
动态场景下基于语义分割的视觉SLAM 方法
2024-03-21 08:15:22杜晓英袁庆霓齐建友王晨杜飞龙任澳
计算机工程 2024年3期
杜晓英,袁庆霓,2,3,齐建友,王晨,杜飞龙,任澳
(1.贵州大学现代制造技术教育部重点实验室,贵州 贵阳 550025;2.贵州大学机械工程学院,贵州 贵阳 550025;3.贵州大学省部共建公共大数据国家重点实验室,贵州 贵阳 550025)
0 引言
同步定位与建图(SLAM)[1]能够在未知环境下完成地图的自主构建与定位,是工业机器人、自主导航、无人驾驶等应用中的基础技术之一。目前SLAM 采用的传感器主要是激光雷达、相机以及惯性测量单元(IMU)[2],视觉SLAM 是一种以相机作为传感器的SLAM,如ORB-SLAM2[3]、LSD-SLAM[4]、DSO[5]等视觉SLAM 方法。
研究视觉SLAM 在真实动态场景下的性能表现已成为SLAM 领域中的趋势,如张慧娟等[6]先计算获得变换矩阵,之后提取线特征,并对其进行静态权重的评估,最后通过余下的静态特征进行相机位姿估计完成跟踪任务。杨世强等[7]对传统SLAM 系统进行改进,提出一种基于几何约束的动态目标检测算法。DAI等[8]采用Delaunay 三角剖分方法为地图点建立与图类似的结构,以判断其邻接关系,之后,将多个关键帧之间观测不一样的边缘移除,最终,完成动态物和静态背景的分离。以上算法虽然可以提高动态环境下视觉SLAM 的鲁棒性,但是其构建的地图缺少丰富的语义信息。随着深度学习的发展和计算机性能的不断提高,目标检测与语义分割为解决动态环境下VSLAM 算法鲁棒性差的问题提供另1 种技术路线。YU等[9]提出DS-SLAM 算法,利用语义分割网络SegNet 和运动一致性检测方法剔除动态特征点。BESCOS等[10]采用实例分割网络Mask R-CNN 分割先验动态目标,并利用多视图结合方法检测潜在运动物。ZHONG等[11]采用目标检测方法SSD[12]检测帧中的动态物体,并对动态特征点进行运动概率传播,在跟踪线程中剔除动态点。XIAO等[13]同样使用SSD 检验先验运动物体,并通过选择性跟踪算法处理动态特征点。然而,无论是SegNet 还是Mask R-CNN[14]网络,都存在计算量大、运行时间长的问题。虽然语义分割可以检测动态物体,改善动态物体对SLAM 的影响,但是如何选择1 个精度高且实时性较好的语义分割网络完成动态特征点的检测,是动态SLAM 需要解决的首要问题。
1 算法框架
ORB-SLAM2 是1 个开源视觉SLAM 算法,因其良好的代码规范性与拓展性,被众多研究人员使用。ORB-SLAM2 主要组成部分为跟踪线程、建图线程、回环检测线程。本文以ORB-SLAM2 为基础框架,提出一种动态场景下基于语义分割的视觉SLAM 方法,具体内容包括:在视觉ORB-SLAM2 的RGB-D相机模式中,在原有的前端里程计、局部建图、回环检测3 个线程基础上,添加语义分割模块、动态特征点检测模块和构建语义八叉树地图的线程。视觉SLAM 总体框架如图1 所示。首先,RGB-D 相机获取的RGB 图像传入跟踪线程,在这个线程中采用ORB 方式提取图像特征,包含当前帧的关键点和描述子;然后,通过语义分割网络对RGB 图像进行像素级的语义分割,分割出具体的对象并筛选出运动对象,对动态点进行初步的去除,如行走的人等;最后,利用多视图几何检测并去除剩余动态物体,将剩余的静态特征用于位姿估计;最终,在语义地图构建线程中利用语义分割提取的语义信息生成点云地图并转换为八叉树地图。
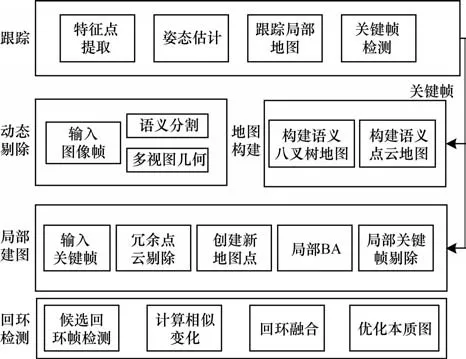
图1 视觉SLAM 总体框架Fig.1 Overall framework of visual SLAM
1.1 改进的DeepLabv3plus 语义分割网络
本文以DeepLabv3plus[15]为基础框架,设 计一种轻量化网络。首先,采用MobileNetV2[16]完成特征提取;然后,将深度可分离卷积应用到ASPP模块中;最后,在网络中插入SE 注意力机制[17]。图2 所示为本文改进的DeepLabv3plus 的网络结构,与原网络结构相比,主干网络选择MobileNetV2 代替原来的Xception[18],并采用迁移学习加载预训练模型,在ASPP 模块中使用深度可分离卷积,在保证分割精度的同时缩短运行时间。考虑到注意力机制能够自动调整网络中表现较好和表现较差的特征通道权重,本文还在网络中插入SE 注意力机制,使网络性能尽可能达到最佳,提升训练效果。
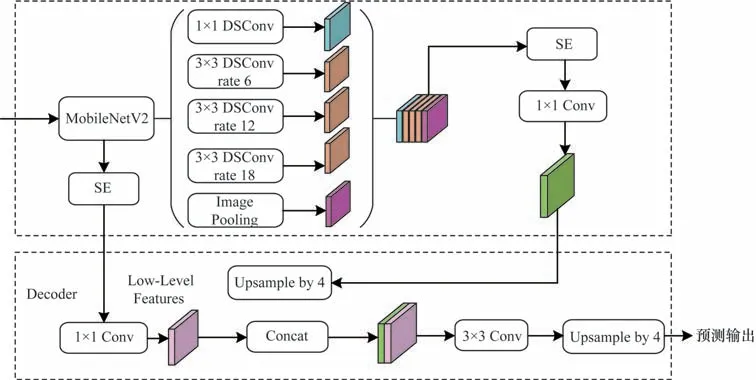
图2 改进的DeepLabv3plus 网络结构Fig.2 Structure of improved DeepLabv3plus network
1.2 多视图几何结合的动态点检测方法
研究人员利用语义分割网络只能检验先验运动目标对象(如人),忽略了椅子、书本等静态物体发生被动运动时对SLAM 产生的影响,如人们手中的书本或者人为推动的椅子等,应将其视为动态目标对象,却被视为静态对象,这将会对SLAM 产生较大影响。因此,本文进一步采用多视图几何方法进行动态特征点检测:将地图点云投影到当前帧,并利用视点差异和深度值变化大小将目标对象区分为动态目标和静态目标。多视图几何原理示意图如图3 所示,对于每个输入帧,选择多个之前与输入图像帧重合度较高的帧,把关键帧Kf中的关键点p投影到当前帧Cf,得到投影点p'和投影深度Dproj,每个关键点对应的3D 点是P,然后计算视差角α(p的反投影与p'之间形成的夹角α)。从TUM 数据集上的测试结果可以看出,当α>30°,可判断其为动态点。同时,本文还须计算深度值差ΔD=Dpro-jD',D'表示当前帧中关键点深度,若ΔD=0,该点被认为是静态的,若ΔD>0,则该点被认为是动态的。
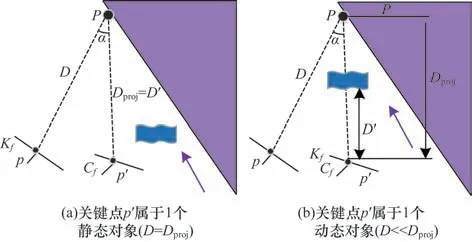
图3 多视图几何原理示意图Fig.3 Schematic diagram of multiview geometry principles
1.3 语义地图的构建
在语义地图构建线程中,借助PCL库[19],结合关键帧和深度图生成点云,利用当前帧的位姿及其点云进行点云后续处理,完成点云地图的构建,并在点云地图中进行语义信息的标注。然而点云地图虽然给人很直观的感觉,但是点云地图存在存储空间大、位置信息冗余以及不能直接用于导航等问题。与点云地图相比,八叉树地图[20]同样具有点云地图的直观性,但存储空间却远远小于点云地图,同时八叉树地图可以用于物流仓储机器人后续的路径规划,适用于各种导航算法,如A*、D*导航[21]算法。因此,本文对点云地图做进一步处理,将点云地图转换为八叉树地图,完成语义八叉树地图的构建。但是在建图过程中,因存在传感器的噪声和运动物体产生的误差,导致某个节点在每个时间点上状态都不一样。因此,本文选用概率方式说明某一节点被占据还是未被占据。假设使用x∈[0,1]进行说明,设x初始值为0.5,若该节点状态一直是被占据的,那么x值会不断增大,反之,该节点是未被占据的,那么x值会不断减小。若x出现不断增大或减小的情况,则会出现x值跳出[0,1]区间的情况,给数据处理带来不便。因此,采用概率对数值描述节点是否被占用,设y∈R(实数集)表示概率对数值,占用概率p的数值范围为[0,1],则logit 变换公式如下:
假设某节点n在T时刻的 观测概率是P(n|Z1∶T),Z表示观测数据,则其被占据的概率P(n|Z1∶T)表示:
其中:P(n)表示节点n被占据的先验概率;P(n|Z1∶T-1)表示n节点从起始到T-1 时刻的估计概率。本文将先验概率P(n)设为0.5,那么式(3)转换为概率对形式为L(n|Z1∶T),表示节点n从起始 到时间T的概率 对数值,则T+1 时刻观测概率如下:
其中:L(n|Z1∶T-1)与L(n|ZT)分别表示节点n在T时刻前和T时刻被占据的概率对数值。由式(4)可知,当某一节点被重复观测到被占据时,其概率对数值随之增加,否则减少。根据获得的信息,能动态调整该节点的占据概率,对八叉树地图不断进行更新。
2 实验结果与分析
实验搭配的平台配置如下:CPU 为AMD R7-4800H,GPU 型号为NVIDIA RTX3060,OS 为64 位Ubuntu 16.04 系统的笔记本。语义分割实验部分使用的软件配置:PyTorch 1.7.1,CUDA 11.0,CUDNN 8.0.5.39,Python 3.6,显存大小为16 GB。
作为Lumix系列相机的全新旗舰,这台无反相机使用了一块4700万像素的全画幅传感器,机内防抖系统以及60fps的4K视频拍摄能力,XQD+SD双储存卡的设置则保证了数据储存的安全性。S1R是松下与适马以及徕卡结成联盟(详见右页)之后发布的第一款产品,使用的镜头卡口为徕卡L卡口。
2.1 语义分割实验测试
改进后的DeepLabv3plus 在PASCAL Voc 数据集[22]上进行训练并验证。表1 所示为DeepLabv3plus与本文改进的语义分割算法的实验测试结果。从表1 可以看出,本文设计的语义分割模型的平均交并比为73.4%,模型大小为13.1 MB,时间约21 ms。

表1 不同模型的语义分割性能对比Table 1 Semantic segmentation performance comparison among different models
图4 所示为DeepLabv3plus 与改进后的语义分割模型的分割效果对比。从图4 可以看出,改进后的DeepLabv3plus 大致轮廓的分割结果与原模型相同,在分割对象细节方面存在微小差别,如图4 中的第2行图中2个人之间的间隙部分。相比DeepLabv3plus,改进后的DeepLabv3plus 模型大小减少约97%,单张图片运行时间缩短约89%。

图4 改进前后DeepLabv3plus 的分割结果对比Fig.4 Comparison of segmentation results of DeepLabv3plus before and after improvement
2.2 定位误差实验
本文将从TUM[23]数据集中选取高动态场景walking 序列共4 组序列进行定位误差实验。为了便于区分,本文用fr3、w、half分别代表freiburg3、walking、halfsphere,并将其作为序列名称。将本文算法分别与DS-SLAM、DLP-SLAM 以及ORB-SLAM2 进行比较,其中DLP-SLAM 是指以ORB-SLAM2 为基础框架,将DeepLabv3plus 算法与多视图几何相结合进行动态物体剔除的视觉SLAM。
本文以绝对轨迹误差(ATE)和相对位姿误差(RPE)[24]作为性能指标,分别计算其对应的均方根误差(RMSE)和标准差(SD)。RMSE 记录了估计值和真实值之间误差,其值越小,代表所估计的轨迹越接近真实轨迹。SD 代表轨迹估计的离散度。
表2 和表3 所示为本文算法与ORB-SLAM2、DLP-SLAM 以及DS-SLAM 算法在绝对轨迹误差和相对位姿误差方面的实验结果。从表2 和表3 可以看出:与传统ORB-SLAM2 相比,在高动态walking序列下,本文算法的绝对轨迹误差的RMSE 值和SD值最高分别提升98%和97%以上;本文算法相对位姿误差的RMSE 和SD 指标值提升幅度在52%~74%之间。与DLP-SLAM、DS-SLAM 相比,本文算法的绝对轨迹误差和相对位姿误差的RMSE 值也有所提升。

表2 不同算法的绝对轨迹误差对比结果Table 2 Comparison results of absolute trajectory errors among different algorithms

表3 不同算法的相对位姿误差平移部分的对比结果Table 3 Comparison results of relative pose error translation parts among different algorithms
图5 所示为在高动态fr3/w/rpy 序列中本文算法、ORB-SLAM2 以及DLP-SLAM在x、y、z轴上的位移估计值和真实值比较(彩色效果见《计算机工程》官网HTML 版),其中蓝色线条代表ORB-SLAM2,虚线代表实际值(ground truth)[25],橘色实线代表DLP-SLAM,绿色代表本文算法。
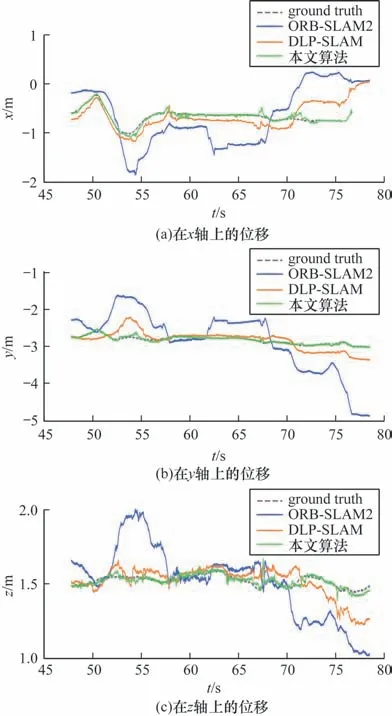
图5 不同算法在fr3/w/rpy 序列下的x、y、z 轴位移对比Fig.5 Comparison of x,y,and z-axis displacements among different algorithms in the fr3/w/rpy sequence
图6 所示为各算法姿态角估计值和真实值的比较(彩色效果见《计算机工程》官网HTML 版)。

图6 不同算法在fr3/w/rpy 序列下的姿态角对比Fig.6 Comparison of attitude angles among different algorithms in fr3/w/rpy sequences
从图5 和图6 可以看出,绿色实线和虚线几乎重合在一起,蓝色线条与虚线的距离最远,其误差最大,橘色实线与虚线之间也存在较小偏差。这表明无论是在x、y、z轴上的轨迹还是姿态角(yaw、pitch、roll)上的轨迹,与真实轨迹相比,ORB-SLAM2 生成的轨迹发生了较大幅度的漂移,DLP-SLAM 发生较小漂移,而本文算法生成的轨迹与真实值几乎重合。本文算法在动态场景下定位与建图的精度更加准确,鲁棒性更好。其原因为原有算法假设环境是静态的,而运动物体的存在会影响位姿估计的结果,甚至引起系统故障的发生。本文算法利用改进的DeepLabv3plus 以及多视图几何检测动态点,并剔除动态点,之后利用剔除掉动态点之后的静态点进行位姿估计,使获得的位姿估计更加准确,避免引起系统故障。
图7 分别所示为在高动态序列fr3/w/xyz 下ORBSLAM2、DLP-SLAM 及本文算法得到的相机运动轨迹与ground truth 之间的偏差(彩色效果见《计算机工程》官网HTML 版)。黑色线条代表ground truth,蓝色线条代表预测轨迹,红色线条代表相机预测轨迹与ground truth 之间的偏差,红色线条越短代表偏差越小。从图7 可以看出,本文算法运动轨迹图中红色线条最短,位姿估计更加准确,说明在动态环境下定位误差较小,能有效降低动态物体对VSLAM 的影响。
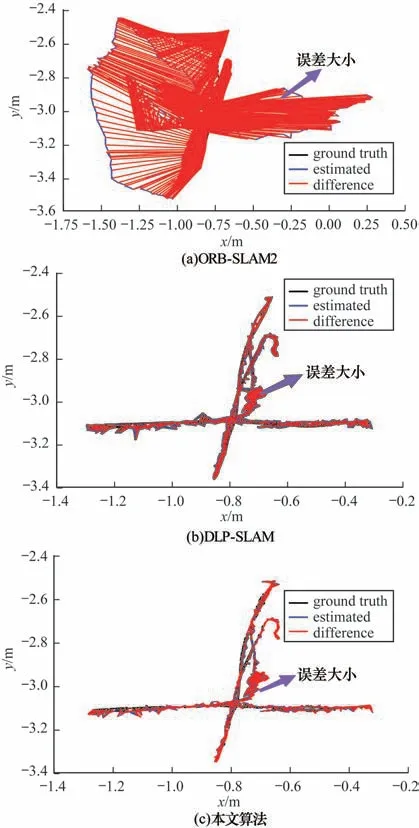
图7 不同算法在高动态序列fr3/w/xyz 下的轨迹Fig.7 Trajectories among different algorithms under high dynamic sequence fr3/w/xyz
为进一步说明本文算法的有效性,本文在实验室真实环境下进行实验验证。图8 所示为移动机器人的真实运动轨迹,边框表示移动机器人在真实环境中的实际运动轨迹。移动机器人平台利用搭载的KinectV2 相机[26]在搭建的实验环境中根据先前设计好的路线运动,并进行环境感知,记录环境数据。随后,在Ubuntu16.04 中,将获取的数据通过ROS 工具制作成TUM 数据集的格式,进而验证本文算法的有效性和可行性。

图8 移动机器人的真实运动轨迹Fig.8 Real motion trajectory of the mobile robot
图9 所示为本文算法在真实环境中的特征提取。从图9 可以看出,本文算法在进行特征提取时剔除掉了人和人手中物体共2 个动态物体。

图9 在真实场景下的特征提取Fig.9 Feature extraction in the real scene
图10 所示为本文算法和ORB-SLAM2 算法在真实环境下的三维轨迹对比。从图10 可以看出,由于实验场景中有运动物体,因此ORB-SLAM2 算法生成的轨迹与实际运动轨迹相比出现了较大幅度的波动,而本文算法生成的轨迹与实际运动轨迹基本相符,波动幅度较小。
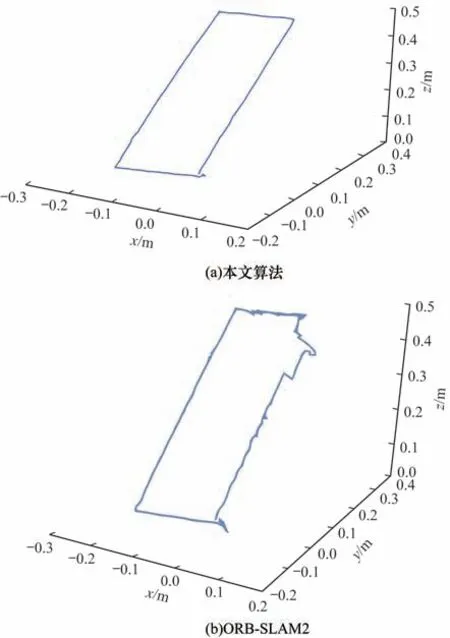
图10 本文算法和ORB-SLAM2 的三维轨迹对比Fig.10 Three-dimensional trajectory comparison between the proposed algorithm and ORB-SLAM2
2.3 建图测试
本文选取TUM 数据集中walking 序列的1 个子序列作为测试对象,如图11 所示,此序列中存在2 个不断运动的行人。

图11 fr3/w/static 子序列Fig.11 fr3/w/static subsequence
图12 所示为本文方法建立的地图(彩色效果见《计算机工程》官网HTML 版)。为了可视化,本文使用蓝色代表显示屏的像素,红色代表椅子的像素,其余像素使用物体本身颜色。从图12 可以看出,本文算法建立的语义地图中已剔除动态物体,不存在显著的动态物体如行走的人,说明较好地完成地图构建。从图12 中像素分布区域可以看出,显示屏中大部分像素得到了很好的语义赋予,但是椅子相对语义赋予较差。这是因为在PASCAL VOC 数据集上训练时,该数据集中的椅子和TUM 数据集中的椅子存在较大差异,因此本文算法没有得到较优的椅子分割结果。另外,为了说明八叉树地图所占内存空间小于点云地图,本文记录了fr3/w/xyz、fr3/w/static 序列构建的点云和八叉树地图所占内存大小,如表4 所示。

表4 不同序列的存储空间对比Table 4 Storage space comparison among different sequences 单位:MB

图12 本文算法生成的点云和八叉树地图Fig.12 Point cloud and octree maps generated by the proposed algorithm
3 结束语
本文提出动态场景下基于语义分割的视觉SLAM 算法。通过对DeepLabv3plus 进行改进,采用MobileNetV2 进行特征提取,对ASPP 模块进行修改,并引入SE 注意力机制,提高分割速度,通过改进后的DeepLabv3plus 和多视图几何方法检测动态特征点并剔除。实验结果表明,本文算法与ORBSLAM2 相比,运行时间延长,与DLP-SLAM 相比运行时间有所降低,并且其精度依然较高,利用语义信息生成静态的语义八叉树地图,节省了大量的存储空间,同时生成的地图可直接用于机器人的路径规划中。在去除动态特征点时因分割的不完整导致部分动态点未被识别,因此后续将选择分割精度更高的网络。
猜你喜欢
枣庄学院学报(2022年5期)2022-09-21 09:35:22
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:51
机械设计与制造工程(2013年4期)2013-09-12 03:23:04
