
基于大规模预训练模型的地质矿物属性识别方法及应用
2024-04-17 08:40:18王彬彬周可法王金林汪玮李超程寅益
新疆地质 2024年1期
关键词:深度神经网络
王彬彬 周可法 王金林 汪玮 李超 程寅益
摘 要:地球科学的研究成果通常记录在技术报告、期刊论文、书籍等文献中,但许多详细的地球科学报告未被使用,这为信息提取提供了机遇。为此,我们提出了一种名为GMNER(Geological Minerals named entity recognize,MNER)的深度神经网络模型,用于识别和提取矿物类型、地质构造、岩石与地质时间等关键信息。与传统方法不同,本次采用了大规模预训练模型BERT(Bidirectional Encoder Representations from Transformers,BERT)和深度神经网络来捕捉上下文信息,并结合条件随机场(Conditional random field,CRF)以获得准确结果。实验结果表明,MNER模型在中文地质文献中表现出色,平均精确度为0.898 4,平均召回率0.922 7,平均F1分数0.910 4。研究不仅为自动矿物信息提取提供了新途径,也有望促进矿产资源管理和可持续利用。
关键词:矿物信息提取;深度神经网络;矿物文献;命名实体识别
地球科学的研究成果通常记录在技术报告、期刊论文、书籍等文献中。近年来,开放数据倡议促使政府机构和科研机构将数据在线发布以供再利用[1-3]。许多国家地质调查机构(如USGS和CGS)已将地质调查成果在线发布。地球科学文献作为开放数据的重要组成部分,为地质矿物信息提取研究提供了巨大机遇。
从地质科学文本数据中提取结构化信息、发现知识的研究在数字地球科学领域尚未深入探讨。特别是在处理中文地质科学文献时更为困难,因为中文单词之间无空格,计算机难以识别有意义的词汇或短语的边界[4-5]。基于深度学习的命名矿产实体识别是实现矿产信息自动提取的重要方法,也是构建矿产领域知识图的前提条件。
目前,地质矿物命名实体识别领域的研究相对较少,在地质命名实体识别方面,一些学者已将深度学习应用于该领域,并取得一定成果。Zhang等 针对地质文献特点[6],設计了一种基于深度信念网络的地质命名实体识别模型。Qiu等提出了一种将双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)与CRF相结合的模型[7],该模型利用注意机制捕捉单词之间的关联信息,并从地质报告中提取地质实体,如地质历史和地质结构。Li等构建了一种基于地质领域本体的中文分词算法[8],并辅以自循环方法,以更好地分割地质领域文本。矿物信息的提取有以下3个难点:①矿物信息来源广泛,包括文献、专利、报告、新闻等多种类型的文本[9];②矿物信息的命名规范不统一,不同地区、不同领域、不同时间的命名方式可能存在差异,需进行多样化命名实体识别;③矿物信息的语言表达复杂,包括词汇多样、语法复杂、语义模糊等问题。
为解决这些挑战,我们提出了一种基于深度神经网络的地质矿物命名实体识别模型,基于5份区域矿产领域报告,据矿产文本的特点,提取了矿产类型、地质构造、岩石和地质时间、成矿区域等信息。与前人所采用的方法相比,结合大规模预训练模型BERT和深度神经网络来学习上下文信息,使用条件随机场来获取最优全局标签序列[10],最终实现地质矿物命名实体识别。
1 方法
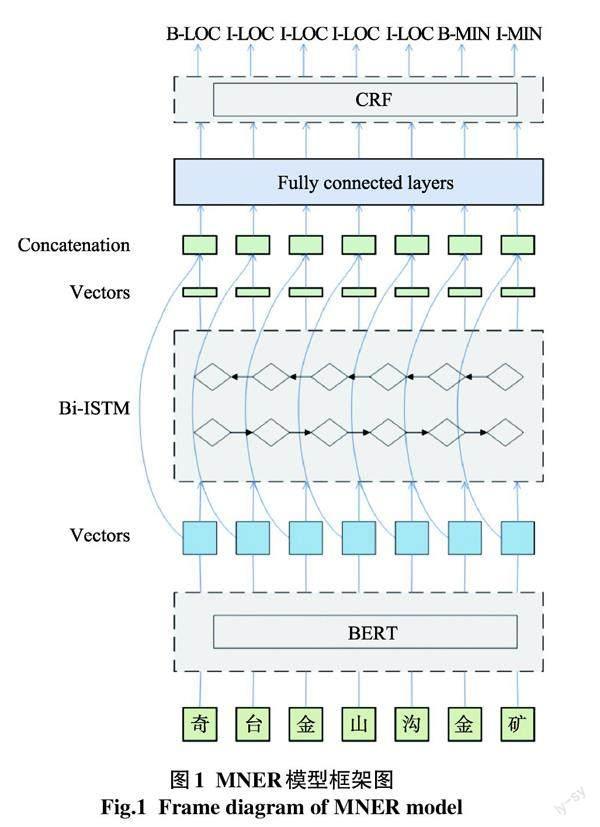
本文采用的大规模预训练模型BERT和深度神经网络的总体结构如图1。整个模型分为BERT层、BiLSTM层、全连接层和CRF层。首先,BERT预训练层在大规模无标注地质矿物数据集上进行无监督训练,提取丰富的语法和语义特征,得到词向量表示;然后将训练好的词向量输入长短期记忆网络进行特征提取,并将两个神经网络的输出特征进行融合;最后,通过一个全连接层进行降维并将输出的特征输入到CRF层进行校正。
1.1 BERT
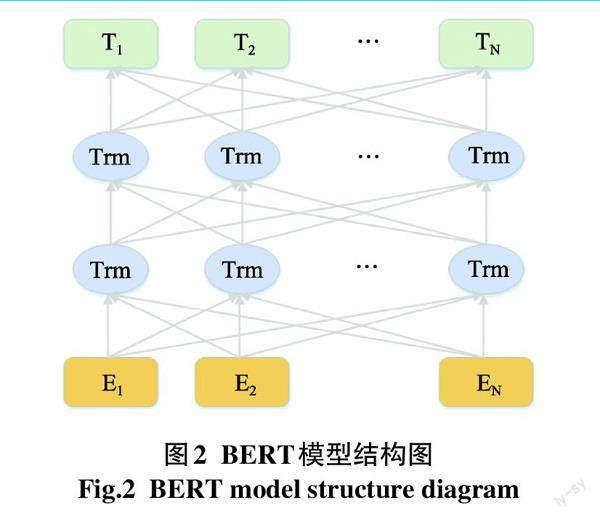
Devlin等提出了BERT模型[11],与OpenAI GPT中的从左到右Transformer和ELMo中的拼接双向LSTM不同[12-13],BERT使用双向Transformer模型架构[14](图2)。“Trm”代表Transformer块。该模型使用注意力机制将任意位置的两个单词之间的距离转换为1,使模型能够充分考虑更长距离的上下文语义,有效解决了NLP中单词和句子的长期依赖问题,并更全面地捕捉语句中的双向关系。[]
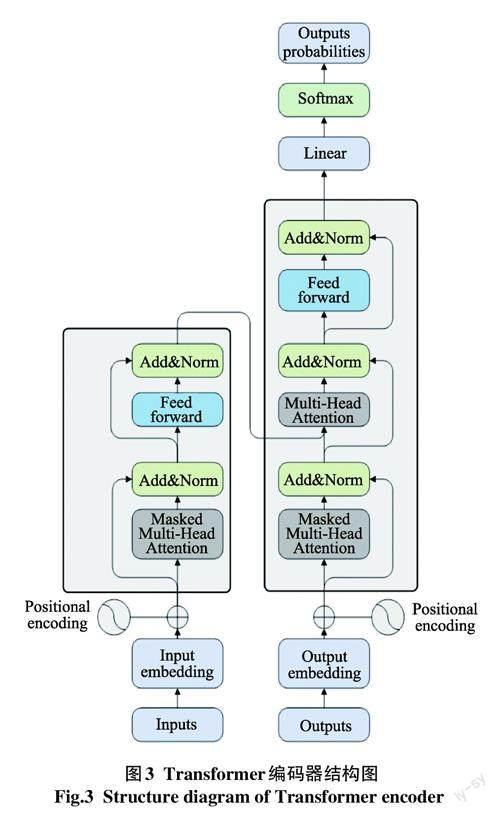
该模型的输入层是词嵌入、位置嵌入和分段嵌入的组合。Transformer Block是基于注意力机制的编码结构(图3),是BERT的重要组成部分。在Transformer编码单元中使用自注意力机制的工作原理主要是计算文本序列中单词之间的相关性。其主要功能是引导神经网络将注意力集中在能够更好地影响输出的特征上,并区分输入对输出的不同部分的影响。其中,编码器由6个相同模块堆叠而成。计算输出公式(1)和公式(2)所示。
outputAtt=LayerNorm(x+Attention(x)) (1)
outputFnn=LayerNorm(outputAtt+FNN(outputAtt))…(2)
解码器同样堆叠有6个相同模块。与编码器模块不同,在底层注意力层中添加了遮蔽,其目的是防止模型接触未来时刻点上信息而影响训练。单个头的缩放点注意力计算公式如下:
其中,[xt]为当前的输入,[ht-1]为上一步的隐藏状态,[ft]为遗忘门,[it]为输入门,[Ot]为输出门,b为偏置,[Ct]为神经元在时间t记忆的信息,[Ct]为当前神经元要存储的信息,[ht]为最终LSTM单元的输出。
在将BiLSTM应用于命名实体识别时,将BERT获得的地质矿物文本中每个单词的向量表示作为输入。通过使用LSTM,网络可自动学习上下文特征,然后计算当前时间步的最佳分类结果。虽然仍为一个分类模型,但该网络能够获取更好的上下文特征表示。
1.3 CRF
尽管BiLSTM和IDCNN神经网络结构能捕捉上下文信息,但忽略了实体标签之间的顺序和关联。在命名实体识别中,根据标注规则,如果某些标签连续出现,则可能不符合语言逻辑。CRF可考虑标签之间的逻辑关系,以获得全局最优的标签序列,因此在模型最后一层使用它来修改识别结果。其原理如下:
定义[Pij]为第i个符合第j个标签的概率,输入的句子序列[x={x1,x2,x3,…,xn}]与其预测序列[y=][{y1,y2,y3,…,yn}]得分计算公式如下:
公式(15)-(17)中,[y*]表示正确标签的对数概率,[y]表示所有可能标记的集合,最优序列分类通过[K(x,y)]函数完成。
2 实体识别实验
2.1 数據集
本研究使用的标注语料库来自不同地区的5份中国区域调查报告,共计约50万字。由于原始文本中有诸多干扰信息,如标题号、图片和表格,这将使文本识别变得困难,因此首先对文本进行预处理,主要检查文本格式和内容,去除图片和表格,将连续的文本划分为只包含单词、标点符号、数字和空格的标记,且无地质矿物实体信息的句子已被删除,最终得到了8 000个有效句子。对这些有效数据,本文按随机选择方法,按8∶1∶1的比例划分为训练集、验证集和测试集。
2.2 标注策略和评价指标
文本标注是指对文本中的实体和非实体进行标记。我们采用了“BIO”(Beginning、Inside、Outside)标注策略,其中“B”表示实体词汇的第一个字符,“I”表示实体词汇的所有中间字符,“O”表示非实体词汇。我们共标注18 783个实体,包括矿产资源的6个主要特征:矿产地、岩石、地层、矿物类型、地质构造、地质时间(表1)。对于复杂实体,我们分别标注多个实体,例如“岩(B-LOC)金(I-LOC)矿(I-LOC)山(I-LOC)潜(B-ROC)火(I-ROC)山(I-ROC)岩(I-ROC)白(B-SG)山(I-SG)组(I-SG)”,“岩金矿山”、“潜火山岩”和“白山组”分别被标记为矿产地、岩石和地层。在实验中,复杂实体也被单独匹配。
命名实体识别的评价指标包括:精确率(P)、召回率(R)和F值。具体的定义如下:Tp表示模型正确识别的实体数量,Fp表示模型误识别的实体数量,Fn表示模型漏掉的实体数量,即模型未能正确标识的实际存在的实体数量。这3个指标在NER评价标准中被广泛使用[17-18]。
2.3 实验参数设置
实验环境和参数设置模型在Python 3.7.3和TensorFlow 1.14.1中进行训练和测试。实验使用BERT-Base模型进行,该模型包含12个转换层、768个维隐藏层和12头注意机制。BiLSTM网络有一个128维的隐藏层。注意机制层被设置为50维,且最大序列长度被设置为256,所有模型均在4×RTX 2080 Ti GPU上进行训练(表2)。
2.4 实验和分析
在进行深度学习模型训练前,合理设置超参数至关重要。学习率作为深度学习模型中的一个关键参数,对于目标函数的收敛速度及是否能够收敛到局部最小值均有显著影响。针对BERT-LSTM-CRF模型进行了学习率调整实验。从实验结果可以明显看出(表3),将学习率设置为4e-5时获得了最优的性能表现。
另一个在BERT模型中常用的正则化技术是dropout。该技术会随机地将部分神经元输出设为零,有助于降低模型过拟合风险。在BERT-LSTM-CRF模型中,我们对dropout率进行调整实验。结果表明(表4),在实验中将dropout设置为0.1时,能够获得最佳性能效果。
实验结果进一步强调了超参数选择的重要性,凸显了在BERT-LSTM-CRF模型中的学习率和dropout率对模型性能影响的关键性。这些参数的优化可在一定程度上提高模型性能和泛化能力。实验的命名实体识别模型结果见表5。
所有考虑的模型中,BERT-LSTM-CRF表现最佳,其精确度、召回率和F1值分别达0.898 4、0.992 7和0.910 4。在使用BERT与CRF结合的情况下,精确度、召回率和F1值分别为0.880 7、0.902 9和0.891 7。在引入双向LSTM网络后,F1值出现下降,可能是因为BERT已具良好的词向量表示,而引入BiLSTM后导致过拟合现象。
当使用RoBERTa预训练模型时,识别效果普遍下降。尽管RoBERTa和BERT均基于Transformer架构的预训练语言模型,但在预训练细节、超参数等方面可能存在差异。BERT的架构和超参数设置更适合地质矿物领域的命名实体识别任务。值得注意的是,在中文文本中,岩石和矿物类型相对容易辨别,且其标签数量在所有实体中占比超过50%,因此,所有模型均表现出对“岩石”和“矿物类型”实体的良好识别效果,F1得分均超过90%。此外,表现较好的另外两种实体类型是“地层”和“地质时间”,且它们对应的标签数量也相对较多。
上述结果表明,在矿物实体识别任务中,BERT-LSTM-CRF模型的表现最佳,而RoBERTa预训练模型表现一般。不同类型的矿物实体在各模型的识别效果也呈现出一定差异。
3 结论和展望
本研究主要致力于运用深度学习构建命名实体识别模型,即从大量地质矿物相关文档中提取命名实体。该工作为构建地质矿物知识图谱提供了重要数据支持。基于BERT-LSTM-CRF模型,笔者团队从地质矿物文献中提取出6种类型实体,实现了平均精确度0.898 4,平均召回率0.922 7,平均F1分数0.910 4。从实验结果中得出以下结论:
(1) 在命名實体识别任务中,BERT-LSTM-CRF模型表现最佳,但引入BiLSTM会导致过拟合,从而降低模型性能。
(2) 当中文实体的语义区别明确且标签充足时,实体识别效果更好。
(3) 在地质矿物领域命名实体识别任务中,RoBERTa不如BERT表现出色。BERT的架构和超参数设置更适合地质矿物领域命名实体识别任务。
尽管本研究在矿物命名实体识别方面取得了良好效果,仍有待进一步改进的空间:
(1) 针对标注较少的实体类型,有进一步提升其识别性能的空间。我们计划通过扩充数据集中的矿物实体数量来解决此问题。
(2) 未来将针对地质矿物领域的特点进行模型调整和优化,以提高模型的领域适应性。
(3) 根据从地质矿物文本中所提取的信息构建地质矿物相关的领域知识图谱。
参考文献
[1] Ali S H,Giurco D,Arndt N,et al.Mineral supply for sustainable development requires resource governance[J].Nature,2017,543(7645):367-372.
[2] Cernuzzi L,Pane J.Toward open government in Paraguay[J].It Professional,2014,16(5):62-64.
[3] Ma X.Linked Geoscience Data in practice:Where W3C standards meet domain knowledge,data visualization and OGC standards[J].Earth Science Informatics,2017,10(4):429-441.
[4] Gao J,Li M,Huang C N,et al.Chinese word segmentation and named entity recognition:A pragmatic approach[J].Computational Linguistics,2005,31(4):531-574.
[5] Huang L,Du Y,Chen G.GeoSegmenter:A statistically learned Chinese word segmenter for the geoscience domain[J].Computers & geosciences,2015,76:11-17.
[6] Zhang X,Fan D,Xu J,et al.Sedimentary laminae in muddy inner continental shelf sediments of the East China Sea:Formation and implications for geochronology[J].Quaternary International,2018,464:343-351.
[7] Qiu Q,Xie Z,Wu L,et al.BiLSTM-CRF for geological named entity recognition from the geoscience literature[J].Earth Science Informatics,2019,12:565-579.
[8] Li W,Ma K,Qiu Q,et al.Chinese Word Segmentation Based on Self-Learning Model and Geological Knowledge for the Geoscience Domain[J].Earth and Space Science,2021,8(6):1673.
[9] Wang B,Ma K,Wu L,et al.Visual analytics and information extraction of geological content for text-based mineral exploration reports[J].Ore Geology Reviews,2022,144:104818.
[10] Sobhana N,Mitra P,Ghosh S K.Conditional random field based named entity recognition in geological text[J].International Journal of Computer Applications,2010,1(3):143-147.
[11] Devlin J,Chang M W,Lee K,et al.Bert:Pre-training of deep bidirectional transformers for language understanding[J].arXiv preprint arXiv:2018,1810.
[12] Radford A,Narasimhan K,Salimans T,et al.Improving language understanding by generative pre-training[J].2018.
[13] Peters M E,Neumann M,Iyyer M,et al.Deep contextualized word representations[J].arXiv preprint arXiv,2018,1802.
[14] Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[J].Advances in neural information processing systems,2017,30.
[15] Bengio Y,Simard P,Frasconi P.Learning long-term dependencies with gradient descent is difficult[J].IEEE transactions on neural networks,1994,5(2):157-166.
[16] Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural computation,1997,9(8):1735-1780.
[17] 庄云行,季铎,马尧,等.基于Bi-LSTM的涉恐类案件法律文书的命名实体识别研究[J].网络安全技术与应用,2023 (7):36-39.
[18] 邱芹军,田苗,马凯,等.区域地质调查文本中文命名实体识别[J].地质论评,2023,69(04):1423-1433.
Geological Mineral Attribute Recognition Method Based on
Large-Scale Pre-Trained Model and Its Application
Wang Binbin1,2,4, Zhou Kefa2,3,5, Wang Jinlin1,2,3,4, Wang Wei1,2,3,4, Li Chao5, Cheng Yinyi2
(1.Xinjiang Research Center for Mineral Resources,Xinjiang Institute of Ecology and Geography,Chinese Academy
of Sciences,Urumqi,Xinjiang,830011,China;2.University of Chinese Academy of Sciences,Beijing,100049,China;
3.Technology and Engineering Center for Space Utilization, Chinese Academy of Sciences,Beijing,100094,China;
4.Xinjiang Key Laboratory of Mineral Resources and Digital Geology,Urumqi,Xinjiang,830011,China;
5.Institute of Geological Survey,China University of Geosciences,Wuhan,Hubei,430074,China)
Abstract: Geoscience research results are usually documented in technical reports, journal papers, books, and other literature; however, many detailed geoscience reports are unused, which provides challenges and opportunities for information extraction. To this end, we propose a deep neural network model called GMNER (Geological Minerals named entity recognize, MNER) for recognizing and extracting key information such as mineral types, geological formations, rocks, and geological time. Unlike traditional methods, we employ a large-scale pre-trained model BERT (Bidirectional Encoder Representations from Transformers, BERT) and deep neural network to capture contextual information and combine it with a conditional random field (CRF) to obtain more accurate and accurate information. The experimental results show that the MNER model performs well in Chinese geological literature, achieving an average precision of 0.8984, an average recall of 0.9227, and an average F1 score of 0.9104. This study not only provides a new way for automated mineral information extraction but also is expected to promote the progress of mineral resource management and sustainable utilization.
Key words: Mineral information extraction; Deep neural network; Mineral documentation; Named entity recognition
項目资助:新疆维吾尔自治区重大科技专项(2021A03001-3)、新疆科学考察项目(2022xjkk1306)、深空大数据智能建设(292022000059)联合资助
收稿日期:2023-09-18;修订日期:2024-01-09
第一作者简介:王彬彬(1998-),男,陕西咸阳人,中国科学院大学地球探测与信息技术专业在读硕士,研究方向为地质大数据;
E-mail: wangbinbin21@mails.ucas.ac.cn
猜你喜欢
计算机应用(2019年2期)2019-08-01 01:57:38
现代电子技术(2019年13期)2019-07-08 05:33:51
软件工程(2019年5期)2019-07-03 02:31:14
电脑知识与技术(2019年2期)2019-03-15 13:31:28
现代电子技术(2018年24期)2018-12-14 09:05:06
无线互联科技(2018年6期)2018-06-25 07:34:40
现代电子技术(2018年6期)2018-03-13 22:28:09
科教导刊·电子版(2017年13期)2017-07-24 08:26:51
电子技术与软件工程(2017年4期)2017-03-27 21:51:30
电脑知识与技术(2016年22期)2016-10-31 20:23:56
