
A semantic segmentation-based underwater acoustic image transmission framework for cooperative SLAM
2024-04-11 03:36:54JiaxuLiGuangyaoHanShuaiChangXiaomeiFu
Defence Technology 2024年3期
Jiaxu Li, Guangyao Han, Shuai Chang, Xiaomei Fu
School of Marine Science and Technology, Tianjin University, Tianjin 300072, China
Keywords:Semantic segmentation Sonar image transmission Learning-based compression
ABSTRACT With the development of underwater sonar detection technology, simultaneous localization and mapping (SLAM) approach has attracted much attention in underwater navigation field in recent years.But the weak detection ability of a single vehicle limits the SLAM performance in wide areas.Thereby,cooperative SLAM using multiple vehicles has become an important research direction.The key factor of cooperative SLAM is timely and efficient sonar image transmission among underwater vehicles.However, the limited bandwidth of underwater acoustic channels contradicts a large amount of sonar image data.It is essential to compress the images before transmission.Recently, deep neural networks have great value in image compression by virtue of the powerful learning ability of neural networks, but the existing sonar image compression methods based on neural network usually focus on the pixel-level information without the semantic-level information.In this paper, we propose a novel underwater acoustic transmission scheme called UAT-SSIC that includes semantic segmentation-based sonar image compression (SSIC) framework and the joint source-channel codec, to improve the accuracy of the semantic information of the reconstructed sonar image at the receiver.The SSIC framework consists of Auto-Encoder structure-based sonar image compression network, which is measured by a semantic segmentation network's residual.Considering that sonar images have the characteristics of blurred target edges, the semantic segmentation network used a special dilated convolution neural network(DiCNN)to enhance segmentation accuracy by expanding the range of receptive fields.The joint sourcechannel codec with unequal error protection is proposed that adjusts the power level of the transmitted data, which deal with sonar image transmission error caused by the serious underwater acoustic channel.Experiment results demonstrate that our method preserves more semantic information, with advantages over existing methods at the same compression ratio.It also improves the error tolerance and packet loss resistance of transmission.
1.Introduction
With the development of underwater sonar detection technology, simultaneous localization and mapping (SLAM) approach has attracted much attention in underwater navigation field in recent ten years[1].But the weak detection ability of a single vehicle limits the SLAM performance in wide areas.Thereby, cooperative SLAM using multiple vehicles has become an important research direction.The key factor of cooperative SLAM is timely and efficient sonar image transmission among underwater vehicles [2].Achieving accurate and reliable sonar image transmission in underwater environment is of paramount importance [3,4].
But the underwater environment is complex and dynamic, and there are two difficulties that need to be dealt with.First, the available bandwidth for the underwater acoustic channel is limited.Sonar images can be transmitted in real time by means of compression at high ratio [5,6].Second, sonar images have the characteristics of blurred target boundaries [7].
Traditional compression methods(JPEG,JPEG2000,etc.)[8-10]are prone to block effects and decrease the level of detail, which makes the reconstructed image at the receiver difficult to be recognized after underwater acoustic transmission.In recent years,deep learning has made great achievements in the field of image compression by virtue of the powerful learning ability of neural networks [11,12].Compared with traditional methods, the deep learning method can learn deep image features,such as texture and shape features, which is one of the current research hotspots[13,14].
However, compression methods are usually evaluated and optimized by traditional quality metrics, such as peak signal-tonoise ratio (PSNR) or structural similarity (SSIM) [15], which are prone to misjudge due to the small pixel-level differences in sonar images.The semantic information [16,17] is recently regarded as the more suitable criterion to measure the quality of image compression and reconstruction by analyzing the image in terms of its texture and global structure.
Semantic information is appended to the compression network to improve the "realistic-ness" [18-21].Initially, Si et al.proposed an image compression framework(DeepSIC)[22]that incorporated semantics in the image compression procedure.It focuses on making the receiver obtain the corresponding semantic representations rather than the reconstructed image quality.In comparison to representation, the semantic map contains more detailed information about the original image.Some map-based image compression methods[23-25] have used semantic information to enhance image quality.A deep semantic segmentation-based layered image compression (DSSLIC) [23] framework was proposed,in which the segmentation map and the compact version of the image were employed to obtain a coarse reconstruction of the image.Because the residual has a lower data volume than the semantic map, an image compression framework with encoderdecoder matched semantic segmentation (EDMS) [26] was proposed, which extracted the segment from the up-sampled version of the compact image and calculated the semantic residual between the up-sample image and the original image on the encoder.However, all those methods need to extract the semantic information and cost the extra bandwidth to transmit them to the receiver, which is unsuitable for the limited underwater acoustic channel.
In this paper, we propose a novel underwater acoustic transmission scheme(UAT-SSIC)consists of the semantic segmentationbased image compression framework (SSIC) and the joint sourcechannel codec, which only requires the transmission of the compressed image without additional semantic segment.The SSIC framework consists of the Auto-Encoder structure-based sonar image compression and reconstruction network, which is measured by a semantic segmentation network's residual.For the semantic segmentation network, traditional sonar image segmentation methods,such as kernel metric method[27],Gauss-Markov random field method (GMRF) [28], and clustering segmentation method [29], only learned a limited range of edge features.Considering that sonar images have the characteristics [30-32] of blurred target edges,a special convolution neural network(CNN)is designed for semantic segmentation.Dilated convolution is adopted to enhance segmentation accuracy by expanding the range of receptive fields,and transfer learning to solve the problem of small sonar image datasets.
To deal with the serious underwater acoustic channel [33], the loss function with residual generated by the semantic segmentation network contains the loss of compression and transmission process.Meanwhile, the joint source-channel codec with unequal error-protected is proposed that adjusts the power level of the transmitted data, to improve the error tolerance ability.The experimental results show that the proposed method can maintain the high semantic segmentation accuracy and PSNR of the reconstructed images even with the high compression ratio.The main contributions of this paper are as follows.
(1) A novel underwater acoustic sonar image transmission scheme called UAT-SSIC that includes semantic segmentation-based image compression (SSIC) framework and the joint source-channel codec,is proposed to deal with the serious underwater acoustic channel,such as the limited bandwidth and the Doppler shift.The key point is that it combines the compression and transmission impairments as the loss function which is the pixel-level and semantic-level residual.
(2) Due to the unique characteristic that sonar images have blurred target edges, the additional dilated convolution is added to the semantic segmentation network.Compared to the basic convolution, the proposed method enhances the individual target recognition accuracy by expanding the range of receptive fields.
(3) The joint source-channel codec with unequal error protection is proposed to adjust the power level of the transmitted data, which deals with sonar image transmission error caused by the serious underwater acoustic channel.
The paper is organized as follow.Section 2 proposes the UATSSIC scheme.Section 3 describes the SSIC framework, the semantic segmentation network for sonar images, and the joint sourcechannel codec with unequal error-protection.Section 4 shows the preprocessing, evaluation, and the results and discussion.Finally,Section 5 presents the work conclusions.
2.The sonar image transmission scheme based SSIC framework
The UAT-SSIC scheme consists of two parts: semantic segmentation-based sonar image compression (SSIC) framework and underwater acoustic transmission.The SSIC framework contains four neural network structures.The diagram of the scheme is shown in Fig.1.
The input is a real-valued sonar image with pixels in the range of 0-255.The input image is fed into both the semantic segmentation network(Seg-Net)and the compression network(Com-Net).Com-Net compresses the image to a low-dimensional matrix representation, and Seg-Net extracts the original semantic segments.The two networks operate in parallel to generate a sonar image with redundant information removed and compact representation.The compressed image is encoded and modulated to generate an acoustic signal for the underwater acoustic transmission.After the acoustic signal has been received, the basic code stream is recovered by a demodulator and decoder and then reconstructed by the reconstruction network(Rec-Net)to produce the original size sonar image and the semantically segmented recognition result.
It is worth pointing out that the non-differentiated method by only using the pixel-level loss[34]when training Com-Net and Rec-Net can damage the body target of the image.The semantic segmentation network is treated as a discriminant, accuracy is obtained by segmenting the target in the original image and the reconstructed image separated by the Seg-Net.The final residual together with the pixel-level and semantic level represents the compression loss and transmission loss to enhance the image quality.It is achieved that the high compressed sonar image still has high semantic accuracy without the need for extra bandwidth for semantic information transmission.
3.Method
3.1.The purposed SSIC framework
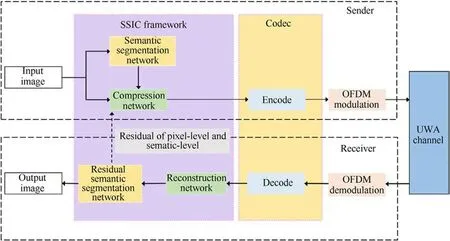
Fig.1.The UAT-SSIC scheme.
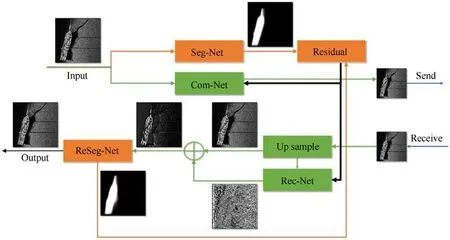
Fig.2.The SSIC framework.
As shown in Fig.2,the proposed SSIC framework is composed of a semantic segmentation network(Seg-Net),compression network(Com-Net), reconstruction network (Rec-Net), and residual semantic segmentation network (ReSeg-Net).
The feature extraction part of the Com-Net network is done by convolution layer, each layer has 256 3 × 3 ×c convolutional kernels, and c is the number of image channels, which generates a feature map with 256 channels.ReLU layer and BN layer are used as activation functions.After the image has been feature extracted,the compressed image is obtained by a compact representation of the feature map,which retain the structural information.The decoded image is up-sampled to the original image size, and the image reconstruction neural network can obtain the underlying features of the image and output a high-quality image through residual learning.
The reconstructed image after compression and transmission will definitely change in spatial structure compared to the original image, and its segmentation accuracy and even semantic information will change.Therefore, in this scheme, an additional network outside the Com-Net and Rec-Net is designed to be a discriminator, it applies the same semantic extraction for two networks and shows the segmentation result.The semantic residual combines with the mean square error (MSE) calculated between the reconstructed image and the original image to express the compression loss and transmission loss.Considering the transmission, Com-Net and Rec-Net are trained separately.When training one network, another's parameters are fixed.
By image compression and reconstruction,the original semantic segments are only used in training.This process also applies to the receiver,so it is guaranteed that the semantic information between the reconstructed image and the original image is correlated without sending semantic segments, while no extra bandwidth is needed, saving the amount of information in transmission.
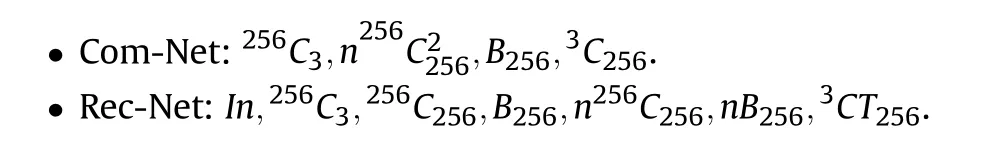
Where,aCi:input has i channels,convolution layer with a filters and stride 1, followed by ReLU.naC2i: input has i channels, convolution layer with a filters and stride 2, the compression ratio is 2n,followed by ReLU.Ba: batch Normalization with a filters.In: upsampling.aCTi: deconvolution layer with a filters and stride 1, followed by ReLU.
3.2.Loss function
Traditional compression networks all use the mean square error(MSE) as the loss function to optimize a reconstructed image with high quality.However,due to the low contrast of sonar images,MSE cannot distinguish pixel changes in the sonar image structure sensitively.In this case, the quality of the reconstructed image is prone to be misjudged as great while the semantic accuracy is low.Therefore, we consider adding the measure of semantic information to the loss function, which analyzes the completeness of the image content, using MSE and semantic accuracy together to ensure the quality of the reconstructed image.
With a set of images xion the sender,the MSE can be calculated:
where I represent the number of the input network batch size, xirepresents the i-th image,θ1and θ2are the parameters of Com(·)and Rec(·).Correspondingly, Com(·) and Rec(·) refer to compression network and reconstruction network.Se(·) refers to the encoder and modulation for the compressed image.Re(·)refers to the demodulation and decoder at the receiver.To simplify the representation, the recovered equal-sized image ^xiat the receiver is:
At the same time, to quantify the semantic level distortion during the compression process, Seg-Net segments the reconstructed images during the training process, extracting semanticlevel information from the original and reconstructed images:
where θ3is the parameters of Seg-Net, F(·) is the set of target features in the original image and the reconstructed image,respectively,and finis the individual target segmentation accuracy.The residual of semantic-level can be expressed:

3.3.The semantic segmentation network for sonar images
Semantic segmentation deals with the image feature information to classify the target's label and mark the pixels they occupy.As the imaging principle of sonar images is different from optical images,the semantic segmentation network is not used in the field of sonar images commonly [30,35], the poor quality and blurred edges of sonar images lead to ineffective identification using existing models.
The semantic segmentation network designed for sonar images is shown in Fig.3.Drawing on the network structure of Mask-RCNN,the deep features of the image are extracted using the convolution layer,and the feature map is generated by forwarding propagation of the network.RPN and ROIAlign are used to generate regional proposals,combining different sizes and aspect ratios in the feature map to determine the anchor.Two kinds of information are the output of each anchor,the first one is the prediction of the anchor foreground or background category,and the second one is the finetuning of the pre-set borders.The mask is then fed into the classifier and convolved, the position and mapping relationships among the image pixels are expressed by convolution, and the mask is mapped back into the original image.It is worth pointing out that due to the serious underwater environment, the boundaries of the targets in the sonar image are mixed with the background,which makes the segmentation more challenging,and the segmentation boundaries are prone to errors.The convolution process uses dilated convolution,it increases the receptive field so that each convolutional output contains a larger range of information, and the target range can be identified more precisely.The large optical dataset contains a wide variety of shallow and deep features,covering the scene features that may be present in smaller data.Although sonar image scenes suffer from feature sparsity,effective features only have shape features in highlighted and shadowed regions,without clear color differentiation or boundary,the basic features of sonar images are not removed from the large range of image features.It is useful to pre-train the ability to extract features effectively on large datasets and then migrate to training on sonar image datasets.
3.4.The joint source-channel codec with unequal error-protection
Traditional error protection codecs [36,37] transform the realvalued data into bit sequences, this process destroys the numerical properties of the original data.Errors can occur when the acoustic signal is transmitted in the serious underwater acoustic channels, resulting in key image information being corrupted or missing.The codec mainly deals with the main image feature information and the channel fault tolerance.
On the encoder side, the DCT transform concentrates the lowfrequency region in the upper left corner, achieving a high concentration of the frequency domain data, the majority of image energy is concentrated in the low-frequency region.The joint source-channel coding with unequal error-protected adjusts the power level of the transmitted data.The entire encoding process is linearly transformed.The entire encoding process is linearly transformed, so the final transmitted data and the compressed image data always remain linear, and the relationship between system performance and signal-to-noise ratio is approximately linear, making it easy to control the transmission quality.The encoder can be expressed as follows:

Fig.3.Semantic segmentation network with dilated convolution for sonar image.
where i represents each pixel,Siis the sent data,hiis a Hadamard matrix, giis a diagonal matrix consisting of energy weighting factors and Dxiis the DCT component for input.
The decoder needs to recover the demodulated data, which computes its best estimate of the original DCTcomponents by using the Linear Least Square Estimator (LLSE):
where N is the diagonal matrix consisting of the channel noise variance and Λiis the diagonal matrix of DCT component variance.Riis the receiver data after demodulation.The computed data can be recovered from the original image by DCT inverse transformation.Furthermore, orthogonal frequency division multiplexing (OFDM) is adopted due to its resistance to multipath interference[38].
4.Experimental results
In this section, we firstly present the experimental conditions and evaluation metrics,followed by an evaluation of our proposed semantic segmentation network for sonar images.Then, the performance of modulation and demodulation methods used to compress images for stable transmission in underwater acoustic channels is analyzed,comparing the image transmission quality at different signal-to-noise ratios.Finally, the semantic retention capability and visual quality recovery of the images at different compression multiples are investigated.Also, the semantic recovery capability of the images after passing through semantic compression networks with different loss functions is analyzed.
4.1.Construction datasets and pre-processing of sonar image
There is no complete publicly available image dataset in the field of sonar imagery, so before investigating the network structure, a sonar image dataset is first established.This dataset will be used in the training and model evaluation of semantic segmentation and image compression networks to achieve target object segmentation and high image quality compression from underwater sonar scenes.
After searching and selecting, a total of 450 side-scan sonar images were obtained, and the target objects contained in the images were divided into four categories:people (39 in total),fish(35 in total), underwater aircraft wreckage (90 in total), and shipwrecks (286 in total).The effect of the neural network model is related to the training set data,the more data in the training set,the more features the neural network model can extract, and the generalization ability and robustness will be enhanced.In the case that the sonar image data set is too small, this paper uses optical natural images for initial training, and then uses the sonar image data set to adjust and optimize the model by means of migration learning.

Fig.4.Comparison of sonar image pre-processing results,the left image is the original image, and the right image is the result after median filters: (a)Original image; (b)Median filtered image.
For the training network dataset,we selected the existing COCO image dataset and the sonar image dataset.As we need the image size of the input network to be consistent, the images were uniformly adjusted to a size of 256×256,and a grayscale image with pixel point range in [0,255].For the test images, we selected 20 sonar images with a resolution of 256 × 256 from a variety of categories,including shipwrecks,aircraft wrecks,frogmen,schools of fish, and other categories.In the experimental results, the shipwreck category, aircraft category, and frogmen images are used as the test images.
The formation of a sonar image is based on the principle of acoustic imaging,where a sonar emits an acoustic pulse and listens for echoes, forming an image based on the arrival time and intensity of the echoes.When the sonar emits sound waves, the presence of seawater or objects in the ocean will prevent some of the sound waves from reaching the seabed,thus creating a shadow.The underwater environment is complex and the side-scan sonar is affected by underwater temperature, salinity, attenuation, and other factors, presenting a side-scan sonar image with low resolution, multiple distortions, blurred edges, noise, and other disadvantages.Therefore, before constructing the dataset, preprocessing the side-scan sonar images to make them smoother is beneficial to ensure the stability and accuracy of the network.
The reverberation and ocean noise in sonar images are both additive components relative to the sonar system, and additive noise is usually expressed as impulse noise,which can be removed with a median filter.The median filter can not only effectively suppress the impulse interference, but can also eliminate the impulse interference noise while reducing the blurring of the image edges to some extent.It replaces the pixel value at a point in the image with the median of the neighboring pixel values,making the pixel value at that point closer to the surrounding pixel values and thus removing isolated noise points.As shown in Fig.4, after the median filtering process, the noise in the image is significantly reduced and the overall image is smoother.
4.2.Experimental parameters setting
When training the network,in order to increase the accuracy of recognition and the correct rate of segmentation,and to avoid datadriven,we first use the COCO dataset for pre-training,the batch size is 5,the learning rate is 5×10-4,and in the second stage,we then fine-tune the pre-trained model using sonar images in 200 steps,input the 256×256×5 tensor to the training network, and use Adam optimized the model, and the learning rate was gradually decayed from 5×10-4to 5×10-6.In addition,when designing the comparison experiments, i.e.when considering different lossfunctions for the training conditions, we use the same network parameter settings as the optimal model to ensure consistency of variables and validity of performance comparison.
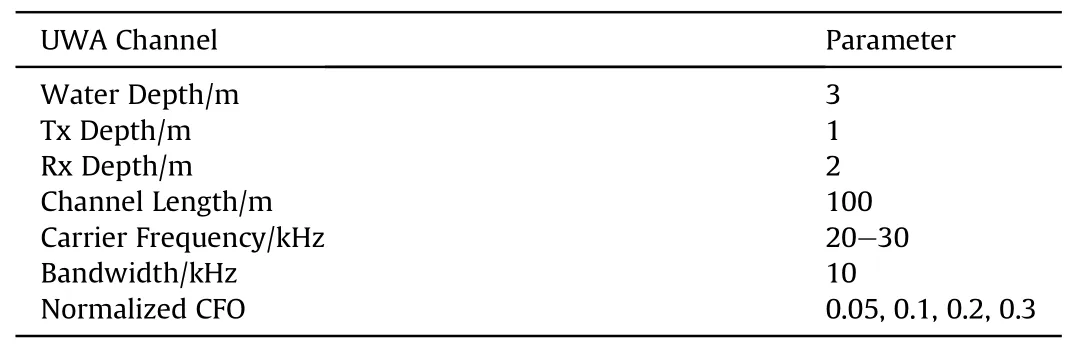
Table 1 Uwa channel parameter.
To verify that the codec can achieve high-quality sonar image transmission,we converted the compressed images into waveform files, which were converted into acoustic signals through a transducer for transmission in the underwater acoustic environment,and used a hydrophone at the receiving end to convert the received acoustic signals into electrical signals for later recovery and reconstructed image processing.The experiments were carried out at the Jingye Lake of Tianjin University, the details of the experimental environment are shown in Table 1.
4.3.Evaluation indicators
To validate the performance of the proposed model,in addition to the subjective analysis of the quality of the recovered images,PSNR is used as an evaluation metric for the recovered images which is the most commonly used evaluation parameter to measure the reconstructed image quality.In addition, the semantic segmentation accuracy of the recovered image is scored and evaluated by the semantic segmentation network.
However,for low bit-rate images,the evaluation parameters are not necessarily equal to the merit of the reconstructed image because the differences between pixel values are not obvious.In addition, for reconstructed sonar images, evaluating quality from low-level visual features alone does not meet the needs of accurate segmentation scenarios.The most common evaluation for target detection is AP (Average Precision), and we use the mAP (mean average precision)of all categories of targets as the final measure of network performance to compare the detection performance of all classes of targets.
In order to measure the accuracy of target localization, the ability of the frame to regress the target position is usually by using an IOU greater than a predefined threshold, which is the intersection ratio between the predicted frame in which the model predicts the target and the real frame in which the original image is annotated, the higher the IOU threshold, the more accurate the corresponding frame regression.If the IOU is greater than or equal to the threshold, the object will be marked as "successfully detected",otherwise it will be marked as"not detected".In our experiments,we set the IOU threshold to 0.5, 0.75, and 0.95 to investigate the detection accuracy of the network with different IOU thresholds.
4.4.Evaluation of semantic segmentation network for sonar images
In this section, we evaluate the recognition and segmentation accuracy of the image semantic segmentation network when using a sonar image database.For the semantic segmentation network,the selection of the IOU threshold has a great impact on the detection accuracy of the model,and we have analyzed the mAP of recognition and segmentation in our experiments with IOU thresholds of 0.5, 0.75, and 0.5 to 0.95 combined, respectively, as shown in Fig.5.
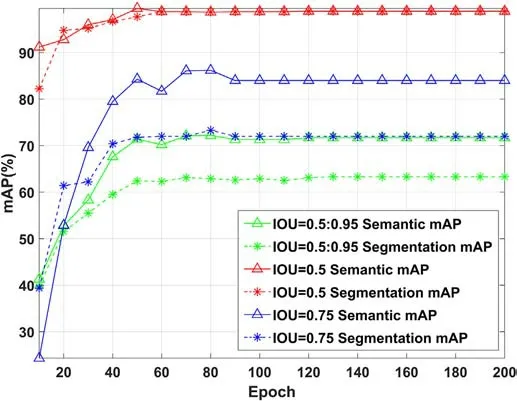
Fig.5.Curves of mAP with epoch at different IOUs.
It can be seen that as the threshold rises from 0.5 to 0.95, the inclusion of false positives gradually decreases and the accuracy of the model to the requirements are getting higher and higher,which means that the accuracy of target object localization and identification is strictly required, reducing the risk of missed detection.Moreover, the combined results of IOU taken from 0.5 to 0.95 and the results of IOU set to 0.75 both differ by 10%,indicating that the high threshold value affects the recognition and segmentation accuracy of the model more.Meanwhile, as the training epoch increased,the overall performance of the model was subsequently optimized,and the change became smaller and stabilized after the epoch reached 100 steps.Finally, the recognition mAP in the integrated case was fixed at 71.7%and the segmentation mAP was fixed at 63.3%.
Table 2 shows the prediction classification and segmentation results for the five test images.We fed five images into the network and used accuracy to indicate the prediction performance in certain categories.It can be seen that all five images accurately predicted the class of significant objects in the images and also achieved a segmentation accuracy of over 99%.Fig.5 shows the semantic segmentation results of the selected original images.The location,form, and background of the target objects in the five images are not similar, and although the selected images' semantic segmentation accuracy is high, the images with lower scores are segmented with significantly less detail,and the images with clear boundaries between the target objects and the background and high contrast will have higher scores and more detailed segmentation details.
Due to the inherent characteristics of sonar images, some network models applicable to optical images cannot address influencing factors such as acoustic shadows and reflections in sonar images.We used Mask-RCNN, U-NET, and other advancedsemantic segmentation architectures to test our dataset, using the same parameters as our model in the experiment.The accuracy comparison results are shown in Table 3.We selected three different classes of images for testing and our model segmented significantly better than the other two for sonar images.
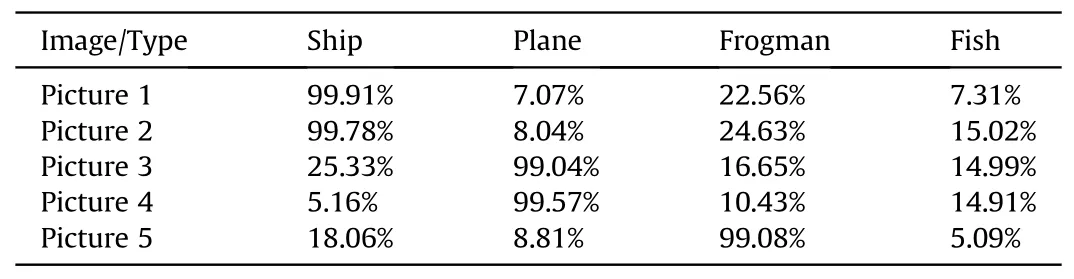
Table 2 Semantic segmentation accuracy of sonar images in the proposed semantic segmentation network.

Table 3 The accuracy comparison of several semantic segmentation networks.
4.5.Evaluation of the sonar image transmission scheme based SSIC framework
The UAT-SSIC scheme is evaluated and compared, using semantic segmentation of reconstructed images as an important measure of the usefulness of the scheme, in addition to the basic PSNR evaluation metrics.
First, three models with different loss functions are considered and compared: (1) the Ours-Seg model, which optimizes and adjusts the output of the network from a semantic analysis perspective only, eliminating the effect of structural-level disparities between the original and reconstructed images; (2) the Ours-MSE model, which controls the optimization of the model using structural similarity disparities only, without considering the loss of deeper features in the image;(3)the Ours model,which integrates the consideration of surface-level features and deeper features at the pixel level of the image.In conducting the comparison experiments, only the loss function is different between the three, the rest of the training and experimental conditions are the same.
In Fig.6,the 4 bars of each image represent the original semantic segmentation accuracy and PSNR of the image and the semantic segmentation accuracy and PSNR of the image recovered by the 1,2,and 3 models respectively.From Fig.6(a) we can see that the original accuracy of all five images is above 99%,indicating that the images themselves are suitable for this measure.Among the other three reconstructed images, the Ours-MSE model scores significantly lower than the other two categories.This phenomenon may be since that the model is obsessed with pursuing a lower MSE effect during the training process, resulting in the loss of highfrequency details in the sonar images with their own lower resolution, making it more difficult for semantic segmentation.Were similar, but in terms of overall performance, the Ours model had the highest accuracy, both above 90%.The results show that optimizing the compression and decompression network with semantic information allows the reconstructed image to retain more detailed features and more closely resemble the original image.As can be seen from Fig.6(b),the mixed loss function is superior to the other two loss functions regardless of PSNR or accuracy, proving that our proposed method can retain more content and structure.
Packet loss and error codes often occur in actual underwater acoustic experiments,to evaluate the ability of the method to fight against the serious underwater acoustic environment,compressed images are transmitted at different signal-to-noise ratios (SNR).Fig.7 shows the comparison of the results of the image reception quality under different SNRs,(a)shows the semantic segmentation accuracy of the reconstructed images and (b) shows the PSNR performance with different SNRs.The original pixel size of all five images is 256×256,and they are compressed by the network into 64 × 64 size images, which is the result of 16x compression.

Fig.6.PSNR and semantic segmentation accuracy with different loss functions: (a)Accuracy performance with different loss functions; (b) PSNR with different loss functions.
As seen in Fig.7, the transmission performance is a continuous upward curve as the SNR increases.When the SNR is 20 dB, the channel conditions are relatively good, and when the underwater acoustic channel conditions are good enough,the channel basically has no great influence on the transmitted signal.When the SNR is 5 dB, the channel conditions are poor and the transmission is affected by more noise.However, even when the channel conditions are serious, the PSNR is kept above 25, and the semantic segmentation accuracy of the image does not vary significantly until the SNR is below 10,which proves that this scheme maintains the error resilience of the transmission process.
To evaluate the practical effectiveness of our model, we investigated the relationship between the accuracy of semantic segmentation and the number of compressions.Five images were selected from the test set, compressed at different multiples, and the compressed images were transmitted in the underwater acoustic channel.After the received images were recovered by the decoder, the reconstructed images were recovered using the network, and then decompression operations were performed.
Fig.8 shows the reconstructed images are compressed at 4x,16x, 64x and 256x respectively, and Fig.8(a) shows the semantic segmentation accuracy of the reconstructed images.With the gradual increase of the compression ratio,the detailed features that can be retained in the compressed image have been drastically reduced.In the transmission process, to save bandwidth, we will not transmit the semantic features to the receiver, who can only extract and recover them from the decoded image,and accordingly,the detailed features of its reconstructed image will also be affected to a certain extent.Evaluated from the perspective of the PSNR as Fig.8(b), the overall curve trend is still gradually decreasing with increasing compression times,but the change interval is not large,and the PSNR of the reconstructed image after 4x compression and 256x compression only within 10.As can be seen from Fig.8,although the difference in theoretical evaluation is not large,there is still a certain gap in the subjective visual effect, and we can conclude that in the practical application process, the semantic evaluation system is more common than structural evaluation systems such as PSNR.The semantic segmentation mask of the reconstructed images that are compressed at the different compression ratios of 4x,16x,64x,128x,as shown in Fig.9.Because the reconstructed images are not recognized when the compression ratio is 256x, Fig.9 only shows the results up to 128x compression.The reconstructed images are compressed at the different compression ratios of 4x, 16x, 64x, 256x, as shown in Fig.10.
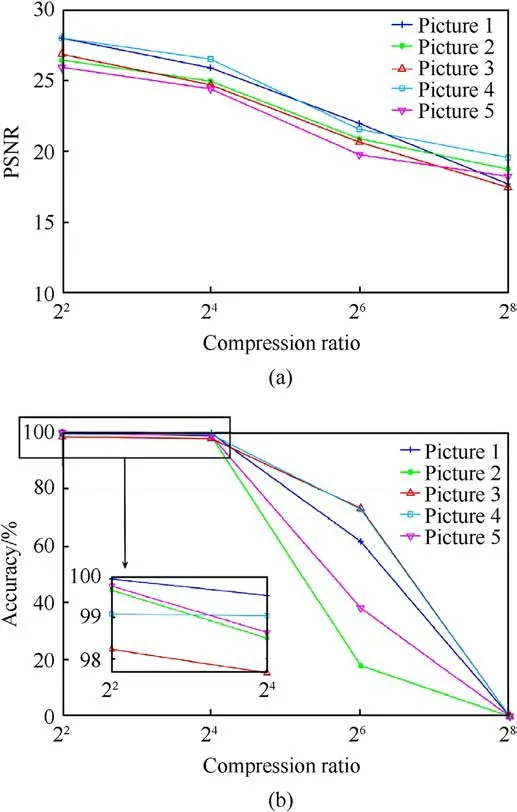
Fig.8.PSNR and semantic segmentation accuracy with different compression ratios:(a) PSNR versus compression ratio; (b) Semantic segmentation accuracy versus compression ratio.
As shown in Fig.11, JPEG, JPEG2000, SPIHT and the proposed method are applied to compare the quality of the reconstructed images.From the results,Fig.11 shows that there is a considerable gap between the proposed method and other compression methods in terms of performance.Although the proposed method is close to other methods in the variation of PSNR, the proposed method has a clear advantage measured by the semantic segmentation accuracy of the reconstructed image which shows more appealing reconstructed image at high compression ratio.At the same compression ratio, the proposed method can preserve more semantic information when other reconstructed images are not recognized.At the pixel level, the results of the proposed method are similar to the others, especially for the SPIHT.However, the proposed method has obvious advantages compared to other methods from the semantic level.Fig.12 shows the image reconstruction for different methods and compression ratios.It can be seen that the overall structure of the target is better preserved using our proposed method,ensuring that the target suffers as less loss as possible during the transmission process.
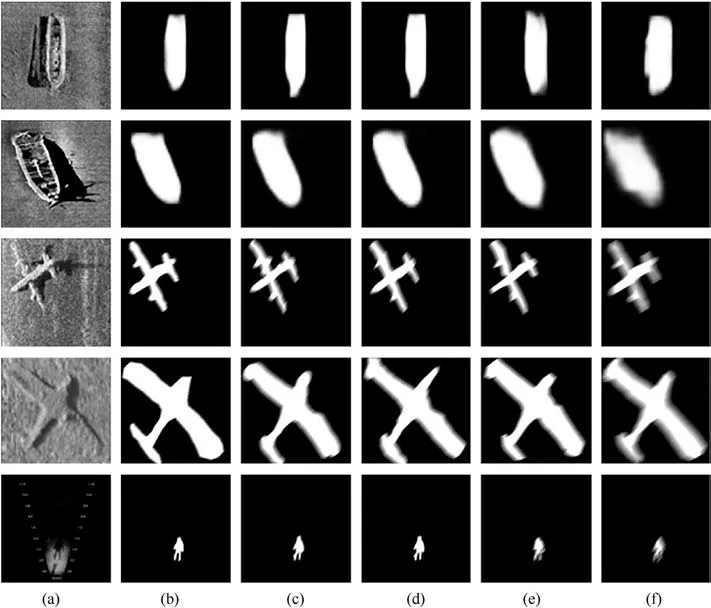
Fig.9.The semantic segmentation mask of the reconstructed images that are compressed at the different compression ratios of 4x,16x,64x,128x:(a)Original image;(b)Original mask; (c) Ratio (4x) compression; (d) Ratio (16x) compression; (e) Ratio (64x) compression; (f) Ratio (128x) compression.

Fig.10.The reconstructed images that are compressed at the different compression ratios of 4x,16x, 64x, 256x: (a) Original image; (b) Ratio (4x) compression; (c) Ratio (16x)compression; (d) Ratio (64x) compression; (e) Ratio (256x) compression.
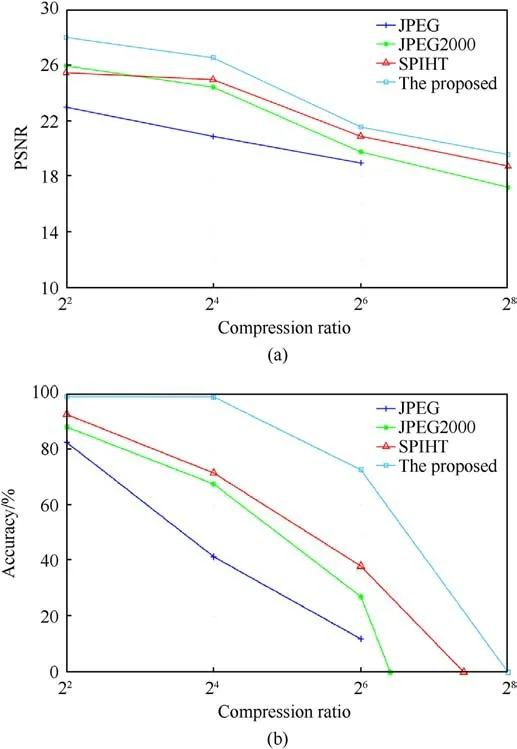
Fig.11.PSNR and semantic segmentation accuracy with different compression ratios based on JPEG, JPEG2000, SPIHT and the proposed method: (a) PSNR versus compression ratio; (b) Semantic segmentation accuracy versus compression ratio.
In addition, considering of the physics of underwater acoustic channel, the method is applied to the different Doppler frequency shifts.The relative movement of the transmitter and receiver during the transmission process and the low propagation speed of the sound wave leads to a serious Doppler frequency shift, which seriously affect the transmission quality of the system.Fig.13 illustrates the PSNR and semantic segmentation accuracy of the recovered image in the different carrier frequency offset (CFO)conditions.ε is the ratio of the CFO to the subcarrier interval,called normalized CFO.When ε = 0 represents no Doppler shift as a reference group.From the results, although both PSNR and accuracy are affected at high Doppler frequency shifts, the overall recognition accuracy of the image content is still intact and can adapt to the variable underwater acoustic environment.
We selected sonar images of 256 × 256 for the runtime experiments on GPU and obtained the results as shown in Table 4, from which we can see that the original image costs 3.848 s after the complete compression and reconstruction process.Since the semantic segmentation network of the image is also involved in the process,the runtime of the Seg-Net network is also calculated.It is worth noting that the runtime of the Rec-Net costs 2.554 s and accounts for most of the runtime, because the Rec-Net has more convolutional layers and a deeper neural network structure compared to the Com-Net.
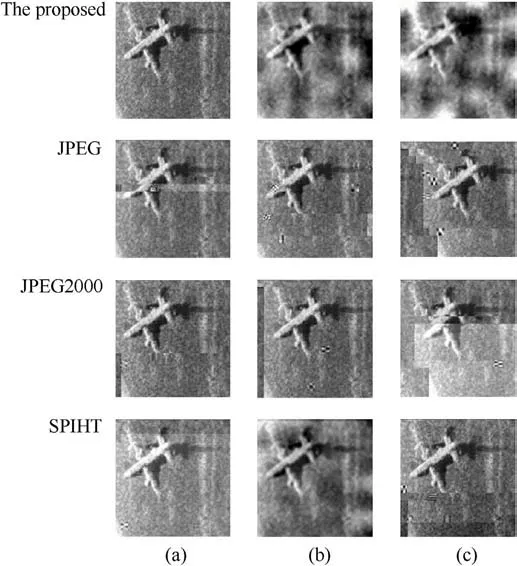
Fig.12.Reconstructed images based on the different compression methods: (a) Ratio(4x) compression; (b) Ratio (16x) compression; (c) Ratio (64x) compression.
When the sonar maps the same object from different angles or distances, the sharpness or morphology of the target in the image will be affected, and the compression effect of image will be different.We choose the images with different distances and angles for comparison experiments to compare the PSNR and Accuracy of the reconstructed images with different compression ratios, as shown in Fig.14.
From Fig.15,it can be seen from the figure that among the three images with different distances, the second image has the closest distance, and the corresponding reconstructed image has the best result.Although the distances of the first and third images are similar,the reconstruction effect of the third image is still relatively weaker due to the quality of the original image, which indicates that the distance is not the most important factor affecting the effect for the same target.For two images with different angles,the variation of the imaging shape of the same target object has a certain effect on the segmentation accuracy, especially with high compression ratios.
In the SLAM experiment, two AUVs make seabed detection using side scan sonars and identify features in the images in real time.The trajectories of the two AUVs and detected features are shown in Fig.16,which start from point x1,the blue route is for AUV1,and the green route is for AUV2.The trajectories of two AUVs have intersection points during the detection process,and the corresponding landmarks are shown in Table 5.The landmarks x17(p4),x18(p8),x19 (p11), x20 (p14) and x21 (p15) are detected by AUV2 first and transmitted to AUV1 using SSIC, JPEG and JPEG2000 for comparison.The features correctly transmitted by SSIC framework is more than the other two methods.

Fig.13.PSNR and semantic segmentation accuracy with different Doppler frequency shifts: (a) PSNR versus SNR; (b) Semantic segmentation accuracy versus SNR.

Table 4 The runtime of the SSIC framework on GPU.
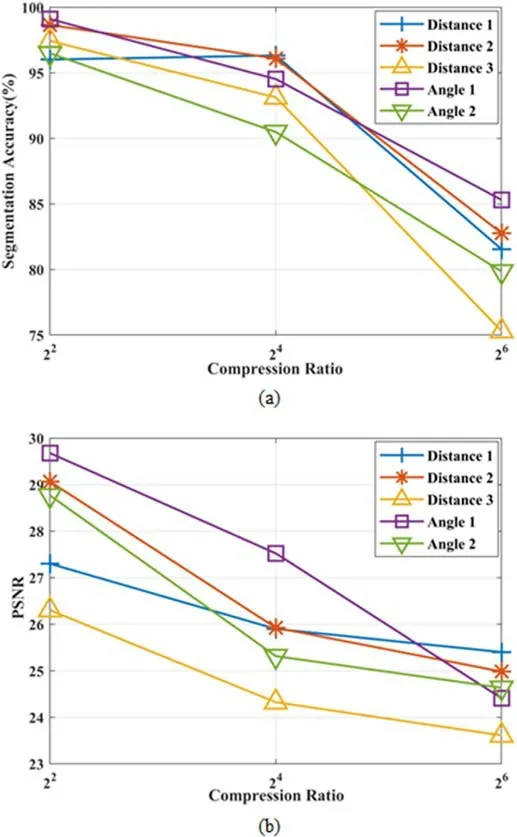
Fig.15.PSNR and semantic segmentation accuracy with different distances or angles of the images: (a) Semantic segmentation accuracy versus Compression Ratio; (b)PSNR versus Compression Ratio.

Fig.14.Different distances or angles of the sonar images: (a)distance 1; (b) distance 2; (c) distance 3; (d) angle 1; (e) angle 2.
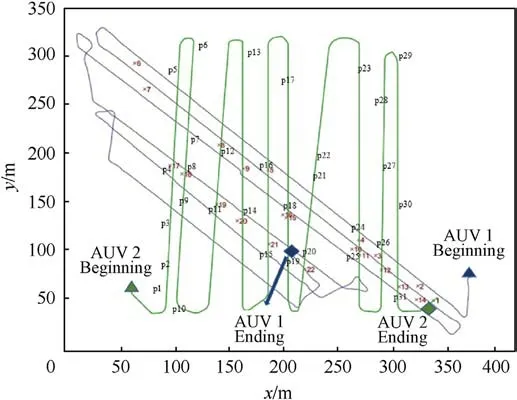
Fig.16.The trajectory of two AUVs.

Table 5 Corresponding landmarks of AUV1 and AUV2.

Table 6 Mean μ (expressed in meters) and Variance σ2 of the Errors.
This paper compares the localization errors among the three methods in this experimental setup.Table 6 shows mean and variance of the errors.It can be observed the SSIC framework provides the best results, because the proposed method focuses more on landmarks that can be effectively matched than other compression methods.
5.Conclusions
To deal with timely and complete sonar image transmission among underwater vehicles for cooperative SLAM, this paper proposes a novel sonar image transmission scheme (UAT-SSIC) with a semantic segmentation-based compression network (SSIC), which only requires the transmission of the compressed image without additional semantic information.The network combines pixel-level and semantic-level residual as the compression and transmission loss, to improve the reconstructed images'semantic segmentation quality.The semantic segmentation network is designed to avoid recognition and segmentation errors caused by the blurred sonar image target edges.To avoid interference during transmission,the joint source-channel codec with unequal error protection adjusts the power level of the transmitted data, which improves the transmission error tolerance.The experimental results show that the proposed method can achieve above 99% in segmentation accuracy,images preserve a certain segmentation accuracy when the compression ratio is 256x, and ensure that the semantic information between the reconstructed image and the original image is correlated without sending semantic segments.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
This work was supported in part by the Tianjin Technology Innovation Guidance Special Fund Project under Grant No.21YDTPJC00850,in part by the National Natural Science Foundation of China under Grant No.41906161, and in part by the Natural Science Foundation of Tianjin under Grant No.21JCQNJC00650.

- Defence Technology的其它文章
- Evolution of molecular structure of TATB under shock loading from transient Raman spectroscopic technique
- MTTSNet:Military time-sensitive targets stealth network via real-time mask generation
- Vulnerability assessment of UAV engine to laser based on improved shotline method
- Free-walking: Pedestrian inertial navigation based on dual footmounted IMU
- Investigation of hydroxyl-terminated polybutadiene propellant breaking characteristics and mechanism impacted by submerged cavitation water jet
- Estimation of surface geometry on combustion characteristics of AP/HTPB propellant under rapid depressurization