
面向桌面交互场景的双目深度测量方法
2024-05-11 03:34朱兴帅丁上上付威威
计算机工程与应用 2024年9期
叶 彬,朱兴帅,姚 康,丁上上,付威威
1.中国科学技术大学生物医学工程学院(苏州)生命科学与医学部,江苏 苏州 215000
2.中国科学院苏州生物医学工程技术研究所,江苏 苏州 215000
目前,虚拟现实已经在全球掀起研究的热潮,相关应用不断涌现。其中一个重要应用场景是桌面书写,然而在这种场景中还没有一种针对性的交互方式解决方案:基于硬件控制器的交互在虚拟空间书写场景中交互效果不够直观;基于视觉的交互方式[1]相比较硬件控制器更能直观体现交互过程,但现有研究缺少笔的三维识别而无法重现完整的书写交互过程,且三维精度不足导致精细交互动作识别效果较差,在桌面书写应用场景中适用性不高。相较而言,一种同时包含手与笔的高精度三维识别技术可以提供更好的书写交互体验,其中三维识别精度的提升离不开更加准确的深度计算,因此针对于桌面书写场景的高精度深度估计在手笔联合的三维识别中有着关键作用。在现有技术上,单目视觉[2-3]可以独立完成深度估计,但存在精度受限且不够稳定的问题,而双目视觉包含了潜在的深度信息,可以更好地完成深度估计任务,同时相比其他三维测量技术,双目立体视觉系统具有成本低、结构简单、易于部署等优点,现已广泛应用于诸如自动驾驶[4]、三维重建[5]、工业检测、医疗影像、虚拟现实等多个领域。
立体匹配算法是双目立体视觉深度计算中的关键环节,传统立体匹配方法[6]可以总结为四个步骤,即匹配代价计算、代价聚合、视差计算和视差优化。近来研究者们将深度学习方法应用在立体匹配领域,且在稠密视差图计算的精度和效率上有了更优良的表现[7]。研究者们初期[8]尝试使用卷积神经网络取代传统算法中的部分过程,之后在端到端的立体匹配网络上做出了努力。EdgeStereo[9]利用一个边缘预测的子网络辅助指导视差的学习,改善视差学习效果。Kendall 提出的GCNet[10]通过共享权重的卷积网络提取左右特征图后将其拼接形成一个四维视差成本特征张量,最后利用三维卷积编解码结构直接回归视差值,后续的诸多研究者们也采取了此思路。PSM-Net[11]在特征提取阶段使用了金字塔结构结合了多尺度语义信息并在三维卷积回归阶段引入了堆叠沙漏结构;GwcNet[12]在PSM-Net 的基础上提出了组相关特征构建匹配代价体;DeepPruner[13]在构建成本代价体的过程中结合了patch match算法。上述算法尽管在精度和实时性上做出了一定改善,但仍然存在计算成本过大、实时性较差、易受匹配范围的限制等缺点。近来有部分研究者尝试寻找替代三维卷积的方法来降低模型计算成本[14-15],但相比于三维卷积结构可以更好地提取图像结构信息的优点,替代方法在估计精度上存在不足。
在桌面书写环境中,上述拥有较高精度的立体匹配算法在计算成本和运算时间上的缺点限制了输入图像对的分辨率,而网络中输入的空间分辨率的不同选择会带来检测精度和效率上的冲突,因此如何合理平衡算法精度以及效率成为了本文深度测量方法的关键问题。考虑到虚拟桌面书写场景中精细交互动作大多通过笔尖实现,笔尖区域需要更高的交互精度,而背景区域精度要求最低。基于此,本文采集了高分辨率、近距离的图像对作为网络的输入,并提出了一种分级精度的多阶段深度测量方法,区分了全局信息和局部关键信息并分尺度输入来解决算法中分辨率限制的问题,同时在不同阶段对全局信息和局部关键信息进行了融合以提升检测精度与速度,具体为创新性地提出利用ROI Align方法在不同阶段构建了区域特征金字塔结构,结合了多尺度语义信息;并且采用视差级联结构初始化视差,有效缩减视差匹配范围,减少算法在视差搜索上的用时。实验证明,本文方法相比现有算法提升了速度和书写关键区域的精度,并减少了显存占用,能够实现桌面书写场景下高精度深度测量,有效辅助手笔联合三维识别技术的精度提升,改善虚拟现实中桌面书写交互体验。在未来本文方法可以作为书写交互三维识别的辅助技术促使虚拟书写应用于近视防控,通过虚拟空间解决青少年长时间近距离用眼问题,具有重要的应用价值。
1 技术方法
为了解决深度估计不准确导致的视觉交互方式在桌面书写环境中适用性不高的问题,本文提出了一种高精度桌面场景双目深度测量方法,针对书写交互区分了图像对中的全局信息和局部关键信息。首先在桌面书写场景中采集高分辨的双目图像对;然后输入本文分级精度式的多阶段双目立体匹配算法,算法流程如图1,通过低尺度全局输入结合高尺度局部输入平衡高分辨率立体图像对带来的精度和效率问题。其中定义了两个局部区域,分别是包含了整个手部和握持笔的手部区域1和包含了笔尖部分的笔尖区域2,区域1在图像中的位置以笔身中心为区域中心而区域2 位置以握持笔笔尖和笔身交界处为区域中心,两个区域在算法中初始位置不定而是由预训练好的区域检测模块决定。
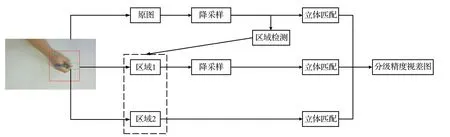
图1 分级精度式算法流程图Fig.1 Hierarchical precision algorithm flow chart
高分辨率立体图像对的原图在k倍降采样后额外通过一个区域检测分支网络,提取关键交互区域以更高的区域分辨率计算图像对的特征相关性;区域1以小于k的降采样比例k′提供更多的区域细节信息保证更高的区域深度精度,区域2则不进行降采样以最丰富的细节信息获得最高的区域深度精度。
本文针对书写交互提出了一种多精度级联立体匹配网络(multi-precision cascaded network,MPC-Net),充分利用全局与局部重要信息交叉融合的思路提升手部以及笔尖所在局部区域深度估计的检测精度,在特征提取模块构建了区域特征金字塔结构融合不同分辨率尺度的图像对特征,提供多尺度的图像语义信息;同时使用上一区域的视差输出结果作为初始值优化下一个区域匹配代价体的构建,大幅减少视差搜索范围,降低网络的运算量;最后利用不同数量的堆叠沙漏结构为每个区域阶段的视差代价体回归视差值,并给三个阶段分配不同的损失权重促使网络趋向重要交互区域的学习,MPC-Net 结构如图2,图中©表示左右特征量通过点积和级联形成四维匹配代价张量。
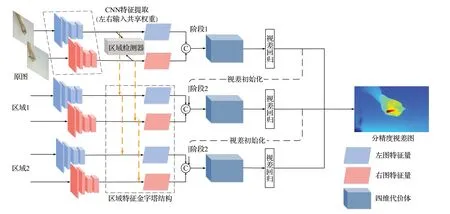
图2 MPC-Net网络结构Fig.2 Structure of MPC-Net
1.1 区域检测器
为了获取交互关键区域位置,本文参考目标检测领域的区域建议网络(region proposal network,RPN)并进行了修改,检测器结合了左右特征图像间的同一区域位置相关性以及区域先验知识,进行左右图像对应关键交互区域位置信息的提取,检测器结构如图3所示。
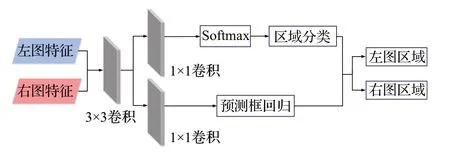
图3 区域检测结构Fig.3 Region detection structure
检测器共有两个任务:区域分类和区域定位,首先在特征图像对每个像素位置处生成固定尺寸的候选回归框,在特征图像对输入后经过一个3×3卷积层利用滑动窗口生成回归框特征向量,之后利用两个1×1卷积层替代全连接,实现区域分类并进行位置定位。区域分类的主要任务是给所有候选回归框确定一个类别,类别总共有三个:背景区域、区域1和区域2,其中区域1和区域2是需要定位的关键交互区域,算法过程中利用候选框和真实回归框交并比(IOU)确定标签类别,当候选框和任一关键区域IOU 比例高于设定的高阈值0.7 时,将其设定该区域的正类别标签,而如果和所有区域IOU均小于设定的低阈值0.3 时标记为负标签,表示其代表背景区域,IOU占比为中间值时舍弃样本。
在偏移位置回归任务中,检测器为每一个立体图像对目标都训练一个三元回归项:[Δul,Δur,Δv],分别代表了参考左图的水平偏移参数、目标右图的水平偏移参数和两者的垂直偏移参数。考虑到立体图像对的位置相关性以及在立体匹配任务中存在的尺寸一致性,本文提前设定了标签区域大小并同步了区域垂直位置,其中手部(区域1)区域大小为640×640,笔尖(区域2)区域大小为256×128,因此检测器不做预测框高度和宽度参数的回归,且图像对共享垂直偏移参数Δv。
区域检测器在获得预测回归框后,可通过计算公式(1)获得图像对的关键交互区域中心:
同时对区域内的视差进行调整,表示为:
在理想双目相机系统中,Xl和Xr分别代表了同一个匹配点出现在参考(左图)图像像素坐标系和目标(右图)图像像素坐标系中的水平坐标。
1.2 区域特征金字塔(RFP)
在近来的深度学习任务中,研究者们注意到图像金字塔结构能够结合多尺度的语义信息改善学习效果,因此多种改进的特征金字塔结构[16-18]成为了各类学习方向中重要的组成部分,在提升网络性能上起到了重要作用。其中,也有部分研究者[11,19]将空间金字塔池化(spatial pyramid pooling,SPP)和特征金字塔(feature pyramid network,FPN)应用在双目立体匹配任务中来结合上下文信息,改善图像对特征信息间的对应关系,丰富后续构建的视差代价体包含的信息。
为了能够充分利用不同分辨率区域间的语义信息,本文构建了基于ROI Align 方法的区域特征金字塔(region feature pyramid,RFP),构建方法如图4,主要思想是基于ROI Align 中利用双线性插值代替量化取整方法的特点,获得局部关键区域在全局区域对应的卷积特征图,并在下一个阶段和该关键区域的自身卷积特征图共同构建特征金字塔。
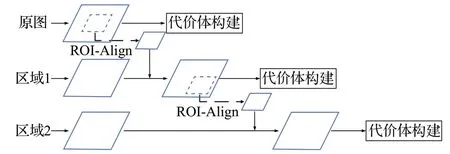
图4 区域特征金字塔Fig.4 Region feature pyramid
在ROI Align 中,利用双线性插值获得了关键区域的浮点数边界,解决了局部区域特征图区域定位不准确的问题,最后按预设输出大小平均化对应特征图进行池化操作。双线性插值计算如式(3),假设浮点数坐标为(x,y),此时特征图中该浮点数周围四个坐标代入计算特征值,公式中各坐标点的权重α与浮点数坐标到各点间距离相关。
1.3 级联成本代价和三维卷积结构
本文在多任务级联卷积网络[20]中受到启发,采用从粗匹配到精细匹配的思路,提出了多区域级联成本代价计算模块,减少网络用于视差搜索的时间。
级联模块可以分为两个阶段,分别代表了视差代价体构建的不同方式,方式1是传统的视差代价体构建方式,应用区域为背景区域,需要以覆盖整个场景的视差范围进行估计,由于对输入图像进行降采样改变了左右图像像素位置对应关系,需要对视差值和视差范围进行缩小,缩小比例为降采样比例k,此时实际视差搜索间隔从1扩大为k。方式2是本文采用的改进式视差代价体构建方式,应用区域为手部区域1和笔尖区域2,应用区域在网络中提高了输入分辨率以增加图像细节信息且可利用上一区域的视差估计结果初始化视差,因此阶段2的视差范围可以大幅缩小,同时低比例的降采样操作带来了更小的视差搜索间隔,保证了更高的视差估计精度。其中三精度模型手部区域和笔尖区域的视差范围分别定义为-8~8和-4~4。
其中视差代价体的构建方式如图5,由输出的左右特征张量在预设范围内逐视差将对应特征元素相关联构成四维代价张量,关联方式由左右特征图对应位置像素的点积和级联共同组成,其大小为D×C×H×W,其中D为每个阶段的视差等级范围大小,C表示输出通道数量,W和H分别表示特征图的宽度和高度。
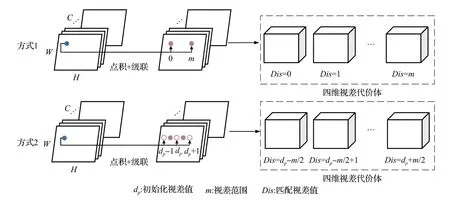
图5 级联视差代价体Fig.5 Cascade disparity cost volume
方式1不存在初始视差值,因此视差代价体的构建方式需要以覆盖全场景的视差范围逐步搜索,即在右特征图上从零到场景最大视差值依次找寻左特征图待匹配点对应的目标特征点。由于输入图像经过校对使得左右图像极线平行,因此目标特征点和待匹配点仅在X轴坐标方向上存在位置差异,目标特征点X轴坐标计算如式(4),Δd为视差搜索范围内的某值。
方式2的输入补充了图像细节信息,因此可以利用上一尺度阶段的粗匹配结果初始化估计视差值,并以更小的细化视差范围在初始值周围继续搜索来优化视差结果。由于每一阶段视差估计结果在进行初始化时并不为整数,需要利用双线性插值的方法在右特征图上生成浮点数特征值。此时目标特征点X轴坐标位置为:
式中,dp为上一阶段估计视差值,Δd′为细化匹配范围内某值且从负数开始依次增大。
在构建四维匹配成本代价张量后需要使用三维卷积同时在视差维度和空间维度上聚合特征信息,本文借助了堆叠沙漏模型组建了一个三维编解码卷积结构完成信息提取。模型结构如图6,N表示沙漏模块数量,考虑到不同尺度输入阶段存在不同的精度需求且三维卷积资源占用较大,本文为每个阶段设置了不同的沙漏模块数量。经多次实验验证,本文三精度模型从低尺度到高尺度的三个阶段设置数量分别为2、2、3,在训练时每一个沙漏模块会额外给出一个输出用于中间监督,提高估计精度。
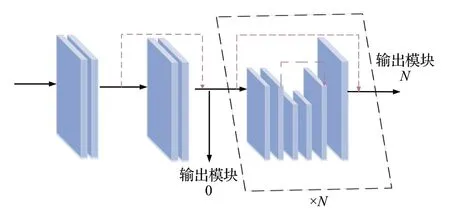
图6 三维沙漏卷积结构Fig.6 3D hourglass convolution structure
1.4 视差回归与损失函数
图像特征经三维堆叠卷积结构后会输出一个四维张量,此时需要通过视差回归函数计算每个像素的视差估计值,本文采用常用的Soft-Argmin[10]方法:
式中,Min和Max分别代表了不同分辨率阶段视差估计范围中的最小值和最大值;dp表示上一阶段视差估计结果,在阶段1 输入时值为0。Cd为卷积后的视差代价,σ(·)则表示对其进行了Softmax操作,将视差成本转化为了每个视差的可能性。
完成视差的估计后,可通过坐标系转换和双目相机存在的空间位置关系直接计算绝对深度值Depth。图像视差信息到空间深度信息转换如式(7):
式中,B为双目相机系统中的基线距离;f为相机的焦距。
本文总的损失包含了每一个分辨率阶段各自的视差回归损失并分配了不同的权重。而基于Smooth L1损失函数在鲁棒性以及异常值敏感度上的优势,选择其作为视差预测的损失计算函数。三阶段视差总损失计算如式(8):
式中,λi为每个阶段分配到的损失权重,选择λ1=0.6,λ2=0.8,λ3=1;而在具体每个阶段损失中结合了中间监督和最后输出的结果,μk表示中间监督结果的系数,是第i个阶段下标K的中间结果输出的预测视差值,则为该阶段的视差真值。smooth L1 损失函数具体的计算公式如式(9):
本文算法也为检测任务分支构建了损失函数,包含了分类损失和区域回归损失,分类损失采用了交叉熵损失函数,区域回归同样采用了Smooth L1函数进行损失计算,分类损失如式(10):
式中,n为检测器过程中选择用于训练的回归框数量;k表示类别小标,此处仅存在背景以及区域一和区域二;pk为回归框中类别号是k的可能性,p′k表示类别标签值,当IOU 计算超过设定高阈值0.7 时为1 而小于设定低阈值0.3时为0。区域回归损失如式(11):
式中,tk为回归框需要预测的三元数[Δul,Δur,Δv],t′k则为标签真值回归量。
2 实验结果与分析
2.1 实验设置
2.1.1 实验环境
本实验在Windows 环境下进行;具体使用了PyTorch1.12.1版本,CUDA11.3版本,Python3.7.0版本构建网络模型;训练过程中均使用Adam优化器并设置参数β1=0.9,β2=0.99,初始学习率为0.001。硬件方面使用了NVIDIA GeForce RTX 3060显卡,12 GB显存;CPU为Intel®CoreTMi5-10400F @2.90 GHz 6核处理器。
2.1.2 评价指标
由于本研究主要关注桌面场景深度信息的获取,因此主要评价指标采用端点平均误差(EPE)和错匹配像素误差比例。其中端点平均误差(EPE)即视差预测结果和标注视差真值之间的平均欧式距离值,单位为像素(pixel),用以表示立体匹配网络平均学习精度,计算如式(12),其中N表示了计算区域内所有像素。
错匹配像素误差比例具体指图像中视差预测结果和真值之间距离大于某个阈值的像素占所有像素的比例,即式(13),其中δ的值为3:
2.1.3 数据集
本实验的数据集是在图7双目视觉平台中采集的,图中展示了拍摄的部分视角。本文在桌面场景中从多个不同的书写方向以不同的交互姿势拍摄了立体图像对,图像分辨率为1 920×1 080,同时使用采集的深度图像作为标签真值。此外,本研究同时在图像对上使用了模糊、亮度变化、翻转以及增加噪声等数据增强技术扩增数据集,最终随机获得了2 936 对双目图像用于网络训练,592对双目图像用作测试。
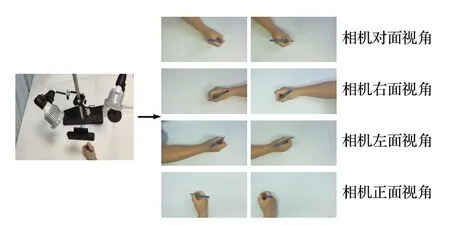
图7 双目数据集Fig.7 Binocular dataset
2.2 立体匹配网络模型验证
2.2.1 降采样实验
首先,为观察输入图像空间分辨率对网络效率以及精度的影响,本文对输入图像进行了不同程度的降采样,为兼顾速度与精度,降采样方法选择双线性插值,并在网络预测完成后对输出结果上采样至原分辨率对比,比较结果如表1所示,表中加粗部分为每个指标对比最佳值:当输入图像的空间分辨率增加时,精度有所提升但网络运行效率随之下降,计算复杂度增加,而如果降低了输入分辨率,在上采样输出时视差结果的平均误差会上升,无法保证桌面场景高精度交互需求。可以得知,本文提出的区域检测器以多尺寸输入能够起到平衡网络精度和效率的作用,在不损失重要区域立体精度的同时防止网络消耗过多资源。
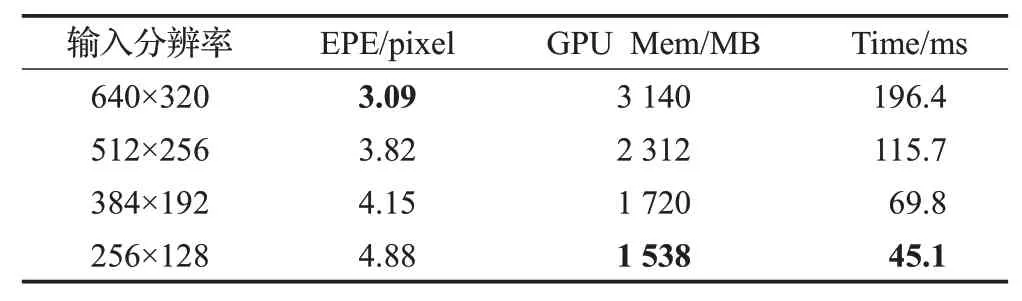
表1 降采样对比实验Table 1 Experiment of downsampling comparison
2.2.2 网络消融实验
本文在手部区域(ROI-1)和笔尖区域(ROI-2)中结合了金字塔结构和级联代价体结构,为了验证这些模块的有效性,在相同环境的实验中针对这两个模块进行了增删对比,以确定模块在网络中对受关注区域的性能是否起到正向作用,对比结果如表2。
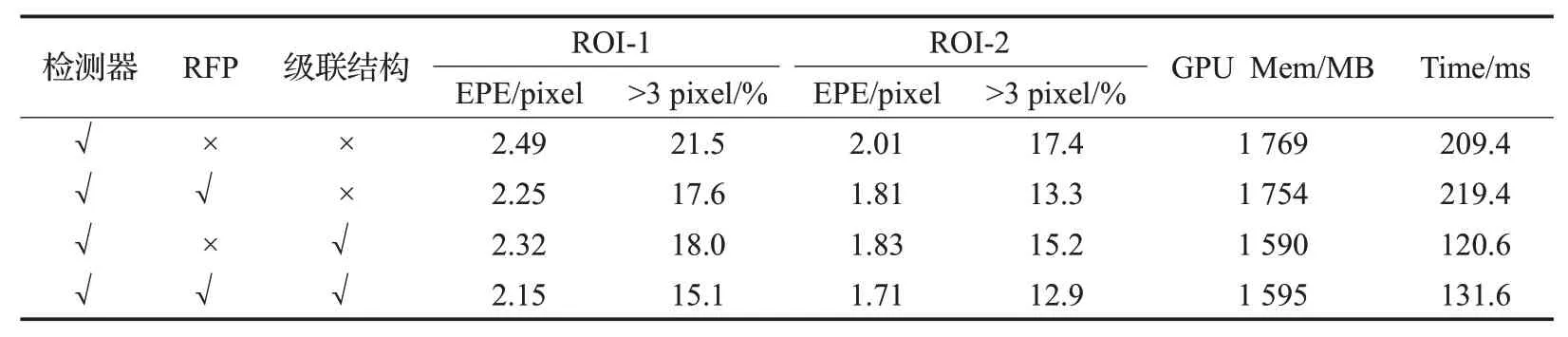
表2 网络模块消融对比结果Table 2 Comparison results of network module ablation
消融实验中,首先取消ROI特征金字塔和代价级联结构,仅采用检测器实现区域检测以及原图和区域1的降采样来完成多阶段视差估计,然后单独引入区域特征金字塔和级联结构分别与单检测器的模型结果进行对比,由表2可知本文提出的结构在深度预测的精度上均有所提升,且级联结构明显提升了网络的运行速度并减少了部分显存占用。最后同时加上两个结构,视差估计结果的误差进一步下降,相比于单检测器模型,手部关注区域(ROI-1)的平均误差相对下降了14%,三像素错误匹配率下降了6.4个百分点;笔尖关注区域(ROI-2)平均误差则相对下降15%,同时三像素错误匹配率也减少4.5 个百分点,而在运行效率上,显存占用从1 769 MB下降到了1 595 MB,推理时间从209.4 ms 减少到了131.6 ms。在手部关键区域1(ROI-1)的预测精度上,本章算法也仅与ACVNet存在着较大差距,原因是本章算法在手部关键区域1上进行了降采样,限制了精度。由此可知本文提出的区域特征金字塔(RFP)结构和级联结构对受关注区域的视差预测精度和稳定性有良好的提升,在运行效率方面也有明显进步。
2.2.3 算法对比
本文以GwcNet[12]作为基础网络结构进行改进,选用了几种较具代表性的立体匹配算法对桌面场景进行视差估计对比来表明所提算法在性能上的提升。考虑到原分辨率1 920×1 080像素的双目图像输入在主流算法上对硬件要求过高,对比实验输入改为检测到的手部区域,分辨率大小为640×640 像素,本文方法也修改为两精度模型。实验主要在手部区域(ROI-1)和笔尖区域(ROI-2)从精度、显存消耗和推理时间三个方面进行对比,结果如表3。
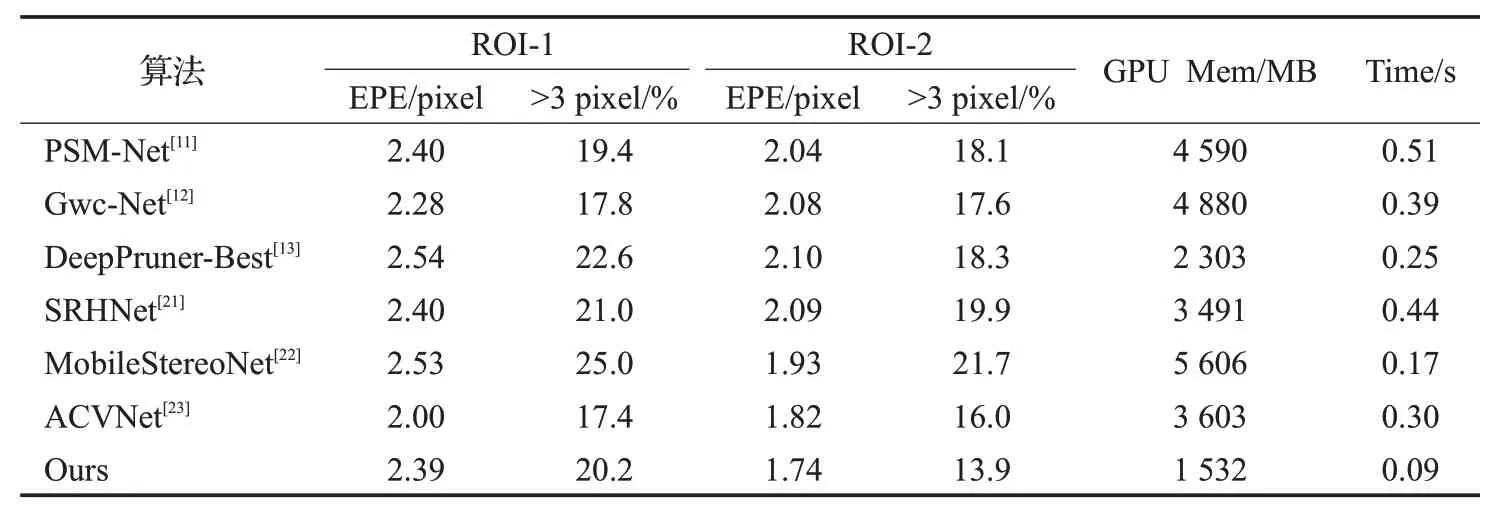
表3 不同算法的性能对比Table 3 Performance comparison of different algorithms
由表3 可知,相比于目前主流的立体匹配算法,本文提出的算法在显存占用和运算速度上有一定的提升,且笔尖关键区域(区域2)也保证了足够的精度,与本文参考网络Gwc-Net[12]相比端点误差(EPE)上相对下降了17%,三像素误匹配率下降了3.7个百分点,同时显存占用从4 880 MB 下降至了1 532 MB 而运算时间从0.39 s下降至0.09 s。
2.3 桌面交互实验
本节的桌面交互实验主要是对场景中三维交互深度准确度的验证,图8为不同视角的输入在本文算法上的视差图,为了便于观察将视差图视差值转化为了颜色像素值,偏蓝表示视差小深度值大,偏红表示视差大深度值小。
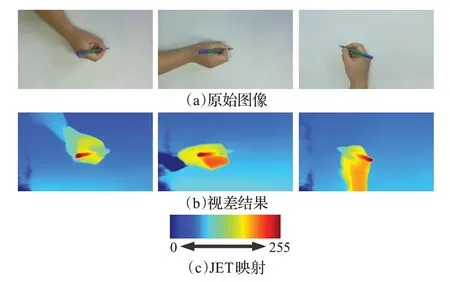
图8 视差估计结果Fig.8 Results of disparity estimation
此外,为了验证本文方法在书写交互三维识别技术中的有效性,本文还利用算法测试了连续帧笔尖交互深度估计的效果,图9 为展示效果图,其中水平面交互表示在桌面空间中平行于桌面进行交互动作,X轴倾斜交互为按图像坐标轴X轴所在的方向进行了水平倾斜的交互动作而Y轴倾斜交互则是按图像坐标轴Y轴所在方向进行了水平倾斜的交互动作。需要注意的是,由于双目相机采集位置不完全与桌面平行而是在图像坐标轴Y轴所在方向和桌面存在一定倾斜角,因此平行于桌面的水平面沿图像坐标轴Y轴正方向深度会逐渐减小。
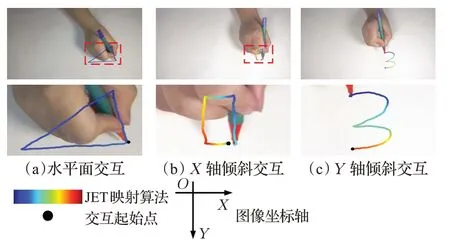
图9 书写交互深度测量效果展示Fig.9 Writing interactive depth measurement effect disparity
本实验将预测视差值归一化到0~255 范围后转换为了颜色像素值,对应方式为JET 颜色映射算法,以达到明显化展示效果的目的,颜色由蓝至红表示距离由远至近。除展示效果外,本文实验还在平行桌面的平面沿图像坐标轴X轴所在方向和Y轴所在方向绘制直线来直观表达连续帧深度测量精度,理想情况下平行桌面的平面深度值在X轴方向不变而在Y轴方向线性变化。精度测试结果如图10,其中蓝色曲线为X轴方向直线连续帧深度估计结果,代表理论深度无变化时的深度精度实验,曲线图上纵轴每单位深度为0.5 mm,红色曲线为Y轴方向直线连续帧深度估计结果,代表理论深度线性变化时的深度精度实验,纵轴每单位深度为5 mm。右侧为所绘制曲线及其所在方向,可知X轴方向直线绘制不完全水平,因此蓝色曲线前后存在一定线性变化。由X方向直线测试结果看出本文在深度测量上的相对精度可以达到1 mm。
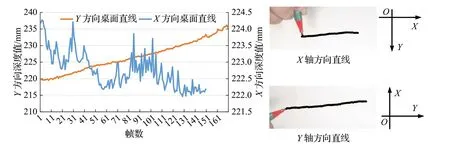
图10 书写交互深度测量精度Fig.10 Write interactive depth measurement accuracy
本文实验结果显示,所提方法在桌面小空间场景中基本能够做到正确的连续视差估计,可以应用于手笔联合的三维识别技术中提高识别精度,实现能够适用于桌面书写场景的一种新型交互方式,提供良好的书写交互体验。
3 结语
本文提出了一种适用于虚拟现实的桌面书写应用场景深度测量方法,用于辅助手笔联合的三维识别技术。该方法中,通过双目视觉系统采集高分辨率立体图像对,然后针对手笔联合三维识别的特殊性使用本文搭建的分精度级联立体匹配算法MPC-Net 可以实现书写场景高精度深度测量。算法构建了一个区域检测任务分支区分场景中的全局信息以及手部和笔尖局部关键区域信息,同时利用区域特征金字塔模块和视差级联模块加深了各尺度阶段之间的联系。与当前主流立体匹配模型相比,本文设计的模型以更少的运算时间和计算成本在关键交互区域达到了相当甚至更好的立体匹配精度,笔尖区域坐标转换后的深度预测结果可以达到1 mm 的连续相对精度,能够有效辅助解决虚拟现实视觉交互方式中三维识别精度不足的问题。
但是本文方法依然存在部分问题:模型不够轻量化,运行速度依然无法满足虚拟设备的低延迟要求;连续交互深度的准确度有待提升。后续研究计划进一步提高网络的实时性,探索时序信息对书写交互的影响,为虚拟桌面场景中的三维识别技术提供更稳定的深度测量方法。
猜你喜欢
艺术家(2023年8期)2023-11-02
数学大王·低年级(2022年12期)2022-12-12
小哥白尼(军事科学)(2022年2期)2022-05-25
小型微型计算机系统(2022年1期)2022-01-21
装备制造技术(2020年12期)2020-05-22
铁道通信信号(2020年12期)2020-03-29
红领巾·萌芽(2019年8期)2019-08-27
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
现代计算机(2016年3期)2016-09-23
CHIP新电脑(2016年3期)2016-03-10
