
基于FPGA的图像处理硬件加速系统的设计
2024-03-21 01:48张灿宇封岸松张华良王俊彭
计算机工程与设计 2024年3期
张灿宇,封岸松,张华良,易 星,王俊彭
(1.沈阳化工大学 信息工程学院,辽宁 沈阳 110142;2.中国科学院 沈阳自动化研究所,辽宁 沈阳 110016;3.中国科学院 网络化控制系统重点实验室,辽宁 沈阳 110016)
0 引 言
图像处理算法[1,2]日益复杂,使用普通的计算平台无法解决算法计算量越来越大、内存需求越来越高的问题,而现场可编程门阵列(field-programmable gate array,FPGA)可以很好地解决这个问题。当前主流的图像处理计算平台有:GPU(graphics processing unit,GPU)、ASIC(application specific integrated circuit,ASIC)[3,4]。GPU可以很好地对算法进行硬件加速,但使用GPU对环境和库的依赖性大,应用场景受限不适合在移动应用;ASIC可为具有特定功能的应用进行设计开发,但ASIC的设计和开发周期长,研究成本高,灵活性差导致其并不适合图像处理算法的部署[5]。
而FPGA不仅内部包含大量的乘法单元,同时还可以对大量变量进行逻辑运算和赋值实现并行计算,让图像处理算法更加适合在FPGA上部署。FPGA有着丰富的片上资源和良好的内存带宽,兼具高性能、低功耗、适应性强的优点,而且根据FPGA的可重构性,在不需要更换芯片的情况下就可以让用户自己设计算法架构和接口类型,极大地方便了开发人员后续的维护工作[6]。然而FPGA使用硬件描述语言开发周期长,调试手段不足导致硬件相关的研究进展缓慢,在HLS(high-level synthesis,HLS)高层次综合技术出现之后突破了以往使用硬件描述语言的局限性,可以快速地描述和实现所需的硬件结构,加速了OpenCV算法的实现过程。
目前已有许多研究人员利用FPGA进行算法的硬件加速并取得了一定的研究成果。Nguyen等[7]采用了硬件RTL电路对YOLOv2算法进行硬件加速,使用了较少的DSP完成了算法的复杂计算任务,Nakahara等[8]使用FPGA进行目标检测算法的硬件加速达到一定的效果,Yu等[9]将卷积和反卷积运算设计在FPGA上采用硬件描述语言进行硬件加速。
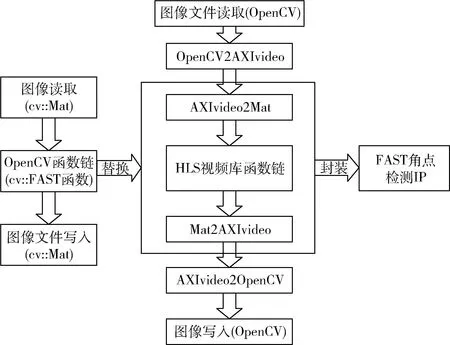
本文以FAST角点检测算法和Sobel边缘检测算法为例,将这两种算法部署在FPGA上进行硬件加速,采用PYNQ-Z2开发板,使用HLS高层次综合技术进行算法的实现及优化,充分利用FPGA的片上资源,同时在Xilinx公司提供的Vivado 2018.3开发工具进行系统模块集成,最后进入Jupyter Notebook计算环境,完成系统模块的调用及驱动,实现系统功能。
1 角点检测及Sobel边缘检测算法原理及IP核设计
1.1 FAST角点检测算法原理
在Edward Rosten和Tom Drummond发表的《Machine learning for high-speed corner detection》文章中提出了一种FAST特征点,随后又对文章进行修改后再次发表了《Feature From Accelerated Segment Test》,其中对FAST角点进行了定义:任取一个像素点与其周围足够多的像素点进行比较,若这个点与周围点的不同符合某种要求时,则该点就是角点。判定某一点是否为角点,先确定一个角点响应函数,如式(1)所示
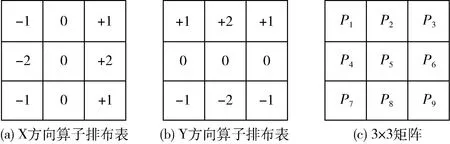
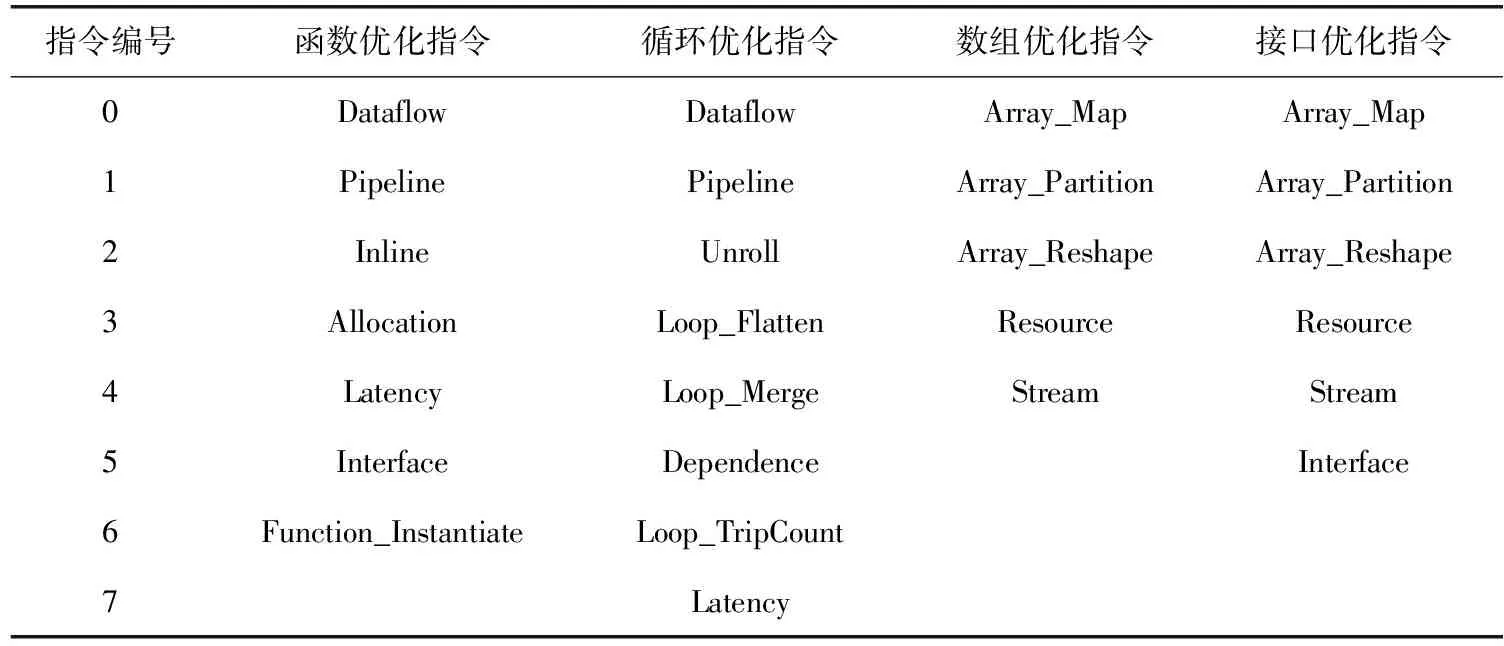
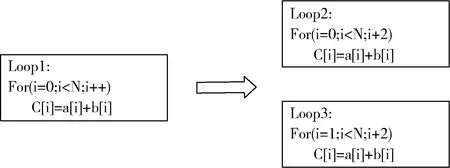
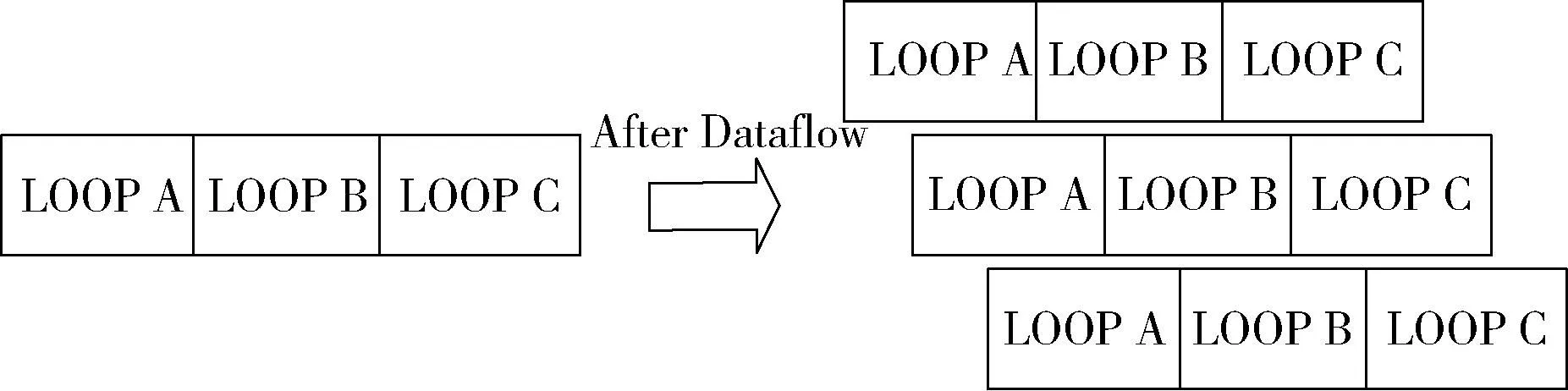
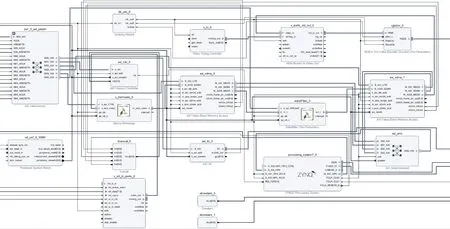
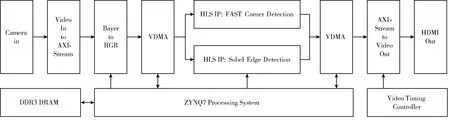
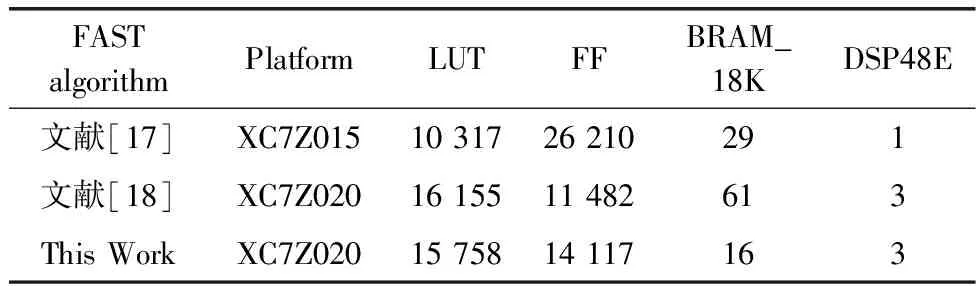
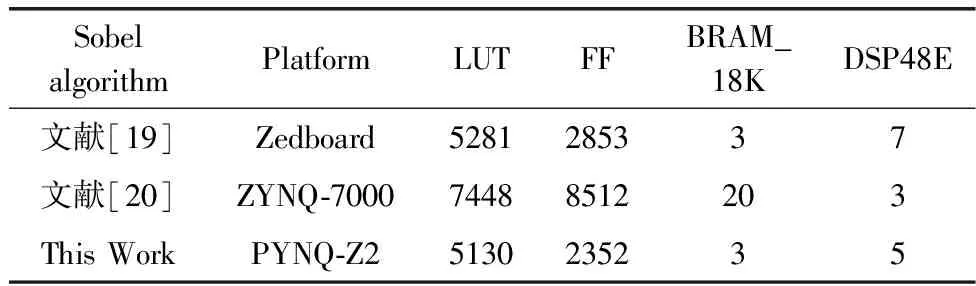
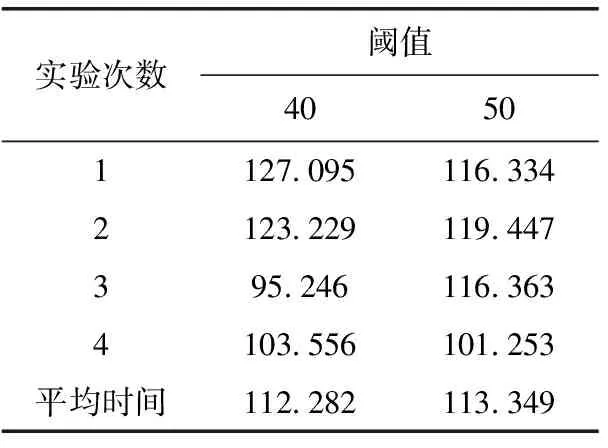
N=∑|I(x)-I(p)| (1) 式中:I(x) 为圆周上任一像素点的灰度值;I(p) 为中心像素点的灰度值,Th为设定的阈值;circlez(p) 是以p点为中心的圆上点的集合。研究后发现,选取的圆半径为3时FAST角点检测的效率和精度能达到一个很好的平衡。FAST角点检测的原理就是任取一像素点作为圆心画圆,圆的半径为3,周长为16像素。FAST角点检测原理如图1所示。 图1 FAST角点检测原理 第一步:像素点编号。在圆上按照顺时钟方向对像素点依次进行编号,一共16个。 第二步:准角点选取。选取其中的第1、第5、第9、第13像素点分别按照式(2)进行比较,若4个像素点中至少有3个符合,则该中心点p为准角点。遍历图像中所有的像素点,所有符合要求的点均为准角点。 第三步:准角点判断。当所有的准角点被筛选出来后,还要进行下一步的判断看是否为角点,即利用式(1)角点响应函数依次与圆上的像素点进行判断,当有至少9个像素点满足要求时,则该认为点为角点,否则,p点不为角点。 第四步:引入非极大值抑制。在经过上述步骤进行角点检测之后,会导致在图像中某一处多次重复出现角点形成聚簇效应,所以通过引入非极大值抑制的方法来解决这一问题。非极大值抑制就是如果在角点p为中心的3×3邻域内出现一个角点,那么就保留这个角点,当存在多个角点时,则需要计算除角点p以外的角点的分值Vi,分值计算如式(2)所示 (2) 式中:Vi为角点p邻域内圆上点Ii(x) 与点Ii(x) 对应的中心点Ii(p) 差值的绝对值总和。最后,保留V值大的角点作为邻域内的角点,V值较小的角点则被删除。 FAST角点检测算法IP通过Xilinx公司提供的Vivado HLS工具进行设计,在算法设计的过程中,需要将OpenCV(open source computer vision library,OpenCV)函数链替换为HLS视频库里提供的函数链[10]。Vivado HLS进行图像处理设计具体流程如下:①HLS在处理图像时需要将存储的OpenCV格式的图像数据转换为AXI-Stream视频流格式,在HLS中通过IplImage2AXIvideo函数实现转换;②再将视频流格式的图像数据转换为Mat格式,通过相应的AXIvideo2Mat函数将其转换;③调用HLS视频库中对应的图像处理函数进行图像处理;④经过处理之后再转换为AXI-Stream视频流格式;⑤最后还原成OpenCV格式将其保存,通过以上操作就完成了使用HLS对图像的处理。最后经过综合和仿真测试将算法打包成IP核放在Xilinx提供的Vivado工具进行系统模块设计。OpenCV与HLS视频库图像处理设计流程如图2所示。 图2 OpenCV与HLS视频库图像处理设计流程 在Vivado HLS中完成了FAST角点检测算法的IP设计,在算法中设置阈值为40,对图3(a)进行角点检测,仿真结果如图3(b)所示。 图3 Vivado HLS原图及仿真结果 由表1所列,FAST角点检测算法硬件加速设计的时钟频率为9.4 ns,算法运行的时钟周期为1021321,则FAST角点检测算法运行的时间为9.6 ms。 表1 FAST硬件加速设计的时钟频率/ns 实验采用Sobel边缘检测算法进行图像的边缘检测,Sobel算子引用类似局部平均的运算,对噪声有平滑效果,同时还能提供精准的边缘信息。Sobel算子在像素的上、下、左、右处进行灰度值加权差计算,对噪声具有一定的平滑作用,在要求不是很高的情况下,Sobel边缘检测算法是足以满足需求的。 Sobel边缘检测的原理是通过将图片划分为多个不同的3×3矩阵,以被处理像素为中心对其邻域进行灰度分析的一种算法。具体操作方法是通过X方向算子和Y方向算子与相邻区域像素点构成的矩阵作卷积来计算该像素点的水平梯度和垂直梯度,然后根据向量的方法求出梯度值,然后将梯度值与设定的阈值比较,如果梯度值大于阈值,这个像素点就为边缘点,就是非边缘点。Sobel算子模板及像素矩阵如图4所示。 图4 Sobel算子模板及像素矩阵 对3×3矩阵分别与Sobel X方向、Y方向算子进行卷积得到像素点的水平梯度、垂直梯度分别如式(3)、式(4)所示 Gx=P1×(-1)+P2×0+P3×1+P4×(-2)+ P5×0+P6×2+P7×(-1)+P8×(-9)+P9×1 (3) Gy=P1×1+P2×2+P3×1+P4×0+P5×0+ P6×0+P7×(-1)+P8×(-2)+P9×(-1) (4) Sobel边缘检测算法IP与FAST角点检测设计流程类似需将OpenCV中Sobel函数替换为HLS视频库里的Sobel函数,具体的设计流程如下:①在HLS中通过IplI-mage2AXIvideo函数实现转换,将存储的OpenCV格式的图像数据转换为AXI-Stream视频流格式;②然后通过AXIvideo2Mat函数再将视频流格式的图像数据转换为Mat格式;③调用HLS视频库中Sobel算子函数进行边缘检测处理;④处理完毕之后还需将其再次转换为AXI-Stream视频流格式;⑤最后还原成OpenCV格式将其保存在DDR3中。在对算法进行仿真时添加一张图像进行验证,最后将算法封装为一个RTL级IP核,通过Vivado软件进行硬件Block Design设计时使用。最终Vivado HLS原图及检测结果如图5所示。 由Vivado HLS综合生成的报告可得到硬件加速设计的时钟频率如表2所列,时钟的频率为10.049 ns,算法运行的时钟周期为1149198,则Sobel边缘检测算法运行的时间为11.5 ms。 表2 Sobel硬件加速设计的时钟频率/ns HLS(high-level synthesis,HLS)即高层次综合,通过Xilinx官方提供的Vivado HLS工具可以将使用的高层次语言(如:C、C++、System C)可自动转换成低层次语言(如:Verilog、VHDL、SystemVerilog)[11,12],由逻辑结构向RTL硬件电路模型的这一转换,突破了以往对FPGA使用硬件描述语言(hardware description language,HDL)设计的局限性,相比之下HLS代码可读性高,便于维护,可以更加方便实现各种接口的协议,同时HLS的使用提高了对IP核(intellectual property core)的重用率,还能从更抽象的层次对算法进行功能性验证,开发效率更高[13]。除此之外,在Vivado HLS工具里提供了HLS视频库,可以直接去调用所需的图像处理函数,然后将其封装为IP核以便调用。 在开发FPGA项目时,可在Matlab中进行算法的功能性验证,当算法的功能能够准确显示出来,就可以在Vivado HLS中使用C、C++代码实现该算法,为了能够充分地利用FPGA的内部资源,发挥FPGA的并行计算能力,以获取更高的性能,在完成算法的综合和仿真后还需进行优化,直到最后的设计能够满足要求为止[14]。 Vivado HLS为用户提供了多种优化方法,通过使用不同的优化方法进而调整和控制FPGA的内部逻辑和I/O行为。Vivado HLS中包含两种优化方法:一是使用Directives,在Directives控制栏中将所需变量进行优化设置,以编译选项的方式插入到代码中,为开发人员带来了极大便利;二是在代码中插入#pragma命令来确定变量实现类型和结构。Vivado HLS优化指令见表3。 表3 Vivado HLS优化指令 一般优化分为串行和并行两种方式,串行方式使用的硬件资源少,但加速效率差;并行方式以消耗硬件资源加速任务执行,效率高。为了实现对算法的硬件加速,通常采用并行处理的方式。并行处理的优化方法有以下几方面:①模块内部进行展开(unroll);②对模块内部进行流水化(pipeline)操作;③对模块之间进行流水化操作;④数据流优化(Dataflow)。循环展开:对for循环来说,可以通过添加directives指令进行展开,可以将一个for循环展开成N个for循环,每个循环执行1/N的运算,而这N个循环可以同时进行计算处理,减少了算法的处理时间,以消耗硬件资源的方式获取更短的计算时间。从图6可知,将原先的一个for循环一分为二,两个for循环并行执行,从而节省了一半的时间。 图6 循环优化Unroll处理前后对比 流水化(pipeline)处理:对任务内部进行流水化操作,它能使II(initiation interval,II)和Latency最大化降低,同时还能使子任务(函数、循环)最大程度地并行执行,II指的是数据初始化间隔,表示模块在连续接收两次输入数据的时间间隔,当II越小,意味着数据吞吐量越大;Latency指的是从输入数据到接收所有输出数据的延迟时钟数,当Latency越小,同样意味着计算速度越快。由图7可以看出,原先的任务在没有pipeline时,整个的计算是按照先后顺序执行的,需要执行N次花费3N个时钟周期才能完成计算,而在进行pipeline处理后整个计算过程只花费了N+2时钟周期,因为现在的计算操作不用再等前一次的循环执行结束后再去执行下一个循环,而是当前一次循环执行完一个阶段就可以执行下一次了,这样开始大大提高了计算效率。 由图8可知,在没有使用Dataflow优化指令时,3个循环是按照顺序执行的,再加入Dataflow指令后,当LOOP A有输出时就可以利用这个输出去执行LOOP B,不需要等到LOOP A执行完后再开始执行,通过加入Dataflow指令后,多个任务的执行就有了交叠部分,从而降低了Latency,提高了数据的吞吐率。 图8 循环优化Dataflow处理前后对比 通过直接计算和进行流水化、循环展开后可得到表4。 表4 结果对比 由表4可知,在进行流水化处理后并不会增加硬件资源的消耗而能高效完成计算任务,在进行循环展开后资源消耗成倍增加的同时效率也会成倍增加,另外,电路的时延因在进入和退出循环各需要一个时钟周期而比像素数多2,这种就是以牺牲硬件资源消耗换取计算效率达到硬件加速效果。 系统硬件平台是基于Xilinx 公司的PYNQ-Z2,FPGA主芯片为ZYNQ XC7Z020-1CLG400C,开发板包含1个650 MHz的双核ARM Cortex-A9处理器、1个630 KB的Block RAM(block random access memory)、220 DSP(digital signal processing)切片和1个外部512MB DDR3(double-data-rate three synchronous dynamic random access memory)。 整个系统可分为两个部分:PS(processing system)、PL(programmable logic)。PYNQ的PS端在ZYNQ的基础上内置了Liunx操作系统和Python的编译环境,PL端的各种IP核都被内置为“Overlays”以方便调用,这种形式类似于软件库。PYNQ使用Overlay可以对连接到PS端的接口进行解析,进而控制FPGA 逻辑资源及IO(Input/Output)。 在PS端负责对OV5640摄像头进行初始化设置以及VDMA和对HDMI显示驱动,PL端负责视频图像数据的采集、角点及边缘检测处理和结果显示。 3.1.1 PL部分 PL端分为3个模块:图像采集、处理以及显示模块。 (1)图像采集模块:图像采集模块采用OmniVision公司的OV5640摄像头作为图像传感器,也就是数据采集前端,它可以将模拟量转换成数字量,支持90 fps VGA(640×480)分辨率的图像采集,支持输出的图像格式为RGB565等。由于图像传感器只能感受光的强弱,无法感受光的波长,而光的颜色是由波长决定的,导致最后画面不能出现颜色。为解决这个问题,引入Bayer插值补偿算法(Bayer interpolation),也就对应于Sensor Demosaic IP。 在使用OV5640时,需要将其上电初始化,而后使用I2C总线对寄存器参数进行配置初始化,当经过两步初始化后就可以进行图像采集工作。I2C总线是一种双向的二进制串行总线,它只需两根线就可在连接在总线上的器件之间进行信息传递,即数据线SDA和时钟线SCL。I2C支持多机通讯,也支持多控模块,但前提是在同一时刻下主控只有一个。 (2)图像处理模块:图像处理模块包含两个IP:FAST边缘检测和Sobel边缘检测,当图像数据由VDMA(video direct memory access)传过来时就可以对数据进行处理。VDMA包含4个基本参数: 1)Memory Map接口(64位):与AXI HP接口进行数据交互,读取在PS端DDR缓存的图像数据。根据AXI HP接口是64位,所以此接口也设置成64位。 2)Stream Data Width(24位):通过此接口将所需传输的图像数据传至HDMI接口,因在此使用的是RGB图像数据格式,所以数据位数设置成24位。 3)Frame Buffers:通过设置此参数来图像帧数,可缓存多帧,根据自己的需求即可。 4)Line Buffer Depth(4096):它以Stream Data Width作为基本单位,设置数值越大,缓存的数据也就越多,这种缓存方式类似于FIFO缓存。 (3)图像显示模块:图像数据处理完后通过HDMI显示器进行显示,图像显示模块包含输出时序控制模块和RGBtoDVI模块,输出时序模块可通过Vivado软件自带的IP核VTC(video timing controller)添加到硬件设计中,通过设置VTC的输出视频分辨率和时钟大小就可以将场同步信号和行同步信号引出,RGBtoDVI模块是将RGB888格式的图像数据转换成TMDS数据输出给HDMI显示器。 在系统搭建后添加Vivado所需的.xdc约束文件进行引脚约束,.xdc文件是一系列的tcl语句,可以直接放在工程里,在综合和布局布线的时候进行调用,Vivado block design设计如图9所示。 图9 Vivado模块设计 3.1.2 PS部分 PL端设计完成后还需从Vivado中导出PYNQ所需的.tcl脚本文件、.bit比特流文件、.hwh文件进行PS端的开发。PS端集成了Linux操作系统和Python编译环境,将PYNQ镜像文件烧录到SD卡中,通过网线以及USB线连接PC端,同时使用PuTTY串行接口连接软件进入到Jupyter Notebook环境下进行系统测试。Jupyter Notebook是一个基于Python内核和Websocket协议的交互式计算环境,它的使用要求简单,只需要一个兼容Web的浏览器就可以进入,在Jupyter Notebook里运行Python对PYNQ进行PS端的开发。 PS部分包含使用I2C初始化摄像头、使能算法IP、调用VDMA和对HDMI显示驱动等与PL端进行数据交互,显示处理结果等,实验最后的实时视频检测可达56帧/s,满足实时图像检测的要求。Jupyter开发环境如图10所示。 图10 Jupyter开发环境 系统框架如图11所示,整个系统的工作流程:PS端通过ARM处理器对OV5640摄像头进行初始化并通过I2C接口对OV5640摄像头进行配置,配置完毕之后将进行图像数据的采集,将采集到的图像数据通过Video In to AXI-Stream IP核转化成AXI4-Stream格式,经过VDMA,再经过AXI_HP接口传至DDR3外部存储器进行存储,然后读取DDR3中的数据传至image processing IP,通过使能不同的算法IP从而进行FAST角点检测或Sobel边缘检测,图像处理完毕之后数据再通过VDMA传至显示器进行显示。 图11 系统框架 相较于文献[15,16]的图像处理系统,如图12所示,使用USB摄像头采集图像数据后需要将数据从PS端传回PL端,在图像处理模块处理之后还需要将图像数据从PL端传回PS端,而本系统在PL端实现了完整的视频通路,可对图像数据直接进行处理,避免了图像数据多次从PS端传给PL端、PL端再回传给PS端的负载问题,提高了性能和降低了时延。 图12 其它系统架构 3.2.1 资源消耗对比 当在FPGA上实现算法时,需要平衡“面积”和“速度”,在这里“面积”指的是资源消耗的多少,“速度”也就是算法的性能,包含算法的处理速度、延时、吞吐量等。当减少“面积”的使用,算法的运行性就会降低;如果要求算法的“速度”快,就要牺牲“面积”。在Vivado HLS中进行综合后得出算法资源消耗情况,同时与其它资源消耗情况进行对比,对比情况如表5所列。与文献[17,18]实现的FAST角点检测算法相比,在HLS中算法的各种资源消耗较为合理介于二者之间,同时可以明显地看出在3种资源消耗情况中差异最大的是BRAM的使用,在进行图像处理中BRAM_18K用于数据量大的存储,HLS技术的使用能够在保持高性能的情况下尽量减少FPGA的资源消耗。 表5 FAST角点检测算法的资源对比消耗情况 Sobel边缘检测算法在Vivado HLS中进行综合后得出算法资源消耗情况如表6所列,在图像处理的过程中,LUT查找表(Look Up Table)和FF触发器(Flip Flop)用于数据量小的存储,BRAM_18K可用于数据量大的存储,DSP数字信号处理在图像处理的过程中主要用于乘加运算。与文献[19]实现的Sobel算法相比,可以清晰地看到本文的各种资源消耗较少;与文献[20]相比,最明显的资源消耗为FF触发器,消耗量为本文的FF触发器的使用量的3.6倍,LUT查找表的消耗量是本文的1.45倍。 表6 Sobel边缘检测算法的资源消耗对比情况 3.2.2 处理时间对比 OpenCV(open source computer vision library)是一个跨平台的开源数据库,为比较OpenCV软件实现的处理结果与本系统实现的结果,将在PC上使用Microsoft Visual Studio软件分别调用OpenCV函数库中FAST角点检测函数和Sobel边缘检测函数,使用同样的图片进行处理。如表7所示,是使用OpenCV FAST进行角点检测分别在阈值为40和50的情况下所需的平均时间为12.282 ms和113.349 ms,而使用Vivado HLS进行FAST角点检测只需9.6 ms,Vivado HLS进行FAST角点检测算法硬件加速设计相比于软件算法实现快了11倍。如表8所示,同样使用OpenCV Sobel边缘检测所需的平均时间为110.418 ms,而采用硬件设计实现图像处理只需11.5 ms,比在软件上实现快了9.6倍。 表7 使用OpenCV FAST角点检测所需的时间/ms 表8 使用OpenCV Sobel边缘检测所需的时间/ms 由此可知,使用FPGA进行算法的硬件加速会大幅度地缩短了算法的执行时间,提高了算法的吞吐量。同时根据Vivado提供的功耗报告可知,系统的总功耗为1.9 W,其中动态功耗为1.743 W,静态功耗为0.157 W,系统满足低功耗的要求。 该文设计并实现了一套完整的实时图像处理系统,将FAST角点检测算法和Sobel边缘检测算法部署到FPGA上进行硬件加速,并采用HLS高层次综合技术对两种算法进行设计优化,同时,在FPGA上实现了全部视频输入输出接口和图像算法的完整通路,提高了性能、降低了时延。实验结果表明,在硬件上实现的算法检测速度比在软件上实现快了9~11倍,同时系统实时视频帧率可达56帧/s,满足实时性要求。FPGA在未来的应用将会越来越广泛,将进一步研究在FPGA上实现更加复杂的算法,充分利用FPGA的片上资源来提高系统性能、降低功耗等。
1.2 FAST角点检测算法IP设计


1.3 Sobel边缘检测算法原理
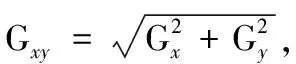
1.4 Sobel边缘检测算法IP设计

2 HLS简介及Vivado HLS开发环境下算法的优化
2.1 HLS简介
2.2 Vivado HLS开发环境下算法的优化

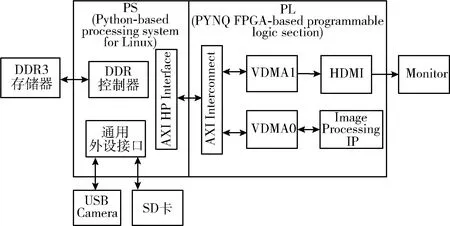
3 系统实现及分析
3.1 系统实现

3.2 实验结果分析

4 结束语
猜你喜欢
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
上海大学学报(自然科学版)(2018年5期)2018-11-02
电子技术与软件工程(2018年10期)2018-07-16
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
电子科技(2016年12期)2016-12-26
系统工程与电子技术(2016年4期)2016-08-24
电气化铁道(2016年4期)2016-04-16
河南科技(2014年1期)2014-02-27
