
大数据认知实践教学改革研究
2024-05-18 13:04:47张扬武李国和
大学教育 2024年4期
张扬武 李国和
[摘 要]面向工程领域中的大数据处理实际需求,培养具备大数据开发和管理能力的人才,是大数据实践教学题中应有之义。文章针对大数据认知实践教学中存在的问题,结合理实协同教学理念,提出产教融合的大数据认知实践教学体系和内容,着力改善大数据认知实践教学效果,提高大数据应用实践人才培养质量。
[关键词]大数据;实践教学;教学改革;教学内容;Hadoop
[中图分类号]G642[文献标识码]A[文章编号]2095-3437(2024)04-0029-04
当前,数据已经成为我们学习、工作和生活中的资源,普通用户既是数据的生产者,也是数据的消费者。随着移动互联网和人工智能的迅猛发展,大数据技术逐渐引起了人们的广泛兴趣,大数据对国家发展也越来越为重要,大数据技术和应用的发展逐步上升到国家战略地位。从数据、信息、知识到大数据,信息技术不断地进行了螺旋式迭代发展。近些年,各个行业的业务数据呈现数量级增长,导致对数据处理的要求越来越高,对大数据分析和处理的人才需求也随之增长。为了适应新时代的国家战略和人才培养需要,教育部于2015年出台了大数据专业培养文件和政策。为了响应教育部大数据人才培养目标,很多高校相继成立了大数据相关专业,以求不断培养出能够从事大数据设计、开发和分析工作的人才,以满足社会对大数据应用人才的需求。
面向工程领域中的大数据处理实际需求,培养目标明确提出,大数据专业人才应该具备基础的知识和应用能力,重点培养学生运用大数据技术进行工程创新的能力,着力解决科技产业涌现的新问题。大数据科学实际上是多门学科融合的专业,其学生既需要掌握计算机科学基础理论,又要熟悉数学统计方法,还要精通程序开发的工程知识,涉及学科领域广泛,技术发展更新快。目前,一些高校的大数据专业人才培养中学生理论知识的学习局限于计算机基本知识、概念和方法原理,实践教学目前还不成熟,处于探索阶段。要让学生掌握大数据存储、计算和分析方法,培养学生运用大数据技术解决工程问题的创新思维和创新能力,实践教学至关重要。因此,研究和探索大数据专业实践教学具有非常重要的作用和意义。
一、大數据认知实践的教学现状及存在问题
目前大数据专业培养方案将Hadoop开发技术作为专业的核心主干课,这是符合实际行业需求的。虽然专业的正式名称为数据科学与大数据技术,但是培养目标为满足行业对大数据应用人才的需求。从课程体系上来说,既要有能够培养学生运用数理知识、专业知识和工程知识解决复杂工程问题能力的课程组,又要有能够培养学生运用软件开发技术、数据分析方法和工程实践知识构建大数据应用系统能力的课程组。数理知识课程包括概率论、数理统计、线性代数、高等数学等,专业知识课程包括操作系统原理、数据库原理、计算机系统原理、数据结构和算法、大数据技术原理等,软件开发技术课程包括软件工程、Java程序设计、C语言程序设计、Python程序语言设计等,数据分析方法课程包括数据统计和分析、数据科学、机器学习、自然语言处理等,工程实践课程包括大数据认知实践、大数据工程实践等。
大数据认知实践在理论学习的基础上,在校内开展实践教学,虽然不是真实数据生产场景,但是尽最大可能模拟数据生产环境。传统的实践教学受限于教学手段和教学方法,不能最大化展现实际应用场景,仅仅作为理论知识的有限拓展,难以实现行业和企业对学生的应用能力的培养要求。传统的实践教学涉及的数据采集、平台搭建和模型算法选择都较为单一,缺乏灵活性,理论知识和实践内容脱节,理论知识不能有效支持实践内容,实践内容也不能巩固理论知识。传统的实践教学不能满足大数据认知实践对资源的开销,大数据分布式存储和计算框架需要服务器集群,并发访问数据量大。大数据实践教学不仅对主机的计算资源和存储资源有着较高的要求,而且涉及的配置细节非常烦琐,需要学生不断地加强练习,这对实验室的硬件环境和开放时间的要求都要高于传统的实践教学。此外,传统的实践教学手段较为单一,很多情况下就是灌输一些步骤,先理论后实践,不能有效激发学生主动学习和创新的热情。
二、大数据认知实践教学改革
(一)大数据认知实践教学内容体系
根据OBE(Outcome?Based Education)教育理念,大数据认知实践应该以学生的学习产出为导向,以行业应用需求为出发点和落脚点,推进学练用大数据认知实践教学改革,强化课程创新,促进教学优化。大数据认知实践教学应该立足社会需求,紧跟时代发展脉搏,抓住大数据应用场景,结合多学科深度融合交叉,根据行业大数据需求特点,进行全方位教育教学改革探索。
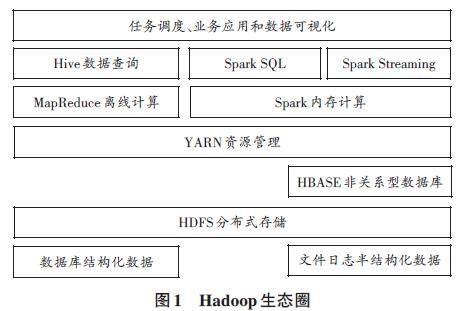
面向各个行业的基本数据生产,需要培养大数据分布存储系统的研发人才;面向企业业务提升,需要培养大数据分布计算系统的开发人才;面向机构管理决策,需要培养大数据处理分析复合型人才。以需求为导向,目前行业中的大数据存储大多数采用的是HDFS分布式存储系统,大数据计算系统采用的是MapReduce,而流式实时分析和处理框架则是采用Spark。因此,大数据认知实践教学实际上是围绕Hadoop生态圈开展的。
[数据库结构化数据 ][文件日志半结构化数据 ][任务调度、业务应用和数据可视化 ][Spark Streaming ][Hive数据查询 ][Spark SQL ][MapReduce离线计算 ][YARN资源管理 ][HDFS分布式存储 ][HBASE非关系型数据库 ][Spark内存计算 ]
图1 Hadoop生态圈
Hadoop是Apache基金会支持的开源大数据存储与计算框架,受到业界的广泛认可和青睐。搜索引擎使用Hadoop平台进行广告点击分析,电商网站利用Hadoop进行高可用数据存储和分析,Hadoop平台不仅包含大数据处理功能,还包括自然语言处理、机器学习以及云计算方面功能。
(二)大数据认知实践教学要求和环境
在开展大数据认知实践教学之前,需要强调学生应该掌握的前置课程和知识储备。Hadoop底层实现源码是用Java语言编写的,因此,学生需要提前掌握Java程序设计语言以及面向对象的程序设计思想。Hadoop部署在Linux操作系统上,学生需要掌握操作系统知识和Linux操作方法。Hadoop分布式存储涉及数据查询和持久化,因此,学生需要掌握数据库原理知识和SQL查询语句。Hadoop分布式计算可以通过编程实现对数据的查询和聚合,因此,学生需要掌握Java平台上的集成开发环境IDE(Integrated Development Environment)。
目前大数据实践教学环境可以分为自己搭建环境和第三方实训平台,两者各有优缺点。自己搭建环境的优势就是学生可以全程参与大数据服务器的部署和开发,可以比较广泛和深入地掌握大数据认知实践知识,其不足之处就是需要进行相关软件安装和组件配置的教学,比较烦琐。采用第三方实训平台的优势就是可以通过云服务器和web控制台方式进行一键部署,提交代码和运行代码的操作简单,其不足之处就是第三方平台使用的容器包装了很多实现细节,不利于学生对大数据认知实践知识的掌握。因此,在实验室有较高配置资源的情况下,推荐使用自搭实验环境。
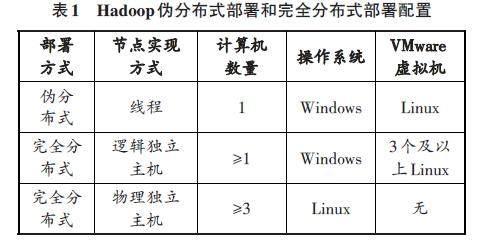
Hadoop可以分为伪分布式部署和完全分布式部署。Hadoop伪分布式部署利用线程模拟master主节点和slave从节点,而Hadoop完全分布式部署利用独立主机(包括物理上和逻辑上的独立主机)来分配主从节点。Hadoop伪分布式部署一般用于数据量和计算开销都不大的场景,也用于对大数据技术进行学习的场景。
Hadoop伪分布式部署需要一台安装Linux操作系统的主机,一般实验室的操作系统是支持应用较多的Windows系统,因此,需要安装VMware Station,在VMware虚拟机中安装Linux系统。另外,还需要在Windows中安装一个可以操作Linux系统的客户端软件,例如Xshell,便于后续操作,将Hadoop安装包上传到Linux系统中以及对Hadoop进行配置操作。
Hadoop完全分布式部署包括物理上独立主机和逻辑上独立主机。物理上独立主机的完全分布式部署需要采用分组实践,例如3人一组,将其中一台主机作为master节点,三台主机都作为slave节点。逻辑上独立主机的完全分布式部署需要在Windows系统中安装VMware Station和Xshell,在VMware虚拟机中安装3个或者多个Linux系统。Hadoop伪分布式部署和完全分布式部署配置见表1。
(三)大数据认知实践教学内容
大数据认知实践应该围绕教学目标展开,概括来说,教学目标包括掌握大数据存储技术和大数据计算技术。传统的软件工程是将存储和计算分离,数据存储在磁盘上,计算时再读到内存,多次磁盘I/O操作将极大降低计算效率,并且随着数据量增加,磁盘存储和内存计算资源只能纵向扩展,不能横向扩展,这种情况显然不能满足大数据的业务需求。为了解决传统工程中存储和计算脱节、无法提供高可用服务的问题,Hadoop通过提供分布式存储系统HDFS、分布式计算框架MapReduce、非关系型数据库Hbase、数据仓库Hive以及内存计算框架Spark等,提供并发处理低延迟的高可用服务。
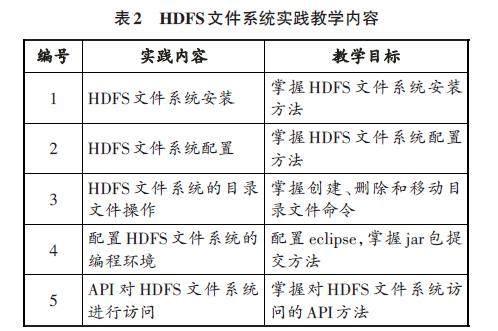
HDFS是大数据分布式存储系统,通过数据块冗余分布式存储提供高可用访问,分布式存储的横向扩展是通过增加机器数量来实现的,既可以突破纵向扩展的瓶颈限制,又可以利用高带宽访问,还可以提供多个冗余副本存储。HDFS在master节点即NameNode上管理整个分布式文件系统的元数据信息,包括文件名、文件大小、文件块数、块ID以及块存储位置。HDFS在slave节点即DataNode上存储拥有多个备份数据块的数据文件。为了防止master节点宕机出现的单点故障,还需要准备一个备份节点即SecondNameNode。同时,master节点通过RPC(Remote Procedure Call)心跳机制检测各个DataNode的工作状态。HDFS分布式存储系统的实践教学应包含HDFS文件系统的安装和配置、HDFS文件系统的目录文件操作命令、用API访问HDFS文件系统的编程方法等(见表2)。
MapReduce是基于HDFS的大数据分布式计算框架或者编程模型,为程序员提供面向业务的编程服务,而不需要考虑分布式计算中出现的诸如任务调度、分配、文件切片等各种具体问题,简化了处理事务,提高了编程工作效率。 MapReduce编程分为Mapper和Reducer两个阶段,前者是映射阶段,将读取的数据映射为key?value类型的迭代器,后者为聚合阶段,将迭代器中的相同的key做聚合,进行统计分析。完成Mapper和Reducer之后,编写驱动类Driver的入口函数。然后,将代码导出为jar包,提交到master节点上运行。MapReduce分布式计算框架的实践教学内容见表3。
Hbase是面向列的开源数据块,与传统的关系型数据库不同,其同一列的数值类型一样,将同一列连续存储更加符合客观规律。非关系型数据库Hbase的实践教学内容见表4。
Hive是基于Hadoop的数据仓库工具,可以将结构化数据映射为一个表,在此基础上提供类SPL的查询语句,其实现的原理是将查询语句映射为MapReduce任务。Hive可以处理不同来源的数据,包括数据库、文件和网络日志等。数据仓库工具Hive的实践教学内容见表5。
Spark是集实时流处理和交互查询为一体的内存计算框架,通过弹性分布式数据集RDD(Resilient Distributed Datasets)实现高容错性的内存抽象弹性机制。对RDD的操作有转换操作和执行操作,转换操作是窄依赖,并没有在内存中真正执行,由此可以进行优化操作,只有在執行操作对应的宽依赖的操作被处理时,数据才被溢写到磁盘上,数据的恢复完全可以通过依赖关系进行。实时流处理Spark的实践教学内容见表6。
三、结束语
为了提高大数据相关专业培养人才效果,开展大数据认识实践教学非常重要,不仅可以强化学生对大数据科学系统知识的理解和掌握,而且可以更加契合市场需求,向社会输出更加合格的人才。针对目前大数据实践教学中存在的问题,结合大数据专业培养目标和方案,本文提出了理实协同、多层次的大数据认知实践课程教学体系和内容,从生产应用场景探索大数据认知实践教学改革思路。
[ 参 考 文 献 ]
[1] 张俊丽,姚香秀,程茜,等. 基于OBE 理念的数据科学与大数据技术人才培养创新研究与实践[J]. 大学教育, 2022(4):185-187.
[2] 周晴红. Hadoop大数据开发技术课程实践教学[J]. 办公自动化,2021,26(20):20-22.
[3] 曾晓云.大数据人才培养的实践教学体系研究[J].湖南邮电职业技术学院学报,2022,21(1):84-86.
[4] 李方东.数据科学与大数据技术专业实验实践教学探析[J].长春大学学报,2021,31(2):88-91.
[5] 梁晶,胡新荣. Hadoop 大数据开发课程实践教学研究[J].计算机教育,2020(2):166-169.
[6] 刘伯红,吴思远,阎英,等.校企合作下大数据人才培养实践教学模式研究[J].软件导刊,2023,22(6):196-200.
[7] 孙开伟,邓欣,王进. 新工科背景下数据科学与大数据技术专业实践教学体系研究[J].高教学刊,2023,9(14):5-8.
[8] 石兵,熊盛武,饶文碧,等. 数据科学与大数据技术专业建设研究与实践[J].计算机教育,2021(4):88-92.
[9] 夏官梦,王健.新工科背景下计算机类人才培养的探索与实践[J].教育现代化,2020,7(48):26-29.
[责任编辑:雷 艳]
猜你喜欢
考试周刊(2016年79期)2016-10-13 23:35:16
考试周刊(2016年79期)2016-10-13 23:26:02
大学教育(2016年9期)2016-10-09 08:12:01
成才之路(2016年25期)2016-10-08 09:51:08
科技视界(2016年20期)2016-09-29 12:59:03
科技视界(2016年20期)2016-09-29 11:25:15
科技视界(2016年20期)2016-09-29 11:20:38
科技视界(2016年20期)2016-09-29 11:16:19
科技视界(2016年20期)2016-09-29 10:53:22
