
MTTSNet:Military time-sensitive targets stealth network via real-time mask generation
2024-04-11 03:38SiyuWangXiaogangYangRuitaoLuZhengjieZhuFangjiaLianQinggeLiJiweiFan
Defence Technology 2024年3期
Siyu Wang, Xiaogang Yang, Ruitao Lu, Zhengjie Zhu, Fangjia Lian, Qing-ge Li, Jiwei Fan
PLA Rocket Force University of Engineering, Xi'an 710025, China
Keywords:Deep learning Military application Targets stealth network Mask generation Generative adversarial network
ABSTRACT The automatic stealth task of military time-sensitive targets plays a crucial role in maintaining national military security and mastering battlefield dynamics in military applications.We propose a novel Military Time-sensitive Targets Stealth Network via Real-time Mask Generation(MTTSNet).According to our knowledge,this is the first technology to automatically remove military targets in real-time from videos.The critical steps of MTTSNet are as follows: First, we designed a real-time mask generation network based on the encoder-decoder framework,combined with the domain expansion structure,to effectively extract mask images.Specifically, the ASPP structure in the encoder could achieve advanced semantic feature fusion.The decoder stacked high-dimensional information with low-dimensional information to obtain an effective mask layer.Subsequently, the domain expansion module guided the adaptive expansion of mask images.Second,a context adversarial generation network based on gated convolution was constructed to achieve background restoration of mask positions in the original image.In addition,our method worked in an end-to-end manner.A particular semantic segmentation dataset for military time-sensitive targets has been constructed, called the Military Time-sensitive Target Masking Dataset(MTMD).The MTMD dataset experiment successfully demonstrated that this method could create a mask that completely occludes the target and that the target could be hidden in real time using this mask.We demonstrated the concealment performance of our proposed method by comparing it to a number of well-known and highly optimized baselines.
1.Introduction
The future of the battlefield is constantly changing, and the combat mode is developing in the direction of information and intelligence.As an essential intelligence source for informationbased warfare, the Internet has become a key to improving battlefield situational generation,reconnaissance,surveillance,and command decision-making in modern warfare.With the increasing development of the Internet and artificial intelligence technology,a large amount of military information has been leaked onto the Internet, which has caused great harm to national security and interests.Military time-sensitive targets include ships,aircraft,etc.,whose strike opportunities are limited by time windows and have high military value.Therefore, all kinds of images or videos of military time-sensitive targets related to national security need to be declassified before they are released to the public.However,there is still a lack of a method that can quickly hide targets, and how to automatically hide military time-sensitive targets in realtime is an urgent research topic.
Traditional target stealth methods rely on manual or semiautomatic methods to find specific military time-sensitive targets,and the main techniques are patch-based and diffusion-based.Patch-based methods [1-5] fill in the missing spaces in the image by looking for better patches in non-sensitive regions.The diffusion-based algorithms [6-8] carry out a filling procedure by smoothly propagating the image material from the boundary to the missing sensitive region.Such algorithms are relatively complex,unable to learn the high-dimensional information of the image,and the repair results have a low resolution.
Deep learning [9-11] has produced amazing advancements in computer vision in recent years.To facilitate the accomplishment of more complex image structures,current image inpainting research efforts have shifted to a data-driven scheme that learns deep semantic information in an image and then infers what is missing based on this information, which can be used to remove specific targets in a snap and can coherently recover texture and structural features of the removed regions [12-16].To better repair the texture details and overall structural information of the missing areas, researchers have proposed various deep learning-based image inpainting algorithms, including deep convolutional neural network-based methods (CNNs) [16-20], and generative adversarial network-based methods [12-15,21-23].
In recent years, significant research has been performed regarding generative adversarial network methods due to their powerful image-generation abilities[24].GANs include a generator responsible for capturing the distribution of sample data through iterative data training and a discriminator accountable for determining whether the samples are generated spurious data or real data.Benefitting from their excellent image generation ability,GANs can directly learn the areas needing completion while utilizing adversarial loss constraint training to generate more realistic target stealth results.However, GAN-based target stealth methods can only handle a single image and cannot complete the military target concealment task for videos.Therefore,some methods based on video target stealth have been proposed[25-29].Among them,typical flow-based methods consider video inpainting as a pixel propagation problem to fully utilize the internal space and temporal information of videos.Nevertheless, such methods require information between the front and back frame images and cannot realize real-time concealment of military target videos.
To address these flaws, in this paper, we proposed a novel concept of automatic hiding of military time-sensitive targets, in which masks can automatically hide military time-sensitive targets in real-time video,and the hidden area will be replaced by similar backgrounds around.The key idea is to generate a mask that effectively masks the target in real time.This real-time processing mode for video sequences substantially improved the efficiency of algorithms, and it could provide target-hiding effects no less than non-real-time processing.The target hiding area was prone to distortion and incomplete hiding challenges,such as the generated mask being unable to cover the target to be hidden entirely.To solve the above problem, we built an encoder-decoder framework based on the mask expansion module to enhance the mask generation effect.Specifically, the original image was encoded and decoded to produce a coarse mask image.We performed external expansion and internal hole filling on the coarse mask to generate the ideal real-time mask.The background reconstruction network received both the created mask and the original picture of the current frame as input.A coarse network based on gated convolution and a refinement network based on contextual attention was used to achieve background filling of the target hidden region.
In summary,the main contributions of this study are as follows:
(1) We introduce a novel Military Time-sensitive targets Stealth Network(MTTSNet).MTTSNet,as an end-to-end framework,can automatically obtain mask images and achieve real-time stealth of targets.It can produce results that are visually reasonable and satisfy temporal consistency.
(2) We design a new domain expansion module to accurately and comprehensively cover all the target areas to be hidden.This domain expansion module is responsible for guiding the adaptive expansion of mask images.It is simple, fast and produces high-quality targets stealth results.
(3) Numerous experimental results have shown that MTTSNet achieves significant results on two standard distortionoriented metrics (i.e., PSNR and SSIM) compared to many existing state-of-the-art methods.Qualitative analysis and user studies likewise demonstrate the progressive nature of our method.
The remaining sections of this article are arranged as follows.Section 2 provides a brief introduction to the related work.The main content of Section 3 is a detailed description of the proposed method.The results are presented in Section 4.The conclusion of the article is given in Section 5.
2.Related work
Our proposed Military Time-sensitive Targets Stealth Network via Real-time Mask Generation mainly includes two modules: a real-time mask generation module based on semantic segmentation and a target region repair module.This section reviews existing work and the most relevant methods to our approach,including target semantic segmentation methods and image and video inpainting methods.
2.1.Target semantic segmentation
As a fundamental computer vision task,semantic segmentation is viewed as a dense prediction problem with the goal of labeling every pixel in the input image [30].DeConvNet [31], an inverse convolutional network consisting of an inverse convolutional layer and an inverse pooling layer, is used to identify pixel-level labels and predict segmentation masks.Subsequently, a fully convolutional coding and decoding architecture known as SegNet was proposed by Badrinarayanan et al.[32].A pixel-level classification layer, a decoder, and an encoder make up the majority of SegNet's essential components.The decoder's method for upsampling the low-resolution input feature maps is what makes it innovative.Specifically,nonlinear up-sampling is performed using the pooling index calculated during the encoder's maximum pooling phase.To obtain more explicit boundary information, algorithms such as PSPNet [33] and DeepLab family [34,35] use spatial pyramid pooling modules[36,37]and parallel void convolution at different rates for feature extraction and fusion.Due to the success of deeply separable convolution [38,39], atrous separable convolution was used for ASPP (Atrous Spatial Pyramid Pooling) and decoder networks[34],and the encoder-decoder structure based on the atrous convolution is shown in Fig.1.However,the mask images generated by most segmentation algorithms cannot fully cover the target area,and the segmentation effect of the target edge could be better.Therefore,to solve the above problems,this paper proposes a mask dilated model.
2.2.Image, video inpainting
Image inpainting was first proposed as an image processing task[40],which aims to repair damaged areas of an image and remove or replace selected targets in the image.Subsequently,researchers have extensively worked in patch-based [1-5] and patch-based algorithms [6-8] for image inpainting.Still, these traditional algorithms can only adapt to more superficial background structures and need mechanisms to model high-level semantic information.Therefore, the repair is ineffective in complex environments, and the resolution of the complementary content could be higher.
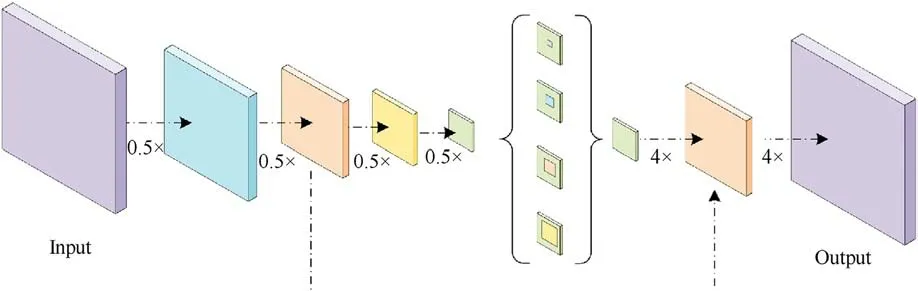
Fig.1.The encoder-decoder structure based on the atrous convolution.
In recent years, image inpainting models have shifted toward deep learning-based approaches that utilize data-driven schemes to fill in the area to be restored end-to-end by generating models[12-15,21-24].These models are trained on a large quantity of data in order to extract the image's deep features and generate the background of the area to be restored.FCN[41]and U-Net[42]are the primary image inpainting architectures based on convolutional neural networks.Both networks use an encoder-decoder architecture.The primary principle of FCN is to extract the highdimensional feature map from the input image using convolutional and pooling layers.The deconvolutional layer is then used in place of the fully-connected layer of CNN to produce a feature map that is the same size as the input by up-sampling.Similar to FCN,UNet is an entirely symmetric structure.The encoder part extract features from the image by convolutional layers and downsampling, and the decoder part outputs feature maps of the same size using up-sampling.The difference is that for residual concatenation, FCN uses addition, while U-Net uses concat to fuse features.
In order to increase image resolution,Sasaki et al.[43]presented an automatic FCN-based image restoration approach that substitutes a nearest neighbor up-sampling technique for the deconvolution layer.As GAN is increasingly employed in image inpainting, FCN is being used more and more as a generator for GAN.A contextual encoder network-a CNN and GAN encoder network combined-was proposed by Pathak et al.[19].Since the area to be repaired does not contain valid information,the effect of repair will be blurred if it is not distinguished from the valid information.As a result, different convolution patterns based on UNet have been suggested by academics, including gated convolution[15],learnable bidirectional attention map(LBAM),and partial convolution [14].A contextual attention mechanism was introduced to the network by Yu et al.[14], which produced images of superior quality.Yan et al.[18],Yu et al.[15],and Liu et al.[44]also managed to solve the problem of irregular region repair.
Recently, the video target removal task [25-29] has also developed more rapidly as an extension of image inpainting.A new End-to-End paradigm for Flow-Guided Video Inpainting was put forth by Li et al.[28], and both qualitative and quantitative measures supported the method's efficacy.However, such methods mainly focus on the already generated video frame.These methods can only process less than one frame per second, with a large gap from real-time video processing.No effective real-time algorithm can be implemented for the real-time hiding of military timesensitive targets.Therefore, we propose an automatic target stealth method based on real-time mask generation, using a datadriven approach for learning and finally generating the hidden video data in real-time.
3.Proposed method
3.1.Overview of our method
Previous work has verified the effectiveness of generative adversarial networks for image-hiding tasks.However,today there is still a lack of an algorithm that can quickly hide military timesensitive targets in real-time.We proposed an intelligent algorithm for hiding military time-sensitive targets based on an encoding and decoding framework and generative adversarial networks to address this problem.Fig.2 depicts the algorithm's overall picture.
Our algorithm consisted of two main stages:The first stage used an improved semantic segmentation algorithm to obtain the realtime mask of the current frame input image.The second stage used a GAN network to achieve time-sensitive targets stealth,thus wholly erasing the time-sensitive target from the image.To address the problem of inaccurate segmentation of time-sensitive targets in semantic segmentation, thanks to the wide application of morphology in binary image processing, we added an external expansion module and a hole-filling module to lay the foundation for the second stage of target stealth.In the next step, the input image and the real-time mask were fed into a generative adversarial network that consisted of two main parts, first, an initial image reconstruction used a coarse feature network based on an encoding-decoding structure and, later, a final target stealth through a two-branch refinement network with contextual attention.
3.2.Real-time mask generation
To apply a generative network to hide military time-sensitive targets, we first need to generate a mask matrix in real time to contaminate the area to be hidden.In this paper,we implemented real-time mask generation by semantic segmentation method and mask expansion module.Chen et al.[34] extended the encodingdecoding architecture based on the classical semantic segmentation algorithm of Deeplabv3.They proposed the Deeplabv3+method, which uses Deeplabv3 as an encoder and constructs a simple and effective decoder to achieve the fusion of features at different levels, reducing the number of parameters while increasing the running speed.Therefore,this method was selected as the first stage of the semantic segmentation model.The network architecture of the semantic segmentation algorithm based on encoding-decoding is shown in Fig.3.
3.2.1.Backbone network optimization
Unlike other Deeplab [34,35] series algorithms, the Xception[38]series was used as the backbone feature extraction network in the architecture of this paper.The Xception series model is an improvement of Inception-v3 [11], which has shown high performance in image classification and target detection.Based on this paper, we improved on Aligned Xception by modifying the structure of the entry flow network and replacing all maximum pooling layers with deep separable convolution with stride ability,thus improving the model effectiveness and computational efficiency.
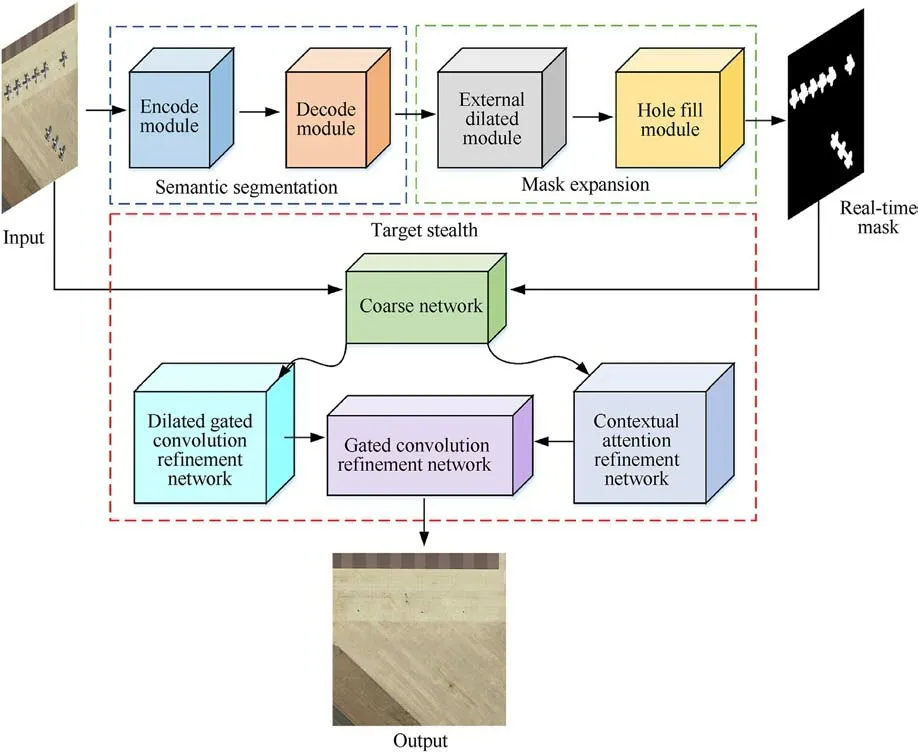
Fig.2.Overview of the intelligent stealth algorithm for military time-sensitive targets.
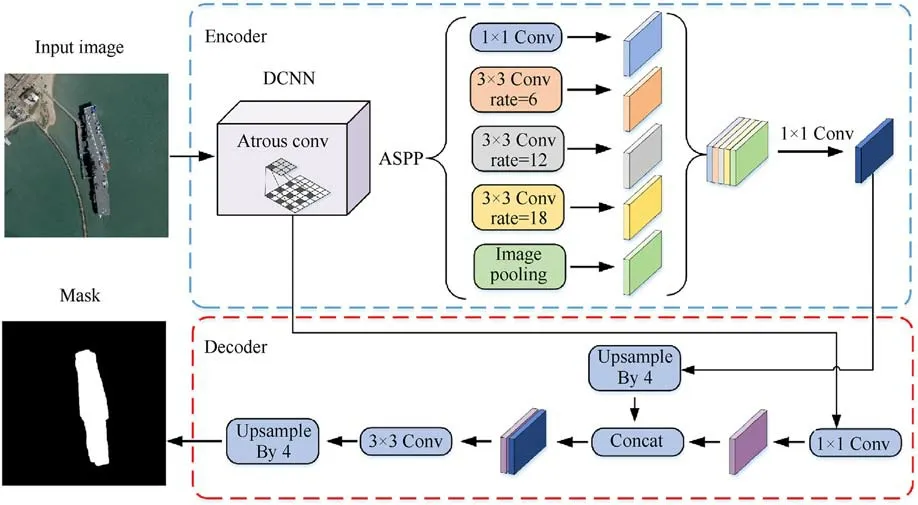
Fig.3.Encoder-Decoder semantic segmentation network architecture.
In the original depth-separable convolution, the depthwise convolution of the input feature map was performed first,followed by the pointwise convolution.In contrast, the depth-separable convolution in Xception expands the channel using 1 × 1 convolution, followed by the depth convolution, and finally, concat.This is called atrous separable convolution, and we can extract feature maps with arbitrary resolution.
3.2.2.Atrous convolution-based encoder-decoder architecture
Usually,we use down-sampling to reduce the computation and increase the perceptual field in deep neural networks,but this leads to a large amount of missing information at the expense of spatial resolution.On the one hand,we can increase the perceptual field to achieve large target segmentation by using cavity convolution.On the other hand, we can improve the resolution to attain precise target localization compared to the downsampling method.
Fig.2 shows that an ASPP (Atrous Spatial Pyramid Pooling)structure is also included in the encoder, i.e., it contains a 1 × 1 convolution, three different rates of atrous convolution, and an ImagePooling layer.First, the ASPP operation is performed on the advanced feature layer, which is compressed four times, the local features were extracted from the image by convolution operation,and ImagePooling implements global feature extraction, feature superposition, and fusion are performed after the multi-scale features are extracted.Finally,the features were compressed by a 1×1 convolution.
In the decoder,we adjusted the number of channels using 1×1 convolution for the initial effective feature layer compressed twice and then concatenate with the up-sampling results of the effective feature layer after the atrous convolution.Then, we performed a refinement operation on the stacked features using 3 × 3 convolution, followed by a quadruple bilinear up-sampling.At this moment, we obtained a final effective feature layer, which is the feature condensation of the whole image.
3.2.3.Mask expansion
Due to the limited quality of data annotation used for training and the mask output of the segmentation model, there is a phenomenon where some targets in the mask image cannot be fully segmented.This increases the difficulty of the hidden algorithm,resulting in poor target hiding performance.Therefore,we added a mask optimization algorithm to the mask output port,as shown in the mask expansion module in Fig.1.Morphology offers a comprehensive and effective solution to numerous image processing issues.Inspired by the widespread use of mathematical morphology for binary image processing, our mask expansion module consisted of two main parts: external dilated and hole fill.
External expansion is similar to"domain expansion",where the target region in the image is expanded to "grow" or "coarsen" the target in the binary image, and the external expansion often be expressed as follows:
where I is the original mask image output by the model, E is the structure element, z is the reflection translation, and ^E is its reflection with respect to the origin.The external expansion of B to I is the set of all shifts z, under the condition that the foreground elements of ^E overlap with at least one element of I.
Hole fill is also the filling of the background area that is surrounded by a border connected by foreground pixels,also known as hole fill.In short, it is to first find a point in the hole, use the structural elements to expand, then use the complement of the original image to constrain, keep repeating the expansion,constrain until the graph does not change (i.e., convergence) to stop, and finally find an intersection with the original graph, and the hole is filled.I(x,y) represents a binary mask image, and we define a labeled image F(x,y) with all positions 0 in the image except for the border position 1- I, the equation is as follows:
Thus,a binary mask image H(x,y)with the holes filled is shown in the following equation.
where RDis the morphological expansion reconstruction, c is the complement operation.Specifically, First perform the complementary set operation on the binary masked image I(x,y).Complement I(x,y)cof I(x,y) sets all foreground pixels to background pixels, while setting background pixels to foreground pixels.The hole is surrounded by foreground pixels by definition; therefore,the operation creates a wall of zeros around the hole.Then Perform expansion reconstruction for F(x,y) with template I(x,y)c.The results show that all positions of the reconstructed image corresponding to the foreground pixels of I(x,y) are now 0.Finally, a complementary set operation is performed to obtain a mask image H(x,y) in which the holes have been filled.
3.3.Target stealth network
The traditional GAN-based image inpainting algorithm suffers from problems such as distorted complementary regions and blurred detailed texture edges.Yu et al.[14,15] proposed a system for free-form image inpainting by incorporating gated convolution into deep adversarial generative networks.Inspired by their work,we derived a contextual generative network for hiding targets.Combined with the real-time mask generation module in the previous section, we applied this generative network to achieve realtime stealth of military time-sensitive targets.
We used the complete model architecture from the literature[15]for reconstructing the hidden target's background region,and the algorithm's overall structure is shown in Fig.4.Like traditional generative adversarial networks,the architecture includes a coarseto-fine two-stage generator based on gated convolution and a fully convolutional spectral-normalized Markovian discriminator.The generator is responsible for capturing the distribution of sample data through iterative data training.The discriminator is responsible for determining whether the samples are generated fake data or real data.The generator consists of a coarse network and a twobranch contextual attention-based refinement network,each using an encoder-decoder architecture,where the core is the use of gated convolution instead of all normal convolution for free-form military time-sensitive target stealth.Assuming that the input and output are channels C and C′, respectively, the gated convolution formula for each pixel located at (b,a) is as follows:hthe kernel size, k′h= (kh- 1)/2, k′w= (kw- 1)/2, Mp∈Rkh×kw×C×C′and Mq∈Rkh×kw×C×C′are two different convolutional filters, I(b+i,a+j) and Ψ(b,a) are inputs and outputs.φ represent sigmoid activation function.Consequently,the output gating value can be set between 0 and 1.φ denotes activation function(e.g.,ELU and LeakyReLU), ⊙denotes element-wise multiplication.
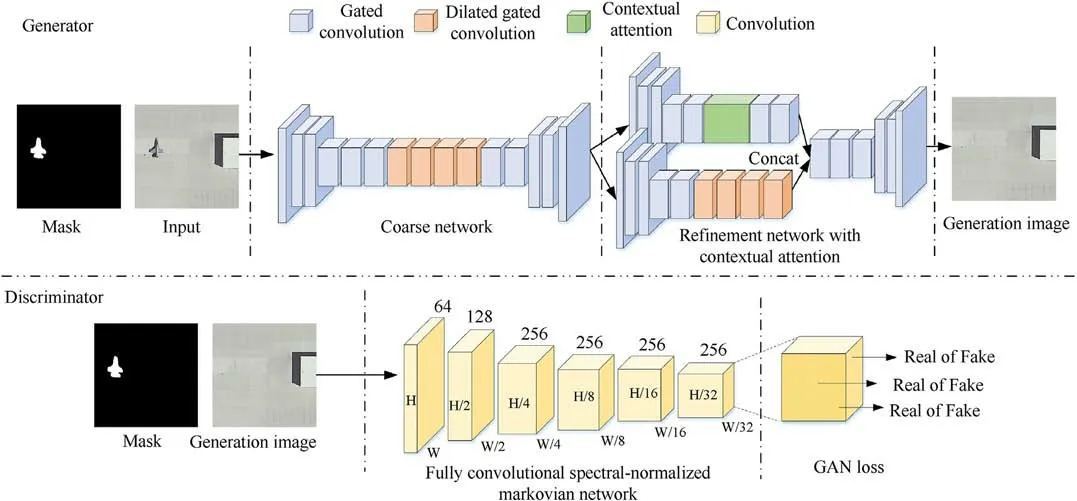
Fig.4.Structure of the time-sensitive object stealth network.
We learned a dynamic feature selection mechanism for each channel and spatial location using gated convolution, such that it can select features based on background and mask.Even in the deep layer, the gated convolution learns to emphasise masked regions in various channels in order to produce a better background for target stealth.For stable training of generative adversarial networks, we used spectral normalization [45], a fast convergence method, and the hinge loss is expressed as
where LGand LDrepresent the objective functions of the generator and discriminator, respectively.D represent spectralnormalized discriminator.G is image inpainting network that takes incomplete image z.
4.Results
4.1.Settings
4.1.1.Hardware/software environment
The experiments below were carried out on a server with an Intel Xeon Gold 6230(2.1 GHz/20C/27.5ML3)CPU×2,NVIDIA RTX 8000 × 2 with 192 GB of memory, and Python code running on Ubuntu 18.04.With CUDA10.1, CuDNN7.6.5, PyTorch1.6, and other widely used deep learning and image processing libraries installed,our development environment was pycharm2022.
4.1.2.Dataset
Semantic segmentation datasets for standard objects, such as PASCAL VOC[46]and MSCOCO,have been released,which contain some time-sensitive objects such as aircraft and ships.However,the military targets in these datasets are minimal, and it is challenging to meet the needs of real-time mask generation for military time-sensitive targets.In this work,we established a dataset based on PASCAL VOC,DIOR[47],called the Military time-sensitive Target Masking Dataset (MTMD).We selected 867 images of aircraft and ships from the PASCALVOC2012 and DIOR datasets as military timesensitive targets.In addition, we obtained 594 images of timesensitive targets through software simulation and Internet downloads, mainly including ships and aircraft.EISeg-develop [48], as a semantic segmentation annotation tool, is used to annotate military time-sensitive target images in PASCAL VOC format.
4.1.3.Training details
Our model training was divided into two parallel branches,training the mask generation network and the object stealth network.First,we divided the MTMD data set,where training set to validation set to test set ratio was 7:2:1.Then, the real-time mask generation network was trained using the MTMD dataset.The training parameters were set as follows: the batch size, learning rate, optimizer and epoch are initialized as 32, 7× 10-4, SGD and 300, respectively.The target hidden network had a total of 4.1 M parameters.We used the public dataset Places2 [49] to train the model.The following training settings were established: the learning rate, beta1, beta2, iters and batch size were initialized as 0.0001,0.5,0.9,500000 and 32.The size of the feature map in the discriminator was 64,while that of the feature map in the generator was 32.
4.2.Object segmentation mask comparison
For the proposed Real-time military time-sensitive target stealth method,as mentioned above,the essential point is that the segmentation mask obtained in real-time can completely cover the time-sensitive target.Otherwise, there will be space distortion,texture details disorder,Etc.It can be observed that the aircraft and ship targets in Fig.5 are partially hidden.We can see the contours of airplanes and ships; the main reason for the failure is that during the real-time mask generation stage,the network did not segment a valid mask image (i.e., the mask image cannot fully cover the hidden area).Therefore,in the target stealth stage,it is impossible to achieve good results,and contours that are not masked can cause defects such as texture distortion when the method generates the background.For algorithm evaluation, we favor high recall over precision.In this section, we experimentally validated the object segmentation mask algorithm on the MTMD dataset.In this section,according to previous work[50],we choose mIoU,mPrecision,and mRecall as our evaluation metrics.We compared our approach to modern baselines,including PSPNet[33],UNet[42],and HrNet[51].To ensure a fair comparison, we configured the training hyperparameters (epoch, learning rate, whether to pre-train, etc.) for each algorithm in the same way on the same device.
Table 1 contains the quantitative evaluation findings for our approach and other benchmarks.Our method significantly outperforms the previous baseline in mIoU and mRecall metrics and is suboptimal in the mPrecision metric.This means that a more complete and accurate target segmentation mask can be obtained using our method, and more importantly, the foundation for subsequent target stealth can be laid.
Precision refers to the probability of being a positive sample among all predicted positive samples, specific to the predictedresults.Recall is for the original sample, which means the probability of being predicted as a positive sample in the actual positive sample.We hope for high precision and recall, but they are contradictory.The above two indicators are contradictory and cannot achieve both.Due to the phenomenon of incomplete segmentation of the target, this increases the difficulty of the hiding method.To overcome this problem,our method has added a mask optimization method called mask dilation module, which will cause the segmentation results to spread around,decreasing the accuracy of the method.However, it is exciting that the recall rate of the method will be improved,laying a good foundation for the second stage of target hiding.Compared with PSPNet, the algorithm proposed in this paper has a significant advantage in recall rate, followed by a loss of partial accuracy.Therefore, the accuracy of the algorithm proposed in this paper is slightly lower than that of PSPNet.
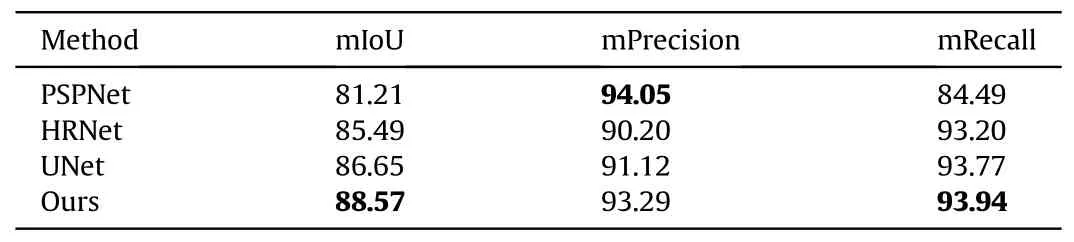
Table 1 Segmentation Quantitative results on the MTMD datasets.
Fig.6 shows the qualitative results of our segmentation method.The first column displays the original image, and the following columns display the Ground Truth (GT) and the corresponding results of the five segmentation methods.The methods are HrNet,PSPNet, UNet, SAM [52] and MTTSNet (Ours).The hidden results obtained based on these segmentation results are provided.These examples demonstrate the effectiveness of our method in fully covering the target.Compared with HrNet, PSPNet, and UNet algorithms,the SAM method has more accurate segmentation and better segmentation performance.Through the results of target hiding, it can be found laterally.Compared with other algorithms,our method can more completely segment military targets and lay the foundation for subsequent target hiding.In the hiding stage,incomplete segmentation will generate many target shadows,resulting in a poor hiding effect.Even if the segmentation is complete,the hiding effect will still be poor due to edge shadows during the target hiding process.

Fig.5.Object stealth failure results.

Fig.6.Visual comparison of different segmentation approaches.Left to right: Original, GT, HrNet, PSPNet, UNet, SAM, ours.
4.3.Object stealth comparison
4.3.1.Quantitative results
We compared our algorithm with three classes of classical algorithms, including CRfill [53], CTSDG [54], and RFR [55].To demonstrate the method's effectiveness, we next evaluated the targets stealth algorithm on the MTMD dataset.Inpainting lacks effective quantitative evaluation metrics,as stated in Ref.[14].As a result, it is challenging to evaluate image completion outcomes quantitatively, and there is no agreement on the best statistic to apply.Here, we present the findings of a number of distinct measures for reference.First,peak signal-to-noise ratio(PSNR)metrics will be used to assess the visual quality of the recovered images produced by the various methods.These metrics measure the difference between the original image and the repaired image.The ratio between the maximum possible power of the PSNR measurement signal and the power of the added noise.In addition,the structural similarity index (SSIM) metric will be used to measure the structural similarity between the original image and the restored image.The evaluation metrics are calculated as follows:
where PSNRS,Istands for the peak signal-to-noise ratio between the complementary image and the source image.m is the image height,n is the image width,S is the original image,I is the complemented image.(2t-1)2is the square of the maximum value of the signal and t is the number of bits per sample point.
where parameters C1and C2are used to stabilize the algorithm.SSIMS,Idenotes the similarity between the source image and the inpainting image.μ and σ denote the mean and standard deviation of the images.
A random selection of 146 images from the MTMD test set and irregularly masked images of various sizes are used to evaluate the targets stealth algorithm.The irregularly masked images are divided into five groups according to size.As shown in Table 2,PSNR and SSIM represent the mean of all values tested.The greater the PSNR value,the closer the SSIM value is to 1,indicating higher image fidelity.The approach presented in this study is the most effective across all measures of the four approaches.The increase in PSNR and SSIM suggests that our results are closer to the actual data.Superior results show that our algorithm can generate less distorted images and visually more believable content, and better spatial and temporal consistency.
4.3.2.Qualitative results
Fig.7 shows the visual comparison results of various targetstealth methods.The first column in the figure contains eight images to be hidden.The aircraft and ships in the figure are the targets to be hidden.The second column contains real-time mask images generated from these eight images.The following four columns show the hidden results obtained by four methods: CTSDG, CRfill,RFR, and Ours.In order to present the method results more prominently,we will enlarge some of the red box areas.The hidden targets in Tests 1 and 2 account for a large proportion of the entire image, and it can be found that the RFR method still has contour information of the hidden targets, while the CTSDG and CRfill methods have some pixel overflow phenomenon.Compared to these methods, only our method performs excellently in this scenario.The method completes the background information in more detail.Tests 3 and 4 demonstrate the stealth results of various algorithms for dense aircraft and ship targets in air-ground view.The CTSDG and RFR methods suffer from many visual artifacts and edge responses, while CRfill produces better results.However, the faded area still has some chromatic aberration compared to the surrounding background, while our method produces a more natural image.There is more interference information around the target to be faded in tests 5 and 6.It can be found that the results of stealth by the three previous algorithms all have a large amount of target structure information.In contrast, our method has a high degree of realism and guarantees edge details while stealth the target.The difficulty of Tests 7 and 8 lies in the complex background around the target being hidden, which can cause image distortion and other issues during background restoration.Currently, most background restoration methods rely on the information around the background to be repaired, which is propagated through surrounding pixels to achieve restoration.It can be found that the stealth results of CTSDG and RFR methods still have target vignettes and poor stealth effects,while the CRfill method makes the stealth area more blurred, and the stealth results of the algorithm in this paper have the best visual effect.
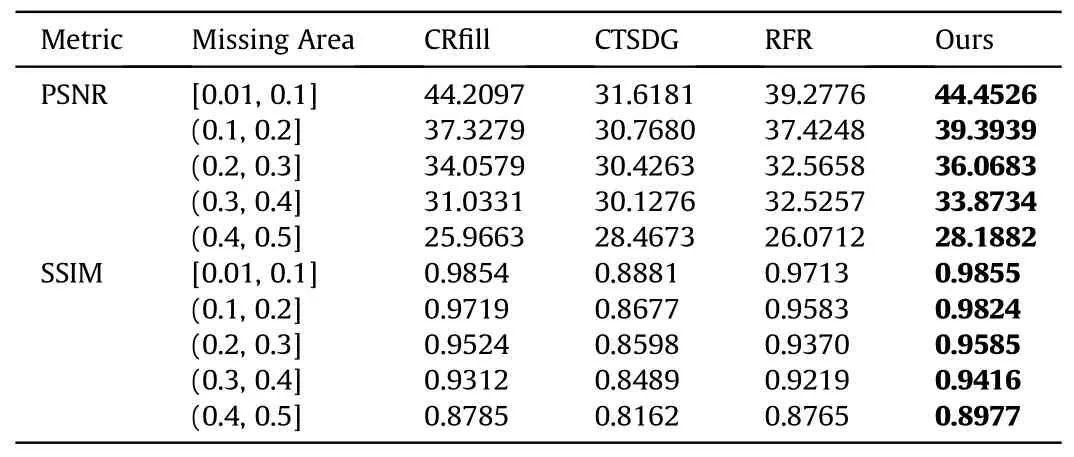
Table 2 Quantitative comparison between different methods.

Fig.7.Comparison of several inpainting techniques visually.Original, Mask, CTSDG, CRfill, RFR, and ours, from left to right.
4.3.3.User study
We conducted a user study of the targets stealth algorithm and enlisted the help of 14 participants in order to undertake a more thorough comparison.From the test set,20 pictures were chosen at random.Then, for comparison, we computed the outcomes of the following four methods,including(1)CTSDG,(2)CRfill,(3)RFR,and(4)Our model.We have done two types of user studies.(A)We rank each method's stealth outcomes (1-10), with greater scores being better.Then calculate the average score for each method.(B)Out of the findings produced by the four approaches,each participant was asked to select the best one.The results of this test depend on the subjective visual perception of each participant.The results of the user study are presented below.
4.4.Video real-time object hiding experiment
The proposed method was compared to the well-known videobased image completion method E2FGVI [28].E2FGVI utilizes the spatiotemporal information of the video sequence to fill in the hidden target area.However, such methods cannot process the collected data in real-time and require early annotation of the video to be processed.We evaluated the performance of E2FGVI and our proposed method based on the inference time.According to the experimental findings,the inference time for each frame of E2FGVI is 0.16 s, while our method only needed 0.069 s to complete the inference process for one image frame.The visualization comparison results of the two methods are shown in Fig.8, and it is discovered that the method proposed in this paper has superior detail restoration capability, and the stealth effect of the target is more pronounced in certain scenarios.
5.Conclusions

Fig.8.Visual results compared with E2FGVI.
MTTSNet was a novel end-to-end military time-sensitive target stealth network proposed in this article.The method consisted of two components, an encoder-decoder network based on an expansion module and a two-branch generative adversarial network, which were used to solve the real-time mask generation and object stealth problems, respectively.In the real-time mask generation stage, the encoder-decoder structure was used to achieve multi-scale feature fusion, and we enhanced the target localization and segmentation accuracy by introducing expansion and padding modules.In the target stealth stage, a gated convolutionbased generator model was used to generate the image after the target is hidden, whereas intensive training increases the discriminator's capacity to discern between real and fake images.Extensive qualitative and quantitative experimental results indicate that MTTSNet outperformed the majority of advanced methods in quantitative metrics and visual perception.In the future, we will, on the one hand, further optimize the model to improve the performance of target concealing, and, on the other hand,we will lighten the network to improve the algorithm's realtime performance.In terms of method application, we hope that this method can be applied not only in the military but also in the civilian field.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China(Grant No.62276274),Shaanxi Natural Science Foundation(Grant No.2023-JC-YB-528), Chinese aeronautical establishment (Grant No.201851U8012)

- Defence Technology的其它文章
- Explosion resistance performance of reinforced concrete box girder coated with polyurea: Model test and numerical simulation
- An improved initial rotor position estimation method using highfrequency pulsating voltage injection for PMSM
- Target acquisition performance in the presence of JPEG image compression
- Study of relationship between motion of mechanisms in gas operated weapon and its shock absorber
- Data-driven modeling on anisotropic mechanical behavior of brain tissue with internal pressure
- The effect of reactive plasticizer on viscoelastic and mechanical properties of solid rocket propellants based on different types of HTPB resin