
多设备多任务场景下基于改进粒子群优化的计算卸载策略
2024-04-01 05:27:28蒋鹏富爽丁晨阳
黑龙江八一农垦大学学报 2024年1期
蒋鹏,富爽,丁晨阳
(黑龙江八一农垦大学信息与电气工程学院,大庆 163319)
随着移动互联网和芯片技术的发展,终端设备及其应用数据不断增多,用户对计算资源的需求也越来越大。针对本地设备计算资源不足的问题,业界引出了移动云计算(Mobile cloud computing,MCC)这一解决方案,移动云计算通过将任务传输到云计算中心,经计算能力充足的远程数据中心计算后,再将计算结果返回到本地设备上,有效地解决了本地设备计算资源缺乏的问题[1]。但近年来,本地设备上新型计算任务不断增加,如虚拟现实、增强现实,以及自动驾驶和在线游戏等[2-3],对计算能力和网络传输时延提出了更高的要求,通常需要强大的计算能力处理,并以极低的时延返回结果[4]。对于移动云计算方案,虽然运行稳定可靠[5],但由于其服务器部署于远程数据中心,网络传输时延高,因此无法处理这类任务[6-7]。在2014 年,针对新型任务,业界提出了移动边缘计算(Mobile edge compute,MEC)这一最新解决方案[8-9],其核心思想是将计算资源部署于网络边缘,以获得更低的网络传输时延[10-11],从而满足新型任务的运行要求。
移动边缘计算作为第五代移动通信技术(5 th ceneration mobile communication technology,5 G)的关键技术[12-13],解决了计算与传输的时延问题,同时降低了本地设备的能量消耗。计算卸载技术是移动边缘计算的关键技术,如何合理卸载任务以及合理进行资源分配,以降低MEC 系统的卸载成本,提升用户的边缘计算体验,是MEC 网络中需要解决的关键问题。为降低MEC 的卸载成本,如能耗和时延,学者们对此进行了深入的研究。余翔等[14]联合优化任务卸载决策和设备传输功率,使用非合作博弈论优化卸载决策,使用二分搜索法优化传输功率,此方法提高了系统的卸载性能,文献的模型建立在多用户单任务场景下,暂未对计算资源进行优化。Lan X 等[15]在多设备单服务器场景下联合优化资源分配、设备传输功率和带宽,使得时延和能耗的加权和最小,利用拉格朗日对偶分解将原问题分解为多个子问题,并逐一解决,还证明时延和能耗之间存在内在的权衡关系,如果放宽时延要求,则本地设备可以得到更低的能量消耗。Liu J 等[16]将卸载和功率优化问题建模,为计算开销最小化的混合整数非线性规划问题,并使用提出的功率控制和卸载子算法求解该问题,仿真结果证明了该方法的有效性,但文献暂未考虑MEC 系统中的计算资源分配问题。Fang F 等[17]通过优化传输功率和任务在本地设备与服务器执行的分配比来最小化延迟,并将该非凸问题转化为等价的拟凸问题,使用二分搜索迭代算法求解,与文献[16]相同,文献假设MEC 服务器的资源是没有限制的,暂未考虑计算资源分配,同时忽略了任务在服务器上的执行时延。罗斌等[18]提出了一种基于粒子群优化算法的计算卸载策略,将计算卸载问题建模为能耗约束下的时延最小化问题,并使用粒子群优化算法对卸载决策变量进行求解,降低了MEC 系统的时延,但该文献仅优化了计算卸载位置,没有考虑任务MEC 计算资源的分配问题。朱思峰等[19]综合考虑任务时延和本地设备的能耗,对计算卸载问题进行建模,并采用改进的粒子群算法来求解,仿真表明其卸载决策结果优于标准粒子群算法以及遗传算法,文献对单个用户的计算卸载位置进行优化,将MEC 服务器资源全部分配至某一任务。在以上研究中,学者们对任务的卸载策略进行了优化,能够达到降低系统时延或能耗的目的,但仍有需要进一步研究考虑的地方。文献[14,16,17,18]通过最小化计算开销,得到了较好的卸载策略,但暂未考虑计算卸载中的计算资源分配问题。文献[14,15,19]降低了计算卸载时延,但缺少对多用户、多任务或多服务器场景的模型建立。在实际的边缘计算场景中,MEC 服务器必定部署于设备较多的地方,以提高其使用率,因此单用户并不符合实际部署场景。此外,由于多种新型任务的出现,本地设备上需要处理多个计算任务,对于大型任务,也可将其拆解为多个子任务,因此单任务不符合本地设备上的任务实际情况。综上所述,对于多用户、多任务、多服务器场景下的任务卸载和资源分配问题,目前的研究较少。如何建立其系统模型,并得到合理的卸载决策和资源分配策略,降低MEC系统的卸载成本,是移动边缘计算领域中亟待解决的问题。
研究对于多设备、多任务场景下的计算卸载问题,主要贡献如下:
(1)结合本地设备的能量信息及充电状态信息,综合考虑能耗和时延卸载成本,通过充电状态与能量信息自适应调整时延能耗权重,结合服务器任务均衡,设置总代价数学表达式,建立多用户、多任务、多服务器场景下的MEC 计算卸载系统模型。
(2)对传统粒子群算法中的惯性因子和学习因子进行了改进,各粒子独立更新因子数值,而不是所有粒子使用相同的因子,在算法迭代过程中按照一定的方法动态更新因子数值,采用改进的粒子群算法对卸载决策和资源分配变量进行求解,最终获得最优的卸载决策和资源分配方案。
1 系统模型
系统模型如图1 所示。在一个多个用户和多个MEC 服务器的MEC 网络中,有多个用户,即本地设备有任务计算需求,多个MEC 服务器可为用户提供计算服务。本地设备同时有多个计算任务需要计算,任务可在本地设备执行或卸载到MEC 服务器进行计算。本地设备通过无线的方式连接到基站,MEC 服务器部署于基站处,本地设备与基站通过无线直连,此种部署方式可使得任务数据传输到服务器的跳数最少,有利于减少通信延时。

图1 多用户多服务器场景下的系统模型Fig.1 System model in multi-user and multi-server scenarios
假设场景模型中包含N 个本地设备,本地设备序号n∈{1,2,…,N},M 个MEC 服务器,MEC 服务器序号m∈{1,2,…,M}。在一个决策周期内,每个本地设备产生一个或多个需要计算的任务。设本地设备n 共产生Kn个任务需要计算,任务数Kn∈{1,2,…,K},K 为产生任务最多的本地设备产生的任务数。设第n 个设备的第i 个任务为K},其属性可表示为一个二元组其中代表该任务的数据量代表该任务的计算量。每一任务可以分配到某一MEC 服务器或在本地进行计算,则每个任务共M+1 种分配选择,所有任务的分配选择构成卸载决策向量表示着第n 个设备上第i 个任务是否卸载到MEC 服务器表示任务卸载到MEC 服务器m 执行=0,表示任务没有卸载到MEC 服务器m,此时任务可能在本地设备上执行,也可能卸载到了其他MEC 服务器。若任务分配到MEC 服务器,则需要为任务分配CPU 计算资源。各MEC 服务器为各任务分配的CPU 资源数量,构成资源分配向量为表示MEC 服务器m 为第n 个设备上第i 个任务所分配的CPU 资源大小,单位为GHz。表1 详细列出了参数符号含义。

表1 参数符号及意义Table 1 Parameter symbols and meanings
1.1 本地计算模型
当某一任务在本地执行时,任务的本地计算时延等于任务本地执行时间,任务的计算能耗为任务本地执行时所消耗的能量。
1.1.1 本地计算时延
1.1.2 本地计算能耗
本地设备的能耗主要为任务计算期间设备自身的CPU 能量消耗,采用经典能耗计算模型来计算CPU 能耗,即E=εf3t[20],其中ε 为与本地设备芯片架构有关的能耗因子,则任务在本地执行的本地计算能耗为:
1.2 边缘计算模型
当任务卸载到MEC 服务器执行时,任务的计算总时延分为任务传输时延、MEC 服务器执行时延和结果传输时延。由于结果数据往往不大,其传输时延远远小于上载任务传输时延和MEC 服务器执行时延,因此忽略结果传输时延[21-22]。任务的边缘计算能耗为任务传输时所消耗的能量。
1.2.1 边缘计算时延
其中,W 为带宽大小,σ2为信道噪声功率。
1.2.2 边缘计算能耗
当任务数据卸载到服务器上计算时,能耗主要包括本地设备的上传能耗和服务器计算能耗。由于服务器是电缆供电,不考虑服务器能耗,只考虑大多数采用电池供电的用户端能耗,则任务的边缘计算能耗为:
1.3 卸载问题模型
1.3.1 性能模型
其中,λn为设备n 的时延权重因子,1-λn为设备n 的能耗权重因子,λn∈{0,1}。λn一般为固定参数,可表示系统对时延和能耗的敏感程度,若对时延敏感,则λn较大,反之较小。
1.3.2 结合充电状态的权重自适应
对于反映时延和能耗的权重因子λn,与能量的敏感度和本地设备的剩余电量有关[24]。当本地设备剩余电量较低时,用户更希望降低处理任务的能耗,而放宽时延要求,对能量更敏感,则λn较小。当剩余电量较高时,用户希望处理任务的时延降低,而放宽能耗要求,以达到最好的用户体验,此时λn较大。因此,λn与设备的剩余电量比 成正比。设用户本地设备n 的当前电量为Bn,电池能容纳的总电量为,则本地设备当前的剩余电量比为,令:
其中,φ 为比例系数,用于调整λn与设备的剩余电量比 的比例偏好。
此外,设备的充电状态也会影响时延和能耗的权重。若本地设备处于充电状态,则不太注重设备的能耗,此时时延权重因子λn增大;若本地设备未处于充电状态,则不做任何处理。假设本地设备n 的充电状态定义为,若=1 时,设备处于充电状态,反之设备处于未充电状态。结合之前的剩余电量比,令:
1.3.3 问题描述
综上,问题可描述为在时延能耗权重自适应的情况下,如何联合优化卸载决策和资源分配,使系统总代价最低,问题可表示如下。
如果MEC 服务器m 性能较好,大量用户的任务都卸载到MEC 服务器m,会造成服务器m 的负载过高,因此需要考虑任务分配至各服务器的公平性问题,以让其他服务器来均衡负载。对于每一台MEC服务器m,令分配到服务器上的总计算量与其计算能力相匹配,将分配到服务器的任务计算量占所有任务总计算量的比值,与服务器m 的计算能力占所有服务器计算能力的比值之差定义为公平度,公平度应尽可能小。定义blance(A)为公平修正函数,表示卸载策略与公平度的关系,如式(16)所示:
由此,用公平修正函数来修正系统总代价,问题P1 更新为:
2 改进的PSO 算法优化求解
问题P2 是一个混合整数非线性规划问题,由于卸载策略变量和资源分配变量耦合,是一个NP 难问题,无法用传统的凸优化理论解决。对于此类问题,智能群体算法能够通过启发式搜索解空间得到问题的较优解[25]。采用改进的粒子群算法(Particle swarm optimization,PSO)来解决以上问题。PSO 算法向大自然中鸟群捕食行为学习,将鸟群抽象为粒子群,将食物源表征为要寻找的最优解,在一个空间范围内,粒子间共享信息,每一个粒子根据自我认知和社会经验搜索解空间,得到最优解。
2.1 粒子编码
设粒子的个数为L,粒子序号l∈{1,2,3,…,L},本地设备个数为N,本地设备n 所产生的任务个数为Kn,n∈{1,2,…,N},用矩阵A=[an,i]N×K和F=[fn,i]N×K表示粒子的运动位置,其中矩阵A 描述任务卸载决策,矩阵F 描述任务的资源分配情况。矩阵A 的元素值an,i表示任务的卸载决策,an,i∈{0,1,2,…,M},当an,i=m 时,代表本地设备n 的第i 个任务分配的MEC服务器编号为m,当an,i=0 时,代表将任务分配到本地设备。矩阵F 的元素值表示资源分配数量,矩阵F的元素值fn,i代表MEC 服务器给第i 个任务分配的计算资源量,单位为GHz。考虑到每个本地设备产生的任务数不一定相同,将设备最大任务数K 作为矩阵A 和F 的列数,若Kn<K,令an,i=-1,fn,i=-1,其中Kn<i≤K,表示此处并无相关任务。
在卸载决策矩阵A 中,粒子采用整数编码,在资源分配矩阵F 中,采用实数编码。如图2 所示,若A矩阵中an,i=[0 3 3 1],i=1,2,3,4,即表示第n 个设备上第1~4 个任务的执行位置,“0”代表此任务在本地设备执行,“3 3 1”分别代表第2~4 个任务在第3、3、1 号MEC 服务器上执行。
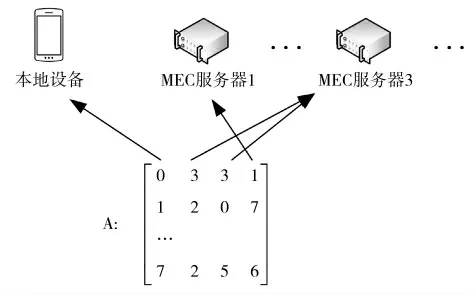
图2 编码矩阵示意图Fig.2 Schematic diagram of coding matrix
用矩阵V1=[v1,n,i]N×K和V2=[v2,n,i]N×K分别表示粒子的卸载决策和资源分配运动趋向。矩阵V1的值v1,n,i表示为任务分配的MEC 服务器编号的运动趋向,矩阵V2的值v2,n,i代表服务器给任务分配的计算资源量的运动趋向。
2.2 适应度函数
将问题P2 的目标函数作为算法的适应度函数,表示系统总代价Y 的大小。
2.3 算法详情
在粒子群算法中,粒子的位置代表一个可行解。在粒子搜索解的过程中,通过每次迭代计算各粒子运动的下一位置,直到收敛到最优位置。粒子位置的更新由上次位置和粒子的速度决定,算法核心是粒子位置和速度的迭代更新方法。速度更新受惯性速度、自身认知经验和社会经验三大方面影响,每一方面对应一个因子,即惯性因子w 和学习因子c1、c2。改进的粒子群算法通过在迭代过程中动态改变各因子的值,达到优化粒子群算法的目的。
若粒子第t+1 次迭代的速度为Vt+1,其更新公式为:
其中,t 表示更新迭代次数,rand()为随机函数,Pbest为粒子当前搜索到的最优解,Gbest为全体粒子当前搜索到的最优解。为保证算法的前期全局收敛能力和后期局部收敛能力,应在算法迭代过程中减小惯性因子w 的数值。令惯性因子w 动态更新,其更新公式为:
其中,t 和tmax分别为当前迭代次数和最大迭代次数,L 为粒子个数,α,β 均为系数,可以根据w 的最优初值来调整。更新公式能够实现在粒子运动前期惯性因子w 较大,使算法具有较强的全局收敛能力,而随着运动中后期迭代次数的增加,w 非线性减小,使得算法具有较强的局部收敛能力。同时,将粒子数量L 作为影响w 的因素,当粒子数量较大时,适当减小w 的值,以防止粒子路径重复,当粒子数量较小时,适当增大w 的值,增加全局收敛能力,防止粒子路径长度不够,导致算法局部收敛。
学习因子c1、c2分别描述自身认知经验和社会经验对粒子速度的影响程度,动态更新c1、c2,根据每次迭代中粒子适应度值的比较,动态减小或增加粒子下一次迭代中c1、c2的值。其更新公式分别为:
其中,Yt、Ypbest和Ygbest分别为粒子第t 次更新时的适应值、粒子当前最优解的适应值和全局最优解对应的适应值,t 表示更新次数,η,θ 均为系数,可以调整增量比例。公式21 表示,当粒子第t 次更新时的适应值比上一次的个体最优解的适应值小时,适当增加粒子第t+1 次更新时的c1,即反之适当减小此操作表示优良粒子会增加粒子自身经验影响力,其他粒子则依赖粒子群的社会经验。公式22 表示当粒子第t 次更新时,若个体最优解的适应值小于全局最优解对应的适应值,适当减小粒子l 的第t+1次更新时的c2,即,反之增加此操作表示优良粒子会减小社会经验对粒子下一次速度的影响程度,信任自身认知经验,而其他粒子的社会经验影响程度也会增加,使得粒子靠向全局最优解。为了防止粒子过度自信或者过度依赖,设置c1和c2的变化范围,即
粒子的位置更新公式为:
为了避免公式计算得到的粒子速度过大或过小,对于V1,将粒子最小速度限制为,最大速度限制为;对于V2,将粒子最小速度限制为最大速度限制为。而在根据速度公式计算粒子下一次的位置时,可能会超过位置边界,其数值不一定合理,为避免越界现象的发生,对于A,将粒子的最小位置限制为Amin,将粒子的最大位置限制为Amax;对于F,将粒子的最小位置限制为Fmin,粒子最大位置限制为Fmax。
用改进PSO 算法求解卸载策略与资源分配问题,算法流程图如图3 所示。

图3 粒子群算法流程图Fig.3 Flow chart of particle swarm optimization
算法具体流程如下:
(1)初始化,在解空间内随机产生L 个粒子的粒子群,包含位置矩阵A、F 和速度矩阵V1、V2。
(2)按照公式14 计算每个粒子的适应值。
(3)更新个体历史最优位置Pbest和全局最优粒子位置Gbest。
(4)更新粒子群位置矩阵A 和F,对卸载决策矩阵A 中越界的元素值,使其位于Amin和Amax之间,使F 中越界的元素值位于Fmin和Fmax之间。
(7)若两次迭代的适应度差异小于定值,或迭代次数r 达到设定值,算法结束,并输出全局最优粒子位置Gbest,否则返回到第2 步继续迭代。
3 仿真与结果分析
采用Matlab 软件对改进的PSO 算法进行仿真分析,试验采用蒙特卡洛方法,结果由1 000 次仿真求平均得到。设场景中有N=30 个本地设备,M=11 个MEC 服务器,其他参数设置如表2 所示。

表2 仿真参数设置Table 2 Simulation parameter settin
对以下4 种算法进行比较和分析:
(1)方法一,改进的PSO 算法。
(2)方法二,遗传算法:经典的遗传算法采用精英策略,以防种群退化,设置交叉概率为0.80,变异概率为0.10。遗传算法将可行解视为带有遗传信息的染色体,通过对染色体进行选择、交叉和变异操作,不断迭代搜索最优解。首先,根据公式14 计算各个染色体的适应度值,选适应度值最小的染色体为精英染色体,该染色体直接进入到下一代染色体中,以防止种群退化。然后对剩下的染色体通过轮盘赌法进行选择操作,并随机选择一对染色体以指定概率进行单点交叉。最后对染色体进行变异操作,以一定概率随机选择部分染色体,并在取值范围内随机设置其数值。选择、交叉和变异均完成后,计算种群的适应度值,开始下一次遗传迭代,直到两次迭代的适应度差异小于定值,或迭代次数r 达到设定值。
(3)方法三,全部本地计算:任务全部在本地设备计算,即A 中的所有元素值均设置为0。
3.1 不同本地设备数下的总代价
图4 为不同本地设备数下的总代价对比,可以看出,随着本地设备数量的增加,总代价随之上升。其中本地计算的总代价最高,在设备数量为30 时达到75.34,而本方法总代价仅为24.92。与本文方法相比,本地计算的总代价高出202%,因为所有任务均在本地执行,而本地设备计算能力有限,会产生较高时延,导致总代价最高,因此本地计算不适合用来处理新型任务,这也是移动边缘计算存在的意义所在,移动边缘计算将部分任务卸载到距离较近的服务器上进行处理,以降低系统代价,提升本地用户的体验。随机算法对任务执行位置进行随机决策,任务是否卸载以及卸载到哪里均随机决定,其处理过程具有盲目性,无法取得最小总代价,但随机卸载算法也会将部分任务卸载到服务器,因此仍会优于本地计算方法,在设备数量为30 时,随机卸载算法相对于本地计算减小了47%总代价。遗传算法通过对染色体进行选择、交叉和变异等操作,能得到较好的解,仅次于本文方法。本文方法取得的总代价最低,优于其他三种算法,这是因为粒子群在迭代求解过程中,通过适应度函数的反馈,能不断通过自身经验和社会经验向最优解靠近,最终取得较低的总代价。

图4 不同本地设备数下的总代价对比Fig.4 Comparison of total cost under different number of local devices
3.2 不同任务计算量下的总代价
图5 为不同每任务计算量下的总代价对比,可以看出,随着任务计算量的不断增加,4 种方法的总代价都随之增高,这是因为随着任务计算量增加,无论任务在何处执行,任务的处理时延和能耗都会增加,因此总代价增加。由于本地计算将任务全部安排到本地设备上执行,而本地设备的处理能力有限,因此总代价是最高的。随机卸载方法能够卸载一部分任务到MEC 服务器上,因此优于本地计算,但由于随机卸载方法不依靠任何迭代和经验,无法最小化总代价,也无法得到较优解,在计算量为1.1 GHz 时,随机卸载总代价为97.9,本文方法总代价为62.17,随机卸载总代价高出57%,因此随机卸载算法无法得到合适的可行卸载方案。本文方法总代价增长趋势和其他方法相同,但在4 种方法中总代价是最低的,优于其他算法,这是因为随着任务计算量增加,粒子群算法通过迭代搜索并共享社会经验,得到了任务的最优执行位置与资源分配方案,较多的计算任务都被分配到了MEC 服务器,降低了任务的总代价。
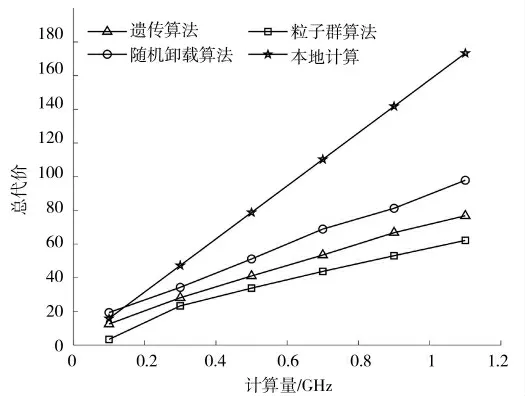
图5 不同每任务计算量下的总代价对比Fig.5 Comparison of total cost under different computations per task
3.3 不同任务数据量下的总代价
图6 为不同每任务数据量下的总代价对比,可以看出,除本地计算外,其他算法的任务总代价均随着任务数据量的增加而上升。这是因为除本地计算外,其他算法均会将部分任务分配到服务器进行执行,随着任务数据量的增加,任务的传输时延会增加,执行时延不变,从而影响到总时延,而本地设备在发送这些数据时,能量消耗也随即增加,因此总代价增加。由图6 还可以看出,在4 种方法中,改进的粒子群算法取得的总代价最低,本地计算的总代价较高,且不随任务数据量的增加而变化,这是由于本地计算不需要传输卸载数据,其代价只与任务计算量有关系,因此数据量改变不会导致总代价的改变。从图6 的总体趋势还可以看出,较计算量而言,数据量对总代价的影响较小,总体走势平缓,斜率较小,这是因为数据量的变化只会在任务上传阶段增加上传时延,对时延和能耗产生的影响较小,最终对总代价产生较小影响。

图6 不同每任务数据量下的总代价对比Fig.6 Comparison of total costs under different data volumes per task
3.4 不同带宽大小下的总代价
图7 为不同带宽大小下的总代价对比。图7 中,除本地计算外,其他3 种算法的总代价都随着带宽的增加而降低,这是由于任务在进行卸载时,会首先将任务上传到服务器,所以带宽较大时会获得较小的传输时延,从而减少任务的时延成本。本地计算由于不进行任务上传操作,任务直接在本地进行处理,没有使用带宽,因此总代价不因为带宽的改变而变化,带宽增大时对总代价不会产生影响,在图7 中表现为一条水平直线。由图7 还可以看出,总代价仍然是最低的,这是因为对传统粒子群算法的惯性权重参数和学习因子进行了优化,使寻优能力得到提升。

图7 不同带宽大小下的总代价对比Fig.7 Comparison of total cost under different bandwidth sizes
4 结论
研究建立了移动边缘计算中多用户、多服务器的计算卸载模型,将时延和能耗的加权和定义为任务执行代价,同时考虑了服务器任务的分配均衡问题。通过联合优化卸载策略和资源分配变量,使得MEC 系统的总代价最低。为解决此问题,使用粒子群算法进行优化,并改进了传统粒子群算法的惯性权重和学习因子,最终得到较优的卸载决策和资源分配结果。仿真结果表明,相比于其他比较算法,能有效降低系统总代价,获得较优的计算卸载策略。但当前研究暂未考虑异构计算资源的分配问题,以及设备移动性问题,这将是下一步的研究方向。
猜你喜欢
英语文摘(2020年10期)2020-11-26 08:12:20
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年7期)2018-12-09 08:57:56
测控技术(2018年6期)2018-11-25 09:50:10
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
中学生(2015年12期)2015-03-01 03:43:53
计算机工程(2014年6期)2014-02-28 01:25:32
