
面向人眼宽视场视觉成像质量的评价方法
2024-04-23 04:35隆海燕贾曦然
计算机工程与设计 2024年4期
王 杨,隆海燕,贾曦然
(1.河北工业大学 电子信息工程学院,天津 300401;2.河北工业大学 天津市电子材料与器件重点实验室,天津 300401)
0 引 言
人眼系统通过中心视觉和边缘视觉获得视觉信息。中心视觉是指视网膜中心1-2度的双侧范围,其它范围则为边缘视觉,两者形成一个宽视场,在视觉信息处理时协同合作以充分发挥人眼视觉能力。例如,在视觉检索中用于捕捉感兴趣区域和探索场景;在篮球防守中用于判断对手球员位置并准确标记[1];在道路行驶中用于获取更高的驾驶安全性。评估不同视场下的成像质量有助于探究人眼的视觉感知,同时在物体识别和安全驾驶等领域具有广泛的应用场景和研究价值。
眼模型一直是研究人眼视觉感知的重要手段。在Gullstrand经典眼模型的基础上,王杨[2]和张伊等[3]构建了个性化人眼光学系统,分别研究宽视场下波前像差的特征以及入射和出射波前像差的统计学差异性。徐欢欢等[4]分析波前像差对调制传递函数(MTF)曲线的影响来评估视觉质量。以上研究均通过分析波前像差来评估成像质量,但未获得人眼在多视场处的视觉成像图,故在探究人眼宽视场的成像质量方面有一定的局限性。
学者们将客观图像质量评价方法应用于图像视觉质量的度量中。由于人类视觉系统对图像的颜色结构敏感并具有感知阈值,闻武等[5]从灰度和色度出发挖掘图像的相关统计特征并建立图像色彩特征与质量的映射关系。曹欣等[6]则在此基础上关注图像的颜色相似性和边缘特性。王晨等[7]通过偏度特征区分图像空洞失真和拉伸失真以模拟人眼视觉系统的机理。卢鹏等[8]则以图像的信息熵和纹理特征表示图像的细节信息,将其融合后进行图像质量评价。杨光义等[9]将孪生神经网络迁移至图像质量评价领域。现有对中心视觉和边缘视觉的研究大多从其功能出发,分析二者在视觉信息获取时所发挥的作用,但获取人眼多视场成像图,并利用卷积神经网络对视觉成像质量进行量化分析,目前尚未见报道。
为准确分析人眼在多视场处的视觉成像质量,受上述人眼对色彩差异化感知和视觉成像特性的启发,提出一种基于个性化眼模型和孪生神经网络的宽视场成像质量评价方法。构建专注于双目重合视野的个性化眼模型以获取视觉成像;通过捕获成像图中的不同色彩区域以模拟人眼的视觉感知;利用孪生神经网络获取图像的多维信息以实现对成像图质量的量化。
1 宽视场视觉成像质量评价算法
本文所提出的宽视场视觉成像质量评价算法主要分为3步:①构建个性化眼部模型得到波前像差的统计学差异以获得不同视场下的成像图;②提取成像图的差异化色彩区域;③利用孪生神经网络进行特征提取,实现对视觉成像优劣的量化。具体流程如图1所示:首先输入各视场的波前像差值以得到差异化视场成像图,然后将完成色彩区域提取的子图像输入孪生神经网络中,最后根据孪生子网络输出值的欧式距离进行度量学习。其中,W为两个子网络中共享的权值向量。
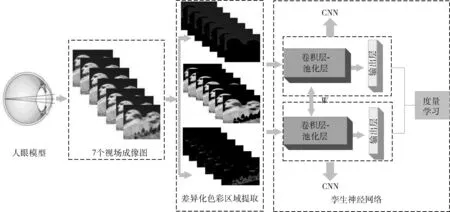
图1 宽视场视觉成像质量评价算法框架
1.1 个性化眼模型的构建
参考文献[2]中的模型构建方法,以Gullstrand-Le Grand眼模型为基础,在ZEMAX环境下完成个性化人眼模型的建立。Gullstrand-Le Grand眼模型的结构参数见表1。
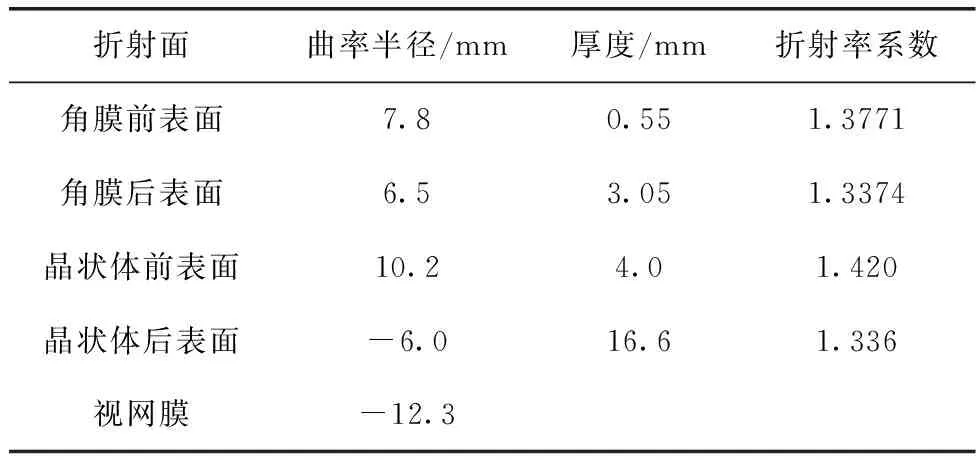
表1 Gullstrand-Le Grand眼模型的结构参数
Gullstrand-Le Grand眼模型的折射面均为球面。个性化眼模型中,引入贴合人眼特征的泽尼克矢高面作为角膜和晶状体的前后表面,迭代优化其曲率半径和非球面系数。个性化眼模型参数见表2。
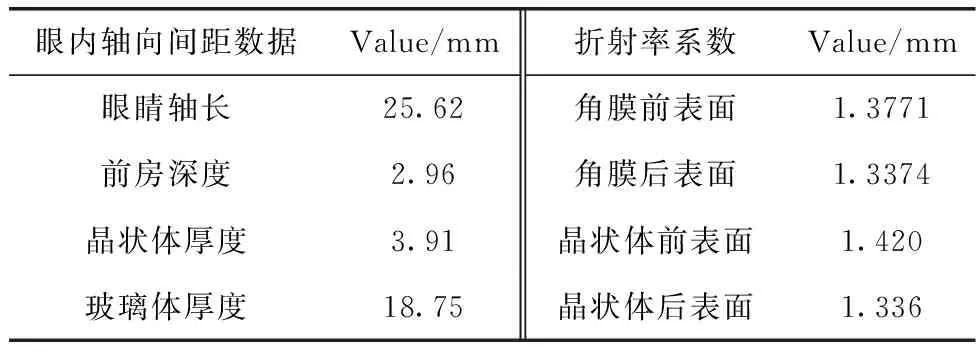
表2 个性化眼模型所用参数
1.2 多视场的选取及成像
双目水平视角的极限值为188°,单目水平视角可达156°。双目重合视域为124°,该视域内视觉感知敏感并具有观测立体感,本文重点关注该范围内视觉成像的优劣。
1.2.1 多视场的选取
为度量双目重合视域的多视场成像质量,本文参考二维物体表面离散点的采样对视场角进行选择。除轴上视场和最大视场外,还需考虑中间视场点的成像优劣。故采用旋转对称法取样,如式(1)所示
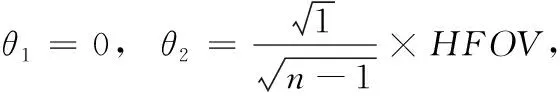
(1)
其中,n表示视场点的数量,θn表示第n个视场,HFOV指最大的半视场。双目重合视野为124°,故取值为62°。根据公式,定义双目中心为0°,视场1至视场7视角的选取依次为62°、50.62°、35.79°、0°、-35.79°、-50.62°和-62°。设置多视场下的个性化眼模型结构如图2所示。
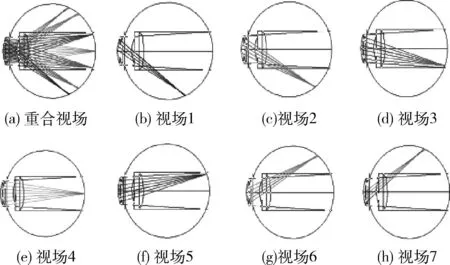
图2 多视场下的个性化眼模型结构
1.2.2 多视场视觉成像
本文通过构建人眼光学系统分析视场下的波前像差以获得差异化成像图。在视光学领域,重建波前像差通常由Zernike多项式描述,如式(2)所示
(2)
其中,Zk(x,y) 是Zernike 多项式的第k个模,Ck是多项式系数,kmax是最大的截断项。点扩散函数(point spread function,PSF)是脉冲函数模的平方,如式(3)所示
PSF=|h(xi,yi)|
(3)
其中,(xi,yi) 是光斑的质心坐标,h(xi,yi) 为脉冲响应函数。PSF可根据Zernike多项式获得点光源在视场1至视场7的成像图,如图3所示。

图3 点光源在7个视场下的成像
1.3 图像预处理
提取图像的色彩区域以模拟人眼对色彩的差异化感知。Lab颜色空间将图像的亮度信息和色度信息分离,基本消除各颜色分量之间的强相关性[10],在彩色图像分割时可保留原图像的自然效果。Lab颜色空间中的L分量用于表示像素的亮度,取值范围是[0,100],表示从纯黑到纯白;a表示从红色到绿色的范围,取值范围是[127,-128];b表示从黄色到蓝色的范围,取值范围是[127,-128][11]。Lab颜色空间的色域宽阔,可密切匹配人眼色彩感知。根据图像色彩的差异提取区域图像的结果如图4所示。
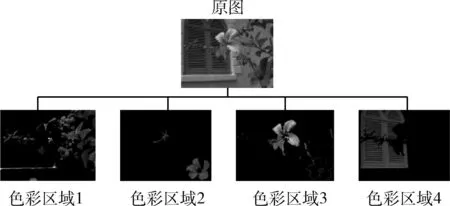
图4 图像差异化区域提取结果
由图4可知,在Lab颜色空间中进行彩色图像预处理时,区域边界细节较清晰,可实现差异化色彩区域的精准分离。
1.4 孪生神经网络
本文所用孪生神经网络模型如图5所示。
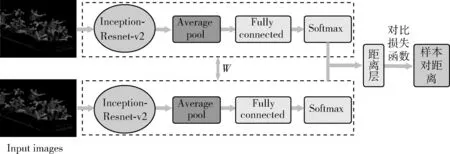
图5 孪生神经网络模型
如图5所示,模型的双分支共享权值W,并具有相同的网络结构和参数。图像以样本对的形式输入,并将其特征映射至指定维度的特征向量空间中,最后以特征向量的欧氏距离判定样本对的相似程度。将Inception-Resnet-V2作为双分支的主干网络,其中Resnet采用残差网络的思想,可加速训练并防止梯度弥散;Inception模块允许卷积池化操作并行以增加网络稀疏性,并利用多尺度卷积核扩大感受野。
Inception-Resnet-V2整体结构由Stem网络、5 组Inception-Resnet-A网络、Reduction-A降维层、10组Inception-Resnet-B网络、Reduction-B降维层、5组Inception-Resnet-C网络、平均池化层、Dropout层、Softmax函数组成,如图6所示。

图6 Inception-Resnet-V2整体结构
其中,3种Inception-Resnet网络的区别在于卷积核的数量、尺寸和卷积通道数不同:Inception-Resnet-A、Inception-Resnet-B和Inception-Resnet-C的结构分别如图7(a)、图7(b)和图7(c)所示。
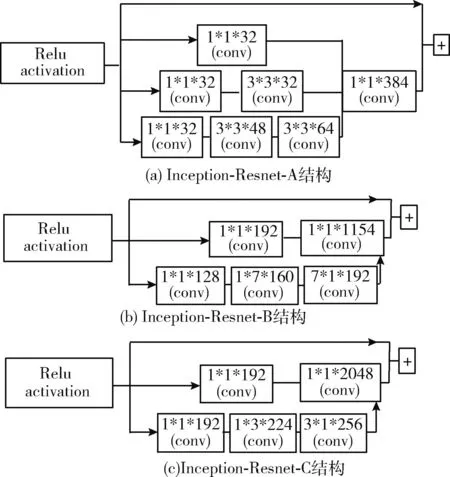
图7 Inception-Resnet-A、Inception-Resnet-B和Inception-Resnet-C结构
Inception-Resnet-A的三路卷积通道由激活函数层先经过1×1×32的卷积层后,二通道和三通道分别进行3×3×32和3×3×48、3×3×64的卷积操作,最后三路通道经384次1×1的卷积运算后和未卷积分支残差连接。
Inception-Resnet-B和Inception-Resnet-C均经过激活函数层后进入卷积通道。一通道均经过1×1×192的卷积层;Inception-Resnet-B二通道为非对称分支经过1×1×128、1×7×160和7×1×192的卷积层;Inception-Resnet-C二通道经过1×1×192、1×3×224和3×1×256的卷积层;最后两模块的卷积通道分别经1154次和2048次1×1的卷积运算与未卷积分支残差连接至激活函数层。
Stem部分网络结构的卷积核拆分用于提取图像浅层特征;Reduction-A和Reduction-B通过卷积和池化操作降低输出特征图尺寸实现降维,将上层结构块的尺寸分别由35×35降为17×17及由17×17降为8×8。
为描述成对样本的匹配程度,本文引入对比损失函数作为模型的优化函数。其数学表达式如式(4)所示
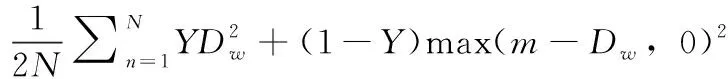
(4)
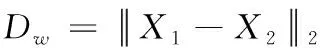
2 结果分析
算法在64位Windows10操作系统下,利用Python3.7平台使用Keras深度学习框架进行实验,所有实验结果及部分对比实验的运行环境均为16 GB RAM内存的Intel(R) Core(TM) i7-10750H CPU处理器、NVIDIA GTX 1060 6 GB。
2.1 数据集与评价指标
LIVE数据集、TID2013数据集和CSIQ数据集应用广泛、图像场景多样,失真类型丰富,有利于评估图像质量评价算法的优劣,故选取作为实验数据集进行性能评估。3个实验数据集的详细信息见表3。
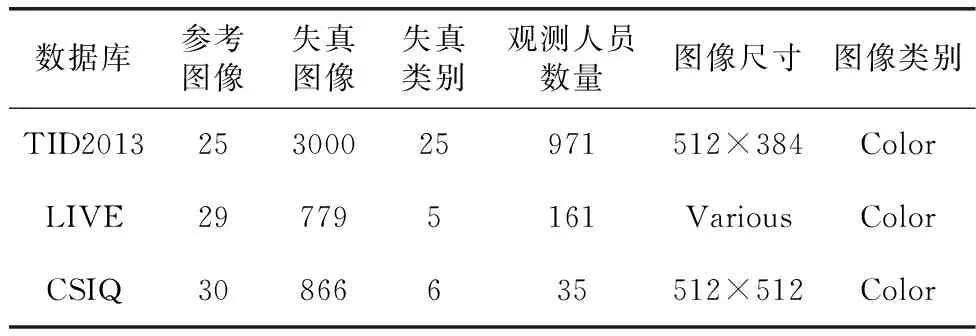
表3 3个基准测试数据库信息
为客观验证所提算法的性能,选择通用性能指标皮尔森线性相关系数(Pearson linear correlation coefficient,PLCC)和斯皮尔曼秩相关系数(Spearman rank order correlation coefficient,SROCC)对所提算法进行评估。PLCC和SROCC分别反映客观质量评价值与主观评价之间的线性相关度和单调性。SROCC/PLCC值越大,代表算法性能越好:反之,则较差。
PLCC的数学表达式如式(5)所示
(5)
SROCC的数学表达式如式(6)所示
(6)
其中,N代表了数据库的失真图像总数目,xj、yj代表了按照一定的顺序作排列后(递增或递减顺序)的主客观序列中的第j个图像的主客观评价值。
2.2 波前像差的描述
利用Zernike多项式对不同视场下的波前像差进行重建。构建个性化人眼光学系统,设置视场角度,视场1至视场7的眼模型如图8所示。
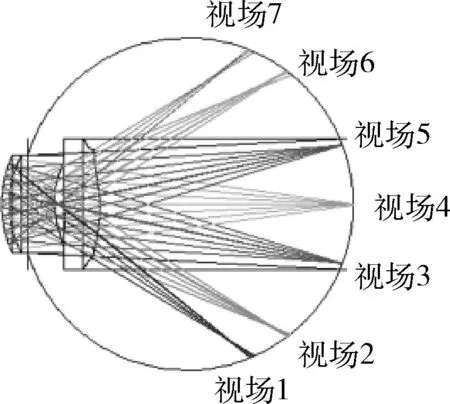
图8 眼模型视场1至视场7
不断优化眼模型的相关结构参数,得到视场1至视场7所对应的Zernike多项式的35项系数。前7阶(35项)Zernike系数见表4,因篇幅有限,这里只列出其中6项,其中Zernike系数的顺序与ZEMAX中一致。
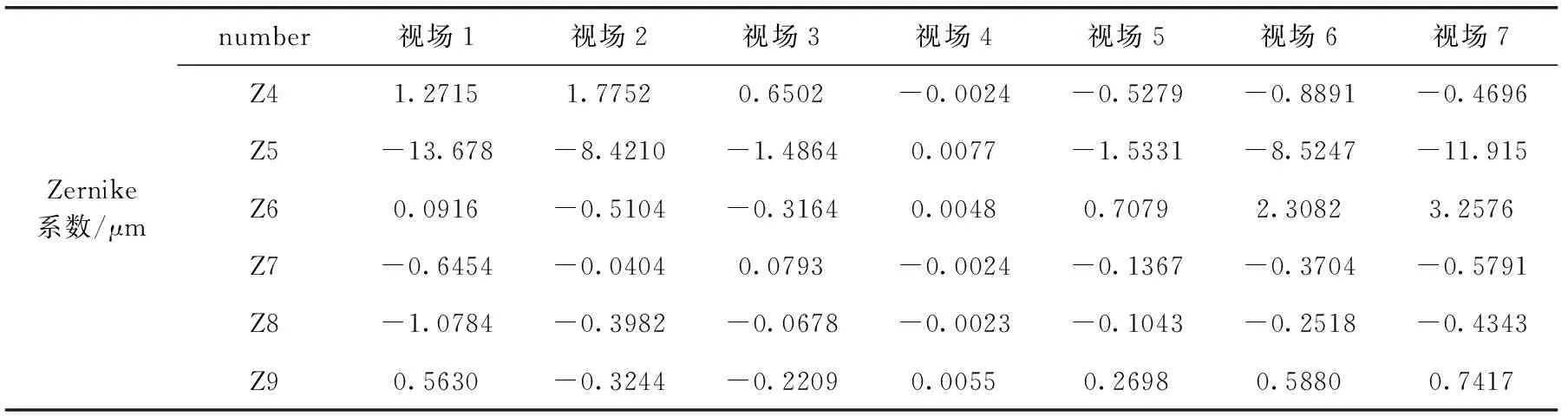
表4 Zernike多项式的部分系数值
2.3 成像图的获取与分割
根据波前像差值对数据集中的图像进行预处理以得到不同视场下的成像图,如图9所示。

图9 7个视场处的成像
以孪生子网络输出的欧式距离差作为对多视场成像图进行质量评价的指标,即客观评价值。视场4成像图的客观评价值为0.8002,其客观质量评价最优;视场1和视场7成像图的客观评价值较低,分别为0.5858和0.5844,其客观质量评价较差。
模拟人眼对色彩的差异化感知,得到7个视场下视觉成像的多个色彩区域。成像图的色彩区域提取结果如图10所示。

图10 成像图的色彩区域提取结果
色彩区域图像以样本对的形式输入到孪生神经网络中,对子图像的评价值加权以获得整幅图像的质量分值。加权公式如式(7)所示
(7)
2.4 模型训练
2.5 性能分析
对LIVE数据集、TID2013数据集和CSIQ数据集中的图像进行多视场成像处理,以孪生子网络输出值的欧式距离表示在视场1至视场7处的客观质量评价值,如图11所示。
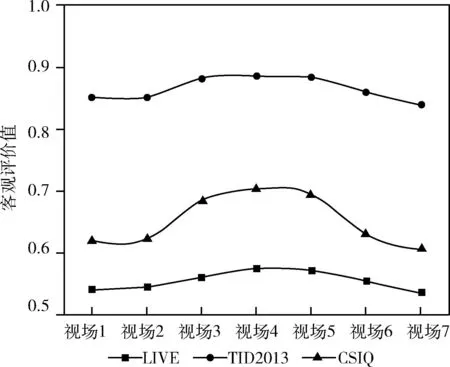
图11 3个数据集的客观质量评价值
其中,3个数据集在多视场处的客观评价值取该数据集中图像的平均值得到。由于TID2013数据集中训练集图像较CSIQ和LIVE数据集大,使得其训练网络泛化能力较优,故所提算法在TID2013数据集的客观图像质量评价值整体显著高于LIVE数据集和CSIQ数据集。从3条曲线的整体趋势来看:视场4的成像评价值最高,视场1和视场7最低。这一趋势表明,由于人眼的波前像差值随着视场角度的扩大而增加,故视觉成像质量逐渐下降。

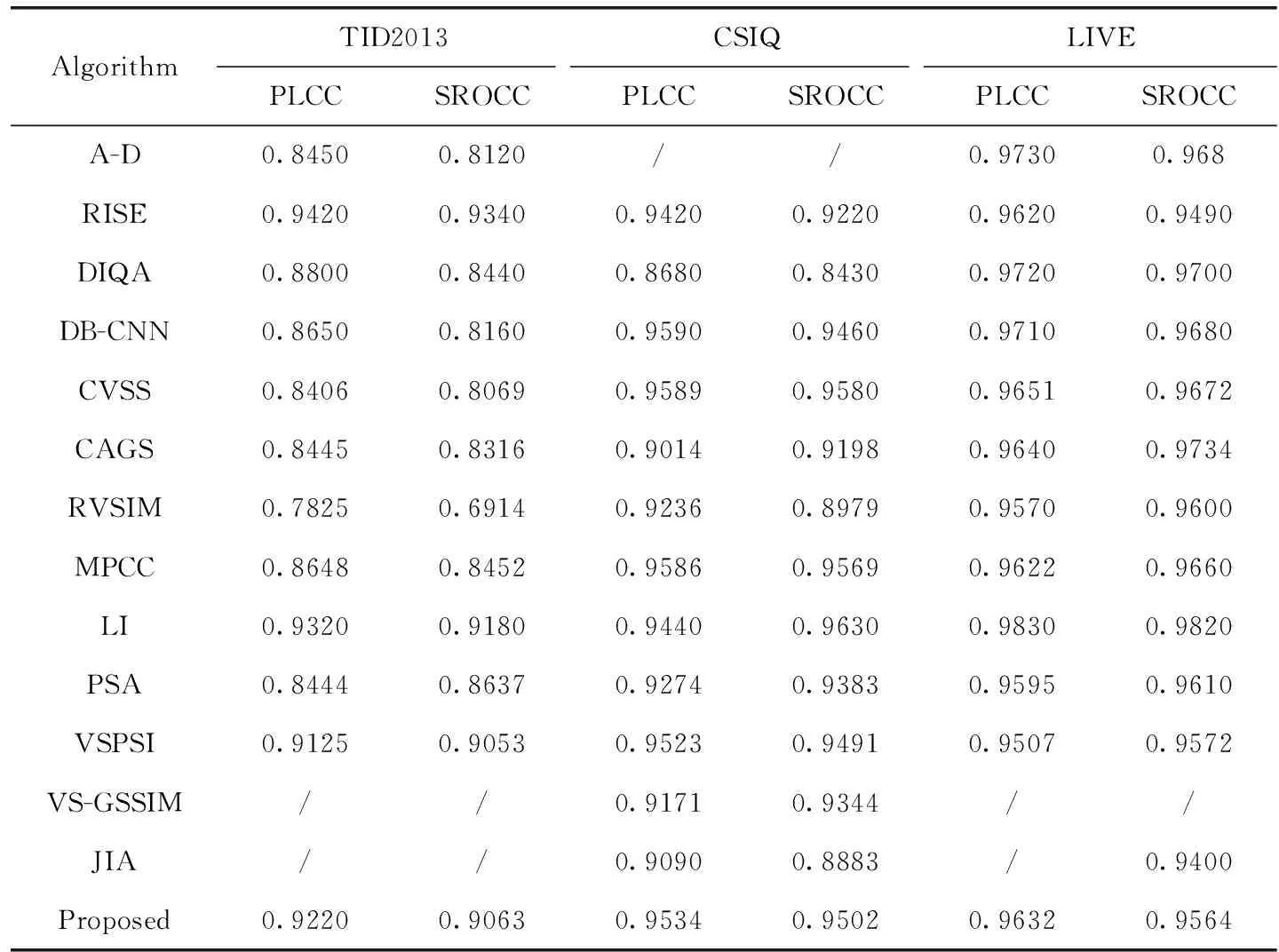
表5 不同评估算法的性能对比
由表5可知,在TID2013数据集上,所提算法的PLCC和SROCC值分别比LI低0.0100和0.0117,比RISE低0.0200和0.0280,但较其它算法有显著提高;在CSIQ数据集上,所提算法的SROCC和PLCC虽低于CVSS、MPCC算法,但均高于RISE、DIQA、CAGS、RVSIM、PSA、SPSIM、VS-GSSIM、JIA算法;所提算法的SROCC低于LI和DB-CNN,但PLCC比二者分别高0.0094和0.0042;在LIVE数据集上,所提算法也显示出较好的一致性。综合评价表明,所提算法模拟人眼视觉感知,利用不同深度的特征图表示其不同维度的特征,充分表达图像由底层到高层的有效信息,在与主观感知相关性方面更具优势。分析原因可能为,所提算法构建IQA模型时重点考虑图像的色度特征并对图像进行局部分块,较好表征了图像;共享权值的孪生神经网络整体参量数减少,可降低过拟合对图像评价的影响;宽视场成像质量的评价值由多视场成像质量加权得到,权重分配顾及了边缘视场,并侧重于中心视场成像,故所提算法性能较优。
所提算法引入边缘视觉成像,同时在Inception模块中增加BN层,利用孪生网络求取局部质量值再加权,在算法上增加了一定的复杂度。对算法的平均运行时间进行记录,并将其与其它算法作了对比。采用柱状图直观表示3个数据集中不同失真类型的平均运行时间。TID2013数据集、LIVE 数据集和CSIQ数据集中单个失真类型的每10幅图像平均运行时间如图12所示。

图12 3个数据集中单个失真类型的每10幅图像平均运行时间
取3个数据集运行时间的平均值与其它算法进行对比,结果见表6。

表6 每幅图像的平均运行时间
由表6可知,虽然其平均运行时间高于CVSS、VSPSI、VS-GSSIM算法,但分别比CAGS、MPCC和JIA算法的运行时间降低了0.2698 s、0.0201 s和0.0349 s;同时由表5可知,模型精度相较于部分算法在3个实验数据集上均有提高。综合成像质量评估准确度和算法效率两方面得出,本文算法可实现对中心视觉和边缘视觉成像质量的量化,同时可尝试应用于自然图像场景的大范围感知中。
3 结束语
本文算法利用个性化眼模型获得中心视觉和边缘视觉的成像图,将颜色作为视觉线索获取成像图的差异化色彩区域,利用孪生神经网络实现对不同视场处成像图的量化,其评价值与主观感知表现出良好的一致性,可用作彩色图像质量评价的新思路。目前所提算法对于色彩复杂的图像区域提取有一定的局限性,后续将继续改进模拟人眼色彩感知的相关算法,同时尝试引入自注意力机制进一步提升算法性能,并将探究边缘视觉在图像检索和场域感知等领域中的应用作为未来研究的新方向。
猜你喜欢
中国光学(2021年6期)2021-11-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
快乐语文(2019年9期)2019-06-22
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
中国医疗设备(2019年1期)2019-01-15
北京航空航天大学学报(2018年1期)2018-04-20
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
激光与红外(2015年10期)2015-03-23
