
结合Transformer和动态特征融合的低照度目标检测
2024-05-11 03:33陈慈发董方敏
计算机工程与应用 2024年9期
蔡 腾,陈慈发,董方敏
1.三峡大学计算机与信息学院,湖北 宜昌 443002
2.三峡大学湖北省建筑质量检测装备工程技术研究中心,湖北 宜昌 443002
目标检测作为计算机视觉领域的基础任务,在近年来取得了长足的进展,并广泛应用于自动驾驶、智能监控等多个领域。在实际应用中,目标检测面临着多种困难,如复杂背景、遮挡和光照变化等,特别是在低照度条件下,会出现目标与环境边界不明显、局部过曝与模糊等问题,这使得检测算法的性能下降。因此,设计一种针对低照度场景下的目标检测算法具有重要意义。
目标检测算法分为多阶段和单阶段两种类型。多阶段方法通常包括候选区域提取和特征提取两个阶段,包括Fast R-CNN[1]、Faster R-CNN[2]和Cascade R-CNN[3]等。单阶段方法直接预测目标的位置和类别,具有较快的速度和较低的计算量,如YOLO[4]、SSD[5]和RetinaNet[6]等。其中,YOLO系列算法在速度和准确率方面均有优异的表现,是目前单阶段目标检测算法中的代表。目前,YOLO 系列已经发展到了YOLOv8[7],YOLO 系列算法在COCO数据集上已经取得了令人瞩目的进展,但是针对低光照条件下的目标检测仍存在挑战。
为了解决低照度下目标检测识别率低的问题,国内外学者开展了广泛研究。张蕊等人[8]通过引入深度可分离卷积、多种注意力机制和空洞卷积,提高了无人驾驶车辆在夜间场景下的检测精度和速度。Kalwar等人[9]提出GDIP和MGDIP,通过学习多种图像预处理操作的权重和并发处理,显著提高了低照度下目标检测性能。Qin等人[10]提出了一种包含DENet和YOLOv3的联合增强-检测框架DE-YOLO,其中DENet负责自适应地增强低光图像,然后将增强后的图像输入到YOLOv3[11]进行目标检测。麦锦文等人[12]提出了一种基于特征交互结构(FIS)的方法,通过全局注意和局部卷积抽取弱光图像特征,能有效解析、利用和结合局部与全局信息。舒子婷等人[13]提出了YOLOv5_DC模型,使用双通道输入、特征增强和定位模块来提高低光照条件下的检测精度。为了解决低能见度场景下的目标检测效果,陈永麟等人[14]使用红外成像技术并提出ITB-YOLO,通过改变多尺度融合关系提高检测精度。Hu等人[15]提出了PE-YOLO算法,使用金字塔增强网络并将其与YOLOv3模型相结合,在低照度场景中取得优秀的检测效果。Sasagawa等人[16]提出了一种域自适应方法,融合低照度图像增强模型和目标检测模型实现夜间目标检测。Yin等人[17]基于离散余弦变换(discrete cosine transform,DCT)提出了一种DCT 驱动的低照度增强Transformer(DEFormer),将DCT 信息作为线索嵌入到网络中,然后与YOLOv3算法结合,增加了识别准确率。虽然上述方法在检测准确度方面表现良好,但计算量较大,夜间监控、无人机夜间飞行等场景无法提供足够的算力支持。为了降低计算复杂度并且提高低照度目标检测准确率,Ali 等人[18]融合脉冲神经网络和卷积神经网络用于低照度目标检测,虽然该方法计算量降低了计算量,但是识别准确率相对较低。为了在保持模型轻量化的同时提高其在低照度场景下的目标检测识别率,本文提出一种基于YOLOv8 的轻量化夜间目标检测模型DarkYOLOv8,该模型具有计算量小和高准确率的特点,主要改进有:(1)使用MobileNet v2[19]替换YOLOv8的主干网络,增加特征提取能力以提高模型识别精度。(2)在MobileNet v2中融入Transformer全局注意力[20],并提出一种可以监督训练Transformer 参数的方法,使得Transformer 能够更加准确地找出低照度环境下难辨认的目标。(3)在颈部结构中提出并使用DFFA 模块,融合浅层和深层特征,同时使用YOLOv8X 对DFFA 模块进行监督训练,增强DFFA模块的特征提取能力。
1 YOLOv8算法原理
目前YOLOv8是YOLO系列最新的目标检测算法,其具有更快的检测速度和简单的网络结构。根据不同的大小,YOLOv8可分为YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l、YOLOv8x 五个版本。整体网络结构如图1所示,主要包括四个部分,即Input 输入端、Backbone 主干网络、Neck颈部网络和Head输出端。
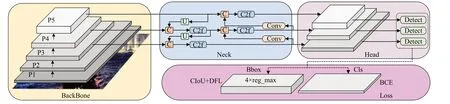
图1 YOLOv8结构Fig.1 YOLOv8 structure
在YOLOv8的主干网络中,C2f作为特征提取模块,由Conv、Split、n个DarkBottleneck 以及Concat 组成。其中,Concat接收Split和n个DarkBottleneck的输出,将其拼接在一起,并使用Conv 进行特征融合。YOLOv8的Neck在YOLOv5的基础上进行了改进,将C3模块替换为C2f模块。Head采用了当前主流的解耦头结构,将分类和检测头分离,并且将Anchor-Based方式转变成了Anchor-Free方式。
2 DarkYOLOv8
2.1 使用MobileNet v2作为主干网络
MobileNet v2 采用了深度可分离卷积、线性瓶颈、倒残差设计策略。其在640×640 输入分辨率下的主干网络的结构如表1所示。t表示第一层1×1卷积层中卷积核的扩展倍率,c表示输出特征矩阵的深度(通道数),n是Bottleneck(瓶颈)块的重复次数,s表示步距。
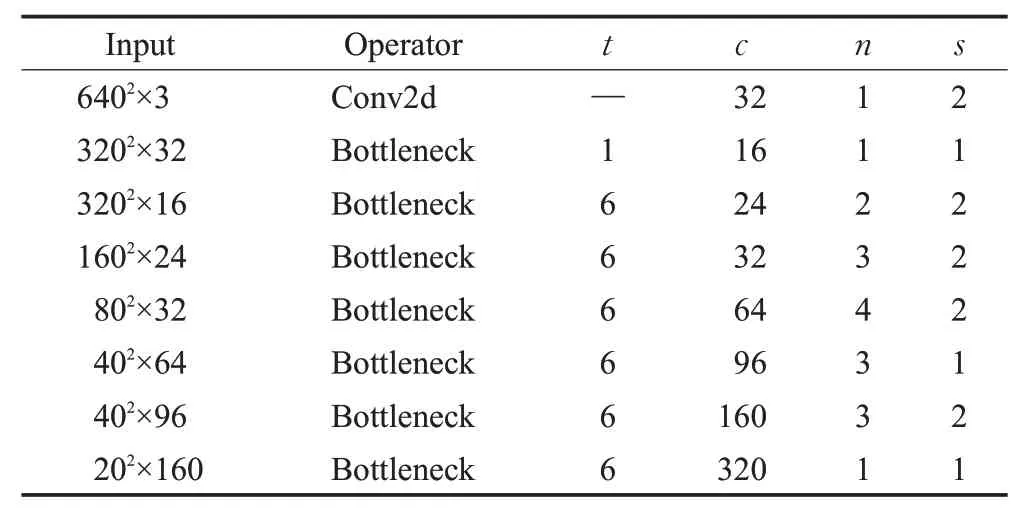
表1 MobileNet v2主干网络结构参数Table 1 MobileNet v2 backbone structure parameters
Bottleneck 块是MobileNet v2 的核心结构,由倒置残差块和线性瓶颈层组成。如图2 所示倒置残差块首先通过1×1 卷积扩展输入通道,以增加特征的表征能力,然后使用3×3 深度可分离卷积提取特征,最后通过1×1逐点卷积压缩通道数量。倒残差结构在1×1压缩卷积后使用线性操作替代激活函数,从而解决了使用倒置残差块之后再使用ReLU6 而失去低纬度信息的问题。当s=1 时,使用残差连接;当s=2 时,不使用残差连接。
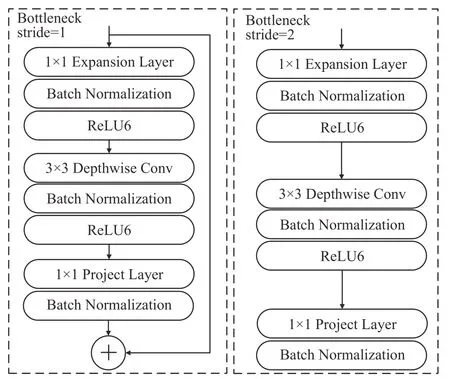
图2 MobileNet v2 bottleneck结构Fig.2 MobileNet v2 bottleneck structure
2.2 Transformer全局注意力机制
Transformer 是一种基于自注意力机制的深度学习模型,在自然语言处理(NLP)领域取得了显著的成果。Dosovitskiy等人[21]将Transformer引入到计算机视觉中,提出了Vision Transformer 算法,并在计算机视觉领域展现出了出色的性能。Transformer 编码器通过学习图像块之间的关系,生成全局的图像表示,从而有效地捕捉图像的全局上下文信息。Transformer编码器由L个标准的Transformer 模块组成,其中Transformer 由层归一化(LN)、多头自注意力模块(MSA)、多层感知机(MLP)和残差连接组成,F表示输入,计算过程如下:
在低照度条件下,可以通过周围的物体判断环境中可能存在的物体,Transformer的全局信息建模能力可以从图片的全局特征推断出环境中可能存在目标的位置,从而对其重点关注。然而Transformer 的计算量较大,因此本文对其输入输出进行了修改,结构如图3灰色区域所示,首先将输入F使用MaxPool 进行降采样,采样至原始尺寸的1/8,再使用Flatten和Transpose 得到输出F1,以降低Transformer的计算量,然后经过Transformer编码器的计算得到输出F2=TransformerEncoder(F1),经过Transpose、Reshape 和上采样操作后,将F2转化为与F相同尺寸的输出F̂,将F̂和原始输入F相加得到最终的输出Fout,公式如下所示:
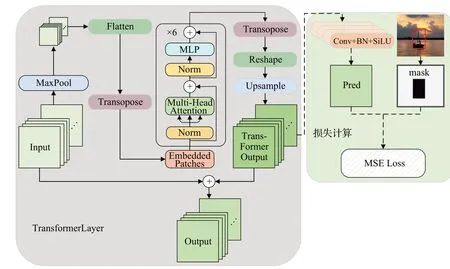
图3 TransformerLayer结构与训练流程Fig.3 TransformerLayer structure and training workflow
为了增加Transformer 的特征提取能力,本文提出来一种基于目标标记信息的监督学习的方法,如图3浅绿色区域内所示,首先基于目标标记信息获取mask 标签,目标范围区域内标记为1,其他位置标记为0,然后对F̂使用输入和输出通道一致的三个3×3卷积得到F3,再对F3使用3×3 卷积将其通道降至1 并使用Sigmoid激活函数得到输出F4,使用MSE 损失函数计算F4与mask之间的损失LossTF,具体公式如下:
2.3 DFFA动态特征融合注意力机制
低照度场景下物体由于模糊、遮挡等问题,容易被漏检,浅层的细节特征信息对于帮助模型粗略定位物体位置至关重要,有助于发现那些不易被检测到的目标。为此本文提出了一个动态融合浅层特征和深层特征的模块DFFA。
如图4 所示,首先对Neck 的第i个输入特征NIi(Neck Inputi) 和第i个输出特征NOi(Neck Outputi)使用Concat 和一个卷积获取可变形卷积的偏移量offset,然后将offset和NIi作为可变形卷积的输入得到,可变形卷积利用偏移量offset动态地将输入特征调整到与NOi对齐,然后将和NOi拼接后使用CBS(Conv+Batch Norm+SiLU)得到,对使用CBAM注意力机制得到最终的输出DOi(DFFA Outputi),公式如下所示:
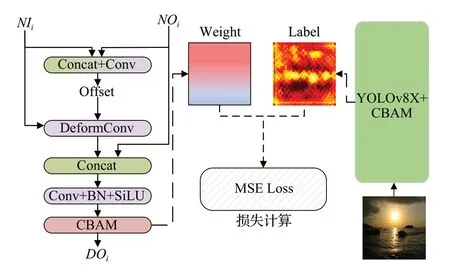
图4 DFFA结构与训练方法Fig.4 DFFA structure and training method
为了增加DFFA对浅层特征的信息提取能力,本文使用YOLOv8X,并对YOLOv8X 中NOi使用CBAM注意力机制,将其权重矩阵Label1、Label2、Label3输出作为DFFA 中CBAM 空间注意力权重wi的标签,对DarkYOLOv8的DFFA模块参数进行监督训练,MSE损失函数作为损失函数,公式如式(14)所示:
2.4 DarkYOLOv8整体结构
DarkYOLOv8整体结构如图5所示,使用MobileNet v2主干网络替换YOLOv8主干网络,在MobileNet v2的第二个Bottleneck层后加入TransformerLayer,对颈部网络的每一层的输入和输出均使用DFFA模块。
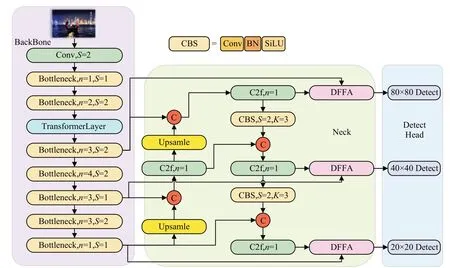
图5 DarkYOLOv8整体结构Fig.5 Overall architecture of DarkYOLOv8
原始YOLOv8损失函数由三部分组成,分别是分类损失Losscls、DFL 损失LossDFL以及边界框回归损失Lossbbox,与YOLOv8不同的是,本文额外添加了Transformer的监督学习损失LossTF和CBAM监督学习损失Losscbam,本文损失函数如式(15)所示:
3 实验与分析
3.1 实验数据集
ExDark 数据集由Loh 等人[22]于2019 年提出,旨在为低光照条件下目标检测算法的评估和比较提供一个具有挑战性的基准,其检测类别分别为自行车、船、瓶子、公共汽车、轿车、猫、椅子、杯子、狗、摩托车、人、桌子。ExDark 数据集共有7 363 张图片,按照8∶1∶1 的比例划分训练集、验证集和测试集,训练集、验证集和测试集分别有5 890、736和737张图片。
3.2 实验环境与评价指标
实验在Ubuntu22.04 LST操作系统下,搭配NVIDIA RTX3090显卡,Pytorch1.13深度学习框架以及Python3.8编程语言进行,未使用预训练权重。超参数设置如表2所示。

表2 实验参数Table 2 Experimental parameters
本文采用mAP评价指标、GFLOPs和FPS来衡量模型效果。
平均精度(mean average precision,mAP)是一种常用于评价目标检测算法性能的指标,检测算法计算在不同类别目标上指定IoU的准确性和召回率,计算不同类别的AP值,并计算各个类别AP的平均值则得到在指定IoU 下的mAPIoU。本文使用mAP0.5:0.95 和mAP50两种评价指标,mAP50表示IoU阈值为50%时的mAP;mAP0.5:0.95表示在不同的IoU阈值(从0.5到0.95,步长0.05)下的平均mAP。
FLOPs(floating point operations)是一种衡量深度学习模型计算复杂度的指标。它表示在模型推理过程中进行的浮点运算的总数量,包括加法、乘法和其他浮点操作。
FPS(frames per second)表示目标检测模型在一秒钟的时间内能检测图片的数量,高FPS对实时目标检测系统至关重要。
3.3 对比实验
为验证本文所提算法在低照度场景下检测性能的优越性,在ExDark数据集下,将DarkYOLOv8与目前主流的目标检测算法、针对低照度场景下的目标检测算法IA-YOLO、ZeroDCE+YOLOv5_DC、FISNet 以及低光照增强算法+YOLOv8n 进行对比,结果如表3 所示,其中mAP表示mAP0.5:0.95。

表3 对比实验Table 3 Comparative experiments
可以看出,DarkYOLOv8在低照度条件下表现出明显的优势,它在计算量保持较低水平的同时,在mAP和mAP50指标上均领先。与专门设计用于低照度条件的目标检测算法ZeroDCE+YOLOv5_DC、IA-YOLO 以及FISNet 和相比,DarkYOLOv8 的mAP 分别领先了2.4、3.6 和3.3 个百分点。这些结果表明DarkYOLOv8 在低照度条件下具有出色的性能。
3.4 消融实验
为了验证不同的改进方法对模型的影响,本次研究采用了逐步添加改进方法的消融实验,并在ExDark 测试集上进行了性能比较,其中BASE 表示YOLOv8n 算法,M1表示使用MobileNet v2作为主干网络,M2表示使用Transformer 注意力机制,M3表示使用DFFA 模块,实验结果如表4 所示。结果表明,YOLOv8n 算法mAP50为66.2%,GFLOPs 为8.2。将MobileNet v2 替换原始YOLOv8 的主干网络后,增加了提取图片特征的能力,mAP50提高了1.6 个百分点,GFLOPs 仅增加了0.19。使用Transformer 全局注意力后,模型能够在浅层获取图片的全局特征信息,mAP50增加了0.6 个百分点,由于使用了下采样操作,因此计算量仅增加了0.01。引入DFFA模块后,模型通过利用浅层特征细节信息获取更加细腻的特征信息,mAP50增加了1.1个百分点。对Transformer和DFFA 模块使用监督学习后mAP50增加了0.6 个百分点,由于损失计算仅在训练过程中进行,因此没引入推理时的计算量。相对于YOLOv8n 算法,DarkYOLOv8算法在增加了仅0.33GFLOPs 的情况下,mAP50指标提高了3.9个百分点,同时推理时间仅略微增加,表明其适用于实时场景。

表4 消融实验Table 4 Ablation experiments 单位:%
3.5 可视化分析
为了展示Transformer 的全局建模能力,本文将主干网络输出的特征图使用热力图可视化技术进行可视化展示,以便于观察模型关注的区域,结果如图6所示,图6(a)是原始图片,图6(b)显示采用YOLOv8n进行可视化处理的结果,图6(c)展示了使用DarkYOLOv8进行可视化处理的效果。图中颜色越红的区域表示对检测结果的贡献越大。YOLOv8n更加注重目标位置的特征信息,而DarkYOLOv8会同时利用环境特征和目标所在位置的特征捕捉目标的信息。这表明Transformer能够更充分地利用图片中的上下文信息,从而提升对物体的检测和理解能力。
为了直观呈现改进后算法的检测效果,本研究针对测试集中的检测难度较大情景进行了检测结果可视化分析。如图7所示,分别给出了YOLOv8和DarkYOLOv8的检测结果,在目标与环境界限不清晰、模糊和明暗差异较大等挑战性场景YOLOv8n均表现出较差的检测效果,每张图均存在漏检情况,在明暗差异较大的场景下无法检测出图中的两只黑猫,而DarkYOLOv8在目标与环境界限不清晰和明暗差异较大的场景中均能正确地检测出所有目标。在模糊场景中,DarkYOLOv8也展现出更优异的检测效果,减少了漏检情况。由此可以得出结论,DarkYOLOv8 具有更加优异的检测效果,即使是面对极端场景也具备优异的检测效果。

图7 YOLOv8n与DarkYOLOv8在低照度情况下目标检测效果Fig.7 YOLOv8n and DarkYOLOv8 target detection effect under low illumination
4 结束语
本文提出一种基于YOLOv8的轻量化的DarkYOLOv8低照度目标检测算法,针对低光条件下目标容易被漏检且目前主流低照度目标检测算法计算量较大的情况,首先引入MobileNet v2主干网络,替换原始YOLOv8主干网络,MobileNet v2能够获取到低照度环境下的目标的更多的特征信息,提升检测准确率,然后将Transformer-Layer 放置在主干网络的第二个和第三个Bottleneck 层之间,使模型在早期就能获取到图片的全局特征信息,同时使用监督学习更加准确地增强目标范围内特征的权重,进一步提升了检测性能,提高低照度下目标与环境间的区分度,最后使用DFFA模块融合颈部网络浅层特征和深层特征,使用特征细节信息增加低照度场景下目标检测准确率。实验结果表明,在FPS为153仍能应用于实时场景的情况下,本文所提出的DarkYOLOv8算法在ExDark数据集上mAP50达到了70.1%,与YOLOv8n以及其他低照度场景下的算法相比,DarkYOLOv8算法在满足实时应用场景的同时有效改善了目标检测精度。
猜你喜欢
军事文摘(2024年2期)2024-01-10
广东教育·高中(2022年1期)2022-03-16
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
光源与照明(2019年4期)2019-05-20
电子测试(2018年9期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
新课程研究(2016年21期)2016-02-28
中国交通信息化(2015年2期)2015-06-05
电视技术(2014年19期)2014-03-11
