
基于生成对抗网络的时尚内容和风格迁移
2024-05-11 03:34丁文华杜军威刘金环
计算机工程与应用 2024年9期
丁文华,杜军威,侯 磊,刘金环
青岛科技大学信息科学技术学院 山东 青岛 266061
近年来,机器学习和深度学习的发展取得了重大的突破,尤其是深度学习的发展使计算机具备了感知物体、识别内容的强大感知能力。生成对抗网络(generative adversarial network,GAN)作为深度学习的分支之一,自Goodfellow[1]在2014 年提出后,由于其新颖的对抗思想及优秀的生成效果,被学术界和工业界所重视。目前GAN在图像处理领域和计算机视觉领域得到了广泛的研究和应用[2],尤其是图像转换任务,例如图像着色[3-5]、语义分割[6-7]、风格转换[8-12]、图像超分辨率[13-14]等。GAN进行图像转换任务可以从输入数据类型来分类,一类是基于配对数据集建立的模型,一类则是针对无配对数据集建立的模型。
在配对数据集下,条件生成对抗网络[15](conditional GAN,cGAN)使用类标签作为生成器和判别器的条件信息,最终来生成特定类的图像。基于cGAN,Isola 等人[16]提出一个改进的模型Pix2pix,解决许多在过去使用不同损失函数才能解决的问题,但该模型只能对特定形状的简单图像做线稿上色任务,如图1(a)所示。在有配对数据集提供监督的情况下,这些方法可以生成优秀的图像,但是在许多任务中,获得配对的数据集通常比较困难和昂贵,这极大地限制了图像转换的性能。为了解决这个问题,CycleGAN[17]提供了一种新的见解——循环一致性损失,直接使用两组生成器和判别器来学习源域和目标域之间的映射和逆映射,完成图像的双向转换任务,如图1(b)所示。该方法虽然有效,但是循环一致损失都是基于源域和目标域之间存在严格的双射关系,该条件很难满足。这时TravelGAN[18]、DistanceGAN[19]和GcGAN[20]通过预定义的距离函数来保证输出图像与目标域之间的相似性,实现单向的图像转换,但是这些方法需要依赖于整个图像之间的关系完成。此外,基于神经网络风格迁移[21](neural style transfer,NST)的发展与一些新的归一化方法密切相关。在NST 中最早出现的归一化方法为实例归一化[22](instance normalization,IN),在IN 的基础上,Dumoulin 等人[23]提出了条件归一化(conditional instance normalization,CIN),它是通过改变风格图像的仿射参数实现多风格迁移。受到CIN方法的启发,Huang 等人[24]提出了一种自适应实例归一化层(adaptive instance normalization,Adain),通过使用自适应仿射参数进行任意风格的迁移,如图1(c)所示。然而,“自适应”仿射参数是通过手动定义的方式计算得来,具有一定的局限性。

图1 经典的图像转换任务对比Fig.1 Comparison of classic image conversion task
目前,生成对抗网络也被广泛应用于各种与时尚相关的任务,如虚拟试穿[25-27]、时尚设计[28-29]和时尚生成[30-34]等。其中,在虚拟试穿方面,Lassner 等人[25]提出了ClothNet模型,应用GAN来生成人体服装图像,实现了虚拟试衣任务。但该方法存在服装外观准确性无法控制的问题。针对该问题,Jetchev等人[26]提出了条件类比对抗生成网络CA-GAN,使服装模特可以自由换装。但是该模型只能粗略变换服装,生成的服装图像无法适应姿势变化。随后,Han 等人[27]提出了虚拟试装系统VITON。它是虚拟试衣研究领域的里程碑,以后的许多方法都是以其为基准。在时尚设计方面,Sbai等人[28]通过对纹理和形状的特定调节,对时尚单品进行设计与生成。这是第一个将设计与时尚单品联系起来的任务。接着,Mo 等人[29]提出的InstaGAN 实现了牛仔裤和短裙、短裤和长裤的互换。在时尚生成方面,TextureGAN[30]是一种以时尚单品的草图、颜色和纹理为指导的深度图像生成方法。该方法允许用户在草图的任意位置和以任意比例放置纹理图像,以控制所需的输出纹理。后来,AMGAN[31]是能够根据目标属性的变化,使用注意力机制对服装的相关属性区域进行转换,同时保持其他属性不变。更进一步地,Zhu等人[32]提出了FashionGAN模型,它是通过训练两个单独的网络来实现多个服装属性的转换任务。然而,该方法在服装生成过程中,无法保留背景且在细粒度纹理合成方面效果也不明显。除此之外,FACT[33]是一种基于语义的服装转移融合注意力模型,主要根据给定的文本描述对人体上衣服的纹理和颜色进行转换,同时保持住他的姿势、体型等。Yoo 等人[34]提出了一种在像素级别上的图像生成模型,该方法可以根据穿着者的输入图像生成一件对应的衣服。本文主要倾向于时尚单品的生成任务,但是现在的相关方法都是在两个域之间进行图像转换,而着重于对时尚单品进行多域特征的融合。如图1(d)所示,给定一件时尚单品、一张风景图像(即内容图像)和一张风格图像,主要任务是生成融合内容图像和风格图像特征的时尚单品。除生成对应风格的时尚单品,对其进行风格迁移外,还需生成与给定内容图像相关的图案,即对其进行内容迁移。对于这种多个图像域(即时尚单品、风格图像和内容图像)的特征融合任务,上述方法均无法实现。
针对以上问题,提出了基于生成对抗网络的时尚内容和风格迁移模型(content and style transfer based on generative adversarial network,CS-GAN),该模型不仅能够保留时尚单品的全局结构信息,而且能够在未配对的数据集上实现多个图像域(如时尚单品、内容图像和风格图像等)的特征融合,从而有效地完成时尚单品的内容特征(如颜色、纹理)迁移和风格特征(如莫奈风、立体派)迁移。它允许在单个网络中同时训练具有不同域的多个数据集,学习所有目标域之间的融合映射。具体而言,本文在内容迁移模块提出了基于对比学习策略,采用对比学习框架来最大化输入的时尚单品与生成图像块之间的互信息。该方法能够将它们之间对应的图像块相互关联,同时与其他的图像块相互远离,避免了依赖于整幅图像之间的关系,可实现时尚单品的内容迁移且对比学习可以在小数据集上使用。在风格迁移模块提出了层一致性动态卷积(layer consistence dynamic convolution,LCDC)方法,它能够将不同风格图像的特征编码为可学习的卷积参数,并与时尚单品对应层的编码特征进行动态卷积操作,然后传递到生成器的解码部分,实现时尚单品的风格迁移。这种方法更加灵活、强大,而且也没有增加模型的参数量。
综上所述,本文的主要贡献可以概括为以下三个方面:
(1)本文提出了基于生成对抗网络的时尚内容和风格迁移模型,不仅可以保留时尚单品的全局结构信息,而且能够同时实现对时尚单品的内容迁移(如颜色、纹理)和风格迁移(如莫奈风、立体派),进而有效地完成多个图像域的特征融合。
(2)本文提出了层一致性动态卷积的时尚风格迁移方法,它可以将风格特征编码为可学习的卷积参数,而这些参数是根据不同的风格图像自适应改变的,这样能够对时尚单品实现更高效、更灵活的风格迁移。
(3)在公开的数据集上进行了大量的实验,验证了本文提出的CS-GAN模型的有效性,在图像合成质量以及定量评估指标上有了明显的提升。
1 基于生成对抗网络的时尚内容和风格迁移
本章详细介绍了CS-GAN模型,其具体的结构框架如图2 所示。该模型在多域特征融合的生成对抗网络基础上,采用基于层一致性动态卷积的时尚风格迁移和基于对比学习的时尚单品内容迁移。

图2 CS-GAN模型整体结构图Fig.2 Overall structure diagram of CS-GAN model
1.1 问题描述
首先对文中的一些符号进行声明。通过X={x1,来表示时尚单品集合,并通过和来分别表示风格和内容的图像集合。其中,Nx、Ns和Nc分别为时尚单品、风格图像和内容图像的总数量。在这项工作中,设计了一个时尚单品生成的建模方案ψ。它对输入的时尚单品xi、风格图像sj和内容图像cu的特征进行融合,最终生成图像z。该图像在保留时尚单品全局结构信息(如外部轮廓)的同时还融合了风格图像的特征(如莫奈风、立体派)和内容图像的特征(如颜色、纹理),其中风格特征突出的表现是色调的变化。该方案不仅能够在未配对的数据集上实现多个图像域特征的融合,且只需要学习它们之间单向的映射。其表达式如下:
其中,Θ为模型待学习的参数。
1.2 多域特征融合的生成对抗网络
当前CycleGAN[17]在两个域的未配对图像生成任务上实现了复杂的局部纹理转换[35],如图像的语义合成[36-37](马到斑马的转换)、风格迁移[38-41](季节互换)和图像着色[30-31](百年旧照上色)。本节采用CycleGAN[17]的生成器和判别器作为基本的生成对抗网络。与之不同的是,设计了一个双分支的判别器,从而实现了多域的特征融合。假设给定一件时尚单品xi,主要任务是通过生成器G将它转换成融合了风格和内容特征的时尚单品z,其转化过程如下:
其中,ΘG表示生成器G中所涉及的相关参数。该生成器G由编码器、转换器和解码器三部分构成。其详细的网络架构如图3所示。
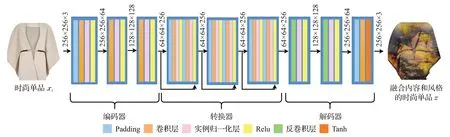
图3 生成器网络结构Fig.3 Generator network structure
当给定一件时尚单品xi时,编码器主要通过一个三层卷积神经网络来学习它的视觉特征编码HN:
其中,Θenc={Wn,bn|n=1,2,…,N}为编码器网络的相关参数。Wn和bn分别表示权重和偏差。Hk为第k层的隐含表示。设置N=3,f(·)表示Relu激活函数。将编码器最后一层的输出HN∈ℝw×h×c作为时尚单品xi的视觉特征编码。其中,w×h×c表示视觉特征编码的维度。
转换器主要将时尚单品的视觉特征编码HN转换成融合了风格和内容的特征编码CSm。它采用了易优化的深度残差网络结构[42],不仅保留了时尚单品xi的全局结构信(如外部轮廓),还缓解了在深度神经网络中增加深度带来的梯度消失问题[43]。该网络结构可用如下公式表示:
其中,η(·)为残差函数。Θtrans表示转换器网络的相关参数。M是残差块的个数,这里M=3。同样,转换器最后一层的输出CSM是时尚单品xi融合风格图像sj和内容图像cu的高级特征信息。
接下来是解码器,它与编码器相反,由两个反卷积层和一个卷积层组成。可以将高级特征信息CSM解码成融合内容和风格的时尚单品z,其相应参数为Θdec。生成器的参数使用来表示。
双分支判别器的结构与其他主流方法类似,均采用PatchGAN[44],根据生成对抗网络的原理,判别器和生成器相互博弈,对生成的图像进行真假判别。一方面,为了让时尚单品的风格特征更加逼真,设计了如下的风格对抗损失函数:
其中,Ds为风格判别器,它让生成图像的风格与输入的风格图像更接近。另一方面,为了让时尚单品的内容图像特征迁移更充分,设计了如下的内容对抗损失函数:
其中,Dc为内容判别器。
图4展示了多域特融合流程图,通过训练一个生成器、两个判别器、内容迁移和风格迁移模块来实现多域特征融合。该任务的输入为时尚单品、内容和风格三个图像域。首先时尚单品经过编码器得到时尚单品的全局结构特征,与此同时,风格图像输入到基于层一致性动态卷积的风格迁移网络中得到风格特征(如莫奈风、立体派),内容图像经过基于对比学习的时尚内容迁移模块后得到内容特征(如纹理、颜色)。然后时尚单品、风格和内容特征经过转换器后进行特征融合,最后通过解码器生成融合内容和风格的时尚单品。
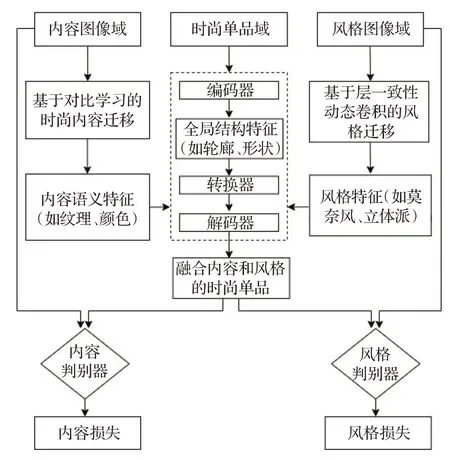
图4 多域特征融合流程图Fig.4 Multi-domain feature fusion flow chart
1.3 基于层一致性动态卷积的时尚风格迁移
为了更好地实现时尚单品的风格迁移,基于GAN设计了一种通用的层一致性动态卷积变换(LCDC)方法。该方法将风格图像和时尚单品编码器网络的对应层进行动态卷积变换操作,进而自适应地将任意的风格特征(如莫奈风、油画风)融合到给定的时尚单品中,从而有效地实现时尚单品的风格迁移。这里以风格图像sj和时尚单品xi编码器的第一层为例,其详细的网络结构如图5所示。
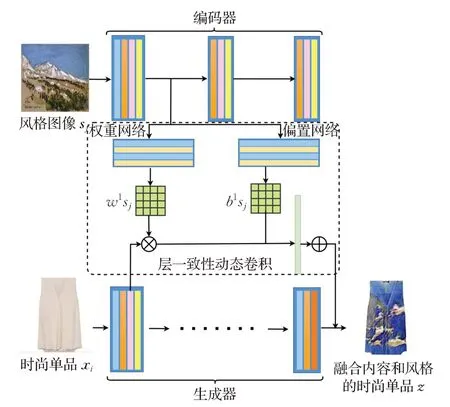
图5 层一致性动态卷积变换方法Fig.5 Layer to layer matching dynamic convolution structure
首先,风格图像sj经过编码器得到风格编码特征Fs,如公式(7)所示。此编码器与时尚单品编码器结构一致且共享网络参数。
将风格图像sj第一层卷积后得到的风格编码特征F1在分别经过权重网络和偏置网络后分离得到风格图像的权重和偏置。这两个网络分别由两层卷积层和自适应池化层构成。此时将得到的和与时尚单品xi在第一层卷积后得到的时尚单品特征做动态卷积操作,如下所示:
其中,IN(·)为实例归一化操作,可展开如下:
与卷积操作相比,层一致性的动态卷积操作接收两个输入。第一个输入是来自时尚单品的特征映射,第二个是风格图像分离出来的权重W和偏置b。特征映射是对输入的时尚单品编码后获得;在传统卷积中,权重和偏置为模型的参数,而在层一致性的动态卷积变换中,W和b是对输入的不同风格图像编码后再分别经过权重网络和偏置网络后的动态输出。然后对这两个输入采用与卷积层一样的方法进行卷积计算。这就是时尚单品xi与风格图像sj特征进行融合的过程。
最后将得到的时尚单品与风格图像的融合特征传递到解码器,然后能够更充分地实现时尚单品的风格迁移。其余两层可以通过类似的方法得到。
1.4 基于对比学习的时尚内容迁移
为了更好地保留时尚单品的全局信息(如轮廓、形状)和更充分地实现内容图像语义信息(如纹理、颜色)的迁移,采用了对比学习的方法。其主要思想是学习生成图像与输入的时尚单品之间的对应关系,让它们之间相似的图像块相互关联,不相似的图像块相互远离,即最大化时尚单品与生成图像之间的互信息。例如给定一张上衣衣领的图像块,在其转换后的图像也应当包含衣领的图像块,而不是对应到其他区域。采用噪声对比估计[45](noise contrastive estimation,NCE)框架最大化输入的时尚单品与生成图像块之间的互信息,该方法旨在学习时尚单品与生成图像块之间的跨域相似性函数。对比学习由三个信号组成:生成图像中的目标样本(如图2青色图像块),时尚单品中的正样本(如图2绿色图像块)和负样本(如图2黄色图像块)。首先将生成图像中的目标样本v和时尚单品中的正样本v+以及N个负样本v-,分别映射为K维向量c,,其中表示第n个负样本。为了防止模式崩塌,这些样本经过归一化后变成单位向量,由此建立了一个N+1 类的分类问题。通过交叉熵损失函计算出正样本被选择的可能性,对比损失函数可表示如下:
其中,τ是比例超参,常被称为温度系数,c·c+和c·c-分别表示生成图像的图像块分别与时尚单品中的正样本和负样本这两个单位向量的内积。
本文采用基于多层次图像块的对比学习实现时尚单品的内容迁移,如图6所示。使用编码器Genc和两层MLP[46]来提取生成图像和时尚单品的特征。假设选择时尚单品xi的共L层特征图,然后将特征图传递给两层MLP 网络Vl,生成一堆特征,其中表示第l层特征的输出,rl表示图像块第l层特征,l表示层数(l∈{1,2,…,L})。这其中的每一个特征代表输入时尚单品xi的一个图像块。然后用k∈{1,2,…,Kl}表示每层的图像块数,其中Kl表示第l层有Kl个图像块。将时尚单品中正样本的特征表示为,负样本特征表示为,其中表示第l层中第k个图像块对应的特征向量,Tl表示第l层的通道数,K/k表示所有的图像块K中除去k的特征图像块。生成的图像z也以相似的方式进行,表示为。目标是将时尚单品xi与生成图像z对应位置的图像块进行匹配,同一张时尚单品的其他图像块作为负样本相互远离,最终通过对的每一层输出,以及输出的每个图像块的特征向量求互信息,来保证时尚单品xi与生成图像z之间语义和结构的一致性。上述的损失函数表示如下(ℓ为公式(10)):
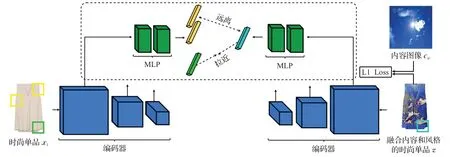
图6 多层次图像块对比学习Fig.6 Patch-based multiplayer contrastive learning
同时,像素级的L1 损失可用于保证生成图像的清晰度,通过最小化生成图像z与内容图像cu之间的像素级损失来完成,公式如下:
最后,通过GAN 与对比学习相结合的方式实现时尚单品单向的内容迁移并保留时尚单品的全局结构信息,最终的内容损失可表示如下:
1.5 总目标损失
基于层一致性动态卷积方法实现时尚单品的风格迁移和采用对比学习策略完成时尚单品内容迁移,并通过多域特征融合的生成对抗网络将以上两个模块融合起来,实现时尚单品的内容和风格迁移。总目标函数可表示如下:
其中,α和β分别表示平衡目标损失的超参数。
2 实验结果与讨论
2.1 实验设置和数据集
为了验证本文方法的有效性,在Ubuntu 20.04系统下,使用基于Python的Pytorch框架,实现本文提出的基于生成对抗网络的时尚内容和风格迁移。机器配置i9-7700 CPU,128 GB 内存和GeForce GTX 3090 显卡图形工作站。在训练前,所有的图片送入网络前都需要进行预处理,保持图像之间的比例关系,将大小重新调整300×300,然后从里面裁剪出256×256 大小区域作为训练样本输入,因此网络可以处理任意大小的输入,同时使用了随机翻转、旋转操作作为数据增强。在训练模型时,内容损失权重α=1,风格损失权重β=1,这是为了重建出的时尚单品图像能够保留同样多的内容信息和风格信息。训练时采用Adam 优化器并且设置优化器的学习率为0.000 2,训练的批次大小为32,epoch 为200。最终的损失如图7所示。
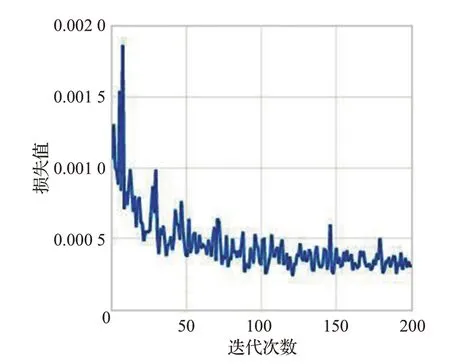
图7 总损失图Fig.7 Total loss
本文训练所使用的数据集有Fashion VC[47]数据集,其中包含20 765 张时尚单品图像,风格图像数据集,其在Wiki Art[48]的artworks 中选取26 472 张风格图像,大约有15 种风格和三种内容图像的数据集,分别为3 896张蓝天白云图像,3 489 张枫林图像和4 012 张草坪图像,均在百度图片爬取。对于每一个数据集,随机选取80%的样本做训练集,20%的样本做测试集。
2.2 评估指标
基于生成对抗网络的时尚内容和风格迁移的目标是使得生成的图像在保留原来时尚单品全局结构信息的基础上,生成具有融合内容和风格特征的时尚单品。使用图像转换任务中常用的评价指标平均分数(IS)、FID[49]、峰值信噪比(PSNR)[50]和结构相似度指数(SSIM)[50]来评估本文所提出的CS-GAN方法。
(1)IS是一种用来评价模型生成图像质量的评价指标,通过使用Inception Net图像分类网络来对生成图像进行分类得到。IS的计算公式如下所示:
其中,p(y|x)表示生成图像x分类为y的概率,p(y)表示对于每个生成图像的类别概率期望。
(2)FID是计算时尚单品与生成图像特征向量间距离的指标,其计算公式如下:
其中,ux和uz分别表示真实图像和生成图像的均值。
(3)PSNR 测量生成图像与其原始图像之间的峰值信噪比,是目前最为流行的图像重建质量评估指标。其具体的计算公式如下:
其中,maxx′表示最大像素强度值,x[i]和x′[i]分别为原始图像和生成图像的第i个像素值。
(4)SSIM根据图像的亮度、对比度和结构来测量生成图像x′和真实图像x之间的结构相似度。其具体的计算过程如下:
其中,μx和μx′分别为x和x′的像素均值,σxx′是x与x′之间的协方差。
2.3 实验结果与分析
2.3.1 对比实验
为了科学地评估本文提出的CS-GAN 模型对输入的时尚单品同时进行在内容和风格特征融合的有效性,本文选取不同的数据集进行了多组实验,结果如图8所示。

图8 生成结果Fig.8 Generate results
但由于目前图像生成方面尚未有内容和风格的同时迁移,因此这里将本文方法的效果分别与以下基准方法中单一的内容迁移或风格迁移任务进行了比较:
(1)CycleGAN:将模型中生成器的网络结构替换为CycleGAN[17]。它是为了解决无监督的图像到图像的翻译问题而设计的,主要通过前向和后向循环一致性网络来训练不成对的数据。
(2)CUT:CUT[51]利用源域中的正负样本实现内容迁移。但其负样本的选择还利用数据集中其余图像的图像块,这在本文的任务中是不必要的。
(3)FastCUT:将FastCUT[51]扩展到对时尚单品的内容迁移任务中。具体来说,FastCUT中也是用的对比学习框架对内容特征进行编码。
(4)Adain:Adain[24]采用手动定义仿射参数变换的方法,训练过程比较漫长且对时尚单品只进行风格迁移。
(5)DIN:该方法[52]采用动态实例归一化进行风格迁移,直接对生成图像分别与目标图像和源域图像进行损失计算。
图9详细地展示了不同基准方法的性能比较,可以观察到以下结果:(1)传统的CycleGAN 模型对时尚单品进行内容迁移时效果时而细腻,时而粗糙,内容特征迁移不稳定,有时还未能体现出内容图像原本的色彩,也未能精细地保留时尚单品的细节;(2)CUT 的内容迁移效果略显粗糙且清晰度不高,因为细节特征的不足造成视觉效果模糊,颜色变化不真实;(3)FastCUT结果在CUT基础上有所改善,未能对时尚单品实现风格,仅实现两个图像域间的转换;(4)在风格迁移方面,Adain 输出结果相较于时尚单品存在明显的失真和伪影,存在着不自然的色块,破坏了整体的观感,且时尚单品原本特征的保留和风格特征的表现上有所欠缺;(5)DIN 结果在风格迁移过程中生成图像的背景会发生颜色变化且时尚单品轮廓模糊,存在部分细节特征的丢失。而本文提出的CS-GAN模型生成的图像相较于其他的方法,在时尚单品结构的基础上更好地保留了内容图像色彩层次、细节信息和风格图像纹理特征,更加接近内容和风格图像的融合,在实现整体内容和风格迁移时没有发生明显的形变,可以实现很好的艺术感与真实并存的滤镜效果,从而获得良好的整体观感。无论是细节的保留还是整体色彩的观感都有着更为优秀的表现。

图9 不同方法生成结果的对比Fig.9 Comparison of results generated by different methods
此外,表1还显示了不同基准方法的生成的结果在IS、FID、PSNR 和SSIM 指标上定量评估结果。分别在三种内容数据集(蓝天白云、枫林和草坪)上进行了测试,通过表中的数据可以看出:(1)CS-GAN模型相较于其他模型均取得了更好的实验结果,说明同时考虑风格迁移和内容迁移进行多个图像域的特征融合具有更好的优越性;(2)CycleGAN 的性能略低于本文所提出的CS-GAN,主要由于其严格的双射条件难以满足,所以合成的时尚单品效果略差;(3)CS-GAN 的性能优于CUT 和FastCUT。这归因于CUT 中的负样本还来源于数据集中其他图像的图像块,导致编码器会冲淡对于输入的时尚单品的关注度;而FastCUT与CS-GAN的生成器结构相比,缺少将时尚单品特征转换为内容特征的转换器。所以CS-GAN 模型在对时尚单品进行内容和风格迁移效果上有一定的优势。

表1 不同方法间的定量指标对比Table 1 Comparison of quantitative indicators among
2.3.2 消融实验
为了进一步说明本文所提出的CS-GAN 模型的有效性,对该模型的几个重要组成部分进行了消融研究。首先,分别禁用CS-GAN 中的风格迁移和内容迁移模块,从而得到CS-GAN 的衍生模型C-GAN 和S-GAN。其中,C-GAN 仅通过对比学习策略来实现时尚单品的内容迁移,而S-GAN 则基于层一致性动态卷积来衡量时尚单品的风格迁移性能。然后,通过同时禁用CS-GAN中的风格迁移和内容迁移模块得到其基础生成对抗网络模型GAN。最后,基于上述衍生模型,在不同的数据集上分别进行了风格迁移和内容迁移的消融实验。
图10 为不同衍生模型的实验结果,通过该图可以看出,网络去除风格迁移模块后生成图像如图10 第四列,在视觉上它多数保留了内容图像的特征,几乎无风格图像的特征;禁用对比学习框架后生成的图像如图10第五列,仅可实现时尚单品的风格迁移无内容特征。完整网络的生成结果如图10 第六列,它可以在原有时尚单品结构的基础上同时保留内容和风格信息,获得最佳的整体观感,从而证明了网络各部分的有效性。
表2 给出了C-GAN 在三个不同数据集(即蓝天白云、枫林和草坪)上的PSNR和SSIM性能比较。通过表2可以看出:(1)C-GAN在PSNR和SSIM两个评价指标上显著优于基础网络GAN,这很好地说明了内容迁移模块对提高图像质量有一定的优势,具有更高的性能增益;(2)本文的CS-GAN模型结果优于衍生模型C-GAN,在PSNR和SSIM方面大约提高了18%和3%,这很好地证明了综合考虑风格和内容模块进行多域特征融合建模的优势。
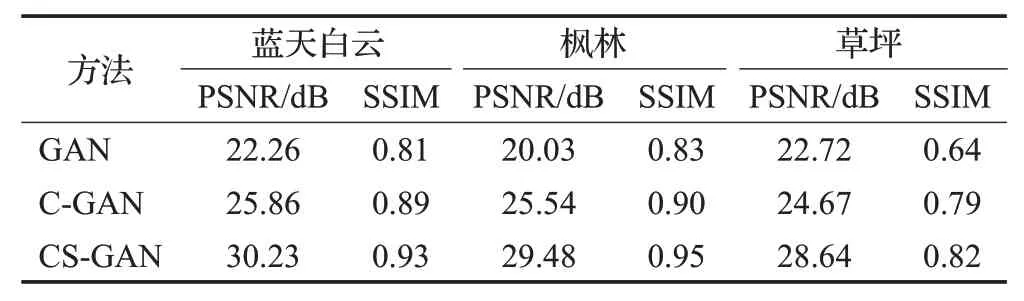
表2 内容迁移模块对CS-GAN模型的性能影响Table 2 Influence of content transfer module on performance of CS-GAN model
表3给出了S-GAN在抽象派、印象派和立体派三个风格数据集上的PSNR和SSIM性能比较。从数据中可以得知:(1)S-GAN提高了基础网络的性能,在PSNR和SSIM 方面大约提高了8%和1%,这说明风格迁移模块可以提高图像生成的性能;(2)本文模型CS-GAN 结果也优于衍生模型S-GAN,这证实了通过添加内容迁移模块可有效地实现多个图像域的特征融合任务,也证明了内容迁移模块的优势。
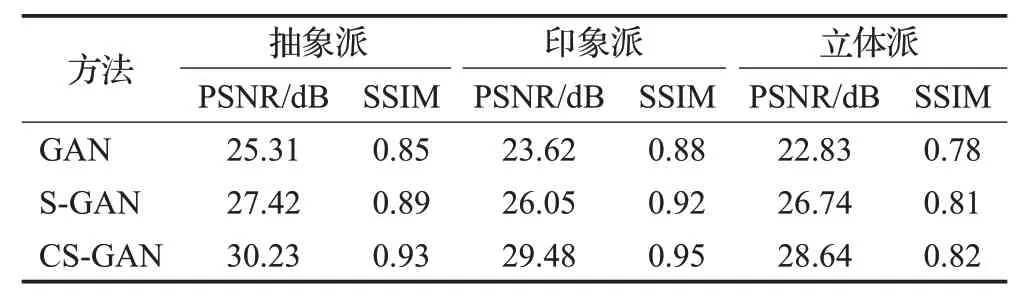
表3 风格迁移模块对CS-GAN模型的性能影响Table 3 Influence of style transfermodule on performance of CS-GAN model
更进一步地,为了证明风格迁移模块中IN 层可以带来更好的优化,将风格迁移模块中的IN层替换为BN层进行时尚单品的风格迁移任务,其他的训练设置保持不变。比较了损失函数的收敛速度,并将训练曲线的定量比较结果显示在图11。可以观察到,IN层与BN层相比实现了更快更好的收敛。
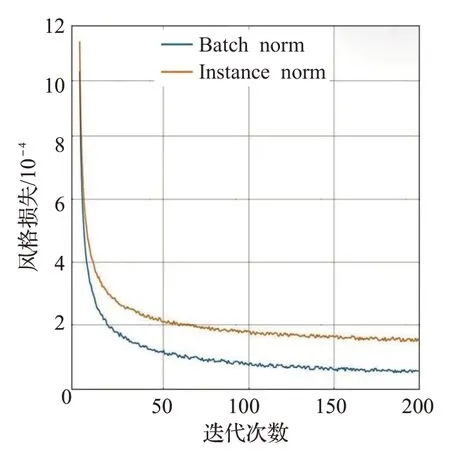
图11 风格损失对比图Fig.11 Style loss comparison
3 结束语
目前主流的未配对的图像到图像的转换通常都是建立在双射的基础上完成且只能实现两个域之间的转换。本文提出的基于生成对抗网络的时尚单品内容和风格迁移(CS-GAN)方法,在未配对数据集的情况下,可对时尚单品同时实现内容和风格图像的迁移,实现多个图像域特征的融合。在内容迁移模块,采用基于对比学习框架实现时尚单品的内容迁移,生成图像中的图像块都应该反应时尚单品中相对应的图像块,通过最大化生成图像与时尚单品之间的互信息,实现时尚单品的内容迁移。在风格迁移模块,提出了基于层一致性动态卷积方法,该方法可以将不同的风格特征编码为可学习的卷积的参数,然后将学习到的风格特征与时尚单品特征进行动态卷积操作,然后传递到解码器,最终实现时尚单品的风格迁移。通过以上的方法,可以充分利用内容和风格图像的信息,对时尚单品实现更好的迁移效果。
定性实验和定量实验的结果表明,本文所提的方法能够在保持时尚单品结构的基础上,实现内容图像的色彩、纹理和风格图像风格特征的巧妙融合,得到优于其他主流方法的整体效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
中国化妆品(2018年3期)2018-06-28
北京航空航天大学学报(2018年1期)2018-04-20
Coco薇(2016年10期)2016-11-29
米娜·女性大世界(2016年8期)2016-08-17
Coco薇(2016年5期)2016-06-03
Coco薇(2016年4期)2016-04-06
Coco薇(2015年5期)2016-03-29
Coco薇(2015年1期)2015-08-13
