
智能交通感知新范式:面向元宇宙的交通标志检测架构
2024-04-11 07:29王俊帆高明煜何志伟董哲康缪其恒
电子与信息学报 2024年3期
王俊帆 陈 毅 高明煜 何志伟 董哲康* 缪其恒
①(杭州电子科技大学电子信息学院 杭州 310018)
②(浙江省装备电子重点实验室 杭州 310018)
③(浙江大学电气工程学院 杭州 310027)
④(浙江华锐捷技术有限公司 杭州 310051)
1 引言
元宇宙被认为是人工智能发展的下一个演变,专注于在虚拟世界中创造沉浸式体验[1]。元宇宙概念的兴起为虚拟世界和现实世界之间的并行智能交通系统构建成为可能。交通标志是向智能车辆或驾驶员传递道路信息的重要媒介,其根据道路状况、交通事故、天气变化需要进行动态的调整更新,实现对其高效精确的识别已成为现有自动驾驶和智能车辆的重要辅助技术。
现有基于学习的交通标志检测器主要从数据和模型架构两方面进行优化以满足实际需求。数据方面,文献[2]提出挑战性条件下的交通标志检测数据集CURE-TSD,以此克服恶劣条件下检测性能不佳的问题。清华大学和腾讯合作制作的交通标志数据集(Tsinghua-Tencent 100K, TT100K)[3],其数据总量达到100,000张,设置类别数为221类。瑞士交通标志数据集(Swedish Traffic Signs Dataset,STSD)数据集[4]记录了350多条公路的瑞典公路和城市交通场景,包含3,488个交通标志,超过20 000张图像(其中20%已标注)。文献[5-7]通过数据增强技术对已有的交通标志数据集进行扩充和丰富,以更好地训练模型。在模型架构方面,文献[8-10]基于卷积神经网络(Convolution Neural Network,CNN),通过修改网络结构来提高网络的泛化能力和鲁棒性来应对各种环境挑战。目前热门的Transformer[11-13]架构通过图像分块操作建立全图的长距离连接,从而能够学习到更多信息,提高模型的泛化性。具体地,文献[14]针对现有交通标志由于天气条件等外部因素导致检测性能低下的问题,提出多尺度交通标志检测器(Multi-scale Traffic Sign Detection, MTSDet),通过引入注意力机制来高效提取语义特征。本文之前的工作[15]通过特征金字塔的特征聚合来提高对特征的提取能力,从而提高模型的泛化性。
从上述两个方面着手在一定程度上能够高效实现交通标志检测,但是也存在着一定的问题:
数据方面,建立一个大型数据集需要昂贵的人工成本和时间成本。现有公开的交通标志数据集普遍存在着数据不平衡、场景多样性不足、数据数量较少等问题。由于标注标准的不统一,不能同时使用多个数据集进行训练和测试,数据集的区域性和单调性也会影响模型的泛化能力。
模型架构方面,许多研究基于CNN和Transformer对检测模型的结构进行优化,但是能否最大程度发挥其性能依然取决于训练数据的数量和质量,尤其是基于Transformer的方法需要大规模数据集的预训练才可以达到其预期检测性能。此外,模型本身的泛化能力对于其多场景应用也至关重要。
基于此,本文提出面向元宇宙的交通标志检测新范式。元宇宙可以创造一个与现实世界平行的人工维度空间,自定义构建高契合度的仿现实场景,为物理世界提供丰富数据。已有汽车公司如保时捷、现代在元宇宙体系下实现整车的设计和验证过程[16,17]。虚拟场景下的训练和测试,可以高效地实现对模型在不同场景下性能的全方面评估,提高了研发过程的效率和安全性。考虑到虚拟世界和物理世界存在一定的数据差异,虚拟数据训练下的模型难以完全适应真实场景,本文提出跨域目标检测架构来克服这一问题。此外,本文从模型结构角度出发,提出一个启发式注意力机制。本机制结合类激活映射[18]和视神经科学[19],提高检测模型对特征的学习和定位能力,从而使得其能够将虚拟数据特征中学习到的知识应用于真实场景,增强网络的泛化能力。本文的主要贡献如表1所示。
2 元宇宙交通标志检测框架
本文提出的面向元宇宙交通标志检测框架首先通过场景映射,构建平行于物理世界的人工维度空间(元宇宙);随后在元宇宙中利用虚拟数据完成检测算法的训练和测试,通过模型映射完成元宇宙到物理世界算法性能的高效统一。所提元宇宙交通标志检测框架如图1所示。
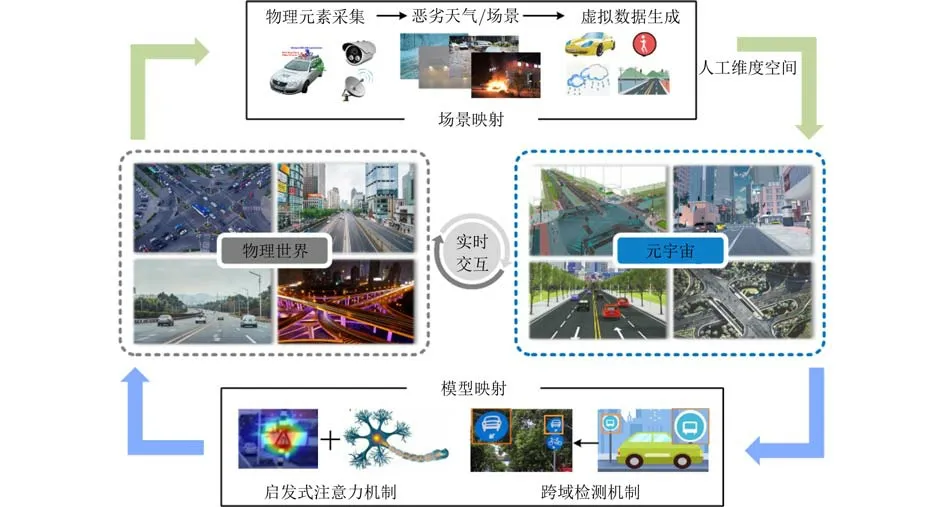
图1 面向元宇宙的交通标志检测框架
场景映射是物理世界中的各类元素在元宇宙一一表示的过程,从而建立一个基于物理世界的自定义人工维度空间。该过程实现了交通标志检测框架在数据层面的两种范式转变:交通数据收集的范式转变和技术测试的范式转变。
基于元宇宙的交通标志检测以人工生成大规模数据代替传统的传感器数据收集。元宇宙中生成环境和对象的方法主要有两种,一是通过反映物理世界来描绘的方法,二是创建新的虚拟环境的方法[20]。现有对元宇宙的空间构建大多通过开源模拟器或商业游戏引擎,如Unity 3DS MAX[21], OpenGL[22]和Google 3D[23]。物理世界被认为是众多元素的集合,具体地,本文将其分为自然元素和人工元素。自然元素包括天气(雨、雾、雪等),光照(曝光、昏暗、白天、黑夜等)、环境(乡村、野外、城市等);人工元素包括交通元素(汽车、人、车道线、交通标志等)、道路(高速公路、隧道等)、突发事故(火灾、车祸、堵塞等)。模拟器或游戏引擎可以通过各类元素的排列组合自定义完成人工维度空间的构建,即元宇宙。空间构建完成后,可在元宇宙中设置虚拟传感器以模拟实际传感器以生成不同的虚拟数据,从而完成对场景的自动标注。上述数据的构建和标注过程具体如图2所示。场景映射实现的另一个范式转变是虚拟测试和学习。高保真模拟对于交通标志检测器的测试中至关重要,对于自动驾驶中的人工智能(Artificial Intelligence, AI)技术,需要数亿公里才能证明它提供给了统计上安全的驾驶机会[24]。然而,一方面数亿公里的测试环境所需成本较高,且即使是数亿公里依然无法保证涵盖了所有可能遇到的交通环境,另一方面,物理世界的测试存在一定的安全隐患,若完全模拟实际交通场景,其测试风险将会进一步提高。元宇宙能够为交通标志检测提供大量测试场景,且在虚拟环境中的测试结果也可以向物理世界推荐额外的场景数据集以及检测器本身存在的不足[25]。

图2 元宇宙虚拟交通场景构建
模型映射被用于满足算法模型在元宇宙和物理世界中保持其性能一致性。因为虚拟数据集在分辨率、色彩、噪声等方面与真实数据具有一定的差异,且虚拟数据与真实数据的分布式不一致,这些导致虚拟数据上训练和测试完成的模型在物理世界应用时无法发挥其最大的性能。基于此,本文从模型训练和模型结构两方面进行优化,建立模型映射使得在元宇宙中训练和测试完成的模型能够无差别地应用于物理世界。首先,针对数据域不同的问题,本文提出基于域自适应目标检测方法构建元宇宙和物理世界中的模型。构建元宇宙域(Metaverse Model,MM)和物理世界域(Physical Model, PM)作为虚实空间中的模型,结合了知识蒸馏结构[26]与均值教师模型[27,28]来完成从元宇宙到物理世界的跨域交通标志目标检测。其次,本文提出了基于启发式注意力机制的交通标志检测网络。启发式注意力机制依托于视神经科学理论和特征可视化技术(Class Activation Mapping, CAM),能够提高检测网络的泛化能力和鲁棒性,从而保证了虚实场景转换时模型性能的一致性。在第3节中将对元宇宙交通标志检测框架中模型映射部分进行展开介绍。
3 元宇宙-物理世界模型映射
本节内容主要介绍了所提出的元宇宙到物理世界中所存在的模型映射,主要由跨域检测和启发式注意力组成,前者实现了元宇宙到物理世界的权重更新,后者优化模型结构从而提升了模型自身泛化能力和鲁棒性。模型映射使得虚拟数据下训练和测试完成的算法/模型在面对物理世界的场景时,能够具备同样的检测性能,使得面向元宇宙的交通标志检测架构具备实际应用意义,具体如图3所示。考虑重参数VGG (Re-parameterization VGG,RepVGG)网络[29]的灵活性和轻量化,本文采用其作为特征提取网络来完成对元宇宙下的标注源数据与物理世界中的未标注目标数据的特征提取。将特征提取网络生成的深层特征分别通过视觉注意力模块和CAM模块进行注意力干预操作,使得特征图中的无效特征与噪声特征被抑制,增强深层特征图中的细节表征和有效表征。其次将生成的3个特征图通过特征金字塔网络完成特征的深度融合,最后网络对其进行预测得到实际的预测结果。

图3 基于视神经科学的跨域目标检测网络
3.1 跨域检测
模型映射中的跨域检测中的MM和PM具备相同的网络结构。前者通过标准的梯度下降方式更新,而PM则通过指数移动平均(Exponential Moving Average, EMA)[30]方法使用来自MM的权重更新自身的权重。
基于元宇宙来完成交通标志检测的另一个优势在于不需要大面积采集现实世界的交通标志数据并一一标注。本文假设元宇宙中采集的数据Im均是带有标注的,其标志信息包括目标边界框信息和类别信息,例如第i张图片的目标边界框信息为Bi={Bj|, Bj=(xj, yj, wj, hj)},类别信息为Ci={Cj|, Cj∈(0, 1, ···, c)},其中N代表一张图像中包含的交通标志目标个数,c代表交通标志的总类别数。本文还假设在交通标志检测任务中,实际采集到的交通标志图像Ir是不存在对应的标注信息。所以本文预设定了两个数据域:(1)元宇宙下的源域Dm={ (,,C|)};(2)物理世界下的目标域Dr={(Ir|)}。MM和PM将分别从这两个数据域中挖掘信息,通过跨域目标检测网络完成源域到目标域的风格迁移,使得PM能够有效的检测现实世界中的交通标志。
元宇宙下的跨域检测框架如图4所示。本文通过在元宇宙使用标注源数据集Dm训练监督模型,并构建了损失函数如式(1)所示。通过使用回归损失和分类损失来加速元宇宙下模型的收敛。Lmeta(Im,Bm,Cm)代表元宇宙下训练的总损失,其包含了两个部分:回归损失Lres(Bm,Im)和 分类损失Lcls(Cm,Im)

图4 元宇宙下的跨域检测框架图
其中,Lres使用GIOU损失,其根据目标实际边界框和MM预测到的边界框,调整模型预测交通标志位置的能力,Lcls使用Focal损失,通过二值交叉熵计算分类概率和目标分数。
根据跨域目标检测结构,PM模型通过EMA方法从MM中完成权重更新。假设PM模型和MM模型的权重参数分别为Pp和Pm,在每一轮训练迭代过程中,P通过式(2)来更新Pr
其中,γ是指数因子,其理想值需要尽可能接近1.0,本文设置为0.999。
在域自适应目标检测任务进行中,本文首先将物理世界下未标记的目标数据Dp作为PM的输入。我们还将部分未标记的数据Ip作为MM的输入来训练。在蒸馏过程中,通过从PM模型的预测中选取具有高概率高置信度的边界框作为伪标签,MM模型通过训练降低源域与目标域之间的方差来增强模型的鲁棒性。本文通过使用蒸馏损失来降低两个模型之间预测的不一致性
其中FB(·)和FC(·)分别为RM模型预测分支的边界框坐标和类别信息以及最大的类别分数。GB(·)和GC(·)代表对应的过滤器。具体来说,本文在训练期间的每一轮迭代中均增加了一个评估过程,使用非极大值抑制(Non-Maximum Suppression, NMS)来过滤按目标置信度排序的预测边界框。然后本文将选择类别分数高于固定阈值的边界框作为伪标签来提供目标域(即物理世界)模型的实例信息。
3.2 启发式注意力机制
模型的泛化能力和鲁棒性反映了模型在面对全新数据时能否具有与测试结果相当的检测能力。对于元宇宙的交通标志检测架构而言,提高模型的泛化能力和鲁棒性能够使得其在虚拟数据训练和测试的条件下,在物理世界也具备同等的检测性能。注意力机制在人类视觉机制中可以解释为倾向于关注图像中辅助判断的信息,并忽略掉不相关的信息[31]。通过注意力机制,检测模型在训练阶段通过虚拟数据学习如何最大程度地关注和定位所需的目标信息,从而在物理世界的应用中可以忽略背景信息,仅关注已学习的目标信息,实现对目标的快速定位和检测。
视神经科学中早期到最近的理论模型认为,激活、选择和控制参与了大脑注意力的构建[32]。注意力是一个多维结构,它是一种状态,在该状态下存在一个最佳的激活水平,使得人们可以选择想要优先处理的信息,以控制我们的行动过程。大脑中神经元反应的选择性与兴奋/抑制连接息息相关[33]。信息量最大的神经元与周围神经元会表现出不同放电模式,同时大脑中存在的空间抑制现象会使得兴奋神经元对周围神经元活动进行抑制。
本文基于视神经科学理论,引入能量函数对单个神经元的重要性进行估计,以此实现3维注意权重的精简计算。首先,需要找到网络中对周围神经元具有较强空间抑制的神经元。本文通过测量目标神经元和其他神经元之间的线性可分性提取出这部分神经元。首先对目标神经元和其他神经元进行线性分类,并为二者分配对应标签,设置线性函数wx+b进行二分类,通过MSE损失函数来对w和b进行优化。每个神经元的能量函数定义为
其中,tˆ =wtt+bt,xˆi=wtxi+bt是关于t和xi的线性变化,其中t, xi分别表示输入特征图在单一通道中的目标神经元和其他神经元。i为空间维度上的索引,M=H×W,表示该通道中神经元的数量。wt和bt表示线性变换中的权重和偏差。通过最小化方程,式(4)等价于找到目标神经元t与同一通道中所有其他神经元之间的线性可分性。
这里为了简化方程,将yt和y0采用二进制标记,即yt=1, y0=-1。同时式(4)添加正则化符,最终表达式为
每一个通道上有M个神经元,因此理论上一个通道上具有M个能量函数。利用wt和bt的快速闭式解对式(5)进行简化
其中,ut和σ2分别为单一通道中除了目标神经元外的其余神经元的均值和方差。
假设单个通道中所有的像素遵循相同分布,因此可以计算所有神经元的均值和方差,并重新用于该通道上的所有神经元,以此降低计算成本。基于式(6)和式(7),能量函数更新为
由式(10)可得,能量函数越小,目标神经元与周围神经元的线性可区分性约到,也就是说明该神经元在网络中所发挥的作用越大。因此将Et的倒数作为每个神经元的重要性分数,最终使用Sigmoid函数来完成对权重图的细化。ME表示对特征图中全部通道进行能量函数求解,对于输入特征图I,其输出注意力图MA计算为
为了简化计算,式(10)的成立基于单个通道中像素遵循相同分布的原则,同时上述方法是对一个通道上的神经元进行处理,无法实现跨通道的信息交互。从全图视角而言,仅依靠能量函数,并不能准确的定位图中的目标区域。深度神经网络中的类激活映射能够通过计算卷积特征映射的加权和来突出感兴趣部分,定位目标对象区域,而CNN的浅层具有更大的空间分辨率,能够捕获目标对象的更精细的细节[34]。 因此,本文通过对浅层特征图的类激活映射作为语义感知输入,以约束通过能量函数得到的注意力图,引导其实现目标区域的聚焦。
首先,本文对第k个特征图在空间位置(i, j)上进行权重定义,具体为
将得到的MA和MC相乘,得到最终的注意力图M
4 实验分析
4.1 实验环境及设置
本文在统一的硬件环境下对本文所提出的方法和对比方法进行模型的训练和评估。硬件环境配置为:CPU(Intel(R) Xeon(R) Gold 6242R CPU @3.10 GHz)、内存(256 GB)、显卡(8×GeForce RTX 3 090)和显存(8×24 GB)等。初始训练神经网络的超参数设置为:Batch-size(8×32)、训练轮次Epochs(200)、图像缩放尺寸(640×640)。本文采用分布式训练,8张显卡将分别搭载32 Batch-size的数据进行训练。
4.2 数据集介绍
CURE-TSD[2]:CURE-TSD数据集是由乔治亚理工学院发布的用于研究交通标志识别算法在挑战性环境下的鲁棒性问题。该数据集由真实环境和非真实环境组成,其中的虚拟数据集对应于在虚拟环境中生成的合成序列,包含各类极端恶劣天气场景下的虚拟交通标志场景。CURE-TSD数据集包含14个交通标志类别,具体类别如图5所示。

图5 CURE-TSD类别信息
Virtual KITTI(VKITTI)[20]和KITTI[21]:VKITTI包含50个高分辨率的单目视频(21 260帧)。该数据集是由仿真图像合成的虚拟视频数据集,视频在不同的成像和天气条件下从城市环境中的5个不同虚拟世界生成。其中的虚拟世界通过Unity游戏引擎和一种新颖的真实到虚拟的克隆方法创建。该虚拟场景在KITTI数据集中存在对应的物理世界场景。
Meta-CURE:本文提出了一个元宇宙数据域下的数据集,称之为Meta-CURE(Metaverse CURE TSD)。该数据集是实际CURE-TSD的基础上,首先对CURE-TSD数据集做数据筛选,剔除相似场景的数据;其次,通过Unity3D构建出一比一对应的虚拟场景数据。通过这样的场景映射方法,本文得到了5 440张尺寸为1 628×1 236的元宇宙数据集。
4.3 训练设置
本文设置了两个训练过程,(1)物理世界域下训练;(2)元宇宙域与物理世界域联合跨域训练。
训练方式1本文采用CURE-TSD数据集中真实场景的图像以及对应的标签作为训练数据集与测试数据集。从后续的对比实验中可以看到,本文引用的交通标志检测方法以及本文所提出的方法均在训练方式1下完成训练并测试。
训练方式2在训练方式2中,本文将使用独立的两部分数据集进行训练,分别是元宇宙数据集(DV)和物理世界数据集(DR)。DV由CURE-TSD数据集中的虚拟部分以及Meta-CURE数据集组成,DR由CURE-TSD数据集中的真实部分组成。其中DV是具有标签的,DR是无标签的。本文基于训练方式2完成元宇宙域到物理世界域的模型跨域训练。
本文将训练完成后的模型在VKITTI以及对应的KITTI数据集上分别测试,以此来验证提出方法的鲁棒性和泛化能力。
4.4 结果分析
本文选取精度、召回率、mAP, AP50, APS,APM, APL7个指标来评判模型在检测精度上的性能。APS, APM, APL分别表示对于小、中、大尺寸的交通标志的平均检测精度。按照MS-COCO数据集对尺寸的划分标准[35],其中目标所占像素小于322的为小尺寸,大于322小于962的为中等尺寸,大于962的为大尺寸目标。同时通过指标FPS来衡量各个方法的检测速度。为了验证元宇宙下交通标志检测网络训练测试的有效性,所提出的网络在虚拟数据集和真实数据集下进行训练,并在同样的真实场景下进行测试,其结果如表2所示。

表2 在CURE-TSD数据集上的对比实验
其中,引用的对比方法均在CURE-TSD的真实数据集进行训练。本文对提出的网络的评估分别两种情况:(1)不使用跨域结构,仅在CURE-TSD的真实数据部分上训练并测试;(2)使用跨域结构,在整个CURE-TSD数据集以及Meta-CURE上训练并测试。可以看到,本文提出的方法在各个指标下均优于其他交通标志检测方法,并且所提出的跨域训练结构能够使得模型在真实场景下的精度高达89.7%,mAP高达48.0%,与在真实场景下训练的模型的精度仅相差2.7%。虚拟数据训练是元宇宙对交通标志检测任务的直接反映,表2中的4个对比实验均是在真实数据集下进行训练和测试,他们的检测精度也均低于本文在元宇宙下训练完成的结果。最后两行对比了所提出的网络分别在物理世界和元宇宙下训练后的测试结果。可以看到虚拟数据训练下的检测精度与真实数据训练下模型的检测精度并无明显差异。
进一步,表3通过训练数据的不同配置来验证所提出的方法能够通过虚拟数据代替真实场景数据,减少数据采集、标注的时间成本和人工成本。第1部分的训练数据为20 000张CURE-TSD数据集中的真实场景,第2部分包括10 000张的虚拟场景数据和5 000张的真实场景数据。测试数据集从CURE-TSD数据集中的真实场景数据组成。表3中可以看到,由于减少了真实场景数据训练,各个指标都会有所下降。对于4个对比方法,由于无法将虚拟数据中的学习知识能够较好的迁移到真实场景下,指标会出现大幅度下降,文献[10]在精度指标上下降了5.0%,本文提出的方法仅下降了1.2%。其他指标上,本文所提方法也可以较好的通过虚拟数据提取关键特征,在真实场景下具有较好的检测性能。
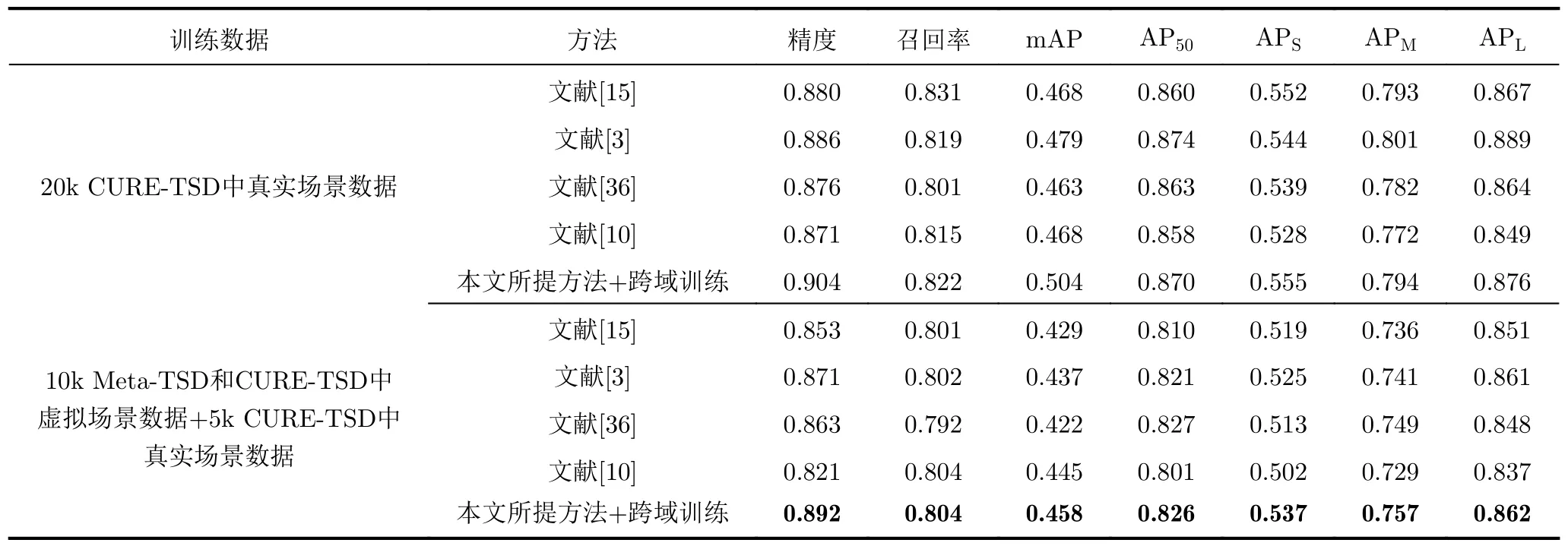
表3 不同训练数据配置下的对比实验
图6展示了上述方法在特殊场景下的测试样例,可以看到本文提出的方法在一些极端场景下也具有优异的检测结果,进一步说明元宇宙下的交通标志检测模型训练和测试对实际应用具有较大的贡献。为了体现元宇宙下虚拟数据的丰富性可以提高模型的泛化能力,本文将在训练方式2下训练完成的模型在KITTI和VKITTI数据集上进行测试,其结果如图7所示。

图6 本文提出的方法在CURE-TSD数据集上的测试结果

图7 本文所提提方法在VKITTI和KITTI上的测试结果
从图7可以直观的看到,无论是在虚拟场景还是真实场景,所训练完成的模型均有较好的检测性能。无论是不同尺寸还是不同场景下的交通标志,都能够对其进行精准的定位和识别。本文将两个数据集上各个类别的准确率和平均置信度进行统计,具体如表4所示。本文将置信度的阈值设置为0.7,对于置信度超过阈值的检测结果将其判断为识别正确。其中KITTI数据集上的平均测试精度为75.7%,在虚拟数据集VKITTI上的平均测试精度较KITTI数据集高了3.1%。KITTI和VKITTI上测试的平均置信度分别为74.7%和77.4%。选取5类出现次数较多的交通标志进行平均置信度的统计,其中“禁止停车”的标签识别率在KITTI和VKITTI上分别达到了82.1%和84.3%。可以看出启发式注意力机制能够在一定程度上提高模型的泛化能力,从而能够使得元宇宙下训练完成的模型更好的适应物理世界。

表4 提出方法在KITTI, VKITTI数据集上测试结果
图8展示了所提出的方法在Meta-CURE数据集上的测试结果。Meta-CURE为本文提出的元宇宙数据域下的交通标志数据集。数据集具备丰富多样的变化场景,涵盖了大部分车辆实际运行过程中所面临的工况。可以看到,通过元宇宙数据域的训练,模型在恶劣、复杂的天气下实现对小尺寸交通标志的精准定位和识别。

图8 本文所提方法在Meta-CURE数据集上的测试样例
图9对网络在特征提取过程中的热力图进行可视化。其中红色部分代表特征聚焦区域,文献[2,34]中的特征图的可视化热力图中,聚焦区域并不能准确的定位到所需要的目标,且会将注意力定位到无关背景中。本文基于CAM可以更好地定位到图中的交通标志所在区域,从而提高特征提取能力。

图9 本文所提方法与其他方法的热力图对比
4.5 消融实验
元宇宙为交通标志检测任务提供了更多更丰富的场景数据,可以更好地提高训练模型的鲁棒性。因此本节中的消融实验均在元宇宙环境下进行,本文将通过实验验证启发式注意力机制和跨域检测结构对元宇宙下交通标志检测任务的有效性。实验均在CURE-TSD数据集上训练和测试,并加入计算量(Giga Floating-point Operations Per Second,GFLOPs)作为计算复杂的衡量指标,结果如表5所示。

表5 在CURE-TSD数据集上的消融实验
可以看到,加入启发式注意力机制后,模型的各个检测精度均有所上升,能更好地适应物理世界的驾驶场景。同时,该结构上的变化对模型的尺寸规模并没有产生明显的影响,避免过大的计算负担,实现检测精度和检测速度之间较好的均衡。跨域检测模块的增加使得虚拟数据集下训练完成的模型可以更好的适应物理世界检测,在CURE-TSD数据集上训练完成的模型在真实数据上测试的精度从85.3%上升至89.7%。因此,本文提出的基于知识蒸馏和均值教师模型的模型映射对于元宇宙下交通标志检测任务具有重要意义,一定程度上弥补了因虚实数据差异导致的检测性能下降。
5 结束语
针对交通标志检测模型训练和测试条件苛刻,长距离的多工况测试成本昂贵,且无法保证其安全性和可靠性等问题,本文提出了一种面向元宇宙的交通标志检测新范式。通过开源模拟器建立虚拟数据集,提高数据的数量和多样性。构建了基于知识蒸馏和均值教师模型的模型映射方法,以实现从元宇宙到物理世界的跨域学习,减少模型对真实数据集的依赖性。此外,本文还提出了基于视神经科学和CAM的启发式注意力机制,能够加强检测器的目标定位和引导,提高模型对虚实数据的特征学习。提出的交通标志检测架构在CURE-TSD, VKITTI和KITTI数据集上表现出了优异的性能,即使在使用较少的真实数据进行训练的情况下,在现实世界中也能获得很好的检测效果。与当前先进的目标检测方法相比,本文方法在检测精度方面达到了89.7%。未来,作者团队将从虚拟数据构建出发,继续研究元宇宙对交通标志检测以及自动驾驶中其他视觉技术的帮助和影响。本文提出的方法为解决交通标志检测中的数据集规模和质量问题提供了新思路,也为实现多场景下的稳定高效运行提供了新的途径。
猜你喜欢
东方少年·布老虎画刊(2023年12期)2024-01-01
汽车实用技术(2022年9期)2022-05-20
自然杂志(2021年6期)2021-12-23
百家讲坛(2020年4期)2020-08-03
现代装饰(2018年5期)2018-05-26
课堂内外(高中版)(2017年1期)2017-03-22
小天使·一年级语数英综合(2016年8期)2016-05-14
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
小天使·一年级语数英综合(2014年7期)2014-06-26
