
基于K-means算法的跨国零售商客户细分研究
2024-05-14 12:28崔雯李剑锋
中国商论 2024年9期
关键词:聚类算法
崔雯 李剑锋

摘 要:随着经济全球化及大数据技术的蓬勃发展,跨国零售商之间的竞争日益激烈,根据客户特征进行客户细分,协助客户进行个性化的服务体验,有利于跨国零售商实现精准营销和高效的客户关系管理。为了提高客户细分的精度,本文提出一种基于RFM模型的K-means聚类算法,使用簇内误方差(SSE)和轮廓系数(Silhouette Coefficient)计算聚类个数,优化K值选取。本文选取一家跨国零售商的数据进行实证检验,对细分后的结果进行特征分析,将客户划分为核心型客户、维护型客户和风险型客户三种类别,并为不同客户群体提供差异化营销策略,仅供参考。
关键词:K-means;RFM模型;跨国零售商;客户细分;聚类算法
本文索引:崔雯,李剑锋.<变量 2>[J].中国商论,2024(09):-040.
中图分类号:F724.2 文献标识码:A 文章编号:2096-0298(2024)05(a)--04
近年来,随着全球经济数字化浪潮的蓬勃兴起,高效的客户关系管理和优化配置客户资源的能力是跨国零售商生存和发展的关键性因素,激烈的市场竞争迫使跨国零售商逐步从刚性的产品导向转为柔性的客户导向。然而,不同类型的客户群体消费需求不同,若对所有客户均采用同样的营销策略,不仅不能提高客户的满意度,还会造成资源的巨大浪费。因此,跨国零售商要实现强竞争力的客户管理,就要科学地甄别不同客户群体的价值,定制基于客户价值差异的个性化营销策略。通过客户细分,跨国零售商可以挖掘客户的潜在需求,细分不同客户群体,对不同特征的客户采取个性化营销策略,从而针对客户进行合理的资源分配,提高营销效率。
1 相关研究
随着客户对跨国零售商的要求越来越高,跨国零售商逐步转变传统的营销模式,开始注重客户体验。在客户关系管理(CRM)领域的研究文献中,Kotler(1999)强调了一个关键理念:确立與企业最具价值的客户之间的持久联系是CRM战略的核心[1]。Wyner(1996)明确指出,企业80%的利润来自20%的客户[2]。跨国零售商的客户关系管理也遵循这一模式,如何对客户进行精准细分,识别不同价值类别的客户,成为跨国零售商需要积极思索的问题[3]。
在客户细分的方法上,K-means聚类算法作为一种基于划分的聚类算法,被应用于不同的聚类场景中。RFM模型及其改进模型凭借便捷高效和通俗易懂的优势,占据着客户价值细分领域的主导地位。许雪晶、林辰玮(2021)通过实验验证RFM模型与K-means方法的结合使用能够对企业客户价值进行有效细分[4]。陈丹红等(2022)在RFM模型的基础上,构建了融入客户信用指标C的RFMC模型,具有良好的实验效果[5]。靖立峥、吴增源(2020)引入了客户消费行为特征,构建了RFPAV客户细分模型[6]。但客户细分研究仍需解决以下问题:如果聚类数目过少,则聚类客户分配就不彻底,聚类效果不佳;如果聚类数目过多,则客户群体细分就琐碎,数据泛化性受到损害[7]。传统的K-means聚类算法存在人为设定K值的缺陷,结果易失真。因此,为提高客户细分的精度,本文使用簇内误方差(SSE)和轮廓系数(Silhouette Coefficient)计算聚类个数优化K值选取,提出基于RFM模型的K-means 聚类算法,按照价值类别的重要程度细分跨国零售商客户群体,并针对每一类细分群体提出个性化的营销建议。
2 RFM模型与K-means聚类算法
2.1 RFM模型
源自Arthur Hughes在美国数据库营销研究所进行的企业用户分析,RFM模型是一种关键的分类手段,用于评估客户的价值及其消费行为。该模型在客户关系管理(CRM)领域得到了普遍采纳,广泛应用于精细化管理和提升客户互动策略[8]。在客户行为分析中,R指标代表最近消费的时间跨度,具体而言,指的是自客户最后一次购买行为发生至今所经过的天数;F指标则用于衡量消费的频次,反映的是在特定时间范围内客户的购买次数;M指标反映了消费的货币价值,即在考察的时间段内,客户的总消费支出。这三个维度共同构成了客户价值评估的框架,有助于企业更精准地识别和理解客户行为模式。
在跨国零售商想要扩大自身业务,却无法一一查看每个客户的细节时,RFM有助于对客户的价值进行合理的评估,瞄准最有可能成为跨国零售商忠实客户的群体,重点关注最有价值的客户。
2.2 K-means聚类算法
K-means聚类算法是一种经典有效的无监督学习聚类算法,数据集通过距离度量被划分为多个类别群组,其中群组内部的样本表现出较高的相似性,而不同群组间的样本相似性则相对较低。该过程的关键步骤包括:首先,设定聚类中心的初始位置。给定一个包含n个数据项的数据集N,并从中挑选K个数据项作为各类别的初始聚类中心。其次,进行样本分配,通过计算每个数据项到这K个聚类中心的距离,并根据这些距离将数据项分配到与之最接近的聚类中心所在的类别中,从而构建不同的类别群组;再次更新聚类中心。令i=i+1,利用公式重新对每个形成的群组内的样本数据计算其平均值,并将此平均值视作更新后的群组中心,通过迭代这一过程,不断重复计算和更新的步骤,直至观察到群组中心的位置稳定,不再发生显著变化,得到最终的聚类分析结果。最后,评估聚类效果。
由于聚类个数K是一个人为设定的数字,不同的 K 值会产生不同的聚类结果,因此对于无监督的K-means聚类来说,两种广泛采用的评估技术分别是:簇内平方和(SSE)和轮廓系数(Silhouette Coefficient)。通过观察SSE在不同K值下的变化,可以找到其学习曲线的转折点,即“肘部”效应,这个点通常被认为是K值的较佳选择。同样地,轮廓系数的峰值指示着K值的最佳设定,当K值达到这两个指标中的任意一个时,可以认为找到了最佳的聚类数目[9]。
通过RFM模型对跨国零售商数据进行建模,采用K-means算法进行聚类,以深入理解客户的购买行为,并识别出各种客户群体的独特消费习惯。
3 客户细分实证分析研究
3.1 操作平台及数据获取
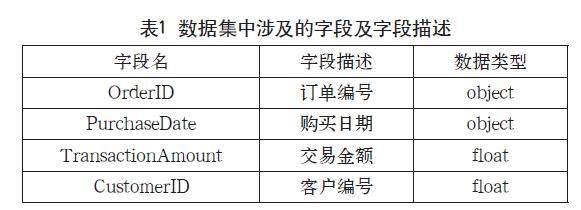
将K-means算法应用于跨国零售商的客户细分过程中,本文获取了一家跨国零售商在2023年4月11日—2023年6月10日的客户订单数据作为样本数据信息 ,共计1000条。研究涉及数据集中的字段:订单编号、购买日期、交易金额、客户编号,字段及其描述如表1所示。
3.2 数据预处理
首先,进行数据清洗,清除数据为零或空值等异常数据,处理重复数据;其次,将PurchaseDate字段中的时间戳字段类型转换成天数的形式,以方便计算R值指标;最后,结合RFM模型,对数据进行重新统计整理,分别从三个维度构建客户价值细分特征,RFM模型部分数据如表2所示。
为消除各指标单位不同而对聚类结果产生影响,在进行算法实验之前,需要对指标提取之后的数据集进行标准化处理,经过处理的数据符合标准正态分布,即均值为0,标准差为1。
标准化公式如(1),其中μ为所有样本数据的均值,σ为所有样本数据的标准差:
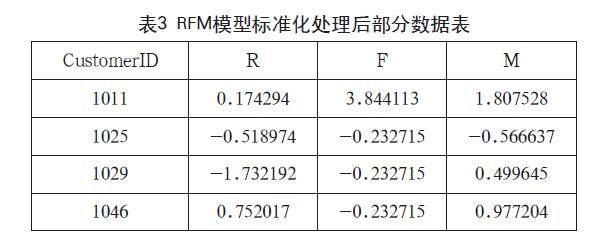
标准化后的部分数据如表3所示,指标R、F、M的数据全部被转换为无量纲的数据值。
3.3 K-means聚类算法实现
在聚类效果评估的众多指标中,簇内平方和(SSE)与轮廓系数(Silhouette Coefficient)被广泛认为是两个关键的性能度量。SSE,也称为簇内误差平方和,代表在多次迭代过程中,数据集中的样本点与各自群组中心之间的距离的平方和。通常,SSE与K值的关系图会呈现出类似手肘的形状,这个形状的转折点通常被认为指示着最优的K值。SSE的具体计算公式如下,其中x(i)表示样本点i,u(j)表示第j簇的质心:
轮廓系数是一个综合考量内聚度和分离度两种因素的度量,值域在[-1,1]。轮廓系数的值越接近1,表示样本聚类效果越好;越接近-1,则表示样本更应分类到其他的簇。轮廓系数公式如下,其中a(i)为样本点a(i)到同簇样本点的平均距离,b(i)为样本点a(i)到其他每个簇距离平均值的最小值:
本文运用sklearn.cluster模块中的KMeans类来执行K-means聚类分析,为了评估聚类效果,本文使用sklearn.metrics模块提供的silhouette_score函数来计算轮廓系数。通过这种方法,本文对K值从2~11进行了循环遍历,并根据每个K值绘制不同 K值下的簇内误方差和轮廓系数,如图1所示。
由图1的分析结果可以观察到,当K值设定为3时,簇内平方和(SSE)呈现出明显的“肘部”现象,同时轮廓系数达到了其峰值。这一现象表明,在考虑SSE和轮廓系数这两个评价标准的情况下,选择K值为3能够带来最佳的聚类性能。
4 聚类结果分析与营销建议
4.1 聚类结果分析
基于RFM模型和K-means聚类算法确定客户的种类归属K=3,将处理过的原始数据导入客户的聚类模型中,分别对跨国零售商的R、F、M指标进行聚类分析,得到3类数据,对每类数据的R、F、M值分别计算均值,所得字段差异性分析结果如表4所示。
文章通过对表4中3类群体聚类结果的R、F、M值进行分析,可以发现:
(1)类别1,此分类群体的R值较小,F、M值均较大,说明该客户群体在样本统计期内消费的次数较多,消费金额较大,且近期有过消费行为,对企业的贡献价值最大但占比最少,是价值最大的客户群体,属于“核心型客户”。
(2)类别2,此分类群体的R值最小,但F、M值相对较小,说明该客户群体近期有过消费行为,贡献了一定的消费金额,但样本统计期内消费的次数相对较少。虽然消费频率和消费金额都表现一般,但最后一次消费的时间较近,所以这类客户很可能是新得客户。因此,可将这类客户视为中等价值客户群,属于“维护型客户”。
(3)类别3,与其他两种客户类型相比,此群体的R值最大,F、M值较小,说明该客户群体在样本统计期内消费的次数较少,消费金额较少且长期没有过消费行为,是最不活跃和最没有价值的一类群体,具有较高的流失风险,属于“风险型客户”。
4.2 客户价值分类的策略分析
(1)核心型客户
核心型客户是跨国零售商运营收益的最大贡献者,因此需要投入大量精力和资源进行持续维护和大力发展。可以通过信息技术动态掌握客户的需求变化,结合其消费行为习惯为其提供优质服务,并优先推荐新产品。同时,保证价格优惠和产品质量,与客户建立良好的信任关系,最大程度地满足客户的消费期望,充分挖掘这类客户的消费潜力,提高客户增购复购的意愿。
(2)维护型客户
维护型客户虽然近期有过消费行为,但可能是新获得的客户,具有一定的流失风险,因此需要及时推送客户可能感兴趣的产品,促进客户关系进一步发展。同时,需要投入一定的资源探寻客户未能持续贡献价值的原因,清楚问题所在后,针对性地制定相应的客户关系管理策略来留存客户,提高客户的购买频率,从而有希望向核心型客户方向发展。
(3)风险型客户
风险型客户消费次数少且长期没有消费行为,极具流失风险,因此不必投入过多资源进行该类客户的关系维护。可以通过再次将该类客户细分的方式,针对不同结果制定不同的留存措施。对于再次细分后价值较高的客户,可以通过发放优惠券等方式进行留存维护。对于价值低的客户,可以选择直接放弃,从而让跨国零售商有限的资源产生最大效益。
5 结语
客户关系管理是跨国零售商保持竞争优势的前提和关键性因素,跨国零售商需要提高客户细分的准确性,以实现精准营销和有效的客戶关系管理。本文针对现有研究存在的传统K-means聚类算法人为设定K值易导致聚类结果偏差的不足,在方法上,引入簇内平方和(SSE)和轮廓系数(Silhouette Coefficient)对K-means聚类算法进行优化,通过对一家跨国零售商客户数据集预处理后,选取最佳K值,基于RFM模型和K-means聚类算法挖掘客户数据,将相似特征的客户归为一类,划分客户群体为核心型客户、维护型客户和风险型客户三种类别,并为不同客户群体提供了差异化的营销建议,从而帮助跨国零售商实现精准营销。
参考文献
Kotler Philip. Kotler on marketing: how to create, win, and dominate markets[M]. Free Press,1999.
Wyner G A. Customer profitability: linking behavior to economics[J]. Marketing Research,1996, 8(2): 36-38.
刘潇,王效俐.基于k-means和邻域粗糙集的航空客户价值分类研究[J].运筹与管理,2021,30(3):104-111.
许雪晶,林辰玮.基于RFM的电商数据客户价值细分实例研究[J].长春师范大学学报,2021,40(4):60-69.
陈丹红,彭张林,万德全,等.众包平台用户价值识别与细分: 基于改进的RFM模型[J].计算机科学,2022,49(4): 37-42.
靖立峥,吴增源.基于改进K-means算法的电子商务客户细分研究[J].中国计量大学学报,2020,31(4):482-489.
杜科,邓佳雯,陈继红.改进RFM模型在房地产客户细分中的研究及应用[J].电脑知识与技术,2018,14(19):243-245+251.
HUGHES A. Strategic Database Marketing: The Master Plan for Starling and Managing A Profitable Customer-Based Marketing Program[M]. New York: McGraw-Hill Professional, 1994:231-238.
巫芯宇.基于FTRM模型和K-means算法的大学生知识付费产品使用行为研究[J].西南大学学报(自然科学版),2021,43(6): 195-204.
猜你喜欢
科技创新与应用(2017年6期)2017-03-23
中国民族民间医药·下半月(2017年1期)2017-03-07
无线互联科技(2016年14期)2017-02-06
软件导刊(2016年12期)2017-01-21
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年8期)2016-05-19
科技视界(2016年8期)2016-04-05
湖南大学学报·自然科学版(2015年8期)2015-09-06
电脑知识与技术(2015年10期)2015-05-29
电子技术与软件工程(2015年6期)2015-04-20
