
基于对比学习的小样本金属表面损伤分类
2024-03-21 08:15:28吴冠荣李元祥王艺霖陆雨寒陈秀华
计算机工程 2024年3期
吴冠荣,李元祥,王艺霖,陆雨寒,陈秀华
(上海交通大学航空航天学院,上海 200240)
0 引言
对金属表面存在的损伤进行分类是金属类工业产品质量检验和反馈工作中不可或缺的一环,通常需要有专业知识的人借助电镜等器材进行判断[1]。但是损伤类型多、视觉疲劳、工业流水线的压力等因素容易影响主观判断,人工分类的准确率忽高忽低。随着机器视觉技术的发展,神经网络对视觉特征的强大学习能力可以弥补人工分类的不足。
基于机器学习的金属损伤分类按照是否使用初始化参数,分为迁移学习方法和深度学习方法。迁移学习方法希望从ImageNet 等大型训练集中学习到最通用的特征,在目标数据集上进行微调[2]。而深度学习方法通过调整模型参数来拟合当前数据的特征分布[3],或者通过加深模型层数,提高模型对多维特征的表达能力[4]。但金属损伤的纹理特征和常见的大型数据集差异很大,公开的预训练模型迁移效果有限,并且金属损伤种类繁多,一些偶发性、新产生的损伤不满足神经网络对训练数据量的需求,若直接使用神经网络进行有监督训练,模型易于过拟合、泛化性能差。因此,在很多应用场景下需要考虑小样本问题。
较早的小样本问题解决方案通常是学习合成伪数据[5]。这类方法依赖于扩充样本的质量,如果合成器效果一般,则容易引入噪声数据,效果有时不升反降[6]。目前,小样本分类研究聚焦于如何学习1 个更好的特征表示,使下游任务中即使只有少量标注信息,分类模型也能表现良好[7]。常见方法包括元学习框架[8-10]、度量学习[11-12]、知识蒸馏[13-14]等,目的都是为了找到更好构造特征空间的方式。ProtoNet[8]使用度量手段进行原型学习,由于其具有一定的灵活性和高效性,因此仍广泛应用在目前算法中。文献[9]在通用的两阶段微调训练机制基础上,增加了一步预训练,利用DINO 机制在额外的无标签数据上训练主干网络的特征提取能力,再在ProtoNet 上训练模型,实现了小样本分类任务的SOTA(State-Of-The-Art)效果。
文献[15]首先将小样本解决方案引入金属损伤分类,利用生成对抗网络(GAN)生成大量无标注的钢材表面损伤样本,在扩充样本量后,再用残差网络进行分类。文献[16]利用Wasserstein 距离的生成对抗网络(WGAN)有效扩充钢板气泡损伤,提高检测精度。然而,生成伪样本的方法容易模式固化,尤其对于金属表面损伤问题,金属材料种类多,损伤种类更多,这些方法仅扩充某种材料或某类损伤的数据量,因此算法的适用性不高。文献[17]针对铝材常见损伤类别各提取一种特征图CCMs,并利用注意力模块生成小样本类别的建议特征图(RCMs),对CCMs 和RCMs 进行映射和转化,分类结果由CCMs和RCMs 共同决定。该方法基于原型学习思路,将类内共性作为区分标准,预测时衡量当前样本与各个类别原型特征的相似度,最相似的类别作为分类结果,构造原型的范式在一定程度上缓解了模型泛化性差的问题。但是,金属损伤纹理细微、多变决定了特征分布的类间距离小、类内距离大,现有方法局限于在弱区分度的特征分布基础上根据类内共性完成分类,导致少样本、新类别分类精度低。
为此,本文提出一种基于对比学习的小样本金属表面损伤分类方法CLFS。该方法在元学习机制下,以外层模型对比、内层模型度量作为元任务,引入类别标签嵌入作为外模型对比不同类别图像特征的监督信号,使得在新的特征空间下,类内特征距离近,类间特征距离远,视觉特征相似的类别中心距离近。在金属损伤分类任务中,外模型对比学习代理任务可以间接使得原有特征空间中不同损伤类别之间的差异更加明显,从而增强了内模型的度量学习能力,有效提高分类精度;引入类别信息作为监督信号可以减少对比学习过程中样本噪声的影响,提高小样本原型向量估计的鲁棒性,从而提升对新类别的泛化能力。
1 小样本学习描述
关于小样本问题的任务设定,本文采用最常见的目标因子分析(TFA)数据划分方法(TFA-split)和全类别测试方案[18]。TFA-split 将数据集分为训练集和测试集:训练集选取具有较高资源的基础类别(Cbase),共Mb类;测试集包含训练集中未出现的新类别(Cnovel),新类别是低资源的小样本问题,新类别数共Mn类。TFA-split 在迭代过程中保持训练集和测试集固定不变。不同于仅测试Cnovel的狭义小样本问题,本文同时测试模型对Cbase和Cnovel的分类性能。
本文模型的训练采用元学习模式。元学习模式在训练过程中将传统的单个循环多批次的训练任务拆分成数个元任务。每个元任务目标一致、构成一致,从所有类别中选取K个类别,每个类别各选N个样本作为元任务输入。1个元任务又称K-wayN-shot任务,1 个元任务的工作周期为1 个episode。在训练过程中多次迭代元任务使得模型满足最终的小样本测试任务要求。元学习模式实现了从以数据为中心向以任务为中心的转变,从而减少对样本量的依赖,并提高小样本学习的性能。
本文根据资源高低将1 个金属损伤样本集按类别区分为Cbase和Cnovel,并将Cbase样本划分出训练集Dtrain和测试子集样本作为测试子集则测试集样本为由于所有样本需要被统一为元任务的输入格式,因此按照K-wayN-shot格式重构Dtrain和Dtest。
在训练阶段,每个元任务先从Cbase中抽取K(K≤Mb)个类别,针对抽出来的每个类别对应从Dtrain中抽取N张图片作为训练样本,称这K×N张样本为1个元任务的支持集S。对同样的K个类别再从Dtrain取N张不同的图片作为验证样本,称为1 个元任务的查询集Q。S和Q的类别相同、样本不同,合在一起作为1 个元任务的输入样本。元学习过程是指在每次元任务中利用S的信息对Q进行分类,从而更新模型参数。Dtrain被重构成m个元任务,即Dtrain=本文采用2 种常用的K、N设定,即5-way 5-shot 和5-way 1-shot。
在测试阶段,将Dtest按照K-wayN-sho(tK≤Mb+Mn)格式重构成多个元任务,模型在多个元任务上的平均分类性能即最后的性能。
2 网络架构
虽然元学习模式能够让模型快速适应新的任务,但是因金属损伤的类内方差大、类间相似度大等特性,使得很多小样本学习方法的效果明显下降。为提高模型的泛化能力,本文提出引入类别标签信息作为对比学习的监督信号。利用对比损失函数惩罚不同类别特征之间的距离,能有效地划分外模型特征空间的类间区域,间接优化内模型的特征分布,使得内模型在分类时可以不受无规律特征分布的影响。
2.1 训练模型
CLFS 分类模型在训练阶段分为内模型和外模型,内模型负责图像分类,外模型负责优化特征分布的代理任务,内外模型联合训练。图1 所示为在K-wayN-shot设定下CLFS 的网络架构,原始样本经过预处理分为图像输入和类别标签嵌入作为整个训练模型的输入信号。图1中Query set即所须训练的样本编码得到的向量集合。内模型主要包括利用ResNet 18的特征提取模块F和原型向量(包括支持向量和查询向量)生成模块。外模型除了与内模型共用的特征提取模块F之外,主要由类别标签嵌入、特征转译(特征编码和类别标签编码)和对比分支3个部分组成。

图1 在训练阶段K-way N-shot 设定下CLFS 的网络结构Fig.1 Structure of CLFS network with the K-way N-shot setting in the training phase
2.1.1 内模型
本文使用ResNet 18作为特征提取模块,ResNet 18由4层残差模块构成,选择特征层8倍下采样结果作为F的输出向量。支持集样本和训练集样本分别经过F映射得到支持向量和查询向量,以计算原型向量集,并采取度量学习的方式完成分类任务[8]。
元任务的内模型工作流程的输入为X:K×N张支持集图片;X':K×N张查询集图片,输出为K*查询集分类结果。工作流程如下:
1)第k类的N张支持集图片Xk经过特征提取模块F的投影后,形成支持向量子集Sk=F(Xk);
3)查询集图片X'经过特征提取模块F的投影后,形成查询向量集
4)根据S计算每个类别的原型向量
5)计算查询向量和每个原型向量之间的欧氏距离Dk=‖Q-ck‖2;
6)第i个查询向量qi距离最近的原型向量所代表的类别为qi对应查询图片分类结果
2.1.2 外模型
在训练阶段增加的外模型中,利用类别标签嵌入信息作为确定的类别中心,减少对比学习过程中样本噪声的影响,从而间接提高内模型原型向量估计的鲁棒性。
1)类别标签嵌入。CLFS 所用的3 个数据集标签如表1 所示。本文的类别标签嵌入流程:当前数据集的所有类别标签经过独热编码后,按照类别顺序存储为Hash 表,在每次元任务中对用到的类别进行Hash 映射,得到初始类别嵌入向量。

表1 数据集标签信息Table 1 Label information of datasets
2)特征转译。该部分包括2 个模块:(1)特征编码器,通过特征提取模块得到的结果向量在进入对比空间前也须经过1 层多层感知机(MLP)映射;(2)类别标签编码器,在预处理阶段嵌入的初始类别标签向量先经过1 层可学习的MLP 映射,再进行有监督对比学习。本文设计2 个特征转译模块主要是为了解决在对比学习中不同模态之间的差异性问题,提升对比特征空间的一致性,同时,构建辅助特征空间使得对比学习过程不影响内模型的度量空间。此外,在特征转译模块提供的新特征空间下,对比学习的动态性[22]让类别标签嵌入和图像特征互相影响。类别标签嵌入的结果作为类别中心监督特征分布,通过反传损失给特征编码器、特征提取模块逐步优化分类边界。图像特征信息通过反传给可学习的类别标签编码器,类别中心的分布位置可以继承视觉特征相似性。类别标签监督不同类别之间的特征分布情况如图2 所示。从图像纹理层面钢材油斑类别(oil_spot)和钢材夹杂物(inclusion)损伤类别相较于油斑和折痕(crease)更相似,则训练后油斑类别的特征分布更接近夹杂物而不是折痕。

图2 类别标签监督不同类别之间的特征分布情况Fig.2 Features distribution among different categories in category labels supervise
3)对比分支。对比学习过程结合2 个可学习的特征转译模块,在训练过程中拉近2 个新映射的特征空间距离,可以有效减小不同模态特征之间的差异。经过相同结构的特征转译模块,类别标签和图像2 种模态的特征被映射到同一空间,主要目标是在新的特征空间下,利用离散的类别标签先验信息对图像特征分布进行有监督对比学习,使得同类别的特征分布聚合性更好,不同类别的特征区分度更高。对比分支示意图如图3所示。
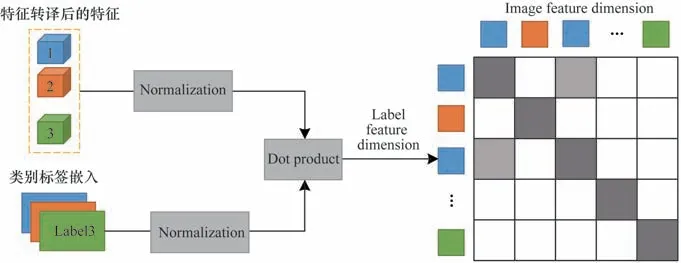
图3 对比分支示意图Fig.3 Schematic diagram of contrasting branches
在特征转译后的图像特征和类别标签嵌入经过归一化(Normalization)和点积(dot product)操作,得到余弦相似度矩阵。
2.1.3 损失函数
损失函数分为度量损失和对比损失,分别是内模型对小样本元任务分类结果的监督和外模型对特征分布情况的监督。
度量损失Ldistance是指在1 次元任务的训练过程中,携带真值的K×N张查询图片,经过特征提取形成查询向量集对于查询向量qi,计算其与对应真值类别原型之间的Softmax 负概率分布,即惩罚当前所得特征与真值类别的原型向量之间的距离[8]:
受SimCLR[22]的启发,本文选取余弦相似度作为转译后的图片特征和类别标签特征之间的对比损失Lcontrast。图3 中最终构成的余弦相似度矩阵分别从标签特征维度和图像特征维度惩罚同类别之间的距离,从而间接增大类间距离。假设1个episode由2N张样本组成,包括N张支持样本和N张查询样本,标准化后标签特征向量表示为vj,对应真值为。查询图片和支持图片所得到的标准化向量均表示为wi,对应真值为,l 表示当{}中条件为真时,则取值为1,反之为0。则1 个episode 的对比损失表达式如下:
其中:温度系数τ用来调节对比学习中的分类细粒度,τ越大,对不同样本间差异性的重视程度越高。
总的损失函数表达式如下:
通过一定的权重系数α将内外模型的损失函数进行统一,外模型的转译层参数由外模型对比损失单独更新,其他模块的可学习参数由整体损失函数共同优化。
2.2 预测模型
经过训练后,多模态对比学习模块加强了内模型对不同类别特征分布的区分能力,元学习模式也使得内模型提前适应小样本任务。因此测试阶段只需要内模型进行前向推理,不需要外模型进行监督和辅助。整个测试推理过程与训练阶段内模型的1 次前向传播步骤一致,1次K-wayN-shot 的全类别测试任务包括训练阶段未涉及的新类别Cnovel,体现了CLFS 小样本分类的泛化性能。预测模型架构如图4 所示。预测模型为训练模型的内模型,最终的分类结果k*由距离查询向量最近的原型向量的所属类别决定。
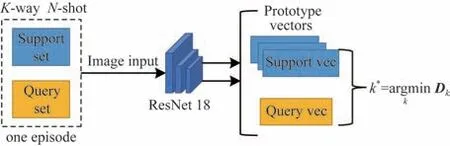
图4 预测模型架构Fig.4 Framework of prediction model
3 实验
3.1 数据集与实验设置
本文实验选取金属表面损伤常用的3 个数据集:GC10 钢板表面损伤数据集[19]、东北大学钢材损伤分类数据集(NEU)[20]、天池铝型材料表面损伤数据集(APSD)[21]。
GC10 数据集包括10 种类型的钢材表面缺陷,每个类别的样本数量不等,共3 570 张灰度图。由于从生产线统一采集,因此GC10 样本尺寸均为2 048×1 000 像素。NEU 数据集由东北大学机器视觉与机器人团队发布,包括6 类常见钢材表面损伤,每类有300 张灰度 图,尺寸固定为200×200 像素。APSD 数据集来自天池2018 铝材表面瑕疵识别比赛,本文选取其中9 个类别用于训练,每个类别的样本量从50 到200 不等,尺寸统一为256×256 像素。本文实验将原始RGB 图像统一转为灰度图。
为统一输入图像尺寸对骨干网络的影响,在预处理阶段将所有样本保持初始的长宽比压缩至150×150 像素左右,再用背景像素填充成方阵。CLFS 采用ResNet 18 作为图像特征提取层,1 层MLP 作为转译层,所有网络使用Adam 优化器,设定的初始学习率为0.001,每20 轮减小1 次学习率,设置对比损失中温度系数τ=2,度量损失占整体损失的权重α=0.2。
实验软件配置包括Python 3.8.10、PyTorch 1.7.0、OpenCV 4.6、Numpy 1.21,硬件平台为GPUNVIDIA GeForce RTX 3090 和CPU-Intel®Xeon®Platinum 8255C。
3.2 实验结果与分析
本文重复10 组对比实验,取所有分类精度结果的标准差作为偏差范围。所选取的比较对象不仅包括传统 的两阶 段微调(TFA)[23],而且包 括MatchingNet[24]、RelationNet[25]、ProtoNet[8]等主流 的小样本分类方法。同时,在全类别测试的基础上,通过混淆矩阵比较新类的分类性能,并进行特征分布可视化分析。
3.2.1 分类精度对比
CLFS 在5-way 5-shot 和5-way 1-shot 设定下,全类别测试的分类精度都得到了较大幅度的提升,如表2 所示,加粗表示最优数据。

表2 不同方法的分类精度比较(全类别测试)Table 2 Classification accuracy comparison among different methods(full category test)%
在5-way 5-shot 设定下,CLFS 的分类精度明显优 于TFA,而 且CLFS 比ProtoNet、MatchingNet、RelationNet 3 个主流小样本方法的分类精度至少提高了5.24、1.39 和6.37 个百分点(与次优结果比),分类错误下降率分别为36.00%、17.94%和66.15%。对于5-way 1-shot 设定,CLFS 相较于3 个主流小样本方法,分类精度提升效果更显著,分别至少提高8.34、3.01 和4.61 个百分点(与次优结果比),分类错误下降率分别为28.32%、23.37%和46.57%以上。
3.2.2 混淆矩阵分析
在GC10 数据集5-way 5-shot 下ProtoNet 与CLFS 分类混淆矩阵如图5 所示。前7 行(列)类别为此次实验中设置的Cbase,最后3 行(列)为小样本的Cnovel,混淆矩阵以行为单位包括真正例(TP)和假反例(FN)类结果,以列为单位包括TP 和假正例(FP)类结果。从全类别测试结果中可以看出,对于GC10 数据集,ProtoNet 不仅对Cnovel的分类效果较差,而且对Cbase漏报率和误报率也较高。CLFS 在同样情况下Cbase的FN 类、FP 类结果基本清零,即真值为Cbase的类别基本分类正确。特别地,CLFS 有效提高模型对小样本Cnovel的泛化性,相较于ProtoNet,Cnovel分类精度由36.53%大幅提升至69.12%。针对NEU 数据集和APSD 数据集,Cnovel分类精度分别由82.43%提升至91.57%,31.89%提升至48.23%。
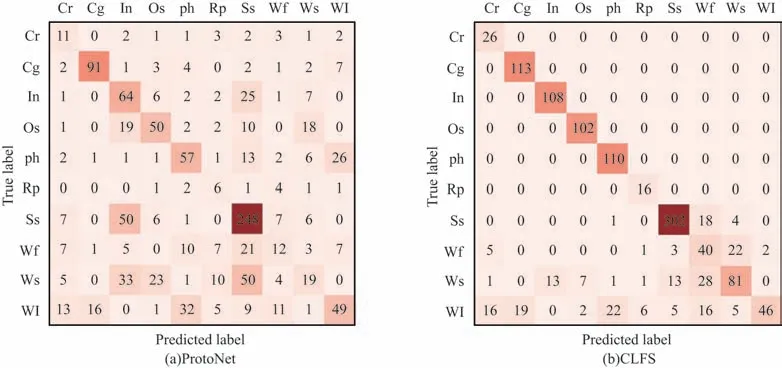
图5 在GC10 数据集上5-way 5-shot 下ProtoNet 与CLFS 分类混淆矩阵Fig.5 Classification confusion matrix for ProtoNet and CLFS in 5-way 5-shot on GC10 dataset
3.2.3 特征分布可视化
为动态监督特征分布,本文采取t-SNE 对统一Backbone 后的ProtoNet 和CLFS 的同一特征层进行降维映射。在GC10 数据集5-way 5-shot 下ProtoNet和CLFS 的特征分布对比如图6 所示(彩色效果见《计算机工程》官网HTML 版)。从图6(a)~图6(c)可以看出,ProtoNet 的特征分布中大多数类别的特征点互相穿插,Cbase和Cnovel都没有区分度。图6(d)~图6(f)所示为同样条件下CLFS 在测试过程中前向预测得到的特征分布,类别之间的间距明显、类内聚合度也显著提高。特别地,将Cbase和Cnovel分开分析,Cbase的特征边界清晰,类别分布的相邻关系保留了视觉特征的相似性。由于测试阶段才引入Cnovel,因此CLFS 模型对于Cbase和Cnovel之间的区分度下降,但是与图6(c)的Cnovel分布对比可以看出,CLFS 有效提高了类内聚合性。实验结果表明,CLFS 利用外模型双模态对比学习,有效地解决了类间相似性较高的金属损伤分类问题。

图6 在GC10 数据集5-way 5-shot 下ProtoNet 和CLFS 的特征分布对比Fig.6 Comparison of feature distribution between ProtoNet and CLFS under 5-way 5-shot for GC10 dataset
3.3 消融实验
为了分别验证对比学习和引入类别标签信息能否提升模型对小样本的分类能力,本文使用ProtoNet 作 为baseline,拆 分CLFS 的外模型为baseline+对比损失、baseline+标签嵌入,在3 个数据集上完成5-way 5-shot 的消融实验。
消融实验结果如表3 所示。加入对比损失和引入类别标签嵌入的方法相较于baseline 分别提升了1%~2%的分类精度,验证了对比损失项和类别标签嵌入的有效性。CLFS 所设计的外模型通过构造辅助特征空间,将对比损失和标签嵌入2 种方法组合,对分类效果有更显著的提升,单个数据集的分类精度相较于baseline 分别提升5.24、3.03 和14.00 个百分点,分类错误下降率分别为36.00%、32.27% 和81.11%。CLFS 的内外模型机制具有一定的有效性。
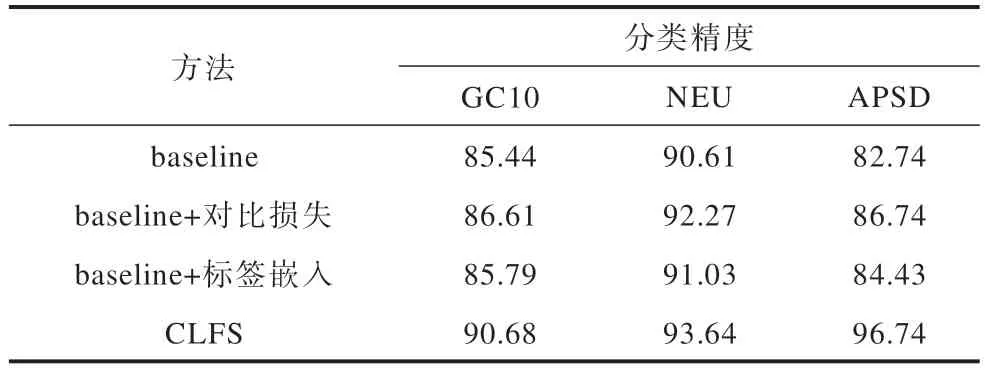
表3 消融实验结果Table 3 Results of ablation experiment %
3.4 超参数分析
CLFS 涉 及2 个超参数τ和α,GC10 数据集 在5-way 5-shot 设定下进行超参数分析,根据经验[22]确定超参数τ和α的取值范围分别为[0.1,1,2,5]和[0.1,0.2,0.5,2]。本文使用网格法对每组参数重复3 次实验。超参数对模型性能的影响如表4 所示,在合适的超参数范围内,分类性能对超参数的敏感度较低,超参数优化空间较为平缓,峰值处的误差范围更小,因此鲁棒性更好。从表4 可以看出,当τ=2、α=0.2 时,模型性能最佳。
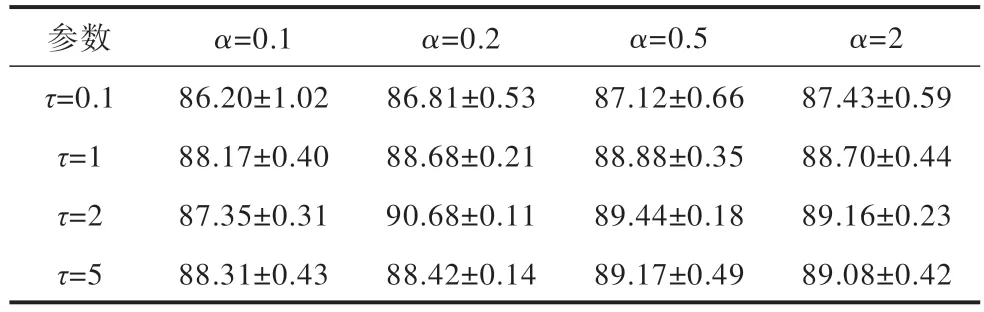
表4 超参数对模型性能的影响Table 4 The impact of hyperparameters on model performance %
4 结束语
针对小样本金属损伤特征分布聚合性低、新损伤类别泛化性差的问题,本文通过设计内外模型机制,提出一种基于对比学习的小样本金属表面损伤分类方法。内模型以传统度量学习为目标,完成小样本分类的任务;外模型构造辅助特征空间,在该空间下利用类别标签嵌入信息,动态对比不同类别的特征分布,从而实现聚合同类别特征,得到明确清晰的分类边界,提高模型对base 类别的分类精度,而且在较大程度上提升对novel 类别的泛化能力。在3 个常见的金属损伤数据集上验证本文方法的有效性,特征分布的可视化进一步展现了本文方法在增加类间距离、聚合类内特征的任务上具有显著的提升效果。目前,小样本金属损伤分类研究尚处于探索阶段,可参考的数据集和实验结果有限。本文仅初步探索了对比学习结合多模态优化特征分布在小样本分类算法方面的可行性,下一步将完善标签嵌入模型,便于从语义相似性角度补充小样本金属损伤的先验信息,进一步优化分类性能,同时使得结果具有可解释性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
公民与法治(2016年10期)2016-05-17 04:12:58
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新校长(2016年8期)2016-01-10 06:43:59
新高考·高二数学(2015年11期)2015-12-23 18:17:44
计算机工程(2015年8期)2015-07-03 12:20:27
商事法论集(2014年1期)2014-06-27 01:20:42
