将“回报值”定义为有关难度特征的函数。利用动态环境特征变量训练深度强化学习的策略网络,最后根据训练好的模型为学习者推荐最符合其当前学习状态的学习对象,这样的设计旨在实现自适应学习路径推荐的动态性,同时也提高适应性。
(二)动态学习环境的表征与计算
1. 动态学习环境的表征
在动态学习环境表征方面,已有研究通常由学习者的认知状态表征,本研究在此基础上加入学习目标特征和领域知识特征,将动态学习环境表征为Statet=[et,Target,p(Kt),p'(Kt),Dift],Statet具体的描述为:et表示当前学习对象;Target为目标知识点概念,学习目标可以由教师制定,也可以由学习者在学习开始前根据自己的情况自由决定;p(Kt)为t时刻学习者的认知状态;p'(Kt)为t时刻预测的下一步知识点概念覆盖;Dift为学习对象的难度值。这些特征中,et值可以从学习环境直接获取,无需计算;Target可以在学习开始时根据学习者的输入得到;而p(Kt)、p'(Kt)和Dift这些特征值则需要专门的计算机算法的精确评估才能获得。
2. 动态学习环境特征值的计算
近年来,深度神经网络在处理非线性建模、自适应学习、大规模数据、端到端的自动化预测等领域表现出非常优秀的预测性能[20]。本研究也使用深度神经网络算法来对动态学习环境的特征值进行计算,利用LSTM模型预测学习者认知状态;使用Transformer模型预测下一题知识点概念覆盖情况;根据学习者的认知状态计算出学习对象的动态难度值。
为了详细说明,本研究以习题推荐为例,假设了一些变量。假设有一门C课程共包含K个知识点概念,表示为K=k1,k2,…,k■。学习者表示为S=s■1,s■2,s■3,…,s■,习题库表示为EB=e1(k),e2(k),…,e■(k),习题表示为ej(k)=[e■(k1),ej(k2),ej(k3)…,ej(k■)], e■(ki)的取值为0或1(0表示该题没有包含第i个知识点概念,1表示该题包含了第i个知识点概念)。将某学习者s■i的历史答题记录表示为X■=x1■,x2,x3,…,x■,t时刻学习者s■i对习题ej的作答情况表示为x■=(s■,e■(k),a■t)|s■∈S,e■(k)∈EB。
(1)认知状态的计算
本研究使用LSTM模型来预测学习者的知识概念掌握情况,追踪他们的认知状态。LSTM模型的输入为x■=(s■,e■(k),a■t)|s■∈S,e■(k)∈EB,习题e■的知识点概念的单热编码用?准(Kt)表示,at的取值为0或1(0和1分别表示作答错误和正确)。模型的输出ht是一个向量,其长度等于K的长度,它的每个组成部分代表正确回答相应的知识点概念的概率。本研究通过二元交叉熵构建一个损失函数来训练这个模型,对于单个学习者的优化损失函数表示为:
Ls=∑■■l■(ht·?准(K■t),at+1) 式(1)
其中,·表示点乘,l■表示二元交叉熵损失。
当LSTM模型训练结束后,输入一个学习者的历史答题记录,该模型的输出就是他对这门课程所有知识点概念的掌握程度,表示为p(Kt)=[p(k■■),p(k■■),p(k■■),…,p(k■■)]。
(2)知识点概念覆盖预测的计算
本研究使用Transformer模型来预测知识点概念覆盖,以准确定位学习者下一步应该学习的知识点概念。利用Transformer模型,编码器将某学习者的习题Et、知识点概念Kt和位置Pt作为模型的输入,因为Transformer是基于自注意机制的深度学习模型,不能像循环神经网络和卷积神经网络那样有效利用历史记录中的序列信息。因此,本研究在Transformer模型的输入中嵌入位置编码,以表征历史学习记录中的顺序信息,模型的输入表示为:
ε(t)=Eet,kt+Pt 式(2)
其中,Eet,kt是连接Et和Kt的嵌入向量,Pt 表示位置嵌入。
Transformer模型利用解码器来预测下一题的知识点概念覆盖。解码器通过自注意机制连接到编码器,最后通过全神经网络得到模型的输出vt。在训练时刻t,vt表示课程中所有知識点概念出现的概率,即Kt+1。该模型通过最小化损失函数L's训练模型,损失函数表示为:
L'■=∑■■l■(vt·?准(kt+1),1) 式(3)
当Transformer模型训练结束后,输入一个学习者的习题记录,该模型的输出为这门课程中所有知识点概念出现的概率,表示为C(Kt)=[c(k■■),c(k■■),c(k■■),…,c(k■■)]。为了提高学习者的学习热情,需要分析所推荐的知识点概念不仅要包括学习者在学习过程中的薄弱知识点概念,也要考虑必须学习的新的知识点概念。因此,在Transformer模型的输出添加一个权值变量,它的长度等于知识点概念的长度,表示为ω(Kt)=[ω(k■■),ω(k■■),ω(k■■),…,ω(k■■]。ω(k■■)的计算如下:
ω(k■■)=1-■,c■>01, c■=0 式(4)
其中,r■为知识点概念k■正确回答的次数,c■为k■出现的次数。利用 p'(Kt)=c(K■■)ω(K■■),最终求出下一题的知识点概念覆盖为p'(Kt)=[p'(k■■),p'(k■■),p'(k■■),…,p'(k■■]。
(3)难度特征的计算
难度是知识项目的重要特征之一,是习题推荐过程中需要考虑的核心因素。现有工作大多是通过研究人员预设习题难度,在学习过程中习题难度值保持恒定。然而,在实际情况下,这种方案会导致学习者的认知偏差。已有研究表明,习题难度是随着知识建构过程动态演变的[21-22]。因此,本研究将该特征整合到动态环境的表征中。受Wu等人[6]研究的启发,利用公式(5)和公式(6)来计算习题的难度。
Re(K)=∏■■(p(k■■)丨e(k■)=1) 式(5)
Re(K)为习题答对的概率,p(k■■)为习题中每个知识点概念的掌握程度。因为学习者的认知状态在动态变化,所有习题答对的概率也在时刻变化。
Dift=1-Re(K) 式(6)
Dift为t时刻习题难度值。
(三)深度强化学习推荐算法
1. MDP组件的定义
MDP主要组件包括:状态、动作和回报值,在本文中的定义如下:
状态(State):本研究将动态学习环境视为MDP的状态,表征为Statet=[et,Target,p(Kt),p'(Kt),Dift]。
动作(Action):策略网络为一个提前训练好的神经网络模型,该模型接受学习环境状态Statet,根据已经保存好的模型参数θ,从动作空间Ct中采样,预测并输出与当前学习环境适应度最高的习题,最后将学习环境更新为Statet'。因为习题库中习题规模巨大、课程知识点概念覆盖广、难度多样,这为智能体的搜索带来巨大挑战。本研究从动态学习环境中获得下一步预测的知识点概念覆盖,从习题库中检索出相关习题,形成候选习题集Ct,计算公式如下:
C■=e■(k■)|e■∈EB,k■∈p'(Kt■) 式(7)
其中,e■(k■)为t时刻的候选习题,j为习题的数量,p'(Kt)为上文中预测的知识概念覆盖。
回报值(Reward):参考Liu等人[5]的研究,本研究设计回报值并对其进行改进。Liu等人只在自适应学习路径完成时给予奖励,这种延迟、稀疏的奖励机制会导致智能体在早期探索阶段盲目选择,表现不稳定。本研究受奖励塑造思想的启发[23],完善了回报值的计算方法,在智能体探索的每一步和探索结束后都给予一定的奖励,在保证整条自适应学习路径有效性的同时,也提高智能体在探索阶段的稳定性,回报值函数设计如下:
R■=α*R■+β*R■丨α,β∈0,1R■=1-δ-Dif■ 式(8)
其中,R■为Liu等人[5]研究中回报值的设计函数,R■为每一步给予的回报值。在智能体探索的早期阶段,本研究设置α=1,β=0,则R■=R■,表示智能体在探索的每一步获得的回报值。其中,δ为学习者期望的习题难度,Dif■为候选集中习题的难度,δ-Dif■值越小时,该习题为最符合学习者需求的习题。当智能体完成探索,本研究设置α=0,β=1,则R■=R■,表示智能体到达目标知识点概念获得的整条自适应学习路径的回报值。
2. 推荐算法描述
本研究在对每个组件进行重新定义后,仍然存在一个问题,就是如何根据学习者当前的动态学习环境来选择候选习题进行学习。为了解决这个问题,我们使用D3QN算法来实现习题推荐功能,该算法具有简单、泛用、没有使用禁忌等特点。D3QN算法设置两个Q网络(评估网络Q和目标网络Q')作為参与者,即利用评估网络Q获取Statet+1状态下最大回报值对应的习题,然后利用目标网络Q'计算该习题获得的真实回报值,从而得到目标值。通过两个网络的交互,有效避免了算法的“过估计”问题。其中,θ和θ'分别表示评估网络和目标网络的参数。目标值的计算如下:
yt=Rt+1+γQ'(Statet+1,arg maxaQ(Statet+1,a,θ),θ')
式(9)
其中,arg maxaQ(Statet+1,a,θ)表示Statet+1状态下评估网络Q根据其参数θ选择回报值最大的习题,这个习题选择的动作再次经过目标网络Q'计算获得最终的真实回报值yt。在计算出yt的基础上,使用均方差损失函数,计算Loss,再通过反向传播更新参数θ。公式如下:
Loss=■∑■■(yt-Q(Statet,Ct,θ))2 式(10)
经过算法多次迭代运行,策略网络就会训练完成。当上文构建的动态学习环境模型中的所有变量输入神经网络后,就可以输出相对应的习题。
四、自适应学习路径推荐模型的实验研究
(一)实验对象
为了评估ALPRM,本研究在一个公共数据集和一个真实数据集上开展了实验,进行性能验证。ASSISTments2009数据集来自ASSISTments网站,本研究筛选该数据集中的初中数学代数部分进行实验,去除没有知识点概念和学习者记录少于10条的记录,得出65,372条数据。自适应学习系统数据集是一个真实的数据集,该系统由本团队自主开发。本研究选择系统中“C程序设计”课程的前三章节的数据开展实验。该系统至少包含一个知识点概念,所以只去除学习者记录少于10条的记录,得出94,886条数据。表2为两个数据集数据清理后的信息统计情况。
表2 两个数据集的统计信息
(二)实验设置
本研究选取最先进的自适应学习路径推荐框架进行对比,分别是认知结构增强模型(CSEAL)[5]、基于知识点概念覆盖预测模型(KCP-ER)[6]、双层多目标推荐模型(MulOER-SAN)[24]。基线模型中涉及的深度学习算法的参数设置与原文相同。本研究中的LSTM模型的参数设置参考Wu等人[6]的研究,Transformer模型的参数设置参考Ren等人[24]的研究,D3QN中explore采用EpsilonGreedy,初始epsilon为1,最终epsilon设置为0.02,epsilon time steps设置成5000,激活函数使用Relu,隐藏层为[256,256], γ设置为0.99,学习率为5e-4,其他参数为默认参数,获取环境状态值进行训练。本研究随机选择其中80%的数据作为训练集、10%为验证集、10%为测试集以开展实验。
(三)实验指标
参考已有研究,本研究采用有效性[5]、适应性[24]指标来评价产生的自适应学习路径的质量。
1. 有效性
有效性用来评估学习者在一个会话中学习成绩的提升情况,定义如公式(11)所示:
Ep(LP)=■ 式(11)
在一个会话中,Es是开始的分数,Ee是结束的分数,Esup是总分数。Ep(LP)值越大代表推荐的有效性越好;值越小代表自适应学习路径的有效性越差。
2. 适应性
适应性反映了每一次推荐的习题是否具有适当的难度水平。Ren等提出适应性的计算公式(12)[24]:
Adaptiviy(LP)=■ 式(12)
δ为学习者对习题的期望难度,Dif■为所选习题的难度,δ-Dif■表示学习者期望选择的习题与真实选择的习题的难度距离,1-δ-Dif■表示每次选择习题的适应性,M为自适应学习路径中习题的个数, Adaptiviy(LP)表示推荐的整条学习路径的适应性。
(四)实验结果分析
表3展示了两个数据集中各模型在有效性和适应性两个指标上的表现效果。通过观察可以发现:(1)在所有基线中,采用CSEAL模型推荐的自适应学习路径表现最差。经过分析发现,CSEAL模型通过知识图谱中当前知识点概念的后继知识点概念直接获取习题候选集,而不是采用知识点概念覆盖预测的方式获取,也没有考虑习题难度特征,这些因素可能是导致推荐效果较差的原因。(2)MulOER-SAN的各项指标都比KCP-ER好,这与Ren等人[24]的研究结果相同。(3)在有效性和适应性两个方面,ALPRM比所有基线的表现都好。
总之,技术对比实验表明,融入领域知识特征的动态学习环境表征,使基于强化学习算法的自适应学习路径推荐质量更高,表现出较优的性能。
表3 所有模型的实验结果对比
五、自适应学习路径推荐模型的应用研究
(一)实验设计
为了验证ALPRM的应用效果,本研究将模型中涉及的算法嵌入本团队自主开发的自适应学习系统中。以太原市某高校软件工程专业的3个班级(实验一班50人,实验二班51人,对照班51人)的大一新生为实验对象,这些新生都没有学习C语言的经历。以“C程序设计”的前三章内容为教学内容,共持续6周,采用课上同一位教师讲授,课下学习者使用自适应学习系统进行练习的教学模式。实验一班的学习者使用基于ALPRM的系统推荐习题,实验二班的学习者使用基于MulOER-SAN的系统推荐习题,对照班的学习者根据知识点概念自己选择习题进行练习。学习6周后,3个班的学习者都参加1小时的小型测试。
(二)实验结果分析
1. 整体学习成绩分析
图2 3个班级学习者学习成绩总体分布箱线图
因为3个班的学习者都没有学习C语言的经历,本研究认为实验前学习者的学习成绩并无显著差异。图2为3个班级学习者学习成绩总体分布箱线图,展示了全班学习者考试成绩的总体数据分布情况。从中值来看,实验一班为86分,实验二班为81分,对照班为77分,实验一班的学习者的总体成绩优于其他两个班;从IQR(箱体的长度)来看,实验一班的成绩分布范围较大,意味着该班学习者的成绩差异较大。实验二班和对照班的成绩分布相对集中,说明这两个班的学习者成绩比较集中。从离群点来看,实验一班没有观察到异常值,实验二班和对照班存在较多的低离群点。从箱线图的中值、IQR和离群点指标可以看出,与其他两个班相比,实验一班的整体学习成绩更好。
2. 案例分析
本研究还随机选取实验一班的一名学习者的自适应学习路径进行了案例分析,该学习者的学习趋势如图3所示。在图3中,横轴(x轴)表示习题推荐的路径,纵轴(y轴)表示准确率,空心点表示所有在系统中回答了这个习题的学习者的平均准确率,实心点表示该生在每个习题的作答情况,若回答正确,则y=1;若回答错误,则y=0。从图中可以看到:(1)从空心点的变化趋势来看,系统为学习者推荐的习题准确率大致呈现波浪式,当该生就某习题回答错误时,系统为学习者推荐准确率较高的习题,当学习者就某习题回答正确时,系统为学习者推荐的习题的准确率越来越低,这一可视化结果表明,系统可以根据学习者的作答情况,为学习者推荐准确率恰当的习题,即难度恰当的习题。(2)当某习题的平均准确率较高,学习者却作答错误时,系统会再次为其推荐准确率相当的习题。若第二次回答依然錯误,说明该习题是该生的薄弱知识点概念;若两次都回答正确,则前一次错误可能是失误等原因导致。(3)当某习题的平均准确率较低,学习者作答错误,则该题可能是学习者的难点。
总之,从学习者的自适应学习路径案例分析来看,基于ALPRM的系统推荐习题能够定位薄弱知识点概念,诊断学习难点,并能够为学习者推荐恰当难度的习题。
图3 自适应学习路径案例分析图
六、结 语
本研究提出了一种融合领域知识特征的自适应学习路径推荐新模型,以解决利用强化学习推荐自适应学习路径的研究中存在的动态学习环境表征不完整和推荐适应性不强等问题。具体来说,第一,将知识点概念覆盖和难度两个特征引入动态学习环境的建模中,然后利用深度学习算法计算动态学习环境的特征值。第二,对强化学习的各组件进行重新设计,并实现推荐。第三,对提出的新模型在实验室环境和真实课堂开展实验。实验室环境中的技术对比实验证明,该模型有较好的有效性和适应性。真实课堂应用实验表明,该模型能够准确定位薄弱知识点,可以推荐难度恰当的习题。本研究也存在一些不足,如在应用实验中,没有收集学习者的学习体验数据,无法感知学习者在学习过程中的感受。未来,相关研究将继续开展,进一步观察学习者在自适应学习路径推荐过程中学习动机、满意度等方面的变化。
[参考文献]
[1] 王磊.基于大数据的精准教学干预模型及应用研究[D].武汉:华中师范大学,2022.
[2] 熊余,张健,王盈,等.基于深度学习的演化知识追踪模型[J].电化教育研究,2022,43(11):23-30.
[3] 钟卓,钟绍春,唐烨伟.人工智能支持下的智慧学习模型构建研究[J].电化教育研究,2021,42(12):71-78,85.
[4] 云岳,代欢,张育培,等.个性化学习路径推荐综述[J].软件学报,2022,33(12):4590-4615.
[5] LIU Q, TONG S W, LIU C R, et al. Exploiting cognitive structure for adaptive learning[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM, 2019: 627-635.
[6] WU Z Y, LI M, TANG Y, et al. Exercise recommendation based on knowledge concept prediction[J]. Knowledge-based systems, 2020, 210: 106481.
[7] JOSEPH L, ABRAHAM S, MANI B P, et al. Exploring the effectiveness of learning path recommendation based on Felder-Silverman learning style model: a learning analytics intervention approach[J]. Journal of educational computing research, 2022, 60(6): 1464-1489.
[8] 高嘉骐,刘千慧,黄文彬.基于知识图谱的学习路径自动生成研究[J].现代教育技术,2021,31(7):88-96.
[9] 吴正洋,汤庸,刘海.个性化学习推荐研究综述[J].计算机科学与探索,2022,16(1):21-40.
[10] NABIZADEH A H, LEAL J P, RAFSANJANI H N, et al. Learning path personalization and recommendation methods: a survey of the state-of-the-art[J]. Expert systems with applications, 2020,159:113596.
[11] SHI D Q, WANG T, XING H, et al. A learning path recommendation model based on a multidimensional knowledge graph framework for e-learning[J]. Knowledge-based systems, 2020,195:105618.
[12] 姜强,赵蔚,李松,王朋娇.大数据背景下的精准个性化学习路径挖掘研究——基于AprioriAll的群体行为分析[J].电化教育研究,2018,39(2):45-52.
[13] ZHOU Y W, HUANG C Q, HU Q T, et al. Personalized learning full-path recommendation model based on LSTM neural networks[J]. Information sciences, 2018,444:135-152.
[14] HUANG Z Y, LIU Q, ZHAI C X, et al. Exploring multi-objective exercise recommendations in online education systems[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM,2019:1261-1270.
[15] 任维武,郑方林,底晓强.基于强化学习的自适应学习路径生成機制研究[J].现代远距离教育,2020(6):88-96.
[16] ISLAM M Z, ALI R, HAIDER A, et al. Pakes: a reinforcement learning-based personalized adaptability knowledge extraction strategy for adaptive learning systems[J]. IEEE access, 2021,9:155123-155137.
[17] SUN Y, ZHUANG F Z, ZHU H S, et al. Cost-effective and interpretable job skill recommendation with deep reinforcement learning[C]//Proceedings of the Web Conference 2021. New York: ACM, 2021:3827-3838.
[18] 李建伟,武佳惠,姬艳丽.面向自适应学习的个性化学习路径推荐[J].现代教育技术,2023,33(1):108-117.
[19] 金天成,窦亮,肖春芸,等.记忆与认知融合的个性化OJ习题推荐方法[J].计算机学报,2023,46(1):103-124.
[20] LIN Y G, FENG S B, LIN F, et al. Adaptive course recommendation in MOOCs[J]. Knowledge-based systems, 2021,224:107085.
[21] GAN W B, SUN Y, SUN Y. Knowledge interaction enhanced sequential modeling for interpretable learner knowledge diagnosis in intelligent tutoring systems[J]. Neurocomputing, 2022,488:36-53.
[22] GAN W B, SUN Y, PENG X, et al. Modeling learner's dynamic knowledge construction procedure and cognitive item difficulty for knowledge tracing[J]. Applied intelligence, 2020,50:3894-3912.
[23] ZHANG Q X, WENG X Y, ZHOU G Y, et al. ARL: an adaptive reinforcement learning framework for complex question answering over knowledge base[J]. Information processing & management, 2022,59(3):102933
[24] REN Y M, LIANG K, SHANG Y H, et al. MulOER-SAN: 2-layer multi-objective framework for exercise recommendation with self-attention networks[J]. Knowledge-based systems, 2023,260:110117.
Adaptive Learning Path Recommendation Model for Dynamic Learning Environments
FAN Yunxia1, DU Jiahui2, ZHANG Jie3, ZHUANG Zichao1, LONG Taotao1, TONG Mingwen1
(1.Faculty of Artificial Intelligence in Education, Central China Normal University, Wuhan Hubei 430079; 2.School of Information Engineering, Shanxi College of Applied Science and Technology, Taiyuan Shanxi 030000; 3.School of Computer Science and Engineering, Hunan University of Information Technology, Changsha Hunan 410000)
[Abstract] Adaptive learning path, as a key technology to realize personalized learning, has received extensive attention from researchers. In recent years, reinforcement learning has become the mainstream method for adaptive learning path recommendation, but there are still deficiencies in the completeness of dynamic learning environment representation and the adaptability of learning path. Based on this, this paper proposes an adaptive learning path recommendation model that incorporates domain knowledge characteristics. Firstly, the model introduces the two features of the coverage of knowledge concepts and the difficulty into the dynamic learning environment to make the representation of the dynamic learning environment more complete. Secondly, a deep reinforcement learning algorithms is used to realize the recommendation of learning paths and improve the adaptability of learning paths. Finally, technology comparison experiment and application experiment are conducted. The technology comparison experiment demonstrates that the model improves the effectiveness and adaptability of the learning paths. The application experiment shows that the model can accurately identify the learners' weak knowledge concepts and recommend adaptive learning paths suitable for their cognitive characteristics.
[Keywords] Adaptive Learning Path; Reinforcement Learning; Domain Knowledge Characteristics; Coverage of Knowledge Concepts; Personalized Learning
猜你喜欢
软件导刊(2017年10期)2017-11-02 11:22:44
现代电子技术(2017年15期)2017-09-04 15:47:05
上海海事大学学报(2017年2期)2017-07-14 22:19:44
中学课程辅导·教学研究(2017年13期)2017-07-01 14:50:34
大经贸(2017年5期)2017-06-19 20:06:37
电脑知识与技术(2016年28期)2016-12-21 11:51:11
教育教学论坛(2016年46期)2016-12-19 21:54:41
中国信息技术教育(2016年21期)2016-12-05 17:50:28
湖南大学学报·自然科学版(2016年10期)2016-11-30 19:02:13
电脑知识与技术(2016年24期)2016-11-14 01:36:35
