
基于改进YOLOv5s的车脸检测算法
2024-03-21 01:48余国豪贾玮迪余鹏飞李海燕李红松
计算机工程与设计 2024年3期
余国豪,贾玮迪,余鹏飞,李海燕,李红松
(云南大学 信息学院,云南 昆明 650500)
0 引 言
传统的灯光检测仪是通过追踪光强来移动支架从而定位前照灯的位置,该过程不仅耗时久,而且不够准确。为了解决此问题,本文基于相机成像并结合深度学习的方法,来定位前照灯的位置,以测量前照灯基准中的高度,同时,还可以利用图像中的车标、车身颜色等信息进一步防止车辆代检情况的发生。
基于深度学习的目标检测算法在车辆检测领域一直是热点研究方向。例如:Xu等[1]提出了基于SSD的车辆检测算法,引入注意力机制和残差连接,将其部署到树莓派上进行使用;Wei等[2]提出了基于PF-Net的车辆检测算法,多个通道共同表达一个局部信息,在相关数据集上取得了较好的效果;GUO等[3]提出了基于YOLOv4的车辆检测算法,引入注意力机制,使用GhostNet作为Backbone,不仅检测精度高,而且检测速度快。由于以上车辆检测算法主要应用于智能交通系统场景,与车检站车辆检测场景的应用需求区别较大,上述算法无法直接应用于车检站的车辆检测领域。查阅文献后未发现有前人研究过用机器学习或深度学习的方法来解决基于图像的车检站车辆检测问题,需要针对这一应用场景做有针对性的研究。
因此,本文针对车辆前照灯检测的实际需求,提出了一种改进YOLOv5s的轻量级网络模型,满足了对车辆前照灯检测的实时性与准确性的要求。实验结果表明,本文检测算法的综合性能最好,能够满足车检站中车辆检测工作的应用需求。
1 改进的YOLOv5网络结构
YOLOv5是One-stage目标检测算法的代表模型,是在YOLOv1~YOLOv4[4-7]等众多模型基础上的又一扛鼎之作。该模型共有4种版本:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,模型的性能随着网络复杂度的增加而提升。为了取得较好的检测精度和检测速度,本文采用YOLOv5s模型来进行车脸(车辆正面,简称车脸)检测。
改进的YOLOv5s由输入端(Input)、主干特征提取网络(Backbone)、多尺度特征融合网络(Neck)和预测器(YOLO Head)4部分组成,其网络结构如图1所示。

图1 改进后的YOLOv5s网络结构
改进后的网络结构以ShuffleNetV2[8]作为Backbone提取特征,并引入STA注意力模块,不仅能加快模型的检测速度,还能减少模型的参数量;删除原有的部分Concat模块,在下采样阶段,使用跨层特征融合模块STA-FF来代替,将Backbone的输出特征通过Sigmoid操作变为可学习的权重,然后与对应特征进行Element-wise product操作,增强了模型的特征提取能力,提高了不同尺寸特征的融合效率。下面分别介绍改进后的网络结构中重要的组成部分。
1.1 轻量化模型
原YOLOv5s检测算法的Backbone由Focus、CSPNet[9]和SPP[10]等结构组成,其网络层数较深且模型参数量较多。为了在保证检测精度的同时,具有较少的模型参数量,并且还具有较快的检测速度,本文引入轻量级的ShuffleNetV2网络作为YOLOv5s的Backbone。为了弥补模型轻量化造成的精度损失,在ShuffleNetV2网络中的Stage结构后添加STA注意力机制,提高模型对有效特征的捕获能力。
输入图像首先经过CBS结构(卷积Conv、批量归一化BN、激活函数SiLU)处理,调整特征矩阵的通道数并缩小尺寸;然后经过最大池化(Maxpool)操作进行下采样处理,目的是减少参数的数量;最后由Stage结构和STA注意力模块交替处理3次,输出不同尺寸的特征。为了让Backbone的输出特征维度能与Neck匹配,本文调整CBS、Stage2、Stage3、Stage4等结构的输出通道数分别为64、128、256、512。ShuffleNetV2网络结构如图2所示。

图2 ShuffleNetV2网络结构
当Stage结构中的步长(stride)取不同的值时,Stage结构也随之不同。当stride=1时,Stage结构中的左分支不做任何处理,右分支依次经过CBR(卷积Conv、批量归一化BN、激活函数ReLU)、DWConv(深度可分离卷积)和CBR处理,左分支的输出结果与右分支的输出结果进行Concat处理;当stride=2时,Stage结构中的左分支会先依次经过DWConv和CBR处理,右分支依次经过CBR、DWConv和CBR处理,左分支的输出结果再与右分支的输出结果进行Concat处理。
ShuffleNetV2网络结构及参数列表见表1。Layer表示每个特征层所经历的模块;Kernel size表示当前Layer层所采用的卷积核尺寸;stride表示步长;Repeat表示当前Layer重复堆叠的次数;Output表示当前Layer层的输出特征尺寸。当Repeat取不同值时,当前Layer层中不同结构的stride、Kernel size取值也不同。

表1 ShuffleNetV2网络结构
1.2 注意力机制
随着YOLOv5s的网络层数不断加深,Backbone在对输入图像不断卷积提取特征的过程中,图像分辨率不断降低,使得图像中分辨率较小的小目标物体的特征信息丢失,从而导致检测精度不高。为了有效改善该问题,将通道-空间注意力SA-Net[11]与跨通道注意力Triplet[12]相结合,改进SA-Net的空间注意力和Triplet的通道注意力,提出一种跨通道-空间注意力模块STA,有效捕获不同维度间的特征映射关系,在不增加计算开销的情况下提高模型的检测精度,本文在Backbone中引入STA注意力模块。STA注意力模块如图3所示。

图3 STA结构
STA注意力模块分为3个分支:
(1)第一分支是通道注意力分支,输入特征C×H×W(C、H、W分别表示特征的深度、高度、宽度)首先经过Split操作将输入特征的通道数均分,得到2组特征矩阵C/2×H×W,再分别经过均值池化(AvgPool)和最大池化(MaxPool)变为1×H×W,然后分别依次经过F(x)处理和Sigmoid激活函数生成权值,再分别将权值与特征矩阵C/2×H×W进行Element-wise product操作,最后通过Concat操作和Channel Shuffle操作得到第一个分支的输出特征C×H×W;
(2)第二分支是空间注意力分支,通道C维度和空间W维度交互处理特征信息,输入特征C×H×W首先经过Permute操作变为H×C×W,再经过Z-Pool操作(将最大池化和均值池化的结果在通道方向上拼接起来)变为2×C×W,然后经过CBR处理变为1×C×W,再经过Sigmoid激活函数生成权值,最后将权值与输入特征H×C×W进行Element-wise product操作,通过Permute操作得到第二个分支的输出特征C×H×W;
(3)第三分支也是空间注意力分支,通道C维度和空间H维度交互处理特征信息,输入特征C×H×W首先经过Permute操作变为W×H×C,再经过Z-Pool操作变为2×H×C,然后经过CBR处理变为1×H×C,再经过Sigmoid激活函数生成权值,最后将权值与输入特征W×H×C进行Element-wise product操作,通过Permute操作得到第三个分支的输出特征C×H×W。
STA注意力模块是对以上3个分支的输出特征进行相加求均值的操作。
图3中,F(x) 表示矩阵的乘法与加法操作,目的是增强特征的表达能力,从而捕获到更有效的特征信息,其计算公式如下
F(x)=wx+b
(1)
式中:w表示权值矩阵,b表示偏置向量。
1.3 跨层特征融合
浅层特征具有较多的细节信息,如纹理信息、位置信息等,而深层特征具有较多的语义信息。目标检测任务不仅需要提取语义信息用于分类识别,还需要提取位置信息用于回归。原YOLOv5s采用PANet[13]结构的多尺度特征融合方法,同时考虑浅层特征的位置信息和深层特征的语义信息。然而,简单求和或拼接的特征融合方式会使得模型对不同尺寸的特征分配固定的权重,从而忽视了不同尺寸特征之间的差异,导致特征在融合的过程中丢失部分细节信息。因此,本文提出了一种基于STA的跨层特征融合(STA-FF)模块,其核心思想是在特征融合过程中引入注意力机制,在通道域和空间域上对不同尺寸的特征引入一个可学习的权值,使模型自行学习不同尺寸特征的重要性来实现加权特征融合,动态地改变原有固定特征权值分配方式。STA-FF模块的结构如图4所示。

图4 跨层特征融合(STA-FF)模块
STA-FF模块的计算公式如下
Z=Concat(X,Y)⊙Sigmoid(STA(A))
(2)
式中:X与Y表示待融合的特征,XY表示经过Concat操作后得到的初步融合特征;A表示Backbone输出的特征,A′表示经过STA注意力模块和Sigmoid激活函数后得到的注意力权值矩阵;⊙表示Element-wise product操作;Z表示最终融合后的特征。
为了更加合理地分配权值,本文通过一种基于STA注意力机制的自适应权值分配方法来动态地分配权值。首先,将待融合特征X与Y通过Concat操作融合,得到初步的融合特征XY;然后,特征A经过STA注意力模块后得到的注意力权值矩阵A′,再经过Sigmoid激活函数处理后A′的值域范围为0~1;最后将初步融合后的特征XY与权值矩阵A′进行Element-wise product操作,得到最终的融合特征Z。
2 实验结果与分析
2.1 数据集及预处理
由于现有的公开车辆数据集主要用于车型检测,大部分是对车身进行标注,用于区分小车(car)、公交车(bus)、出租车(taxi)、卡车(truck)等车型,导致数据集中车辆类别不多、车辆图片单一,外形相差无几,缺少车脸的信息,不适用于车辆前照灯检测的需求,所以本文构建了一个车脸数据集Car-Data,对汽车的车脸部分进行标注,即对车灯(carlight)、车标(logo)、车身颜色(color)进行人工标注。其中,车标尺寸小于32像素,车灯尺寸介于32像素与96像素之间,车身颜色尺寸大于96像素,根据MS COCO数据集[14]的定义,它们依次为小、中、大目标。


图5 数据集部分图片
由于是自建数据集,故YOLOv5网络中原anchor参数不再适用于本文的数据集。因此,使用K-means聚类[15]算法获取合适目标的边界框,以便能使算法更快收敛。先验锚框的尺寸见表2。
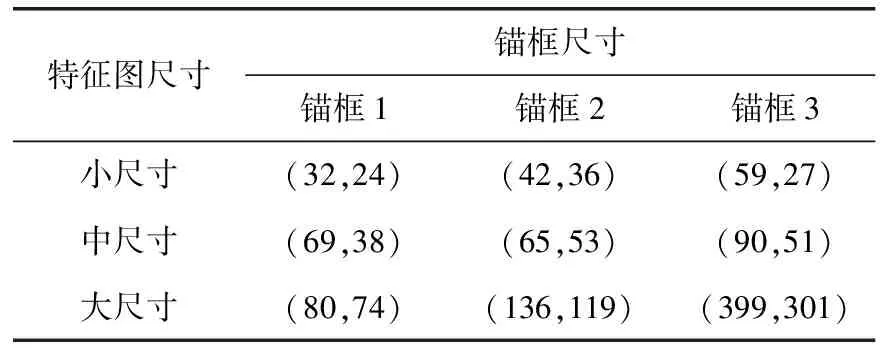
表2 先验锚框尺寸
2.2 训练环境及超参数
本实验的深度学习框架为Pytorch1.9.0,CUDA版本为11.4,编程语言为Python3.8,集成开发环境为PyCharm,程序运行平台为Windows10操作系统,CPU为11th Gen Intel(R) Core(TM) i7-11700 @2.50 GHz,GPU为GeForce RTX 3060,显存为12 G。
网络的超参数配置如下:在模型训练中,通过Adam优化器对参数进行调优,初始学习率为0.001,学习率动量为0.937,权重衰减系数为0.0005,使用余弦退火算法动态调整学习率,以防止模型过拟合;batch-size设置为32,提高训练速度;训练总次数为100个Epoch。
YOLOv5模型的损失函数Loss由分类损失Lclass、定位损失Lloc和置信度损失Lconf这3部分加权求和组成,计算公式如下
Loss=λ1Lclass+λ2Lloc+λ3Lconf
(3)
式中:λ1、λ2和λ3为平衡系数。
分类损失Lclass的计算公式如下


(4)
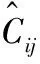
定位损失Lloc的计算公式如下
Lloc=1-CIoU



(5)
式中:IoU表示预测框与真实框的交并比;ρ(b,bgt) 表示预测框与真实框中心点坐标的欧氏距离;c表示能够同时包含预测框与真实框的最小闭包区域的对角线距离;α为权重参数;v为度量长宽比一致性的参数;wgt、hgt分别表示真实框的宽和高;w和h分别表示预测框的宽和高。
置信度损失Lconf的计算公式如下


(6)

训练过程中的损失函数迭代过程如图6所示。

图6 训练损失
2.3 评价指标
本文采用平均精准率(mean average precision,mAP)、模型参数量(Parameters)和检测速度(frame per second,FPS)作为算法性能评价指标。mAP是针对多类别目标检测精度的情况,它是多类别目标平均精度(AP)的平均值;Parameters表示模型的参数量,其值越小则模型越轻量化;FPS用来评价检测速度,其数值表示检测模型每秒检测图像的帧数,该指标用于衡量模型的实时性。
召回率Recall、精度Precision的计算公式如下
(7)
(8)
其中,TP(True Positive)表示模型检测为真的正样本个数;FN(False Negative)表示模型预测为非真的正样本个数;FP(False Positive)表示模型检测为真的负样本个数。
AP是指在所有召回率的可能取值情况下得到的所有精度的平均值,计算公式如下

(9)
式中:P表示Precision,R表示Recall,以Recall为横轴,Precision为纵轴,并将每次的值连线,绘制得到PR曲线。使用积分的方法来计算PR曲线与坐标轴围成的面积,得到AP。
mAP表示所有类别的平均准确率AP均值,计算公式如下
(10)
式中:n为总的类别数量。
2.4 消融实验
对轻量化模型、注意力机制以及跨层特征融合的有效性分别进行实验,选择Ultralytics5.0版本的YOLOv5s作为实验的基准模型。
2.4.1 不同Backbone对比
通过消融实验来验证本文使用ShuffleNetV2作为Backbone是否能够在保证模型检测精度的同时实现模型的轻量化和实时性,实验结果见表3。

表3 不同Backbone对检测性能的影响
从表3中结果可以看出,在YOLOv5s网络的基础上将Backbone替换为ShuffleNetV2,mAP降低了0.7个百分点,FPS提升了20.98 frame/s(23%),Parameters降低了14.20 M(53%)。实验结果表明,在mAP略微降低的同时,能够极大降低模型参数量,并能有效提升模型的检测速度,这验证了替换Backbone对减小模型参数量和加快图像推理速度的有效性。
2.4.2 注意力机制对比
注意力机制并不是在网络中的任何位置均有作用,通过多次实验发现,相比于将STA注意力模块添加到Neck和YOLO Head中,将其添加在Backbone中,取得了最好的检测效果,实验结果见表4。本文认为将STA注意力模块嵌入到模型的不同位置之所以导致不同的检测效果,是因为Backbone中的特征含有丰富的轮廓信息和纹理信息,能够更好地捕获细节特征信息;而在更深层次的Neck和YOLO Head中,由于特征含有更丰富的语义信息和更大的感受野,导致STA注意力模块难以区分特征间的重要性。

表4 不同注意力模块对检测性能的影响
YOLOv5s-Backbone表示在Backbone中的每个Stage结构后面引入一个STA注意力模块;YOLOv5s-Neck表示在Neck中的每个CSP结构后面引入一个STA注意力模块;YOLOv5s-Head表示在YOLO Head中的每个Head结构前面引入一个STA注意力模块。
从表4中结果可以看出,以ShuffleNetV2作为Backbone,在YOLOv5s模型的不同位置分别嵌入STA注意力模块后,Parameters保持不变。在Backbone中嵌入STA注意力模块后,mAP提升了0.8个百分点,FPS降低了2.24 frame/s;而在Neck和YOLO Head中分别嵌入STA注意力模块后,mAP分别降低了0.2个百分点和0.9个百分点,FPS分别降低了1.81 frame/s和3.02 frame/s。
实验结果表明,在Backbone中嵌入STA注意力模块虽然使得模型的检测速度有一定程度的降低,但却能捕获到更为完整的特征信息,增强了模型对特征信息的捕获能力,从而提高了模型的检测精度,并且不会额外增加模型参数量,即不会造成额外的计算开销,这验证了STA注意力模块对提高模型检测精度的有效性。
2.4.3 特征融合方法对比
为验证改进的特征融合方法STA-FF模块的有效性,本文对不同的特征融合方法进行消融实验,实验结果见表5。

表5 不同特征融合方法对检测性能的影响
从表5中结果可以看出,引入改进的特征融合方法STA-FF模块后,mAP提升了2.1个百分点,FPS降低了4.85 frame/s,Parameters保持不变。实验结果表明,与原始特征融合方法Concat相比,改进的特征融合方法STA-FF在特征融合过程中基于注意力机制分配可学习权值,使得模型不仅能够捕获特征中更加高级的语义信息,还能保留更多特征融合后的细节信息,从而能够提升模型的检测精度,这验证了改进的特征融合方法STA-FF模块对提高模型检测精度的有效性。
2.5 网络模型对比实验
为了检验本文模型的性能,选取Faster R-CNN[16]、RetinaNet[17]、YOLOv4和YOLOv5s在相同数据集上进行训练、验证和测试。实验结果见表6。

表6 不同检测算法性能对比
从表6中结果可以看出,本文模型提高了检测精度,mAP达到了94.3%,实现了模型的准确检测;同时具有较高的检测速度,FPS达到了105.60 frame/s,实现了模型的实时检测;相比原YOLOv5s模型,Parameters减小了14.20 M(53%),实现了模型的轻量化。因此可以得出,与其它主流目标检测模型相比,本文模型在检测精度、检测速度和模型轻量化等方面性能更优,能够更好地完成车检站中车辆检测的任务。
2.6 定性结果分析
为了定性比较本文模型与原YOLOv5s模型,从而获取更直观的对比效果,本文分别用这两种模型对测试集的部分车辆图片进行了检测,部分检测结果对比如图7~图9所示。
从图7对比结果中可以看出,YOLOv5s模型出现了置信度较低的情况:“carlight”标签、“Roewe”标签和“Suzuki”标签的置信度相对较低,均低于0.9;而本文模型的置信度较高,达到了0.9及以上。
从图8对比结果中可以看出,YOLOv5s模型出现了漏检的情况:未检测到“Blue”标签、“Subaru”标签和“Peugeot”标签;而本文模型准确检测出所有目标,且置信度较高。

图8 检测效果对比(漏检)
从图9对比结果中可以看出,YOLOv5s模型出现了误检、漏检的情况:将正确的“Orange”标签误检为“Yellow”标签、未检测到“JAC”标签;本文模型能够全部将目标正确检测出来且置信度较高。

图9 检测效果对比(误检)
由上述多种情况比较可知,相比于原YOLOv5s模型,本文模型的检测性能更好,对复杂环境具有较好的鲁棒性,降低了误检和漏检的概率,具有良好的泛化能力。
3 结束语
针对车检站中车辆检测的实际需求,本文结合ShuffleNetV2设计出一种基于YOLOv5s的轻量化车脸检测算法。实验结果表明,相比于目前几种主流检测算法,本文算法在满足轻量化的同时,也具备较高的检测精度,并且能更好地满足目标检测任务的实时性要求。本文算法的不足之处在于对小目标物体检测的效果不够理想。后续工作的研究重点是确保模型轻量化的同时进一步提高检测精度和检测速度,同时探究雨雪天气和夜间环境对车辆目标检测的影响,加强模型对小目标物体的检测能力。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
小雪花·成长指南(2022年1期)2022-04-09
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
电子制作(2018年11期)2018-08-04
传媒评论(2017年3期)2017-06-13
自动化学报(2017年7期)2017-04-18
第二课堂(课外活动版)(2016年2期)2016-10-21
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
