
基于深度学习的炸点图像识别与处理方法
2024-03-11 11:11刘佳音李翰山张晓倩
探测与控制学报 2024年1期
刘佳音,李翰山,张晓倩
(1.西安工业大学兵器科学与技术学院,陕西 西安 710021;2.西安工业大学电子信息工程学院,陕西 西安 710021)
0 引言
随着实战化训练的不断深入,实弹射击训练不断贴近实战,其形成的炸点可用于估计击中敌方火力位置和评估炮兵射击训练效果等[1],因此,寻找一种可以实时准确识别炸点的方法,有助于验证武器系统的整体性能,而且对现代数字化战争具有重要意义。
当前炸点识别方法常用的有声测法、激光扫描法、雷达探测法和图像识别法。文献[2]利用声学测量设备求解连发弹丸落炸点,采用空域搜索算法求解弹丸的炸落点三维坐标,具有较好的求解效果。文献[3]针对声源被动测向的传统方法存在精度低和结构单一的问题,利用不规则排列声传感器接收到声信号的时间差,采用最小二乘原理计算声源方位。文献[4]针对弹目交会过程中难以精确控制炸点的问题,采用置于弹丸头部横向旋转扫描的线阵激光引信作为探测装置,并利用Monte-Carlo算法对弹目交会过程进行数学统计,计算分析破片数目和目标有效交会面积对目标毁伤的影响,最终确定引信最佳炸点。文献[5]研究了炸点和普通目标回波信号经动目标检测(MTD)处理后的特征,利用炸点目标与普通目标的多普勒分布差的区别进行目标识别,并取得了很好的效果。文献[6]提出采用基于定目标为参照的双面阵相机交汇摄像法来测量近炸引信对空中目标引炸的炸点位置,利用交汇相机的空间几何关系、图像处理技术与模拟目标实际尺寸,计算弹丸炸点相对模拟目标的空间三维坐标。文献[7]利用高速相机帧频高、布站方便、多镜头灵活更换的优点,提出基于高速相机的近地炸点三维坐标测试方法,利用莱卡定位系统实际测量炸点坐标进行误差分析。
声测法测试精度较低且易受噪声影响;激光扫描法投入成本较高且实时性差;雷达探测法耗费巨大且需要搭建庞大系统。而图像识别技术投入成本低,定位准确度高,且不受风力、风向、温度、地质条件等影响,因此利用图像识别技术准确捕捉炸点爆炸产生的火焰,从而准确识别炸点位置成为目前的研究热点。由于图像识别技术针对炸点位置的识别主要依赖于所检测到的炸点轮廓精确度,所以需要对爆炸火焰的外部轮廓进行高精度分割。
基于深度学习的语义分割算法主要采用深度神经网络对图像进行细粒度特征提取,并标记图像中每个像素点,分割出目标区域[8]。文献[8]针对炮兵对抗训练系统中炸点图像目标捕捉的问题,提出一种基于YOLACT 的炸点区域快速识别及分割方法,根据区域信息得到炸点中心坐标。文献[9]针对目前靶场炮弹火焰图像分割算法对火焰边界分割效果差而导致定位精度下降的问题,提出改进PSPNet的炮弹火焰分割PSP_FPT算法,实现对炮弹火焰目标的高精度分割。文献[10]为了实现炮口火焰与复杂背景环境的分离,引入深度可分卷积与残差结构,对U-Net语义分割模型进行优化。
上述基于深度学习的语义分割网络相较于传统方法具有更好的鲁棒性与泛化性,能够克服目标周围复杂环境以及光照强度的影响,但分割效果依赖网络层数。若层数过少,无法提取到更深层、更关键的分割特征信息;若层数过多,则容易增大网络运算量,造成过拟合。
因此提出一种改进的U-Net网络。将主干特征提取网络换为层数更深的ResNet50,且为了解决前景与背景类别不平衡问题,结合FocalLoss与DiceLoss函数,并采用自适应矩估计函数增加标签图像与分割图像之间的相似度,最终对改进U-Net网络进行训练和测试,获取最佳的网络性能,实现炸点图像分割及后续图像处理。
1 炸点图像获取及位置信息分析
本文采用高速摄像机对炸点爆炸过程进行拍摄,获得起爆时刻至爆炸结束的图像全过程,由于最终要获取炸点位置,而爆炸瞬间与爆炸后期所拍摄到的炸点图像对炸点位置的获取影响很大,因此要对拍摄的爆炸图像进行分类筛选。将炸点爆炸瞬间的几帧图像作为选取的目标,因为此刻拍摄的炸点图像受周围环境干扰较小,且炸点形状一般呈现扇形或不规则圆形,特征较为一致,能够准确地反映炸点位置;而当炸点爆炸一段时间后,由于受风向及炸点扩散等影响,相机拍摄的炸点图像会发生很大变化,若对此刻的炸点图像作后续图像处理,其获取的炸点位置偏差较大。GoogLeNet是基于Inception模块的深度神经网络模型,Inception模块将多个卷积与池化操作并列组成网络结构,在相同的计算量下提取更多的特征,提高网络训练效果。本文利用GoogLeNet对所拍摄的近景及远景多序列爆炸图像进行分类,首先将拍摄的炸点爆炸过程分为多帧图像处理;其次根据炸点爆炸瞬间形成的炸点形状特征进行图像分类,即将不包含炸点形状特征的图像定义为“未起爆”,将包含炸点形状特征的图像定义为“爆炸瞬间”,将包含炸点形状特征及烟尘特征的图像定义为“爆炸后期”;然后将已定义的多帧图像作为GoogLeNet网络的输入,对其训练并测试,最后得出分类结果。分类结果如图1、图2所示,网络训练后的分类准确率及损失如图3所示。

图1 近景场景下炸点图像分类结果Fig.1 Classification results of fried point images in close-up scenes

图2 远景场景下炸点图像分类结果Fig.2 Classification results of fried point images in long-range scenes

图3 网络分类准确率及损失Fig.3 Network classification accuracy and loss
根据GoogLeNet网络分类结果,提取“爆炸瞬间”炸点图像作为炸点位置信息获取的样本数据集。基于样本数据集,先利用改进U-Net分割网络对炸点图像进行分割,再采用边缘提取算法对分割出的炸点图像进行轮廓提取及最小二乘法轮廓拟合,获取图像中的炸点位置信息,最后采用摄像机成像原理将二维炸点坐标信息转换为三维炸点位置信息。假设图像中炸点的像素坐标为(u,v),图像坐标为(x,y),相机坐标为(X,Y,Z),空间坐标为(U,V,W),利用二维至三维坐标转换公式,将获取到的炸点图像二维坐标计算得出炸点空间坐标。
(1)
(2)
(3)
(4)
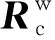

f=185 mm,Z=20 000 mm。
为了更加接近炸点空间真实坐标值,利用改进U-Net网络对样本数据集训练测试,提高炸点分割精度,获取更为准确的炸点二维坐标。
2 改进U-Net网络分割炸点图像模型的构建
面对炸点的复杂环境,本文利用ResNet50代替原网络中的特征提取网络,通过增加网络层数来提取更多的目标特征信息;为了解决图像分割中前景与背景类别不平衡问题,本文采用以焦点损失函数FocalLoss为主函数,DiceLoss为辅函数的多重损失函数优化网络模型;同时为了缩小实际输出值与样本真实值的差距,增加分割标签图像与分割图像之间的相似度,在反向传播更新权值参数阶段,选用自适应矩估计函数作为优化函数[11],动态地调整学习率,寻找最优权重参数。改进U-Net网络结构如图4所示。
2.1 改进主干特征提取网络
ResNet网络被广泛应用于各种特征提取场合中,深度学习网络层数越深,特征表达能力越强,但当深度达到一定程度后,分类性能不但不会提高,还会导致网络收敛更加缓慢,准确率也会降低,即使把数据集扩增,解决过拟合问题,网络的分类性能和准确度也不会提高[12],ResNet50网络层次结构如表1表示。

表1 ResNet50网络层次结构Tab.1 ResNet50 network hierarchy
由表1可知,ResNet50经过了4个Block,每一个Block中分别有3,4,6三个Bottleneck模块,每一个Bottleneck模块里包含两种Block。第一种是Conv Block,如图5(a)所示,通过1×1卷积核对特征图像先进行降维操作,再用3×3卷积核做一次卷积操作,最后通过1×1卷积核恢复图像维度,后续传入BN层与ReLu层,虚线处采用256个1×1的卷积网络,将maxpool的输出降维;另一种是Identity Block,如图5(b)所示,即用实线连接,不经过卷积网络降维操作,直接将输入加到最后的1×1卷积输出上,再经过后续的Block,进行平均池化操作和全连接操作,用Softmax实现回归。图像降维卷积处理过程如图6所示。

图5 结构图Fig.5 Structure diagram
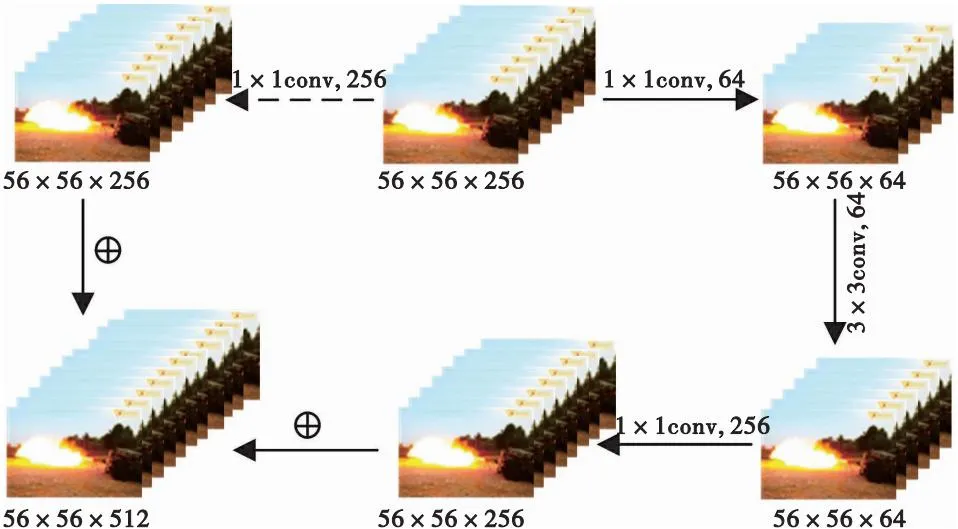
图6 图像降维卷积处理过程Fig.6 Image dimensionality reduction convolution processing
2.2 优化损失函数
在语义分割中存在大量前景与背景类别不平衡问题,使用单一损失函数往往趋向于捕捉炸点占比更大的样本,而炸点占比小、背景占比大的样本容易被损失函数过滤掉,为解决该问题,本文采用以焦点损失函数FocalLoss为主函数,DiceLoss为辅函数的多重损失函数优化网络模型。
DiceLoss是计算集合的相似度函数[13],用于监督实际输出值与样本真实值之间的相似度,数值越小越相似,预测效果越理想,使用 DiceLoss 可以在初期加快收敛,提升模型训练效率。同时采用以上两种损失函数监督网络,可以从不同角度捕捉预测过程中的不足和损失,在定位全局最优的结果下得到局部最优,提高泛化性。损失函数计算公式为
(5)
LFocal(pj)=-a(1-pj)γlog(pj),
(6)
LALL=LFocal(pj)+λ×LDice,
(7)
式中:|X|表示其标签值像素个数;|Y|表示预测值像素个数;|X∩Y|表示标签值和预测值交集的像素数;-log(pj)为初始交叉熵损失函数;a为类别区间(0或1二分类)的权重参数;(1-pj)γ为简单/困难样本调节因子;γ为聚焦参数[14];λ为经验参数,用于调节两个损失函数之间的权重。
为了减小损失函数数值,缩小实际输出值与样本真实值的差距,增加分割标签图像与分割图像之间的相似度,在反向传播更新权值参数阶段,选用自适应矩估计函数作为优化函数,利用梯度的一阶矩估计和二阶矩估计,动态地调整学习率,寻找到最优的权重参数,公式如式(8)—式(12)所示。
mt=μ×mt-1+(1-μ)×gt,
(8)
(9)
(10)
(11)
(12)
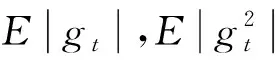
3 实验结果与分析
3.1 实验环境与参数设置
本文实验操作环境为Windows10系统,CPU参数为16 vCPU Intel(R) Xeon(R) Platinum 8350C CPU @ 2.60 GHz,42 GB内存,RTX 3080 Ti(12 GB)×1。网络框架基于PyTorch 1.10.0,Cuda 11.3,使用Python 3.8版本进行编程实现,网络初始参数设置如表2所示。
表2 网络初始参数Tab.2 Network initial parameters
3.2 炸点图像标签数据集的构建
本文利用Labelme软件对数据集进行轮廓标注,形成名称为boom的标签,并保存成json格式。以VOC2007数据集为格式标准,将json格式的数据转换为png格式的图片,单独保存至名为“SegmentationClass”的文件夹,同时将原始炸点数据集保存至名为“JPEGImages”的文件夹,确保后续进行网络训练的文件路径统一。利用Labelme软件标注标签示例图如图7所示。

图7 炸点标签图Fig.7 Fried point label
3.3 实验结果分析
3.3.1基于改进U-Net网络的图像分割结果评价指标
本文选用PA,MPA,MIOU三个评价指标来评估改进U-Net网络模型的性能。PA表示分类正确的像素占总像素的比例,PA值越高,说明分割结果越精确。MPA表示图像整体分割效果,MPA值越高,说明模型对所有类别的分割效果越好。MIOU表示整个图像中所有类别分割结果的平均质量,MIOU值越高,说明分割结果越准确。其计算公式为
(13)
(14)
(15)
式中:Nij代表真实值为i,被预测为j的数量;k代表分割类别数;Nii为真正,代表正确分为该类的像素数量;Nij为假正,表示他类被分为该类的像素数;Nji为假负,表示该类被误分为他类的像素数。式中先将背景和炸点分别作为正样本求出评价指标,再取平均值便可得到所有类的平均评价指标,式中正样本为炸点[15]。
3.3.2基于改进U-Net网络的图像分割结果
为了验证本文提出的改进U-Net分割网络在图像分割精度上有一定的提升,本文选用原始U-Net分割网络与U-Net+ResNet50,U-Net+优化函数以及改进U-Net网络进行测试,使用相同的炸点数据集和初始网络权重参数进行训练,然后对训练好的网络模型,用炸点原始图像进行对比验证,实验结果如图8所示。

图8 实验结果对比图Fig.8 Comparison of experimental results
由图8可以看出:原始U-Net网络对炸点的分割效果不够理想,对比标签图像会有毛刺出现;特征提取主干为ResNet50的U-Net网络,由于增加了网络层数,因此可以获得炸点更深层的细节信息,但对比标签图像,其相似度有所下降;加入优化函数后的U-Net网络,对比标签图像其分割效果相对较好,但所提取的图像信息仍有不足;改进U-Net网络融合上述两个改进点,对比标签图像,分割效果更好,有利于后续的目标边缘提取。其实验结果对比如表3所示。

表3 改进U-Net分割算法评价指标结果对比Tab.3 Comparison of evaluation indicators of improved U-Net segmentation algorithm
原U-Net的特征提取网络为VGG16,提取更深层次的细节特征需要增加网络层数,这会导致模型计算量大,因此本文选用ResNet50网络将其替换,通过加入残差模块连接输入与输出,缓解网络层数增多过程中的梯度消失问题。图9为ResNet50与VGG16对同一张图像分别进行特征提取的结果示意图。
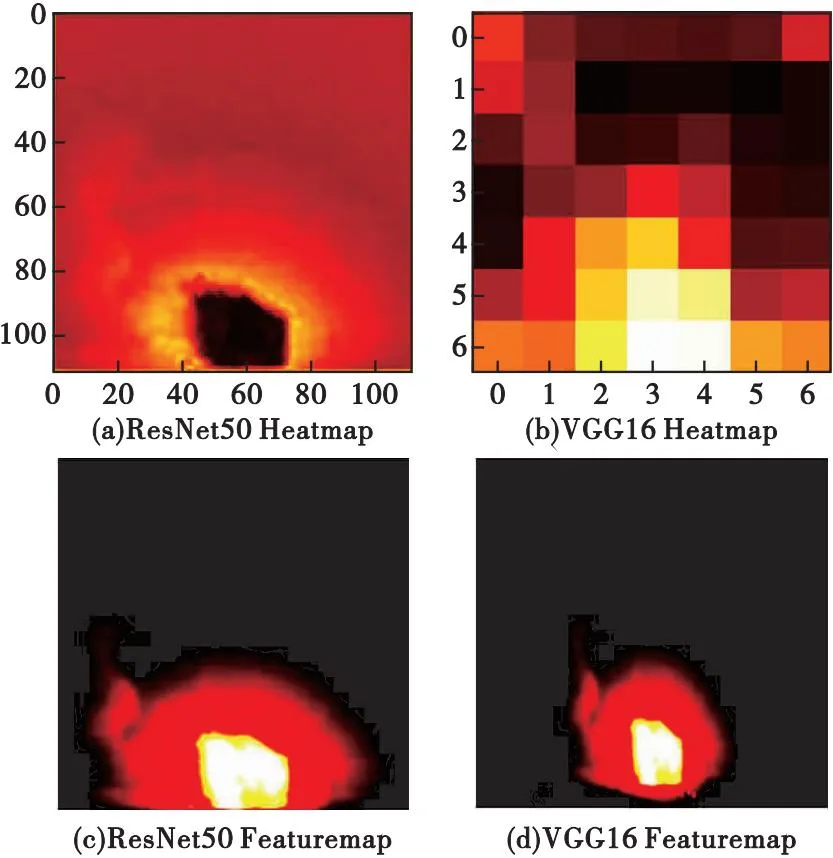
图9 特征提取示意图Fig.9 Feature extraction diagram
从图9可以看出,采用ResNet50主干特征提取网络的模型能够捕捉到更广泛的图像信息,提取出更加有细节的目标特征。
本文选用模型运行时间、模型计算量及模型体积大小三个指标作为网络模型优势评价标准,具体数值如表4所示。由表4分析得出,相比于原始VGG16主干特征提取网络,本文采用的ResNet50模型体积较大,但运行时间更短,计算量更少,同时结合表3,也可以反映出ResNet50模型的精度更高,因此可以证明ResNet50主干特征提取网络在增加网络层数的同时,能够提取到更深层图像特征信息,提升模型收敛速度。

表4 不同主干特征提取网络参量对比Tab.4 Comparison of networkparameters extracted from different backbone features
为了验证添加优化函数前后图像的相似度变化,以标签图像像素面积为判断标准,分别对U-Net原始网络、U-Net+ResNet50和U-Net+优化函数以及改进U-Net网络的图像分割结果与标签图像进行相似度计算,其结果如表5所示。
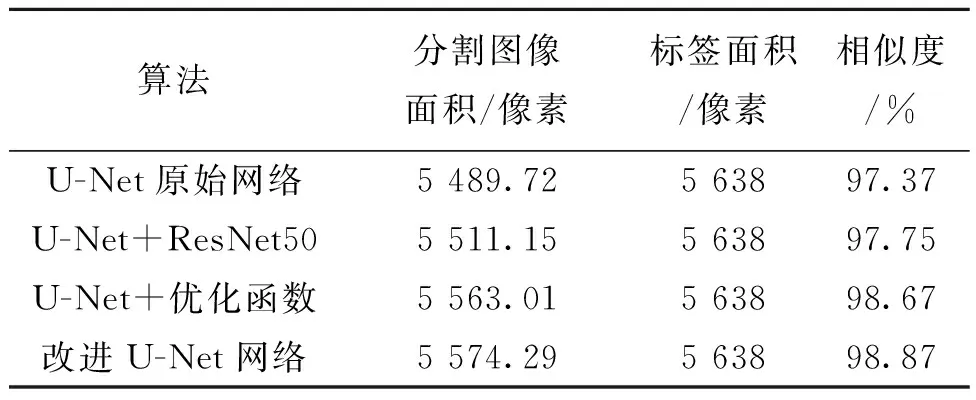
表5 各分割图像与标签图像相似度计算结果Tab.5 The similarity calculation result of each segmented image andthe label image
3.3.3炸点图像二维坐标到空间位置的转换
用已训练好的改进U-Net分割网络模型,对数据集中的炸点图像进行分割,采用Canny边缘轮廓提取算法提取炸点的边缘轮廓,Canny算法主要利用高斯函数对炸点图像进行平滑处理,再根据一阶微分处理后的炸点图像像素点的极大值来确定边缘点,之后使用最小二乘法轮廓拟合,获得轮廓中心及半径,根据摄像机成像原理求得炸点位置。具体步骤如下:
1) 利用GoogLeNet分类出的炸点图像数据集对改进U-Net网络进行训练并测试,获得分割图像;
2) 使用Canny边缘提取算法,对炸点分割图像进行边缘检测,并输出炸点边缘轮廓图像;
3) 使用最小二乘法进行轮廓拟合,获得轮廓中心及半径,并用轮廓中心y轴数值与半径求差,求得炸点像素坐标;
4) 根据摄像机成像原理转换炸点像素坐标,获取炸点空间坐标。
选用多张炸点图像,对其分别进行上述操作处理,处理结果如图10所示。

图10 炸点图像处理结果图Fig.10 Explosion point image processing result
将获取的像素坐标记为(u,v),代入第一章的坐标转换公式(1)—(4)中,计算炸点空间坐标(U,V,W),如表6所示。

表6 炸点空间坐标Tab.6 Bursting point in air coordinates
由图10可以看出,采用爆炸瞬间的炸点数据集训练改进U-Net网络,获得的分割图像精度更高,因此获取的炸点像素坐标更为准确,通过坐标转换关系,求出更加接近真实炸点位置的三维坐标,由此证明本文基于深度学习的炸点图像识别与处理方法可以对炸点目标实现位置获取及准确识别。
4 结论
本文首先利用GoogLeNet对高速摄像机拍摄的多序列爆炸图像进行分类,提取出爆炸瞬间的多帧图像,作为获取炸点位置信息的图像数据集;其次对U-Net分割网络进行改进,将特征提取主干网络替换为ResNet50,通过与VGG16作为主干特征提取网络对比,可知本文采用的ResNet50主干特征提取网络模型计算量更少,运行速度更快,结合FocalLoss与DiceLoss函数,并采用自适应矩估计函数作为优化函数,增加分割图像与标签图像的相似性,由计算结果可知,采用自适应矩估计函数作为优化函数的相似度结果为98.67%,比不加该优化函数的U-Net原始网络相似度结果高出1.30%,能够提高网络分割精度;然后采用Canny边缘提取算法对已分割的炸点图像进行轮廓提取,并采用最小二乘法轮廓拟合,获得轮廓中心及半径,对轮廓中心y轴数值与半径求差得到炸点像素坐标;最后利用摄像机成像原理将炸点二维坐标转换为三维坐标,获取炸点空间位置信息。
猜你喜欢
火控雷达技术(2023年1期)2023-04-07
装备制造技术(2020年1期)2020-12-25
兵器装备工程学报(2020年5期)2020-06-07
制造技术与机床(2019年11期)2019-12-04
成都信息工程大学学报(2019年6期)2019-08-13
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
计算机工程(2015年4期)2015-07-05
噪声与振动控制(2015年4期)2015-01-01
兵工学报(2012年1期)2012-02-22
