
基于结构感知和全局上下文信息的小目标检测
2024-05-11 03:35李钟华林初俊朱恒亮廖诗宇白云起
计算机工程与应用 2024年9期
李钟华,林初俊,朱恒亮,廖诗宇,白云起
福建理工大学计算机科学与数学学院,福州 350118
近几年来,小目标检测作为计算机视觉领域的基本任务之一,在遥感、无人机、自动驾驶等领域都起到了重要作用。随着深度学习的不断发展,研究者们提出了许多优秀的检测算法[1-5],并且取得了较好的检测结果。但是,对于小目标来说,由于图像中的像素信息过少,包含的判别性特征不足,导致这些检测方法在复杂场景下效果不佳,容易出现漏检、误检等问题。因此,针对复杂场景下设计高效的小目标检测算法仍然面临着巨大挑战。
为了解决复杂场景下的小目标检测问题,研究者们从多种角度出发提出了大量优秀的检测方法。为了更好地捕捉目标特征,利用特征融合设计网络模型[6-7]来提升小目标检测的性能受到了广泛的关注。这些研究大多借助多尺度特征的FPN网络,把高层的语义特征保留下来,并且与低层的几何特征结合,以便获得高分辨率、强语义的特征。此外,一些研究[8]从卷积神经网络本身的缺陷出发,设计更好的网络架构来提升性能。虽然这些方法在一定程度上可以提升复杂场景下小目标检测的准确性,但是没有充分利用图像中的全局上下文信息,而且很少关注小目标本身的结构特征,因此在复杂场景中检测效果并不令人满意。
受视觉注意力[9-10]的启发,人眼往往更多地关注图像中重要的感兴趣区域。受此启发,本文提出一种基于多尺度结构感知和全局上下文信息的小目标检测算法。首先,为了获取丰富的特征信息,在原有的模型基础上添加了一层小目标层。同时为了使网络能够融合不同尺度下目标携带的细节信息,并获得更丰富的结构特征,本文提出一种多尺度结构感知模块(multi-scale structure perception,MSSP),该模块能有效地使模型定位到目标本身,更加关注目标本身的结构,而不是背景等一些噪声信息。其次,为了充分利用全局特征,搭建上下文信息的桥梁,提出一种全局上下文信息模块(global context module,GCM)。该模块能有效建立特征图中当前通道和其余通道之间的置信程度,通过一系列的交互计算,网络可以感知到一些比之前更加有用的特征,从而改进小目标携带特征信息较少的问题。此外,本文还从小目标像素点少可能造成梯度爆炸这一问题出发,提出了一种新的带权重的损失函数W-CIoU(weight CIoU)。该损失函数更加适用于小目标检测,它不仅一定程度上解决了梯度爆炸的问题,还保证了网络训练的收敛速度。在VisDrone 无人机小目标数据集以及TinyPerson数据集进行了大量实验,结果表明本文提出的方法以及损失函数在小目标检测的各项指标上都比基线模型优秀,也验证了提出的网络模型对小目标检测有更好的检测效果。
本文的主要贡献包含以下3个方面:
(1)提出一种多尺度结构感知模块,使网络融合多尺度下的结构特征,关注目标完整的结构,提高网络的检测效果。
(2)提出一种全局上下文信息模块,建立特征图中不同通道之间的联系,解决小目标携带特征信息少这一问题,提升了复杂场景下的检测准确性。
(3)提出一种新的带权重的损失函数W-CIoU,可以缓解梯度爆炸现象,有效提升了网络的收敛速度。
1 小目标检测算法设计
为了使网络融合不同尺度的目标特征,保持对目标本身的关注,提出一个基于多尺度结构感知的方法用于小目标检测。为了更好地利用全局信息,设计了一种全局上下文信息模块。最后提出了一种更适合小目标检测的损失函数W-CIoU,可以提升模型训练的收敛速度。
1.1 网络架构
为了兼顾实时性和准确性,本文选取YOLOv5作为基线网络。为了得到更加丰富全面的结构特征信息,本文针对小目标提出了多尺度结构感知模块(MSSP),可以感知更加丰富的目标结构。另外,针对小目标像素点少,设计了全局上下文信息模块(GCM),进一步丰富网络深层的语义信息,以便于弥补小目标在深层丢失的细节。本文提出的网络架构如图1所示。
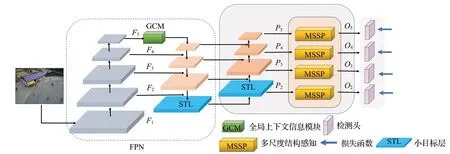
图1 网络结构Fig.1 Network structure
其中MSSP 代表多尺度结构感知模块,GCM 代表全局上下文信息模块,Head代表检测头,负责对最后的结果进行分类和定位。F1~F5代表特征金字塔每一层经过特征提取后的特征图,P2~P5以及O2~O5分别代表了最终送入MSSP模块以及检测头的特征图,对于每一个检测头采用本文提出的W-CIoU 损失函数进行监督训练。除此之外,为了增强小目标的多尺度特征,本文在现有的3个不同尺度特征图检测的基础上,增加了一层小目标层(small target layer,STL),即图中浅蓝色方块。该小目标层通过上采样操作对上一层输出的特征图进行放大,通过卷积归一化等操作对特征信息进行处理。小目标层主要处理分辨率较高的特征图,分辨率越大,表示图像中目标的清晰度越高,包含的小目标特征信息就越丰富,从而有利于网络进行特征提取,减少小目标的漏检和误检。同时,检测头的数量也会增加一个,配合本文提出的模块以及损失函数设计,提升模型的检测性能。
1.2 多尺度结构感知模块
为了充分利用不同尺度下的特征信息,同时保证模型关注小目标本身,本文提出一种多尺度结构感知模块(MSSP),该模块共有两个部分,分别是多尺度融合模块(multi-scale structure fusion,MSFF)和结构细化层(structure refinement layer,SRL),如图2 所示,其中MSFF 表示多尺度结构融合模块,SRL表示对目标结构进行细化。
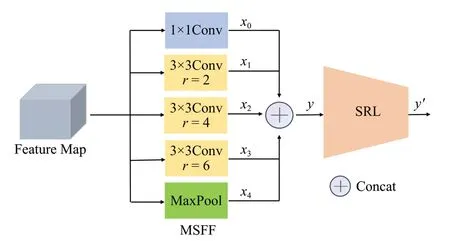
图2 多尺度结构感知模块Fig.2 Multi-scale structure perception module
图像的特征图作为MSFF模块的输入信息,分别经过五个并行的分支后输出。其中,第一个分支是1×1的标准卷积,主要目的就是保持原有的感受野。第二至四个分支是空洞率分别为2、4、6的空洞卷积,可以获得不同的感受野,从而获得目标不同尺度的特征信息;第五个分支是最大池化操作,减少无用信息的影响,提高所提取特征的鲁棒性。最后将五个分支的特征图在通道维度上进行拼接。
MSFF 模块的计算过程如公式(1)和(2)所示。其中,x代表图像的特征图,r代表空洞率,Conv代表卷积操作,MaxPool代表最大池化操作,Concat代表拼接操作,y代表该模块的输出结果。
在得到融合后的特征信息之后,为了使网络能够更快速地定位到目标本身,而不是一些噪声信息,本文引入注意力机制来提高检测器对小目标的特征捕捉能力,提出一种结构细化层(SRL),结构如图3 所示,其中,ConvBnSiLu 代表卷积(Conv)、批量归一化(Bn)以及激活函数操作(SiLu)。
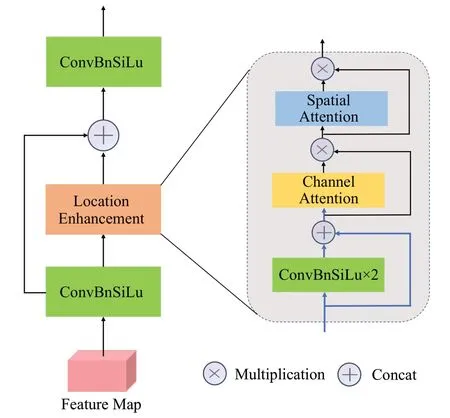
图3 结构细化层Fig.3 Structure refinement layer
SRL主要包含一个位置增强模块(location enhancement),该模块融合了空间注意力和通道注意力[10],可以更加准确地捕获目标结构。输入的特征图进行卷积操作后,输入到位置增强模块里,通过两个普通卷积操作后,然后依次通过通道注意力和空间注意力。通道注意力会着重于分析每个通道的特征,即目标结构;而空间注意力则更关注于目标的位置,即目标在哪里,可以很好地对通道注意力进行信息互补。此外,所设计的位置增强模块还可以作为任意一层特征图后的优化处理操作,是一个即插即用的模块。
为了更直观地验证SRL 的效果,分别对网络使用SRL前后做了可视化分析,如图4所示。

图4 可视化分析Fig.4 Visual analysis
第2 列是没有使用SRL 的结果,第3 列是加上SRL后的效果图,可以看出使用结构细化层之后,网络模型更加注意到小目标本身包含的特征区域,而不是背景等一些噪声信息,证明了该模块的有效性。
1.3 全局上下文信息模块
众所周知,图像的全局视图可以提供有用的上下文信息,因此在小目标周围的其他物体可能会对检测结果的提升带来一定的帮助。另外,由于卷积是一种局部的操作,受卷积核大小的限制,它只会对像素邻近的区域进行相关计算,这就导致了全局的上下文信息没有被充分利用起来。为了捕捉不同区域像素之间的联系,本文引入Transformer[11-12]架构设计了一种全局上下文信息模块(GCM),结构如图5 所示。由于Transformer 可以有效地捕捉图像特征的长距离依赖关系,因此GCM 是一种全局操作,它会为当前区域和其他区域搭建起桥梁,通过不同区域像素之间相互学习,更好地利用全局信息,从而改善小目标携带特征信息少这一问题,提高模型对小目标的检测能力。其中ConvBnSiLu操作与图3代表的含义一致。原始的Transformer采用的是LayerNorm层归一化,考虑到这种归一化通常是对不定长文本序列的处理,而图像的尺寸往往是统一的,故没有采用原设计模型的LayerNorm,即图中的Transformer-LN。
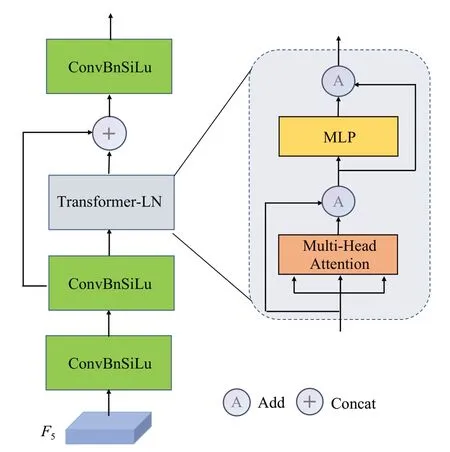
图5 全局上下文信息模块Fig.5 Global context module
1.4 W-CIoU损失函数
目前已有的一些方法通常采用的损失函数是CIoU[13],其定义如式(3)~式(5)所示:
其中,IoU代表交并比,b、bgt分别代表预测框和真实框的中心点,ρ代表这中心点之间的欧式距离,c代表能覆盖预测框和真实框的最小矩阵的对角线长度,w、wgt分别代表预测框和真实框的宽度,h、hgt分别代表预测框和真实框的高度。考虑惩罚项v对w和h求梯度的情况,如式(6)、式(7)所示:
不难看出,如果目标过小,那么w和h就会频繁地出现在0到1的区间之内,从而导致趋近于无穷大,造成梯度爆炸,不利于模型的收敛;另外,当惩罚项v在预测框和真实框长宽比相同时退化成0,即失效的情况。针对两种局限性,提出一种更加高效的损失函数W-CIoU,定义如式(8)、式(9)所示:
其中,T是为了防止β=0 的情况加入的偏移量,其余参数含义与CIoU 保持一致。同时,将每一项都进行二次幂的计算,加速损失函数收敛速度。同样,考虑β对w和h求梯度的情况,如式(10)、式(11)所示:
可以看出,此时的梯度函数就不会因为目标过小而导致梯度爆炸的问题,同时,还比较了这两个损失函数在训练时的loss图,结果如图6所示。
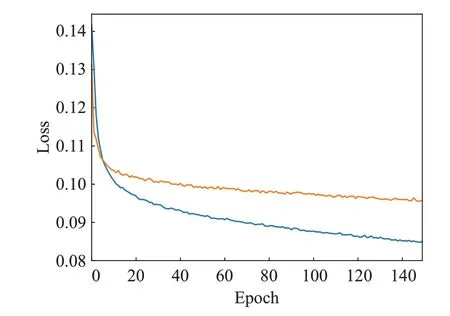
图6 在数据集VisDrone训练时的loss曲线Fig.6 Loss curve on VisDrone dataset
从图6 中可以看出,W-CIoU 在缓解梯度爆炸的同时,还保持了较快的网络收敛速度。相较于CIoU,本文设计的W-CIoU 更适用于小目标检测。
2 实验数据与结果分析
2.1 数据集
本文采用数据集VisDrone2019[14]以及TinyPerson[15]数据集来训练并评估改进后的模型。这两个数据集都是以小目标为主,其中VisDrone2019数据集是在不同的场景、光照条件下使用不同的无人机平台收集。TinyPerson数据集主要包括海滩和海上的人群,其目标像素点少于20个像素。
2.2 实验细节设定
在模型训练阶段,epoch 设置为150,batchsize 设置为16。在评价指标方面,本文采取P(precision)、R(recall)、Params、mAP50、mAP50:95等指标作为模型的评价指标。mAP50表示IoU阈值等于0.5时所有目标类别的平均检测精度,mAP50:95 表示步长为0.05,计算IoU阈值从0.5~0.95的所有IoU阈值下的检测精度的平均值。Params代表模型的参数量,主要用于衡量模型关于显存资源的消耗。
2.3 对比实验
对比了改进后的算法和其他算法在两个数据集上的表现,包括了经典的小目标检测算法,例如FPN、FS-SSD、TPH-YOLO以及SPD-CONV,同时比较了其他YOLO系列的算法性能。实验结果如表1所示。
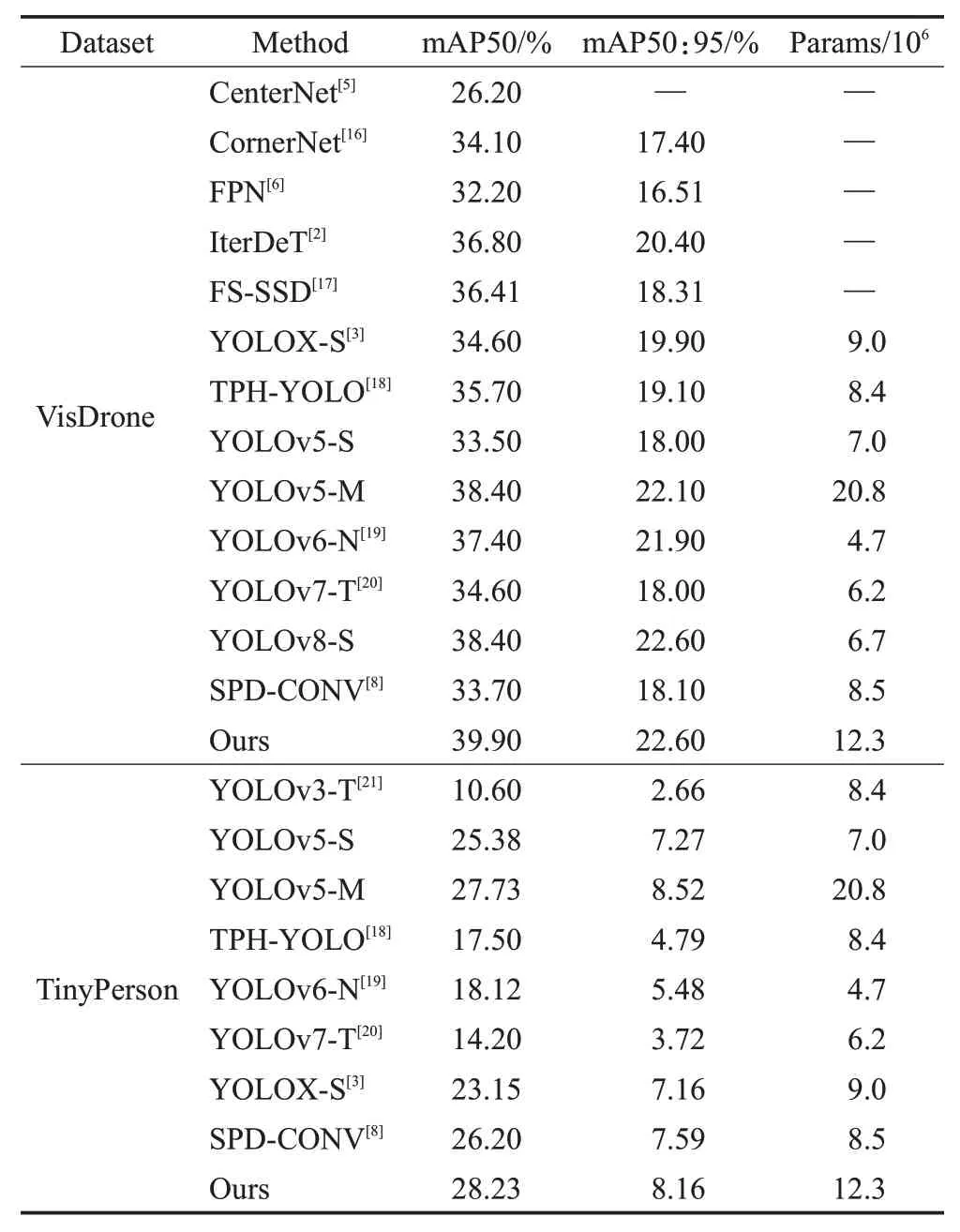
表1 对比实验Table 1 Comparative experiment
其中,Ours 代表本文提出的模型,为了保证对比的合理性,本文选取了同一规格参数量的算法进行对比。表格上半部分代表各算法在VisDrone数据集的结果,下半部分代表各算法在TinyPerson数据集的结果。从表1可以看出,本文提出的模型相较于基线网络YOLOv5-S在数据集VisDrone 上mAP50 和mAP50:95 分别提高了6.4 和4.6 个百分点,在数据集TinyPerson 上mAP50 和mAP50:95分别提高了2.85和0.89个百分点。
2.4 不同模块的消融实验
为了验证提出的多尺度结构感知模块(MSSP)、全局上下文模块(GCM)以及引入的小目标层(STL)的有效性,本文评估不同模块在VisDrone数据集相同实验条件下对小目标检测性能的影响,即消融实验。实验结果如表2所示。
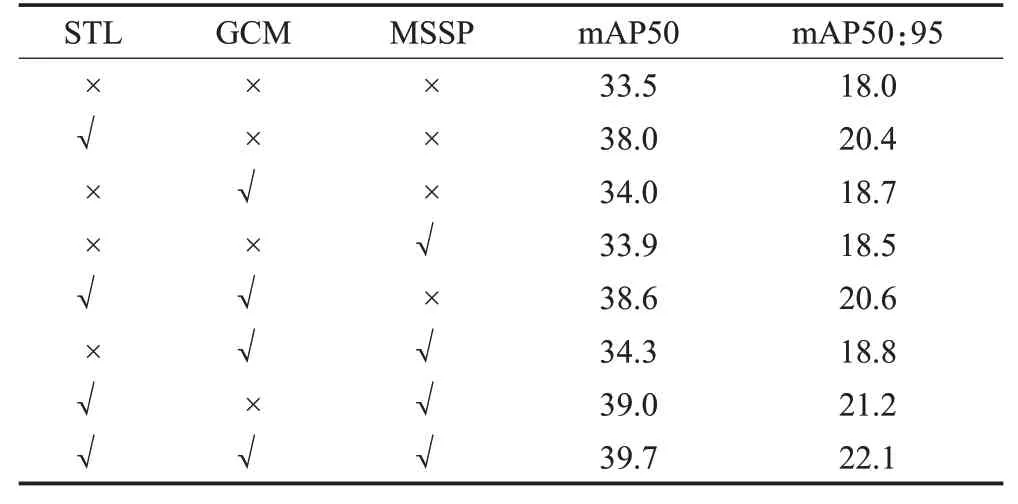
表2 消融实验Table 2 Ablation experiment 单位:%
实验结果表明,设计的多尺度结构感知模块、全局上下文信息模块以及添加的小目标层都对小目标的检测有明显提升。对比基线网络,STL 在mAP50 和mAP50:95 分别提高了4.5 和2.4 个百分点;MSSP 模块在mAP50和mAP50:95分别提高了0.4和0.5个百分点;GCM模块在mAP50和mAP50:95分别提高了0.5和0.7个百分点。另外,各个模块之间的组合相较于单独使用某个模块效果要好,验证了本文提出的多尺度结构感知模块和全局上下文信息模块的有效性。
2.5 多尺度结构感知对比实验
为验证提出的多尺度结构感知MSSP 模块的有效性,对比了其他几种多尺度模块融合的性能表现。为了充分发挥多尺度融合模块的特点,实验添加了小目标层STL模块作为基线。实验结果如表3所示,本文设计的MSSP 模块相较其他方法取得了不错的效果,证明了MSSP的有效性。
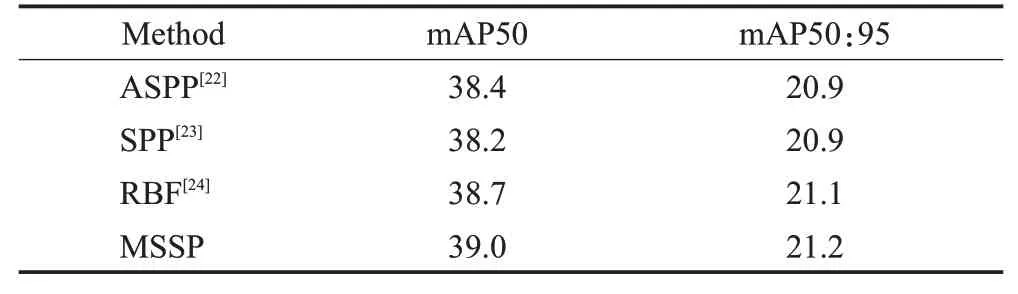
表3 多尺度结构感知模块对比实验Table 3 Multi-scale structure perception comparison experiments 单位:%
2.6 损失函数对比实验
为验证提出的W-CIoU损失函数,对比了其他几种主流的损失函数在小目标检测中的性能表现,实验结果如表4所示。从表中可以看出,本文提出的W-CIOU在大多数指标上表现出色,在指标mAP50 上略逊色于EIOU,这主要由于EIOU从预测框和真实框的宽和高的差异角度出发进行最小化。而本文设计的损失函数WCIoU 综合考虑了小目标的特点,从缓解梯度爆炸的角度出发,起到了加速收敛的作用,如在指标mAP50:95上表现出色,说明W-CIOU更关注高质量的预测框。另外,在精度P和召回率R指标也取得了最优结果。综合各项指标来看,W-CIOU更适用于小目标检测。
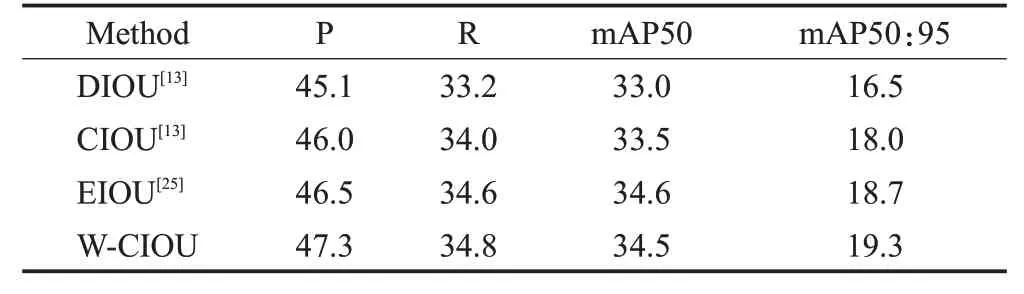
表4 损失函数对比实验Table 4 Loss function comparison experiment单位:%
2.7 全局上下文信息模块消融实验
为了更详细地验证全局上下文信息模块(GCM)对小目标检测的影响,进行了对比实验,分别在主干网络不同层数的位置添加该模块,实验结果如表5所示。
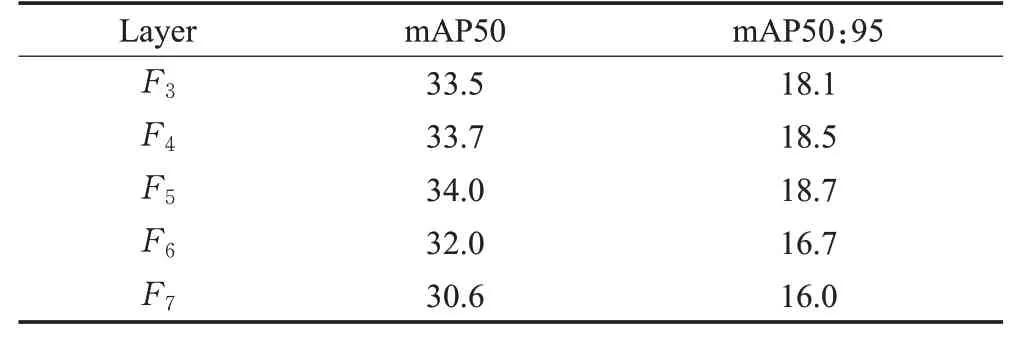
表5 全局上下文信息模块消融实验Table 5 Global context ablation experiments单位:%
通过实验结果可以看出,GCM 在深层时结果有明显的提升,在浅层的表现并不是特别理想;随着网络层数的不断加深,网络性能反而会变差。如表5 中所示,当层数为5时,mAP50和mAP50:95指标取得最好的结果。主要原因在于特征金字塔越往上,即层数越深,特征图的尺度就越小,包含小目标区域的特征越少,从而导致小目标检测的性能变差,故本文选取五层的特征金字塔作为主干网络。
同时,结合实验以及分析,认为有以下两点原因导致该模块在F3、F4的表现不如F5。
(1)浅层学习到的特征质量不高。浅层学习到的特征大多数是目标的纹理、外观等十分容易学习到低层特征,甚至有些通道分支学习到的都是背景噪音等特征。而深层的特征就会更偏向于目标本身,该模块使各自通道学习到的特征信息与全局进行交互,最大程度上地利用了全局上下文信息。
(2)浅层通道数量不够。浅层可以学习的特征通道数过少,参与交互的特征信息不足,这就导致即使浅层学习到了一些小目标的特征信息,全局上下文信息模块也很难进行交互从而学习到更有判别力的特征。
图7展示了网络分别在浅层和深层提取的特征图,第一行代表浅层F3特征图,第二行代表深层F5特征图深层的特征图相较于浅层更丰富、更具体,这也验证了上述的分析。

图7 深层和浅层的特征图对比结果Fig.7 Comparison of feature maps between deep and shallow layers
2.8 视觉效果对比
将改进后的模型与基线网络进行了视觉效果的对比,如图8 所示。可以看出改进后的模型在目标遮挡、光线昏暗以及模糊情况下,相比原模型,漏检、误检的情况有明显的改善,尤其在小目标检测上表现更加出色。图中的白色方框展示了本文算法和基线网络在视觉效果上较为明显的区域。

图8 视觉效果对比Fig.8 Visual effect comparison
3 结论
本文提出了一种基于多尺度结构感知和全局上下文信息的小目标检测算法。首先,为了使模型融合不同尺度下小目标的特征信息,快速定位到目标本身,提出一种多尺度结构感知模块。通过实验结果和视觉效果的分析验证了该模块的可行性,它可以使网络对小目标特征更加关注。其次,为了更好地利用上下文信息,本文借助Transformer 结构捕捉长距离依赖的优势,提出了全局上下文信息模块,该模块使得每个通道都能与其他通道进行交互、学习。最后,本文提出了一个更适合小目标检测损失函数,即带权重的W-CIoU 损失函数,可以有效地加快模型收敛的速度。大量的实验结果表明,本文方法在召回率、平均准确率等指标都有明显的提升,验证了本文提出的方法更适合复杂场景下的小目标检测。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
金桥(2018年4期)2018-09-26
数学小灵通·3-4年级(2017年9期)2017-10-13
太空探索(2016年5期)2016-07-12
中国卫生(2014年5期)2014-11-10
时代英语·高三(2014年5期)2014-08-26
