
两种高效局部搜索算法求解RB模型实例
2024-06-01 08:20杨易王晓峰唐傲彭庆媛杨澜庞立超
计算机应用研究 2024年5期
关键词:模拟退火
杨易 王晓峰 唐傲 彭庆媛 杨澜 庞立超

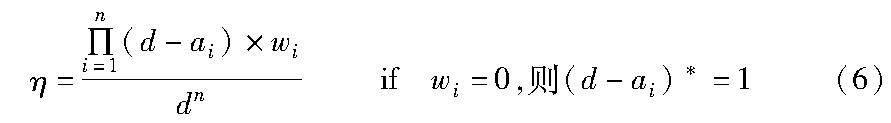
摘 要:RB (revised B)模型是一种在约束可满足问题中具备精确相变增长域的随机实例模型,提出两种高效的启发式局部搜索算法用于解决RB模型生成的大值域约束可满足问题。首先为基于权重指导搜索的W-MCH算法,该算法通过约束判断和违反约束数计分来进行搜索,并引入了基于约束违反概率的权重计算公式,根据其关联的约束权重进行修正,再对变量进行迭代调整。然后提出最小化值域的MDMCH算法,该算法通过记录违反约束和逐步消除已违反约束变量的启发式策略来减少搜索空间,并在最小化后的变量域内重新校准变量赋值,进而有效提高算法的收敛速度。此外,还提出了融入模擬退火策略的WSCH和MDSCH算法,这两种算法都能根据变量的表征特点对变量域进行针对性的搜索。实验结果表明,与多种启发式算法相比,这两种算法在精度与时间效率方面均呈现明显提升,在复杂难解的实例中能够提供高效的求解效率,验证了算法的有效性和优越性。
关键词:RB模型;约束满足问题;局部搜索算法;模拟退火;最小冲突启发式
中图分类号:TP301 文献标志码:A 文章编号:1001-3695(2024)05-017-1394-08
doi: 10.19734/j.issn.1001-3695.2023.09.0415
Two efficient local search algorithms for solving RB model examples
Abstract:The RB (revised B) model is a stochastic instance model with an accurate phase change growth domain in constraint-satisfiable problems. This paper proposed two efficient heuristic local search algorithms to solve the large-value domain constraints generated by the RB model. The first is the W-MCH algorithm based on weight-guided search. This algorithm searched through constraint judgment and constraint violation score, and introduced a weight calculation formula based on constraint violation probability, which was modified according to its associated constraint weight, and iteratively adjusted then variables. Then it proposed the MDMCH algorithm for minimizing the value range, this algorithm reduced the search space by recording the heuristic strategy of constraint violations and gradually eliminating the violated constraint variables, and recalibrated the variable assignments within the minimized variable domain, thereby effectively improving the algorithms convergence speed. In addition, it also proposed the WSCH and MDSCH algorithms that incorporate simulated annealing strategies. Both algorithms can perform targeted searches in the variable domain based on the characterization characteristics of the variables. Experimental results show that compared with various heuristic algorithms, these two algorithms have significantly improved accuracy and time efficiency, and can provide efficient solution efficiency in complex and difficult instances, verifying the effectiveness and superiority of the algorithms.
Key words:RB model; constraint satisfaction problem; local search algorithm; simulated annealing; minimum conflict heuristic
0 引言
约束可满足问题(constraint satisfiability problem,CSP)作为人工智能科学领域的一个关键研究方向,在实际优化问题中具有重要地位。许多现实世界中的优化难题都能以CSP形式建模,这使得CSP通过不同编码方式的可满足性判定问题(satisfiability,SAT)公式相对于随机SAT公式更自然地刻画了约束之间的关系。约束编程在诸如机器设计[1]、电路设计[2]、汽车变速器设计[3]、调度与规划[4]等领域得到成功应用。因此,对CSP的深入研究变得愈加意义非凡。在CSP的生成模型、可满足性相变和求解算法等方面,学者们都展开广泛探讨。最初,Achlioptas等人[5]发现了CSP的A、B、C、D四种初始模型存在严重缺陷,随着变量数量的增加,并没有出现渐进性的相变现象,即平凡渐进不可满足性。为了弥补这些传统模型的不足,E模型[5]和广义模型[6]相继被提出。然而,E模型无法灵活地调整实例的密度,而广义模型则在引入概率分布后变得复杂。随后,Xu等人[7]在2000年提出了一种新的随机CSP模型,名为RB(revised B)模型。RB模型以其精确的相变特性,成为了一种增长域实例模型,完美地弥补了前述模型的不足。此后,Fan等人于2011年在RB模型基础上提出了K-CSP[8]和d-K-CSP[9]两个改进模型。赵春艳等人[10]则提出了p-RB模型。尽管这些模型都是基于RB模型的改进,但都存在一定的局限性。Huang等人[11]通过一阶矩方式,推导出以RB模型生成的Max-CSP和Min-CSP的上下限。Xu等人[12]采用严格的一阶和二阶矩方法,证明了在可解阶段接近可满足的转变,解会以指数数量的良好分离簇的形式聚合,每个簇包含亚指数数量的解,呈现出了聚类动态跃迁,而不是凝聚跃迁。最近,Zhou 等人[13]研究了模型RB的强制实例空间,并严格地证明了RB实例强迫解的期望数目与非强迫解的期望数目渐近相等。Xu等人[14]探究了RB模型解空间的结构,发现随着约束密度的增加,模型呈现出独立相变、聚类相变、可满足性相变以及隔离相变四种相变特性。RB模型因其兼具上述模型的优点并弥合其缺陷,被广泛应用于该领域。然而,RB模型生成随机实例的求解难度在变量规模达到仅为102量级时变得极具挑战性[15]。综上所述,RB模型在CSP研究中扮演着重要角色,为该领域的研究人员提供了一种常用且多特性的随机实例模型。
针对RB模型生成的大值域CSP实例的求解方法可以分为两大类。首先是完备性算法,例如回溯技术、约束传播和变量排序启发式,这些方法虽然能确保解的准确性,但在处理大规模的RB模型实例时,时间复杂度呈指数级增长;其次是不完备性算法,包括局部搜索、自然启发式和近似概率求解。虽然这些方法可能无法获得精确解,但它们旨在可接受的时间内寻找近似解。2016年,王晓峰等人[16]探究了置信传播算法在RB模型上的收敛性。同年,Xu等人[17]研究了局部搜索算法,提供了随机游走算法的阈值界,并给出了随机游走结合最小冲突启发式算法。此外,2017年,原志强等人[18]引入了基于模拟退火的改进方法RSA(revised simulated annealing algorithm)和结合遗传算法的GSA(genetic simulated annealing algorithm),用于求解RB模型实例。2018年,Bouhouch等人[19]将二元CSP建模为0-1二次规划,提出了基于离散化神经网络和局部搜索最小冲突启发式MCH(minimum conflict heuristic algorithm)启发式的方法,用于求解RB模型生成的二元CSP实例。2022年,Tnshoff等人[20]提出了一个可以训练的通用图神经网络架构作为任何约束满足问题的搜索启发式方法,通过实验证明该方法优于神经组合优化。同年,Korani等人[21]提出两种离散群智能算法离散母树优化(mother tree optimization,MTO)和离散的粒子群(discrete particle swarm optimization,PSO)求解RB模型生成的CSP实例。2023年,Hossain[22]根据CSP的约束条件对所有变量进行变量排序的启发式策略,求解CSP实例。
本文基于RB模型生成的CSP问题实例,对CSP中的最大约束可满足问题(MAX-CSP)的求解算法进行了深入研究。主要关注局部搜索算法,并提出了两种高效的局部搜索算法:基于权重搜索的W-MCH(weight-based minimum conflict heuristic algorithm)局部搜索算法和最小化变量域的 MDMCH(minimizing variable domain-minimum conflict heuristic algorithm)算法。通过收敛性和求解效率等实验结果的验证,这两种算法各自展现了独特的优势。相较于MCH和WMCH(random walk minimum conflict heuristic algorithm),这两种算法在收敛性上有了显著提升。此外,在两種局部搜索的基础上提出了融入退火策略[18]的变体WSCH(weight-based simulated annealing minimum conflict heuristic algorithm)和MDSCH(minimizing variable domain simulated annealing minimum conflict heuristic algorithm)算法。而与文献[17,18]中提到的RSA、GSA、WMCH等启发式算法相比,这两种算法在各变量规模上的求解时间至少缩短了30%,且在减少不可满足约束数方面取得了显著进展。与多组启发式算法相比,实验结果表明,这两种局部搜索算法在求解RB模型生成的CSP实例时,呈现出高效的求解效率。
1 RB模型
RB模型是从著名的CSP模型B改进而来,RB模型的一类随机CSP实例表示为P∈RB{k,n,α,r,p},其中对于每个实例的符号定义[11]如表1所示。由表1定义可以看出,随着RB模型变量数xn的增长,取值域dn规模是呈多项式级增长。生成一个实例P∈RB(k,n,α,r,p),具体步骤如下:
a)设置模型RB的主要参数n、p、α和r。其中n是变量数量,p是约束紧度,r和α是两个自定义的常数。
b)重复随机选择m个约束条件,每个约束都是通过从n个变量中独立随机地选择k个变量形成。
c)对于每个约束C,从完整的dkn个赋值中随机选取pdkn 种不同的k元赋值,形成一个不相容赋值的集合Qa,当约束C的变量取值不属于这些不相容赋值集合Qa时,该约束满足。
在文献[23]中给出控制参数p,临界值pcr,可确定RB模型的可满足性相变现象,并给出以下定理。
利用上述定理公式,根据RB模型的参数取值可确定出相变点pcr。更准确地说,变量数接近无穷时,若p
2 局部搜索算法
2.1 MCH算法
局部搜索是解决约束满足问题复杂计算组合问题的基本范式之一。尽管系统、完整的搜索算法已经取得了进步,但在大多情况下,局部搜索方法是解决这些大型复杂实例的优秀可行方法。在解决CSP时,传统的局部搜索算法通常从一个初始解s出发。在算法的迭代过程中,它会反复在当前解的邻域(s) 中寻找比当前解更优的解,并将找到的更优解替代当前解s*,直到在当前邻域(s)中无法找到比当前解更好的解为止。如果在整个搜索过程中无法找到比解s*更优的解,则该解被视为局部最优解。
MCH迭代地修改单个变量的赋值,使违反约束的数量最小化。假设给定一个CSP实例P,通过为P中的每个变量赋值来初始化搜索过程,该值是从其域中统一随机选择的。在每个局部搜索步骤中,首先从冲突集中均匀地随机选择一个CSP变量x,然后从x的值域中选择一个新值d,将d赋值变量x,使不满足的约束冲突的数量最小化。如果有多个具有该属性的冲突变量x值,则随机选择。当找到解决方案或超过搜索步骤数限制时,终止搜索。这种传统的局部搜索策略在寻找解决CSP的最优解时,一般都是通过持续地在搜索空间中寻找更优解,逐步单个地改善当前解,以达到更好的问题解决效果。MCH求解RB模型实例的伪代码如算法1。
算法1 MCH算法
2.2 W-MCH算法
与MCH算法不同,基于约束权重的概率选择变量赋值的W-MCH算法是一种可变深度搜索策略,同时引导多个变量的搜索过程。在这一算法中,首先仍以CSP问题的违反约束记录值作为算法的求解评价标准,即评估函数。对于RB模型实例,一组赋值解为X={x1,x2,…,xn},对该组赋值进行约束检查,若违反约束时标记1分,否则计0分。通过对一组赋值进行约束检查并计算评估分值,MAX-CSP问题的目标在于最小化评估函数的目标分值S,具体函数如下所示。
其中:m为约束的数量,通过检查赋值是否满足约束集Cm,使得评估分值S为0或最小,特别是在处理复杂实例的可满足相变区域时,求解算法的主要目标是在合理的时间范围内寻找到违反约束最少的解。
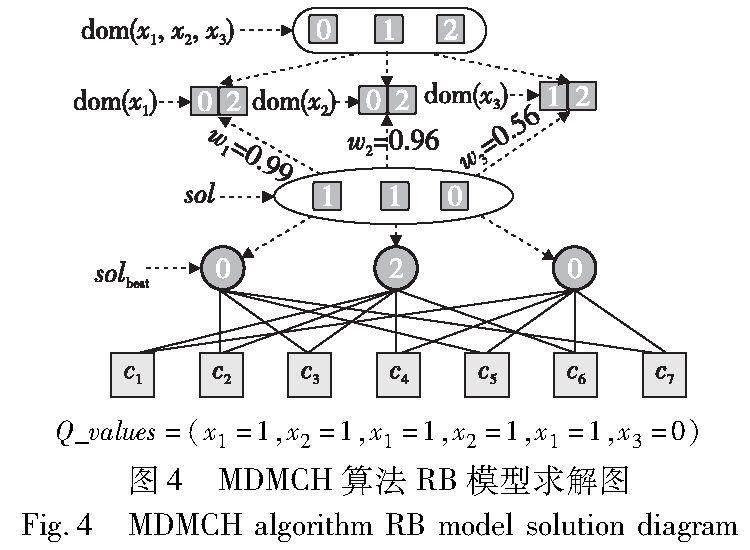
当k=2,n=3,α=1,r=2,p=0.25时,考虑图1中的RB模型实例P(k,n,α,r,p)。图中绿色圈中,表示变量X={x1,x2,x3},而红色框中(参见电子版)表示的是变量约束,由r×n×ln n可得出约束数m为7,则约束C={c1,c2,…,c7} ,每个变量x映射的dn域大小为nα,计算结果为3,即值域d={0,1,2},图1中下方为不相容赋值Qa。W-MCH算法开始于随机初始化多组解,并为每组解进行评估得分。随后,记录初始赋值中得分最低的解,记为sol。假设初始解为sol={1,1,0},接下来进行约束检查,以c1约束为例,涉及变量(x2,x3),当x2赋值为1,x3赋值为0时,检查其约束对应的不相容赋值Q1={(1,2),(2,2)},可以发现约束c1是满足的,如图1用实线表示满足约束。依次检查完所有的约束,在此实例中,初始解sol={1,1,0}违反约束c2、c3、c5,如图1用虚线表示。同时,在检查的过程中,初始化一个变量索引数组,记为C_values,在索引数组中存储其违反约束的变量索引,如违反约束c2的变量对应索引值为(1,2),累计存储在C_values数组中。
此时,在MCH算法中的做法是记录违反的不相容赋值中的Q,记为冲突集,对违反的单个变量进行赋值修改。然而当实例复杂时,MCH算法在单个变量上的修改可能效果有限。相比之下,W-MCH算法采用一种基于权重的方法,不同于MCH的是,W-MCH以C_values变量索引数组寻找其违反约束值,在每次循环中对赋值sol,通过权重指导实现多变量修改的算法策略。分析得到的索引变量集C_values,在该数组中发现索引的次数恰好代表了其变量的违反次数,故可对C_values进行统计排序,并对应地计算在数组中的占比概率pi。
pi=C(indexicount)/C_valueslength(4)
其中:C(indexicount)表示對应索引值的计数频次;C_valueslength为索引数组长度。事实上使用频次计算出频率pi或者其他概率,并不能有效地进行概率选择。原因是随着变量的增加,单纯的概率值并不能完全反映出变量的优劣程度。如C_values中最大的P1 =0.5,但实际C_values数组中的x1已是最差的赋值变量。需要将概率值进行映射以便更好地表征好坏程度,或者按照概率值的大小给予不同的权重来进行选择,对此提出了以下的权重公式。
其中:s=0.05为一个常数,控制着权重公式与映射曲率的大小,图2为s取不同数值对其曲率的影响。由于s参数控制权重值的大小,又因在上述公式中,若indexicount值越大,表明当前的赋值违反约束的数量越多,违反概率也相应增大,所以需要更大的权重值来调整当前赋值中的差值变量。理论上,当存在概率值时,都必须修改违反约束的变量,然而变量之间的相互约束,必须固定一部分违反约束较少的赋值变量,对于违反约束多的赋值,使之以更高的权重去修改变量赋值。然而整体权重值不能过大,以免导致算法过于随机化。经过多次实验和分析,取参数值s=0.05。由于权重值是以约束的违反概率进行计算的,所以并不会影响变量修正的准确性,可以看出,随着变量数的增加,C_valueslength的违反约束数也会增加,当indexicount=0,即违反约束为0时,权重也为0,而当约束违反时,权重也会随之增加。但当变量增多时,整体的权重值在迭代修正后会陷入一个局部值,从而影响算法的收敛速度。利用此策略得到一组最优赋值后再利用MCH算法,所以此操作并不会影响算法的准确性。如在图1 C_values中,变量x1的赋值违反约束频次为index1count=3,同理index2count=2,index3count=1,代入上述公式可以计算出weight1=0.99,weight2=0.96,weight3=0.56。以此权重对sol的所有变量重新赋值,假设赋值x1=2,x2=0,x3未能修改,则得到的解为solbest={2,0,0},重新检查约束集,则只有c3和c6违反,重复上述操作即可有效地降低算法的违反约束。
从图2中可以看出,实际上在当Pi>20% 时,权重已经大于0.6,能满足大多数违反变量的修改,在实际操作中若以weight>0 时的权重赋值,会造成算法过于随机化,导致算法不能有效收敛。当weight为0.3左右时,变量的原始概率值基本处于5%之上,为了使初始权重大多数变量都能被优化,则取weight>30%为每次迭代的赋值概率。
Q1={(1,2),(2,2)},Q2={(0,0),(1,1)};
Q3={(1,1),(2,0)},Q4={(2,1),(1,1)};
Q5={(1,0),(2,2)},Q6={(0,1),(0,0)};
Q7={(1,2),(2,1)}
C_values=[1,2,1,2,1,3]
为了验证以上取值,分析算法的权重初始值与迭代后的权重值。在图3中可以看出变量数n=100,在经过200次迭代计算,得到的蓝色区域(参见电子版)为迭代后的权重与初始权重的差值,可以看到,经过权重指导搜索后,绝大多数变量的权重已经小于初始权重值。此操作可以根据权重的不同分配,对不同的概率值造成不同程度的影响,从而实现根据权重调整的效果。经过权重调整后,可以得到一组优秀赋值解,再以MCH算法逐步搜寻单个变量进行修改。W-MCH算法的伪代码如算法2所示。
算法2 W-MCH算法
2.3 MDMCH算法
若能以高效策略为MCH算法提高一组出色的起始赋值,那么在相变区域内或许将获得优越的可行解。在分析W-MCH算法的权重图之后,可观察到在迭代之末,大约有20%的权重值仍保持较高水平。然而,对于这些过于突出的权重值,有时一个变量可能违反多个约束。为解决这一问题,引入MDMCH算法,此算法基于权重思想构建,旨在通过消除违反约束的变量,从而有力地缩减搜索空间。
首先同W-MCH算法初始步骤基本一致,先进行初始的约束检查,记录C_values数组,同时记录冲突变量集Qc,但MDMCH算法对于冲突集Qc的处理方式与MCH算法不同,MCH是在冲突集Qc中随机选择变量进行变量修改,最小化冲突数量。而MDMCH算法是在冲突集中寻找变量对应的违反变量值,然后将寻找出的变量与变量值累计存储到Q_values数组中。如图4所示,假设现在初始赋值还是sol={1,1,0}。可检查出每个变量的违反约束值,在该组赋值中,x1、x2、x3三个变量取值都与约束冲突。然后将冲突值依次在各自的变量域中消除冲突的变量,分别得到变量域dom(x1)=(0,2),dom(x2)=(0,2),dom(x3)=(0,1),再利用权重公式进行指导搜索。通过权重值和消除后的各个变量域,可计算出此操作后的搜索空间为2×0.99×2×0.96×2×0.56≈4.25,而最初的基本搜索空间为33,此实例中搜索空间降低了85%。假设变量数为n,对应的变量域为d,而对应每个变量域消除的冲突变量数为ai(a∈d-1),每個对应的修改权重为wi,可计算出最小化值域与搜索空间dn的有效比值,计算公式如下:
若以各自的权重得到新赋值solbest={0,2,0},并未违反约束进而高效地寻找出可行解。在最小化值域的策略中,每次消除的变量都是在随机初始赋值的基础上找出违反约束的赋值变量进行消除。每次消除违反赋值变量后,在剩余的值域内进行重新赋值。显然,由于变量之间的相互约束性,此操作一定会过于删除搜索空间,导致无法针对性求解,但会加快寻找局部最优解的速度;然而在简单易解实例上,容易陷入局部最优;相反,在难解实例上,能高效地降低违反约束数,但在迭代后期也会陷入局部最优。虽然最小化值域的策略充分地减少了搜索空间,导致无法精确求解,但此操作的目的并不是最终求解,而是快速地得到一组较优赋值,在此赋值的基础上再利用MCH算法在整个搜索空间进行针对性的精确搜索,不但不会影响MDMCH算法的精确性,反而这一策略加快了算法的收敛速度。由于在循环消除变量域的过程中,此操作无法考虑多组变量之间的约束相互影响的变量域,所以当变量增加时,在实验中发现变量域中会被消除为空,这也是导致在此操作陷入局部最优的一个原因,这时取当前变量域中违反约束最小的赋值解,记为当前最优解。对此,以0.2的概率对变量域为空的变量在其原有的变量域中进行随机赋值,跳出局部最优值,然后进行MCH算法的单个变量寻优。最后,通过权重差值实验发现,同样对100个变量进行200次迭代,分析初始权重,与迭代末的权重进行对比。权重值的优化如图5所示,可以看出,MDMCH算法只有极个别权重值超过了初始权重值,对于大多数权重值都进行了优化处理。该操作利用最小化变量域的方式,极大地增强了算法的局部搜索能力。MDMCH算法的伪代码如算法3所示。
算法3 MDMCH算法
2.4 WSCH与MDSCH算法
由于在后期的搜寻中,基于权重和最小化值域的两种算法策略都会缩小搜索空间,陷入局部最优,而MCH算法的收敛效果较差。故而在W-MCH与MDMCH迭代后寻得一组最优赋值,可融入模拟退火策略的MCH算法再进行寻优,并以1-3/T的概率进行选择扰动,利用最小约束数及当前退火温度T以 exp[-(Fnow-Fbest)] 概率来接受新的赋值,在退火初期,需要使赋值进行扰动后接受新赋值的概率较大。此赋值在大范围的赋值空间中对变量赋值能够进行随机扰动。在退火后期,随着T值的减少,扰动概率减小,则对较优赋值进行针对性扰动。这样在求解实例时,开始退火时期算法有优秀的能力来逃避局部最优值,从而快速找到简单实例解。在求解复杂实例时,前期虽然过于随机化,但随着退火温度的下降,算法在退火后期又可以进行针对性的寻优。避免以传统退火策略中盲目性的随机扰动降低求解效率,以此来提升算法的求解精度。引入退火策略算法具体的WSCH与MDSCH伪代码如算法4。
算法4 WSCH、MDSCH算法
2.5 算法时间复杂度分析
两种改进的局部搜索策略中都涉及到了约束检查与后续MCH算法的寻优,对此首先分析约束检查的时间复杂度,在W-MCH算法迭代的主循环内部会依次遍历其约束数m,则时间复杂度为O(m)。对于内部约束检查中每次在解sol中取出k个变量x的时间复杂度为O(k) ,然后将取出的变量与每组约束C中的t个具体约束集进行判断的时间复杂度为O(t),该操作的时间复杂度为O(m×k×t)。即约束检查的时间复杂度为
T1(m,t,k)=O(m×t×k)(7)
而约束数r×n×ln n=m,pdkN=t,dN=nα,则T1为
记录索引数组与权重计算涉及的操作相对较少,从约束集中取出不满足约束索引为O(k),而对于C_values数组索引排序的最大操作时间复杂度为数组长度,与赋值操作都为常数级。
MCH算法的时间复杂度主要取决于两个因素。首先是算法的迭代次数,算法通过迭代多次来寻找解,迭代次数可以通过设置参数来控制。通常情况下,迭代次数与问题的规模和复杂性无关,因此可以视为常数。其次是单次迭代中的局部搜索复杂度和冲突减少的效率与具体问题局部搜索实现算法相关。
综合考虑以上因素,最小冲突启发式算法的时间复杂度可以表示为
T2(n)=O(f(n,M,m))(9)
其中:n为问题规模;M为迭代次数;m为局部搜索的复杂度,而MCH的局部搜索主层循环时间复杂度为O(maxSteps),内部搜索操作的搜索复杂度和冲突减少的效率主要取决于循环中约束检查不满足变量的时间复杂度T1,而对于每次变量修改的时间复杂度为O(k),所以MCH的时间复杂度为
T3(maxSteps,T1)=O(maxSteps×T1×k)(10)
MDMCH比W-MCH算法多一步消除变量域的中间处理操作,实际处理的主要时间复杂度为O(nα),而nα为变量域的大小,为常数级。两种局部搜索的主要时间复杂度都为
WSCH与MDSCH算法外层循环主要为降温次数,时间复杂度为O(log(T0/T)) ,内层循环为尝试产生新的解并决定是否接受新解,主要的迭代次数由马尔可夫链长度L参数控制,约束检查与上述复杂度T1一致。两类变体算法的主要时间复杂度为
T5(T0,T,L,T1)=O(log(T0/T)×L×T1×k)(12)
由于RB模型为二元约束,k为常数取2,其中α取0.8,r和约束紧密度P为常数。即当RB模型参数确定时, 两种局部搜索W-MCH、MDMCH与两种退火策略的WSCH与MDSCH变体算法的主要复杂度为T=O(n×ln n)。
3 实验分析
为了验证基于权重和最小化值域两种算法策略的效率,分别进行了收敛性与求解概率实验。此次实验取文献[17,18,24~27]中参数明确,且为同类型的随机启发式算法作为对比实验。实验环境为Windows 11,64位操作系统,CPU为AMD Ryzen 7 5800H,主频为3.20 GHz,内存16 GB;RB模型参数取与文献[18]中相同的参数,k=2,α=0.8,r=3,n=[20∶20∶100]由定理1计算,可满足性相变点为Pcr=0.234。对于不同的n取约束密度p=[0∶0.01∶0.2],由上述数值生成的RB模型的具体参数如表2所示。
3.1 收敛性分析
首先,对W-MCH、MDMCH与MCH,和文献[17]中随机游走最小冲突启发式WMCH算法的收敛曲线进行对比分析。随后与文献[18]中RSA和GSA算法进行收敛曲线对比,而GSA和RSA算法都是以退火策略为循环。由于迭代次数与RSA和GSA不一致,为了方便比较,实验的收敛性比较以时间为横轴。
在图6(a)~(d)中,分别展示了这四种算法随着变量数和约束密度的增加,其收敛曲线的变化趋势。在图6(a)中,展示了变量数n=20 以及约束密度p=0.14时的收敛曲线。在这种情况下,WMCH表现出最佳的收敛性能。这归因于随机游走搜索方法的盲目性,使其在简单实例上寻找可行解空间时的表现较优。尽管期望步数在随机给定初始分配后非常大,即(1-p)-rnln n,但WMCH在一定概率下执行随机游走,具有一定程度跳出局部最优的效果,因此,在较为简单的实例中,WMCH的优越性明显。而W-MCH与MDMCH表现一般,由于在本身策略下缩小解空间,得到的一组较优赋值后再由MCH算法处理,与MCH、WMCH在简单实例上随机赋值相比有一定的随机性,当WMCH与W-MCH和MDMCH的初始赋值违反约束数相差不大时,相对于WMCH与MCH,W-MCH与MDMCH增加了算法的复杂度,故收敛性较差。
不过随机实例的复杂性上升,在n=60,p=0.14时,两种局部搜索的搜索优势体现出来,在图6(b)中可以看到,W-MCH的收敛速度最快,在100次迭代后,最小不可满足约束数相对比于MCH、WMCH与MDMCH至少降低了34%左右。而WMCH有一定概率的随机游走步骤,在实例稍复杂时,则是四种算法中收敛速度最差的。值得注意的是,在较复杂的实例中,MDMCH算法的效率与MCH、WMCH相当,这是因为其中违反约束的数量相对较少,约束密度较小导致的不相容赋值稀疏,indexicount 违反的频次与C_valueslength的比值较小,处于一个权重低位值,然而此实例下也不是难解实例,复杂约束较少,故最小化值域策略的效果不明顯。
进一步增加模型实例的复杂度,当n=100和p=0.14 时,两种局部搜索方法的收敛速度显著增快,如图6(c)所示,大约在50次迭代后,这两种方法的最少不可满足约束数位于[40,60],而MCH和WMCH算法的最少不可满足约束数则在[130,140]。在相同的迭代次数下,相对于其他三种算法最少不可满足约束数至少降低了70%。在此实例下,MDMCH算法的优势十分明显,其最小化变量域的策略有助于更快地获得一组初始赋值,加快算法的收敛速度。此外,随着实例的复杂程度增加,似乎在接近实例的可满足相变点附近,MDMCH算法更具有快速收敛的趋势。对于最具挑战性的实例,即n=100和p=0.20 的情况下,复杂约束增大,如图6(d)所示,MDMCH算法在难解实例上的收敛速度最佳,这是由于无论算法处于哪种实例,在每次迭代求解中,C_valueslength 为一次约束检查数组长度的定值,然而当实例复杂时,即weight 与indexicount成正比,若赋值变量的违反约束数越大,则导致该变量的indexicount越大,则权重的值也相应增大,故而在复杂难解实例上算法的收敛速度越快,而实例简单时,该值影响的权重值较小,故而收敛速度无难解实例上那样明显,但由于变量约束的相互影响,又不能将概率权重映射过度放大,会造成多组赋值变量都需要以高权重进行修正,导致算法难以收敛,而该组实验的收敛图像正好验证了笔者的预期。需要指出的是,MDMCH算法引入了0.2概率的随机赋值策略,从而在对比实验图(b)~(d)中复杂实例上的MDMCH算法的最少不满足约束数最小。
图6(e)(f)分别为n=60,p=0.14和n=100,p=0.14引入退火策略的两种算法与GSA和RSA算法的时间收敛对比。可以看出,融入基于权重搜索和最小化值域搜索策略的WSCH与MDSCH算法能迅速收敛到局部最优值,在图6(e)中两种算法在10 s之内已达到个位数的最少不可满足约束数,比其他两种算法的时间效率最高提升70%,进而有效地给退火策略的MCH提供一组有效赋值,能尽早地搜索最优解。随着实例的复杂度增加,在图6(f)中,WSCH与MDSCH算法的收敛速度似乎更加明显,而MDSCH相比于其他三种算法能更早地跳出局部最优,收敛速度大幅提升。此实验中更加清晰地验证了两种改进方法对于变量迭代修正的效率远远高于RSA、GSA、MCH和WMCH改进算法。
3.2 求解效率对比分析
图7中分别对比WSCH、MDSCH算法与RSA、GSA在RB模型各维度10组实例上的求解概率。图7(a)~(d)分别展示了RSA、GSA、WSCH和MDSCH四种算法在不同约束密度下的收敛概率。其中RSA在p≤0.07时,GSA在p≤0.1时两种算法在各组RB模型变量实例上以概率1收敛,W-SCH在p≤0.11时以概率1收敛,而MDSCH在p≤0.12时可有效求解。在低维实例上n为20、40时,WSCH表现出最佳的求解效率,在相变区域内依然有高概率可解,其次为MDSCH,在变量n取20,WSCH和MDSCH算法求解概率的约束密度p都达到了0.16,RSA与GSA算法分别为0.1和0.13。WSCH和GSA算法在临近相变点0.20时依然有0.1概率求解,但求解概率高于GSA。在变量n取40时,MDSCH在p取0.14,0.15 时,求解概率分别为0.9和0.5,WSCH求解概率都为0.6,RSA和GSA算法分别在p取0.14和0.15时失效,而MDSCH和WSCH算法的求解概率分别达到了0.16和0.17。综上分析,在低维实例上,WSCH稍优于MDSCH,两种算法都优于RSA和GSA的求解效率。随着实例变得复杂,MDSCH的求解能力在n取60、80、100的高维实例上体现了出来。在n为60时,WSCH在p=0.15 有0.1的概率收敛,而MDSCH算法有0.5的概率收敛,RSA和GSA求解失败。在n取80时,WSCH在p=0.14有0.3的概率求解,RSA和GSA均已失效,而MDSCH依然有0.6的高概率求解。MDSCH在n取100时,将求解概率的约束密度提升到了0.12。综合分析实验结果,相比于其他三类算法,MDSCH在高维复杂实例上表现出色,其求解概率均高于对比算法,与此同时,WSCH在低维实例中表现出了良好的性能。
图8中对比了四种算法在不同变量规模下的总运行时间。可以观察到,每个规模下MDSCH和WSCH算法的总运行时间都明显优于GSA和RSA算法,时间效率最大提升了50%左右。值得注意的是,随着变量规模的增加,尤其是在复杂可解实例中,MDSCH的时间效率开始优于WSCH算法,MDSCH的最小化值域策略开始发挥作用,这使得它能更快地为退火策略的MCH算法提供一组出色的赋值,从而提高了求解的时间效率。综上所述,MDSCH和WSCH算法在不同规模的变量下都表现出良好的性能,特别是在高维度和复杂实例中,MDSCH算法在求解效率方面表现出色。
为了进一步验证WSCH和MDSCH算法的有效性,图9(a)(b)分别在变量n取80、100,约束密度为[0.11,0.17],进行50个随机实例的求解概率对比。其中BP-RSA-1(belief propagation-revised simulated annealing algorithm-1)[24]、 BP-RSA-2(belief propagation-revised simulated annealing algorithm-2)[24]、禁忌搜索TS(Tabu search)[25]、TS-SA(Tabu search-simulated annealing algorithm)[25]都为启发式随机搜索算法。而回溯BT(backtracking algorithm)[26]、基于度启发式的HBT(heuristic backtracking algorithm)[26]、动态度的ddeg-MAC(dynamic degree-maintaining arc consistency)[27]都为基于回溯的完备性求解算法,基础的BT与TS算法在高维难解
实例中并不具有求解能力。从图9(a)可以看到,当变量取80时,WSCH与MDSCH在同组算法中,p为0.12~0.14时展现的高概率求解,均优于对比算法,在p=0.14时,表现最好的MDSCH与对比算法中最优的BP-RSA-2相比,求解概率高出32%。而在p>0.14时,由于实例的复杂度增加,各算法均不能高效求解。如图9(b),当变量n取100,在p=0.14时,实例的复杂度上升,MDSCH算法稍弱于BP-RSA-2、HBT。在p=0.13时,WSCH求解概率仅次于MDSCH,而MDSCH与对比算法中最优的TS-SA相比,求解概率高出16%。在变量n取100时,MDSCH算法在p=0.12時以概率1求解,为所有对比算法中最佳值。而无论变量n取80、100,在p取0.11、0.12时,两种算法的求解效率均表现最佳。综上分析,WSCH与MDSCH算法在高维难解实例中,对比各类启发式算法表现出了高效的求解性能。
表3为RSA、GSA、WSCH和MDSCH四种算法在随机的RB模型实例上,在各变量维度中分别运行10次,取约束密度0.16~0.20在接近可满足性相变的实验结果。ANVC表示平均不可满足约束数,time为平均运行时间。在平均运行时间方面,对于复杂且难解的RB模型实例,WSCH和MDSCH算法的运行时间基本相当,相比之下,RSA和GSA算法的平均运行时间至少增加了近30%。在不可满足约束数量方面,当变量维度较低(如n 取20或40)时,WSCH表现最佳。但在高维实例中,尤其是在变量维度较高(如n取60、80或100)且实例较复杂的情况下,MDSCH表现出色。值得注意的是,在复杂但可解的区域中,当约束密度为0.16时,MDSCH的平均不可满足约束数量提高的效率最多。综上所述,这些实验结果表明,MDSCH在高维度和复杂RB模型实例上的性能表现优越,特别是在可满足性相变点附近的情况下,其平均不可满足约束数量显著减少。
4 结束语
对大值域CSP的求解探索是极其有意义的,如在一些实际应用中,CSP的问题参数如域大小、变量数量、约束数量等可能不确定,RB模型可以用于生成多个实例,以测试不同参数下算法的表现。通过分析在不同参数配置下算法的性能表现,为实际应用中的问题选择最佳参数设置以提高问题求解的效率和准确性。其次在自动化调度和资源分配问题中,RB模型可用于生成不同场景下的调度问题,这有助于评估自动化调度算法在处理多种不同场景下的性能。通过对多个场景下的调度问题进行建模和求解,可以优化资源分配,提高效率,最大程度减少成本。 本文提出了基于权重指导搜索的W-MCH和最小化值域MDMCH的两种局部搜索方式,显著提高了MCH算法在整体规模接近可满足相变区域的求解效率。此外,融入退火策略的WSCH和MDSCH算法进一步增强了算法的局部搜索能力。这些算法在求解RB模型生成的CSP问题实例方面表现出色,尤其在高约束密度和复杂性下具有明显的优势。然而,这些算法仍有待优化。例如,对于高维实例,可以进一步优化权重处理,采用自适应权重调整策略,在迭代一定次数后重新映射各个变量的权重,实现更精确的搜索引导。未来的研究可以继续探索这些算法在其他领域的应用,并优化它们以提高求解效率。
參考文献:
[1]Frayman F,Mittal S. COSSACK: a constraint-based expert system for configuration tasks[M]//Knowledge-Based Expert Systems in Engineering: Planning and Design.Berlin:Springer,1987: 143-166.
[2]De Kleer J,Sussman G J. Propagation of constraints applied to circuit synthesis[J]. International Journal of Circuit Theory and Applications,1980,8(2): 127-144.
[3]Nadel B A,Lin J. Automobile transmission design as a constraint satisfaction problem: modelling the kinematic level[J]. AI EDAM,1991,5(3): 137-171.
[4]Mackworth A K. On seeing things,again[C]//Proc of IJCAI. 1983: 1187-1191.
[5]Achlioptas D,Kirousis L M,Kranakis E,et al. Random constraint satisfaction: a more accurate picture[C]//Proc of International Conference on Principles and Practice of Constraint Programming. Berlin: Springer,1997: 107-120.
[6]Molloy M. Models and thresholds for random constraint satisfaction problems[C]//Proc of the 34th Annual ACM Symposium on Theory of Computing. New York:ACM Press,2002: 209-217.
[7]Xu Ke,Li Wei. Exact phase transitions in random constraint satisfaction problems[J]. Journal of Artificial Intelligence Research,2000,12: 93-103.
[8]Fan Yun,Shen Jing. On the phase transitions of random k-constraint satisfaction problems[J]. Artificial Intelligence,2011,175(3-4): 914-927.
[9]Fan Yun,Shen Jing,Xu Ke. A general model and thresholds for random constraint satisfaction problems[J]. Artificial Intelligence,2012,193: 1-17.
[10]赵春艳,范如梦,刘雅楠. 不同紧度下约束满足问题的相变现象 [J]. 计算机应用研究,2020,37(9): 2739-2743. (Zhao Chunyan,Fan Rumeng,Liu Yanan. Phase transitions in random constraint satisfaction problem with various constraint tightness [J]. Application Research of Computers,2020,37(9): 2739-2743.)
[11]Huang Ping,Yin Ming Hao. An upper (lower) bound for Max (Min) CSP[J]. Science China Information Sciences,2014,57(7):1-9.
[12]Xu Wei,Zhang Pan,Liu Tian,et al. The solution space structure of random constraint satisfaction problems with growing domains[J]. Journal of Statistical Mechanics: Theory and Experiment,2015,2015(12): P12006.
[13]Zhou Guangyan. Hiding solutions in model RB: forced instances are almost as hard as unforced ones[EB/OL]. (2021-3-15). https://arxiv.org/abs/2103.06649.
[14]Xu Wei,Zhang Zhe. The solution space structure of planted constraint satisfaction problems with growing domains[J]. Journal of Statistical Mechanics: Theory and Experiment,2022,2022(3): 033401.
[15]Cai Shaowei,Su Kaile,Chen Qingliang. EWLS: a new local search for minimum vertex cover[C]//Proc of the 24th AAAI Conference on Artificial Intelligence. Menlo Park: AAAI Press,2010: 45-50
[16]王晓峰,许道云. RB模型实例集上置信传播算法的收敛性 [J]. 软件学报,2016,27(11): 2712-2724. (Wang Xiaofeng,Xu Daoyun. Convergence of the belief propagation algorithm for RB model instances [J]. Journal of Software,2016,27(11): 2712-2724.)
[17]Xu Wei,Gong Fuzhou. Performances of pure random walk algorithms on constraint satisfaction problems with growing domains[J]. Journal of Combinatorial Optimization,2016,32(1): 51-66.
[18]原志强,赵春艳. 两种改进的模拟退火算法求解大值域约束满足问题 [J]. 计算机应用研究,2017,34(12): 3611-3616. (Yuan Zhiqiang,Zhao Chunyan. Two improved simulated annealing algorithms for solving constraint satisfaction problems with large domains [J]. Application Research of Computers,2017,34(12): 3611-3616.)
[19]Bouhouch A,Bennis H,Loqman C,et al. Neural network and local search to solve binary CSP[J]. Indonesian Journal of Electrical Engineering and Computer Science,2018,10(3): 1319-1330.
[20]Tnshoff J,Kisin B,Lindner J,et al. One model,any CSP: graph neural networks as fast global search heuristics for constraint satisfaction[EB/OL]. (2022-08-22). https://arxiv.org/abs/2208.10227.
[21]Korani W,Mouhoub M. Discrete mother tree optimization and swarm intelligence for constraint satisfaction problems[C]//Proc of ICAART. 2022: 234-241.
[22]Hossain M S. Constraint propagation and variable ordering heuristics for solving Constrained Partial CP-nets[D]. [S.l.]:University of Regina,2023.
[23]Xu Ke,Boussemart F,Hemery F,et al. Random constraint satisfaction: easy generation of hard (satisfiable) instances[J]. Artificial Intelligence,2007,171(8-9): 514-534.
[24]吴拨荣,赵春艳,原志强. 置信传播和模拟退火相结合求解约束满足问题 [J]. 计算机应用研究,2019,36(5): 1297-1301. (Wu Borong,Zhao Chunyan,Yuan Zhiqiang. Combining belief propagation and simulated annealing to solve random satisfaction problems [J]. Application Research of Computers,2019,36(5): 1297-1301.)
[25]李飞龙,赵春艳,范如梦. 基于禁忌搜索算法求解随机约束满足问题 [J]. 计算机应用,2019,39(12): 3584-3589. (Li Feilong,Zhao Chunyan,Fan Rumeng. Solving random constraint satisfaction problems based on tabu search algorithm [J]. Journal of Computer Applications,2019,39(12): 3584-3589.)
[26]范如梦,赵春艳,李飞龙. 启发式回溯算法求解约束满足问题 [J]. 計算机应用研究,2021,38(5): 1438-1442. (Fan Rumeng,Zhao Chunyan,Li Feilong. Heuristic backtracking algorithm to solve constraint satisfaction problems [J]. Applied Research of Compu-ters,2021,38(5): 1438-1442.)
[27]张学才,赵春艳. 基于动态度的回溯算法求解大值域约束满足问题 [J]. 计算机应用研究,2022,39(5): 1427-1431. (Zhang Xuecai,Zhao Chunyan. Dynamic degree based backtracking algorithm to solve constraint satisfaction problems with large domains [J]. Application Research of Computers,2022,39(5): 1427-1431.)
猜你喜欢
软件导刊(2023年1期)2023-02-18
成都信息工程大学学报(2022年4期)2022-11-18
汽车实用技术(2022年10期)2022-06-09
网络安全技术与应用(2021年7期)2021-07-16
中国金属通报(2020年2期)2020-06-30
测控技术(2018年3期)2018-11-25
软件(2017年7期)2018-01-24
断块油气田(2016年3期)2016-11-03
软件(2016年3期)2016-05-16
电测与仪表(2016年17期)2016-04-11
