
基于CP-ABE算法的Fabric隐私保护模型
2024-04-23 04:34:40王有恒王瑞民张建辉
计算机工程与设计 2024年4期
王有恒,王瑞民,张建辉
(1.郑州大学 计算机与人工智能学院,河南 郑州 450001;2.郑州大学 网络空间安全学院,河南 郑州 450002)
0 引 言
区块链系统本质上是一个多方维护的分布式账本,具有一致性和不可篡改性,但是仍存在隐私泄露的风险。文献[1-4]分析了区块链系统中的存在隐私保护问题,并整理出一些隐私保护技术,其中包含地址混淆、信息隐藏、通道隔离、环签名、零知识证明技术和访问控制技术[5-7]。
属性基加密方案常用于云数据存储与共享,该技术可以实现粒度细化到属性级别的加密访问控制。汪金苗等提出了面向区块链的隐私保护与访问控制方案[8]。沈韬等提出基于区块链的支持外包的多授权属性加密技术方案[9]。有效解决了属性基加密中解密开销大的问题。邱云翔等提出了一种基于CP-ABE算法的超级账本区块链数据访问控制方案[10]。该方案实现了细粒度安全访问控制,但仍存在加解密效率低,访问控制策略不灵活的问题。
超级账本(hyperledger Fabric)是联盟链的代表,与公链以太坊相比,Fabric区块链设置了准入机制,仅允许授权的节点加入区块链网络,且节点的权限不同,加强了对数据的隐私保护。但其仍存在以下问题:通道内的数据缺乏保护;数据隐私保护粒度过粗;成员对数据的访问控制缺乏动态性。CP-ABE算法对数据进行加密时,使用的是双线性对加密方式,与传统公钥加密方案相比,运算更复杂,开销更大。因此需要优化CP-ABE算法的加解密效率。
本文针对Fabric的隐私保护需求,提出了一种基于CP-ABE算法的Fabric隐私保护模型CP-PPM,该模型融合了CP-ABE算法和IPFS技术,利用Fabric-CA完成CP-ABE算法中密钥的分发,将上链数据转变为IPFS文件存储地址,使用CP-ABE算法对上链地址进行加解密。
1 背景技术
1.1 超级账本
超级账本(hyperledger fabric)是一个许可制的区块链平台,与私有链不同的是,超级账本区块链网络的成员需要从可信赖的成员服务提供者(MSP)注册。超级账本还提供了创建通道(channel)的功能,允许一组参与者创建各自的交易账本。通道机制基于发布-订阅的关系,将Peer和Order连接在一起,形成具有保密性的通讯通道(虚拟),节点可以订阅多个通道,并且只能访问订阅通道上的交易,实现了不同通道中的数据的相互隔离。Fabric网络中的身份是使用数字证书实现的,因此需要CA来处理证书的管理。Fabric-CA是超级账本自带的证书管理工具,可以为用户注册身份和颁发证书,当用户信息改变时,同步地更新证书信息。
Fabric-CA架构如图1所示,与CA服务器的交互有两种方式:Fabric-CA-Client和SDK。所有与Fabric-CA服务器的交互都是通过REST APIs来完成的。Fabric Server端包括一个由树结构构成的服务器集群,包括Root和若干中间节点。在服务器集群中,可以通过客户端或者SDK与CA服务器进行交互。
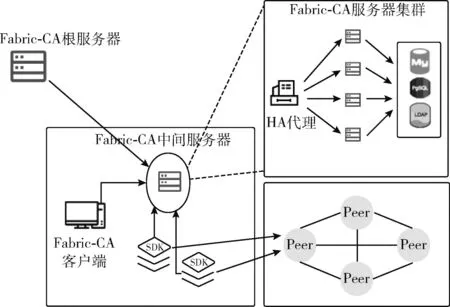
图1 Fabric-CA架构
1.2 CP-ABE算法
属性基加密的思想是让密文和密钥与属性集合和访问结构产生关联。当且仅当属性集合满足访问结构的时候,才可以解密成功,从而实现一对多的数据细粒度访问控制。在密文策略属性基加密(CP-ABE)方案中,由数据的拥有者来制定密文访问策略,以决定谁可以解密密文。访问策略与密文相关联,代表着数据拥有者具有了对自己的数据的访问控制权,根据设置的策略可以判断哪些访问者能够合法访问数据。而策略的逻辑判断表达式中,一般以属性为判断依据。也就是对自己的数据做了一个粒度可以达到属性级别的细粒度加密访问控制。CP-ABE方案一般用于分布式环境中的数据加密存储。
CP-ABE包含4个基本算法:Setup、Encrypt、Key Generation、Decrypt[11]。
Setup:输入隐式的安全参数。输出公共参数PK和主密钥MK。
Encrypt(PK,M,A):输入PK,消息M和访问结构A,对M进行加密,产生密文CT。
Key Generation(MK,S):输入主密钥MK和描述密钥的属性集合S。输出私钥SK。其中SK由属性来确定。
Decrypt(PK,CT,SK):输入公共参数PK、包含访问结构A的密文CT,以及私钥SK。其中私钥由属性集合S生成。若S符合A的访问控制策略,则对CT进行解密并返回消息M。
1.3 IPFS
IPFS是一个分布式文件系统协议。IPFS的设计与WEB类似,是全新的超媒体文本传输协议。采用去中心化分片加密存储技术,文件被分割存储在IPFS网络节点中。区块链系统和IPFS的协作可以突破区块链本身的存储瓶颈。著名的区块链项目Filecoin是运行在IPFS的一个激励层,以代币为沟通桥梁,将数据提供者和使用者联系在一起。IPFS的优势在于其效率高、隐私性强,安全性方面则可以抵御女巫攻击、外包攻击和DDoS攻击等。
2 模型设计
2.1 模型框架
针对提出的Fabric区块链缺乏隐私保护的问题,本文提出了一种基于CP-ABE算法的Fabric区块链隐私保护模型CP-PPM。
模型设计思想是利用CP-ABE算法实现对上链数据的隐私保护,并通过调整访问控制策略达到细粒度访问控制。将CP-ABE算法中的生成包含用户属性的密钥和密钥分发任务交由Fabric-CA模块,省去与第三方CA机构交互的步骤,提高算法执行效率,减少证书和密钥泄露的风险。将Fabric区块链系统和IPFS系统相结合,上链原数据转变为IPFS文件存储地址,减少CP-ABE算法加解密原数据的开销,同时增强区块链系统存储大文件的能力。
模型主要包含4部分:区块链网络Fabric、星际文件系统IPFS、客户端Client和证书颁发机构Fabric-CA。模型框架如图2所示。
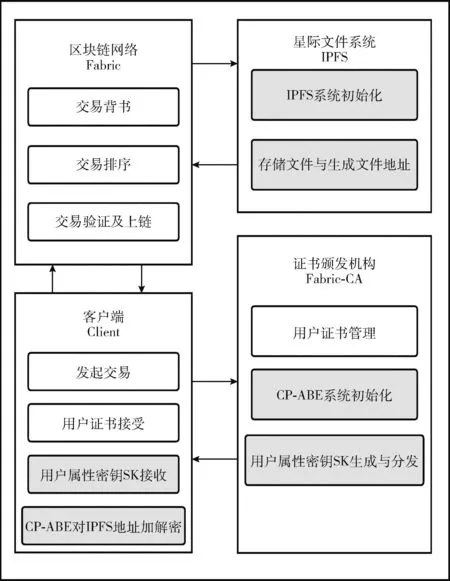
图2 Fabric区块链隐私保护模型CP-PPM
(1)区块链网络Fabric:该部分主要承担区块链网络的基础功能。在模型CP-PPM的设计流程中,该部分的作用是与IPFS系统交互,利用IPFS存储原始文件。经过背书、排序、节点验证等上链流程后,在通道中存储使用CP-ABE算法加密后的IPFS文件路径。
(2)星际文件系统(IPFS):该部分的功能是运行IPFS系统,进行原数据的存储。需要上链的数据分布式存储在IPFS节点中,并返回文件地址给客户端。
(3)客户端(Client):原有的Fabric区块链网络中,该部分的作用是发起交易和接受用户证书。在CP-PPM中,客户端需要先对用户属性密钥SK进行接收,成功接收后完成CP-ABE方案中的对IPFS存储地址的加解密,即运行Encrypt算法和Decrypt算法。
(4)证书颁发机构(Fabric-CA):该部分主要实现的功能是:①管理系统用户的身份证书,包括颁发证书及撤销证书。②CP-ABE方案初始化,由Setup生成公共参数PK以及主密钥MK。③用户属性密钥的生成与分发,对应CP-ABE方案中的Key Generation算法,针对用户的属性生成并分发包含该用户属性私钥SK。
2.2 模型工作流程
(1)用户注册:该模块主要是用户User与Fabric-CA的交互,首先User向Fabric-CA申请注册用户证书,由Fabric-CA中MSP对用户的证书申请请求进行数字签名,生成X.509证书形式的数字身份Ucert。用户身份注册成功后,初始化CP-ABE算法,初始化阶段的主要工作是通过输入系统安全参数λ,生成主密钥MK以及公开参数PK,并且根据数字证书生成包含用户属性的私钥SK。最后Fabric-CA将用户证书Ucert和用户属性私钥SK返回给User。
(2)数据存储:该模块主要是Fabric区块链网络和Fabric-Client以及IPFS系统。当数据所有者Owner需要将自己的数据上传到区块链系统上时,先向Fabric-Client提交自己的数据上传请求,Fabric-Client与IPFS系统进行交互,等待IPFS系统初始化完成。IPFS系统中将单位数据块大小设置成256 KB,当数据大小超过数据块容量时,会对数据进行切割处理,并分段存储在不同数据块里。IPFS系统将数据存储到分布式节点中后,会生成一个数据的存储地址M并返回。Owner根据自己的访问控制需求设置访问控制策略P,并将P和公开参数PK作为公钥,对返回的M进行加密,生成密文CT。接下来通过交易的方式让CT上链,使用交易负载的方式上传CT。在对Fabric发起交易请求后,区块链网络将交易进行全网同步。Fabric区块链网络先对交易进行背书,背书过程完成后由User封装交易,并以Envelope的形式发送给排序节点。排序完成后交易先被打包生成区块,经由排序节点传输,接着在通道组织内接受验证。通过最终验证的区块会被存储到同一通道内的各个节点上,至此数据存储阶段完成。数据存储流程如图3所示。
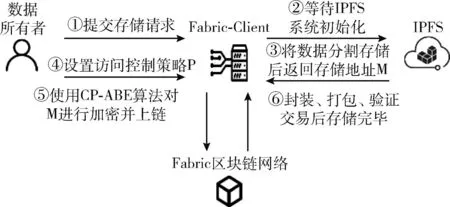
图3 数据存储流程
(3)数据访问:该模块主要是数据访问者Visitor与Fabric网络的交互。当Visitor需要访问上链的数据时,通过Fabric-Client请求获取Fabric区块链网络中存储CT的交易信息,得到CT后,Visitor首先使用自己的属性私钥SKV对CT进行解密,如果SKV属性满足访问控制策略P时,则可以成功解密,得到加密数据所对应的数据存储地址M,Visitor可根据数据存储地址M访问数据。反之,SKV属性与P不匹配时则解密失败。数据流程访问如图4所示。
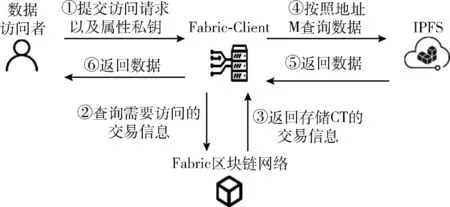
图4 数据访问流程
2.3 访问控制策略的使用
CP-ABE算法中,使用树结构来保护密钥,与、或逻辑操作和门限操作表现为树的节点[12,13],叶子节点则用于表示属性并且存储相应的属性值。当数据访问者需要访问数据时,要匹配数据所有者设定的属性才能解密出该叶子节点的秘密值[14]。其中非叶子节点为门限节点,数据访问者需达到门限最低值才能解密此节点的密码值。用户不同的属性关系组合在一起,并形成逻辑表达式,即为访问控制策略。
在模型CP-PPM中,访问控制策略关系到访问控制的粒度,用户属性是CP-ABE方案属性集中的最细粒度。在Fabric网络中,可以同时存在多个通道,而且每个通道内可以存在多个组织,用户被包含在不同的组织内。区块的分发是按照通道ID进行分发的,那么不同的用户所属的通道ID即为该用户的固定属性之一。此外,数据所有者可根据自己的访问控制需求灵活选择用户属性,例如组织ID、用户ID,并将这些属性设置成策略,当访问者的属性集满足访问策略时才被授权访问数据。
针对不同的使用场景,访问控制的策略也有所不同,对数据访问控制的粒度也会产生影响,例如在学校管理系统中,A用户属性是:①通道ID Channel1;②计算机学院;③学生;④机器学习实验室;B用户属性是:①通道ID Channel2;②计算机学院;③;教师;④网络安全实验室;C用户属性是:①通道ID Channel1;②计算机学院;③学生;④网络安全实验室。
当数据所有者需要在某一个通道内共享自己的数据,则可以将通道ID这一属性设为唯一的通道策略,属于该通道ID的用户都可以访问该数据。如只让Channel1通道内的用户访问,可将策略设为:(Channel ID=Channel1),此时用户A和用户C可以合法访问。
当数据所有者具有更细粒度的数据访问控制需求时,则可以按照自己的需求将特定的用户属性加入到访问控制策略中。如需要让用户所属院系为计算机学院,且职业是老师访问,则可将访问控制策略设为:(Department=CS,Occupation=Teacher),此时仅有用户B可以合法访问。
访问控制策略以逻辑表达式为基础,访问控制策略中的属性数量越多,该访问控制结构就越复杂,细粒度访问的程度也就越高。
3 实验与分析
3.1 实验环境
为了对模型CP-PPM的性能进行分析。实验环境为Ubuntu 16.04 LTS虚拟机,虚拟机内存为4 GB,处理器数量为2。硬件信息见表1。在虚拟机中搭建了Fabric区块链网络和IPFS存储系统。该区块链网络使用了官方超级账本框架,包含一个排序服务节点和两个组织,每个组织中分配了两个Peer节点。IPFS存储系统使用Go-IPFS技术搭建,该存储系统共有5台机器,所有机器接入到相同的局域网内。云存储服务则由一台本地服务器提供。CP-ABE算法采用斯坦福开放源码cpabe-0.11程序库来编写和实现。

表1 硬件信息
3.2 性能分析
3.2.1 数据加解密时间效率比较
本实验是测试模型CP-PPM中CP-ABE算法加解密数据的性能,并与文献[10,13,14]的方案进行对比。
由于IPFS系统生成的文件存储地址时采用了SHA-256算法,对任意长度的内容,生成长度固定为32个字节的Hash值,封装成Multihash之后,最后转化为Base58,最终文件存储地址都是46个字节。相较于文献[10]的方案,模型CP-PPM数据大小固定,且远小于1 MB,无需考虑单个区块的容纳量。同时加解密算法与原始方案一致,密钥长度和公钥长度均小于文献[13-15]。在将属性个数设置为相同,且文件大小大于46字节时,模型CP-PPM数据加解密效率更高。
根据上述,本实验将文件大小设置为46 Byte,分别计算当属性个数为2、4、8、12、16、20时,CP-ABE方案的加密和解密的时间。从图5可以观察到,CP-ABE算法进行加解密运算的时间与访问控制策略中设置的属性个数,是一种线性关系。当属性数量增大时,CP-ABE算法加解密时间也随之增加,且加密时间增长速率大于解密时间增长速率。因此,访问控制需求越高,所需设置的属性个数也越多,访问控制粒度更细的同时,所产生的时间开销也会增加。
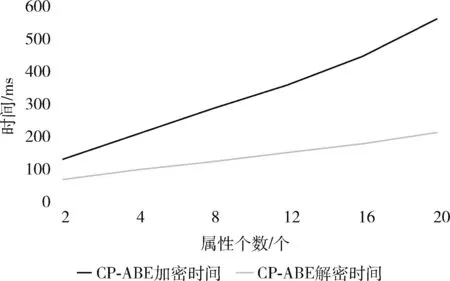
图5 不同属性个数时CP-ABE算法加解密时间
3.2.2 两种存储系统的存储效率比较
模型CP-PPM在原有Fabric区块链系统的基础上增加了IPFS系统,用IPFS系统来代替区块链系统存储原始数据。所以需要测试引入这种链下存储方式的时间开销,并与其它链下存储方式进行对比。
本实验是针对云存储系统和IPFS存储系统两种常用链下存储方式的性能对比实验。在同一局域网下使用了一台本地服务器模拟云存储系统,并且搭建了IPFS分布式网络集群。实验测试的目的是,比较IPFS和云存储在对不同大小的文件进行上传和下载时的时间开销。
为了不失一般性,实验分别设置了500 KB、1000 KB、2000 KB、3000 KB、5000 KB、10 000 KB的文件,分别在两种存储系统上进行上传和下载的操作,测试100次后求平均值,图6比较了两种存储系统的文件上传时间,图7比较了两种存储系统的文件下载时间,从图6和图7可以明显看出,文件大小相同时,IPFS存储系统文件上传和下载的时间开销都低于云存储系统,当文件大小增大时,IPFS系统的上传和下载时间变化幅度更小。因此本文使用IPFS系统来进行原数据的存储,可以减少系统开销,提升存储性能。
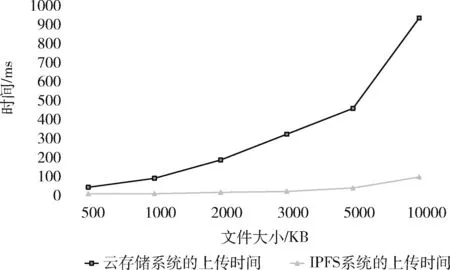
图6 云存储和IPFS存储系统的文件上传时间
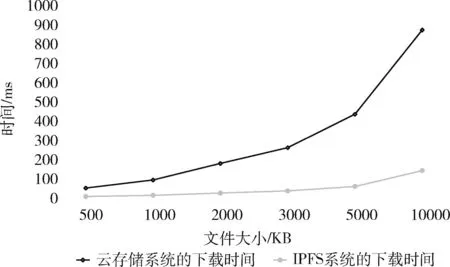
图7 云存储和IPFS存储系统的文件下载时间
3.2.3 Fabric的吞吐效率测速
本实验的目的是测试密文CT作为交易负载上链对Fabric系统吞吐量的影响。实验时将源数据文件大小设置为46 Byte,属性数量固定为10个,经过CP-ABE算法加密后,生成的模拟CT大小为52 Byte。编写一个交易链码,通过Tape工具来对Fabric系统吞吐量进行测试。实验组每次交易将模拟CT上传为交易负载;对照组每次不上传交易负载。为防止瞬间交易量过大而导致部分交易被丢弃,每轮只运行两次Test函数,共进行100轮测试,取结果平均值。实验结果见表2,由结果可知,将CT上传为交易负载保存在区块链中,对Fabric区块链网络吞吐量影响在可接受范围内。
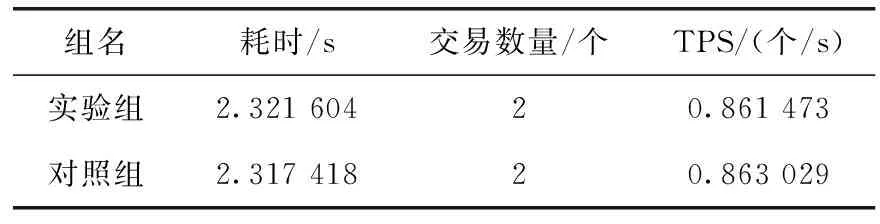
表2 吞吐量测试
3.3 安全性分析
隐私保护模型CP-PPM可以保证系统数据的机密性和完整性。Fabric-CA作为超级账本网络的原始模块是完全可信的,所以在算法初始化阶段中,密钥的生成过程可信、用户属性的真实性可信。在数据的存储和访问过程中,数据的传输都包含加密步骤,当用户不符合数据所有者所设置的访问权限时,无法访问原始数据,因此可以确保数据机密性。采用的IPFS系统进行存储时,先使用哈希算法对存储数据的单位数据块进行加密,计算结果由一个数组保存,然后再次对存储哈希值的数组使用哈希算法,得到一个数组的哈希值。当数据被篡改时,该数组的哈希值也会改变,因此可以保证数据的完整性。Fabric区块链网络中的每个区块内容中都包含上一区块所有数据的哈希值,区块相连形成链接关系,也保证了链上数据的完整性。此外,为保证数据可用性,访问控制策略的设置由数据所有者决定,数据访问者需要符合数据所有者制定的访问策略要求,即数据访问者自身属性与访问策略属性集合相匹配。通过访问策略之后,数据访问者才可以获取访问数据的权限。数据所有者根据使用场景、使用需求的差异,可以灵活使用不同的属性集合来设置访问控制策略,将数据的访问控制粒度细化到属性级别。
4 结 论
CP-PPM隐私保护模型利用CP-ABE算法实现对区块链上数据的细粒度访问控制,并使用Fabric区块链中的原有的Fabric-CA来承担CP-ABE算法中的密钥生成和分发工作。性能分析结果表明,CP-PPM方案节省了初始化CP-ABE算法的时间。同时为减少CP-ABE算法加解密数据的消耗,使用IPFS系统来代替区块链系统存储加密数据,CP-ABE算法仅需对数据的存储地址进行加解密。实验结果表明,相较于云存储的链下存储方案,IPFS系统的上传文件的时间开销减少了90%,下载文件的时间开销减少了84%。有效缓解了区块链系统的存储压力。安全分析结果表明,CP-PPM可以实现数据安全和细粒度隐私保护。
5 结束语
针对超级账本区块链系统中存在的数据安全共享和隐私保护问题,提出了一种融合了CP-ABE、区块链和IPFS的隐私保护模型CP-PPM。与前人方案相比,CP-ABE算法加解密效率更高,访问控制策略的使用更灵活,访问控制细粒度化更高,并且提升了存储效能。通过性能分析与安全性分析,并且与已有方案进行对比,表明了隐私保护模型CP-PPM对Fabric区块链网络的链上数据实现访问控制具有可行性。CP-PPM模型基于Fabric区块链网络设计,也可与其它拥有CA模块的联盟链适配。未来考虑利用Fabric系统中的链码机制配合CP-ABE算法达到更加灵活的隐私保护效果。
猜你喜欢
能源工程(2020年6期)2021-01-26 00:55:22
山东冶金(2019年3期)2019-07-10 00:54:04
消费导刊(2018年10期)2018-08-20 02:57:02
中国公共安全(2017年11期)2017-02-06 05:28:08
通信学报(2016年11期)2016-08-16 03:20:32
网络空间安全(2016年3期)2016-06-15 20:27:07
现代工业经济和信息化(2016年19期)2016-05-17 05:38:20
通信电源技术(2016年1期)2016-04-16 04:57:26
电子技术应用(2016年6期)2016-03-18 05:41:13
信息安全研究(2016年10期)2016-02-28 20:18:36
