
基于维度融合注意力的行人重识别
2024-03-21 01:49陈海明张琳钰刘国庆
计算机工程与设计 2024年3期
陈海明,王 进+,张琳钰,万 杰,刘国庆
(1.南通大学 信息科学技术学院,江苏 南通 226000;2.中天智能装备有限公司 信息部,江苏 南通 226010)
0 引 言
在理想状态下,行人重识别任务已经实现了较高的识别率。然而,由于现实中摄像头安装的位置不同,目标行人被不同摄像头所捕获的图像存在背景、姿态、视角和遮挡的差异,这往往会造成同一个行人的不同图像之间的差异较大,因此,如何提取判别性强且鲁棒性好的高质量行人特征仍然具有挑战性[1-5]。
针对上述问题,前人提出了一些解决方法,这些方法大多可分为3类:利用全局特征进行行人重识别、利用局部特征进行行人重识别和使用注意力机制提取行人标志性特征。利用全局特征进行行人重识别是将整张行人图像提取成一个特征向量,然后对提取到的特征向量进行相似性度量[6-8]。利用局部特征进行行人重识别是将整张行人图像分割为几个部分的集合,针对各个部分进行相似性度量[9,10]。近来,许多模型借助注意力机制来提取具有辨别性的行人特征[11]。相较于无注意力模型,有注意模型通过增强有效行人特征和抑制无关行人特征的方法取得了较为理想的效果。
上述方法中,无论是有注意模型还是无注意模型,都将特征的空间域和通道域独立处理,而忽略了空它们之间的依赖关系。因此,本文提出了一种基于维度融合注意力的表征学习网络(dimension fusion network,DFNET)。其贡献如下:
(1)提出了维度融合注意力机制,使用维度的变换和滑动窗口的方法融合通道维度和空间维度,采用大感受野学习融合后的维度的关系以达到学习通道域和空间之间联系的目的。
(2)在网络的结尾引入ECA[12](efficient channel attention)注意力,使网络能够很好地适应行人不对齐等极端场景。
(3)使用交叉熵损失、加权正则化的三元组损失和中心损失联合优化网络参数,缓解类内差异。
1 相关工作
1.1 行人重识别
受益于深度学习的发展,近年来,行人重识别方向取得了长足的发展。Chen等[13]在三元组损失的基础上提出四联体损失,弥补了三元组损失存在的缺点;Luo[14]通过在以Resnet50为基线的模型中加入了一些小技巧,极大提升了行人重识别的准确率;Sun等[15]提出将行人特征水平切分为6块,针对每块行人局部零件使用身份损失训练网络,证明了人体局部零件对识别精度的有效性;Luo等[16]针对行人局部零件不对齐的问题,提出了AlignedReID模型,使用最短路径的方法动态齐局部特征,进一步提升了行人重识别的精度。上述方法认为行人图像中的所有部分的重要性是相同的,而事实并非如此,为关注图像中值得被关注的部位,基于注意力的行人重识别便应运而生。
1.2 注意力机制
注意力机制通过模仿人类视觉感知,具有抑制不相关特征和关注相关特征的作用,这种方式有助于精炼行人特征。Hu等[18]提出了SENet,这是第一个成功实现的轻量级通道注意力机制,能够很好改善网络性能;Woo等[19]提出了CBAM注意力机制,通过为通道注意力添加最大池化特征以及添加的空间注意力来丰富注意力图,与SENet相比,这种空间注意力和通道注意力的结合在性能上有了显著的提高;Wang等[20]提出非局部注意力机制,该注意力机制能够通过少的参数,少的层数,捕获远距离的依赖关系,避免了使用小的感受野而丢失全局信息的缺点;受SENet启发,Wang等[12]提出了ECA注意力机制,该注意力机制验证了降维会对通道注意力造成负面影响,通过使用自适应的一维卷积核代替SENet中的全连接层,在降低了网络计算复杂度的同时提高了模型效果。
1.3 基于注意力模型的行人重识别
Chen等[21]提出了混合高阶注意力网络,增强注意知识的辨别力和丰富性,然而该方法使用小卷积核的卷积运算来学习注意力而忽略了全局范围的特征;AANet[22]结合了全局信息、局部信息、属性信息和注意力信息进行行人重识别,取得了较好的效果;Gong等[23]提出LAG-Net,将局部特征与注意力机制结合,针对每部分局部特征学习具有辨别性的行人表示;Ye等[1]提出了AGW模型,在以BagTricks[14]为基准的基础上引入了非局部注意力机制、加权正则化三元组损失和广义平均池化,很好地解决了小卷积核无法看清全局情况的问题。而非局部注意力为像素级注意力,所提取的特征会因背景,遮挡等问题产生噪声影响,且该模型未考虑特征的位置相关性和通道注意力;Zhang等[24]设计了关系感知的全局注意力模块(relation-aware global attention),该模块可同时应用在通道和空间层面,在关注全局范围的基础上对于每一个特征位置,能推断与其它位置的关系,进而确定该特征位置的重要程度。
2 本文方案
2.1 网络结构
本文在BagTricks基线的基础上设计了维度融合注意力网络DFNET,网络结构如图1所示。首先,在Resnet50的每一个瓶颈块(bottleneck)的第二个批归一化处理后引入维度融合注意模块(dimension fusion attention)以充分学习通道和空间之间的关系。其次,在网络最后的池化层后引入ECA注意力模块,用以充分挖掘DFA模块的价值,同时,在网络的最后使用ECA注意力,能够避免因遮挡,行人不对齐等因素造成的不利影响,更直接提取具有辨别性的行人特征。最后,关于损失函数,采用率行人重识别最常用的3大损失函数来共同训练网络参数。

图1 DFNET网络结构
2.2 维度融合注意模块(DFA)
受益于Triplet Attention[25],本文提出了一种轻量级维度融合注意力。该模块分为3个阶段,分别为池化准备阶段、维度融合交互阶段和特征注意阶段,3个阶段中上一个阶段为下一个阶段做准备。其结构如图2所示。

图2 维度融合模块
图2第一部分为池化准备阶段,该阶段的任务是通过池化和旋转操作将输入的特征处理成方便通道和空间维度融合的形状。具体来说,给定一个三维输入张量X∈PC×H×W,其中C、H、W分别表示输入张量的通道数、高、宽,分别对空间域的H和W维度做池化操作,得到XW∈PC×4×W和XH∈PC×H×4。接着对两个张量做旋转和拼接操作得到池化张量Xr∈P4×C×(H+W)。准备阶段的计算过程如式(1)所示
Xr=Cat(Per(PoolH(X)),Per(PoolW(X)))
(1)
式中:PoolH(·)表示对H维度做池化操作,PoolW(·)表示对W维度做池化操作,Cat(·)表示张量拼接操作,Per(·)表示张量旋转操作。
与传统池化操作不同,此处的池化包括平均池化(AvgPooling)、最大池化(MaxPooling)、直接取平均(Mean)和直接取最大值(Max)。在图2中直接用Avg&&Max表示。
图2第二部分为特征融合交互模块,该部分的主要任务是学习通道空间交互特征图。对于上个阶段的输出Xr∈P4×C×(H+W),使用Unflod(·)操作融合通道维度,融合后的特征由三维转变为二维,Unflod(·)为卷而不积的操作,即使用滑动窗口的方式融合空间与通道维度。卷积核不当作网络参数。考虑到融合后的特征维度较高,故采用大小为49的超大一维卷积核学习通道维度和空间维度之间的关系,最后使用Flod(·)操作将特征还原为三维张量Xf∈P1×C×(H+W)。融合交互的计算过程如式(2)所示
Xf=Flod(Conv49(Unflod(Xr)))
(2)
式中:Unflod(·)表示维度融合操作,Conv49(·)表示大小为49的一维卷积核,Flod(·)为Unflod(·)的逆操作。
图2第三部分为特征注意阶段,该阶段的主要任务是将上各阶段的特征图转换为注意图,与常规注意力机制相同,本方法使用Sigmoid函数作为激活函数来激活有效特征;再使用张量切片和旋转操作得到特征注意图ACH∈PC×H×1和ACW∈PC×1×W,受益于广播机制,其结果如式(3)所示
OutputDFA=X·(ACH+ACW)
(3)
式中:OutputDFA为本模块最后的输出,ACH和ACW分别为切分后的注意图。
2.3 ECA模块(efficient channel attention)
如图3所示为卷积核大小为5的ECA注意力机制,此处输入特征已经过池化层,所以不需再做池化处理,其余操作均与标准ECA相同,此处不再赘述。ECA计算流程如式(4)所示

图3 efficient channel attention
X5=X·Unsqueeze(σ(Conv5(Squeeze(X))))
(4)
X为输入特征;Squeeze(·)为挤压操作,将三维特征挤压为二维;Conv5(·)为大小为5的卷积核;σ为激活函数;Unsqueeze(·)为Squeeze(·)的逆操作,将二维特征展开为三维。
为更好学习最后的行人特征,本文在ECA基础上融合了金字塔卷积的思想,即加入了大小分别为1、3、5、7的卷积核共同学习行人特征。该模块最后的输出如式(5)所示
(5)
式中:X1、X2、X3、X4分别为使用大小为1、3、5、7的卷积核学习到的注意特征。
在网络的结尾处引入ECA注意力的好处有3点:能更直接体现注意力机制的优势,学习到的特征具有更强的辨别性;经过池化层的特征不再有特征不对齐和遮挡等不利因素的影响,此时添加通道注意力效果更佳;ECA注意力具于跨通道交互的优势,与DFA注意力相呼应。
2.4 损失函数
为了更好地学习本文模型的参数,采用交叉熵损失,加权正则化三元组损失和中心损失共同限制网络参数。这也是行人重识别领域常用的3种损失函数。交叉熵损失表示如式(6)所示
(6)
式中:yi,k代表第i张图像的身份是否为k,N表示数据集中行人总类别数,pi,k表示第i张图像的身份为k的概率。为了克服模型过拟合的问题,本文采用了带平滑标签的交叉熵损失,增强模型的泛化能力。
加权正则化三元组损失也是行人重识别常用损失之一,它继承了三元组损失优化正负样本之间的距离的优点,且避免了引入范围参数,其计算公式见式(7)


(7)

为使类内特征更加紧凑,本文引进了中心损失,中心损失在每个行人类别找到一个中心特征点,训练时,通过中心特征点拉进同类距离,以达到缩小类内距离的作用,其计算公式如式(8)所示
(8)
式中:fi为第i个样本的特征,yi表示第i个样本的标签,cyi表示第yi个类别对应的高维特征中心。B表示批次大小。
综上所述,本文最终损失函数如式(9)所示
L=Lcls+Lwrt+Lcenter
(9)
3 实 验
3.1 数据集介绍
为验证所提出模型的先进性,本文在Market1501、DukeMTMC-reID和CUHK03这3大公开的主流数据集上进行了实验。
Market1501数据集是2015年采集于清华大学,数据集由6个摄像头采集,包括1501个行人所组成的共32 668张图片,其中训练集有751个行人12 936张图片,测试集有750个行人19 732张图片,包括3368张查询图片和16 364张待查询图片。
DukeMTMC-reID数据集于2017年在杜克大学采集,是DukeMTMC的一个子集,数据集由8个不同的摄像头采集,其中共有1404个行人,且每个行人被两个及以上的摄像头拍摄,训练集由702个行人共16 522张图像所组成,测试集由702个行人共19 889张图像所组成。
CUHK03数据集在2014年提出,数据集由5对共10个不同的摄像头采集,每个行人被两个不同摄像机拍摄,其中测试集由767个行人共6880张图片所组成,测试集由700个行人共6284张图片所组成。该数据及包括供含有人工标注(CUHK03_Detected)检测器检测(CUHK03_Labled) 两种检测框的图像,本文在这两种图像上都做了比较。
3.2 实验设置与评价指标
本文采用ResNet50作为网络的基本骨架,网络最后一个瓶颈块的步幅设为1。在训练过程中,对行人图像,使用了随机裁剪、水平翻转和擦除3种数据增强方法,三元组损失的边缘和标签平滑正则化率分别为0.3和0.1。图像的输入大小为384×192,学习率采用预热方法,在前10个epoch由4×10-6均匀的增加到4×10-4,以后每40个epoch的学习率进行系数为0.1的指数衰减,总epoch次数为160次,使用Adam优化器优化模型参数,L2正则化的权重衰减因子为5×10-4。测试阶段,用原始测试图像和水平翻转过图像的平均特征作为行人特征,使用余弦距离度量方式来计算特征之间的距离。本实验使用pytorch1.8深度学习框架,采用一张NVIDIA 3090进行加速。
本文使用行人重识别最具权威性的累积匹配特征(cumulative match characteristic curve,CMC)曲线中的Rank-1和平均精度均值(mean average precision,mAP)作为评价指标,本文的所有实验结果未使用重排序(Re-Ranking)技巧。
3.3 对比实验
本实验选择了部分较新且主流的行人重识别方法进行比较,以验证本文提出算法的有效性。其分类如下:基于局部特征的方法(PCB、AlignedReID、MHN-6(PCB)等)、基于专用模型的方法(CDNet、OSNet)和基于注意力机制的方法(AGW、RGA-SC、MHN-6(PCB)等)。本文中所有实验均采用单帧查询模式,除了设计专有网络外,其它所有对比实验的骨干网络均为ResNet50。在三大数据集上的实验结果见表1和表2。

表1 Market1501和DukeMTMC-ReID数据集上对比结果

表2 CUHK03数据集上对比结果
基于Market1501数据集的实验对比结果见表1,本文提出的模型在该数据集上的Rank-1和mAP分别为96.2%和90.8%,相较于同样基于注意力的模型RGA-SC和AGW,本文方法在Rank-1上分别提高了0.1%和1.1%,mAP分别提高了2.4%和3.1%,AGW和RGA-SC主要是通过对全局注意力的统筹考虑,AGW只考虑了空间注意力,而网络最后输出特征的维度和通道数是一致的,就行人特征而言,通道注意力的优势更为明显,本文的模型在网络骨架之后嵌入ECA注意力,直接在输出的行人特征上加入通道注意力,且DFA模块也存在通道注意力,故本方案效果较AGW而言更胜一筹;RGA-SC考虑了特征像素点之间的关系,这同样是局限于空间层面,而忽略了空间通道之间的交互,本文在网络骨架中插入DFA模块,很好地弥补了这个缺陷,故本方案较RGA-SC而言更胜一筹。相较于无注意力模型CDNet和SIAMH,本文方法在Rank-1上分别提高了1.1%和0.8%,mAP分别提高了4.8%和2.0%。与现有较为先进的模型在Market1501数据集上的对比结果验证了本方法的有效性。
基于DukeMTMC-ReID数据集的实验对比结果见表1,Rank-1和mAP分别为91.3%和82.5%,两个指标同时达到目前的最好结果,相比于同样基于注意力的模型AGW和LAG-Net,Rank-1分别提高了2.3%和0.9%,mAP分别提高了2.9%和0.9%。相较于无注意力模型CDNet和SIAMH,本文方法在Rank-1上分别提高了2.7%和2.2%,mAP分别提高了5.7%和3.1%。与现有较为先进的模型在DukeMTMC-ReID数据集上的对比结果验证了本方法的有效性。
基于CUHK03数据集的实验对比结果见表2,本文在CUHK03-Detected上Rank-1和mAP分别为84.5%和82.0%,在CUHK03-Labeled上Rank-1和mAP分别为86.7%和85.1%。与现有先进的模型在CUHK03数据集上的对比结果验证了本方法的有效性。
3.4 消融实验
为进一步验证算法的有效性,本文在Market1501和CUHK03-Detected数据集上进行消融实验。
在Market1501上的消融实验见表3,在基线上结合了DFA模块后,Rank-1和mAP分别提升了0.9%和2.5%,再结合ECA模块后Rank-1和mAP提升不明显。在CUHK03-Detected上的消融实验见表4,在基线上DFA模块后,Rank-1和mAP分别提高了6.9%和6.0%,再结合ECA模块后,Rank-1和mAP分别比基线提升了5.5%和4.2%,结合二者,Rank-1和mAP分别比基线提升了15.1%和13.6%。可以注意到,在CUHK03-Detected数据及上,两个注意力的效果不仅仅是相加得到,而是起到了1+1>2的效果,进一步验证DFA和ECA相互配合的有效性。

表3 Market1501上的消融实验
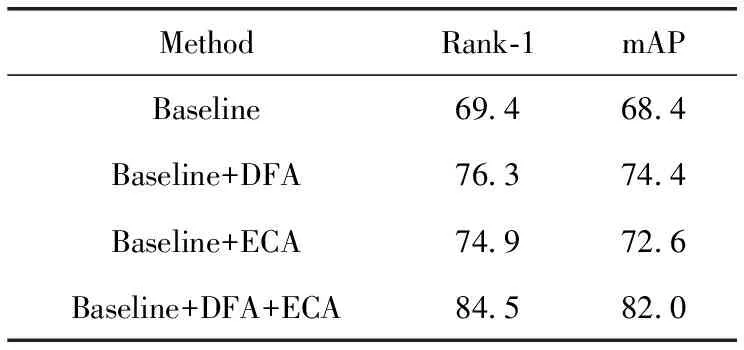
表4 CUHK03-Detected上的消融实验
对比上述两个消融实验的结果,本文提出的模型在CUHK03上的效果提升远高于Market1501,这是因为CUHK03数据集则更具挑战性,更符合现实情况下所截取的行人图像的特点,本文所提模型更能适应现实场景下的行人重识别任务。
本文选用参数量(params)和每秒浮点运算次数(FLOPs)来评价网络大小和网络推理速度。其结果见表4。其中FLOPs的值为输入一张大小为384×192的图像所得。
由表5可知,两个轻量级注意力模块对网络大小和推理速度的影响较小,所需计算成本有限。

表5 网络计算量结果
3.5 可视化结果分析
为在此说明本文方法的先进性,随机选择了Market1501中的3个行人进行识别,并将检索相似率排名前十的图像展示在图4,其中Query为查询图像1~10为检索相似度排名前十的图像。如图所示,本文所选取的3张图像所查询的相似度前十的图像全部正确,且第二个行人的第五张查询图像、第三个行人的第六张查询图像和第七张查询图像行人不对齐,第二个行人的第十张查询图像、第三个行人的第九张查询图像和第十张查询图像明显与查询图像分辨率不同,这表明本文方法能够适应各种极端情况、更贴近真实场景下的行人重识别。

图4 Market1501上的检索结果
4 结束语
为应对复杂环境下的行人重识别,本文提出了基于注意力机制的表征学习网络DFNet。其中,DFA模块能在图像较为规整的情况下帮助网络提取出辨别性较强的行人特征,ECA模块在复杂环境下表现更为优秀,两个模块相辅相成共同提高行人重识别的精度。实验结果表明,本文方法优于现有大部分模型的水平。接下来,会继续研究轻量级网络与注意力机制相结合在行人重识别中的应用,在提高重识别准确率的同时,提高重识别的速度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
小天使·一年级语数英综合(2017年6期)2017-06-07
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
