
大数据背景下基于机器学习的公司财务风险识别研究初探
2024-04-20 05:53:10李仕瑾
审计与理财 2024年3期
李仕瑾
【摘要】传统的财务风险识别主要依赖对财务报表的分析和判断,但财务报表可能存在伪装、欺诈等问题,这将导致分析结果存在偏差。本文基于机器学习算法,构建了以企业财务评价指标和非财务评价指标为维度的财务风险识别体系,并对这两个维度所采用的预测模型进行了初步分析。
【关键词】大数据背景;机器学习;财务风险识别
【基金项目】江西省教育厅科学技术研究项目“大数据背景下基于机器学习的企业财务风险识别研究”(GJJ2205225);江西省高等学校教学改革研究重点课题“基于CDIO理念的大数据与会计专业课程体系优化与实践”(JXJG-22-53-2);江西省教育科学“十四五”规划年度课题“岗课赛证融通背景下高职商科专业教学质量学生满意度实证研究”(22GZQN62);江西交通职业技术学院教改课题“基于CDIO理念的“一异二型三化”会计专业课程教学体系改革研究(2022JG16)”。
一、引言
2015年,国务院印发了《促进大数据发展行动纲要》,明确了大数据的主要特征。同年,党的十八届中央委员会第五次全体会议将大数据战略上升至国家战略层面,提出了要实施“国家大数据战略”。2021年,工业和信息化部在《“十四五”大数据产业发展规划》中明确了新的历史时期大数据及大数据相关产业的发展目标。目前,大数据及大数据技术已广泛的应用到行业的方方面面,助力经济社会发展。
随着经济全球化发展及我国经济体制改革的深入,企业需要面临更加复杂的市场环境。当前,中美贸易摩擦、汇率变动、物价变化等市场外部环境越来越复杂,这给企业的经营增加了许多不可控因素。如果企业的外部市场或政策出现异常变动,企业的内部投资和融资决策出现问题,将会导致企业出现财务风险。上市公司作为市场经济的重要组成部分,其财务状况和风险对投资者、股东、经理人员和其他利益相关者都密切相关。
传统的财务风险识别主要依赖对财务报表的分析和判断。但财务报表可能存在伪装、欺诈等问题,这将导致分析结果存在偏差。因此,基于数据挖掘技术对上市公司的各类数据进行分析,在海量的财务数据中发现潜在的风险因素,提前预测财务分险,对上市公司、投资者、股东及证券监管部门均具有重要意义。
二、国内外研究现状
國外关于财务风险的研究始于上世纪30年代,到目前已有90多年的历史。纵观相关学者的研究成果,主要聚焦在了财务风险预警模型上。经文献梳理,研究成果从最初的单一变量预警模型发展到多变量风险预警模型,基于人工智能的预警方法也在不断完善与发展。Fiztpatrick(1932)提出了最早的单元风险预警模型,选取了债务保障率、资产收益率、资产负债率、资金安全率、安全边际率等单一财务变量作为预警变量;Altman(1968)突破单一变量风险识别方法的局限,首次提出了Z-Score多元判别分析模型;Martin(1977)打破财务指标数据必须服从正态分布的假设,首次引入了多元逻辑(Logit)回归模型;Odom等(1990),首次将神经网络理论应用于财务风险预警研究。进入21世纪以后,随着计算机技术术的发展,财务风险预警模型的构建也在不断创新。VanGestel(2003)建立了LS-SVM模型识别财务危机;Zieba等(2016)将梯度提升决策树应用于破产预测;Halteh&Kumar等(2018)将决策树、随机梯度增强和随机森林应用于101家伊斯兰上市银行组成的数据集的金融困境预测。
相较于国外,国内关于财务风险预警的研究起步较晚。吴世农等(1986)最早开始国内的财务风险预警研究;陈静(1999)通过27家被ST和正常公司的财务数据开展了单变量分析和多元判定,开创了我国学者对上市公司进行财务风险识别预警的先河;关欣等(2016)将逻辑回归模型及BP神经网络模型应于财务预警模的实证分析;王玉冬等(2018)采用粒子群算法进行了改进,建立PSO-BP和FOA-BP神经网络模型;杨贵军等(2022)利用Benford律和Myer指数,构造了BM-BP神经网络财务风险预警模型。
结合国内外的研究现状,关于财务风险预警,经历了简单的单元预警模型、多元判别模型、逻辑回归模型向复杂的神经网络模型、支持向量机模型和其他混合模型发展历程,相关文献的研究结果证明了机器学习算法在财务风险预警领域的适切性。
三、传统的财务风险识别指标体系
早期的研究中,受数据获取渠道及计算机技术等方面的条件制约,难于获取海量的公司财务数据,也难以实现对大规模数据的分析处理。因此,在传统的财务风险识别过程,一般选取与企业财务信息相关的盈利能力、偿债能力、营运能力和发展能力等方面的指标进行模型构建,采用的模型主要有逻辑回归模型、BP神经网络模型、粒子群算法改进的神经网络模型等。从目前的发展状况来看,包含传统财务指标体系的账务风险识别模型的构建已相对完善。
四、大数据背景下财务风险识别指标体系构建
随着云存储、区块链、计算机等技术的飞速发展,海量数据的存储、管理和应用变成了可能。大数据及大数据处理相关技术的应用,拓宽了投资者获取企业财务信息渠道,也使快速、准确地收集、整理和分析财务数据成为了可能。云计算、大型计算机服务器的算力指数级增加,这使得对大规模数据的分析与处理成为了可能。
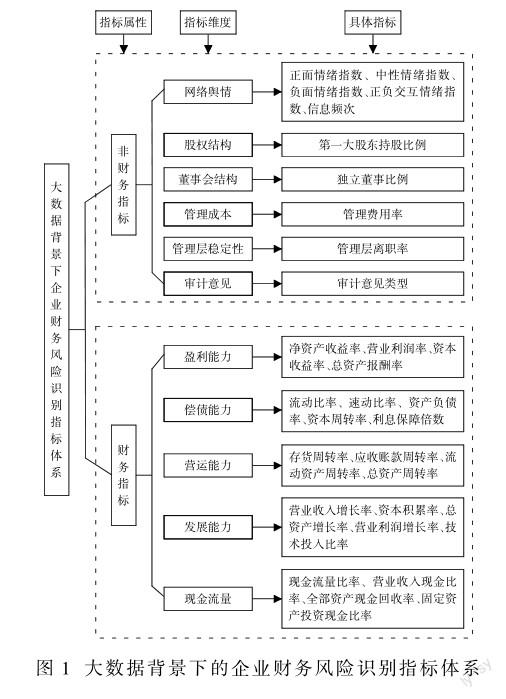
企业的财务风险与企业的财务评价指标和非财务评价指标相关。传统的财务风险识别只考虑企业的财务评价指标,但对上市公司而言,社会网络舆情数据、股权结构、董事会结构、管理成本、审计意见等非财务评价指标也与企业的正常经营息息相关。非财务评价指标一般为文本型数据,具有难于量化的特点,而机器学习算法对文本、图像都具有强大的处理能力。因此,应用机器学习算法,结合企业的非财务指标对风险识别模型进行改进,可以取得更好的风险识别效果。有鉴于此,笔者对传统的财务风险识别模型进行改进,采用财务评价指标和非财务指标两个维度构建大数据背景下的财务风险识别模型。具体构建中,财务评价指标主要选取盈利能力、偿债能力、营运能力、发展能力、现金流量等几个代表参数;非财务评价指标主要选取社会网络舆情数据、股权结构、董事会结构、管理成本、管理层稳定性、审计意见等参数。按照指标属性、指标维度及具体的指标选取值,模型结构如图1所示。
五、财务评价指标及非财务评价预测模型选择
大数据背景下财务风险识别指标体系由企业的财务评价指标和非财务评价指标两部分组成。在风险模型构建时,财务评价指标采用的是财务报表中以数值形式出现的反应盈利能力、偿债能力、营运能力、发展能力及现金流量数据;非财务评价指标采用的是反映企业的股权结构、董事会结构、客理成本、管理层稳定性、审计意见及与企业相关的网络舆情数据,这类数据在企业年报中,经常以文本的形式出现。针对以上两种不同的数据类开型,在模型构建的过程中,需要采用不能的预测模型进行数据处理。
决策树模型、随机森林模型、梯度提升决策树模型等以树模型为基础的预测模型对数值型数据具有强大的处理能力,可以很好的解决分类和回归问题。因此,在财务风险的预测过程中,对于公司财务报表中的数值型数据,可以采用决策树模型进行预测。利用对照组和实验组数据,结合Bagging以及Boosting提升算法,可以模擬现实中人类决策行为,通过优化决策树,相当于提高了财务分析人员的决策能力,使模型对公司是否存在风险的判读更加科学、准确。
机器学习中的卷积神经网络和循环神经网络可以很好的处理文本型数据。因此在财务风险预测过程中,对于非财务评价指标等文本型数据,采用神经网络中的词袋(Bag of Words)模型进行,通过对非财务评价指标的分析,对比正常公司的年报文本和存在财务风险公司的年报文本,深度挖掘文本型数据下隐藏的规律,进而判断公司是否面临财务风险。
六、结束语
结合数值型数据,可以构建以财务报表为基础,决策树为主要算法的风险预测模型;结合文本型数据,可以构建以上市公司年度报告文本为基础,深度神经网络为算法的风险预测模型。综合上市公司的财务报表数据及年报文本数据,将两种模型进行集成学习,便可以获得一个同时接收财务报表数据和文本数据的财务风险预测模型。
········参考文献·····················
[1]王贺敏,刘明玮.大数据在财务风险识别与管控中的应用探析[J].中国注册会计师,2022,(10):107-112.
[2]吴世农,黄世忠.企业破产的分析指标和预测模型[J].中国经济问题,1987.6(6):20-28.
[3]陈静.上市公司财务恶化预测的实证分析[J].会计研究,1999,4(9):31-38.
[4]关欣,王征.基于Logistic回归模型和BP神经网络的财务预警模型比较[J].统计与决策,2016,17(49):179-181.
[5]杨贵军,杜飞,贾晓磊.基于首末位质量因子的BP神经网络财务风险预警模型[J].统计与决策,2022,38(3):166-171.
(作者单位:江西交通职业技术学院运输管理学院)
猜你喜欢
电脑知识与技术(2016年33期)2017-03-21 20:54:17
财会学习(2017年4期)2017-03-15 17:13:29
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
商场现代化(2016年29期)2016-12-23 23:42:48
科技创新与应用(2016年31期)2016-12-03 03:33:48
智富时代(2016年12期)2016-12-01 17:03:10
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
现代经济信息(2016年19期)2016-10-20 16:11:45
科学与财富(2016年28期)2016-10-14 21:19:17
