
融合时间因素的隐语义模型推荐算法
2024-04-19 13:56马震
电子设计工程 2024年8期
马震
(西安邮电大学现代邮政学院,陕西西安 710061)
随着电商系统和互联网技术的发展,网络中的信息量爆炸式增长,出现所谓的信息迷航、信息过载现象[1-2]。面对网络中海量、多源、异构的用户行为数据,推荐算法效率是影响推荐性能提高的瓶颈之一[3],其中的数据稀疏问题是最亟需解决的难题[4]。
为了解决数据稀疏问题,文献[5-7]通过聚类算法从稀疏评分矩阵中提取密集评分模块进行协同过滤。文献[8-9]在用户相似度计算的过程中结合项目类型标签来解决因数据稀疏而无法计算相似度的问题。矩阵分解算法由于在解决数据稀疏问题上的高性能而被许多学者应用于推荐系统中。文献[10-12]通过协同过滤与矩阵分解算法的结合,以减小数据稀疏对于推荐性能的影响。
基于前人的研究,针对数据稀疏以及推荐性能较低的问题,提出一种融合时间因素的隐语义模型推荐算法,该算法考虑时间推移带给用户喜好的变化,通过协同过滤算法与隐语义模型的结合提高推荐算法的准确性与各项性能。
1 相关工作
随着研究的不断深入,许多学者发现传统推荐算法只利用了用户对项目的评分数据,忽略了许多可利用的相关信息数据,而其中的时间标签信息作为一种重要的上下文信息[13],对推荐准确度的影响最为显著。因为用户兴趣偏好会随着时间的推移而产生变化,早期用户的交互行为相较于近期对于用户偏好的预测会占较低的权重。
为避免用户兴趣偏好随时间推移而变化所带来的误差。文献[14]提出一种基于时序漂移的潜在因子模型推荐算法,通过引入时间因子平衡不同时期用户行为的影响。文献[15]将时间权重融入门控循环单元模型以提高用户兴趣预测的准确性。文献[16]结合艾宾浩斯遗忘曲线与基于模糊聚类的协同过滤算法以降低时间因素的影响。
以上几种融合时间因素的推荐算法都考虑了时间推移给用户兴趣偏好造成的差异,但存在着计算量大、算法执行效率不高等不足。基于此,提出以指数时间函数代表时间因素的影响,融入隐语义模型的用户偏好向量中,在不增加矩阵维度的条件下引入时间偏置项,将评分矩阵转换为稠密矩阵的同时避免了时间因素对传统隐语义模型带来的误差。
2 系统模型
2.1 问题描述
给定样本数据集,每条数据(u,i,r,t)表示用户u对项目i的评分为r,t则表示用户u给项目i评分时的时间标签。基于时间标签信息和评分信息挖掘出用户与项目之间的隐含特征,预测用户对未交互项目的评分,进而生成推荐列表。
融合时间因素的隐语义模型推荐算法主要包括融合时间因素的改进隐语义模型和协同过滤推荐两个模块,模块一从样本数据中获取时间标签信息得出用户与项目交互的时间跨度,基于指数时间函数构造时间偏置项引入隐语义模型中,预测评分矩阵中空缺评分;模块二则是在填补后的稠密评分矩阵中通过皮尔森相关系数寻找相似用户集,为目标用户生成推荐项目列表。算法流程图如图1所示。
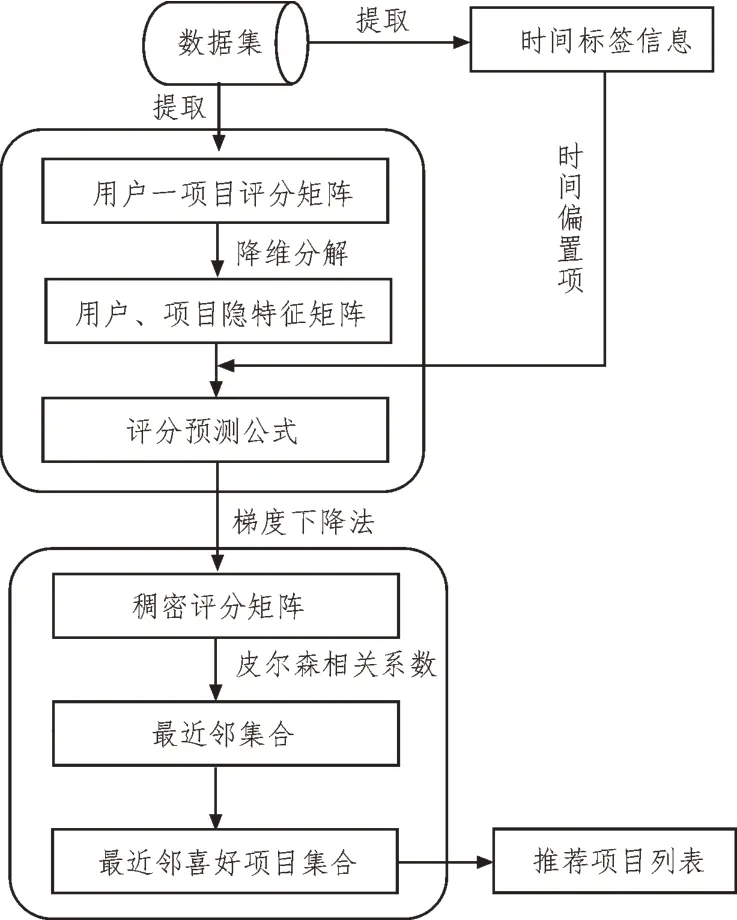
图1 算法流程图
2.2 隐语义模型
隐语义模型是Simon Funk 在矩阵分解技术的基础上,通过梯度下降法改进而来的,核心思想是通过用户项目之间的隐含特征联系二者,挖掘分析用户历史行为得到其潜在兴趣偏好。从矩阵分解的角度来看,隐语义模型是将评分矩阵R分解为两个低维矩阵的乘积,用户u对项目i的评分可表示为:
其中,k表示隐语义模型中隐特征个数。
但在实际应用中,某些用户总会给出比其他用户偏高或偏低的分数,某些项目总是会得到偏高或偏低的评分,因此可以在评分预测模型中加入偏置项,以降低对于评分预测的影响。同时,由于用户评分数据的稀疏性较高,隐式数据远多于显式数据,因此将象征用户隐式兴趣的特征向量加入预测公式中的用户偏好矩阵中,此时预测评分为:
3 融合时间因素的隐语义模型推荐算法
3.1 时间偏置项
通常,时间推移会改变用户偏好,同一用户早期感兴趣的项目到近期可能兴趣度会产生一定量的衰减,因此用户近期交互过的项目相较于早期会对用户的兴趣偏好有更大的影响。例如用户早期喜欢动作片,但近期喜欢上了悬疑片,所以早期对于动作片打的高评分会导致推荐列表中会存在很多动作片,为用户推荐一些已经不感兴趣的项目。因此,将评分数据中的时间标签加以利用,使用指数函数表示隐语义模型中用户特征矩阵中的时间偏置项,时间跨度越大的用户交互行为时间偏置量越小,定义如下:
其中,λ表示时间衰减速率,可动态调节;t表示用户和物品交互的时间跨度;tu,i表示用户u与项目i的交互时间;tu表示用户u的最早交互时间;f(t)是时间偏置量,取值范围是[1/2,1)。
3.2 融合时间因素的隐语义模型
在考虑了时间因素对于隐语义模型中用户偏好的影响后,将基于指数时间函数(3)的时间偏置项加入评分预测公式,用户u对于项目i的评分计算公式可表示为:
其损失函数为:
利用随机梯度下降法最小化上述损失函数,分别对各参数求偏导可得到最速下降方向,进而求得各参数的迭代公式,不断迭代至参数收敛,迭代公式如式(6)所示:
其中:
3.3 基于最近邻的推荐
将原评分矩阵转变为稠密矩阵后,计算出目标用户与其他用户之间的相似度,然后基于相似度由高到低选取前k名用户作为最近邻集合,将最近邻集合中用户打出高评分且目标用户没有交互过的项目推荐给目标用户。采用皮尔森相关系数(Pearson Correlational Coefficient,PCC)求出目标用户的相似用户集合,其计算公式如下:
其中,rui和rvi分别表示用户u和v对项目i的评分,分别表示用户u和v所有评分的均值。根据相似度排序,找到与目标用户最为相似的n个用户,根据这n个用户有过交互的项目为目标用户进行推荐。
4 实验结果分析
4.1 实验数据集及环境介绍
实验采用的数据集为Movielens1M 数据集,其中包含了6 040 名用户对3 952 部电影的1 000 209 条评分记录以及用户评分时的时间戳,评分为1~5 分,数据稀疏度为:1-1 000 209/(6 040×3 952)=0.958 1。实验环境为PC 机,Windows10 操作系统;编程语言为Python3.8。在实验中将数据集划分为两部分:80%作为训练数据集用于训练CF_TSVD++模型,剩余的20%作为测试数据集。
4.2 衡量指标
文中共使用到五种指标来评估所提算法。采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)评估算法预测准确性,值越小说明算法的预测准确度越高。采用准确率(Precision)、召回率(Recall)和综合F值(FMeasure)评估算法推荐准确性,Precision 表示用户对所推荐商品感兴趣的概率,Recall 表示用户感兴趣的商品被推荐的概率,F值则是二者的调和平均值,能更加综合地反映推荐算法的各项性能,三个指标越高说明推荐的质量越好。五个指标计算如式(9)所示:
其中,rij是真实评分,prij是预测评分,| hisu|表示正确推荐给用户u的相关项目的数量,| recsetu|表示推荐物品总数,| tentsetu|表示理论上最大的命中数量。
4.3 实验结果分析
4.3.1 参数分析
该文主要分析迭代次数及时间衰减速率对算法性能的影响。在实验中保持其他参数不变,设置时间衰减速率λ分别为0.4、0.5、0.6,观察其随迭代次数的变化对MAE 和RMSE 值的影响,分布曲线如图2-3 所示。

图2 时间衰减速率对RMSE的影响
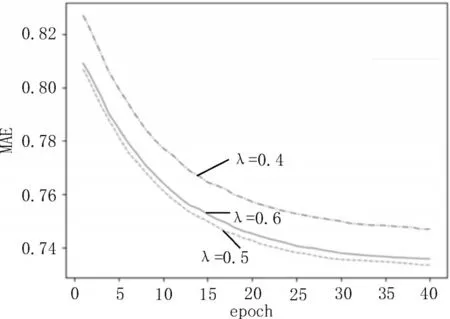
图3 时间衰减速率对MAE的影响
由图2、3 可知,时间衰减速率λ取值分别为0.4、0.5 和0.6 时,算法的MAE 值和RMSE 值均随着迭代次数的增加在逐渐减小。当迭代次数小于30 时,两项指标减小速度较快,在迭代次数达到30 左右下降趋势趋于稳定,迭代次数大于30 时减小速度越来越慢,说明当迭代次数为30 时算法性能趋于稳定。当迭代次数相同时,时间衰减速率λ为0.5 时算法的两项指标均高于λ为0.4 和0.6 的值,因此,当λ=0.5 时,算法的性能达到最优。
4.3.2 推荐准确性分析
为评价融合时间因素的隐语义模型推荐算法(记为CF_TSVD++)的推荐性能,计算其在近邻个数k取不同数值时的准确率、召回率以及综合F值,将这三项指标与传统的基于用户的协同过滤算法(记为UserCF)以及基于隐语义模型的推荐算法(记为LFM)进行比较,实验结果如图4-6 所示。

图4 不同算法的准确率曲线图
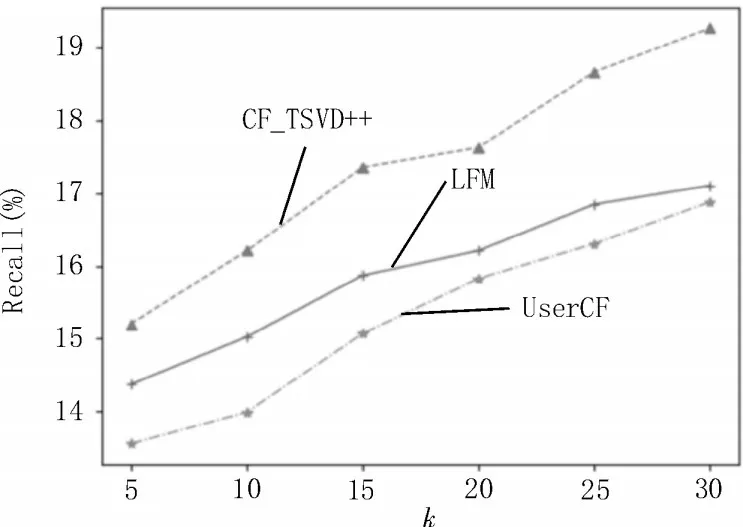
图5 不同算法的召回率曲线图
由图4、5 可知,随着近邻个数k的增加,三种算法的准确率、召回率都呈增长趋势,CF_TSVD++的整体增长速度与幅度高于其他两种算法;当近邻个数k相同时,CF_TSVD++的两项性能指标都明显高于其他两种算法。
图6 给出三种算法的综合F值的柱状对比图,三种算法的综合F值都随着k的增加而增加,当k相同时,CF_TSVD++的综合推荐性能明显高于其他两种算法。通过上述实验结果可以得出,CF_TSVD++与UserCF 以及LFM 相比,在准确率、召回率以及综合F值三项指标上均优于其他两种算法,说明在隐语义模型的基础上融合时间因素能在有效解决数据稀疏问题的同时提高评分预测准确性,进而提高推荐系统的推荐性能。
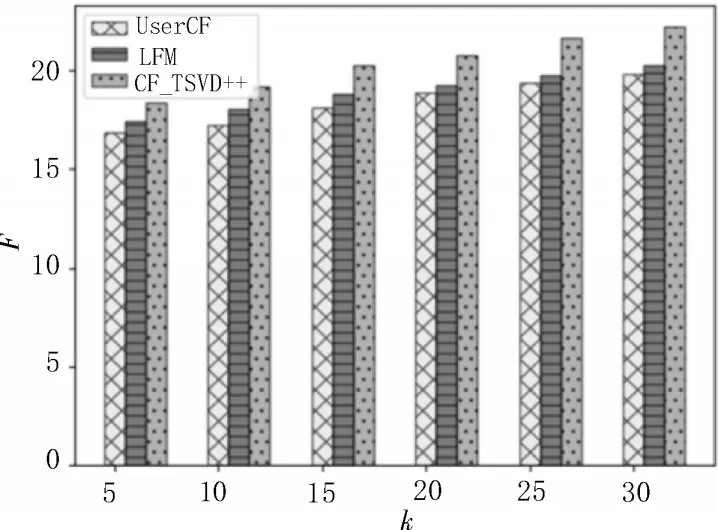
图6 不同算法的综合F值对比
5 结束语
文中在改进的隐语义模型中引入时间偏置项,避免时间因素给用户评分预测造成的误差,该模型用指数时间函数表示时间偏置项加入用户偏好向量中,在填补稀疏评分矩阵的同时提高预测精准度,最后基于邻域协同过滤求出目标用户的推荐项目列表。采用Movielens1M 数据集进行实验,结果表明:1)隐语义模型能够在保证初始数据完整性的情况下填补空缺评分,有效解决了数据稀疏问题;2)引入时间偏置项避免了时间推移造成的用户偏好误差,提高了评分预测的准确度;3)该算法与UserCF 和LFM相比能够有效解决数据稀疏、推荐精准度较低问题,提高推荐系统的推荐质量。
下一步工作的改进思路主要是基于用户画像理论构建动态用户画像模型,更加精准地预测用户兴趣偏好的变化趋势,进一步提升推荐效果和算法性能。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19
中国信息化(2022年5期)2022-06-13
开放教育研究(2020年2期)2020-03-31
北京航空航天大学学报(2016年6期)2016-11-16
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
现代语文(2016年21期)2016-05-25
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
大连民族大学学报(2015年2期)2015-02-27
