
基于任务感知关系网络的少样本图像分类
2024-04-11 07:29郭礼华王广飞
电子与信息学报 2024年3期
郭礼华 王广飞
(华南理工大学电子与信息学院 广州 510641)
1 引言
在图像分类任务中,小样本学习(Few-Shot Learning, FSL)旨在通过对新类别少量图像样本的学习,获得对该类别图像的识别能力。度量学习和元学习是两大解决小样本学习的方法。元学习方法通过跨任务之间的学习,在不同任务之间学习以适配新任务。度量学习是学习样本对之间的相似度量,从而获取可以推广至其他类别样本的度量能力。由于度量学习的泛化能力更强,其也是目前主流的小样本图像分类方法。
经典的关系网络(Relation Networks, RN)在度量阶段采用卷积神经网络对图像特征之间的相似性进行度量[1]。可是RN模型在类别原型生成阶段和相似性度量阶段都缺乏对分类任务整体信息的感知,其中类别原型的选择不能反映分类任务中图像的分布信息,并且度量模块由于缺乏对任务全局信息的感知,此模型缺乏对特定任务的适应能力。为了提升模型的适应能力,本文早期工作位置感知的关系网络(Position-Awareness Relation Network,PARN)模型[2]尝试给每个位置增加注意力机制,但是其侧重于关注空间信息关系,缺乏建模任务信息。Oreshkin等人[3]通过尺度缩放来设计一个和任务相关的度量空间,实验结果也验证了任务信息的加入可以提升少样本图像分类的性能。但是这种设计的任务相关的度量空间仅依赖尺度缩放,缺乏更深入的建模任务相关信息。根据心理学研究成果1https://plato.stanford.edu/entries/perceptual-learning/,人在学习过程中,都会提前感知学习任务,再根据学习任务进行相应的学习。如果机器模型也能提前对任务进行分类,然后再进行学习是符合人类学习的规律,这样的学习范式可以提升学习效率。基于此,本文提出任务感知的关系网络模型(Task-Aware Relation Network, TARN)。相比于RN, TARN模型引入模糊C均值(Fuzzy C-Means, FCM)聚类算法,生成基于任务全局分布的任务相关类别原型;同时设计任务相关注意力机制(Task Correlation Attention mechanism, TCA)。TCA使得输出特征在每一个空间位置都聚合有任务全局信息,并自适应地学习局部特征。
本文的主要贡献包括3个方面:
(1)提出一种新的原型生成方式,利用FCM聚类算法生成任务相关的类别原型。
(2)设计任务相关注意力机制,计算局部特征与任务全局之间的相关性,然后将其相关性作为注意力权重赋予每个局部特征。
(3)设计任务感知的关系网络模型,融合任务相关的类别原型生成和任务相关注意力机制。
2 相关工作
基于度量学习的小样本学习算法旨在通过“学习比较”的方法解决小样本图像分类问题,即通过比较两个图像之间的相似度去判定图像所属类别。Sung等人[1]设计提升度量模块的度量能力的方法,提出关系网络模型(RN)。位置感知的关系网络(PARN)模型[2]尝试在RN网络模型的基础上,给每个位置增加注意力机制来获取特征空间信息的关系。Oreshkin等人[3]则是在原型网络的基础上引入任务嵌入网络。Maniparambil等人[4]提出一种基变换器(base transformer)的方法,这种方法关注到在基础数据集的特征空间里面存在大量的相关局部区域,利用这些局部区域的相关性可以很好地对示例表征进行建模。Liu等人[5]认为传统方法使用一组局部特征作为图像表示而不是采取混合的局部特征,为此提出互中心化学习的思想来关联图像局部特征的稠密表示。
基于元学习的小样本学习算法一般是设计一些迭代优化的策略,指导模型通过大量分类任务学习到有助于模型快速优化的通用知识,例如模型初始化参数,模型参数优化策略等。Finn等人[6]提出了一种模型无关的元学习方法(Model Agnostic Meta Learning, MAML)。MAML旨在通过对大量分类子任务的学习,学习得到模型的初始化参数。Nichol等人[7]提出1阶梯度近似和低维隐空间用于解决MAML算法中计算量过大的问题。Oh等人[8]通过修改Meta学习次序,在模型更新过程中,固定分类器参数,只更新特征学习部分参数,提高特征表达学习能力。Chen等人[9]则提出了一个新的元学习的新基准,通过先在基础类上预训练一个分类模型,然后保留分类模型地编码器作为特征提取的骨干网络。最后微调骨干网络进行元训练。Shen等人[10]也认为在元学习过程中需要在基础模型里面固定或者微调某些特定层参数来实现部分知识的迁移。Snell等人[11]则是利用贝叶斯学习框架将一些先验假设建模到少样本学习中,克服算法的过拟合问题。
目前小样本图像分类研究是一种百家争鸣状态,本文从度量学习角度出发,引入任务相关信息,设计任务相关的类别原型和注意力机制,这种思路不同于传统方法。
3 任务感知的关系网络模型
3.1 整体框架
TARN模型的整体框架如图1所示,给定一个图像分类任务,首先对支持集图像和查询集图像利用特征提取网络进行特征提取,得到对应的支持集图像特征fs和查询集图像特征fq。为了获得任务中的图像分布全局信息,采用FCM算法对分类任务中的全部图像特征进行聚类,以便生成任务相关类别原型ft(更多细节参考3.2节)。最后为了使得度量模块获得对任务全局信息的感知,本文提出TCA算法,将任务相关类别原型ft的全局信息聚合到支持集类别原型fs和查询集图像特征fq的每一个空间位置(更多细节参考3.3节)。

图1 TARN模型整体框架
3.2 基于FCM聚类的类别原型生成方法
RN模型将支持集中同一类别图像特征的均值作为类别原型,用于后续度量模块的相似性计算。但是由于小样本学习任务中只有少量标注图像,所以生成的类别原型不准确。另外,由于类间相似性和类内差异性,支持集中某些远离真正类别中心的图像会在一定程度上破坏类别原型的类别表征能力。针对上述问题,本文提出采用FCM算法,依据任务全局分布信息进行聚类,生成任务相关的类别原型,并设定基于FCM聚类的类别原型数量等于数据集中类别的数量。
图2给出FCM模块计算任务相关类别原型的示意图。对于特征提取模块输出的支持集类别原型特征∈R[c,h,w]和查询集图像特征∈R[c,h,w],其中c,h,w分别表示图像特征的通道维度大小、空间维度的高度和宽度,i ∈[1,s]和j ∈[1,b]分别表示分类任务中s个类别原型中的第i个,和b个查询集样本中的第j个。利用卷积神经网络计算类别原型和查询集样本的隶属度信息,得到隶属度矩阵Ms∈R[s,s]和Mq∈R[s,b]用以分别表示类别原型的隶属度和查询样本的隶属度。隶属度矩阵中元素Mi,j的计算为

图2 FCM模块计算任务相关类别原型的示意图
其中,hϵ(·)表示用于计算隶属度大小的卷积神经网络。fi代表第i个类别的类别原型,fj则在Ms和Mq的计算中分别代表第j个类别的类别原型和第j个查询集图像特征,fi和fj在特征维度进行级联后送入卷积神经网络计算隶属度大小,并且卷积神经网络的输出经过sigmoid函数映射到[0, 1]。对矩阵Ms和Mq在第1维度进行l1归一化,使得每一个图像特征对任务中s个类别的隶属度大小之和为1,即每个图像属于s个类别得可能性之和为1。最后基于隶属度矩阵计算任务相关类别原型ft,其中类别i的任务相关类别原型f计算为
在上述任务相关类别原型ft的计算过程中。一方面通过隶属度矩阵Ms的计算,从类间相似度的角度调整类别原型fs对类别原型ft的贡献度大小,减弱远离类别中心的图像对ft表征能力的破坏。另一方面通过特征隶属度矩阵Mq的计算,使得查询集中的无标签样本可以参与ft的计算,在一定程度上利用分类任务中无标注样本实现了数据增强的目的。
3.3 任务相关注意力机制(TCA)
由于分类任务中类间相似度的存在,面对不同分类任务时应当关注的部分也是不同的。RN模型中1对1的度量方式缺乏对任务全局信息的感知,不能利用任务全局分布信息找到有助于正确分类的局部特征,从而在一定程度上限制了模型在特定任务上的性能表现。为此本文提出TCA算法,采用类似非局部神经网络中非局部操作的思想,将任务相关类别原型的全局信息聚合到输出特征空间维度的每一个位置上。
TCA算法流程如图3所示,当给定分类任务中的一个查询集样本特征fq、类别原型特征fs和任务相关的类别原型特征ft时,TCA算法通过计算ft全局信息在fq和fs空间维度位置的响应得到fqt和fst。ft是基于任务全局分布信息聚类得到的,则fqt和fst空间维度的每个位置都包含有任务全局信息在该位置的响应。最后将fq,fs,则fqt,fst在特征维度通道进行级联并送入卷积神经网络进行相似度度量,则每次卷积操作都可以包含任务全局信息,并能根据任务全局信息在局部位置的响应,自适应地对局部特征的关注度进行学习。

图3 TCA算法流程
TCA算法的具体计算过程如下:在给定特征fq∈R[c,h,w]和ft∈R[c,h,w]计算fqt的过程中。为了计算ft全局信息在fq空间维度上每个位置的响应,需要计算fq局部特征和ft局部特征之间的相关性,并以相关性大小作为权重计算ft所有特征的加权和,作为ft全局信息在fq对应位置的响应。首先使用卷积核尺寸1 ×1的卷积层对fq和ft进行线性映射,得到fq′∈R[c′,h,w]和ft′∈R[c′,h,w],并将其进行维度转换得到fq′∈R[hw,c′]和ft′∈R[hw,c′],然后进行相关性计算得到任务注意力图At∈R[hw,hw]。当 计 算fq′的 空间 位置i( 1≤i ≤hw)和ft′的空间位置j( 1≤j ≤hw)对应局部特征之间的相关性A时 ,从对应位置分别取得特征向量∈R[c′]和∈R[c′] , 并记在对应位置的逐点运算操作,即由计算得到。在具体实践中,选择余弦相似度函数用于相关性计算,则的计算为
征向量。将fq′和ft′在特征通道维度进行l2归一化,则Aqt的 计算过程可以表示为如式(4)的矩阵运算形式
利用At包含的相关性信息充当权重,计算ft所有位置的特征加权和,然后作为在fq特定位置的响应,其中ft全局信息在fq空间位置i( 1≤i ≤hw)的响应的计算为
则fqt可由如式(6)的矩阵运算得到
再将fqt进行维度转化得到fqt∈R[c′,h,w],并通过1×1卷积神经网络将特征通道维度还原为c。
给定fs和ft,可以采用同样的方式计算ft全局信息在fs局部位置的响应,得到fst。经过TCA算法的计算后,将fq,fs,fqt,fst在特征维度进行级联,送入TARN模型的度量模块。则度量模块中的卷积运算可以根据任务全局信息在局部位置的响应,自适应地对局部位置卷积所得特征进行比较。从而使得TARN模型学习到更加鲁棒的度量。
4 实验设置与环境
4.1 数据集和网络结构介绍
实验选用两个经典小样本图像分类数据集,即Mini-ImageNet[12]和Tiered-ImageNet[13]。Mini-ImageNet包含有100类共60 000张RGB彩色图像,其中每一类图像有600个样本,图像统一大小为84 ×84,Mini-ImageNet划分64个类作为训练集,16个类作为验证集,20个类作为测试集。Tiered-ImageNet包含了更多的图像类别,并且采用了层级划分的策略。Tiered-ImageNet将608个类别共计779 165张图片划分为34个大的类别。
本文TARN模型的特征提取网络可以采用两种通用特征提取网络:4层卷积层网络(Conv4)和12层残差网络(ResNet12)。Conv4拥有4层卷积层,每个卷积层输出特征通道数为64,卷积核尺寸为3×3,其中每层卷积层后面连接有批量归一化层和ReLU激活层,并且最后两层卷积层后连接有2×2的最大池化层。ResNet12则是文献[14]中的结构。模型利用Sigmoid运算将度量模块的输出结果映射到0~1之间,作为对应查询集图像与对应类别之间的相似度结果。
4.2 实验环境与相关设置
实验系统环境为Ubuntu 18.04系统,英伟达RTX 2080Ti(11GB), PyTorch(1.5.1)深度学习框架。实验采用Adam优化算法对模型进行端到端的训练,训练开始学习率初始值设置为0.001,每经过100次迭代后,学习率降低1/2。对于5-way 1-shot任务和5-way 5-shot任务,在训练过程中,查询集中每个类别的样本数量分别为15张和10张;而在验证和测试过程中查询集中每个类别的样本数量统一为15张。通过在训练集中随机采样的方式得到100 000个分类任务用于TARN模型的训练。并且每经过2 000个分类任务训练,就通过在验证集中随机采样的600个分类任务对模型的性能进行验证,并根据模型在这些分类任务中的平均分类准确率,选择最优的模型权重参数进行保存。训练过程结束后,从测试集中采样600个分类任务对模型的性能进行测试,并将模型的平均分类准确率作为模型的性能指标。这些数据划分类似经典RN算法的实验设置。
4.3 实验结果与分析
对比算法主要有以下几类:(1)元学习(Reptile[7], SNAL[14], BOIL[8], Meta-Baseline[9],OVE[11], P-Transfer[10]和MELR[15]);(2)度量学习(RN[1], PARN[2], TADAM[3], FEAT[16], DSN[17],NCA[18]和UniSiam[19]);(3)注意力机制(PSST[20],BaseTransformer[4]和MCL[5])。 给出的对比算法涵盖了基于元学习、度量学习和注意力机制的主流小样本学习算法。
表1给出了本文与其他小样本图像分类算法在Mini-ImageNet数据集的分类准确率结果。通过实验结果对比可以看到,在Mini-ImageNet数据集上,采用Conv4作为特征提取网络的情况下,TARN模型通过FCM模块和TCA模块的加入,5-way 1-shot和5-way 5-shot设置下,TARN模型的分类准确率比RN模型分别提高了8.15%和7.0%;当改用更深层次的残差网络ResNet12进行特征提取,TARN模型的分类准确率比RN模型分别提高了7.81%和6.7%。与PARN相比,在数据集Mini-ImageNet上,5-way 1-shot设置中分类准确率也提高了1.24%。与其他的度量学习方法,如DSN 和NCA, 5-way 5-shot设置下,本文TARN比DSN识别精度高1.22%,比NCA识别精度高2.54%。在5-way 1-shot的设置下,本文TARN模型和基于注意力的PSST方法比,识别精度有0.77%的提升。相比元学习的P-Transfer,在P-Transfer引入外部数据辅助的情况下,无外部数据帮助的TARN模型的识别精度仍高0.61%。最后本文TARN与最近几年的小样本图像分类算法性能比较,本文TARN模型在此数据集上都获得了最佳的识别精度。

表1 Mini-ImageNet数据集上小样本分类准确率(%)
表2给出了本文与对比小样本学习算法在Tiered-ImageNet数据集上的分类准确率结果。通过实验结果对比可以看到,在Tiered-ImageNet数据集上,当采用特征提取Conv4网络时,本文TARN模型和RN相比,5-way 1-shot和5-way 5-shot设置中的分类准确率分别提高了4.77%和5.03%。当采用更深层次的特征提取网络ResNet12时,本文TARN模型和RN相比,5-way 1-shot和5-way 5-shot设置中的分类准确率分别提高了7.81%和6.7%,TARN模型对比RN模型的性能提升更为显著。主要原因在于浅层特征提取网络并没有很好地学习到图像的特性信息,从而限制了模型的整体性能。当采用更深层次的特征提取网络时,输出特征包含了更丰富的图像特征信息,因而提出的FCM模块和TCA模块可以获得更加丰富的任务相关信息,从而本文TARN算法获得更显著的性能提升。与其他的度量学习方法,如DSN, NCA和UniSiam,5-way 1-shot设置下,本文TARN比DSN识别精度高7.77%,比NCA识别精度高5.64%,比UniSiam高6.98%,表明了本文TARN有强大的极少样本学习能力。虽然在5-way 5-shot下,TARN比MELR低0.001 6(这么小的性能波动受测试分组和测试方差等多种因素影响,并不意味着本文方法比MELR方法性能低),但在5-way 1-shot下TARN比MELR高出1.85%,表现出更好的少样本学习能力。最后本文TARN与最近几年的其他小样本图像分类算法性能比较,本文TARN模型在此数据集上都获得了最佳的识别精度。
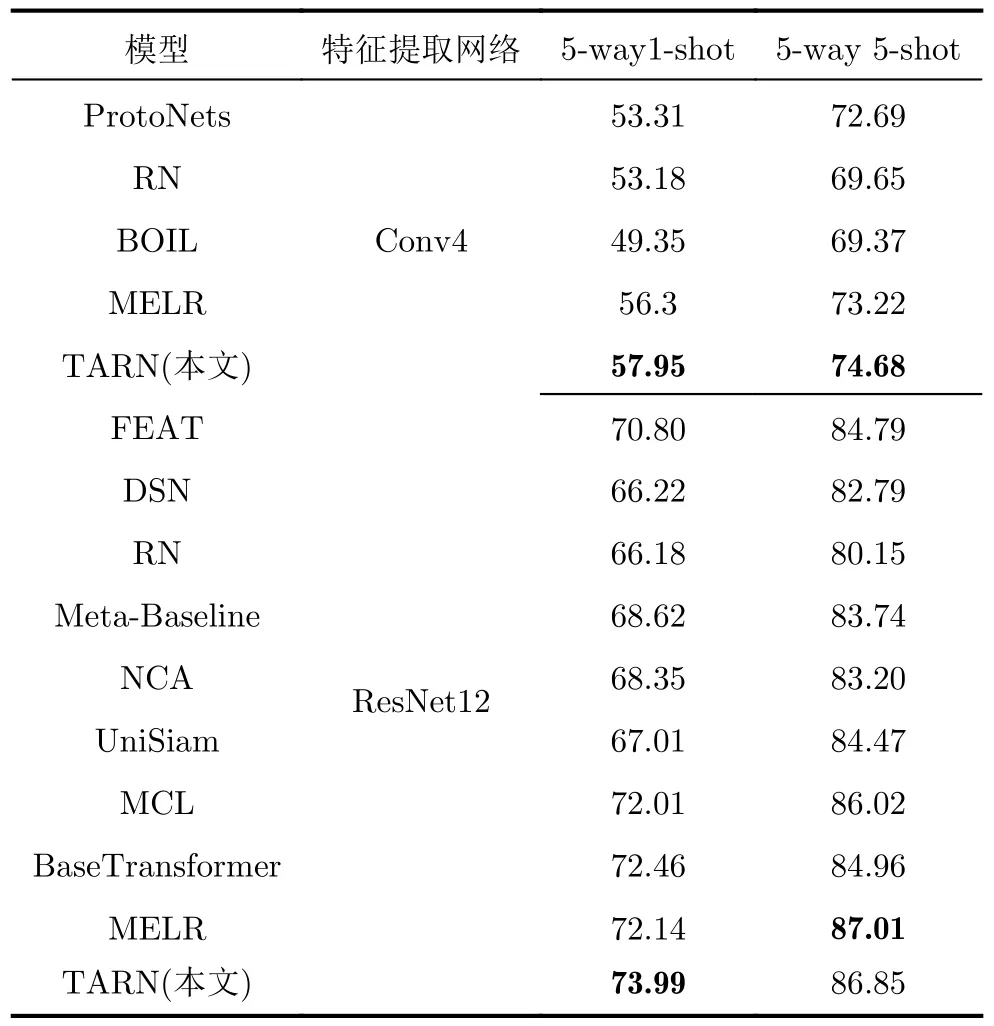
表2 Tiered-ImageNet数据集上小样本分类准确率(%)
为了更直观地观察TARN算法的有效性,本文使用权重化类别响应梯度图方法(Gradient-weighted Class Activation Mapping, Grad-CAM)[21]来获取热力图,以可视化显示图像分类时深度网络模型的误差梯度响应情况。图4是本文TARN方法和RN,PARN的对照Grad-CAM热力图,从图4可见,本文的TARN方法的Grad-CAM热力图更聚焦于分类物体,表现出TARN对于分类任务的感知能力,这也更进一步说明本文的TARN方法的有效性。

图4 TARN与RN, PARN的对照Grad-CAM热力图
下面比较算法的运算时间复杂度,实验选用RN, PARN和本文的TARN作为测试对象,这3种算法分别采用两种特征提取网络(即Conv4和Res-Net12),模型训练50个Epoch后统计模型的训练时间和测试时间。如表3所示,由于ResNet12特征提取网络的深度和复杂度都高于Conv4,所以基于ResNet12特征提取网络的训练时间都比基于Conv4特征提取网络的训练时间长。相比PARN和TARN,不管是训练时间还是测试时间,本文的TARN比PARN稍有所增加,但表1结果显示,TARN的实验精度要高于PARN。由此可见,本文TARN相比PARN牺牲了少量的运算复杂度,但提升了模型的分类性能。

表3 3种模型的训练时间和测试时间对比
本文利用经典的非线性降维t分布统计邻域嵌入 (t-distributed Stochastic Neighbor Embedding,t-SNE)算法将查询样本与原型进行降维后,降维后可视化图如图5所示。系统采用5-way 1-shot模式,共5个类别的数据,图中圆点是查询样本的特征,方块是关系网络所提取的类别原型,五角星是本文经过模糊聚类后所提取的类别原型。降维后可视化图结果可见,查询样本更接近本文模糊聚类后所提取的类别原型,当算法进行度量学习的时候,本文的算法进行查询样本类别的判断时,更能找到正确的类别原型,并做正确的分类判断。
4.4 消融实验
为了验证FCM模块和TCA模块的有效性,将RN模型、FCM算法模块以及TCA模块进行组合。此外还将FCM算法模块替换为硬判C均值聚类算法(HCM),即采用硬性划分的方式对任务中的样本特征进行聚类。FCM模型和HCM模型拥有相同的可训练参数量,并且采用了相同的训练策略,以此保证对比结果的有效性。在Mini-ImageNet数据集上,采用Conv4作为特征提取网络,对上述各种算法模型的分类性能进行比较,实验结果如表4。根据实验结果对比可以看出,FCM比HCM在5-way 1-shot和5-way 5-shot分类任务中均获得了更好的分类性能。并且可以看到在5-way 1-shot分类任务中,FCM模块比HCM模块获得了更大的性能提升。原因在于5-way 1-shot任务中支持集中样本数量更少,类别原型的类别表征能力更差,因此普通C均值聚类方法会将更多查询集图像错误分类,导致聚类得到的任务相关的类别原型的类别表征能力遭到破坏。而模糊C均值聚类算法则可以基于任务样本特征分布信息调整原类别原型对于任务相关类别原型的贡献度大小,从而在一定程度上减弱支持集中样本数量不足带来的影响。通过实验结果的对比,FCM算法的有效性和优势得到了证明。此外,增加TCA模块后,在两个实验设置下,其性能还可以得到提升,实验结果也同样证明了TCA模块的有效性和优势。

表4 Mini-ImageNet数据集的消融实验(%)
5 结论
从提升关系网络对于任务感知的能力角度考虑,本文提出基于任务感知的关系网络(TARN)用于提升小样本图像分类性能。其主要包括两大模块:(1)提出模糊C均值(FCM)聚类模块,对全体样本特征进行聚类,得到包含任务全局信息的任务相关类别原型。(2)提出任务相关注意力机制(TCA),通过计算任务全局信息在输出特征空间维度局部位置的响应,使得度量阶段的卷积操作能够包含任务全局信息,并且自适应的学习对特定位置特征的关注度。在Mini-ImageNet数据集和Tiered-ImageNet数据集上,本文TARN模型和其他主流小样本学习模型进行实验对比,实验结果显示本文TARN模型可以获得比其他主流小样本学习模型更佳的识别精度。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15
数学年刊A辑(中文版)(2022年4期)2022-02-16
小资CHIC!ELEGANCE(2021年45期)2021-01-11
数学年刊A辑(中文版)(2019年3期)2019-10-08
英美文学研究论丛(2018年2期)2018-08-27
剑南文学(2016年14期)2016-08-22
中国学术期刊文摘(2016年1期)2016-02-13
新校长(2016年8期)2016-01-10
人间(2015年20期)2016-01-04
商事法论集(2014年1期)2014-06-27
