
SQL-to-text 模型的组合泛化能力评估方法
2024-03-21 08:15:28陈琳范元凯何震瀛刘晓清杨阳汤路民
计算机工程 2024年3期
陈琳,范元凯,何震瀛,刘晓清,杨阳,汤路民
(1.复旦大学计算机科学技术学院,上海 200433;2.星环信息科技(上海)股份有限公司,上海 200233)
0 引言
随着信息技术的高速发展,各类应用产生大量数据,关系数据库被广泛用于数据的存储和管理。用户在与关系数据库交互时,常使用结构化查询语言(SQL)。然而,SQL 的使用受限于用户对SQL 的熟练程度和对关系数据库中数据的了解程度,导致SQL 的使用门槛相对较高。针对这一问题,根据自然语言的翻译到SQL(text-to-SQL)[1]和根据SQL 到自然语言的翻译(SQL-to-text)成为降低SQL 使用门槛、提高数据库易用性的重要尝试,引起了研究人员的关注。其中,SQL-to-text 能够帮助用户理解查询的含义,在需要解释SQL 语义的场景下具有重要意义[2],并且有助于强化搜索引擎的SQL 程序查找能力,还可以用于搭建数据库的自然语言交互接口[3]。
虽然SQL-to-text 已逐渐成为业界关注的热点问题之一,但就其效果而言,在现阶段还难以达到广泛应用的程度。其主要原因有翻译模型的能力不足、对数据库应用中的数据理解程度不足和对数据库应用中的知识使用不足。其中,翻译模型的能力不足是一个重要原因,鉴于组合泛化能力对翻译模型的重要性,需要对SQL-to-text 模型的组合泛化能力展开研究。
组合泛化一词由语言学家提出,是通过已知的成分理解和产生无限新组合的代数能力[4],此概念于近年来被引入机器学习领域。对神经网络模型而言,若学习得到的知识以不同的方式组合后仍能理解其含义,则表明该模型具有组合泛化能力。此能力不足的模型一般只学习到模式间的映射,需要大量训练数据才能达到人们用少量数据即可达到的学习效果[5]。
针对SQL-to-text 任务,当模型在训练时学习的SQL 子句以不同的方式组合后,若模型仍能理解其含义并提供正确翻译,则说明此模型具有组合泛化能力。例如,模型已学习了SELECT first_name,last_name FROM players WHERE hand=‘L’和SELECT first_name,last_name FROM players ORDER BY birth_date 如何翻译,具有组合泛化能力的模型应能正确翻译SELECT first_name,last_name FROM players WHERE hand=‘L’ ORDER BY birth_date。在实际应用场景中,模型使用者通常更需要模型为复杂SQL 提供翻译,而提供的训练数据对复杂SQL 的覆盖程度较低。此情况要求SQL-totext 模型从简单的SQL 中学习到当前应用场景所需的基础知识,并在面对复杂SQL 时通过对基础知识的重组得到正确的理解,即具备组合泛化能力。
虽然SQL-to-text 领域的研究已取得一定成果,但现有的数据集缺乏对模型组合泛化能力的考察,模型难以发挥其组合泛化能力。鉴于此,本文提出一种评估SQL-to-text 模型组合泛化能力的方法。该方法对现有数据集中的SQL 和相应的自然语言翻译(SQL-自然语言对)进行切分再组合,并按照生成的SQL-自然语言对所含SQL 子句的个数将其划分为训练数据与测试数据,以此达到评估模型组合泛化能力的目的。最终基于Spider[6]数据集创建SpiderCompose 数据集,选取序列到序列、树到序列、图到序列3 种类型的SQL-to-text 模型进行实验,对比模型的组合泛化能力强弱,并对模型的翻译错误进行分析。
1 相关工作
1.1 组合泛化数据集
文献[7]于2018 年提出了组合泛化数据集SCAN(Simplified version of the CommAI Navigation tasks)。该数据集包含一组简单的导航命令以及对应的动作序列,模型的学习目标是将简洁描述的命令翻译成表示动作的序列。文献[8]于2020 年提出COGS(COmpositional Generalization challenge based on Semantic interpretation)数据集。该数据集的任务是将英文句子通过语义解析映射成逻辑形式。文献[9]提出DBCA(Distribution-Based Compositionality Assessment)方法,并用此方法构造出 CFQ(Compositional Freebase Questions)数据集。它为每个问题提供针对Freebase 知识库[10]的相应查询。文献[11]则对组合泛化进行更细致的定义与分类,并提出PCFG(Probabilistic Context Free Grammar)数据集,其任务是在输入序列上递归应用字符串编辑函数,得到输出序列。
1.2 SQL-to-text 数据集
由于SQL-to-text 与text-to-SQL 领域的数据集主要内容都是SQL-自然语言对,因此两个领域的研究可以共用数据集。目前text-to-SQL 领域的数据集主要包括ATIS[12-13]、GeoQuery[14]、Restaurants[15-16]、Scholar[17]、Academic[18]、Advising[19]、WikiSQL[20]、Spider[6]等。由 于WikiSQL 和Spider 数据集 规模较大,SQL-to-text 领域一般使用这两个数据集进行研究。
2 方法框架
SQL-to-text 任务的输入是一个SQL 和SQL 所属的数据库相关信息,输出是一个自然语言翻译。为评估SQL-to-text 模型的组合泛化能力,需要改变已有的SQL-to-text 数据集,使其测试数据中的组合泛化基本单元(SQL 子句)皆以不同的组合方式在训练数据中出现。
图1 所示为提出SQL-to-text 模型组合泛化能力评估方法的整体框架,主要分为3 个部分,包含了4 个主要步骤。数据转化是评估方法的核心部分,负责输入的数据集,构造出一个能够评估SQL-to-text模型组合泛化能力的新数据集,其核心思路是将现有的数据集中的SQL 与自然语言进行切分再组合,得到新数据集中的SQL-自然语言对,再通过数据划分操作分出用于训练和测试的数据。模型训练及能力评估是方法的重要部分,此部分基于数据转化部分创建出的新数据集用于评估的SQL-to-text 模型,并基于新数据集对模型进行能力评估,得到最终的模型组合泛化能力评估结果。
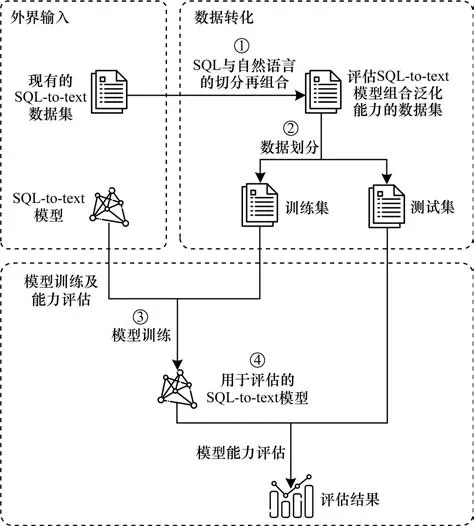
图1 SQL-to-text 模型组合泛化能力评估方法整体框架Fig.1 Overall framework of compositional generalization ability evaluation method for SQL-to-text models
3 SQL 与自然语言的切分再组合
为使现有的SQL-to-text 数据集转化为能够评估模型组合泛化能力的新数据集,评估方法先对现有数据集中的SQL 与自然语言进行切分再组合。为方便说明,使用Spider 数据集中的一个SQL-自然语言对作为输入,对此步骤内的具体操作进行详细介绍。
SQL:SELECT first_name,last_name FROM players WHERE hand=‘L’ ORDER BY birth_date。
自然语言翻译:What are the full names of all left handed players in the order of birth date。
3.1 SQL 子句切分
由于组合泛化考察的是以一种与训练不同的方式组合基本单元时模型能否理解其含义,因此需要对任务中的基本单元进行定义。本文将SQL-to-text任务中组合泛化的基本单元定义为按SELECT、WHERE、GROUP BY、ORDER BY、INTERSECT、UNION、EXCEPT 关键字切分SQL 得到的子句,称为SQL 子句。其中,查询连接和嵌套子查询不会额外切分SQL 子句,如此设置的原因是:自然语言比SQL 更加凝练,往往一句话就能够表达出整句SQL的含义,如果更细地划分SQL 子句,将导致自然语言片段难以切分。为了与其他SQL 关键字进行区分,将用于SQL 子句切分的关键字称为顶层关键字。表1 所示为切分后SQL 子句的类型及示例。
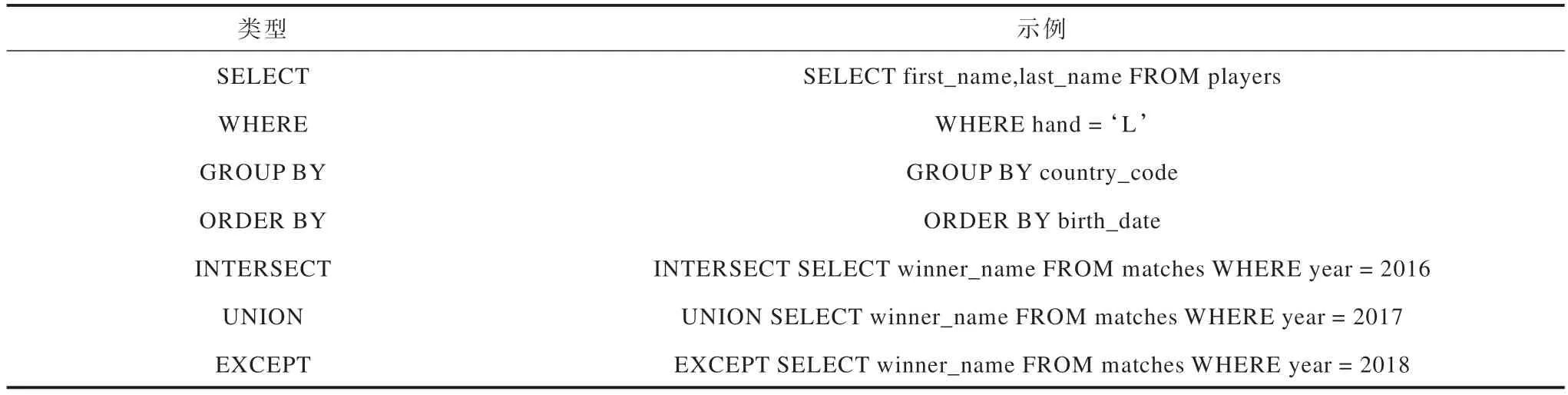
表1 SQL 子句的类型及示例Table 1 Types and examples of SQL clauses
对SQL-to-text 任务中组合泛化的基本单元进行定义后,即可完成对SQL 的切分操作。以上述SQL为例,使用SELECT、WHERE 和ORDER BY 3 个顶层关键字将其切分为SELECT first_name,last_name FROM players、WHERE hand=‘L’以及ORDER BY birth_date 3 个子句。SQL-to-text 模型在测试时将面临与训练时不同的SQL 子句的组合。
3.2 自然语言片段到SQL 子句对齐
为了确定训练及测试时的正确翻译结果,将SQL 切分为SQL 子句,在得到组合泛化的基本单元后,需要将自然语言也切分为与SQL 子句语义相符的片段,即令自然语言片段对齐到SQL 子句。表2所示为自然语言片段到SQL 子句对齐的示例,示例中的自然语言被切分为3 个片段,每个自然语言片段都与一个SQL 子句语义相符。
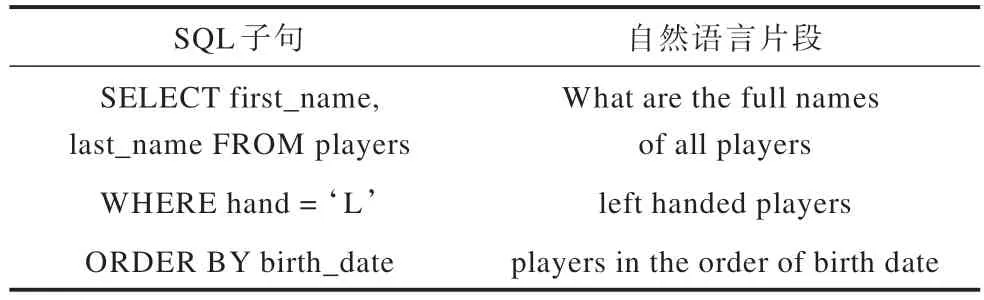
表2 自然语言片段到SQL 子句对齐的示例Table 2 Examples of aligning natural language fragments to SQL clauses
由于自然语言比SQL 更加凝练,往往一句话表达出整句SQL 的含义,因此自然语言比SQL 的切分更为复杂,并且切分出的自然语言片段可能存在重叠的部分。例如,表2 中的players 一词既属于SELECT 子句对应片段,又属于WHERE 和ORDER BY 子句对应片段。在一些情况下,即使采取人工切分的方式仍难以得到与SQL 子句一一对应的自然语言片段。
自然语言片段到SQL 子句对齐是SQL 与自然语言的切分再组合过程中的主要难点。此操作有2 种实现手段:通过启发式规则进行切分与借助神经网络模型进行切分。由于此领域缺乏自然语言切分模型所需的数据集,因此选择使用启发式规则进行此操作,具体可细分为关键字标注和自然语言单词拼接两步。
3.2.1 关键字标注
图2 所示为关键字标注的一个示例。此操作是依据SQL 和数据库模式等相关信息,通过一系列规则对自然语言中的部分单词标注上对应SQL 中的顶层关键字,它是自然语言片段到SQL 子句对齐的基础。在图2 中,SQL 的SELECT 子句查询的是球员的全名,因此给自然语言中的names 和players 单词加上标注,表示这2 个单词与SELECT 子句有关。WHERE 子句则提到查询限定的是使用左手的球员,因此给自然语言中的left、handed、players 单词加上标注,表示这3 个单词与WHERE 子句有关。ORDER BY 子句则提到查询的球员是按照生日排序的,因此给players、birth、date 单词加上标注,表示这2 个单词与ORDER BY 子句有关。最后,观察到自然语言中的What 疑问代词一般对应SQL 的SELECT 子句,以及in the order of 词组一般对应SQL 的ORDER BY 子句,也为这些单词加上相应的标注。

图2 关键字标注示例Fig.2 Example of keyword tagging
由于顶层关键字与SQL 子句一一对应,因此关键字标注的本质是SQL 子句与自然语言单词的匹配。受文献[21-23]的启发,为了尽可能地缩小SQL与自然语言间的语义差距,首先从SQL 出发,为每个SQL 子句生成一个备选词集合,再使用SQL 子句对应的备选词集合与自然语言中的单词进行匹配,为匹配成功的单词标注上引导该SQL 子句的顶层关键字,最后再对标注的结果进行调整,目的是使最终得到的自然语言片段更优。
SQL 子句的备选词为:该SQL 子句若翻译为自然语言表达可能会使用到的词。SQL 子句的备选词集合中包含两类词:第1 类是与当前特定查询相关的词,例如SQL 子句涉及的表名、列名、取值等;第2 类是适用于所有场景的词,例如SQL 子句在自然语言中通常对应的疑问代词、连词等。要获取与当前特定查询相关的词,需要先对SQL 进行解析。在Spider 数据集中,每句SQL 都对应了一个名为SQL 的字典[6](下文简称为SQL 字典),该字典能够无歧义地表达SQL 的含义,因此能够从SQL 字典中提取出与当前特定查询相关的词,放入相应的SQL子句的备选词集合中。而要获取适用于所有场景的词,需要依靠对Spider 数据集中大量SQL 及自然语言的观察与归纳。例如:SELECT 子句一般对应自然语言中的疑问代词、与查询或返回相关的动词,WHERE 子句一般对应定语从句引导词以及表示条件的介词等。
为SQL 的每个子句生成备选词集合后,即可使用此集合与SQL 对应的自然语言中的单词进行匹配,为匹配成功的单词标注上引导该SQL 子句的顶层关键字。在进行匹配之前,需要先对单词进行预处理,将单词的时态、单复数、比较级、最高级等去除,只留下其主干部分,方便后续的匹配。例如将had 转为have,dogs 转为dog。
经过匹配后,自然语言中的部分单词被标注了一个或多个顶层关键字,但是标注的结果还能通过进一步调整达到更好的效果。基于对Spider 数据集和实际标注情况的观察,设置了一系列标注结果调整规则,设置规则的目的是减少关键字误标注并提高后续单词拼接得到的自然语言片段的连贯性。标注调整规则的具体示例如下:
若单词为when、where、which、who、why 其中之一,且不是句子中的第一个单词,当前一个词为and且SQL 的顶层关键字中没有INTERSECT 时,将and和此单词的标注设置为只有SELECT;当前一个词是名词时,将此单词的SELECT 标注去除。此规则的目的是尽可能地减少疑问代词上的多重标注情况,考虑到查询多个列以及疑问代词作为定语从句引导词2 种情况。查询多个列,例如:SELECT T1.emp_lname,T1.emp_hiredate FROM employee AS T1 JOIN professor AS T2 ON T1.emp_num=T2.emp_num WHERE T2.prof_office=“DRE 102”。对应的自然语言翻译为:What is the last name of the professor whose office is located in DRE 102,and when were they hired。在初步匹配后,when 的标注为 SELECT 和WHERE,经过规则的调整,when 的标注为SELECT。在自然语言翻译中使用疑问代词作为定语从句引导词,例如:What are the id of students who registered course 301。对 应SQL 为:SELECT student_id FROM student_course_attendance WHERE course_id=301。在初步 匹配后,who 的标注 为SELECT 和WHERE,经过规则的调 整,who 的标注为WHERE。
3.2.2 自然语言单词拼接
为自然语言翻译中的部分单词标注对应SQL 的顶层关键字后,即可依据标注对自然语言中的单词进行拼接,得到与SQL 子句语义相符的自然语言片段。此操作需要考虑:并非在每个单词上都带有标注,在部分单词上带有多个标注,同一种标注可能在句子中不连续。通过算法1 为一个SQL 子句生成自然语言片段,此算法的关键是依据关键字标注确定自然语言片段对应的单词位置区间。经过关键字标注后,自然语言翻译中的每个位置都标注了0 或多个顶层关键字,算法1 将这些分散的位置连接成区间,SQL 子句对应的自然语言片段正是由这些区间内的单词拼接而成。算法1 的输入为自然语言翻译中的单词、单词的标注以及引导当前SQL 子句的顶层关键字,输出为关键字对应的单词列表以及单词位置区间列表(方便后续自然语言片段的组合)。算法伪代码如下:
算法1自然语言单词拼接
算法1从左到右遍历自然语言翻译,找到第1 个标注有输入的关键字的位置,将其设置为区间的开头。从区间开头往右继续遍历,若某个位置上存在关键字标注,但不含输入的关键字,则将其定为区间的结尾。由于关键字对应的位置区间可能不止一个,因此还需继续向右遍历,重复上述方法寻找新的区间。若遍历结束后当前区间只有开头没有结尾,则将其结尾定为自然语言翻译的结尾,得到最后一个区间。假设一个SQL 对应的自然语言翻译中有N个词,则算法1 的时间复杂度为O(N)。
3.3 SQL 子句和自然语言片段组合
将SQL 切分为SQL 子句,即得到组合泛化的基本单元后,便能得出基本单元的多种组合,作为模型需要翻译的内容。如表3 的第1 列所示,将切分出的SQL 子句进行拼接组合即可得到多种组合结果。为保证组合结果的合理性,并避免人工书写新的自然语言翻译,仅对来自同一个SQL 的子句进行组合。以Spider 数据集中的SQL 为例,若对来自SELECT avg(age),min(age),max(age)FROM singer WHERE country=“France”以 及SELECT DISTINCT country FROM singer WHERE age >20 中 的SQL 子句进行组合,可得到SELECT avg(age),min(age),max(age)FROM singer WHERE age >20 以 及SELECT DISTINCT country FROM singer WHERE country=“France”。在此情况下,第1 个SQL 虽然符合语法,但是没有实际意义,2 个SQL 都需要人工书写新的自然语言翻译。相比在同一SQL 内进行SQL子句的组合,能避免为组合出的SQL 人工书写对应的自然语言翻译,且更容易组合出具有实际意义的SQL。这些SQL 子句的组合结果即为模型需要翻译的内容。

表3 SQL 子句和自然语言片段的组合示例Table 3 Examples of combinations of SQL clauses and natural language fragments
确定了模型需要翻译的内容后,还需要确定正确的翻译结果。因此,在组合SQL 子句时还需要将SQL 子句所对应的自然语言片段以相同方式进行拼接组合。表3 的第2 列展示了与第1 列相对应的自然语言片段的组合结果。由于仅对来自同一个SQL 的子句进行组合,因此也只对来自同一个翻译结果的自然语言片段进行组合,保证自然语言片段组合结果的合理性。需要注意的是,一些自然语言片段间存在重叠部分,例如从表3 可以看出,SELECT 子句和WHERE 子句对应的两个自然语言片段都含有players 一词,需避免在组合的结果中重复出现。
得到SQL 子句的组合及对应的自然语言片段的组合后,就确定了模型需要翻译的内容及相应的正确翻译结果。如表3 所示,第1 列是模型需要翻译的内容,第2 列是正确的翻译结果,由一个翻译内容和其翻译结果构成的一组数据为一个SQL-自然语言对,是SQL-to-text 模型组合泛化能力评估数据集的主要组成成分。
4 数据划分
通过对SQL 与自然语言的切分再组合,得到了大量的SQL-自然语言对,为评估SQL-to-text 模型的组合泛化能力,按SQL-自然语言对中含有的SQL 子句个数对数据进行划分,得到用于模型训练和测试的两种数据。如表4 所示,令SQL 子句个数小于3 的数据作为模型的训练数据,令SQL 子句个数大于等于3 的数据作为模型的测试数据。
数据划分后,组成测试数据的SQL 子句会以不同的组合方式在训练数据中出现,采用这种数据划分方式可以得知,当训练时学习的知识以不同方式组合后,模型是否仍能理解其含义,即模型是否具有组合泛化能力。并且,模型测试时需要翻译的内容与训练时相比,SQL 子句个数更多,普遍长度更长且复杂度更高,此设置更加贴近SQL-to-text 模型的实际应用场景,也更符合研究SQL-to-text 模型组合泛化能力的初衷。
通过对SQL 与自然语言的切分再组合得到大量的SQL-自然语言对,再按所含的SQL 子句个数对数据进行划分,便完成了评估方法的数据转化部分,创建出了用于评估SQL-to-text 模型组合泛化能力的新数据集。
5 实验与结果分析
5.1 实验设置
5.1.1 对比方法
对比方法主要有以下2 种:
1)Template 方法[19]。此方法将SQL 中的地名、人名、数字等内容进行匿名化处理,得到SQL 对应的查询模板,并按模板划分训练数据与测试数据,使同一模板对应的SQL 只能同时出现在训练数据或测试数据中。
2)TMCD 方法[24]。此方法将SQL 中的单词视为组合泛化的基本单元,保证每个单元至少在训练数据中出现一次,并使训练与测试数据中的分布差异尽可能大。
5.1.2 参与评估的SQL-to-text 模型
根据目前SQL-to-text 以及组合泛化领域的研究工作,选择对文献[3]在研究中所使用的SQL-to-text模型进行组合泛化能力的评估,并沿用了该研究使用的模型名称。这些模型都是编码器-解码器架构的模型,涵盖了序列到序列、树到序列、图到序列3 大类型,是SQL-to-text 领域常用的神经网络模型。由于这些模型都使用了基于注意力机制的长短期记忆(LSTM)模型[25]作为解码器,因此按其使用的编码器类型命名。以下为参与评估的5 个模型:
1)BiLSTM:序列到序列模型。编码器为双向长短期记忆(BiLSTM)模型[26],输入为SQL 序列。
2)Transformer-Absolute position(ABS):序列到序列模型。编码器为使用绝对位置编码的Transformer 模型[27],为表述方便简称为ABS 模型,输入为SQL 序列。
3)Transformer-Relative position(REL):序列到序列模型。编码器为使用相对位置编码[28]的Transformer 模型,为表述方便简称为REL 模型。输入为SQL 序列。
4)TreeLSTM:树到序列模型。编码器为子结点的TreeLSTM 模型[29],输入为SQL 构造出的树。
5)RGT:图到序列模型。编码器为文献[3]提出的RGT 模型,输入为SQL 构造出的树。
5.1.3 数据集
根据提出的SQL-to-text 模型[30-31]组合泛化能力评估方法,基于Spider 数据集构造出评估SQL-totext 模型组合泛化能力的新数据集,将其命名为SpiderCompose 数据集。由于Spider 数据集的测试集未公开,输入数据来自Spider 训练集与验证集,训练集包含7 000 个SQL-自然语言对,验证集包含1 034 个SQL-自然语言对。为了评估模型的组合泛化能力,按SQL 子句的个数对数据进行划分,因此SpiderCompose 训练集包含了所有SQL 子句个数为1 和2 的数据,共有25 709 个SQL-自然语言对;验证集包含所有由Spider 训练集得到的SQL 子句个数为3 和4 的数据,共有1 584 个SQL-自然语言对;测试集包含所有由Spider 验证集得到的SQL 子句个数为3 和4 的数据,共有200 个SQL-自然语言对。
在此数据划分设置下,SpiderCompose 数据集与Spider 数据集具有不同的数据长度分布情况。表5和表6 分别展示了Spider 数据集和SpiderCompose数据集中SQL 和自然语言的长度分布情况。Spider数据集在设计时并未考虑到评估模型组合泛化能力的需求,其训练集和验证集具有相似的SQL 长度分布和自然语言长度分布。由于SpiderCompose 训练集中的SQL 包含1~2 个子句,而验证集和测试集中的SQL 包含3~4 个子句,因此训练集中的SQL 和自然语言普遍较短,而验证集和测试集中的SQL 和自然语言普遍较长。整体上SpiderCompose 数据集的训练集、验证集和测试集具有不同的SQL 和自然语言长度分布,这种分布更贴近模型的实际应用场景,符合评估模型组合泛化能力的需求[11]。
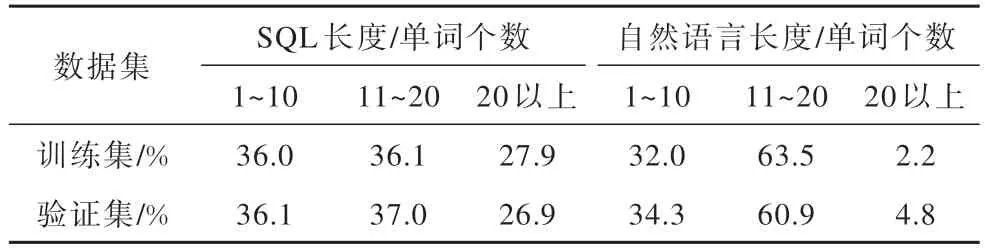
表5 Spider 数据集的SQL 和自然语言长度分布Table 5 SQL and natural language length distribution of Spider dataset

表6 SpiderCompose 数据集的SQL 和自然语言长度分布Table 6 SQL and natural language length distribution of SpiderCompose dataset
为了将本文提出的评估方法与Template 和TMCD 方法进行实验对比,使用文献[24]的开源代码将 Spider 数据集转化为 SpiderTemplate 和SpiderTMCD 数据集。表7 展示了SpiderTemplate 数据集中SQL 和自然语言的长度分布情况。由于Template 方法将查询模板随机地划分到数据集的不同部分,使其训练集、验证集、测试集具有相似的SQL 和自然语言长度分布。表 8 展示了SpiderTMCD 数据集中SQL 和自然语言的长度分布情况。由于TMCD 方法使训练数据和测试数据间的组合分布差异尽可能得大,其训练集、验证集和测试集具有不同的SQL 和自然语言长度分布,然而此方法未对数据的长度进行控制,导致验证集和测试集中的SQL 普遍较短,这种分布不符合SQL-to-text 模型的实际应用场景。
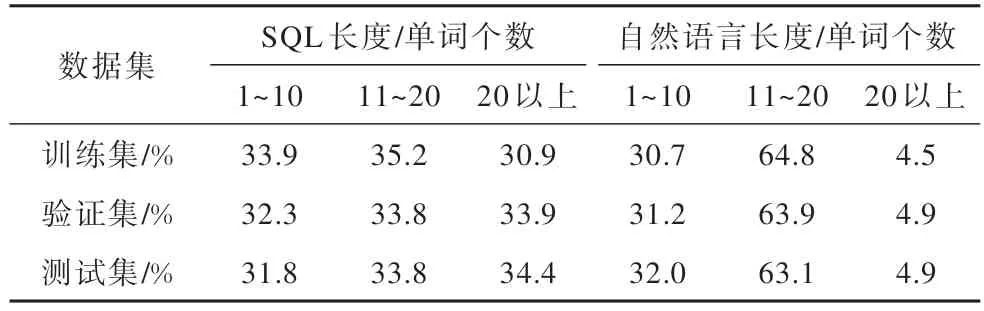
表7 SpiderTemplate数据集的SQL 和自然语言长度分布Table 7 SQL and natural language length distribution of SpiderTemplate dataset
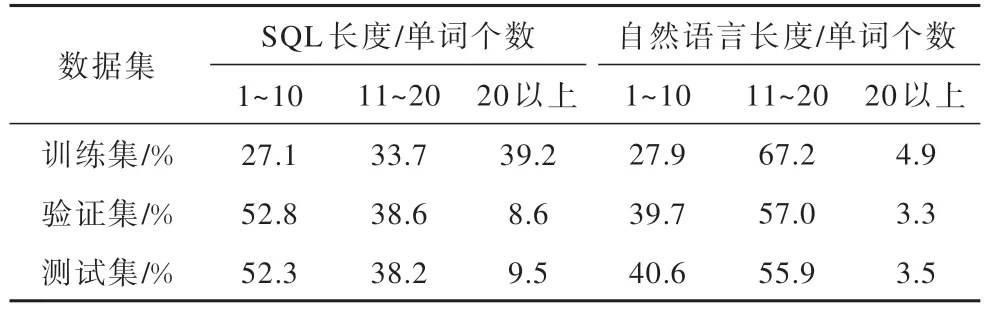
表8 SpiderTMCD 数据集的SQL 和自然语言长度分布Table 8 SQL and natural language length distribution of SpiderTMCD dataset
5.1.4 评估指标
模型的能力评估实验使用了BLEU-4 评分[32]、人工评分、完全匹配率3 种指标,并取平均值作为评估结果。
双语评估替补(BLEU)是目前常用的翻译模型自动评估方法。它采用N元组匹配的规则计算模型翻译结果与参考翻译结果之间的相似度,结果的值域范围是[0,1],值域越大表示模型的翻译质量越好。
由于BLEU 算法只计算精度而不关心召回率,并且仅从字符串匹配的角度评估模型的翻译质量,无法重点关注对语义影响程度较大的词,未考虑到同义表达的情况,因此加入了人工评分以弥补这些缺陷。
完全匹配率指模型翻译结果与数据集提供的参考翻译结果完全相同的比例,在计算时不会引入误差,能够较好地反映出模型提供完全正确的翻译的能力,是模型能否投入实际应用的关键指标。
5.2 结果分析
5.2.1 基于SpiderCompose 数据集的评估实验
使用SpiderCompose 测试集对5 个SQL-to-text模型的组合泛化能力进行评估。为得到更准确的评估结果,此部分包含2 组实验,在实验1 中模型能发挥其组合泛化能力,在实验2 中模型无法发挥其组合泛化能力。通过2 组实验排除模型其他翻译能力对评估结果的影响。
在实验1 中,5 个模型皆基于SpiderCompose 训练集进行学习,基于SpiderCompose 测试集进行评估,测试集中的SQL 子句皆以不同组合方式在训练集中出现,保证模型能够发挥其组合泛化能力。鉴于组合泛化能力仅为模型翻译能力的一部分,需要进一步确认实验1 中模型在测试集上提供正确翻译的原因以及其中依靠组合泛化能力的占比。因此,在实验2 中同样使用SpiderCompose 测试集对5 个模型进行评估,区别是去除了训练集中与测试集含有相同SQL 子句的SQL-自然语言对。在实验2 的设置下,SQL-to-text 模型无法发挥其组合泛化能力,它们为SQL 提供正确翻译依靠的是其他翻译能力。对比实验1 与实验2 的结果,即可进一步确认模型的组合泛化能力。表9 展示了实验1 和实验2 中5 个模型在SpiderCompose 测试集上翻译的BLEU-4 评分、人工评分和完全匹配率的平均值以及2 次实验结果的差值,使用此落差作为最终的组合泛化能力评估结果。
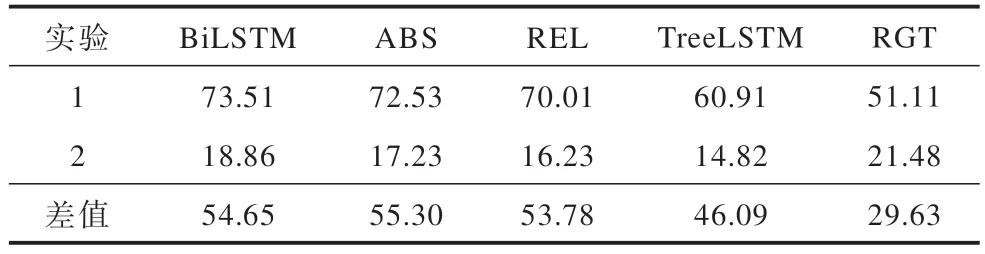
表9 基于SpiderCompose 数据集的评估结果Table 9 Evaluation results based on Spider Compose dataset %
如表9 所示,5 个模型在实验2 中的表现和实验1 相比都存在较大的落差。此结果反映出模型在SpiderCompose 测试集上提供正确翻译主要依靠其组合泛化能力,且模型组合泛化能力的发挥依赖于数据集的设置。在实验2 中所有模型的完全匹配率均为0,说明组合泛化能力在模型提供完全正确的翻译方面起到了重要作用,而能否提供完全正确的翻译对于模型能否投入正式的使用具有重要的影响。结合实验1 与实验2 的结果可知,ABS、BiLSTM、REL 3 个模型的组合泛化能力相对较高,RGT 模型的组合泛化能力最低,而它在实验2 中表现最好,说明现有的专为SQL-to-text 任务设计的模型(RGT 模型)虽具有较强的其他翻译能力,但其组合泛化能力仍有较大的提升空间。
5.2.2 基于多个数据集的评估对比实验
使用5 个SQL-to-text 模型在SpiderTemplate、SpiderTMCD、Spider 数据集上进行实验,与基于SpiderCompose 数据集的评估实验结果进行对比。其中,Spider 数据集并非为评估模型组合泛化能力而设计,其余3 个数据集则是为了评估模型组合泛化能力由Spider 数据集转化得到。表10 展示了5 个模型在4 个数据集上的评估结果。如表10 所示,4 个数据集上的评估结果并不一致,在总体上,SpiderCompose 数据集与SpiderTMCD 数据集上的模型表现排序较为接近,SpiderTemplate 数据集与Spider 数据集上的模型表现排序较为接近。
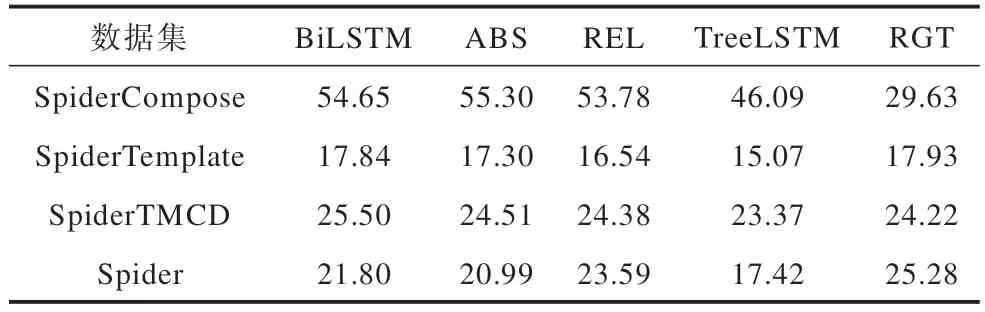
表10 5 个模型在4 个数据集上的评估结果对比Table 10 Comparison of evaluation results of five models on four datasets %
由于完全匹配率对于模型能否投入实际应用影响较大,表11 对5 个模型在4 个数据集上的完全匹配率进行了对比。如表11 所示,在SpiderCompose数据集上模型的完全匹配率远高于其他2 个数据集,其中在Spider 数据集上模型的完全匹配率都为0。受完全匹配率影响,在表10 中SpiderCompose 数据集上的模型总体表现也优于其他数据集上的模型总体表现。
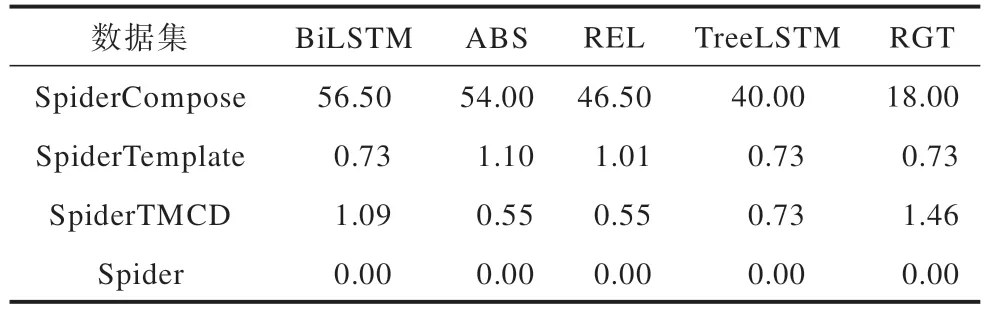
表11 5 个模型在4 个数据集上的完全匹配率对比Table 11 Comparison of perfect match rates of five models on four datasets %
以下对3 种组合泛化能力评估方法进行对比分析,说明结果存在差异的原因以及本文提出方法的优势。
首先,查询知识的使用程度不同。Template 和TMCD 方法提出时的初衷是评估text-to-SQL 模型的组合泛化能力,受此影响,Template 和TMCD 方法未使用到SQL 子句的概念,导致模型在SpiderTemplate和SpiderTMCD 数据集上无法学习到SQL 子句的含义,对查询相关知识的学习程度不足。虽然模型在SpiderTemplate 训练集中学习到了一些查询模板的含义,但难以从中学习到模板的每个组件的含义,导致模型难以泛化到其他查询模板。而TMCD 方法将SQL 包含的单词设置为组合的基本单元,未充分考虑到同一单词在不同的SQL 上下文中具有不同含义,使模型难以学习到完整的查询知识。本文所提的方法则通过SQL 与自然语言的切分再组合,显式地引导模型学习SQL 子句的含义以及子句间组合后的含义,帮助模型加深对SQL 结构和查询知识的理解,因此SpiderCompose 数据集上模型的翻译表现优于其他数据集。并且,模型翻译结果的完全匹配率取得了大幅的提升,为模型投入实际应用提供了启发。
其次,划分数据的方式不同。Template 方法首先提取出SQL 对应的查询模板,然后将属于同一查询模板的SQL 一起随机地划分到训练数据或测试数据中,虽然保证了训练数据与测试数据中的SQL 具有不同的组合方式,但随机划分无法保证两类数据间的关系。而本文方法依据SQL 子句的个数对数据进行划分,排除了随机划分带来的问题,不仅符合组合泛化的要求,而且贴近SQL-to-text 模型的实际应用场景。
最后,组合泛化能力对评估结果的影响不同。Template 和TMCD 方法未排除组合泛化能力以外的其他翻译能力对模型评估结果的影响,即无法确认模型提供正确翻译的原因中依靠组合泛化能力的占比,导致评估结果不够客观准确。相比之下,本文提出的方法不仅通过两组实验排除了模型其他翻译能力对结果的影响,得到了更为准确的组合泛化能力评估结果,而且通过对SQL 和自然语言的切分再组合保证了模型在训练时能够学习到所需的基础知识,不受来自原始数据集的限制,因此在基于SpiderCompose 数据集的实验中组合泛化能力对评估结果的影响较为明确。
综上所述,本文所提方法对查询知识的使用程度更高,划分数据的方式更加合理,得到的数据集更符合评估组合泛化能力的需求且更贴近模型的实际应用场景,受到原始数据集的限制程度更低,能使模型发挥出其组合泛化能力,得到的评估结果也更准确,并且为模型投入实际应用提供了启发。因此,与其他评估方法相比,本文提出的方法更具有优势。
6 结束语
本文主要对SQL-to-text 模型的组合泛化能力评估进行研究,分析组合泛化能力对于SQL-to-text 模型的重要性,提出一种评估SQL-to-text 模型组合泛化能力的方法,将Spider 数据集转化为能够评估模型组合泛化能力的SpiderCompose 数据集,并对SQL-to-text 模型进行组合泛化能力评估,弥补现有数据集对模型能力考察的不足。实验结果表明,本文评估方法优于Template 和TMCD 方法,且现有模型在组合泛化维度上仍有较大提升空间,对模型投入实际应用具有较大影响。后续将加强数据集对模型的引导,或对模型结构及训练方式进行改变,以提升SQL-to-text 模型的组合泛化能力。
猜你喜欢
四川师范大学学报(自然科学版)(2023年1期)2023-03-12 07:23:28
华人时刊(2022年1期)2022-04-26 13:39:28
计算机集成制造系统(2020年8期)2020-09-11 02:49:36
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
西夏学(2018年2期)2018-05-15 11:24:42
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
意林(绘英语)(2017年5期)2017-05-15 02:17:23
智能系统学报(2015年5期)2015-12-03 05:18:10
智能计算机与应用(2011年4期)2012-05-15 02:24:18
