
基于改进YOLOv5 模型的农作物病斑图像自动标注
2024-04-01 05:27:30马文宝田芳明谭峰
黑龙江八一农垦大学学报 2024年1期
马文宝,田芳明,谭峰
(黑龙江八一农垦大学信息与电气工程学院,大庆 163319)
人工智能正在改变着人类的生活,深度学习作为人工智能的一个应用方向,成为过去十年该研究领域取得的关键性成就之一,其在计算机视觉、图像处理、语音分析识别和自然语言处理等场景下都取得了极大的突破[1-2]。例如,马晓丹[3]采用神经网络实现了大豆叶片病斑区域的识别,识别准确率达到100%,证明了神经网络对农作物病斑识别的可行性,同时为水稻、玉米等农作物的叶片病斑识别提供理论依据。刘凯旋[4]设计了一种基于级联R-CNN 的水稻害虫检测算法,算法使用了2 855 张照片,使用labelImg 标注水稻害虫类别和位置后形成训练集,然后进行模型训练,最终多种害虫检测准确率平均值mAP 达到94.15%,检测效果取得了较大提升。上述监督学习模型需要利用几万、甚至几十万张标注数据训练模型,如ImageNet 用于物体分类的数据集,分为2 万个类别,共1 400 万张图像[5],Microsoft COCO用于物体分类的数据集共250 万张图像。这些数据集数量十分庞大,并且大多数都是靠手工标注的,如亚马逊的众包平台亚马逊土耳其机器人(AMT,Amazon mechanical turk)数据标注[6]。这种方式虽然为社会提供了就业机会,但是其标注成本高且效率低,存在费时耗力的问题。因此,如何提升标注效率,降低标注成本,成为研究人员进行深度学习研究所面临的一个重要问题。针对上述问题,以农业图像研究方向中水稻茎叶病斑标注为目标,提出基于YOLOv5 改进的图像自动标注方法。
1 实验材料与设计
1.1 实验材料
在Kaggle 上下载600 张水稻茎叶病斑图片组成了实验使用的数据集,图片中包含许多小目标病斑和数量密集的病斑,可以用来训练模型对小目标和密集目标的感知。图片挑选后用LabelImg 软件手工标注,采用txt 格式的标注文件进行训练,标注后的图像如图1 所示。研究将数据集中的600 张图片以3∶1 的比例进行划分,其中450 张图片作为训练集,150 张图片作为验证集。

图1 标注后的水稻茎叶病斑图像Fig.1 Marked image of disease spots on rice stems and leaves
1.2 实验环境
实验的操作系统为Windows11,CPU 型号为Intel(R)Core(TM)i5-12400F CPU @ 2.5 GHz,运行内存为16 GB。GPU 型号为NVIDIA GeForce RTX 3060,显存为12 GB,硬盘为500 GB。代码测试环境使用的Pytorch 的版本为1.11,Python 的版本为3.7.11,使用CUDA11.3.1 和CUDNN8.2.1 对GPU 进行加速。
1.3 实验设计
为了验证改进模型的有效性,并且能够实现植物病斑图像的快速标注,搭建了Python 和Pytorch 的实验环境,通过Kaggle 平台下载的水稻病斑图像进行手动标注,对YOLOv5 模型结构进行改进,为了验证改进的有效性,在水稻茎叶病斑图像上实验,然后验证结论的有效性[7]。实验流程如图2 所示。

图2 实验流程Fig.2 Experimental flow
2 YOLOv5 结构的改进
2.1 改进YOLOv5 模型结构
YOLOv5 的网络结构由Input、Backbone、Neck 和Prediction 四部分构成[8],对YOLOv5 网络结构进行改进,其中,将FPN(Feature Pyramid Networks)改进为加权双向特征金字塔网络BiFPN(Bidirectional Feature Pyramid Network),相比FPN 来说BiFPN 增加了双向交叉尺度连接和加权特征融合,可以更加方便、快速的进行多尺度特征融合。由于Backbone 部分是由多层卷积层堆叠,导致特征提取并不充分和模型泛化能力差,将ViT(Vision Transformer)模型引入Backbone 部分,将C3 与ViT 结合形成C3TR 模块,用来提升Backbone 部分的特征提取能力。同时将YOLOv5 中的IoU(Intersection of Union)函数替换为CIoU 损失函数,使预测框更加符合真实框。尝试将C3TR 模块替换YOLOv5 网络结构中不同位置的C3模块,主要分为两种替换方式。其中第一种替换方式是将SPPF 之前的C3 模块进行替换,为了方便区分并命名为YOLOv5-TR-BiFPN。另外一种替换方式是除了替换SPPF 前的C3 模块为C3TR 模块,并将Neck 部分中的3 个用于特征提取的C3 模块替换为C3TR 模块,并命名为YOLOv5-TR-BiFPN-1。以上两种结构如图3 所示。
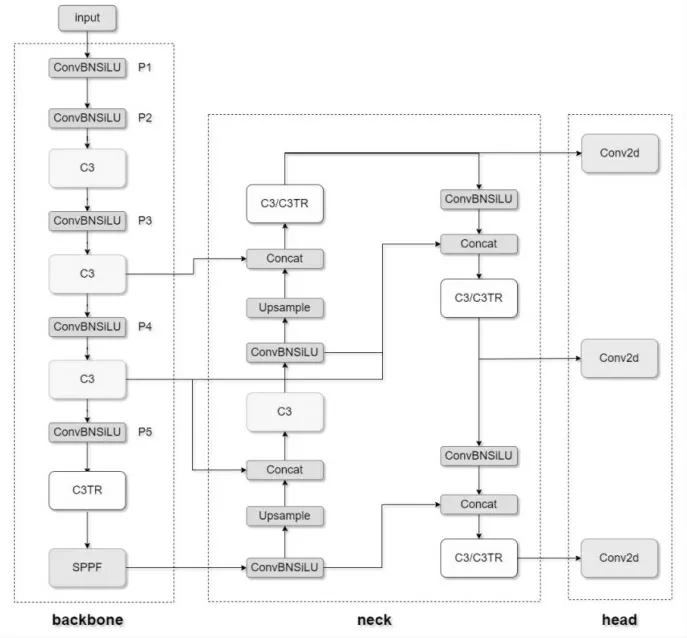
图3 改进的YOLOv5-TR-BiFPN 结构Fig.3 Improved YOLOv5-TR-BiFPN structure
2.2 Vision Transformer 模块
Transformer 是由谷歌在2017 年针对自然语言处理领域提出的模型。由于更早的RNN(Recurrent Neural Network)模型记忆长度有限且无法并行化,Transformer 克服了RNN 的问题,在自然语言处理领域引来极大的震动。最近一些文章创新性地将Transformer 技术跨领域地引入到计算机视觉任务中,开创了视觉领域的新时代。2020 年10 月谷歌的Dosovitskiy 等人提出了ViT(Vision Transformer)模型,主要由Embedding、Transformer Encoder、MLP Head三层构成,是基于自注意力机制的图像分类方案。
ViT 模型为了将图像转化成Transformer 结构可以处理的序列数据,引入了图像块(patch)的概念。首先将二维图像做分块处理,每个图像块展平成一维向量,接着对每个向量进行线性投影变换(Linear Projection of Flattened Patches),同时引入位置编码[9](Position Embedding),加入序列的位置信息,在输入的序列数据之前添加了一个分类标志位(class),更好地表示全局信息[10],然后将这些信息输入到Transformer Encoder 模块中进行编码,在Transformer Encoder 模块中引入了多头注意力机制[11](Multi-Head Attention),多头注意力机制能够联合来自不同head部分学习到的信息,因此可以学习到多种目标的特征。通过Transformer Encoder 后输出和输入的形状是保持不变的,由于ViT 模型是分类模型,所以要提取出分类标志位(class)中生成的对应的分类结果,将其传递给MLP Head,MLP Head 模块由全连接层组成,通过MLP Head 可以得到最终的分类结果,ViT模型结构如图4 所示。

图4 ViT 和Transformer Encoder 结构图Fig.4 Structure diagram of ViT and transformer encoder
将ViT 模型进行修改与YOLOv5 中的C3 卷积模块融合形成C3TR 卷积模块,并嵌入到YOLOv5 模型的Backbone 中,增强Backbone 的特征提取能力。曾尝试将YOLOv5 中所有卷积模块替换为C3TR 卷积模块[12],但是运算量太大,GPU 内存被占满,导致训练不能继续。将YOLOv5 的Backbone 部分C3 模块和Neck 部分C3 模块分别替换为C3TR 卷积模块时虽然能够训练,但是模型运算量依然很大,GPU 内存最多只能运行一个batch_size,训练结果也不够理想。经过测试与对比发现只将SPPF 模块前的一个卷积模块替换为C3TR 卷积模块,可以达到一个良好的训练结果,所以,将改进后的ViT 模型融合到YOLOv5的Backbone 部分。
2.3 加权双向特征金字塔
多尺度特征融合就是融合不同分辨率的特征图,方法存在各个尺度的特征信息不一致的问题,所以,Tan 等[13]提出了加权双向特征金字塔(Bidirectional Feature Pyramid Network,BiFPN),BiFPN 采 用高效的双向交叉尺度连接的方案,其结构图如图5所示,因为只有一个输入边界且没有特征融合的节点信息量有限,对融合不同特征的特征网络没有太大贡献,所以,BiFPN 通过移除这些节点来简化双向网络,同时也能减少计算量。另外就是加权特征图融合,为了在不增加成本的情况下融合更多的特征,并增强特征的表示能力,在原始输入到输出节点处于同一水平的时候增加一条残差边,BiFPN 将每个双向路径当作一个特征网络层同时重复多次,从而实现更高层次的特征融合,由于不同输入特征的不同分辨率对输出特征的贡献不同[14],所以针对融合的各个尺度特征增加一个权重,调节每个尺度特征的贡献度,并让模型学习每个不同权重的输入特征[15]。BiFPN 采用Fast normalized fusion 加权融合方法,每个标准化权重的取值范围为(0,1),但是由于没有softmax 操作,因此效率更高,从而提高检测速度。为了更好地平衡不同尺度的特征信息,更高效的进行多尺度特征融合,将YOLOv5 结构中的FPN 改进为BiFPN。
图5 BiFPN 结构图Fig.5 Structure diagram of BiFPN
2.4 CIoU 损失函数
YOLOv5 模型的Bounding Box 损失则采用了GIoU 损失函数计算损失,GIoU(Generalized Intersection over Union)解决了IoU(Intersection over Union)检测框和真实框没有重叠时Loss 等于0 问题。但是当检测框和真实框出现包含的时候GIoU 退化成IoU,当两个框相交时,在水平和垂直方向上收敛变慢[16]。DIoU 要比GIou 更加符合目标框回归的机制,将目标与anchor 之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU 一样在训练过程中出现发散的问题。CIoU(Complete-Intersection over Union)相比DIoU 充分考虑了预测框的长宽比和目标框之间的长宽比的一致性[17],从而提升预测框接近真实框的概率,所以,将YOLOv5 中计算Bounding box 的损失函数由GIoU 改进为CIoU,在使用预测框标注图像时可以使预测框更加接近真实框的位置。CIoU Loss的计算公式如式(1)所示。
其中ρ2(b,bgt)分别代表了预测框和目标框的中心点的欧氏距离,c 代表的是最小包围两个边界框的闭包区域的对角线距离,v 代表目标框和anchor 框之间的长宽比相似度,α 是权重函数[18],α 和v 的公式如式(2)所示,其中分别代表目标框和预测框的宽高比。
2.5 CIOU-NMS
非极大值抑制(Non Maximum Suppression,NMS),在计算机视觉任务中都有广泛应用,例如边缘检测、目标检测等,NMS 中需要计算当前得分最高的检测框和其他检测框之间对应的IoU 值,并将超过阈值的预测框全部过滤。由此可以知道在传统的NMS 中IoU 值的作用是控制预测框是否被滤除。但是在IoU 值比较大时,NMS 会出现滤除过多的现象,导致很多对象没有目标框产生漏检,所以NMS 的IoU 设置要同时考虑到预测框与真实框的重叠面积、中心点距离、长宽比等方面因素,这样才能剩下位置更加准确的目标框[19]。但是IoU 只考虑到了预测框与真实框重叠区域,并没有考虑到中心点距离、长宽比。CIoU 克服了IoU 的缺点,CIoU 同时兼顾了预测框与真实框的重叠面积、长宽比、中心点距离[20],这样过滤后剩下的预测框就会更加的符合现实场景的使用,因此,将YOLOv5 中的IoU-NMS 改进为CIoUNMS,这样就可以保证滤除掉多余预测框之后剩下的预测框与真实框位置最接近,保证图像中的每一个目标都被预测框选中。CIoU 的公式如式(3)所示,传统NMS 计算公式(4)。
其中si代表每个边框的得分,M 为当前得分最高的框,bi为剩余框的某一个,Ni为设定的阈值,可以看到,当IoU 大于Ni时,边框的得分直接置0,相当于被舍弃掉了,这就会造成边框被过滤导致目标漏检,而CIoU-NMS 考虑了中心点距离、长宽比,认为两个中心点较远同时IoU 比较大的Box 可能位于不同的对象上,不会将其删除,这样就会降低目标漏检的概率。CIoU-NMS 的计算公式如式(5)所示:
3 实验
3.1 实验参数设置
为了测试相同条件下不同模型的性能,在模型训练过程中均使用相同的数据集和参数设置,并对训练结果进行对比,部分训练参数设置如表1 所示。

表1 参数设置Table 1 Parameter settings
3.2 模型训练算法
模型输入为水稻病斑图像及标注文件,模型的输入初始化参数包括学习率、批量大小、动量、IoU 阈值、yaml 配置文件、数据增强系数和训练轮数,在准备的数据集基础上,分别加载训练集和测试集,对输入图像进行预处理,包括调整图像大小和数据增强,其中,数据增强包括Mosaic、Mixup、Copy_paste 等,预处理后加载初始化参数、配置和数据集,然后,加载网络模型并对输入图像进行处理,随着epoch 增加不断更新学习率筛选出最佳模型,保存权重文件和AP、mAP 等指标数据。
3.3 评价指标
实验使用平均精度均值mAP(mean Average Precision)、准确率P(Precision)、平均准确率AP(Average Precision)、召回率R(Recall)、F1 值(F1-score)等评价指标对模型进行评价,计算公式如式(6)所示,其中TP 为正类样本被模型预测为正类的比例;TN 为负类样本被模型预测为负类的比例;FP为负类样本被模型预测为正类的比例;FN 为正类样本被模型预测为负类的比例[21]。
3.4 实验结果与分析
基于YOLOv5s 改进了模型结构,在训练时将改进后的YOLOv5-TR-BiFPN 模型先在coco128 上进行300 轮预训练获得训练权重,然后使用预训练权重在手动标注的水稻茎叶病斑图像数据集上进行200轮训练,训练获得mAP_0.5 达到73%,mAP_0.5∶0.95达到35%,准确率Precision 达到86.3%,召回率Recall 达到86%,如图6 所示。

图6 改进后的YOLOv5-TR-BiFPN 模型训练结果Fig.6 Improved YOLOv5-TR-BiFPN model training results
研究对YOLOv5 模型结构进行了改进。由于ViT基于自注意力机制的图像分类方案具有优秀的分类表现,因此,研究将ViT 和YOLOv5 结构中的C3 模块结合形成C3TR,并用C3TR 替换YOLOv5 结构中原有的C3 模块,用于提升YOLOv5 的模型准确率。由于YOLOv5 中采用了很多C3 模块,因此替换不同位置的C3 会得到不同的效果,研究只采用两种替换方案分别命名为YOLOv5-TR-BiFPN 和YOLOv5-TR-BiFPN-1。另外,研究将BiFPN 融入到YOLOv5结构中,用于增强YOLOv5 的特征提取能力。为了能够分析出每一项改进对YOLOv5 的影响,分别训练YOLOv5s、YOLOv5-TR、YOLOv5-BiFPN、YOLOv5-TR-BiFPN 和YOLOv5-TR-BiFPN-1 五种结构的模型,最终对比改进模型获得的效果。五种模型训练的准确率对比如图9 所示,mAP 值如图7 所示。

图7 五种模型训练平均准确率对比Fig.7 Comparison of mAP_0.5 of five models
将五种模型训练后,通过准确率对比图、平均准确率对比图,可以看到YOLOv5-TR-BiFPN 和YOLOv5-TR-BiFPN-1 两个模型的收敛速度相对于另外三个模型来说较快,并且YOLOv5-TR-BiFPN的平均准确率最高。改进后的YOLOv5-TR-BiFPN相比YOLOv5s 模型的平均准确率(mAP)提升了3.8%,召回率(Recall)提升了3%,F1 值提升了3%,权重大小相差0.1 M,训练结果详细对比如表2 所示。

表2 模型训练结果对比Table 2 Comparison of model training results
从表2 中可以看到YOLOv5-TR-BiFPN 结构模型的训练效果最好,所以,将改进结构训练获得效果最好的权重文件进行模型验证,采用训练过程所使用的一部分图像对模型进行验证。同一幅手动标注的图像和验证模型标注的图像见图8 和图9。经过对比可知,图8 中一块未标注的病斑在图9 模型验证过程中被成功标注。因此,该模型可准确标注病斑,达到了预期效果。

图8 数据集中手动标注的图像Fig.8 Manually labeled images in data set

图9 验证模型自动标注的图像Fig.9 Image of automatic annotation of verification model
3.5 小样本条件下结果验证
为了验证上述综合表现较好的YOLOv5-TRBiFPN 模型在少量训练样本情况下的适用性和不同种类植物病斑的适用性,研究将60 张标注后的水稻茎叶病斑图像划分出30 张图像做训练集,30 张图像做验证集。并且将上述YOLOv5-TR-BiFPN 模型训练后的权重文件作为初始训练权重。对从Kaggle 网站下载的60 张水稻茎叶病斑图像进行手动标注,标注后的水稻茎叶病斑图像如图10 所示。为了方便衡量模型的可用性,验证模型的训练初始化参数与表1中参数保持一致。

图10 手动标注的水稻茎叶病斑图像Fig.10 Manually labeled image of rice stem and leaf disease spot
在水稻茎叶病斑图像数据集下,经过200 轮训练之后获得的训练平均准确率mAP 达到了89.3%,准确率Precision 达到84.1%,召回率Recall 到达88.5%,F1 值达到86%,模型测试结果汇总如表3 所示,整体上该模型表现优秀,表明YOLOv5-TRBiFPN 在小样本条件下可以准确标注病斑图像。由于训练采用了之前水稻数据集训练后的权重文件作为初始权重,所以在训练开始阶段具有了比较优秀的表现,训练曲线在经历一定起伏之后不断上升,最终模型快速达到收敛状态,mAP 训练曲线在200 轮时整体趋于稳定,并最终稳定在89.3%,mAP 曲线如图11 所示。

表3 水稻茎叶病斑数据集下YOLOv5-TR-BiFPN 模型测试结果Table 3 Test Results of YOOv5-TR-BiFPN model under rice stem and leaf disease spot data set
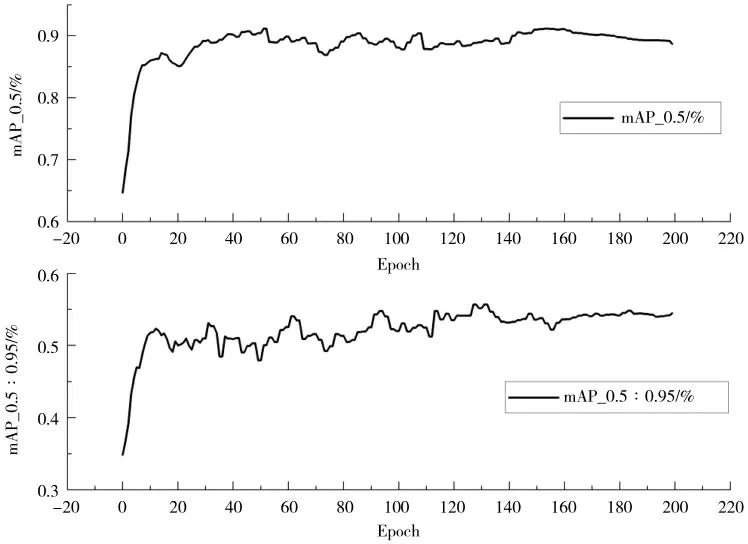
图11 模型在水稻茎叶病斑图像数据集中训练过程的mAP 曲线Fig.11 mAP curve of the training process of the model in rice stem and leaf disease spot image data set
使用上述训练过程中产生的权重文件进行水稻茎叶病斑图像自动标注的验证,验证结果如图12 所示,从图中可以看到模型将水稻茎叶上所有病斑都进行标注,并且预测概率大部分都在0.9 左右,由此可以得知经过改进的YOLOv5-TR-BiFPN 模型能够在少量训练样本的情况下快速收敛,可以准确的定位图像中病斑位置且进行标注,同时对图像中较小的病斑也能够准确标注。

图12 验证模型的标注结果图像Fig.12 Annotation result image of verification model
4 结论
将YOLOv5 模型结构改进为YOLOv5-TRBiFPN 模型结构,把BiFPN 和ViT 融入到YOLOv5-TR-BiFPN 结构中,增强了YOLOv5-TR-BiFPN 模型的感受野和对目标的精确定位能力,从而提高了模型的标注精度,并且采用CIoU 计算Loss 和NMS 提高目标框的准确度。实验结果表明,YOLOv5-TRBiFPN 模型平均准确率达到了73%,相比YOLOv5s提高了3%,能够对水稻茎叶上的小病斑和密集病斑获得良好的标注效果。在少量水稻茎叶病斑图像数据下测试,YOLOv5-TR-BiFPN 模型的mAP_0.5 达到89.3%,且快速收敛,证明YOLOv5-TR-BiFPN 模型可以在少量样本的情况下能够对病斑图像进行快速标注。这为农作物病斑图像自动标注提供了可能,同时为各专业研究领域标注专用图像数据集提供了一种快速标注方法,具有较高的应用价值。
猜你喜欢
青少年科技博览(中学版)(2022年6期)2022-12-27 19:44:27
军事文摘(2021年22期)2021-11-26 00:43:51
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
文苑(2020年6期)2020-06-22 08:41:52
文苑(2019年22期)2019-12-07 05:29:00
农业工程学报(2018年24期)2019-01-14 10:41:30
中国蚕业(2018年4期)2018-12-05 05:45:12
江苏林业科技(2018年4期)2018-09-14 09:31:06
