
基于改进生成对抗网络的时序数据异常检测
2024-03-21 01:58王德文潘晓飞赵红博
计算机工程与设计 2024年3期
王德文,潘晓飞,赵红博
(1.华北电力大学 控制与计算机工程学院,河北 保定 071003;2.复杂能源系统智能计算教育部工程研究中心,河北 保定 071003)
0 引 言
近年来,随着深度神经网络迅速发展,基于深度学习的异常检测算法变得越来越流行,它能够较好地处理复杂的时间相关性并且具有较强的学习能力,因此被用于许多时序数据的异常检测中[1-3]。
生成对抗网络(generative adversarial network,GAN)在图像的异常检测和生成领域被广泛应用[4],并且GAN和对抗训练框架已经能够成功地用于生成复杂和高维分布的真实数据中[5],足以说明它可以用于时序数据的异常检测。使用GAN进行异常检测的方法是使用对抗训练学习正常数据的特征,检测重构效果不佳的异常数据[6]。
然而,由于时序数据具有高度复杂的时间相关性并且通常缺少标签,现有的异常检测模型难以有效提取时序数据的时间信息,缺乏时间关系和特征关系的结合,模型检测的准确性不高;模型在训练过程中不稳定,容易发生训练不稳定[7]等问题;进行异常检测时,若使用人为统一设定的阈值会影响异常检测效果。针对以上问题,本文提出结合BiLSTM与WGAN-GP的时序数据异常检测模型。该模型的生成器和判别器采用BiLSTM来捕捉时序数据复杂的时间相关性。为保证训练过程稳定性,使用Wasserstein距离代替JS散度的衡量方法,并且在判别器损失中增加梯度惩罚项。最后使用重构损失和判别损失的加权平均值来定义异常函数,通过局部自适应阈值判别异常,提高异常检测的准确性。
1 相关工作
时序数据异常检测方法主要包括基于相似度、基于预测、基于重构3大类方法。
基于相似度的方法有:基于距离度量的KNN(K-nearest-neighbors)算法、基于密度度量的LOF(local outlier factor)算法。然而,这些方法无法捕捉时序数据之间的时间相关性,不适用于时序数据中[8]。
基于预测的方法是通过预测未来值,将预测值与预定义的阈值或者观测值相比较来检测异常。基于长短期记忆网络(LSTM)[9]和基于深度卷积神经网络(CNN)[10]的模型被提出用于预测下一个时间戳来发现时序数据中的异常。
基于重构的方法是通过学习一个模型来捕捉时序数据的潜在结构,将重构值与观测值的差异进行比较检测异常。一种基于自动编码器的无监督时序数据的实时异常检测方法被提出[11],然而,该方法较容易发生过拟合问题,降低异常检测的效果,因此本文采用对抗学习的方式进行时序数据的重构。
与传统的方法不同,在缺少标签的情况下,GAN经过训练后的判别器可以判别数据的真假,这使得GAN成为一种有吸引力的无监督异常检测模型。AnoGAN[12]模型是基于无监督GAN的图像数据异常检测方法,该模型使用CNN作为生成器和判别器,将图像映射到潜在空间并重构图像数据,使用重构图像的损失来计算异常分数。Zenati等[13]提出了称为EGBAD的异常检测方法,该模型使用BiGAN[14]网络结构,解决了AnoGAN每次接收新图片需要调整参数的问题。但是,由于CNN不包含处理时序数据的机制,AnoGAN和EGBAD方法并不适用于序列数据。Li等[5]提出了MAD-GAN模型,该模型将LSTM作为生成器和判别器检测异常,通过实验发现LSTM能够有效地捕捉时序数据的时间关系输入到GAN中。BeatGAN[15]模型将自动编码器(AE)和GAN结合检测异常节拍。Bashar等[16]提出了一种TAnoGAN异常检测方法,结合LSTM和AnoGAN来处理时序数据异常问题,可以用在只有少量实例的时候。马标等[17]提出使用多级离散小波变换进行数据预处理,在GAN模型中加入注意力机制并使用多层LSTM提取数据特征。但是上述几种方法忽略了原始GAN在训练的过程中对超参数非常敏感,容易造成训练不稳定的问题[18]。
使用GAN进行异常检测的研究已经有几年的时间了,但它在时序数据异常检测上的应用仍是一个新兴的领域,针对现有的模型仍存在准确率不高、训练不稳定等问题,本文使用能够保留长期历史信息的BiLSTM来捕获时序数据特征,使用Wasserstein距离度量真实数据分布与模型拟合分布之间的距离。
2 时序数据异常检测模型
2.1 问题描述
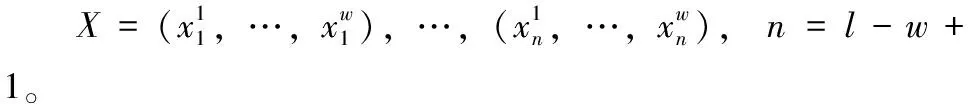
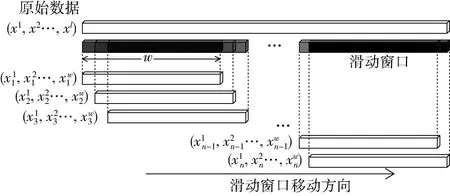
图1 原始数据与滑动窗口的关系
2.2 模型结构
本文提出一种BiLSTM与WGAN-GP结合的时序数据异常检测模型,结构如图2所示。
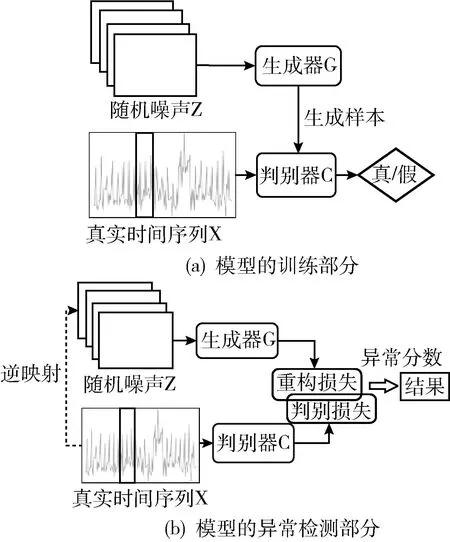
图2 BiLSTM-WGAN-GP模型结构
BiLSTM-WGAN-GP时序数据异常检测模型主要分为模型训练和异常检测两个部分。
网络模型训练部分的主要目的是通过对抗性训练学习真实的数据分布,经过足够多次迭代后训练出能够产生相似(假)时序数据的生成器(Generator,G)和能够区分假时序数据与真时序数据的判别器(Critic,C)。将随机噪声Z输入到G中,G需要学习如何生成相似(假)的样本骗过C。然后将生成的时序数据和真实的时序数据输入到C中,C需要区分出真实样本和假样本。为了处理时序数据,生成器和判别器均使用BiLSTM作为基础网络,BiLSTM的计算过程将在2.3.1节中详细阐述。
异常检测部分是使用训练好的生成器G和判别器C来检测序列中的异常数据。首先将测试样本通过逆映射从潜在空间中找到最合适的随机噪声向量z,然后将最合适的随机噪声向量z输入到G中,G生成的样本与真实样本的距离定义为重构损失;将测试样本输入到判别器C中,输出得到判别损失。最后利用重构损失和判别损失的加权平均值计算出异常分数,采用局部自适应阈值方法找出异常的时序数据。基于BiLSTM-WGAN-GP的时序数据异常检测算法如算法1所示。
算法1:基于BiLSTM-WGAN-GP的时序数据异常检测算法
输入:一个小序列X
输出:异常分数Score
(1)Function Train(X):
for epochs do
从随机噪声Z中取随机噪声向量z
从真实样本分布Pr中取真实数据向量x
Train C//训练判别器C区分真实数据和生成数据,更新参数
Train G//在第二组随机噪声向量上训练生成器G,更新参数
return G,C
(2)Function AD(X,G,C):
foriin 1 to m do
通过逆映射从随机噪声中找到最合适的噪声向量zi
forλin 1 toτdo
生成器生成数据向量G(zi)
计算损失函数L并通过梯度下降更新zi
计算异常分数Score
returnScore
2.3 模型训练
2.3.1 BiLSTM捕获时序数据相关性
在本文所提出的模型中,生成器和判别器均将BiLSTM作为基础网络来捕获时序数据的时间相关性。BiLSTM是以LSTM为基础的优化网络,包含正向层和反向层,其运算如图3所示。
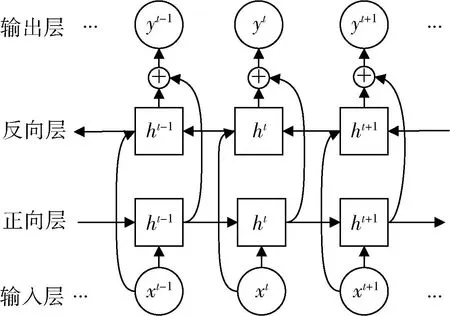
图3 BiLSTM运算
BiLSTM网络结构的优势在于可以让输出单元同时包含过去和未来序列的数据特征,更好地捕捉时序数据的依赖性,能够保留长期的历史信息。其正向层计算过程可以表示为
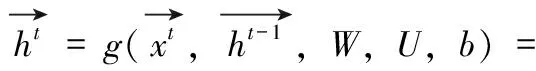
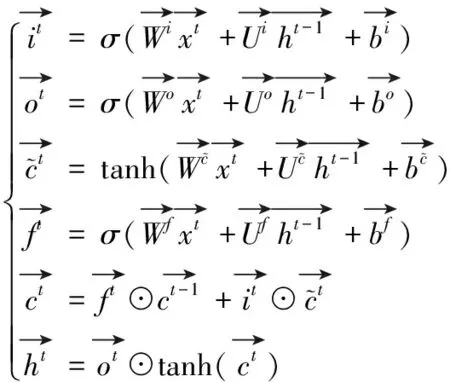
(1)
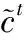
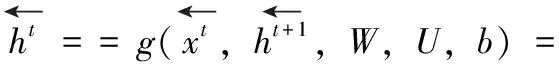
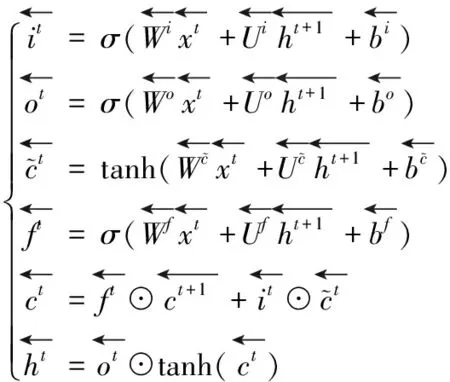
(2)
基于以上计算,则隐藏层输出为
(3)
2.3.2 生成器
生成器的目的是能够生成与真实样本相似的假数据分布来骗过判别器。对于小数据集上的训练,浅层的生成器无法生成足够相似的假数据,因此本文采用中等深度的生成器,使用具有64个隐藏单元的两层BiLSTM、一层全连接层,采用LeakyRELU作为激活函数,生成器结构如图4所示。
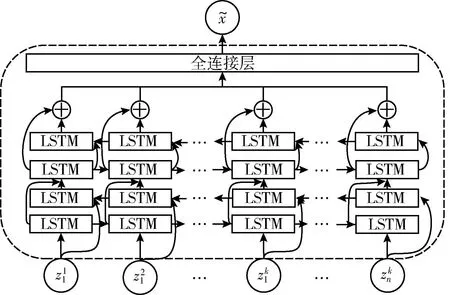
图4 生成器结构
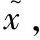
(4)
生成器的损失函数定义为
(5)
式中:pg表示生成样本分布。
2.3.3 判别器
针对数据集较小的情况,若使用较大的判别器容易发生过拟合,因此本文模型的判别器使用一层包含100个隐藏单元的BiLSTM网络。原始的GAN容易发生训练不稳定的问题,它的生成器倾向于生成那些被发现擅长于愚弄判别器的样本,不愿意生成有助于获取时序数据中的其它模式的新样本。为了克服这个限制,保证训练过程的稳定性,本文使用Wasserstein距离代替JS散度,并且在判别器的损失中加入梯度惩罚项限制梯度变化范围。直接计算真实样本分布Pr和生成样本分布Pg的Wasserstein距离比较困难,因此采用以下方式计算
(6)
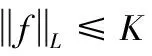
(7)
由于需要拟合Wasserstein距离,去掉了最后一层的Sigmoid函数,采用全连接层来输出各类分布的值。判别器的损失函数定义为
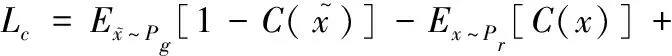
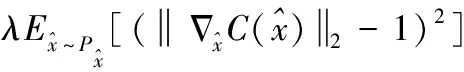
(8)

(9)
δ为0到1之间的一个随机数。
2.4 异常检测过程
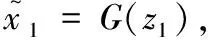
(1)重构损失
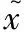
(10)
(2)判别损失
原始GAN是完成真假二分类任务,但本文模型采用了WGAN-GP的思想,判别器输出的是Wasserstein距离,因此本文使用判别器的输出来计算判别损失,定义为
Lc(xn)=f(xn)
(11)
f(·) 表示判别器的输出。
损失函数L被定义为重构损失LR和判别损失LC的加权平均值
L(xn)=(1-η)LR(xn)+ηLC(xn)
(12)
η是由经验决定的平衡因子。
在每次迭代中,损失函数L会估计生成的假序列和真实序列的差异,异常评分函数Score(x)以表示给定时间序列X与正常小序列模型的差异,公式如下
Score(xn)=(1-η)R(xn)+ηC(xn)
(13)
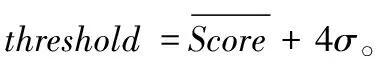
为了减少误报,本文采用Hundman等[9]提出的修剪方法。对于每个异常序列,先获得该异常序列的最大异常分数 {Score1,Score2,…,Scorem},然后按照降序排序,计算下降百分比pi=(Scorei-1-Scorei)/Scorei-1,当第一个Scorei不超过某个阈值θ(默认θ=0.1)时,后续的序列则被重新分类为正常序列。
3 实 验
3.1 实验环境及数据集
本文所有实验均在同一环境及配置下进行,见表1。

表1 实验环境
实验使用numenta anomaly benchmark(NAB)数据集[19],NAB数据集旨在为时间序列异常检测提供数据。该数据集分为7类,除去一类不含任何异常的人工数据集和一类已知异常原因不含手工标签的数据集,本文选取剩下的5类包括多个领域的时序数据集共45个数据文件(除去一个不含任何异常的数据文件),每个文件有1000~22 000个数据实例,每一行包含一个时间戳和一个标量值。这5类数据集分别是AWS、AdEx、Art、Traffic、Tweets。AWS是AmazonCloudwatch服务收集的AWS服务器指标数据集;AdEx是在线广告点击率数据集;Art是包含不同类型异常的人工生成的数据集;Traffic是由明尼苏达州交通部收集的实时交通数据集;Tweets是Twitter上关于大型上市公司报道的数据集。
本文提出的方法是基于无监督的方式来训练模型,也就是说没有标签,NAB提供的标签仅仅用于比较检测的异常来评估模型的性能。
3.2 评估指标
本文采用精确率(Precision)、召回率(Recall)、F1分数3项指标作为评估指标。
精确率Precision值是针对识别为正确的样本,反映的是模型能正确识别出样本类别的程度
(14)
召回率Recall值是针对实际样本,反映的是模型能够正确识别出所有样本类别的程度
(15)
F1分数是调和平均值,能够兼顾精确率和召回率的影响,作为评估模型的主要指标
(16)
3.3 实验结果与分析
3.3.1 模型训练过程分析
本文通过可视化训练过程中生成器和判别器的损失函数的绝对值来反映本文提出模型的性能,原始GAN和BiLSTM-WGAN-GP模型训练过程中的生成器和判别器的损失函数变化对比如图5所示。
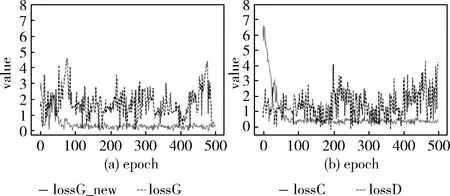
图5 训练损失对比
图5显示了迭代500次模型损失函数变化对比,图中虚线为未使用WGAN-GP的GAN模型损失值变化,实线为本文提出模型的损失值变化,左图为生成器损失函数变化,右图为判别器损失函数变化,纵坐标为损失值。可以看出,未使用WGAN-GP的模型在训练过程中损失值变化浮动较大,损失值未收敛。本文所提出模型在训练的刚开始阶段,判别器能够比较容易地判别出输入数据的真假,生成器和判别器的损失变化较大;当训练次数在50次之后,生成器逐渐学习到部分特征,生成器和判别器的损失函数的绝对值呈现下降的趋势;在训练次数达到75次之后,生成器和判别器的损失函数值变化趋势趋于平缓;在训练次数达到100次之后,生成器和判别器的损失没有较大的波动达到相对稳定且接近0,表示该模型具有了较好的收敛能力,判别器的判别能力在训练过程中不断增强,生成器能够生成相似于真实数据的样本。
3.3.2 滑动窗口大小设置
在BiLSTM-WGAN-GP模型中,使用了滑动窗口将长时间序列划分为较短的时间序列,滑动窗口太短则会无法很好地捕捉时序数据的特征,同时也不宜太长。因此确定出最佳的窗口长度是该研究中一项重要的问题。本文尝试了不同长度的窗口大小来进行实验,经过分析,窗口长度window_length控制在70范围以内即可,以10为间隔进行对比实验,如图6所示。
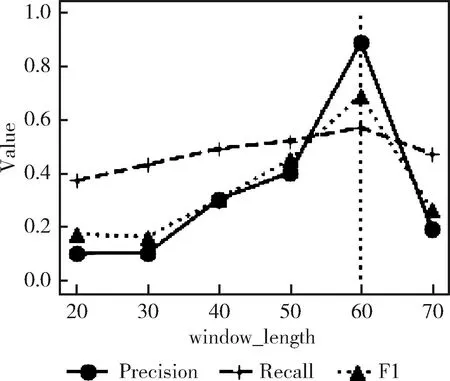
图6 滑动窗口大小对比实验
由图6中所显示的实验结果可以看出,当窗口长度window_length为60时,BiLSTM-WGAN-GP模型的各项评估指标均为最好。
3.3.3 实验结果
为了分析BiLSTM-WGAN-GP模型的时序数据异常检测效果,本文采用LSTM[9]、DeepANT[10]、LSTM-AE[11]、MAD-GAN[3]、TAnoGAN[16]、CNNGAN[12]模型与其进行比较,通过对比几种模型在5类数据集上的综合性指标F1分数来验证本文提出模型的性能。对比结果见表2。
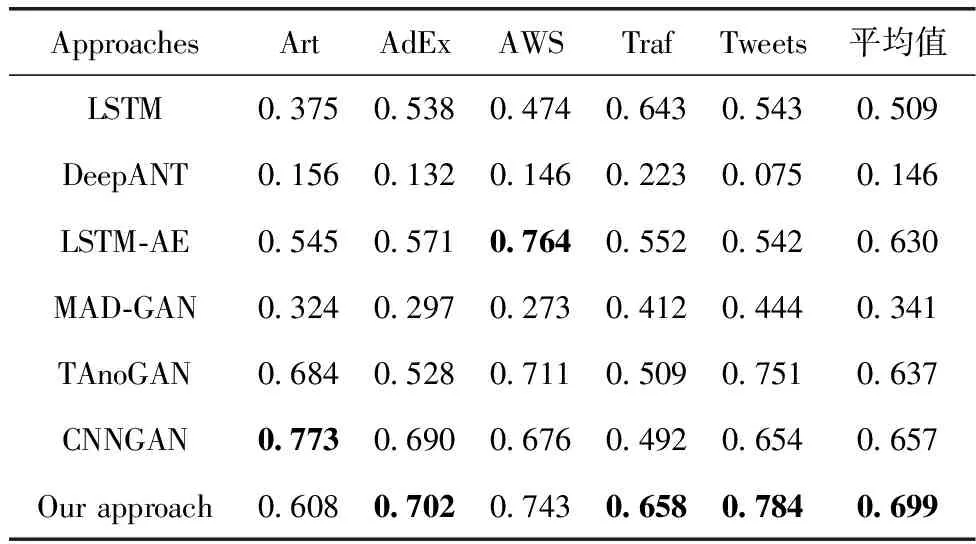
表2 不同时序数据异常检测模型实验结果对比
表2中使用加粗字体显示了各个数据集中最高的结果,BiLSTM-WGAN-GP模型同其它几个模型相比,F1分数的平均值最高。
LSTM、DeepANT是基于预测的方法学习时间序列的历史变化,对接下来的几个时间步长进行预测,使用逐点预测损失定义异常分数。这两种模型在每个数据集上的F1分数均不如本文提出的模型。LSTM对上下文异常并不敏感,检测准确性并不高。DeepANT模型在各个数据集上的检测结果均不佳,使用CNN作为预测器检测异常的效果并不好。
LSTM-AE、MAD-GAN、TAnoGAN、CNNGAN均是基于重构的异常检测方法。LSTM-AE使用LSTM单元捕捉传感器之间的时间依赖性,自动编码器结构用于学习数据集的正常行为。LSTM-AE在AWS数据集上表现最好,但在其它4类数据集上异常检测效果并不如本文提出的模型,且本文所提出模型的F1分数平均值提升了6.9%。MAD-GAN、TAnoGAN具有与BiLSTM-WGAN-GP相似的架构。MAD-GAN是使用LSTM-RNN作为GAN基本架构的多元时序数据异常检测模型,本文模型的异常检测结果明显优于MAD-GAN模型,所使用的BiLSTM能够实现捕捉上一单元和下一单元的时序特征。MAD-GAN在面对数据集较小时,异常检测效果并不好,适用于数据集较大的情况。TAnoGAN同样是适用于较小数据集的异常检测模型,使用LSTM作为生成器和判别器的基础网络,通过表中对比结果来看本文所提出模型的F1分数平均值提升了6.2%,且在5类数据集上的F1分数均比TAnoGAN模型高。TAnoGAN中使用原始GAN,忽略了可能会发生训练不稳定的问题。CNNGAN模型将CNN作为生成器和判别器的基础网络捕获时间依赖性,其结构与AnoGAN[14]相似,该模型在Art数据集上检测效果最好,但在其它数据集上的检测效果均不如本文提出的模型,本文模型的F1分数平均值相比较该模型提升了4.2%,这是由于使用CNN作为生成器并不适用于时序数据中。
为了进一步验证本文所提出模型的性能,本文模型与使用LSTM作为生成器和判别器的GAN(LSTM-GAN)、使用BiLSTM作为生成器和判别器的GAN(BiLSTM-GAN)、使用LSTM作为生成器和判别器的WGAN-GP(LSTM-WGAN-GP)分别进行了实验,实验对比结果如图7所示。
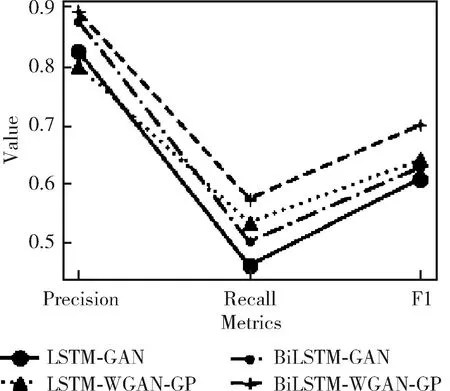
图7 不同模型实验结果对比
从图中可以看出,仅仅加入BiLSTM之后3项指标均有所上升,这是因为BiLSTM能够捕捉过去和未来的数据特征。单独使用WGAN-GP作为基本模型时,可以发现虽然精确率有所下降但是有更高的召回率,综合指标F1分数也比基础模型GAN高,验证了本文使用WGAN-GP模型的有效性。本文所提出的BiLSTM-WGAN-GP模型在3个评估指标上表现均为最好,表明了该模型将BiLSTM与WGAN-GP结合可以提升异常检测效果。
4 结束语
本文提出BiLSTM-WGAN-GP模型用于时序数据异常检测。该模型使用BiLSTM作为生成器和判别器的基本模型,用来捕捉时间依赖性。使用Wasserstein距离代替JS散度的计算方法并且在判别器损失中增加梯度惩罚项,避免训练不稳定等问题;将重构损失与判别损失相结合定义异常函数,使用局部自适应阈值方法找出异常数据。为了验证BiLSTM-WGAN-GP模型有良好的性能,该模型在涉及多个领域的5类数据集上进行了实验,并且与其它方法进行了对比,本文提出的模型有较好的异常检测效果。在接下来的工作中,我们将在模型训练时间方面继续探索,做到在提升模型异常检测效果的同时压缩模型训练的时间。
猜你喜欢
中国农业信息(2023年3期)2023-03-18
摄影世界(2022年1期)2022-01-21
中国农业信息(2021年3期)2021-11-22
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
电子制作(2016年15期)2017-01-15
山东大学法律评论(2016年0期)2016-08-16
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
