
基于CNN-Transformer 双模态特征融合的目标检测算法
2024-04-15 03:17:12杨晨侯志强李新月马素刚杨小宝
光子学报 2024年3期
杨晨,侯志强,李新月,马素刚,杨小宝
(1 西安邮电大学 计算机学院, 西安 710121) (2 陕西省网络数据分析与智能处理重点实验室, 西安 710121)
0 引言
目标检测作为计算机视觉领域的重要分支,已广泛应用于自动驾驶[1]、视频监控[2]、智能交通[3]等场景中。近年来,基于深度学习的目标检测算法以其出色的检测性能得到大力发展。在深度学习框架下,目标检测方法通常分为两大类:基于锚框的方法和无锚框的方法。基于锚框的方法为每一个位置设定多个矩形框,通过微调这些矩形框实现目标检测,根据检测流程的差异,可分为两阶段目标检测和单阶段目标检测两类。两阶段目标检测首先提取候选框,再分类和回归这些候选框以生成检测结果,其中典型方法包括RCNN[4]、Fast R-CNN[5]和Faster R-CNN[6]等;而单阶段目标检测算法直接对预定义锚点框进行分类和回归,如SSD[7]和YOLO[8-14]等系列算法。无锚框的目标检测算法去除了锚框的使用,通过关键点的组合和定位来实现目标检测,代表算法如CornerNet[15]、FCOS[16]和CenterNet[17]等。随着Transformer 在计算机视觉领域的广泛应用,基于Transformer 的目标检测算法也得到了显著进展,如DETR[18]、VIT-FRCNN[19]、Deformable DETR[20]等。然而,基于Transformer 的方法因其高计算成本,在实际任务中面临部署难题。因此,许多研究者提出将卷积神经网络(Convolutional Neural Network,CNN)与Transformer 结合的目标检测方法,典型如BotNet[21]和CMT[22]等。这些方法巧妙地结合了CNN 和Transformer 的优势,融合了局部特征与全局特征,增强了特征表达能力,有效提升了目标检测性能,实现速度和精度的平衡。
目前,大多数目标检测算法主要基于可见光图像。在光照充足的情况下,可见光传感器能够有效地捕捉目标的颜色和纹理等信息。然而,实际应用中,由于各种环境因素的干扰,如遮挡、恶劣天气(如雨雾)、光照不均等情况[23],可见光传感器往往难以获取完整的目标信息,从而无法满足精确的检测需求[24]。相反,红外图像主要基于热辐射能量成像,受光照影响较少,在光线不足的条件下可以提供清晰的轮廓信息,但其也存在图像对比度低、纹理信息匮乏等问题。针对上述问题,红外与可见光图像融合技术被提出,通过有效整合两种模态的互补信息,不仅可以提升目标检测性能,还能扩展其在真实场景中的应用。因此,构建基于双模态特征融合的目标检测技术逐渐成为当前的研究热点。例如,ZHU Yaohui 等[25]在已有目标检测特征金字塔结构的基础上,引入基于Transformer 的多模态融合特征金字塔结构,从而提升了目标检测性能;ZHANG Heng 等[26]在YOLO 架构中引入循环细化模块,有效地实现了双模态特征融合与目标检测;ZHOU Kailai 等[27]提出模态平衡网络并结合差分模态感知融合模块,实现了模态间的互补,从而增强了行人检测性能;赵明等[28]通过跨域融合网络结构,将红外域与伪可见光域的双模态特征进行融合,提升了目标检测的准确性;YANG Xiaoxiao 等[29]通过双向自适应门控机制,高效地实现了跨模态特征融合;JIANG Qunyan 等[30]提出了一种适用于多光谱行人检测的单机检测器,利用跨模态互补模块和基于注意力的特征增强模块,实现了行人检测;FANG Qingyun 等[31]运用Transformer 中的自注意力机制,实现了多光谱目标检测中不同模态信息的高效融合,从而显著提升了检测性能;CHEN Yiting 等[32]采用了概率集成技术,将多模态检测结果有机地融合在一起,为多光谱目标检测领域带来了创新;WANG Qingwang 等[33]提出了一种冗余信息抑制网络,抑制了跨模态冗余信息,促进了红外-可见光互补信息的融合;CAO Yue 等[34]采用了通道切换和空间注意力的有效融合策略,成功地整合了来自不同模态的输入信息,显著提升了多模态目标检测的准确性。
双模态目标检测算法所采用的双模态融合策略主要可分为早期融合、中期融合和后期融合三大类。早期融合一般是指像素级融合,通过逐像素地整合来自不同模态的图像,生成融合图像后输入检测网络。例如,WANG Wensheng 等[35]通过提取与集成不同模态的高频信息来实现显著性目标检测;ZHANG Xiaoye等[36]提出了一种基于局部边缘保留滤波器的图像分解和融合策略,获得融合图像来进行显著性目标检测。中期融合通常是指特征级融合,即在特征提取过程中将不同模态特征进行融合,从而获得融合后的特征图用于目标检测。例如,ZHANG Heng 等[37]引入了一种新的多光谱特征融合方法,通过动态融合多光谱特征来提高检测性能;AN Zijia 等[38]提出了跨模态信息共享网络,通过共享不同模态的目标信息来增强特征提取能力。后期融合是指决策级融合,侧重于将不同模态的检测结果进行组合,以优化最终决策方案。例如,LI Chengyang 等[39]利用光照信息对可见光和红外预测结果进行加权融合;BAI Yu 等[40]通过对两种模态检测结果的决策来进行融合检测。中期融合能够有效利用两种模态的不同特征,实现特征层次的信息交互。
本文提出了一种基于CNN-Transformer 双模态特征融合的目标检测算法CTDMDet(CNNTransformer Dual Modal feature fusion Object Detection)。搭建了一个双分支网络,使其能够同时处理红外和可见光图像。采用基于CNN 的红外特征提取模块(CNN-based Feature Extraction,CFE)来获取红外图像局部特征。选用基于Transformer 的可见光特征提取模块(Transformer-based Feature Extraction,TFE),以更好地获取可见光图像全局上下文信息和细节特征。最后,设计了双模态特征融合模块(IR-RGB Fusion Module, IRF),通过模态间信息的交互,获取跨模态互补信息。
1 本文算法
在YOLOv5-s 的基础上进行扩展,构建了一个能够同时输入红外和可见光图像的双模态融合目标检测网络。如图1 所示,所提算法整体网络结构由三个主要部分组成:双模态特征提取主干网络、特征融合颈部网络和检测头。

图1 整体网络结构Fig.1 Overall network architecture
针对红外和可见光图像各自的特点,双模态特征提取主干网络包含两个并行的网络分支。红外分支由基于CNN 的特征提取模块CFE 及卷积层CBS(Conv-BN-SiLU)组合而成,可见光分支则由基于Transformer 的特征提取模块TFE 和卷积层CBS 组合而成。首先,红外图像MIR和可见光图像MRGB分别输入到对应的分支中,经过卷积CBS 操作后获得特征信息FIR和FRGB。随后,FIR和FRGB分别经过四个连续的特征提取模块CFE 和TFE,获得不同尺度的红外特征FiIR和可见光特征FiRGB(i∈1,2,3,4)。其次,采用中期融合方式,在网络的后三层,将并行获取的两种模态特征输入到红外-可见光融合模块IRF 中,以获得融合特征信息FjIRF(j∈1,2,3)。融合后的特征与对应尺度的两种模态特征相加后分两路进行处理。一路送回原始红外和可见光分支,继续后续的特征提取和融合。另一路与另一种模态的特征相加,得到融合特征(j∈1,2,3),然后送入特征融合颈部网络。特征融合颈部网络是由包含卷积和残差结构的C3 模块以及上采样操作构成,利用特征金字塔结构实现不同尺度的特征融合。最后,融合特征根据不同的尺度送入对应大小的检测头中进行目标检测。
1.1 红外特征提取网络
红外特征提取网络主要由基于CNN 的红外特征提取模块CFE 构成,CFE 模块具体结构如图2 所示。

图2 红外特征提取模块Fig.2 Infrared feature extraction module
由于红外图像中目标细节缺失,基准算法的特征提取模块在特征提取时容易出现信息丢失的问题。然而,红外图像中具有清晰的轮廓信息,对目标的定位有指导作用,因此,设计了新的特征提取模块CFE,使模型更加聚焦于关键特征,提升特征信息的表达能力。
以图1 中的第一个CFE 模块为例,对于输入的红外特征FIR,操作流程为:首先,经过三次连续的标准卷积、归一化和激活函数操作,捕获图像中不同层次的特征,得到经过初步处理的特征FIRC。接着,通过全局平均池化操作获取特征的全局信息,得到特征FIRG。此后,将特征FIRG分两个分支进行处理。第一个分支经过连续两个1×1 卷积层和ReLU 激活函数,以提取各通道上的关键信息,从而建立通道间的依赖关系。第二个分支采用3×3 深度可分离卷积层和1×1 逐点卷积层,获取特征的空间信息。深度可分离卷积层能够在确保所获取特征的有效性的同时降低计算负担。之后,两个分支的特征信息融合,融合后的特征通过Sigmoid 函数进行权重映射,并与FIRG相乘。这样操作后,特征信息在通道和空间维度上都得以强化,获得增强后的特征信息FIRE,即
式中,δ表示Sigmoid激活函数,Conv1×1表示1×1 卷积,∂表示ReLU 激活函数,PWConv1×1表示1×1 的逐点卷积,DWConv3×3表示3×3 的深度可分离卷积。
为了减少特征在提取过程中信息的丢失,实现特征复用,同时避免反向传播过程中出现梯度消失、梯度爆炸等情况,引入残差结构。将输入的红外特征FIR经过连续两个CBS 结构提取关键信息后,与增强后的特征信息FIRE沿着通道维度进行拼接,随后再次经过CBS 结构整理通道数并进行下采样,最终得到输出的红外特征具体操作为
式中,Down 表示Downsample 下采样操作,CBS 表示Conv-BatchNorm-SiLU 操作,Concat 表示逐通道拼接操作。
1.2 可见光特征提取网络
可见光特征提取网络主要基于Transformer 的可见光特征提取模块TFE 构成,其中TFE 模块具体结构如图3 所示。

图3 可见光特征提取模块Fig.3 Visible feature extraction module
可见光图像包含丰富的颜色、纹理等细节,因此充分利用这些信息对于实现有效的可见光特征提取至关重要。然而,传统卷积神经网络中的卷积层感受野通常较为有限,从而造成全局上下文信息捕获不足。Transformer 作为一种具备全局建模能力的方法,在自然语言处理领域得到了广泛应用,同时在计算机视觉任务中,如目标跟踪和目标检测中也展现出了优越的性能。因此,本文提出了一种基于Transformer 的可见光特征提取模块(TFE),将Transformer 的强大全局建模能力与卷积的局部建模能力相结合,既能够捕获长距离依赖关系,又能够有效地利用局部特征信息,从而充分地提取可见光图像中的关键特征。此外,由于Transformer 的核心机制是自注意力机制,传统自注意力在处理高分辨率图像时往往伴随着计算开销过大的问题。为了解决这一问题,采用卷积投影的方法,取代传统自注意力机制中的线性映射,从而在保持训练和推理效果的同时,降低计算成本。
以图1 中第一个TFE 模块为例,输入的可见光特征FRGB首先经过CBS 卷积操作,对特征进行重组,强化了特征的表达,获得特征FRGBC。接着,将提取到的特征FRGBC通过卷积映射为查询(Q)、键(K)和值(V)三个向量,以便在后续的注意力计算中针对不同方面的信息进行交互。其中,FRGBC经过1×1 卷积得到的特征映射与FRGBC相乘所得的值,被用作值(V)的计算。对于键(K),利用3×3 的分组卷积来提取其上下文信息,以增强键(K)向量的表示能力,使其能够更好地匹配查询(Q)向量。随后,将提取到的信息与查询(Q)按通道维度拼接,并经过两个连续的1×1 卷积,生成注意力矩阵。此外,在注意力矩阵生成的过程中,引入了Softmax 函数进行加权,获取加权后的信息,并与值(V)向量相乘,从而捕获不同位置的关联度,提升自注意力机制的学习能力,实现全局上下文的有效捕获。之后,通过加法操作将全局上下文信息与原始键(K)相加,实现特征的复用,并通过reshape 函数将其重组为原始尺寸的特征,以确保特征的完整性和连贯性。具体操作为
式中,reshape表示重组函数,σ表示Softmax 激活函数,GConv3×3表示3×3 的分组卷积。
同时,为了避免信息丢失,引入残差结构。将融合了局部信息和全局信息的FRGBT与原始特征经过CBS卷积层后的结果按通道维度进行拼接,再次经过CBS 卷积层,实现信息的跨层传递和特征的有效融合。最后,通过下采样操作对特征进行处理,得到输出的可见光特征具体操作为
1.3 红外-可见光双模态融合模块
红外图像中包含着丰富的位置信息,可见光图像中包含着丰富的纹理信息,两种模态的融合能够实现跨模态信息互补,丰富特征信息,提高检测性能,因此设计了图4 所示的红外-可见光双模态融合模块IRF 来实现两种模态的特征融合。

图4 红外-可见光双模态融合模块Fig.4 Infrared-visible dual modal fusion module
以图1 中第一个IRF 融合模块为例,首先将红外和可见光两种模态的特征和沿通道维度进行拼接,然后通过1×1 卷积实现跨通道特征组合,从而获取初步的融合特征FRI。之后设计了对称路径,将FRI分别与和经过交叉注意力Cross-Attention 模块进一步融合,得到特征FIF和FRF,由此实现单模态信息的增强和模态间信息交互。获得的融合特征FIF和FRF再与和按通道维度进行拼接,捕获目标特征在每个通道间的关系,得到增强特征FIIF和FRRF,在丰富融合特征的同时实现特征复用。最后通过逐元素相加的方式,将两种模态的融合信息相加,得到融合特征融合特征既保留了原始两种模态的特征,又实现了模态间特征互补,提升了目标特征的表达能力。具体操作为
针对模态间特征融合和信息交互,提出了交叉注意力Cross-Attention 模块来捕获两种模态间的信息相关性。以可见光模态为例进行说明,红外模态同理。首先,对初步融合后的特征FRI经过1×1 线性投影和全局平均池化编码,分别获得了查询(QRI)、键(KRI)和值(VRI)三个向量。同样地,可见光特征经过上述相同操作,得到相应的查询向量(QRGB)、键向量(KRGB)和值向量(VRGB)。这些向量在不同的模态中编码了特征映射中的关系信息,以便后续的信息交互。之后,在特征融合过程中,保留了单一模态中的键(K)和值(V)信息,同时利用元素乘法,将一个模态的键(K)值与另一个模态的查询(Q)值相乘。这一操作的意图在于计算两种模态间的匹配度,获取两种模态间的相似性。通过这种操作,引入了模态间的相互关联信息,从而在特征融合过程中实现模态之间的有效交互。随后,使用Softmax 函数进行权重加权,将融合后的关联性信息与原始模态的值(V)相乘,在特征表示中引入模态间的全局关联性,进一步提升交叉注意力模块的信息传递和融合效果,并通过reshape 函数,得到ZRI和ZRGB。具体操作为
为了充分利用多模态数据的互补性,将获得的跨模态信息ZRGB和ZRI按照通道维度拼接,从而实现不同通道间的有效交互,得到融合特征。融合特征通过1×1 卷积整理通道数后,利用Sigmoid 函数获取权重,并与两种模态的特征分别经过3×3 卷积后获取的信息相乘,输出具有全局信息的跨模态融合特征FRF,具体操作为
式中,Conv3×3表示3×3 卷积。
2 实验结果及分析
2.1 实验细节
实验的操作系统为Ubuntu 16.04,CPU 为i5-8400,GPU 为TITAN Xp(显存11GB),CUDA 以及CUDNN 的版本为11.1 和CUDNN8.0.5。提出的网络基于PyTorch 实现,训练过程中使用随机梯度下降(SGD)对网络参数进行迭代更新,动量参数设为0.937,起始学习率设为0.01,BatchSize 设为8,共训练150 个Epoch。在加载数据时将所有图像的分辨率统一调整到640×640,再对整体网络进行端到端训练。
实验的损失函数由三个主要组成部分构成,包括目标检测损失(Objectness loss)、定位损失(Localization loss)以及分类损失(Classification loss)。目标检测损失函数用于度量网络在目标和背景之间的区分能力,实验中采用了二进制交叉熵(Binary cross-entropy)损失函数来评估网络是否能准确地预测目标的存在与否。定位损失函数用于评估网络对目标位置的定位精度,实验采用平滑的L1 损失(Smooth L1 loss)来计算,以衡量网络对目标边界框坐标的预测与实际目标位置之间的误差。分类损失函数则关注网络对目标类别的分类准确性,实验使用交叉熵损失(Cross-entropy loss)来度量网络对目标类别的预测与实际目标类别之间的一致性。这三个损失函数的综合应用使得网络能够在检测过程中有效地识别和定位物体。总的损失函数是这三个部分的线性组合,通过调整权重参数来平衡它们的相对重要性,以更好地指导网络的训练和性能提升。
实验使用类别精度(Average Precision, AP)并选取了AP0.5、AP0.5:0.95两个指标和每秒帧数(Frames Per Second, FPS)作为算法评价指标。其中AP0.5表示平均检测精度,AP0.5:0.95指IoU(Intersection over Union)从0.5 到0.95 每隔0.05 计算的所有类别的AP 平均值。FPS 代表每秒检测图片的数量,能够有效反映出算法的检测速度。
2.2 数据集
实验所用的三个数据集分别为KAIST 数据集[41]、FLIR ADAS 数据集[42]和GIR 数据集[43]。
KAIST 数据集是使用最广泛的大规模多光谱行人检测数据集之一。原始数据集共有95 328 对红外可见光图像对(640×512 分辨率),包括在白天和夜晚不同场景下拍摄的校园、街道和乡村的各种常规交通场景。但由于原始数据集是取自视频连续帧图片,存在相邻图片相似度高的问题,故实验选择了Hou 等[44]清洗后的数据集,其中包括7 601 对用于训练的红外可见光图像对和2 252 对用于测试的红外可见光图像对,并将标签类别仅标注为“person”一类。
FILR ADAS 数据集是一个具有挑战性多光谱目标检测数据集。数据集包括的图像有四个对象类别:“person”、“car”、“bicycle”和“dog”。实验选择最新对齐版本的FLIR ADAS 数据集,清洗后的数据集包含5 142 个对齐的可见光红外图像对(640×512 分辨率),其中4 129 对用于训练,1 013 对用于测试。
GIR 数据集是本实验自行创建的数据集,图像来源于李成龙团队[40]建立的RGBT210 数据集,每张图片包含可见光彩色图像和红外图像两个版本,图像尺寸为630×460。从该数据集中选取5 105 张图片,划分为训练图像4 084 张,测试图像1 021 张。对图片进行标注,确定5 类目标为“person”、“dog”、“car”、“bicycle”和“motorcycle”。
在三个数据集中,每张图像均包含了红外和可见光两个光谱版本,从而形成了一个多模态图像对。这些图像对经过了高度对齐的裁剪,这是通过对成像硬件设备所捕捉的图像进行准确的空间位置匹配所实现的。每个图像对都代表了已经在几何和空间上配准好的两张图像,确保了它们在视觉上相互对应。实验中,针对这些多模态图像,即红外图像、可见光图像以及红外-可见光图像对,分别进行了训练和测试。这样的实验设置保证了所有类型的图像都共享同一套标签,即所含目标的类别信息。通过这种设计,能够在不同光谱模态下,针对单独的红外图像、可见光图像以及红外-可见光图像对,进行有针对性的训练和测试,以探究算法在各种情况下的适用性和性能,确保了实验的严谨性和可信度。
2.3 消融实验
为了验证双模态特征提取网络和双模态特征融合模块的有效性,在KAIST、FLIR 和GIR 三个数据集上进行了一系列消融实验,以评估不同模态特征提取和融合策略的效果。
消融实验的详细设置为:
1) 将可见光和红外图像分别输入YOLOv5-s 网络,进行特征提取和目标检测。
2) 分别用本文所提出的红外特征提取网络和可见光特征提取网络,替代YOLOv5-s 的原始特征提取网络,从而进行单模态目标检测。
3) 将YOLOv5-s 改造为双分支网络,其中可见光分支仍使用YOLOv5-s 的特征提取网络,而红外分支则被本文所提出的红外特征提取网络所代替。同时,引入双模态融合模块IRF,以输入可见光和红外图像进行双模态目标检测。
4) 在双分支融合网络基础上,红外分支保留YOLOv5-s 原始特征提取网络,将可见光分支替换为本文提出的可见光特征提取网络。
5) 在双分支融合网络基础上,红外分支设置为本文所提红外特征提取网络,可见光分支设置为本文所提可见光特征提取网络。
表1 为在KAIST 数据集上得到的消融实验结果,基准模型单独检测红外和可见光图像时,分别达到了71.5%和59.8%的检测精度;通过单模态特征提取网络的替换,分别获得了72.2%和60.4%的检测精度;在引入双分支结构的基础上,将红外分支替换为由CFE 模块组合成的主干网络,并加入双模态融合模块IRF后,双模态检测精度达到了76.3%;此外,将可见光特征提取网络更换为由TFE 模块组合成的主干网络,检测精度提升至76.5%;当将红外和可见光特征提取模块同时替换为CFE 和TFE,并加入双模态融合模块IRF 后,检测精度达到77.2%,较基准模型单独检测可见光和红外图像分别提升了17.4%和5.7%。

表1 在KAIST 数据集上的消融实验Table 1 Ablation experiment on the KAIST dataset
在FLIR 数据集上的消融实验结果如表2 所示。在YOLOv5 模型上仅输入红外图像时,检测精度为73.9%;使用CFE 特征提取模块替换原始特征提取模块后,检测精度提升为82.4%;同样地,单独输入可见光图像时,检测精度为67.8%;通过使用TFE 替换原始特征提取模块,检测精度达到80%;在引入双分支结构的基础上,将红外分支替换为CFE 组合成的主干网络,并引入双模态融合模块IRF,检测精度显著提升至85.3%;通过添加双模态融合模块IRF,并将可见光特征提取模块替换为TFE 模块,检测精度提升至84.9%;同时将红外和可见光特征提取模块替换为CFE 和TFE,并引入双模态融合模块IRF 后,检测精度达到85.5%,较基准模型单独检测可见光和红外图像分别提升了17.7%和11.6%。

表2 在FLIR 数据集上的消融实验Table 2 Ablation experiment on the FLIR dataset
在GIR 数据集上的消融实验结果如表3 所示。仅输入红外图像时,基于YOLOv5 模型的检测精度为76.8%;使用CFE 组成的特征提取网络替换原始特征提取网络后,检测精度为84.4%;当在YOLOv5 模型仅输入可见光图像时,检测精度为89.9%;将特征提取网络替换为由TFE 组成的特征提取网络后,检测精度提升为91.1%;在同时输入红外和可见光图像的情况下,将红外分支替换为由CFE 组合成的特征提取网络,并引入双模态融合模块IRF,检测精度达到91.6%;添加双模态融合模块IRF 并将可见光特征提取网络替换为TFE 组合成的特征提取网络,检测精度保持在91.3%;而将红外特征提取模块替换为CFE,可见光特征提取模块替换为TFE,并添加双模态融合模块IRF 后,检测精度达到91.7%。较基准模型单独检测可见光和红外图像分别提升了1.8%和14.9%。
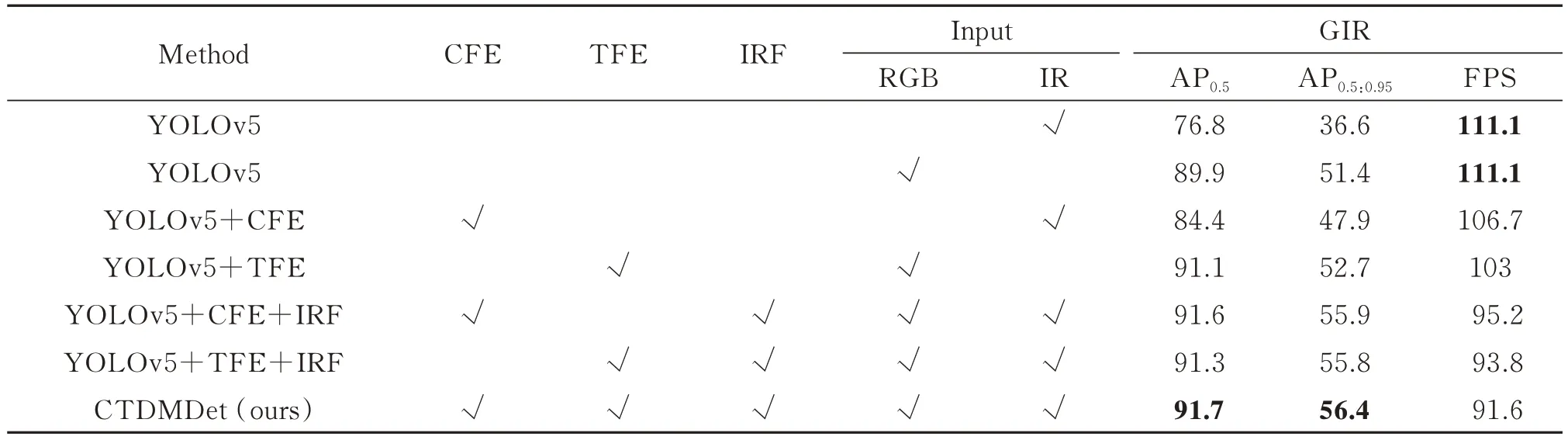
表3 在GIR 数据集上的消融实验Table 3 Ablation experiment on the GIR dataset
在三个数据集上的消融实验结果证明了提出的双模态特征提取网络和融合模块在双模态目标检测任务中具备显著的性能优势,有效地提升了检测精度,丰富了特征信息。
2.4 定性分析
为了更加直观地对比基准算法与本文所提出方法在检测任务中的表现,在三个数据集上进行了定性分析,结果分别如图5~7 所示。其中,图(a)、(b)呈现了真实目标框(Ground Truth, GT)在两种模态图像上的位置信息,图(c)、(d)分别展示了基准算法在可见光图像和红外图像上的检测结果,图(e)、(f)分别展示了本文所提算法在可见光图像和红外图像上的检测结果。

图5 在KAIST 数据集上的定性分析结果Fig. 5 Qualitative analysis results on the KAIST dataset

图6 在FLIR 数据集上的定性分析结果Fig. 6 Qualitative analysis results on the FLIR dataset

图7 在GIR 数据集上的定性分析结果Fig. 7 Qualitative analysis results on the GIR dataset
由定性分析结果可以看到,本文提出的算法在各种场景下均展现出优越的检测性能,涵盖了强光、夜晚、遮挡等复杂环境,还成功地解决了基准算法中出现的漏检和误检问题。例如,在图5 中的第三行,夜间场景下基准算法在可见光图像上漏检了三个目标,在红外图像上漏检了两个目标,而本文算法能准确地检测到所有目标;在图6 中的第一行,白天光照强烈时,基准算法在两种图像上均未能检测到小目标,而本文算法在可见光和红外图像上均实现了准确的检测;在图7 中的第三行,当目标被遮挡时,基准算法在红外和可见光图像上均未检测到目标,而本文算法通过融合两种模态的信息成功地检测到所有目标。这些定性分析结果进一步验证了所提算法在多种复杂场景下的优越性能。
2.5 定量分析
为了全面评估所提算法的有效性,在KAIST、FLIR 和GIR 数据集上同当前主流的双模态融合目标检测算法进行了比较。同时,为了验证所提出的单模态特征提取网络的性能,分别在红外和可见光单模态图像上同部分主流单模态目标检测算法也进行了比较。为确保实验的公平公正,在相同的硬件和软件环境下分别部署了本文所提算法和对比算法。对于对比算法,严格遵循了原始论文中的实验设置和参数设定,以保持一致性。评估过程中统一采用目标检测常用指标,如AP0.5、AP0.5:0.95等,确保实验结果的可比性和科学性。比较结果如表4 所示。

表4 KAIST、FLIR、GIR 数据集上的定量分析结果Table 4 Quantitative analysis results on the KAIST, FLIR, and GIR datasets
从表4 的数据可以观察到,在KAIST 数据集上,本文所提出的红外、可见光特征提取网络在单模态检测中分别获得了72.2%、60.4%的检测精度。在FLIR 数据集上,其红外、可见光单模态检测精度分别达到了82.4%、80%。在GIR 数据集上,红外、可见光单模态检测精度分别达到了84.4%、91.1%。结果表明,提出的单模态特征提取网络虽然在速度方面略有下降,但在检测性能上均得到了显著提升,超越了经典的单模态检测算法。此外,在双模态融合方面,该算法在KAIST 数据集上实现了77.2%的检测精度,在FLIR 数据集上达到了85.5%,在GIR 数据集上达到了91.7%。相比经典的双模态融合算法,如CFT、RISNet、CSAA等,该算法在检测精度和速度上都展现出了明显的提升。这些结果进一步突显了本文算法在多种数据集和场景下的优越性能,以及其在双模态目标检测领域的优势。
3 结论
本文提出了一种基于CNN-Transformer 双模态特征融合的目标检测算法(CTDMDet),通过构建双流特征提取网络,采用CNN 和Transformer 结构分别对红外与可见光图像进行特征提取,有效地提升了对不同模态图像的信息获取能力。并且,通过双模态特征融合模块,成功实现了不同尺度、不同模态的特征信息的有效融合,从而实现了跨模态信息的互补和目标检测性能的显著提升。
在KAIST、FLIR 数据集上,本算法在红外和可见光图像的检测精度分别获得了显著的提升,为目标检测的不同环境提供了更为准确的解决方案。同时,在自建的GIR 数据集上,本文算法也实现了明显的检测精度提升,从而进一步证明了其适用性和鲁棒性。
未来的工作将集中在进一步优化算法的运行速度,以满足实际应用中的实时性要求。此外,计划在更复杂和多样化的场景中测试算法的鲁棒性,进一步验证其在不同应用领域的可靠性和稳定性。随着深度学习和计算机视觉领域的不断发展,还将会继续探索更先进的模型架构和融合策略,以进一步提升双模态目标检测的性能,并将其应用于更广泛的实际场景中。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
电子制作(2019年7期)2019-04-25 13:17:14
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
光学精密工程(2016年3期)2016-11-07 09:03:43
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
噪声与振动控制(2015年4期)2015-01-01 07:08:21
计算物理(2014年2期)2014-03-11 17:01:39
