
基于卷积神经网络的医疗护理实体关系抽取
2024-04-19 13:56曹茂俊胡喆
电子设计工程 2024年8期
曹茂俊,胡喆
(东北石油大学计算机与信息技术学院,黑龙江大庆 163000)
医疗护理学的形成与发展和人类文明及健康需要密切相关,在不同的历史发展时期,护理学都在不断发展以适应当时社会对护理实践的需求,有望带来更高效精准的医疗服务。实体关系抽取问题是知识抽取中的一个经典问题,其目的是能够准确地挖掘相关领域的实体与实体之间的关系[1]。
基于医疗文本的特点,该文提出基于卷积神经网络(Convolutional Neural Network,CNN)的实体关系抽取模型,模型中应用弱监督学习来进行实体关系标注,并运用Softmax 回归对语句文本进行分类处理,将所提取的文本特征向量矩阵化,同时将得到的向量输入到卷积神经网络中,最终抽取到更为精确的医疗护理学实体关系[2]。
因此,采用卷积神经网络模型对医疗语料文本进行实体关系抽取,并采用分段最大池化策略,能够明显地降低一般最大池化策略对于信息缺失的影响[3]。
1 基于卷积神经网络的实体关系抽取模型
CNN 相比于其他模型来说,具有训练速度快、局部特征提取效率高、权值共享的同时还不易发生过拟合的问题等优势。因此该文选用卷积神经网络模型进行实体关系抽取任务,将文本“她去妇科确诊了慢性的乳腺炎”作为实例,提出的卷积神经网络实体关系抽取模型架构如图1 所示。

图1 CNN实体关系抽取模型
该模型实际上代表输入至输出之间的一种映射,应用一个含有实体对的相对全面的文本作为输入,最终输出一个与所有关系类型相对应的概率向量。首先对现有的文本进行文本预处理,特征层主要是对文本进行标记工作,嵌入层使用Word2vec 对于词序列进行向量化[4]。最大池向量使用卷积核来获取全局特征。并将采集得到的特征输送到全连接前馈神经网络中完成推理。在输出层,使用Softmax分类器,得到输出数等于实体之间存在的关系数,最终获得实体关系的抽取结果。
1.1 文本预处理
文本预处理过程包括文本分句、去重、分词和文本标注。①文本分句: 关系的抽取主要是对文本进行分解抽取,通过将句号当成分隔符,以此对文本进行分句。②去重: 删除重复句子和只出现单个实体的句子,文本选用卷积神经网络模型进行实体关系抽取任务,CNN 实体关系抽取模型如图1 所示。首先,对输入文本进行预处理,其次,在词嵌入层使用Word2vec 对词序列进行向量化,将得到的向量送入CNN 模型,最终,对模型的输出进行池化和分类,得到关系抽取结果[5]。③分词:该文将Python 中的jieba库作为分词的工具,以此对文本进行分词操作。④数据标注:实验数据集是结合收集数据的特点,应用参考文献的部分关系名称对数据进行手工标注,总结归纳了以下10 种关系,其中,关系类型和相关术语如表1 所示。
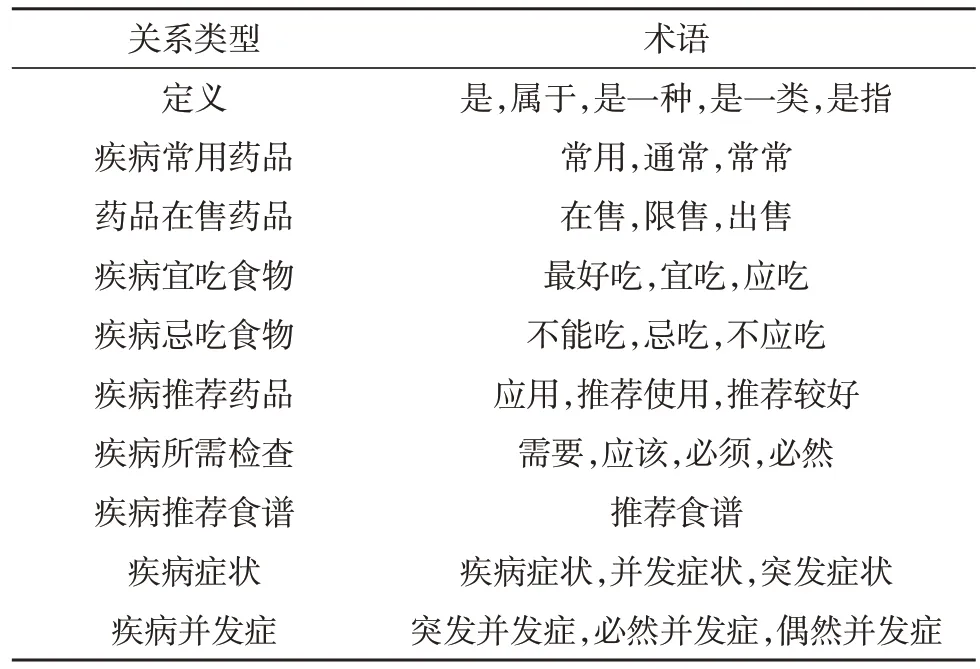
表1 关系类型与术语
最终,经过数据标注操作之后的部分数据样例如表2 所示。其中,<e1>被放在实体1的后面,<e2>被放在实体2 的后面。

表2 数据样例
1.2 特征层
该文将文本之间的所有词使用5 个相对分散的特征进行表示,如下所示。
1)W:指代文本中所出现的词语,图1 中的模型中用v1-v8 来代表文本中的词;
2)P1:当前词和第一个实体的间隔,如图1 中所出现的第一个实体“妇科”,“慢性”一词与“妇科”之间的间距为3,“去”同“妇科”之间的间距为-1。
3)P2:现有当前的词同相邻第二个实体之间的间距,与P1 的计算方法相似。
4)N:词性的标签,如上述文本分词所示,该文对文本语句进行分词并且对词性进行标注。选取jieba分词进行功能标注。
5)T:指代实体的类型,将处理后的句子进行实体类型标注,因为医疗文本语料常常涉及医疗事件、医疗药物处理等,该文所采用命名实体识别标注法,即用BMEO 进行标注。B 指代实体词的开头部分,M指代实体词的中间词部分,E 指代实体词的词尾部分,O 则指代与实体词有关的词。
1.3 词嵌入层
词嵌入层利用查找表把所有的特征转变为嵌入向量,并将其串联在一起。将语料文本中每个词以及实体e1、e2 之间的距离依次代表p1 和p2 维向量,获得语料文本所对应的位置向量的矩阵。同传统的文本词向量化表示方法相比,词嵌入技术能够更全面地获取文本特征。
实验采用Google公司于2013年所开源的Word2vec工具,其能够通过卷积神经网络训练语料文本,并将文本中的词语转化为k维的向量进行运算[6]。Word2vec 工具面向词向量的训练共包含两种模型,分别是CBOW 模型以及Skip-gram 模型。其中Skipgram 模型主要基于现有的词语文本对上下文出现词的概率进行推理预测,如现有一个词w(t),对其进行上下文的概率推测,模型的结构示意图如图2 所示,Skip-gram 模型共含有输入层、映射层以及输出层三层神经网络结构模型,最大化的目标函数如式(1)所示:
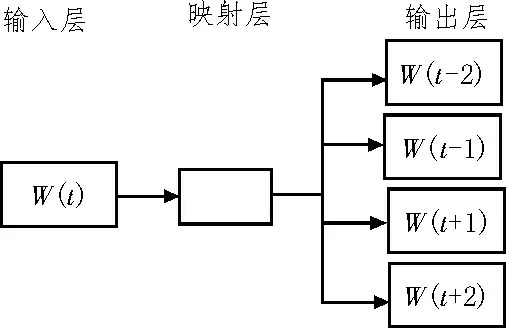
图2 Skip-gram模型
式中,w1,w2,w3,…,wt表示文本中的一组词语的排列顺序,该文窗口大小选的是5,词向量维度数为100。
1.4 卷积层
卷积层作为卷积神经网络的核心,其本质上为特征抽取层,能够将所输入的医疗语料文本通过卷积核进行卷积操作,从而抽取语料文本中的部分特征[7]。
卷积层主要由滤波器来完成操作,再实验过程中,滤波器的数量通常和所提取特征的数量成正比。当面对不同位置的输入数据时,滤波器通常使用“滑动窗口”的方法来取得数据的特征,最终变为一个特征集合。同时,当前层取得的特征会作为下一层的输入数据进行抽取,输入文本的特征向量序列为x1,x2,x3…,xm,在该序列中,xi∈Rd代表第i个词含有的特征向量,xi;i+j则代表xi-xi+j的特征相互连接[8]。假设存在权重向量参数化类型的卷积核,权重向量应由w∈Rcd所指代;c指代卷积核的长度值,因而卷积层的输出序列为hi=f(w·xi;i+c-l+b),其中,i=1,2,…m-c+1,操作“·”代表点乘,f为线性的整流函数,b∈R为偏倚项,w和b均为学习参数,并且对于所有的i=1,2,…,m-c+1 参数值均保持不变。
1.5 池化和分类
卷积神经网络的池化阶段能够获得整个卷积进程中的重要特征,池化层的效用即为将获取的特征进行过滤,清除前一层输出中的噪音,并且通过降低卷积节点数量使得训练参数的数量减小,相应的去除模型过拟合的问题[9]。
该文应用最大池层获取长度相对固定语料文本的全局特征,目的是要保存文本语料中有价值的信息,即仅考虑所有语料中相对来说最具有价值的特征。池化处理对于提升卷积神经网络的训练结果和效率起到促进作用,并且在不缺失主要特征的前提下能够减小输出结果的维度,能够减小整体模型的计算量[10],卷积层最终的输出长度(m-c+1)取决于文本中m的个数,如式(2)所示:
依据上所述过程,表达了如何利用单个过滤器从整个文本中提取一个特征。依据图1 可知,实验所利用长度为3 和4 的过滤器(卷积核)全面地提取了4 个特征。为了判断过滤器长度对提取效果的影响,对不同长度过滤器进行实验比较,同时也可以判断上下文在不同的窗口大小时周围的词。卷积神经网络的池化层基于大小不同的滤波器获得较为重要的特征,同时把获取到的特征传递给输出层,最后输出层应用Softmax 函数对池化层得到的特征进行分类,如式(3)所示:
式中,wy和by是分类函数的权重和偏置。
2 实验与分析
2.1 实验预料获取及标注
基于医疗领域的关系抽取研究较少,这是在护理学关系抽取任务中的一个难点。因此,该文根据专业医生所提供的数据作为语料来源,构建医疗护理学领域的语料数据库。通过1.1 节的预处理和数据标注工作,筛选出包含实体对和它们之间关系的句子,作为实验语料。实验主要针对于医疗护理领域的相关数据,如表3 所示。

表3 医疗护理邻域相关数据
实验共收集了294 149 条数据,包括疾病诊断项目、医疗科目、疾病名称以及药品名称等。应用词频统计的策略,将所获取的数据进行剖释处理,了解所收集到的医疗语料知识,并且依据预料文本进行汇总,共定义了10 种实体关系类型。
数据标注部分主要依靠自己开发设计的医疗语料的标注系统,将语料的格式进行确认后直接进行标注工作。在预料标注系统中,只需要选择与要标注的实体以及上述的各种关系即可完成对实体和彼此的关系标注,使用该系统可以降低繁琐的人为操作,同时提高了准确率,最终完成基于该系统的半自动化标注[11]。文本标注的结果如例1 所示,将被标注的部分结果进行了人工的校对,能够获得最终的实验数据。
例1:<e1>乳腺增生</e1>疾病检查<e2>妇科</e2>。
其中,“乳腺增生”被标注为实体1,“妇科”被标注为实体2。两者之间的关系为“疾病检查”。
2.2 实验参数设计
在该实验期间,共用到了如下评价指标:准确率P、召回率R和F1 值,所应用到的公式如式(4)-(6)所示:
式中,V表示正确识别的实体关系个数;V1表示总的识别实体关系数;V2表示总的实体关系个数。该实验中,共获取并标注的数据为294 149 条,每次实验都会随机选择10 000 条数据成为训练数据,并进行3 次实验,最终将3 次实验的平均数作为该实验的结果。
2.3 结果与分析
该文通过单个滤波器和组合滤波器对评价指标的影响进行实验,实验结果显示了不同长度的滤波器对准确率、召回率以及F1值的影响效果,如表4所示。
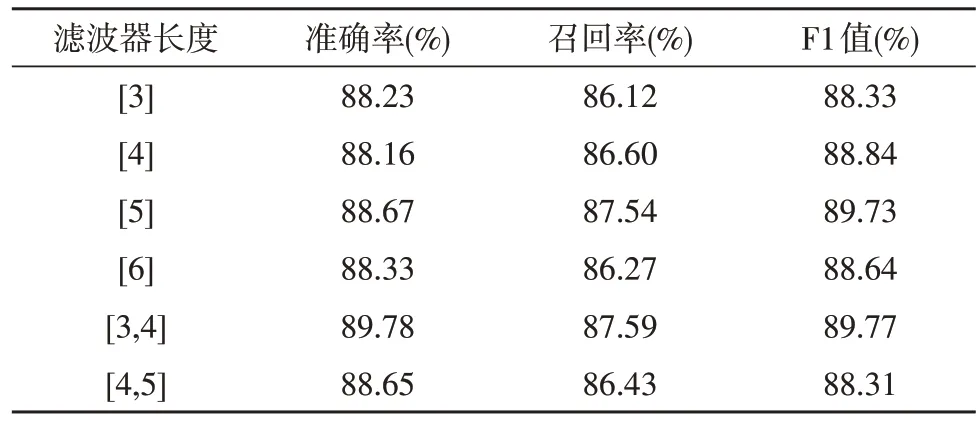
表4 滤波器对训练模型的影响效果
如表4 所示,在实验过程中,当滤波器(卷积核)长度为3 时,其准确率、召回率以及F1 值均小于滤波器(卷积核)长度为4 以及滤波器长度为5 时的数值,因此,相应地填充单个滤波器的长度,能够相对明显地提高该实验评价指标的百分比[12]。但是当滤波器长度大于5 时,实验的测量数值明显呈现下降趋势。对组合滤波器进行实验时,可以发现[3,4]组合滤波器的评价数值相对单个滤波器的较大值有所提升。因此,由表4 的实验结果可知,3 和4 两个滤波器整合的实验效果可以达到最优,F1 值为89.77%。该文所标注的数据共294 149 条,命名的实体关系对共10 种,在此过程中,相较其他的标注来说“疾病-推荐药品”类中所标注语料最多,为59 467 条[13]。
关系抽取模型对比结果如图3 所示,能够得出该文方法与基于LSTM 和Bi-LSTM 的方法相比较,其准确率P、召回率R包括F1 值都存在相对明显的提高,其中,相对于LSTM,准确率P,召回率R、F1 值指标提升较为明显[14]。对比实验表明,该文所使用的方法能够更好地应用于医疗数据的领域关系抽取。
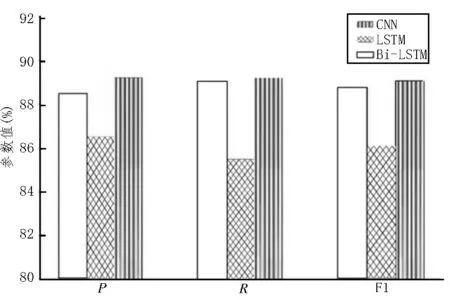
图3 关系抽取模型对比结果
3 结束语
该文研究了基于卷积神经网络在医疗护理领域的实体关系抽取情况。从医疗护理领域出发,从近30 万条数据中抽取了10 种实体-关系对,并基于此构建关系语料库[15]。最终,在池化层部分,采用了分段最大池化的策略,有效地降低了部分关键医疗实体特征的损耗。同时,该文基于LSTM 以及Bi-LSTM的方法同CNN 模型进行对比,最终得出该文所采用的卷积神经网络方法模型可以极大地增强医疗护理学实体关系抽取的成果,具有更好的性能[16]。
猜你喜欢
中国外汇(2019年18期)2019-11-25
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
海外华文教育(2016年1期)2017-01-20
系统工程与电子技术(2016年7期)2016-08-21
火控雷达技术(2016年2期)2016-02-06
当代教育理论与实践(2015年9期)2015-12-16
