
基于改进YOLOv5s的小目标检测算法
2024-04-23 04:53:18贵向泉秦庆松孔令旺
计算机工程与设计 2024年4期
贵向泉,秦庆松+,孔令旺
(1.兰州理工大学 计算机与通信学院,甘肃 兰州 730050;2.甘肃省气象信息与技术装备保障中心 气象数据质量控制室,甘肃 兰州 730020)
0 引 言
目前,广泛使用的基于卷积神经网络的目标检测方法可以分为两类[1]。第一类是两阶段目标检测方法,如R-CNN、Fast R-CNN、Faster R-CNN[2]等;第二类是一阶段的目标检测方法,如SSD、YOLO[3,4]系列。在YOLOv4以前,基于两阶段的目标检测算法虽然精度较高,但速度较慢,难以满足实时性的要求;而一阶段的目标检测方法,虽然具有更快的检测速度,但精度有所欠缺。在YOLOv4以后以及YOLOv5的发布,使得一阶段的目标检测算法与两阶段的目标检测算法相比无论是在检测速度上还是在检测精度上都有所提升[5]。
在实际的应用中我们发现当前社区、街道、景区的监控摄像机架设位置较高,使用目前主流的目标检测算法对其回传的图像进行检测,容易导致对远距离的小目标和密集场景下的遮挡目标产生漏检、误检等问题,而使用效果较好的YOLOv5l、YOLOv5x等网络进行检测又会受到计算机硬件设备的制约,难以达到实时性的要求。为了解决上述问题,本文在YOLOv5 6.1版本的基础上,从优化定位损失函数、添加小目标检测层、引入CARAFE[6]上采样算子和添加CBAM[7]注意力机制4个方面对YOLOv5s进行相关研究和改进。
1 YOLOv5s的改进
1.1 损失函数的改进
YOLOv5s的损失函数由边界框定位损失(Lboxloss)、分类损失(Lclassloss)、置信度损失(Lobjectloss)这3部分组成;其中在计算置信度损失时,计算所有正负样本的损失;而在计算分类和定位损失时,只计算正样本的损失;总损失的计算方法如式(1)所示(λ是超参数)。其中Lobj和Lcls采用二值交叉熵作为计算损失;Lloc采用CIOU作为计算损失,计算方法如式(2)所示
Loss=λ1Lcls+λ2Lobj+λ3Lloc
(1)
(2)
在式(2)中,IOU代表的是真实的边界框与预测边界框之间的交并比,ρ2代表的是两个边界框中心点之间的欧式距离,b和bgt分别代表预测框和真实框的中心点,c表示的是预测边界框和真实边界框的最小外接矩形框的对角线长度;v表示边界框自身宽高比之间的关系,a在求导时作为常数项不参与梯度的更新,v和a的定义如式(3)、式(4)所示。其中,w和h分别为预测框的宽和高,wgt和hgt分别为真实框的宽和高
(3)
(4)
虽然CIOU综合了IOU的交叉面积占比损失、DIOU[8]的中心偏移损失和自身宽高比3种损失;但通过公式中的v反映的仅仅是真实框和预测框之间长宽比的差异,而并不是w与wgt和h与hgt之间的真实关系;当 {w=kwgt,h=khgt} (k为正实数),都有v=0,使CIOU会退化为DIOU,所以会导致边界框收敛速度慢和定位不准确的问题。针对上述问题,EIOU[9]在CIOU的基础上进行改进,将公式v反映的横纵比拆分开,如式(5)所示
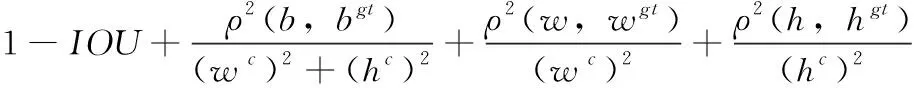
(5)
式(5)中的wc和hc是覆盖预测边界框和真实边界框的最小外接矩形框的宽度和高度。也就是说,我们将损失函数分为3部分:IOU损失LIOU、距离损失Ldis和方位损失Lasp。这样与CIOU相比,一方面可以保留CIOU损失函数的特性,另一方面,从更多的维度来考虑预测框和真实框之间的差异,来提高边界框的回归速度和定位精度。
另外,由于训练样本中不同质量的锚框样本数量存在不均衡的问题,即回归误差较小的高质量锚框的数量远小于回归误差较大的低质量锚框;进而会导致模型在训练时,低质量的锚框会产生过大的梯度,从而影响模型的训练结果。因此,为了避免低质量的锚框对损失函数带来的影响,加强高质量锚框在训练过程中的作用,进一步对定位损失函数进行优化;在EIOU的基础上结合Focal Loss[10]损失函数构建Focal-EIOU loss,如式(6)所示。其中,IOU为预测框和真实框的交并比,γ为超参数
LFocal-EIOU=IOUγLEIOU
(6)
从式(6)中可以看出IOU越大时损失函数越大,以突出高质量锚框在训练过程中的作用,从而提高边界框的定位精度。因此本文选用Focal-EIOU作为边界框的定位损失函数。
1.2 增加小目标检测层
为了提高YOLOv5s对远距离小目标的检测精度,本文对YOLOv5s的Neck部分进行优化。在Backbone的第2层经过4倍下采样处,增加一个小目标检测层,同时将算法的Neck部分修改为四尺度融合,经过PAN[11]结构与8倍下采样处、16倍下采样处和32倍下采样处产生的特征图进行特征融合。融合后,当输入图像为640×640时,最终输出的特征图大小为160×160,与其它尺度的特征图相比拥有更小的感受野,以便于检测更多的小目标。修改后的网络为YOLOv5s-p2,如图1所示。其中Neck部分的实线内是增加的小目标特征融合部分,Head部分的实线内增加的是小目标的检测头。
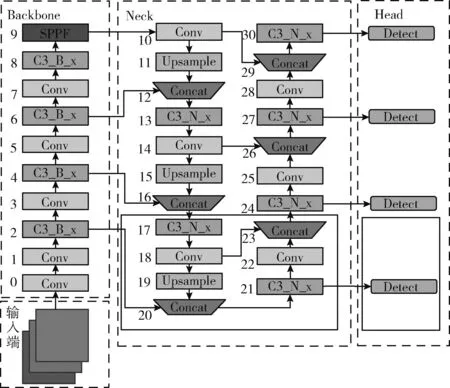
图1 YOLOv5s-p2的网络结构
1.3 上采样的改进
上采样算子在FPN[12]结构中起着关键性的作用,负责多尺度特征信息的融合。常用的上采样算子有最近邻插值上采样,双线插值上采样,转置卷积上采样。在YOLOv5s中采用的是最近邻插值上采样,由于图像中的小目标分辨率较低,有效特征信息少,且最近邻插值上采样和双线插值上采样算子的感受野较小,在多尺度特征融合时,产生的有效特征图会损失很多有关小目标的特征信息,不利于小目标的检测。而转置卷积上采样时通常需要使用较大的卷积核,会引入大量的参数和计算量。因此在本文中我们采用具有大感受野的轻量级上采样算子CARAFE来代替原来的最近邻插值上采样算子。CARAFE上采样算子的网络结构如图2所示,由上采样核预测模块和特征重组模块组成。
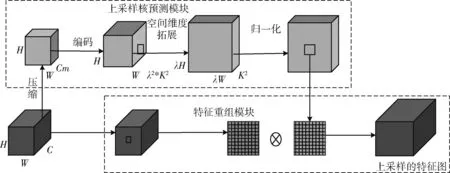
图2 CARAFE上采样算子的网络结构
在上采样核预测模块部分中,为了减少模型计算量,提高CARAFE上采样的效率,首先对输入大小为H*W*C的特征图进行通道压缩操作,压缩后的通道数为Cm;然后利用K*K大小的卷积层对压缩后的特征图进行特征编码,编码之后的特征图,在空间区域内拥有更多的上下文信息,并对编码后的特征图在通道上进行上采样核预测(其中λ为上采样的倍数);其次再进行空间维度扩展后得到一个λH*λW*K2大小的上采样核特征图;最后利用Softmax函数对每个通道的上采样核进行归一化,使得每个通道上卷积核的权重和为1。在特征重组模块中,首先以输入特征图中通道上的每个位置为中心点取出K*K大小的区域,然后与归一化后该通道的上采样核做点积操作,最终得到经过上采样后的特征图。
1.4 引入注意力机制
注意力机制是深度学习中一种常见的改进策略,源自于人类视觉的研究,本质上是使神经网络对于更加需要关注的信息,赋予更高的权重,从而突出有用信息,抑制无用信息。注意力机制具有即插即用和不会大幅增加模型计算量的优点,且现有的注意力机制在神经网络上取得了很好的效果,如通道注意力机制SE[13]和ECA[14]等。但通道注意力机制通常会忽略目标的位置信息,不能够充分融合不同位置特征之间的信息。因此,为了进一步提高YOLOv5s特征图对远距离小目标的信息提取能力,在本文中引入融合空间注意力机制和通道注意力机制的CBAM结构。CBAM结构由CAM模块和SAM模块组成,其网络结构如图3所示。
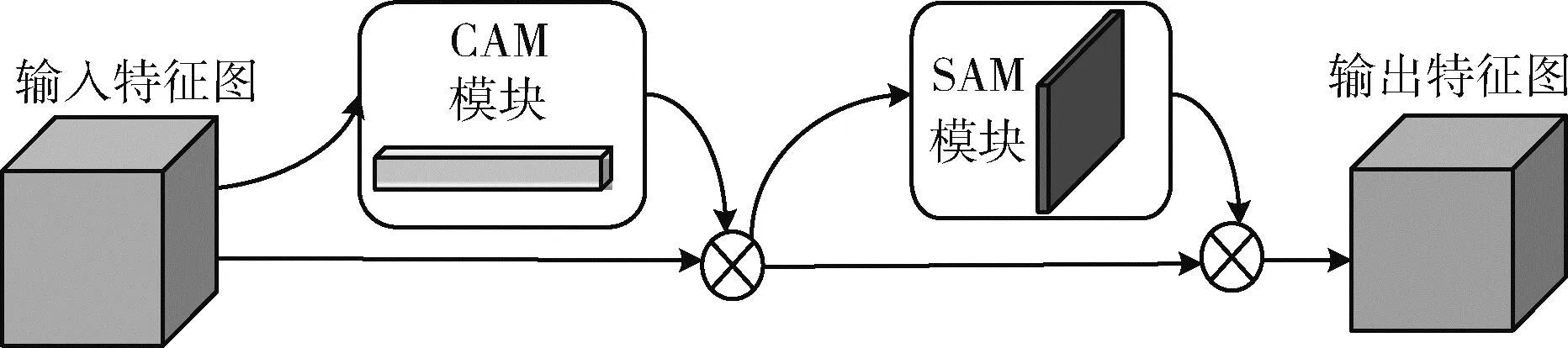
图3 CBAM注意力机制的网络结构
CBAM结构作为一个即插即用的模块,理论上可以插入在每一个输出特征层的后面进行加强处理。而在本研究中,为节省计算资源,使用预训练的权重进行初始化;若在Backbone中添加注意力机制,由于其随机初始化权重,会破坏预训练的初始化权重,减弱Backbone的提取能力。因此本文在YOLOv5s-p2的基础上,在Neck部分的每一个C3模块后添加注意力机制,修改后的模型结构为最终的ST-YOLOv5,网络结构如图4所示。
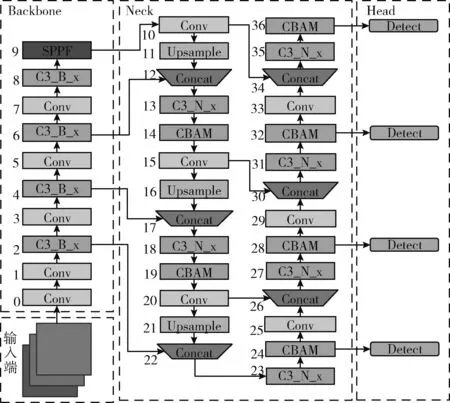
图4 ST-YOLOv5的网络结构
2 实验与结果分析
2.1 实验环境
本文所采用的实验环境见表1。

表1 实验环境配置
在网络训练时,为了节省计算资源,加快模型的收敛速度,使用YOLOv5s在COCO数据集上预训练的权重对模型进行初始化;使用autoanchor机制自动对数据集重新进行锚框聚类;采用SGD优化器,学习率为0.01,动量参数为0.937,BatchSize大小为32,模型迭代200次。
2.2 数据集及预处理
为验证本文改进的算法在小目标检测上的有效性,使用 VisDrone[15]数据集进行验证。VisDrone数据集由天津大学的AISKYEYE团队,使用无人机在中国的14个城市的不同场景和不同天气及光照条件下进行收集,涵盖了大量密集场景下的小目标,标签大小分布如图5所示,横纵坐标的数值代表标签宽高占整张图像的比例。其中,训练集有6471张图像,验证集有548张图像,测试集有1610张图像,最大分辨率不超过2000*1500,共有10个类别。
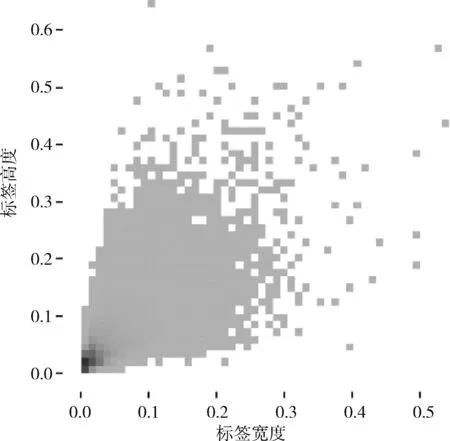
图5 标签大小分布
在YOLOv5s训练时,输入端默认采用Mosaic-4的方式进行数据增强,即在一个BatchSize批次中随机选取4张图片进行随机平移、缩放和裁剪,然后拼接成和原图一样大小的图片。而在本研究中,为了扩充小目标的数量,提高模型的鲁棒性,对Mosic-4数据增强进行改进,选用Masic-9的方式进行数据增强,即在一个BatchSize批次中随机选取9张图像进行随机平移、缩放、裁剪和拼接。通过这种方式进行数据增强,一方面可以扩充原始数据集中小目标的数量,另一方面可以变相的增加BatchSize,减少显存的占用。VisDrone数据集增强后的效果如图6所示。

图6 VisDrone数据集增强后的效果
2.3 评价指标

(7)
(8)
(9)
(10)
其中,Precision为精准率,Recall为召回率,TP为预测正确的样本、FP为预测错误的样本、FN为漏检的样本;AP代表的是以Recall为横坐标,以Precision为纵坐标所围曲线的面积。
2.4 实验结果
2.4.1 损失函数改进的对比实验分析
为了验证改进定位损失函数的有效性,在YOLOv5s的基础上,将算法中原有的CIOU定位损失函数分别替换为本文引入的Focal-EIOU以及GIOU[16]和DIOU两种常用的定位损失函数,其余部分不做修改,修改后的算法分别称为YOLOv5-Focal-EIOU、YOLOv5-GIOU、YOLOv5-DIOU,并在VisDrone数据集上做了以下3组对比实验,实验结果见表2。

表2 不同损失函数的对比实验结果
从表2中可以看出,将原始的CIOU定位损失函数替换为GIOU和DIOU后,mAP@0.5和mAP@0.5:0.95均有所下降,而改进后的EIOU定位损失函数与CIOU相比,在mAP@0.5上增加0.6%,在mAP@0.5:0.95上增加0.7%,因此可以验证Focal-EIOU定位损失函数的有效性。
2.4.2 更换上采样的对比实验分析
为了验证CARAFE上采样算子的有效性,分别在YOLOv5s中引入双线插值上采样、转置卷积上采样,然后与基准模型最近邻插值上采样作对比。在VisDrone数据集上做了以下4组对比实验,实验结果见表3。
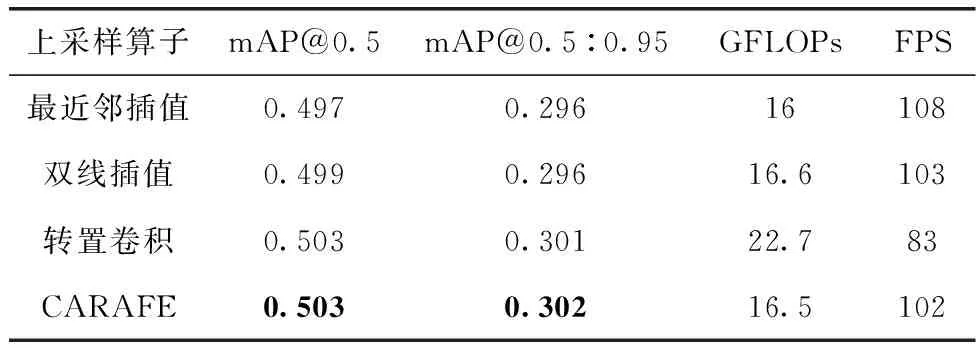
表3 不同上采样算子的对比实验结果
从表3中可以看出,使用双线插值上采样,模型的性能只会得到小幅的提升,虽然使用转置卷积上采样能够提高模型的性能,但也会带来一定的计算量。而使用CARAFE算子上采样,相比于邻近插值上采样在模型上性能有很大的提升,参数量只是小幅增加,且不会影响模型的实时性。因此验证了CARAFE上采样算子的有效性。
2.4.3 消融实验
为了综合验证4种改进方法的有效性,本文在上述两组对比实验的基础上,增加融合不同改进方法之后的消融实验。实验结果见表4,其中√代表了使用的改进策略。
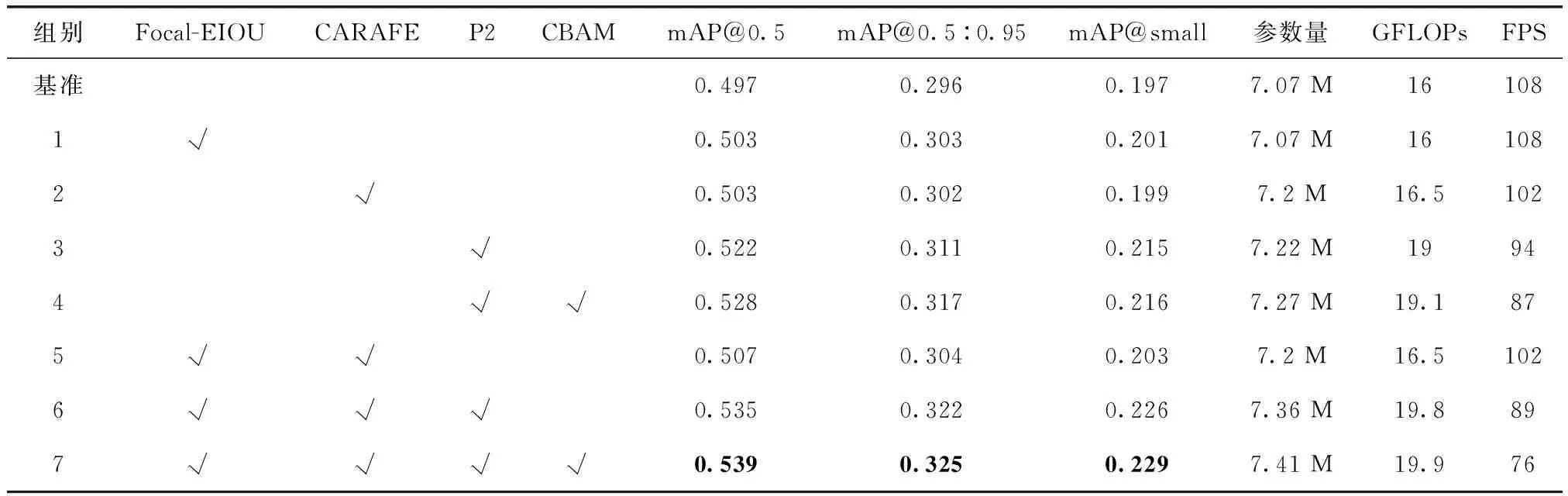
表4 VisDrone数据集上的消融实验结果
2.4.4 对比实验
同时,为了进一步验证本文改进算法的有效性,将本文所改进的算法与当前主流的YOLOv3、YOLOv3-SPP、YOLOv5n、YOLOv5s、YOLOX-s、YOLOv5m目标检测算法在VisDrone数据集上进行对比实验,实验结果见表5。

表5 不同模型之间的对比实验结果
从表5中可以看出,在YOLOv3的基础上引入SPP模块后,模型在小幅增加计算量的情况下,增加了模型的检测精度;但与本文改进的算法相比,参数量和计算量偏大,不利于模型在嵌入式设备上部署。而YOLOv5n虽然具有较快的检测速度,但在精度上有所欠缺,在密集场景下容易产生漏检和误检等问题。最后与检测精度较为相近的YOLOv5m算法相比,本文改进的算法参数量仅是YOLOv5m的35%,计算量仅是YOLOv5m的41%,且速度能达到76 FPS。由此可见,本文所改进的算法,无论是在检测精度上,还是在检测速度上都有一定的优越性。
同时,为了更加直观评价本文改进的算法,在VisDrone数据集中选取不同场景下的3张图像对 YOLOv3算法、YOLOv5s算法和改进后的算法ST-YOLOv5的检测效果进行可视化对比实验,实验结果如图7所示。

图7 不同算法的检测结果对比
从图7中可以看出,在远距离的密集场景下,本文提出的ST-YOLOv5算法,与当前主流的目标检测算法相比,具有更高的检测精度和置信度,解决了当前主流目标检测算法在远距离小目标检测任务中存在的误检和漏检等问题。
3 结束语
本文为解决当前主流目标检测算法对图像中远距离小目标产生的漏检和误检等问题,在YOLOv5s算法的基础上,分别从优化定位损失函数、添加小目标检测层、引入CARAFE上采样算子和添加CBAM注意力机制4个方面对其进行改进。实验结果表明,本文改进后的算法在VisDrone数据集上mAP@0.5和mAP@small分别提高了4.2%、3.2%,且检测速度可以达到76 FPS;与目前主流的目标检测算法相比在精度和速度方面都有一定的优越性,能够很好地应用于不同场景下的小目标检测任务中。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
数学物理学报(2021年2期)2021-06-09 08:54:26
应用数学(2020年2期)2020-06-24 06:02:44
西南石油大学学报(自然科学版)(2019年1期)2019-01-28 09:33:52
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:54
今日农业(2019年15期)2019-01-03 12:11:33
数学物理学报(2016年3期)2016-12-01 05:36:27
电测与仪表(2016年10期)2016-04-12 00:26:24
电测与仪表(2016年14期)2016-04-11 12:32:48
