
基于API序列和预训练模型的恶意软件检测
2024-04-23 04:34窦建民师智斌于孟洋张舒娟
计算机工程与设计 2024年4期
窦建民,师智斌,于孟洋,霍 帅,张舒娟
(中北大学 计算机科学与技术学院,山西 太原 030051)
0 引 言
随着恶意软件的急剧增加,自动化检测成为主流方法。静态分析方法易受代码混淆、加壳等影响[1]。而动态分析通过软件的实际运行状态来提取其行为特征实现检测,如API(application program interface)函数调用等行为[2],特别是敏感API调用直接反映了软件的良性或不良意图[3],能有效解决代码混淆等技术的影响。
目前在软件行为特征的提取方法中,机器学习依赖人工提取特征且需要有完备的先验知识[4]。而深度学习方法能实现特征的自动提取,但不能捕获API序列全局语义信息,特别是API函数在不同序列的多种语义问题[5,6],同时深度学习方法依赖大量有标注数据,而恶意软件数据集通常包含大量无标注数据,无法直接进行有监督学习。
本文基于BERT模型,在大量无标注API序列上利用无监督学习构建动态掩码序列模型,使模型会考虑API序列的上下文和语义关系,获得API序列的全局编码表示,从而有效解决无法捕获API序列全局语义信息和和处理API函数在不同序列的多种语义问题以及带标注数据不足的问题。主要工作如下:①为避免其它领域不相关的分词干扰,重新定义词级编码器和规范器等组件构建分词器,将API序列解析为模型可识别的数值表示;②基于BERT模型,使用无监督学习在大量无标注API序列数据上利用动态掩码机制构建恶意软件动态掩码序列模型(malware dynamic mask sequence model,MDMSM),从零训练模型学习API序列的语义关系,获取API序列的全局动态编码表示,实现动态挖掘API序列的语义特征;③将该编码作为检测模型的词嵌入,在少量有标注的API序列数据上微调模型完成检测。
1 相关工作
机器学习方法通过人工特征工程提取静态和动态特征后训练模型实现检测[7,8]。PektaA等[9]通过n-gram算法树提取恶意软件常见API子序列用于检测,也验证了动态分析能更有效地获取软件的行为特征。Han H等[10]基于Android程序运行时的API调用序列,使用支持SVM来进行恶意软件检测。田东海等[11]使用n-gram算法优化恶意代码中的操作码特征,然后使用词袋模型和TF-IDF算法优化API调用序列特征,最后使用决策树进行分类。虽然机器学习方法通过学习浅层样本特征能实现对恶意软件进行自动化检测,但该方法会依赖人工提取特征,存在特征表达受限等因素影响。
深度学习在模型构建和特征提取方面效果更好,深层神经网络具有自动学习样本特征的能力,有较高的准确率[12,13]。Li C等[14]提取软件API调用序列,利用词嵌入获得序列的向量表示并将其输入LSTM进行软件分类。唐永旺等[15]使用Bi-LSTM学习样本字节流序列并利用注意力机制获取序列的深层特征完成分类任务。Cui Z等[16]将恶意软件的特征用灰度图像表示,然后利用卷积神经网络提取恶意软件的图像特征进行分类。深度学习方法在一定程度上能提高任务性能,但该方法需要大量有标注数据,在小数据集上模型不易收敛且捕获API序列的特征不全面。
对API函数进行语义特征提取及编码表示,即词嵌入方法,也是目前研究热点,其特征表示和编码方式将直接影响恶意软件的检测效果。Cakir B等[17]基于操作码序列使用Word2vec作为特征提取方法表示软件样本,然后使用梯度提升机搜索算法实现分类任务。Zhang J等[18]利用Glove表征从程序中提取信息,然后使用CNN分析词嵌入表示的特征图进行分类。Feng L等[19]使用FastText作为序列表示方法,提取API序列特征实现软件的分类任务。但传统词嵌入方法提取的词向量不能根据上下文的不同而发生变化,无法解决API函数在不同调用序列中的多种语义问题。
以上方法虽然在一定程度上能提高任务效率,但都无法解决API函数的全局语义信息和处理API函数在不同序列的多种语义问题以及有标注数据集不足的问题。BERT是NLP任务中较最先进的语言模型[20],通过预训练机制对大量无标注数据利用无监督学习获得通用编码表示,因为文本序列自身的顺序性就是一种天然的标注,目前该方法也被应用到软件检测中。Oak R等[21]利用BERT模型在安卓软件数据集上进行软件分类任务。Alvares J等[22]通过BERT模型生成API序列的词向量进行分类。由于现有方法都直接使用NLP领域的BERT模型[23],而API序列包含的是与系统调用相关的词汇和标识符,与NLP领域文本序列的分词规则有所差异,在软件分类的应用中效果不佳,无法高效完成检测任务。
2 恶意软件动态掩码模型结构
本文基于BERT模型架构,在大量无标注API序列上使用动态掩码序列机制,构建恶意软件动态掩码序列模型MDMSM,重新构造预训练任务,实现对API序列的全局动态编码表示,可有效解决动态编码和带标注数据不足的问题。模型结构如图1所示,该模型由多种词编码组合的输入和12个编码层叠加的编码器所组成。
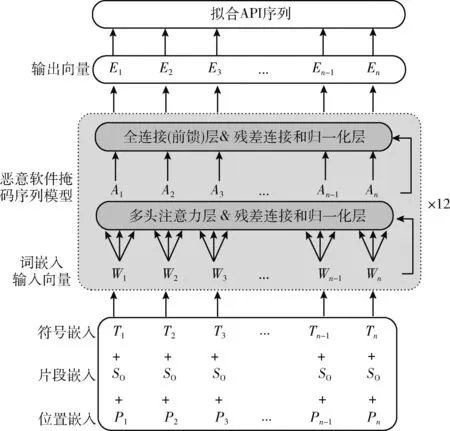
图1 恶意软件动态掩码序列模型结构
MDMSM的输入是由符号嵌入、片段嵌入和位置嵌入3个不同层级词向量组成。符号嵌入是用分词器对API序列分词后的结果,而片段嵌入和位置嵌入由模型随机初始化。
采用Word2vec、Glove、FastText等传统模型获取的编码表示通常忽略了API上下文关系,而同一个API函数在不同序列中往往会表征出不同的语义信息。MDMSM结构是由12个编码层串联叠加组成的编码器,其中每个编码层是由多头注意力层、残差连接、层归一化、前馈层组成,前馈层的激活函数和自注意力的计算提供整个网络模型的非线性变换。
MDMSM的核心是多头注意力机制,它类似CNN中多个卷积核的概念,通过多个不同的Head分别进行注意力计算,从不同角度抽取API序列的特征使得信息表征更丰富,实现全局信息的采集。设头数为i, 分头后输入矩阵为Ii, 3个中间变量矩阵为Qi、Ki、Vi, 其第2个维度分别为dq、dk、dv。 注意力机制公式为
(1)
3个中间变量矩阵公式为
(2)
(3)
(4)
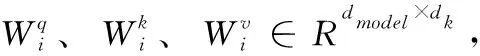
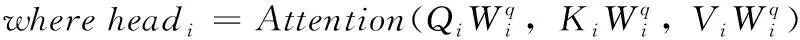
(5)
其中,WO∈Rhdv×dmodel, 在模型中用h=8构建多头自注意力模块且限定dk=dv=dmodel/h, 使用多头注意力的好处是相较原来dmodel的高维空间,每个Head都经过降维,可以利用矩阵并行化处理使得计算效率更高。
对于一条API序列,每经过一层多头注意力,每个API的词向量都是该序列中所有API函数词向量的加权平均,即融合该序列所有的关键信息。因此,对于同一个API函数,不同上下文会让该API融合不同的语义信息,从而更好地捕获序列的上下文语义关系,使得该API在不同的上下文中有着不同的词向量去表征不同的语义,从而解决API函数在不同序列的多种语义问题。采用以上机制,MDMSM模型可获得API序列全局语义的编码表示,能够弥补传统模型的不足。
3 基于预训练模型的恶意软件检测方法
本文基于API序列,利用预训练的MDMSM进行恶意软件检测。该方法分以下4个步骤实现:首先进行数据预处理工作,将API序列进行数据清洗和剪枝;其次为了将数据解析为模型可识别的数值表示,需要重新定义字符编码器和规范器等组件,构建分词器MalTokenizer(malware tokenizer);然后基于BERT模型,利用动态掩码机制在大量无标注API序列上构建恶意软件动态掩码序列模型进行无监督学习的预训练,同时获取API序列的全局动态编码表示;最后将该编码作为检测模型的词嵌入,通过微调技术完成检测任务。虽然预训练的计算成本比较昂贵,但预训练后的模型可以用在各种基于API序列的计算成本低的下游任务。整体设计流程如图2所示。
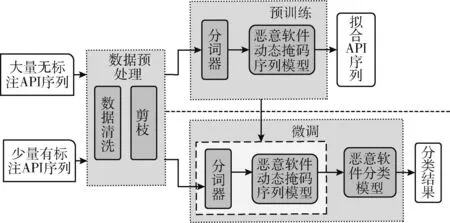
图2 恶意软件检测模型流程
3.1 数据预处理
软件行为分析报告中的API调用序列字段中包含很多无关的噪音信息和冗余数据,如图3所示给出一份从分析报告中提取的原始API调用序列信息。

图3 原始API调用序列
为了使API序列可直接用于模型的训练,减少无关字段和噪音数据对模型效果的影响,需要对其进行数据清洗和剪枝。首先将加载的原始API序列数据使用data_clea-ning()函数按照指定的过滤规则从API序列中去除各种无关噪音并使用空格符号作为每个API之间的分割标识;然后使用deduplication()函数对过滤后的序列数据进行剪枝处理并将较短的序列固定为指定长度length。其中剪枝是指从某条API序列中去除位置相邻且相同的冗余API函数,只保留最后一个。算法1为数据预处理的伪代码。
算法1:数据预处理
输入:原始API序列S
输出:预处理后的API序列
(1)files=open(S)
(2)api_filter={‘#’,‘-’,…}
(3)length=fixed_length
(4)last_api=‘’
(5)forlineinfilesdo
(6)content=data_cleaning(line,api_filter)
(7)apis=deduplication(content,last_api,length)
(8)endfor
(9)returnapis
对图3所示的API调用序列经过数据清洗和剪枝处理后,得到如图4所示的序列数据。

图4 预处理后的API序列
3.2 构建分词器
为了让模型能处理API序列,需要使用分词器将其解析为模型可识别的数值表示,因此分词器需要完成分词、初始编码等功能。由于本文研究对象特定于软件API序列,而不是普通文本,数据中包含与程序描述相关的词汇和标识符,同时避免来自其它不相关领域通用词汇的分词干扰,因此需要重新构建基于API序列的分词器,方法如下:
首先定义标记器Tokenizer,并使用词层级WordLevel的字符编码器;接着定义训练器WordLevelTrainer,并重新制定针对API序列的规范化器、预标记器等组件;然后将训练语料和训练器传入标记器中;最终训练完成会生成vocab.json和merges.txt,即词典文件。后续在模型中使用分词器时,只需加载词典文件,分词器会将经过数据预处理的API序列拆分成词典中对应的字段,然后通过查找表将其转换为数值并进行标记化处理。算法2为构建分词器的伪代码。
算法2:构建分词器
输入:预处理后的apis
输出:生成的vocab.json、merges.txt
(1)MalTokenizer=Tokenizer(WordLevel(unk_token))
(2)trainer=WordLevelTrainer(special_tokens)
(3)MalTokenizer.normalize&post_processor
(4)MalTokenizer.train(apis,trainer)
(5)MalTokenizer.save()
对图4的API序列进行分词后得到如图5所示的结果。可以看到API序列已被解析为数值序列,后面将被直接输入到MDMSM预训练模型中。

图5 分词后的API序列
3.3 恶意软件动态掩码序列模型的预训练
MDMSM模型通过在大量无标注API序列上构建动态掩码序列任务进行预训练,实现动态生成包含API序列上下文语义信息的编码,并捕获数据内部结构。动态掩码序列任务是指随机掩盖API序列中一些API函数,然后训练模型来预测这些被掩盖的API函数,实现无监督学习。在模型预训练的每轮次中,动态地把输入的无标注API序列随机掩盖掉15%让模型去预测,实现动态掩码。由于预训练阶段采用[MASK]遮挡API函数,但在微调阶段是没有[MASK]的,因此为了解决该问题,对于被随机掩盖的API函数有80%的概率会被替换为[MASK],10%的概率被替换为其它API函数,10%的概率保持不变,其中较短的序列用[PAD]进行填充并在序列开头添加[CLS]标志位。步骤如下:
首先使用3.2节中的词典文件载入分词器MalTokenizer,在每轮模型预训练的过程中使用generate_positions()函数,根据API序列动态生成掩码位置的索引值,在每轮训练时会不断更新被掩码的位置,并用MalTokenizer的tokenize()方法把经过数据清洗的API序列做分词处理,同时根据分词后的数据使用generate_mlm_tokens()函数分别生成被掩码的序列M、被填充的序列P和原始的序列T,从而完成对动态掩码序列任务的构建;然后使用batch_samples()函数将M、P、T数据划分批次,输入到模型中进行预训练,模型通过预测序列中[MASK]位置最有可能被替换的API函数来不断拟合原有序列;最终获得预训练的恶意软件动态掩码序列模型。算法3为模型预训练的伪代码。
算法3:恶意软件动态掩码序列模型预训练
输入:预处理后的apis
输出:预训练后的MDMSM
(1)vocab=dictionary_file
(2)epoch=training_number
(3)MDMSM=Malware Dynamic Mask Sequence Model
(4)MalTokenizer=PreTrainedTokenizerFast(vocab)
(5)forindexinepochdo
(6)forapiinapisdo
(7)pos=generate_positions(api)
(8)tokens=MalTokenizer.tokenize(api)
(9)M,P,T=generate_mlm_tokens(tokens,pos)
(10)endfor
(11)batchs=batch_samples(M,P,T)
(12)MDMSM_file,loss=MDMSM(batchs)
(13)loss.backward()
(14)endfor
(15)returnMDMSM_file
模型预训练采用交叉熵损失函数,公式为
(6)
其中,yi表示样本i真实标签,即真实的API函数,pi表示模型预测的API函数,两者做交叉熵进行梯度更新。
3.4 模型微调和恶意软件检测
模型微调是指通过无监督学习从大量无标注数据中训练一个深层的预训练模型后,得到一组预训练的模型参数;然后针对不同的下游任务,把预训练模型的输出添加相应的网络模型组成用于解决特定目标任务的新模型;最后在少量有标注数据上对模型进行有监督地微调来完成指定任务。在微调的过程中,预训练模型的权重可以选择更新或者冻结部分网络层,以减少资源开销。
在3.3节的预训练模型基础上,针对下游的软件分类任务进行检测模型的微调。步骤如下:首先在恶意软件动态掩码序列模型后面添加检测模型,将MDMSM最后一层输出的动态词向量作为下游检测模型的词嵌入,从而构建出恶意软件检测模型;然后使用batch_samples()函数把少量有标注API序列划分批次,输入到恶意软件检测模型中进行有监督地微调,在微调的过程中选择冻结一部分预训练模型的参数防止模型过拟合;最终在小规模的API序列上训练检测模型完成分类任务。下游检测模型是在MDMSM之上单独添加的网络结构,其中的权重参数是模型随机初始化并需要从头开始训练,微调时MDMSM本身继续训练,预训练模型的部分权重参数也被不断更新从而更好地适应软件分类任务。检测模型仍然采用交叉熵损失函数。其中标签0为良性,标签非0为恶意。算法4为模型微调的伪代码。
算法4:检测模型微调
输入:预训练后的MDMSM,少量有标注API序列datasets
输出:检测模型和评价指标
(1)vocab=dictionary_file
(2)epoch=training_number
(3)model=MDMSM and Classification Model
(4)MalTokenizer=PreTrainedTokenizerFast(vocab)
(5)datas=MalTokenizer(datasets)
(6)forindexinepochdo
(7)batchs=batch_samples(datas)
(8)model_file,loss=model(batchs)
(9)loss.backward()
(10)endfor
(11)evaluation=evaluate(model,datas)
(12)returnmodel_file,evaluation
4 实 验
4.1 实验数据
为了验证恶意软件动态掩码序列模型预训练和检测模型微调的有效性,本文首先进行软件API序列数据集的收集和整理工作。目前单一的API序列数据集都比较小,本文收集了8个不同来源的数据集,见表1。因为后续要和其它方法进行性能比较,本文全部采用了带标签数据,实际中可采用无标签的数据进行预训练。由于收集到大部分数据集提供的是软件行为分析报告或是所提供数据集中存在很多无关噪音干扰字段,因此需要对收集的数据筛选与整理,并尽可能平衡不同类别样本的比例来排除数量不一致对实验结果的影响。表1中前7个数据集总共包含61 381条API序列,共同构成本文的数据集1,进行恶意软件动态掩码序列模型的预训练和二分类任务的验证,最后一个数据集来源于阿里云天池大赛恶意程序检测的数据集,共有13 887条样本,构成本文的数据集2,用于多分类任务的验证。
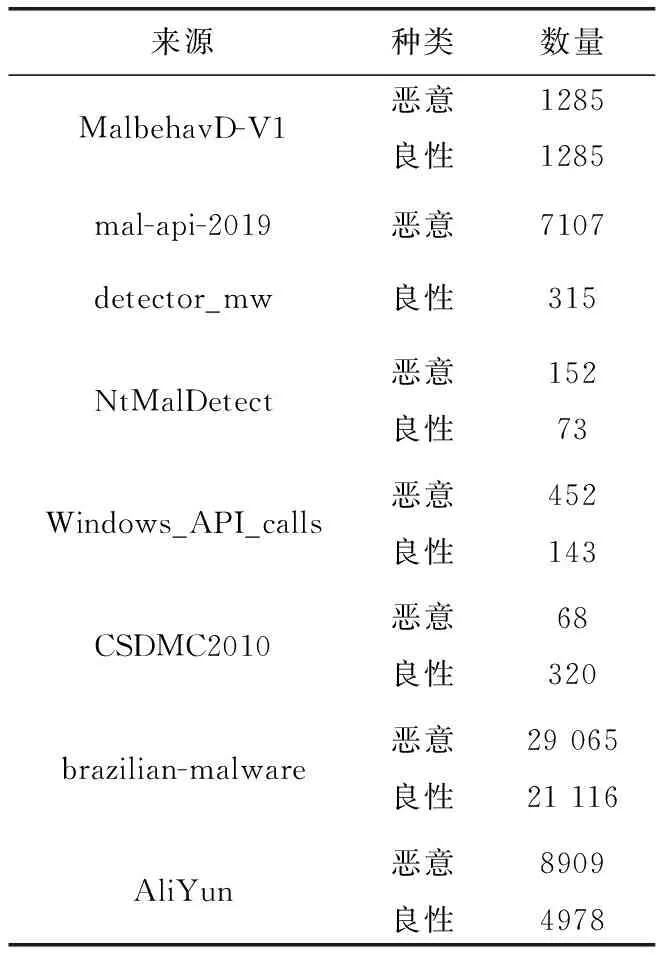
表1 数据集来源
在本文数据集1上,分别选取20 000条恶意和良性API序列样本用于恶意软件动态掩码模型的预训练,再分别选取2000条用于检测模型的微调做二分类任务,最后再选取1000条用于模型测试,共计46 000条数据。数据集1上的划分见表2。
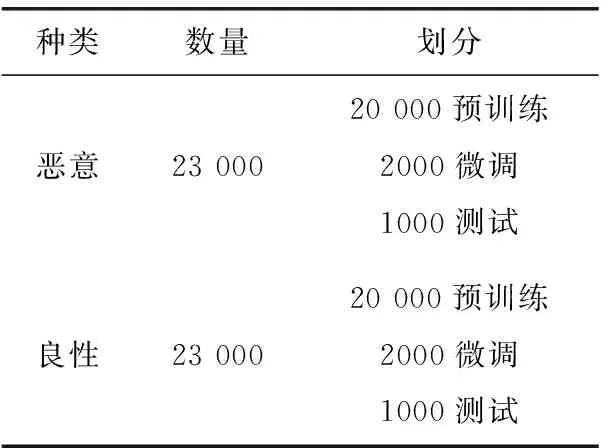
表2 数据集1划分
在本文数据集2上,不同种类的恶意样本分别选取500条,良性样本选取1000条,共计4500条数据,然后将80%的数据作为训练集,剩余20%的数据作为测试集做多分类任务。数据集2的划分见表3。

表3 数据集2划分
4.2 评估方法和标准
评价指标对分析模型有着至关重要的作用,通过计算Accuracy、Precision、Recall和F1评估模型的性能。当恶意样本被检测为恶意则标记为TP;当恶意样本被识别为良性则标记为FN。当良性样本被检测为良性则标记为TN;当良性样本被识别为恶意则标记为FP。公式如下
(7)
(8)
(9)
(10)
Precision和Recall是一对矛盾的指标,引入F1值能有效地平衡两者,F1值越接近1代表模型性能越好。
4.3 实验结果和对比
本文选取4种机器学习、3种传统词嵌入和原始BERT作为对照实验方法,其中机器学习方法选取K近邻算法、决策树、支持向量机、朴素贝叶斯,在评价指标中用K-NN、DT、SVM、NB表示,传统词嵌入方法为Word2Vec、Glove、FastText。为验证MDMSM的效果。在数据集1中,将用于MDMSM预训练和微调的数据样本组合为对照实验的训练集,用于模型测试的数据样本作为对照实验的测试集,尽可能平衡训练集和测试集所带来的差异。
4.3.1 不同分词器进行模型预训练对比
由于NLP领域的通用语言序列和网络安全领域软件API序列的分词规则有所不同,按照3.2小节所述,根据API序列的特点重新构建分词器,在数据集1上,采用原始BERT模型的分词器BertTokenizer和本文MDMSM的分词器MalTokenizer分别对模型重新进行预训练,然后进行二分类任务的实验结果对比。
通过表4可知,采用MalTokenizer作为分词器的预训练模型进行分类任务要远高于采用BertTokenizer作为分词器的预训练模型的检测效果。主要是因为原始BERT模型的分词器主要是针对通用NLP领域的通用语言样本进行编码的,而API函数几乎不存在于BertTokenizer的词典文件,并且API函数不存在子词或者词根词缀,每一个API函数所具备的系统功能也不尽相同,实验结果表明,基于API序列采用预训练模型完成恶意软件分类任务时,需要先重新训练分词器对API序列进行编码的必要性。
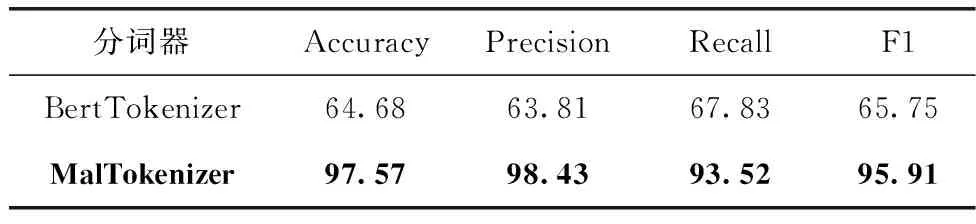
表4 不同分词器的结果对比/%
在数据集1上,采用不同分词器的预训练模型进行动态掩码序列任务的预训练,如图6所示,其中横坐标的数据进行了缩放,一个单位代表实际5000的步长。可以看出,MalTokenizer模型的损失值随着训练步长很快减小,在一定步数后开始趋于稳定状态接近0。然而MalTokenizer模型的损失值降至4后不再变化,表明该模型无法很好地收敛。
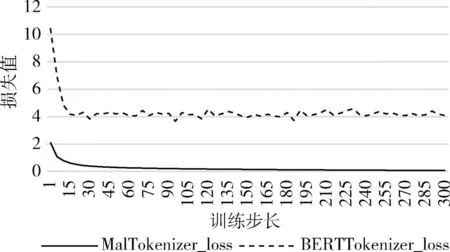
图6 不同分词器进行模型预训练的loss曲线
4.3.2 与现有方法作二分类对比
针对不同检测模型在二分类任务上的实验结果进行分析,各项指标见表5。
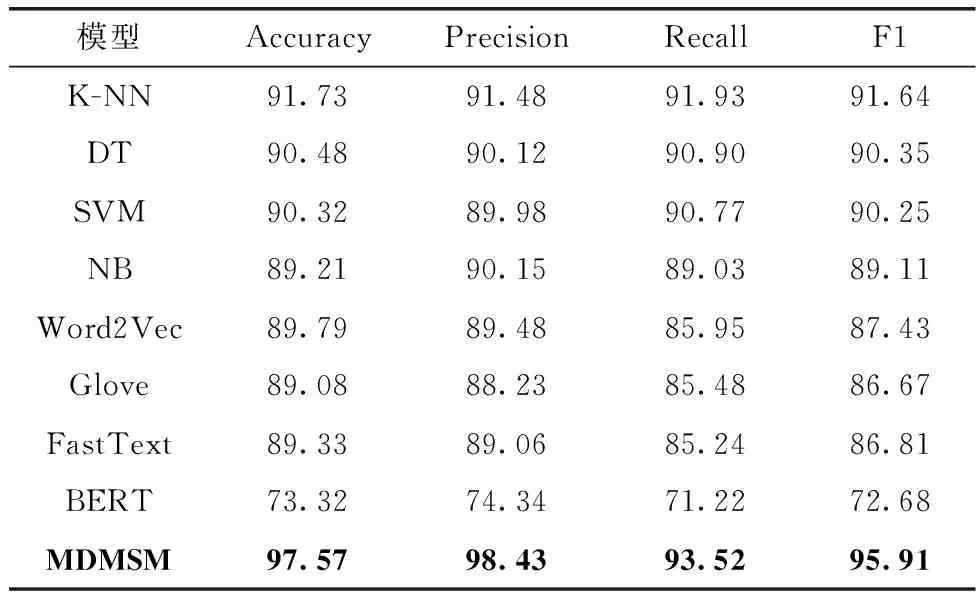
表5 不同方法在数据集1上的实验结果对比/%
由表5可知,本文方法在二分类问题上,相较于其它方法有着更高的准确率达到97.57%,通过对比发现F1值也是高于其它方法。与BERT相比,本文提出基于API序列利用动态掩码序列任务针对BERT模型重新进行无监督学习的预训练,同时获得API序列的全局动态编码表示,然后将该编码表示作为检测模型词嵌入用于软件检测的方法,结果显示准确率提高了25.09%,其它指标也有较高的提升,验证基于API序列,对BERT模型利用动态掩码序列任务进行无监督学习的预训练,然后进行恶意软件分类任务的可行性;该方法也优于现有机器学习方法的结果,在准确率上比分类效果最好的K-NN算法高出5.84%,间接验证该模型能更准确地捕捉到API序列的上下文语义特征并为软件分类提供有力依据;虽然本文方法也属于词嵌入模型的范畴,但相较于传统词嵌入模型,其准确率平均提升了8.17%,验证本文方法在捕获API序列特征时会考虑到样本数据的全局信息,不再只局限于利用滑动窗口捕获局部信息,有效地解决API函数在不同调用序列中的语义表示问题,使得恶意软件分类任务更加有效地完成。本文方法在捕获API序列特征方面表现出色,充分考虑全局信息使得分类准确率显著提高。
4.3.3 与现有方法作多分类对比
在数据集2上直接使用已经预训练的MDMSM做多分类任务,虽然准确率等指标相较于二分类有所降低,但仍优于其它算法。各项指标见表6。
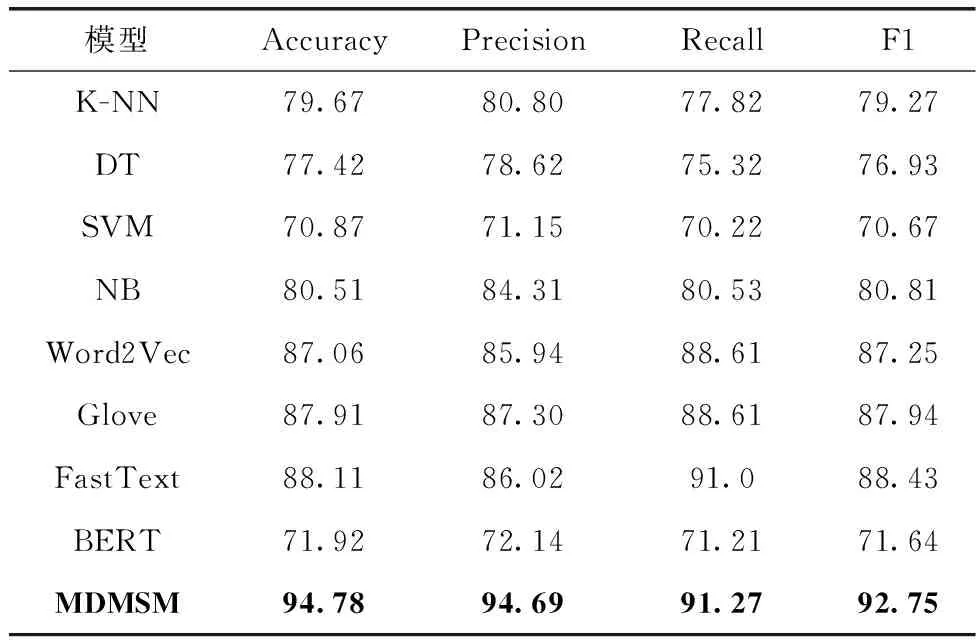
表6 不同方法在数据集2上的实验结果对比
由表6可知,本文方法在各项指标上仍均高于其它模型。图7为不同方法的多分类和二分类准确率变化曲线。
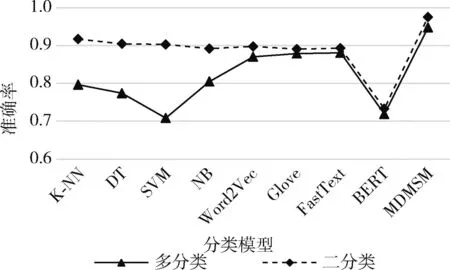
图7 多分类和二分类的准确率对比
在对比实验中,使用机器学习方法进行多分类任务比二分类任务的各项指标波动较大,这是因为数据集2中不同种类的样本数据量较少,而多分类任务需要更多的特征数量和和更全面的特征表达,而且数据噪声也容易影响模型性能。这使得模型在多分类任务中难以准确地提取用于软件分类的特征,从而导致效果不佳。相比之下,使用传统词嵌入方法的准确率变化不大,但整体效果仍不尽如人意。这是因为数据集2的多分类任务需要更复杂的模型和特征表示以及更多的数据标签,而在数据量有限的情况下,复杂的模型可能导致过拟合,降低多分类任务的性能,也无法有效地捕获API函数的全局语义信息和处理API函数在不同序列的多种语义问题。本文方法是基于大量无标注的API调用序列,通过模型预训练的过程来拟合原始API序列的目标任务,从而使预训练后的模型能够准确关注序列中每个API的关键特征,并提取到融入API序列全局语义信息的编码表示用于分类任务。该方法的优势在于能够更好地捕获API序列的上下文语义关系,从而有效地提取到软件分类相关的特征,使得检测效果显著提升。
5 结束语
本文通过动态掩码机制在大量无标注API序列上构建恶意软件动态掩码模型,获取API序列的动态编码表示,解决了传统方法无法捕获API序列全局语义信息和带标注数据不足的问题,然后在少量有标注API序列上微调模型完成检测。该方法在二分类和多分类任务中均优于其它方法,显著提高软件检测的准确率。然而在软件分析报告中只利用到API调用序列的字段,在后续中将尝试结合其它数据展开工作,此外本文用于模型预训练的数据量仍然有限,接下来计划搜集更大规模的软件样本进行分析。
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
开放教育研究(2020年2期)2020-03-31
环球慈善(2019年6期)2019-09-25
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
现代语文(2016年21期)2016-05-25
浙江大学学报(工学版)(2015年4期)2015-03-01
大连民族大学学报(2015年2期)2015-02-27
