
K—Means聚类算法在MapReduce框架下的实现
2017-01-21 14:51杨健兵
软件导刊 2016年12期
杨健兵

摘 要:MapReduce是一种编程模型,这种编程模型编程简单,不必关心底层实现细节,可用于大规模数据集的并行计算。K-Means是一种简单、基本的数据挖掘聚类方法,它将对象组织成多个互斥的组或簇。针对K-Means的特点,给出了MapReduce编程模型下K-Means的实现方法。实验结果表明,MapReduce编程模型下的K-Means算法部署在Hadoop集群上运行具有较好的性能。
关键词:K-Means;MapReduce;数据挖掘;聚类算法
DOIDOI:10.11907/rjdk.162043
中图分类号:TP311
文献标识码:A文章编号:1672-7800(2016)012-0030-03
0 引言
伴随着计算机技术的不断进步和互联网技术在各领域的深入发展,海量数据在各行业中不断产生。由于传统的数据挖掘算法往往运行在一台普通的计算机上,但面对大量的数据尤其是海量数据时,传统的计算机在计算能力、处理速度、存储容量、带宽速度等多个方面往往表现出力不从心。面对这些问题,云计算提出使得这些问题迎刃而解。云计算是基于网络平台上的一种计算模型,可以在多台计算机上同时平行运行。它的模型可以由一系列普通计算机加上网络组成,对计算机硬件要求相对较低,但其性能可达到普通计算机的若干倍以上。这种计算模型为数据挖掘领域开辟了一条新路径。
MapReduce模型[1]是美国谷歌公司提出的一种分布式并行编程模型,其主要功能是可以利用大量计算机处理海量的数据。对于MapReduce这种编程模型,Map和Reduce是其主要思想,通过Map和Reduce,编程人员可以在不通晓分布式并行编程的情况下,将自己的程序运行在分布式系统上。通过Apache开源社区Hadoop项目[2],程序设计人员实现了该模型,使得该模型进行分布式并行计算成为可能。
根据文献记载,多种数据挖掘算法已经在云计算编程模型MapReduce上实现。冀素琴等[3]提出了基于MapReduce的K-Means聚类集成,谢雪莲等[4]提出了基于云计算的并行K-Means聚类算法研究,黄斌等[5]提出了基于MapReduce 的数据挖掘平台设计与实现,毛典辉等[6]提出了基于MapReduce的Canopy-Kmeans改进算法。本文结合各自算法的思想与MapReduce 的运行机理,提出K-Means聚类算法在MapReduce框架下的实现。在MapReduce框架下,K-Means聚类算法的使用范围由单机扩展到云计算平台,在面对海量数据时,极大地减少了K-Means聚类算法的运行时间,显著地提高了运行效率。
1 MapReduce编程模型
MapReduce编程模型采用分治法的思想,在主节点管理下,MapReduce编程模型将海量的数据分发给各分节点共同完成,各节点对中间结果进行分类、排序、整合并得到最终结果。简言之,MapReduce就是任务分解与结果汇总。
1.1 MapRedue集群结构
MapReduce任务需由几个部分协作完成。它主要有4个部分组成:Client客户端、JobTracker、TaskTracker以及分布式文件系统。
1.2 MapReduce执行过程
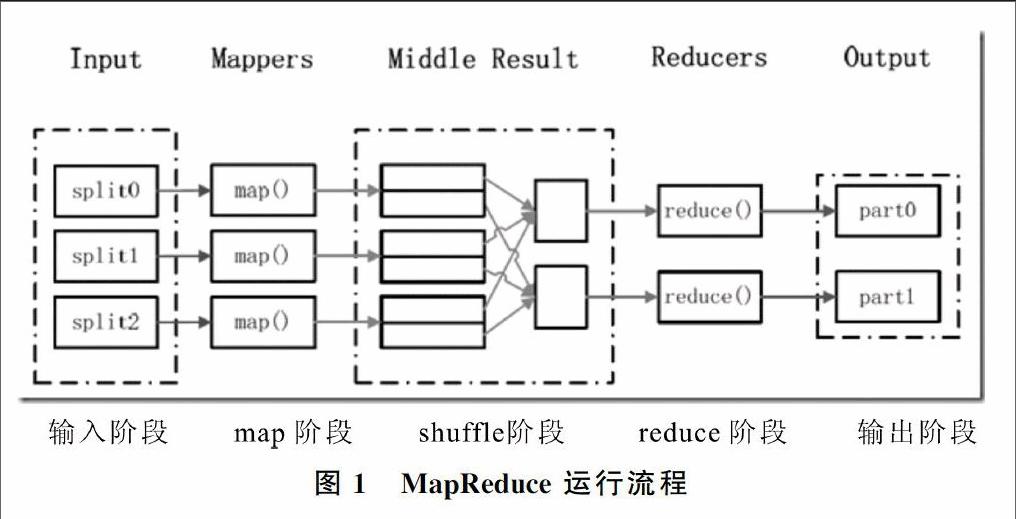
在Hadoop中,有两个机器角色用来执行MapReduce任务,一个是JobTracker,另一个是TaskTracker。JobTracker的作用是执行调度工作,在Hadoop集群中有且只有一个,TaskTracker的作用是执行任务,在Hadoop集群中有若干个。图1描述了MapReduce的运行机制,在数据输入阶段,输入文件按照一定的标准进行分片;在Map阶段,在JobTracker的统一调度下,多个TaskTracker完成Map运算任务并生成中间结果;在Shuffle阶段完成中间计算结果的排序和分类;在Reduce阶段,在JobTracker统一调度下,多个TaskTracke完成Reduce任务;Reduce任务完成后通知JobTracker以产生最后的输出结果。
2 K-Means聚类算法实现
2.1 K-Means聚类算法
K-Means算法是很典型的基于距离的聚类算法,它将对象组织成多个互斥的组或簇,一般采用欧式距离作为评价指标,即认为两个对象的距离越近,其相似度就越大。假设数据集D包含n个欧式空间中的对象。聚类的目的是将D的对象分配到k个簇C1,…,Ck中,使得对于1≤i,j≤k,Ci∈D且Ci∩Cj=¢。聚类划分以簇内高相似性和簇间低相似性为目标。
设p是空间中的点,表示给定的数据对象;ci是簇Ci的中心,其中p和ci都是多维数据。对象p∈Ci与该簇的代表ci之差用dist(p,ci)度量,其中dist(x,y)是两个点x和y之间的欧式距离。簇Ci的质量可以用簇内变差度量,它是Ci中所有对象与中心ci之间的误差平方和,定义为:
E是数据集中所有对象的误差平方和。
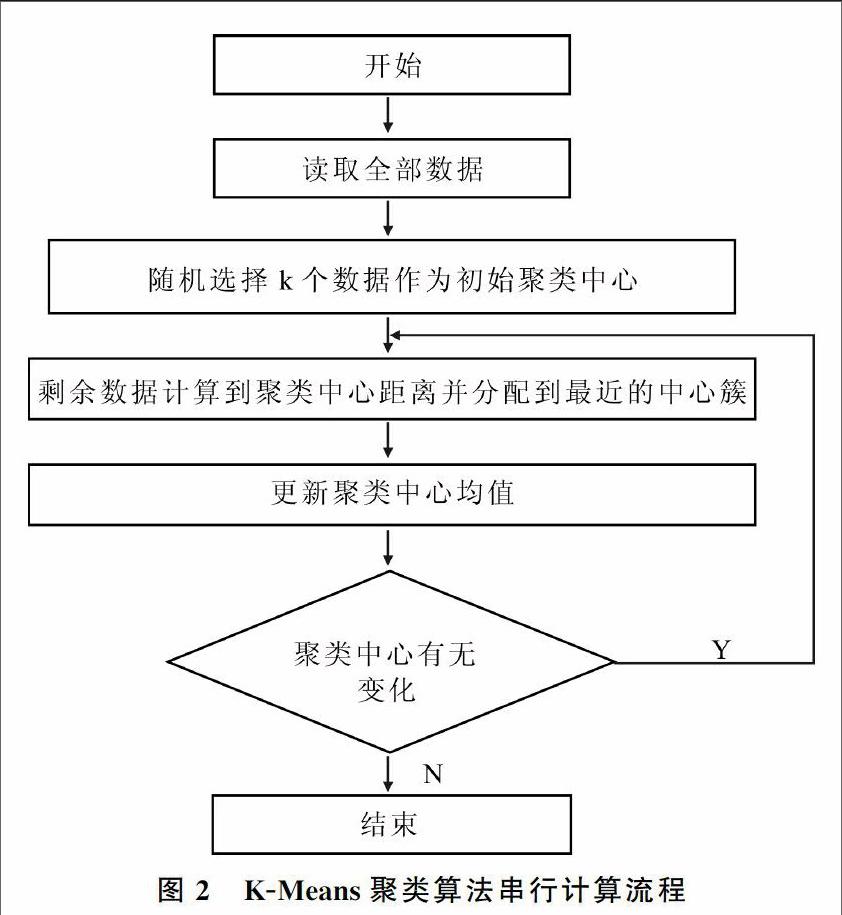
根据给定的公式,K-Means算法的具体实现过程如下:在初始化过程中,在数据集中任意选择k个对象,每个对象代表该簇的中心点,对于其余的每个对象,根据它们与各簇中心的距离,将该对象划分到最近的簇。然后对于k个簇,重新计算其均值。更新后的均值作为该簇新的簇中心。迭代继续,直到分配稳定。图2为K-Means聚类算法的串行计算流程。
K-mean均值的算法复杂度为O(nkt),其中n是对象总数,k是用户指定的簇数,t为迭代次数。通常情况下k< 2.2 算法实现 K-Means聚类算法在MapReduce模型下处理的基本思路如下:对K-Means的串行计算过程执行MapReduce计算,Map阶段完成每个记录到簇中心点距离的计算,并标记到每个记录所属的类别;在Reduce阶段,根据Map函数得到的结果进行分类排序即可计算出新的聚类中心,供下一轮Map使用,如果本轮Reduce得到的聚类中心与上轮相比变化小于给定的阈值则算法结束,反之进行新一轮的MapReduce过程。
2.2.1 Map函数设计
Map阶段的主要任务是通过计算每个记录到簇中心点距离,并将该记录标记所属的簇。在进行Map计算之前,MapReduce会根据输入文件计算输入数据片分片,每个数据片针对一个Map任务,输入数据片存储的并非数据本身,而是
2.2.2 Reduce函数设计
在Reduce阶段,根据Map函数得到的中间结果将相同类别的数据组成一个簇,并计算出新的聚类中心,供下一轮Map使用。输入数据以(key, value)对的形式展示,key为聚类所属类别,value为该簇中记录向量,所有key相同的数据送给一个Reduce任务,累计计算key相同数据的均值,得到新的聚类中心。输出结果
2.3 算法时间复杂度分析
在MapReduce框架下处理K-Means聚类算法,数据预处理阶段,通过Hadoop平台下的分布式文件系统,把要处理的数据先存储在其中,然后将数据根据分块原则分别存储在不同的节点上。在Map计算阶段,通过将相应的数据块分配给Map任务进行计算。如果每个节点完成p个Map任务,那么其时间复杂度为O(nkt/p)。这样可大大提高计算效率和计算速度,节省算法运行时间。
3 实验结果
通过实验,对K-Means聚类方法在MapReduce框架下的实现效果进行了展示和评估。
3.1 实验环境
该实验在南京工业大学云平台上进行,平台由一系列IBM服务构建。其中管理节点1个,计算机节点16个,网络采用万兆网络,操作系统采用RedHat Linux。在硬件配置上,每一个节点的CPU 采用Intel Xeon 2.0GCPU,8G内存,100G硬盘,软件配置Hadoop 。
3.2 实验结果
单个样本为15个整数,分别生成106(54M)、107(540M)、108(5400M)个样本作为数据集。K-Means算法的实验结果如图4、图5、图6所示。
从图4可看出,并行运行时间远远地大于单击运行时间。这是由于MapReduce进行并行计算之初,其初始化过程需要一定的时间,耗费一定的机器性能。同时由于该文件只有54M,只需要分配给一个Map任务去执行。因此对于数据量比较少的数据,单机运行的效率反而高、时间耗费反而少。
从图5可看出,随着数据量的增多,MapReduce的优势慢慢地凸显出来。根据理论计算,540兆数据可以分为9个分片,通过分析,如果节点数量比较少的时候,MapReduce的优势不但不够明显,反而还不如单机K-Means计算,但是随着节点逐渐增多,MapReduce的计算优势逐渐显露起来,并且计算时间逐渐减少。但是当节点超过5个时,节点数目已经饱和,所以运行时间基本保持不变。
从图6可看出,当数据量非常大时,MapReduce的绝对优势一览无遗,并且随着集群中节点数量的增加,运行时间逐渐减少。当节点到达一定数目时,MapReduce运行算法达到它的极限值,该任务的运行时间达到最小。
4 结语
随着互联网业务的不断发展,每天都有大量的数据产生,对于产生的数据用数据挖掘的方法对它进行分析并提取有益的信息已经成为大家关注的重点。在源源不断的数据产生以后,可以在MapReduce框架下采用K-Means方法对这些数据进行聚类。
本文提出了面对大量数据时如何使用MapReduce框架去处理这些数据的基本思路。实验表明,该解决方法在处理大量数据时可以极大地提高运行速度和效率。
参考文献:
[1] DEAN J,GHEMAWAT S.MapReduce simplified data processing on large cluster[J].Communication of the ACM,2006,51(1):107-113.
[2] APACHE HADOOP. Hadoop[EB/OL].http://hadoop.apache.org.
[3] 冀素琴,石洪波.面向海量数据的K-Means聚类优化算法[J].计算工程与应用,2014,50(14):143-147.
[4] 谢雪莲,李兰友.基于云计算的并行K-Means聚类算法研究[J].计算机测量与控制,2014,22(5):1510-1512.
[5] 黄斌,许舒人,蒲卫.基于MapReduce 的数据挖掘平台设计与实现[J].计算机工程与设计,2013(2):495-501.
(责任编辑:孙 娟)
猜你喜欢
电力与能源(2017年6期)2017-05-14
现代电子技术(2016年23期)2017-01-12
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
