
基于深度神经网络的数字电网边缘侧数据迁移
2024-04-19 13:56祝健杨辛明勇代奇迹
电子设计工程 2024年8期
祝健杨,辛明勇,代奇迹
(贵州电网有限责任公司电力科学研究院,贵州贵阳 550002)
深度神经网络[1]是机器学习领域中的关键技术,可以用较少的参数来表示复杂函数,由于训练样本能够充分覆盖未来样本集合,所以训练过程中不会陷入局部最优。与其他类型的网络模型相比,深度神经网络既可以实现对数据样本的分类存储,也可以在转化数据样本的同时,提高网络的存储能力,一方面解决了数据样本过量累积的问题[2],另一方面也可以大幅提升信息参量的传输速率,避免数据库主机出现过负载运行的情况[3]。
数字电网是一种数字化电网应用平台,可以对传统电网进行数字化处理,从而拉近了局域电网模型与广域电网模型之间的数字孪生关系。在实际应用过程中,随着数据传输量的增大,数字电网边缘侧会出现明显的数据样本过量累积现象,这不但会增大电网主机的运行压力,还会造成电网边缘侧数据迁移时间的大幅延长。为了避免上述情况的发生,基于容器技术的处理机制按照优先级原则,对数字电网边缘侧数据进行筛选,又借助云边协同平台,完成对信息参量的调度与迁移处理[4]。然而此方法的应用存在一定的局限性,并不能将电网边缘侧数据迁移时长控制在既定数值标准之内。为解决上述问题,引入深度神经网络模型,设计一种新型数字电网边缘侧数据迁移方法。
1 电网边缘侧数据整合
1.1 深度神经网络
深度神经网络负责将待迁移电网边缘侧数据从混合信息样本中提取出来,为后续的数据迁移奠定基础,该网络由输入层节点、隐含层节点、输出层节点三部分组成。其中,输入层节点直接与电网边缘侧混合信息样本接触,与其他类型的应用节点相比,输入层节点只负责数据参量的录入,不具备辨别信息成分的能力;隐含层节点与输入层节点对接,负责辨别已输入混合样本的成分,由于每一类数据样本都包含大量的待识别信息,所以隐含层节点数量相对较多;输出层节点与隐含层节点对接,能够根据数据样本成分辨别结果,更改待迁移信息参量的编码形式,从而使得边缘侧数据输出结果能够满足数字电网主机的实际应用需求[5-6]。深度神经网络布局形式如图1 所示。
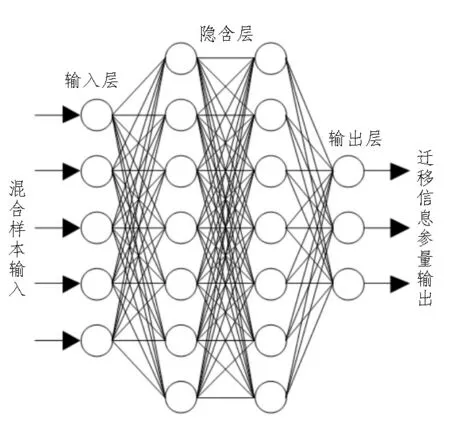
图1 深度神经网络布局形式
为避免数据回流行为的出现,深度神经网络的构建必须满足单一性传输原则。
1.2 样本容错系数
样本容错系数可以用来衡量数字电网主机对边缘侧数据样本的承载能力,由于深度神经网络始终保持完全开放的状态,所以样本容错系数越大,表示数字电网主机对边缘侧数据样本的承载能力越强[7-8]。假设c˙表示电网边缘侧数据样本的存储特征,其求解表达式为:
式中,x表示常规存储系数,α表示方向性特征。假设δ表示数据容错指征的最小取值,χ表示容错指征的最大取值,cδ表示电网边缘侧数据特征最小值,cχ表示基于电网边缘侧数据特征最大值,Δc表示待迁移电网边缘侧数据的单位累积量,联立上述物理量,可将样本容错系数求解结果表示为:
由于深度神经网络对于电网边缘侧数据样本的承载能力有限,所以容错系数指标取值不可能无限增大。
1.3 资源分配权限
资源分配权限约束了数字电网环境中边缘侧数据样本与待迁移数据参量之间的数值映射关系,随着数字电网主机对于数据样本承载能力的不断增强,资源分配权限表达式的取值也在不断增大[9-10]。在样本容错系数保持为定值的情况下,资源分配权限表达式的构建受到边缘侧数据迁移特征的直接影响。假设边缘侧数据迁移特征最大值vmax、最小值vmin会对资源分配权限的取值标准产生一定影响,在深度神经网络模型的作用下,二者之间的差值越大,边缘侧数据样本的单位迁移量也就越大。假设vˉ表示边缘侧数据迁移特征的平均值,β表示数字电网环境中的数据样本匹配系数,联立式(2),可将资源分配权限表达式定义为:
实施数字电网边缘侧数据迁移时,深度神经网络对于数据样本的承载能力不可能为零,所以系数vmax、系数vmin、系数vˉ的取值都不可能等于零。
2 数字电网边缘侧数据迁移算法
2.1 FIFO调度器
FIFO 调度器是一个完整的数据调度闭环结构,能够将数字电网环境中的传输数据转化成边缘侧数据样本[11-12],并可以借助深度神经网络模型,将这些数据参量转存至迁移信息寄存结构之中。FIFO 主机作为调度器闭环的核心应用设备,可以控制数据追踪器与电网调度设备之间的实时连接关系,在深度神经网络模型的作用下,边缘侧数据输入量越大,FIFO 主机对于数据追踪器元件的控制能力也就越强地影响原则。完整的FIFO 调度器闭环结构如图2所示。
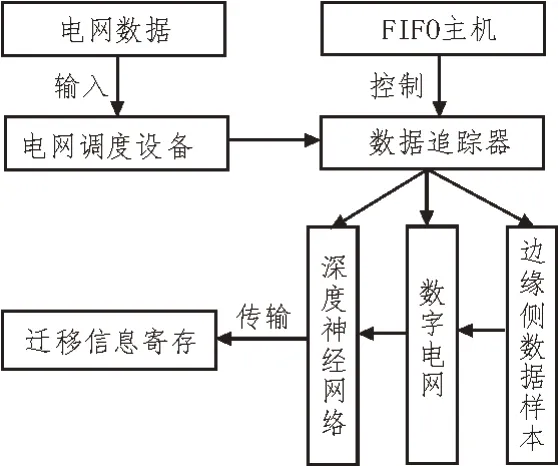
图2 FIFO调度器闭环结构
数据追踪器元件同时控制深度神经网络与数字电网体系的布局形式,可以更改边缘侧信息样本的存储状态,从而使其能够更好适应迁移信息寄存结构对于数据参量的存储需求。
2.2 数据流获取
数据流获取是实现数字电网边缘侧数据迁移的关键处理环节,能够更改电网信息样本在深度神经网络模型中的存储形式,最大程度降低电网边缘侧数据的迁移时长。假设ε、γ表示两个随机选取的电网边缘侧数据样本标记系数,其取值条件满足公式(4):
在式(4)的基础上,设mε表示与系数ε匹配的电网边缘侧数据查询特征[11-12],mγ表示与系数γ匹配的电网边缘侧数据查询特征,φ表示数据迁移标准值,φ表示数据样本度量值[13-14]。在上述物理量的支持下,联立式(3)、式(4),可将数据流获取表达式定义为:
为了有效控制电网边缘侧数据迁移时长,mε、系数mγ的取值必须同时属于数值区间[1,e)。
2.3 HBase迁移参量
HBase 迁移参量也称HBase 促传参量,在数字电网环境中,该指标决定了边缘侧数据样本的传输能力,对于数字化电网主机而言,在处理数据流信息参量时,HBase 迁移参量值的求解受到深度神经网络模型的直接影响[15-16]。假设fa表示第a次查询到的数字电网边缘侧数据样本中的信息参量,且f≠0 的不等式条件恒成立,F(fa)表示数据样本取值函数,λ表示电网边缘侧数据样本迁移指征,a表示电网边缘侧数据样本的查询次数,ΔS表示深度神经网络中数字电网边缘侧数据样本的单位迁移量,η表示边缘侧数据在数字电网环境中的传输利用率,联立上述物理量,可将HBase 迁移参量求解结果表示为:
至此,完成对各项指标参量的计算与处理,在深度神经网络模型的支持下,实现数字电网边缘侧数据迁移方法的设计。
3 实验设计
3.1 实验环境搭建
该次实验的检测环境为图3 所示数字电网环境,调节集线器元件已接入部分的阻值水平,使数字电网环境环境中的负载电压保持相对稳定的数值状态。
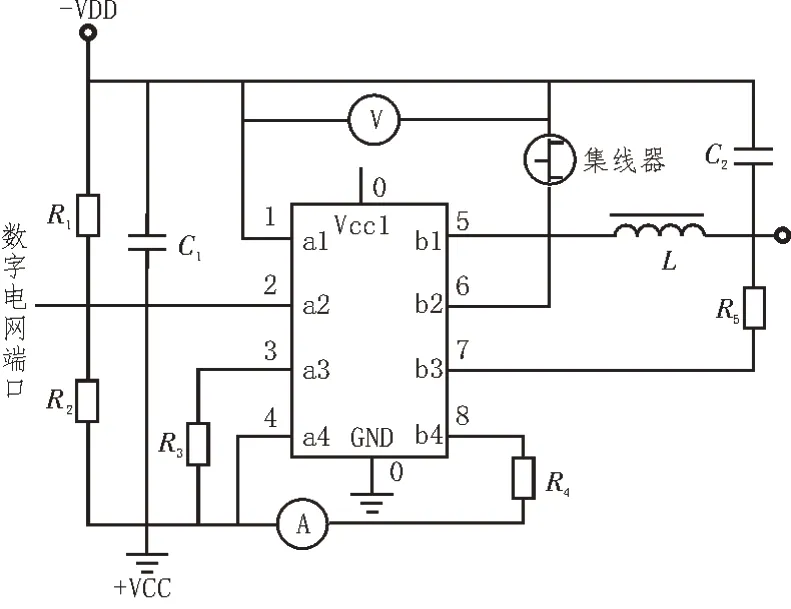
图3 数字电网实验环境
数字电网的具体运行环境如表1 所示。

表1 数字电网运行环境
实验过程中,利用基于深度神经网络的数字电网边缘侧数据迁移方法控制Hive 0.8.1 数字主机,将所得数据作为实验组变量;然后利用基于容器技术的处理机制控制Hive 0.8.1 数字主机,将所得数据作为对照组变量;最后对比实验组、对照组实验数据,总结实验结果,得出实验规律。
3.2 结果分析
迁移时长影响边缘侧数据样本在数字电网环境中的传输速率,在不考虑其他干扰条件的情况下,迁移时间越长,边缘侧数据样本在数字电网环境中的传输速率就越慢,此情况下数据样本极易在数字电网环境中出现过量累积的现象;反之,若迁移时间相对较短,则表示边缘侧数据样本在数字电网环境中的传输速率较快,数据样本也就不会出现明显累积的表现情况[17]。
图4 反映了随着电网信息样本总量增大,边缘侧数据迁移时间的数值变化情况。

图4 边缘侧数据迁移时间
在顺序传输情况下,实验组电网边缘侧数据迁移时间呈现出持续增大的趋势,平均迁移时长为23.1 s;对照组电网边缘侧数据迁移时间也呈现出持续增大的趋势,平均迁移时长为30.6 s,与实验组平均数值相比,增大了7.5 s。
在逆序传输情况下,实验组电网边缘侧数据迁移时间呈现出先不断增大、再来回波动的趋势,平均迁移时长为44.5 s;对照组电网边缘侧数据迁移时间依然保持不断增大的趋势,平均迁移时长为68.9 s,与实验组平均数值相比,增大了24.4 s。
综上可知该次实验结论为:
1)在数字电网环境中,边缘侧数据逆序传输比顺序传输所需的平均迁移时间更长;
2)基于容器技术的处理机制在控制边缘侧数据迁移时间方面的能力相对较差,故而该方法不符合提升电网边缘侧数据传输速率的应用需求;
3)基于深度神经网络的数字电网边缘侧数据迁移方法能够有效控制边缘侧数据的迁移时长,达到了提升数据迁移效率的目标,有效解决了数据样本过量累积问题,实际应用效果较好。
4 结束语
数字电网边缘侧数据迁移方法按照深度神经网络模型的构建标准,求解样本容错系数的实际取值条件,又通过判断资源分配权限的方式,完成对数据流参量的处理,在FIFO 调度器闭环结构的支持下,控制HBase 迁移参量数值水平,保证了数字电网边缘侧数据迁移质量与效率。该方法不但解决了数字电网环境中出现的数据样本过量累积问题,还可以有效压缩电网边缘侧数据的迁移时长,符合实际应用需求。
猜你喜欢
电子制作(2019年19期)2019-11-23
通信产业报(2016年44期)2017-03-13
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
物理实验(2015年9期)2015-02-28
海军航空大学学报(2015年4期)2015-02-27
数学年刊A辑(中文版)(2014年4期)2014-10-30
声学技术(2014年2期)2014-06-21
物理与工程(2011年1期)2011-03-25
雕塑(1999年2期)1999-06-28
