
基于K?均值与AGNES聚类算法的校园网行为分析系统研究
2017-01-12 09:40茆汉国
现代电子技术 2016年23期
茆汉国


摘 要: 校园网中的服务器存有海量的用户访问日志文件,记录了校园网用户的访问信息。鉴于此,提出了一种基于聚类算法的校园网用户行为分析技术,设计和实现了数据预处理系统,对日志数据进行一系列的清理、合并,标准化等预处理,使其更好地适应后续的聚类操作。将预处理后的数据作为输入数据,分别实现了三种常用的聚类算法对日志数据进行聚类,然后从聚类准确率和聚类速度两个角度对现有算法进行优化。为了提高聚类准确率,提出了用K?均值算法结合AGNES算法的方法;为了提高聚类速度,在MPICH2平台上设计和实现了并行K?均值算法,实现多机并行分析,最后简单介绍了校园网行为分析系统的应用。
关键词: 校园网; 行为分析; 聚类算法; MPICH2
中图分类号: TN98?34; TM417 文献标识码: A 文章编号: 1004?373X(2016)23?0116?05
Research on campus network user behavior analysis system
based on K?means and AGNES clustering algorithm
MAO Hanguo
(Information Construction and Management Office, Nanjing Institute of Technology, Nanjing 211167, China)
Abstract: The server in campus network has massive user access log files, and records the access information of the campus network users. In view of this issue, a campus network user behavior analysis technology based on clustering algorithm is proposed. The data preprocessing system was designed and implemented. The log data is conducted with a series of cleaning, merging, standardization and preprocessing to suit for the subsequent clustering operation. The preprocessed data is taken as the input data to cluster the log data by means of 3 commonly?used clustering algorithms respectively, and then, the available algorithms are optimized in the aspects of clustering accuracy and clustering speed. In order to improve the clustering accuracy, a method of combining AGNES algorithm with K?means algorithm is proposed. In order to improve the clustering speed, the parallel K?means algorithm was designed and implemented on MPICH2 platform to realize the multimachine parallel analysis. The application of the campus network user behavior analysis system is introduced simply.
Keywords: campus network; behavior analysis; clustering algorithm; MPICH2
0 引 言
当前,为了更好地管理校园网,各个高校会在校园网中安装各种硬件设备,记录校园网用户的访问信息。日积月累,校园网中就积累了大量的用户访问记录[1]。但是,这些硬件设备自带的软件只能用来记录访问信息,但却无法进一步挖掘存在于这些数据中的潜在关系,无法以现有数据预测未来的发展趋势,无法将隐藏在数据背后的知识挖掘出来。同时,校园网上存在的不良信息、系统漏洞、病毒等问题对校园网系统产生了巨大的威胁[2]。
当前的网络环境迫使管理者对校园网的安全性、稳定性和服务质量提出更高的要求,在校园网提供优质的网络服务的同时,还要能够保护网络和用户系统的安全[3]。因此,为了保障校园网能通畅运行,必须建立一种有效的校园网分析机制,从不同角度分析校园网的运行状态,然后根据实际情况进行调整。Web日志中记录了用户的访问信息,保存有大量用户的访问规律。通过设计一种Web日志分析软件,分析Web日志中的数据,了解校园网用户的访问特点和规律,然后根据分析的结果调整和优化校园网结构,更好地为校园网用户进行服务。
1 校园网行为分析系统的总体设计
根据数据挖掘技术的操作流程,系统分为以下几个部分:数据采集,数据预处理,数据挖掘,结果分析。系统的结构如图1所示。
图1 校园网行为分析系统的结构
2 数据预处理的设计与实现
2.1 数据采集
校园网用户行为分析系统的数据来自于某大学公网访问流量控制服务器,其位置处于校园网和公网出口路由之间。流控服务器上的访问日志有:RPT_PUR,RPT_LUR,RPT_TR,RPT_MALUR,RPT_MEDIA等文件,其中RPT_TR为主日志文件,记录了全部的公网访问信息,所以将该日志作为本系统的原始数据源[4]。
2.2 数据预处理
2.2.1 清理脏数据
对于行为分析系统来说,并不需要关心日志文件中的所有字段,而只需要对其中一部分进行处理。因此,只需要提取以下几个字段:“客户端IP”、“请求访问时间”、“网站域名”、“上行流量”、下行流量等这些字段[5]。另外,对于字段不完整的数据条目,予以舍弃。
2.2.2 数据归并
根据校园网日志文件做用户的行为分析时,有两个数据是至关重要的。第一个就是某个网站的访问次数,另一个是该网站的访问流量。其中访问流量还包括上行流量和下行流量两部分。由于不分别考虑上行流量和下行流量,可将二者相加,并将其统一命名为流量[6]。然后将相同网站进行归并,这样根据数据条目的多少和每个数据条目中的访问流量,可以得到每个网站的总访问次数和访问流量。
2.2.3 数据的标准化
数据标准化的形式有很多,根据整理后的校园网日志文件的特点,采用极差归一化方法。由于相同字段中,数据之间的数量级差异比较大,如果单纯的使用极差归一化方法,会出现很多接近0的数据,这样会降低后续聚类操作的准确率[7]。所以需要根据实际情况对现有的极差归一化方法进行改进,对数量级差进行级放大,具体的操作过程如下:
(1) 设数据集中需要计算的字段数量为[n,]首先获取每个字段的最大值,分别记为[xmaxi(i=1,2,…,n);]
(2) 比较[xmaxi]每个值的数量级,选择数量级最小的值分别记为[xmaxs;]
(3) 对各个字段使用极差归一化的方法对数据集进行标准化,但在计算每个值[xi]与最小值[xmin]的差时,都乘以[xmaxs]对应的数量级[Os],即:
[xinew=(xi-xmin)×Osxmax-xmin] (1)
经过极差的级放大后,得到的数据处于同一个数量级,这为后续的聚类操作的准确性提供了保障。
2.2.4 处理效果评价
在校园网日志文件经过清理脏数据、数据归并和数据标准化之后,原始数据集数量由原来的7 000万条变为现在的85万条,并且数据形式也更符合后续聚类操作的要求。数据预处理工作有效地缩减了原始数据规模,并为后续聚类操作做了铺垫。
3 聚类算法的设计
3.1 算法的选择
聚类算法的形式有很多种,不同的聚类算法适合不同的原始数据集。例如K?均值法适合大数据集,K?中心点算法适合小数据集,BIRCH算法适用于数据分布呈凸形及球形的数据集等。根据校园网日志数据的情况,分别选择K?均值算法,AGNES算法和DBScan算法对数据集进行分析,并对比三种算法的执行效率。
3.2 K?均值算法的实现
3.2.1 算法的输入
算法的执行过程如下:首先,随机从原始数据中选出[k]个对象,设置为[k]个簇,每个簇的平均值就是这个对象的值,把这个平均值又叫做质心或中心。对于剩余的对象,根据每个对象与每个簇中心的距离大小,把他们分到最近的簇中,这个过程完成后重新计算各个簇的平均值[8]。此过程需不断重复,直至准则函数收敛,或达到指定的迭代次数为止。通常采用平方误差准则函数,即:
[Je=i=1kx∈CiX-mi2] (2)
式中:[Je]是数据集中所有数据对象的平方误差的总和;[X]代表数据对象;[mi]代表簇[Ci]的平均值。
对于两个数据对象之间的相似度,可以通过他们间的相异性来定义和描述。一般而言,在计算两个对象之间的相异性时,采用两个对象之间的距离来计算。在计算簇中的个体对象与簇中心的距离时,通常采用欧式距离,其计算公式为:
[d(x,y)=k=1nwk(xk-yk)2, 1≤k≤n] (3)
式中:[x=(x1,x2,…,xn)]和[y=(y1,y2,…,yn)]是两个[n]维的数据对象;[m=(m1,m2,…,mn)]则代表每个属性在计算相异度时所代表的权重,不同的权重设置就会产生不同的相异度,从而影响到簇的划分。
3.2.2 算法的过程
K?均值算法的过程如下所示:
输入:簇的数目[k,]包含[n]个对象的数据集
输出:[k]个簇
过程:
(1) 从数据集中随机选择[k]个对象,将每个对象都作为一个簇的初始中心;
(2) 分配每个剩余对象到离他最近的簇中心所在的簇中;
(3) 计算每个簇中所有对象的均值向量,使其作为新的簇的中心;
(4) 重复步骤(2),步骤(3)过程,直到[k]个簇的中心不再发生变化或者准则函数收敛;
(5) 返回各个聚类的中心和成员。
K均值算法的时间复杂性为[O(tkn),t]代表迭代次数,[k]代表聚类数,[n]代表样本数。
3.3 AGNES算法的实现
3.3.1 算法的输入
AGNES算法的输入变量只有1个,就是最终簇的个数[k,]这点与K?均值算法一样。算法最初将数据集中的每个对象都看成一个簇,通过特定的规则将这些簇逐步合并,直到簇的数目达到要求。在这里规定:在簇[A]中的一个对象和簇[B]中的一个对象之间的距离是所有属于不同簇的对象之间最小的,将[AB]合并。按照这个规则,不断地合并现有的簇,直到簇的个数等于变量[k]后,算法结束。
3.3.2 算法的过程
AGNES算法的过程如下:
输入:簇的数目[k,]包含[n]个对象的数据集
输出:[k]个簇
过程:
(1) 设置每个对象都作为一个初始簇;
(2) Repeat;
(3) 以两个簇中最近的数据点为标准找到最近的两个簇;
(4) 将两个簇合并生成新的簇的集合;
(5) Until达到要求的簇的数目。
AGNES算法的时间复杂性为[O(n2),n]代表样本数。
3.4 DBScan算法的实现
3.4.1 算法的输入
DBScan算法是典型的基于密度的聚类方法。除了数据集,DBScan算法的输入有两个:半径[e]和最少数目MinPts。DBScan算法的核心思想是,对于簇中的每一个对象,在给定的半径[e]邻域内,包含数据对象的个数必须大于给定的最少数目MinPts。
3.4.2 算法的过程
DBScan算法的过程如下所示:
输入:半径[e,]包含[n]个对象的数据集,最少数目MinPts
输出:生成达到所有密度要求的簇
过程:
(1) Repeat;
(2) 从数据集中找到一个未处理的点;
(3) IF找到的点是核心点,THEN找出全部从该点密度可达的对象,形成一个簇;
(4) ELSE找到的点是边缘点(非核心对象),从本次循环中跳出,继续寻找下一个点;
(5) UNTIL所有的点都被处理。
DBScan算法的时间复杂性为O(nlog n),其中n代表样本数。
3.5 几种聚类算法执行结果对比
3.5.1 效率对比
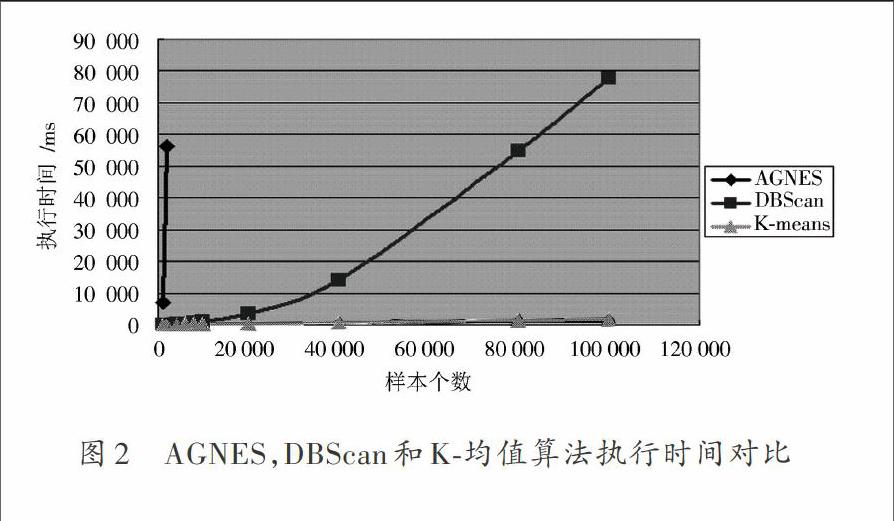
在样本数达到4 000时,AGNES算法的执行时间已经是无穷大了,所以AGNES不适合数据量较大的聚类。而DBScan算法和K?均值算法的执行时间相对较快,特别是K?均值算法,在簇数远小于数据集样本个数时,K?均值算法的时间复杂性为[O(n)。]三种算法的执行效率如图2所示。
从图2得出的结论:K?均值算法的执行效率最高,远远优于另外两种算法。而AGNES算法的执行效率非常低,不适合在大数据集上进行聚类运算。
3.5.2 准确率对比
AGNES算法和DBScan算法在聚类准确率上效果比较好,而K?均值算法的聚类准确率跟初始聚类中心的选定有很大关系。而在实际操作中,能正确地选取聚类中心是一件很困难的事情,因为在聚类结果出来之前,很难预先确定聚类中心的大概位置。所以,如果要在实际中使用K?均值算法,一定要解决这个问题,让初始聚类中心贴近最终的聚类中心,然后才能得到满意的聚类结果。
4 K?均值算法的优化
4.1 优化方案
因为K?均值算法的执行效率会比另外两种聚类算法高过很多,在数据量较大时这种效率优势会更加明显,所以决定在K?均值算法的基础上进行优化。设计优化的方案有两种,第一种是采用AGNES算法和K?均值算法结合的方式,这样既能利用AGNES算法提高聚类准确率,又能兼顾K?均值算法的高效率。第二种优化是利用MPICH2接口设计一种并行的K?均值算法,让它在多机的环境下执行,这样可以显著地提高执行效率。
4.2 AGNES算法与K?均值算法的结合
使用AGNES算法和K?均值算法结合的方式,在执行K?均值算法前,从原始数据中随机抽出一部分数据,并在这些抽出来的数据上运行AGNES算法,然后将运行结果得到的聚类中心当做K?均值算法的初始聚类中心。具体过程如图3所示。
4.3 K?均值算法并行实现
4.3.1 并行K?均值算法的实现
分析K?均值算法可以看出,算法中每次迭代的计算只要分为两个步骤:
(1) 计算各个数据对象与各个类中心之间的距离;
(2) 产生新的聚类中心时,需要对每个类中所有数据求和并取平均值。
随着数据量的增加而导致计算时间延长的处理阶段主要是第一步,因此考虑并行处理这一过程来提高聚类效率,降低算法对内存的较高要求。
采取基于主从(Master/Slave)模式的数据并行策略。主程序运行在一个主节点上,负责分配数据和汇总从其他节点产生的聚类结果,生成新的聚类中心。从程序运行在其他节点上,处理主节点分配给自己的一部分数据集。主从节点之间的通信通过MPICH2平台实现,所以写程序时不用关注具体的并行通信细节,在很大程度上方便了编程。
首先,主节点先将数据集划分后,连同现有的聚类中心集一并发给各个从节点,每个节点接收到的数据集大小为整个数据集的大小/从节点数。各个从节点将接收到的数据集进行聚类,并把聚类结果返还给主节点。这时主节点等待各个从节点的数据,一旦将所有从节点的聚类结果收齐后,主节点计算各个类的新的聚类中心,然后和原聚类中心通过计算误差平方准则函数进行比较。如果原来的聚类中心和新的聚类中心之差小于给定的阈值,算法结束。否则主节点将重新划分数据集并分配给各个从节点,开始新的一次迭代过程。
4.3.2 执行结果
把多台配置为Intel Core i3 3.2 GHz,4 GB RAM的计算机用100M/10M自适应网卡连接起来,在系统上安装好MPICH2构成一个机群系统。使用C++实现这个算法,在这个机群系统的基础上完成算法的验证实验。通过实验可以看出K?均值并行算法具有以下几个特征:
(1) 当[N=100K,p=2]时,并行算法的加速比是小于1的。也就是说,由于数据量不够大,数据分块过多,各节点获分配的数据量比较少,并行计算粒度过小,导致计算与通信比值下降,从而造成并行算法的执行时间不如串行算法。
(2) 当[N>100K][且2≤p≤4]时,并行算法在绝大多数情况下加速比大于1。当输入数据规模增大,每个节点的运算量增加时,并行算法的优势就体现出来了,这时并行算法的执行时间要优于串行算法。
(3) 当[N>100]K且[p=3]时,算法的加速比达到了最高值,即3为理想节点数。当再增加节点数目,因为各个节点之间的通信量增加,加速比开始下降,当[p=5]时,加速比开始小于1,也就意味着并行算法的效率小于串行算法。
4.3.3 提高并行性能的方法
通过对K?均值并行算法的设计与实现,发现在PC机群网络并行的环境下,要提高并行算法的执行效率,需要注意以下两点:
(1) 计算机节点数人。在计算机节点数目较少时,增加计算机节点数会提高并行度,提高并行算法的执行效率。
(2) 应该尽量加大每个节点的预算量并减少节点间的通信,即采用粗粒度的并行算法。
5 系统的应用
5.1 统计分析
将预处理后的日志文件以散点图的形式显示出来。可以看到,几乎99%以上的数据都集中在左下角,这表明校园网用户在进行网络访问时,对于大部分的网站用户访问流量低且点击次数少。这个统计结果也是符合事实的,因为人们上网时,只有个别非常有名的网站,会让用户长时间访问而造成大量的上行和下行流量,或者让用户频繁地访问。随着搜索引擎的普遍使用,用户对于某些信息的搜索会查询大量的网站,对于大部分网站来说,用户只会访问有限的几次,甚至绝大部分网站用户在很长一段时间内只会访问一次,说明校园网用户的访问呈现出流量少和访问次数少的特点。
校园访问的网站点击流量和次数分布如图4所示。
5.2 聚类分析
应用本文研发的系统对校园网日志文件进行聚类分析,然后得出校园网用户的网络行为。为了让聚类既准确又快速,采用AGNES+K?均值合并算法,同时K?均值算法部分采用并行实现。通过分析,本系统可以通过分析访问日志而得出各类网站的访问状况,进而得知校园网用户的上网行为。可以知道,校园网用户访问最多的网站是bit.edu.cn,而访问量最大的网站是几个视频网站。利用本系统对校园网日志文件进行聚类,其结果有助于分析校园网用户的上网行为,了解他们的喜好。校园网管理者可以根据分析的结果对校园网结构进行调整,从而更好地为校园网用户服务。
6 结 论
本文介绍了一种基于聚类算法的校园网用户行为分析技术,在分析日志文件的过程中,系统采用的核心算法为聚类算法。首先设计了系统的总体结构,提出了分析模型,然后设计并实现了对校园网日志数据进行预处理的模块,通过处理脏数据,数据归并,数据标准化等操作筛选出有效的数据,为数据挖掘做准备。进一步,根据当前的校园网实际运行情况,提出了校园网行为分析系统的创建意义,然后设计并实现了K?均值,AGNES,DBScan几种聚类算法,并对K?均值算法进行优化。最后介绍了本系统的应用方法,并根据系统的执行结果分析了校园网用户的上网行为。
参考文献
[1] 丁青,周留根,朱爱兵,等.基于K?means聚类算法的校园网用户行为分析研究[J].网络新媒体技术,2010,31(6):74?80.
[2] 马艳英.基于遗传算法的Web文档聚类算法[J].现代电子技术,2016,39(1):148?152.
[3] 罗军锋,洪丹丹.基于数据抽样的自动K?means聚类算法[J].现代电子技术,2014,37(8):19?21.
[4] 步媛媛,关忠仁.基于K?means聚类算法的研究[J].西南民族大学学报(自然科学版),2009(1):198?200.
[5] 王燕,吴灏,毛天宇.基于K?中心点聚类算法的论坛信息识别技术研究[J].计算机工程与设计,2009,30(1):210?212.
[6] 刘兴光.基于云计算的大型校园互联监测系统设计[J].现代电子技术,2015,38(24):90?93.
[7] 张建文,徐琼,王强.基于MPI环境的并行程序设计[J].东华理工学院学报,2007,30(1):81?84.
[8] 吕元海,孙江辉,马龙.基于OracleRAC的校园网数据库集群系统设计与实现[J].现代电子技术,2016,39(4):72?75.
猜你喜欢
甘肃教育(2020年18期)2020-10-28
电子制作(2019年10期)2019-06-17
电子制作(2017年8期)2017-06-05
无线互联科技(2016年14期)2017-02-06
软件导刊(2016年12期)2017-01-21
电子技术与软件工程(2016年20期)2016-12-21
经营者(2016年12期)2016-10-21
电脑知识与技术(2016年8期)2016-05-19
科技视界(2016年8期)2016-04-05
电子设计工程(2015年17期)2015-02-27
