
融合汉字输入法的BERT与BLCG的长文本分类研究
2024-05-11 03:33杨文涛雷雨琦李星月郑天成
计算机工程与应用 2024年9期
杨文涛,雷雨琦,李星月,郑天成
1.华中科技大学集成电路学院,武汉 430074
2.湖北大学知行学院人文学院,武汉 430011
随着自然语言处理研究的不断发展,文本分类作为其重要内容,被广泛应用于信息检索、新闻分类、情感分析、垃圾邮件过滤等领域[1-4]。随着互联网的普及,文本数据的规模不断的扩增[5]。在大数据时代,如何精准进行文本信息的分类成为当代研究的焦点[6]。
基于深度学习的文本分类的研究主要围绕文本表示、特征提取和特征分类三个方面。针对文本表示一般采用词嵌入方式,Google团队提出了Word2Vec[7]词向量训练工具,可以从大规模没有标注的语料中高效地生成词的向量表示,并提供了CBOW和SKip-gram这两种模型。Pennington等人[8]提出Glove模型,基于全局词频统计的词表征工具,考虑文本的局部信息和整体信息。然而,Word2Vec 与Glove 文本表示是静态的映射关系,没有考虑到在不同语境下词汇含义不同的问题,因此Google 团队在Transformer 模型[9]的基础上,提出了BERT(bidirectional encoder representations from transformers)模型[10],动态生成词汇的向量表示,解决了一词多义的问题。但是BERT模型最初为英文设计,对于中文文本分类,它忽略了中文特有的两个重要信息:读音、笔画,在一定程度上降低了模型的准确性。本文在BERT模型的基础上,融合五笔输入表示汉字的笔画,充分表示汉字的语义信息;通过拼音输入表示汉字读音,解决中文的多音词问题。
在特征提取领域,卷积神经网络[11]与循环神经网络[12]的结合在文本分类中层出不穷。Lai等人[13]提出了一种循环卷积神经网络用于文本分类,该模型选择的是BiRNN和CNN的结合,利用了两种模型的优点,提升了文本分类的性能。但是,RNN 存在梯度消失和梯度爆炸等问题,为此,Zhang 等人[14]提出了LSTM 和CNN 的混合模型,文献[15]提出了CNN 和LSTM 的混合模型。为了更好地获取文本的上下文特征,文献[16]提出了BiLSTM-CNN方法,采用BiLSTM模型获得两个方向的表示,然后通过卷积神经网络将两个方向的表示组合成一个新的表达式。然而,上述模型没有考虑到长文本中可能包含部分与目标主题无关的信息导致模型误判问题。为此,本文提出了门控机制动态的融合BiLSTM提取的全局特征信息与CNN 提取的局部特征信息,通过组合局部特征信息与全局特征信息,提高了长文本分类的准确性。
为了兼顾文本表示和文本特征提取,提高基于深度学习的中文长文本分类准确性。本文提出基于CIMBERT与BLCG相结合的中文文本分类。本文的贡献如下:
(1)在BERT 模型的基础上,通过拼音输入法与五笔输入法融入了读音与笔画两个重要的汉字信息,增强了汉字的语义信息,解决了中文常见的多音词问题。
(2)提出门控机制动态的组合BiLSTM提取的全局特征信息与CNN 提取的局部特征信息,解决了长文本中部分文本偏离主题,导致模型误判的问题,提升长文本分类的准确性。
在THUCNews与Sogou数据集上的实验表明,本文提出的分类模型精度较高。
1 模型分析
本文提出的模型由输入层、文本表示层、信息提取层和分类层4 部分组成。其中,对于输入层,获取输入文本的拼音嵌入向量与五笔嵌入向量,通过融合层与字嵌入向量进行融合,得到的融合嵌入向量与位置嵌入向量相加,作为整个模型的输入。文本表示层使用BERT模型对输入层传入的向量进行文本表示。信息提取层首先使用BiLSTM提取文本的全局特征信息,然后通过CNN 提取文本的局部特征信息。为了避免在长文本中,部分文本偏离目标主题导致的模型误判,使用门控机制动态地结合全局特征信息与局部特征信息,提高分类的准确性。最后将门控输出结果通过分类层获取最终的分类结果。模型的整体架构如图1所示。
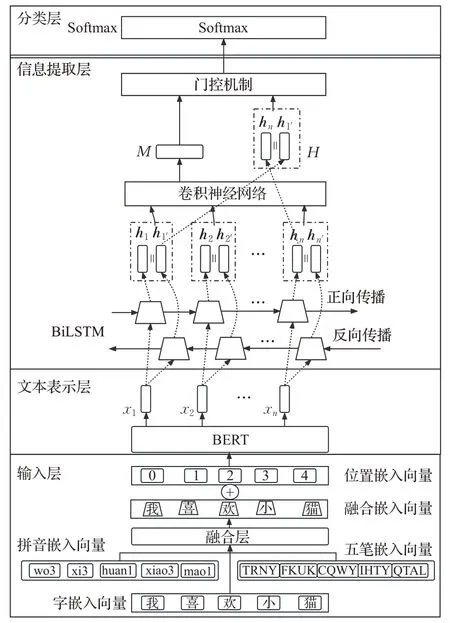
图1 系统模型架构Fig.1 System model architecture
1.1 输入层
在输入层中,首先获取输入文本的字嵌入向量、拼音嵌入向量与五笔嵌入向量,三种向量通过融合层获取融合嵌入向量,最后与位置嵌入向量进行相加,作为模型的输入。下面将详细介绍如何获取拼音嵌入向量、五笔嵌入向量与融合嵌入向量。
1.1.1 拼音嵌入向量
在输入向量中引入拼音嵌入向量是为了解决多音汉字的识别问题。本文采用开源的pypinyin 包生成指定汉字的拼音,构建了自定义拼音字母数字对应表,将拼音字母转化为数字,并在拼音字符最后拼接读音,每个汉字对应的拼音向量长度为8,如果长度不够使用0进行填充。通过拼音向量的引入,可以有效地区分多音汉字不同的语义。最后,通过CNN 将初始的拼音向量转化为拼音嵌入向量。获取拼音嵌入向量的方法如图2所示。
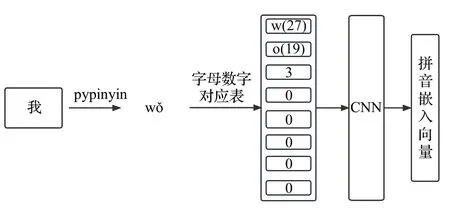
图2 拼音嵌入向量生成Fig.2 Procedure of creating Pinyin embedding vector
1.1.2 五笔嵌入向量
在输入向量中引入笔画信息是为了充分表示汉字的语义信息。五笔输入完全依据笔画和字形特征对汉字进行编码,是典型的形码输入法,可以表示汉字的笔画信息。本文使用98 版五笔构建汉字五笔对应表,通过汉字五笔对应表获取汉字的五笔表示,然后使用字母数字对应表获取数字向量,最后通过CNN 将初始的五笔向量转化为五笔嵌入向量。汉字的五笔嵌入向量获取如图3所示。
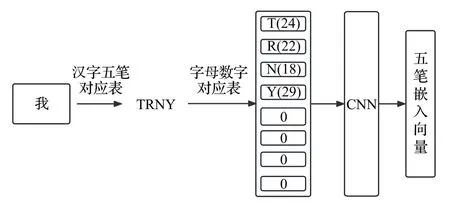
图3 五笔嵌入向量生成Fig.3 Procedure of creating Wubi embedding vector
1.1.3 融合嵌入向量
汉字的字嵌入向量可以通过词表对应获取,当获得了汉字的字嵌入向量、拼音嵌入向量、五笔嵌入向量后,按列维度进行拼接,最后通过全连接层进行降维,得到融合嵌入向量。与位置嵌入向量进行相加,作为整个模型的输入向量,融合嵌入向量的获取如图4所示。
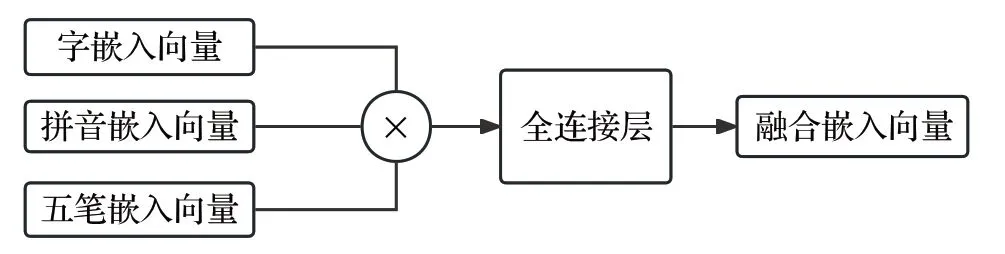
图4 融合嵌入向量生成Fig.4 Procedure of creating fusion embedding vector
1.2 文本表示层
文本表示层用于将输入文本表示为特征向量。本文采用BERT模型进行文本表示。BERT模型通过由双向Transformer 模型组成,可以根据上下文信息动态地生成词汇的向量表示,解决了一词多义的问题,BERT模型的结构如图5所示。
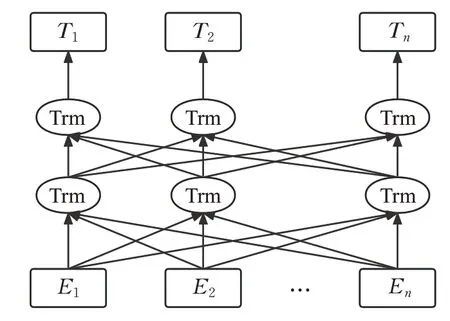
图5 BERT模型图Fig.5 Structure of BERT model
图5 中,Ei表示当前语句中第i个词,Trm 表示Transformer模型,Ti为第i个词对应的特征向量。
1.3 信息提取层
信息提取层采用BiLSTM 模型提取文本的全局特征信息,使用CNN提取文本的局部特征信息。最终,为了解决长文本中可能出现的部分文本偏移目标主题导致模型误判的问题,本文提出了门控机制动态组合全局特征信息与局部特征信息,解决了上述问题。
1.3.1 BiLSTM模型
本文使用BiLSTM 提取文本的全局特征信息。BiLSTM 包含了前向传播与反向传播LSTM,分别从正向和反向获取文本的全局信息。LSTM 单元如图6 所示,LSTM由遗忘门、输入门、输出门以及内部记忆单元组成。
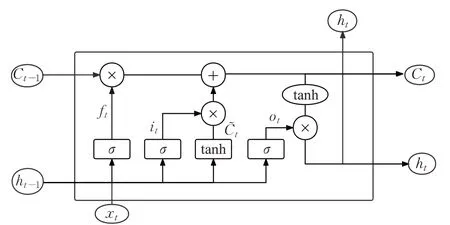
图6 LSTM模型图Fig.6 Structure of LSTM
对于BiLSTM,每一时刻t,都有前向传播的LSTM和反向传播的LSTM分别计算出隐藏层ht和ht′,然后对ht与ht′进行拼接,作为t时刻的BiLSTM的输出,见公式(1):
对于整个BiLSTM,可以得到输出为:
1.3.2 CNN模型
本文采用CNN提取文本的局部特征信息。CNN主要包含了卷积层和池化层。卷积层是CNN 模型的核心,它包含若干个卷积核,通过卷积核与输入向量的卷积操作进行特征的提取。池化层的目的是对卷积结果进行采样,减小卷积向量的大小,避免过拟合。池化方法分为最大池化和平均池化。在文本分类中,最大池化可以保留文本的关键信息。
1.3.3 门控机制
在长文本分类中,文本中常常携带着与目标主题无关的信息,甚至部分文本与其他主题有关,在使用CNN做局部特征提取时可能会提取到其他的主题信息,导致模型的误判,因此,保留全局特征信息是非常有必要的。在本文中,提出了一种门控机制,可以动态地对局部特征信息与全局特征信息分配权重并相加。通过门控机制可以有效地提高长文本分类的准确度。门控机制的计算公式见公式(3)~(5):
其中,M为CNN输出的向量,H为BiLSTM输出的hn与h1′的拼接,α1为H的权重,W与b分别表示权重矩阵与偏置向量,Z表示经过门控机制最终的向量输出。
1.4 分类层
将门控机制输出的向量Z分别经过全连接层进行降维,并最终由Softmax函数决定输出的标签类别,分类层的计算见公式(6):
其中,a表示当前标签种类,Wk、Wa与bk、ba分别表示对应的权重矩阵与偏置向量。
2 实验验证
2.1 实验环境
为了验证分类模型的性能,本文模型的实验平台为Ubuntu20.04 操作系统,硬件为Intel®Xeon®Platinum 8350C,16×2.6 GHz 处理器、43 GB 内存、RTX 3080 Ti显卡,模型采用Python 编程语言实现,版本为3.7,使用深度学习的框架为Pytorch 1.10.0,编码工作主要使用Pycharm开发工具进行完成。具体实验环境如表1所示。
2.2 实验数据集
实验选取了THUCNews 数据集与Sogou 语料库作为实验的数据集。
THUCNews 为THUCTC 数据集的子数据集,包含了运动、金融等10 类标签数据,每个标签选取了5 000的训练数据与1 000 的测试数据,总训练集数据和总测试集的数据数量分别为50 000和10 000。
Sogou 语料库由搜狗实验室提供,包含了Sogou CA与Sogou CS两个数据集,本文过滤了其中数据较少的类别以及较短的数据,保留了运动、健康、环境等10个类别,每个类别包含10 000 的训练数据与2 000 的测试数据。
数据集经过处理后统计信息如表2所示。

表2 数据集概况Table 2 Dataset overview
2.3 评价指标
本文选取的评价指标为文本分类领域通用的评测标准:准确率、精确率、召回率和F1-score。
在测试数据中,FP表示实际为负、但是被预测为正的样本数量,TN表示实际为负、但是被预测为负的样本数量,TP 表示实际为正、但是被预测为正的样本数量,FN表示实际为正、但是被预测为负的样本的数量。
准确率为分类正确的样本占总样本个数的比例,准确率Acc的数学定义见公式(7):
精确率表示测试集中预测为正类正确的比率,由测试样本中预测正确的正例样本数量除以所有预测为正例的样本总数得到,精确率P的计算公式为:
召回率表示原有样本中有多少正例被预测,由原有样本中预测为正例的样本数除以样本中总正例的个数得到,召回率R计算公式为:
F1-score 是评价分类文本的综合标,F1-score 的计算公式为:
2.4 实验结果分析
为了验证提出的长文本分类模型的合理性与有效性,本文在THUCNews数据集与Sogou语料库下进行不同的文本分类模型进行对比测试。本文提出的模型具体的超参数如表3所示。

表3 模型超参数设置Table 3 Parameters setting
将提出模型和以下7种文本分类模型进行对比评估。
(1)BERT:使用BERT 模型对数据集进行预训练并提取深层特征后,使用全连接层将生成的对应向量输入一个Softmax函数进行计算得到分类结果[10]。
(2)ChineseBERT:在BERT 模型的基础上,在输入层融入了中文拼音和汉字图片特征,在一定程度上优化了中文的文本分类任务[17]。
(3)RCNN:由RNN 与CNN 相结合的文本分类模型,首先采用BiLSTM 对文本的特征向量进行提取,再将其与嵌入层输出的词向量进行拼接,然后经过一层卷积后实现对文本的分类[16]。
(4)BERT_RCNN:使用BERT进行词向量化后输入到RCNN模型中进行文本分类[18]。
(5)CNN_LSTM:由CNN与LSTM相结合的文本分类,分别使用CNN 与LSTM 来局部特征提取与全局特征提取,最后进行文本分类[15]。
(6)ERNIE:由百度团队提出的一种知识增强语义的预训练模型,核心由Transformer构成,在多个NLP中文任务上有优异的表现[19]。
(7)RoBERTa:在BERT 模型的基础上做了增强,拥有更大的模型参数以及更多的训练数据,对BERT模型很多细节进行了优化[20]。
具体的对比实验结果如表4、表5所示。
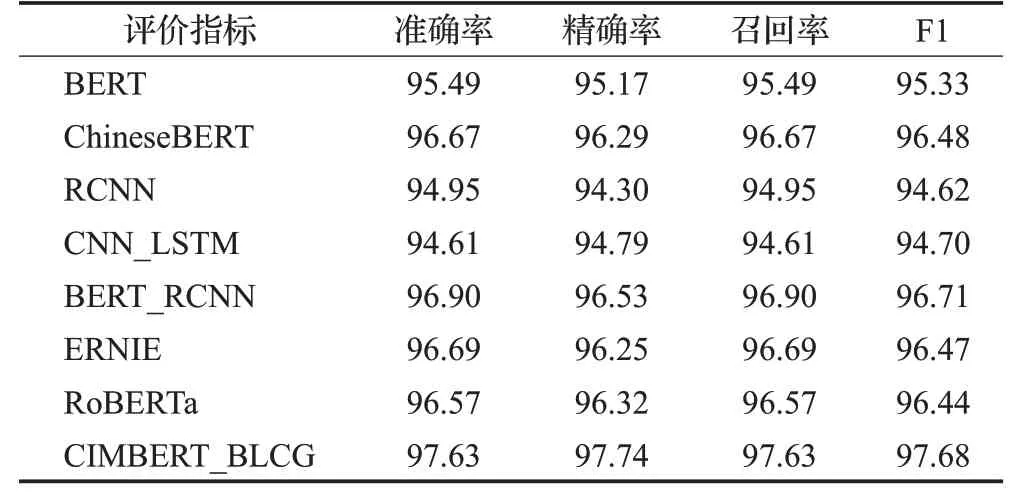
表4 THUCNews数据集上各模型实验结果比较Table 4 Comparison of experimental results of several models on THUCNews 单位:%
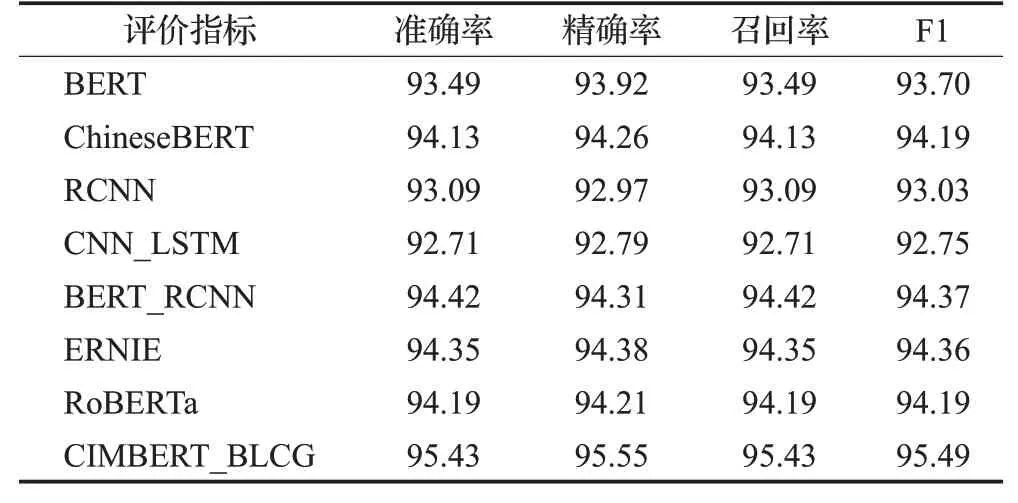
表5 Sogou数据集上各模型实验结果比较Table 5 Comparison of experimental results of severalmodels on Sogou 单位:%
根据表4 和表5 所示的实验结果发现:本文提出的模型对比现有的文本分类模型,在THUCNews 数据集和Sogou语料库准确率和F1-score分别达到了97.63%、97.68%与95.43%和95.49%,在所有对比实验模型中表现最优,验证了本文提出模型的有效性。
2.5 模型局部验证
文本的模型主要包含两个部分:融合汉字输入法的BERT、含门控机制的长短期记忆卷积网络。为了分别验证两个网络对文本分类结果都具有积极的效果,设计了如下几组对照实验,其中,BERT_pinyin为在BERT模型中融入了拼音输入;BERT_wubi为在BERT中融合了五笔输入;BERT_BLCG 为BERT 模型与BLCG 模型的组合;BERT_pinyin_BLCG 为融合拼音输入的BERT 模型与BLCG 模型组合;BERT_wubi_BLCG 为融合五笔输入的BERT 模型与BLCG 模型组合。具体的实验结果如表6、表7所示。
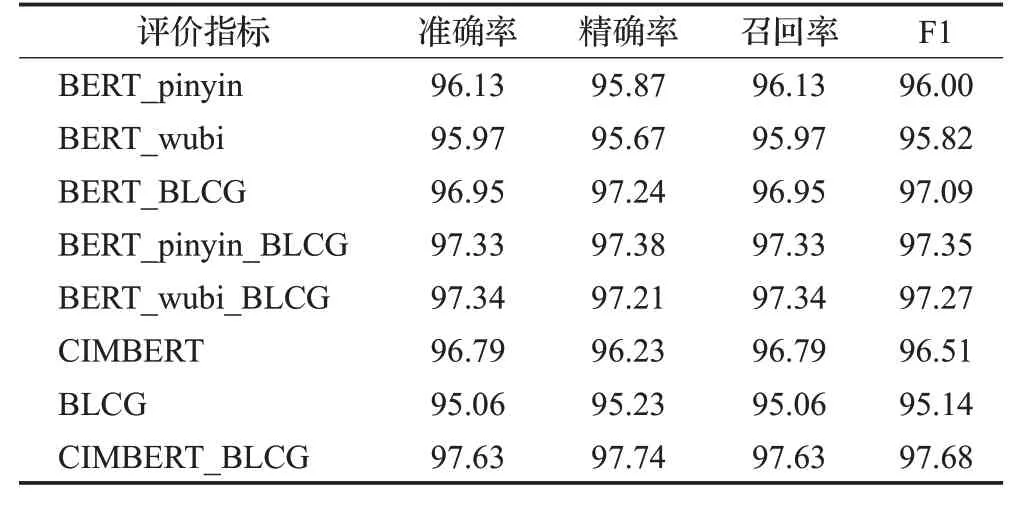
表6 THUCNews数据集在局部模型对比实验结果Table 6 Comparative experimental results of partial models on THUCNews 单位:%
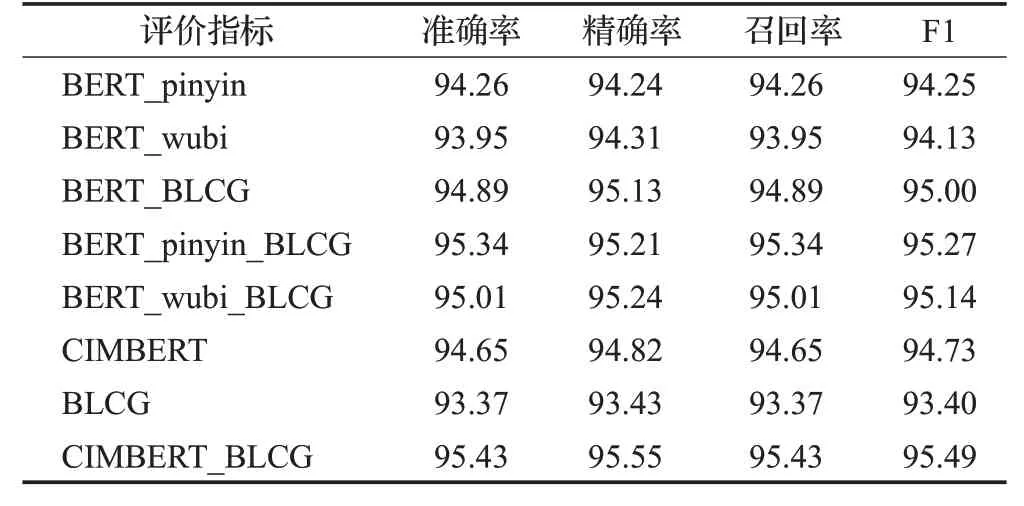
表7 Sogou数据集在局部模型实验结果比较Table 7 Comparison of experimental results of partial models on Sogou 单位:%
由表6、表7 数据可知,对于整个CIMBERT_BLCG来说,模型的两个部分CIMBERT 与BLCG 对模型都具有积极的影响,具体如下:
(1)CIMBERT:由CIMBERT与BERT的实验对比可知,在THUCNews与Sogou两个数据集上,模型F1值的提升分别为1.18与1.03个百分点,同时,CIMBERT_BLCG相较于BERT_BLCG来说,模型的F1值提升分别为0.59与0.49 个百分点,说明了CIMBERT 相比于BERT 更能表征中文语义。在CIMBERT_BLCG中,去除CIMBERT模型后,剩下的BLCG 模型与CIMBERT_BLCG 模型相比F1值在两个数据集上分别下降了2.54与2.09个百分点,验证了CIMBERT模型对整体具有很大的积极效果。
(2)BLCG:由RCNN 与BLCG、BERT_RCNN 与BERT_BLCG 对比实验可知,在THUCNews 与Sogou 两个数据集上,F1 值提升分别为0.52 与0.37 个百分点以及0.38与0.63个百分点,说明BLCG模型在一定程度上优化了RCNN模型。在CIMBERT_BLCG中,去除BLCG模型后,仅剩的CIMBERT 模型与CIMBERT_BLCG 相比F1值在两个数据集上分别下降了1.17与0.76个百分点,验证了BLCG模型对整体具有积极效果。
(3)拼音输入与五笔输入:由表中数据可知,在同等条件下,融合拼音输入相较于五笔输入,模型的准确率略高,在一定程度上说明在模型中融合拼音嵌入更能表征汉字的语义信息,但在整体上拼音输入与五笔输入相辅相成,都是不可或缺的。
总体来说,本文提出的CIMBERT 与BLCG 的文本分类模型在THUCNews 数据集与Sogou 语料库上训练结果有较好的表现。主要通过在输入层融合了拼音与五笔输入法,并在信息提取层用过门控机制动态地组合全局特征向量与局部特征向量。最后通过实验验证了本文提出的模型的合理性。
3 总结
本文针对中文的长文本分类,提出了融合汉字输入法的BERT 与BLCG 的文本文本分类模型。使用融合拼音输入和五笔输入的BERT模型进行中文文本表示,融合中文的语义信息,解决了中文多音字的问题。在信息提取层首先使用BiLSTM进行全局特征的提取,然后通过CNN 进行局部特征的提取,为了解决长文本中部分文本与目标主题无关导致的误判问题,提出了门控机制,动态地组合全局特征信息与局部特征信息。最后通过分类器进行分类。实验表明,本文提出的模型准确率与F1-score均优于其他的深度学习文本分类模型。
在未来的工作中,需要解决以下几个问题:(1)CIMBERT_BLCG 模型相较其他模型时间复杂度高,训练时间较长,未来会设计并行计算减少模型训练时间。(2)本文提出的分类模型聚焦于增强中文语义,减少与主题无关信息对模型判断的干扰,未来希望能够将模型用于一些特定场景的短文本分类中。(3)在BERT 模型中融合拼音、五笔输入法,提升了模型的效果,未来会考虑四角码等更多的输入方式,以增强模型汉字语义信息,提升模型准确率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小学阅读指南·低年级版(2017年4期)2017-04-24
小学阅读指南·低年级版(2017年1期)2017-03-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小天使·一年级语数英综合(2015年8期)2015-07-06
小天使·一年级语数英综合(2015年2期)2015-01-14
