
基于DIGWO-VMD-CMPE的轴承故障识别方法*
2024-03-11 01:03鲁玉军朱轩逸
机电工程 2024年2期
辛 昊,鲁玉军,朱轩逸
(1.浙江理工大学 机械工程学院,浙江 杭州 310018;2.浙江理工大学 龙港研究院,浙江 温州 325802)
0 引 言
作为旋转机械中的关键部件,滚动轴承目前被广泛应用于各种机械设备中[1]。滚动轴承的失效可能会导致整个机械系统的损坏[2]。因此,在机械设备中,轴承的诊断识别研究显得尤其重要。
机械设备中的振动信号一般呈非线性,传统的特征提取方法对于这类信号不能做到有效提取。因此,任学平等人[3]采用经验模态分解(empirical mode decomposition, EMD)与AR谱对轴承振动信号进行了分解与故障特征提取;但EMD存在模态混叠和端点效应的问题。许凡等人[4]采用集合经验模式分解(ensemble empirical mode decomposition, EEMD)的方法分解了轴承振动信号,然后利用模糊熵计算熵值,并结合主要成分分析(principeconponents analysis, PCA)对数据进行了降维和可视化,最后使用Gath Geva(GG)聚类算法进行了故障识别;但EEMD依旧存在模态混叠的问题。为此,DRAGOMIRETSKIY K等人[5]提出了VMD算法,利用迭代求解来确定每个分量的中心频率及带宽,使解调到基带的信号是平滑的,并通过实验证明了在采样和噪声方面,该方法更具鲁棒性。张燕霞等人[6]提出了VMD-SVD的特征提取方法,并在双跨度转子故障模拟实验台上对其可行性和有效性进行了验证。
但以上模态分解均未考虑到算法中选取参数k和α的自适应性。
信号在不同工况下的复杂程度是不同的,通常需要使用基于熵值的非线性分析方法对其进行处理。如离散熵(dispersion entropy,DE)[7]、模糊熵(fuzzy entropy,FE)[8]和排列熵(permutation entropy,PE)[9]等都被广泛应用。以上算法虽能较好地描述振动信号的幅值大小和类别;但都只考虑了原始信号的单一尺度,未能全面地描述信号的内部规律。因此,研究人员对熵值进行多尺度粗粒化处理,提出了多尺度熵值算法。
陈东宁等人[10]采用快速变分模态分解和参数优化多尺度排列熵(multiscale permutation entropy, MPE)提取故障特征,并通过Gustafson Kessel(GK)模糊聚类的择近原则进行了故障的分类识别;但MPE无法提取到信号的高频信息。周付明等人[11]通过快速样本熵结合改进的多尺度拓展方法构建了特征样本,避免了幅值信息的丢失,并利用SVM分类器进行了故障诊断。王贡献等人[12]提出了一种基于多尺度均值排列熵(multiscale mean permutation entropy, MMPE)的方法,进行了故障特征提取,并将其输入GWO-SVM分类器中,进行了轴承故障的识别;但嵌入维度M对MMPE的特征提取能力影响较大,造成重构向量信息不足。
针对上述问题,笔者提出一种基于自适应消噪算法和复合多尺度排列熵的滚动轴承故障识别方法。首先,利用DIGWO算法的自适应性优化VMD分解以实现信号的消噪;然后,采用CMPE方法提取故障特征的熵值,构建故障特征向量;最后,利用DIGWO算法优化SVM的参数,构建DIGWO-SVM分类模型,对滚动轴承的不同故障进行诊断和识别。
1 相关理论
1.1 灰狼优化算法
因具有参数量少、寻优能力强等优点,灰狼优化算法(grey wolf optimizer, GWO)被广泛应用于模型优化、路径寻优及车间调度等方面。它源于模拟狼群跟踪、围捕、攻击猎物的行为,依照适应度的高低将狼群分为α、β、δ、ω四个等级,前三者对猎物进行追捕,ω跟随围捕。
在其捕食过程中,目标猎物的位置表示空间内的最优解,其个体与猎物之间的距离如下式所示:
D=|C·Xprey(t)-Xi(t)|
(1)
而狼群中每匹狼的位置代表空间内的一个解,其个体更新方式如下式所示:
Xi(t+1)=Xprey(t)-A·D
(2)
式中:Xi(t)表示当前灰狼的位置;Xi(t+1)为灰狼下一次迭代的位置;Xprey(t)表示猎物的位置;r1,r2为[0,1]范围内的随机向量。
A和C均为随机系数向量,是GWO算法中决定攻击和搜索之间平衡的主要参数,其攻击和搜索猎物的行为如图1所示。

图1 攻击和搜索猎物行为示意图
随机向量A如下式所示:
A=2a·r1-a
(3)
当时∣A∣>1时,GWO算法会迫使搜索算子对猎物进行搜索,强调全局的搜索能力;当∣A∣<1时,GWO算法则更注重向猎物进攻的速度,强调局部的搜索能力。
随机向量C如下式所示:
C=2·r2
(4)
式中:r1,r2为[0,1]范围内的随机向量;C为[0,2]中的随机值,该分量为猎物提供随机权重,以便强调(C>1)或弱化(C<1)猎物在式(1)中的勘探能力,最终有助于提升GWO算法的全局探索能力和局部最优规避的能力。
a为收敛因子,且服从[0,2]的线性递减规律,其公式如下式所示:
(5)
式中:iter为当前迭代次数;Max_iter为最大迭代次数。
狼群经过跟踪及追捕后,会对猎物发起进攻,该过程由α、β、δ狼主导,ω狼根据前三者的位置从而更新自己的位置,其过程如下式所示:
(6)
式中:X1,X2,X3为ω狼向α、β、δ狼移动的距离和方向。
GWO算法[13]具体步骤如图2所示。

图2 GWO算法流程
作为一种新型的算法,GWO算法本身也容易发生过早收敛和收敛缓慢的问题。针对以上问题,笔者提出了一种基于维度学习的改进灰狼优化算法(dimen-sion improved grey wolf optimizer, DIGWO)。
1.2 基于维度学习的改进灰狼优化算法(DIGWO)
1.2.1 维度学习的狩猎搜索策略
基于维度学习的狩猎(DLH)搜索策略[14]是:采用α、β、δ狼相互学习的方式,构建候选狼XDLH,挖掘不同维度的信息,将信息传递给其他狼,以此平衡算法全局和局部的搜索能力。其计算步骤如下。
计算个体狼当前位置和候选狼之间的距离及搜索半径ri(t),如下式所示:
ri(t)=‖Xi(t)-XDLH(t+1)‖
(7)
再构造Xi(t)的邻域,进行多邻域学习,如下式所示:
XDLH,d(t+1)=Xi,d(t)+rand×(Xn,d(t)-Xr,d(t))
(8)
式中:XDLH,d(t+1)的第d维是使用Xn,d(t)的第d维来计算。
最后,比较两个候选狼的适应度值,确定最优候选狼,如下式所示:
(9)
1.2.2 余弦收敛因子
传统GWO算法易陷入局部最优解的问题[15],这是因为狼群的距离控制参数a为线性递减,从而导致了全局搜索能力差,易陷入局部最优解的问题。
笔者使用余弦非线性收敛因子对GWO算法的全局搜索能力进行优化,如下式所示:
(10)
笔者设置线性、指数及余弦收敛因子函数进行对比,迭代曲线变化如图3所示。
由图3可以看出:指数函数前期迭代较快,后期迭代较慢,并不能有效地解决局部最优解的问题;余弦收敛因子在迭代过程的前期迭代速率缓慢,能有效地避免陷入局部最优解,提高全局搜索的能力,而后期迭代速率变快,使算法搜索局部最优解的能力得到提高,有助于算法稳定地收敛。
1.2.3 个体狼ω位置更新
GWO算法中选取3个最优解为α狼、β狼和δ狼,其他个体狼ω以此向目标猎物位置靠近。当领头的三匹狼陷入局部最优时,整个狼群就无法对目标猎物的位置做出准确判断,这就导致狼群的捕食失败。
笔者提出了一种新的个体狼ω位置更新方法,来平衡算法的全局搜索和局部搜索性能,即:
(11)
1.3 基于DIGWO算法的VMD参数优化
变分模态分解(VMD)[16]是一种基于维纳滤波(Wiener filtering)、一维希尔伯特变换(one-dimensional Hilbert transform)和外差解调(heterodyne demodul-ation)的非递归自适应信号处理方法,由DRAGOMIRE-TSKIY等人于2014年提出。与EMD和LMD的递归“筛选”模态不同的是,VMD的实质就是变分问题的构造和求解[17],其具体步骤如下:
首先,将原始数据f分解为多个离散模态分量uk(t),k=1,2,…K,建立变分模型如下式所示:

(12)
式中:{uk},{ωk}为模态和中心频率集合的缩写;δ(t)为狄拉克分布;∂t为时间的偏导数;*为卷积运算符。
随后,为了将上式的约束问题转为非约束性分解问题,在式(12)中引入二阶惩罚因子α和拉格朗日惩罚算子λ,其最优解方程如下式所示:
L({uk},{ωk},λ)=
(13)
最后,采用连续迭代更新{uk}、{ωk},如下式所示:
(14)
然而,VMD分解需要提前设置分解层数k和二阶惩罚因子α,参数选取的好坏决定了信号分解效果的好坏。当k和α过大或过小时,会导致过多虚假分量和模态混叠现象。
因此,考虑到上述情况,为了得到VMD参数的最优解组合,笔者使用了DIGWO算法进行自适应优化,并以模糊熵构建新的适应度函数,进行参数寻优,其步骤如下:
1)初始化VMD和DIGWO参数,包括种群数量N,最大迭代次数Max_iter及各种群的初始位置[ki,αi];
2)采用VMD分解滚动轴承振动信号,并计算各IMF分量的模糊熵,以模糊熵的最小值作为适应度函数;
3)通过式(10)和式(11)对狼群位置进行更新,得到狼群下一次迭代的位置;
4)计算所有灰狼的适应度函数值,更新α、β和δ狼的位置,以及a,A,C;
5)判断迭代次数是否满足终止条件,满足则输出[ki,αi]的最优解;如不满足则终止条件,返回步骤3)。
DIGWO算法优化VMD的过程如图4所示。

图4 DIGWO优化VMD

其参数优化迭代曲线如图5所示。

图5 参数优化迭代曲线
由图5可知:DIGWO算法和GWO算法均能达到收敛,但GWO算法并没有达到最小理论值,而DIGWO算法跳出了局部最优,达到了最小的理论最优解。
由此可见,DIGWO算法在参数寻优中更具优势。
1.4 复合多尺度排列熵(CMPE)
作为一种衡量时间序列复杂性的参数,排列熵由BANDT C和POMPE B[18]于2002年提出。因该算法具有简洁、抗噪性强及鲁棒性强等优点,得到了研究人员的广泛运用。
其详细计算过程如下。
1)输入一维时间序列T={xi,i=1,2,…,N},并对其进行相空间重构[19],得到重构矩阵Y,如下式所示。
(15)
式中:M为嵌入维度;t为延时因子;K为重构分量,K=N+(m-1);t为矩阵的行数。
2)将任意重构向量xi中m个元素按照降序重新排列,并引入索引值j的大小以进行降序,即当jm≤jm-1时,排列顺序如下式所示:
x(i+(j1-1)t)≤…≤x(i+(jm-1)t)
(16)
3)根据重构向量中各元素位置的列索引得到一组符号序列,如下式所示:
S(l)=(j1,j2,…,jm)
(17)
式中:l=1,2,…m!,k≤m!,m!为S(l)序列中所有的组合。
4)最后,通过计算空间矩阵中的排列熵PE,并对其进行归一化处理,如下式所示:
(18)
传统的排列熵方法不仅面临采样点个数不足导致信号特征损失的问题,还将随着嵌入维度的增加导致信号变化不明显。为此,笔者提出了复合多尺度排列熵(CMPE),改进数据重构过程,通过计算多尺度下多个复合粗粒化时间序列的多个PE,求PE的均值得到CMPE。
其具体计算过程如下:
1)对原始时序信号进行复合粗粒化处理,如下式所示:
(19)

(20)
CMPE采用“滑动平均”的思想,优化了MPE中不充分的粗粒化过程,特别是尺度因子较大时,复合粗粒化时间序列能最大程度地保留原始时间序列所蕴含的振动特性。
2 基于DIGWO-VMD-CMPE的诊断方法
针对故障信号非线性的特性,笔者提出了一种自适应消噪算法和复合多尺度排列熵的轴承故障诊断方法,其流程图如图6所示。
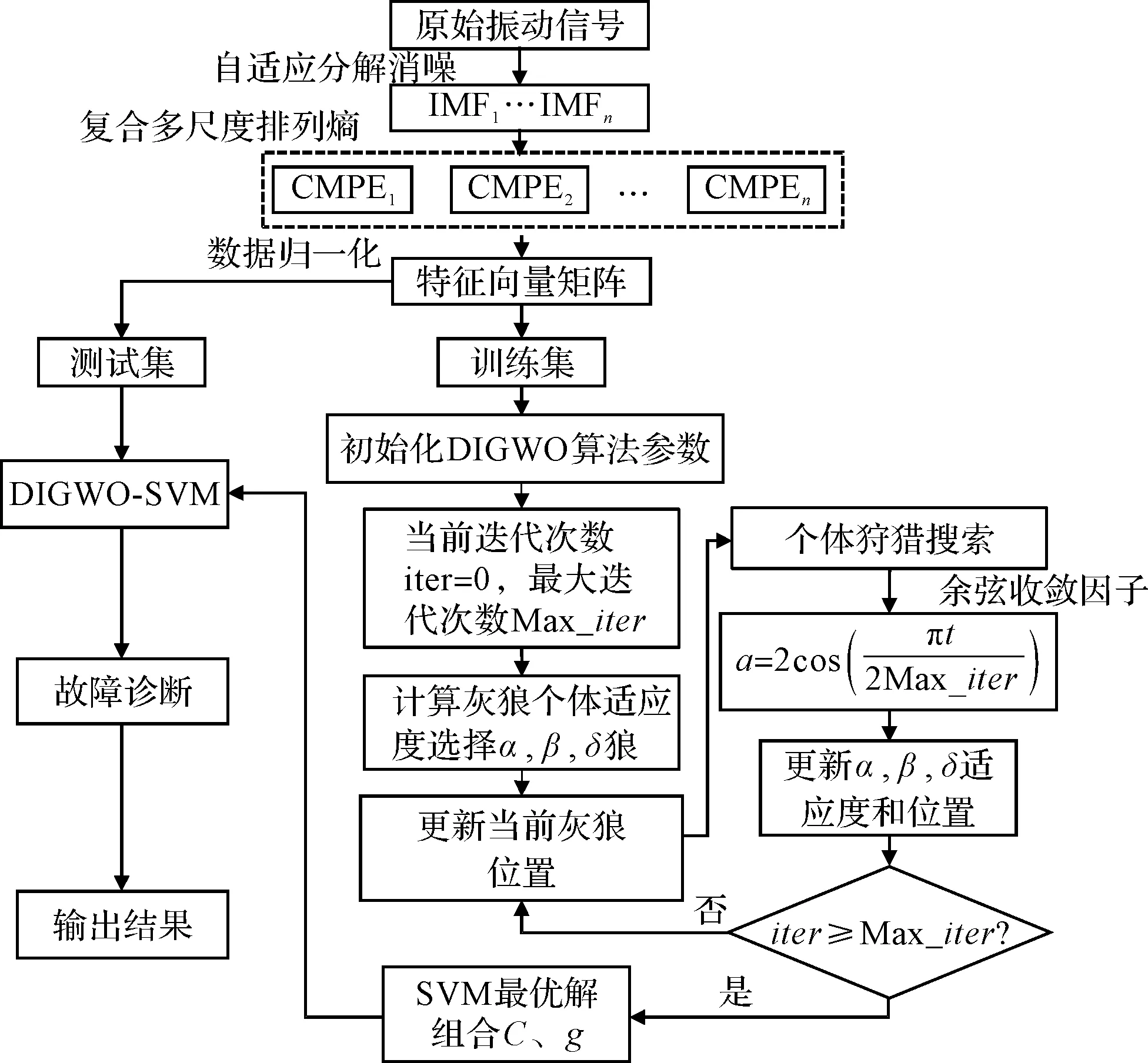
图6 滚动轴承故障诊断流程图
其具体流程如下:
1)输入原始数据(假定轴承有k种状态,每种状态有m组样本),利用自适应消噪分解算法对信号进行参数优化,并得到每类状态的n个IMF分量;
2)根据IMF信号分量确定复合多元排列熵的参数设置,包括样本长度N、嵌入维度M、时延因子t和尺度因子S;
3)计算各类样本的熵值,并进行归一化处理,组成特征向量矩阵;
4)将特征矩阵中的数据设置为相对应的n个标签,按照7 ∶3分为训练集和测试集;
5)初始化DIGWO参数,设置迭代次数iter=0,最大迭代次数为Max_iter。计算每个灰狼的个体适应度,保存适应度最佳的前三者为α、β和δ狼;
6)对当前灰狼的位置进行更新,利用维度学习的狩猎搜索策略、余弦收敛因子和个体狼ω位置更新策略,提高算法的全局和局部搜索能力;
7)更新α、β和δ狼的适应度和位置,并判断是否满足终止条件,如满足则输出C,g的最优解;反之,则返回步骤6);
8)最后,将训练集输入DIGWO-SVM分类器中进行训练,并输出结果。
3 实验与分析
3.1 数据来源
为验证DIGWO-VMD-CMPE方法在轴承故障诊断上的可行性,笔者采用美国凯斯西储大学(Case Western Reserve University)[20]提供的滚动轴承数据集来验证该方法的可行性。其轴承型号为6205-2RS JEM SKF深沟球轴承,电机的转速为1 772 r/min,采样频率为12 kHz。利用电火花在电机驱动端轴承上进行人为破坏,加工出0.177 8 mm的正常、内圈、滚动体故障并与外圈数据组成数据集,并将4种工况的标签依次设置为1、2、3、4。将特征向量样本集按7 ∶3的比例随机分为训练集和测试集,其中每类样本集有35个训练集,15个测试集。
滚动轴承状态数据如表1所示。
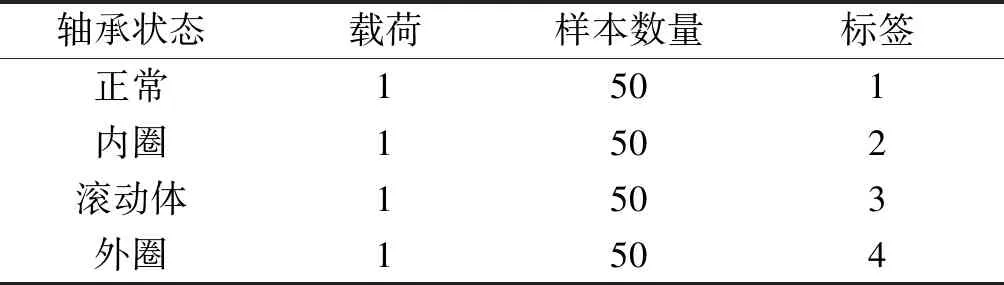
表1 轴承状态数据
笔者按照7 ∶3的比例划分训练集和测试集,每种类型分为50个样本且每段数据长度为2 048,共计200个样本。
其故障时域波形如图7所示。
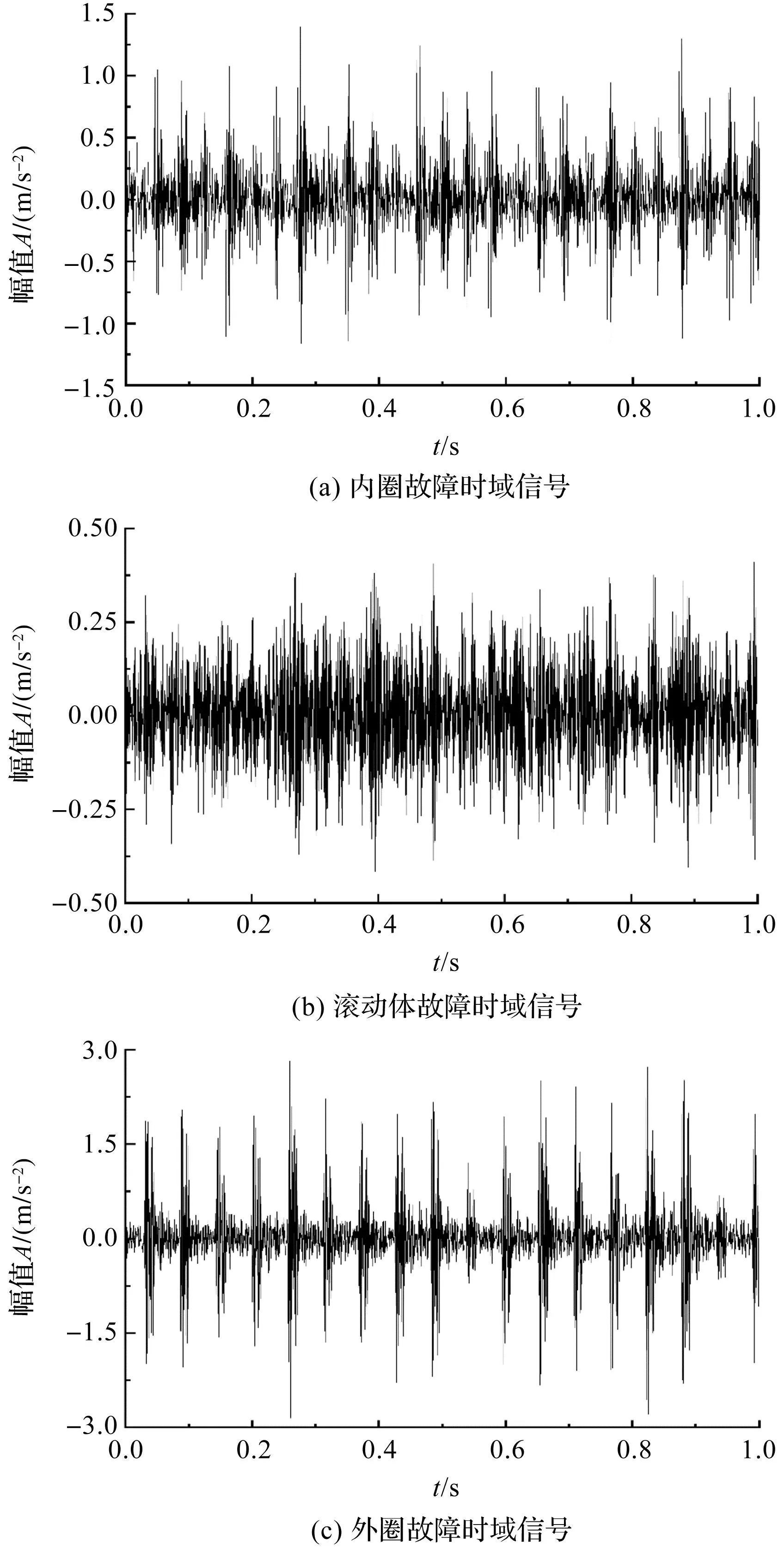
图7 轴承故障时域波形信号
由图7中可知:正常信号、噪声信号与故障信号存在混叠现象,无法区分。
3.2 数据预处理与特征提取
3.2.1 DIGWO-VMD信号分解
因此,笔者首先采用DIGWO-VMD分解振动信号,其中,k∈[2,10],α∈[200,4 000]。
轴承VMD分解结果如表2所示。
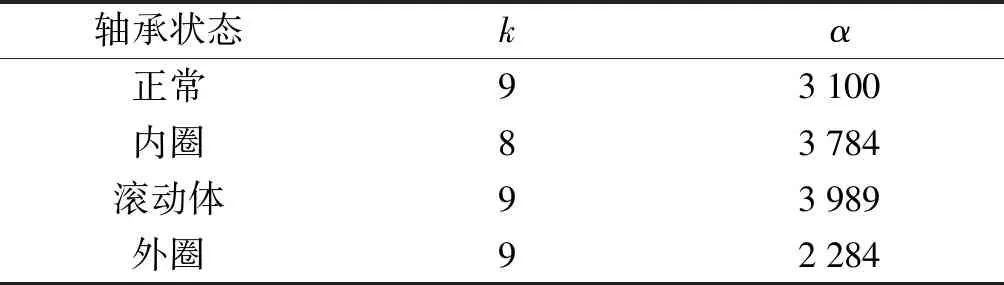
表2 轴承VMD分解参数
为了验证DIGWO算法优化VMD的有效性,笔者采用麻雀搜索法(sparrow search algorithm,SSA)、粒子群算法(particle swarm optimization,PSO)和灰狼算法(greywolf algorithm, GWO)与其进行对比,并以模糊熵的最小值为适应度函数,初始化算法种群数为15,最大迭代次数为50。
寻优对比结果如图8所示。

图8 寻优算法对比曲线
由图8可知:在迭代13次后,DIGWO算法就收敛到了最优,而GWO算法在迭代28次才达到收敛,PSO算法在32次迭代处开始出现了震荡,并且未能达到收敛,这证明了PSO算法的局部搜索能力较差;SSA算法则是收敛于一个较大的值,这说明SSA算法的全局优化能力较差,易陷入局部最优。
为了进一步证明DIGWO算法的优势,4种算法的参数设置如表3所示。

表3 寻优算法参数设置
不同参数设置下,4种寻优算法的结果如图9所示。

图9 不同参数下寻优算法对比曲线
由图9可知:DIGWO算法依旧能够快速地收敛到最优,而PSO算法在迭代后期依旧存在震荡的现象,SSA和GWO收敛的值依旧大于DIGWO的值。由此证明,DIGWO算法在优化VMD过程中具有优势。
3.2.2 CMPE特征提取
笔者将信号分解所得的9个IMF分量构成特征矩阵,利用CMPE熵值计算法提取特征,组成特征向量。而CMPE中共有4个参数需要设置,因此,笔者针对时延因子t、样本长度N、嵌入维度M及尺度因子S对熵值的影响,以美国凯斯西储大学公开的轴承数据为例,采用采样频率12 kHz下电转速为1 772 r/min时驱动端轴承内圈故障信号进行分析。
首先保持M、N、S不变,不同时延因子t下CMPE值的变化如图10所示。

图10 不同时延下CMPE对比结果
由图10可知:不同的时延因子t对复合多尺度熵没有明显的影响,所以,为了减少算法的运算时间,笔者设置t=1。
然后保持M、t、S参数不变,笔者分别对样本长度N取256、512、1 024、2 048进行对比分析,其结果如图11所示。

图11 不同样本长度下CMPE对比结果
由图11可知:随着样本长度的增加,熵值越稳定,但考虑到样本数据要包含轴承一个运行周期的数据,所以笔者设置N=2 048。
保持N、t、S参数不变,笔者取样本长度N=2 048,并设置嵌入维度M的范围为[2,9],进行对比研究,其结果如图12所示。

图12 不同维度下CMPE对比结果
由图12可知:当2≤M≤5时,内圈故障、外圈故障及滚动体故障的CMPE值存在混叠,且熵值变化过小,难以区分有效的特征信息;当M=6时,算法对各类轴承状态的CMPE值的变化较为敏感;而当7≤M≤9时,CMPE值又会产生混叠的现象,并且随着嵌入维度M的增大导致运算时间延长,严重影响了轴承的故障检测效率。
最后,笔者对不同故障类型下的信号进行CMPE分析,其结果如图13所示。

图13 不同故障类型下的CMPE
由图13可知:不同故障类型下,轴承振动信号的CMPE在第16个尺度之后出现外圈故障和滚动体故障熵值交叠现象。若选择较大尺度因子下的CMPE特征向量会造成信息冗余,从而影响模型的识别准确率;若是选择较小尺度因子下的CMPE构建特征向量矩阵,则无法完全反映滚动轴承的故障信息。
综上所述,笔者设置CMPE的参数N=2 048,M=16,S=15,t=1,选择前15个尺度的熵值构成特征向量矩阵,将其作为SVM的输入。
3.3 模型对比验证
3.3.1 基于DIGWO-VMD-CMPE的诊断方法
笔者在MATLAB2019b中搭建模型,设置种群数为30,最大迭代次数为50次,惩罚系数C和径向基函数g取值范围均为[0.01,100],选择预测错误率为适应度函数,如下式所示:
Fitness=100-Acc
(21)
式中:Acc为模型的预测准确率。
基于DIGWO-VMD-CMPE的诊断结果如图14所示。

图14 DIGWO-VMD-CMPE故障诊断结果
由图14可知:在模型中,正常状态下的样本有34个类别被预测正确,有1个类别被误分为滚动体故障,但其余三类轴承状态的识别准确率均能达到100%,并且模型的整体识别准确率达到了98.33%。
DIGWO-VMD-CMPE方法的混淆矩阵如图15所示。

图15 DIGWO-VMD-CMPE的混淆矩阵
由图15可知:黑色格子代表实际样本被正确预测的数量,白色格子代表实际样本被错误预测的数量。在120个样本中,被预测准确的类别为119个。由此,进一步证明了DIGWO-VMD-CMPE方法的可行性。
3.3.2 不同特征提取方法对比
为了验证CMPE特征提取的性能,笔者选择多尺度排列熵(MPE)和能量熵(energy entropy,EE),分别构建了特征向量矩阵并进行对比分析;设置小样本试验,其中4组轴承状态各选取14个样本作为训练集,6个样本作为测试集。
基于EE特征提取方法的故障识别效果如图16所示。
由图16可知:使用能量熵作为特征向量训练时,4个轴承内圈故障被误判为滚动体故障,1个轴承内圈故障被误判为正常轴承状态,4个轴承滚动体故障被误判为内圈故障。其整体的故障识别准确率仅有62.5%,相比DIGWO-VMD-CMPE方法的准确率下降了35.83%。这也说明了能量熵在轴承信号分解时存在样本特征模态混叠的现象,不利于模型的分类识别。
基于MPE特征提取方法的故障识别效果如图17所示。

图17 基于MPE特征提取方法的诊断结果
由图17可知:基于MPE特征提取的故障诊断模型的准确率为87.5%,其中有3个轴承外圈故障被误判为轴承滚动体故障。
基于CMPE特征提取方法的故障识别效果如图18所示。

图18 基于CMPE特征提取方法的诊断结果
由图18可知:在小样本训练集下,基于CMPE特征提取的故障诊断模型的准确率达到了100%。
为保证实验的可靠性,笔者利用每种方法运行10次,并取平均准确率来衡量特征提取方法的优劣,其结果如图19所示。

图19 不同特征提取方法对比
由图19可知:CMPE特征提取方法能够一直保持在较高的准确率,基本都在90%以上波动,最终达到了100%。
3.3.3 不同分类器对比
为了验证DIGWO-SVM的可靠性和优越性,笔者采用CMPE特征向量构建的样本数据集作为PSO-SVM和SSA-SVM的输入,最终得到了模型的故障识别结果,如图20所示。

图20 不同分类器识别结果对比
笔者进行5次实验后,取平均准确率作为模型的评价指标,同时记录最优惩罚系数C和最优径向基函数g。不同分类器识别结果如表4所示。

表4 不同分类器识别结果
由图20和表4可知:基于DIGWO-VMD-CMPE方法的故障诊断模型在准确率上取得了最优的效果。其中,PSO和SSA分类器的准确率分别为91.67%、97.74%,比DIGWO分类器的准确率分别低了7.75%、1.68%;PSO分类器中有4个轴承滚动体故障被错误区分为轴承正常状态,SSA分类器中由2个轴承正常状态被错误区分为轴承内圈故障和轴承滚动体故障;而DIGWO分类器能够有效地区分出每种故障的类型,具有较高的准确率。
根据上述分析可知,DIGWO-VMD-CMPE模型在轴承故障诊断和识别上更具优势。
4 结束语
针对滚动轴承故障信号特征提取困难和识别准确率低的问题,笔者提出了一种基于自适应消噪算法和复合多尺度排列熵的轴承故障识别方法。
研究结果表明:
1)采用DIGWO对VMD的参数k和α进行了自适应优化,能够有效地分解出含有更多特征信息的IMF分量,更利于完成信号的特征提取任务;
2)在对滚动轴承进行VMD的过程中,DIGWO要优于PSO、SSA和GWO方法的效果,并且利用CMPE“滑动平均”思想和复合粗粒化的方法,能够最大程度地保留原始时间序列所蕴含的振动特性,构建高质量的故障特征向量;
3)基于DIGWO-VMD-CMPE方法的识别准确率和速度均优于其他分类器,其能够达到99.42%,相比于PSO-SVM和SSA-SVM分类器高了7.75%、1.68%。
虽然笔者提出的故障诊断方法能较好地完成滚动轴承的故障识别任务,但如何确保各类寻优算法均处于最佳状态下的寻优结果仍旧存在不足。因此,在后续研究中,笔者将对寻优算法的自适应性进行研究,以进一步提高算法的寻优能力和自适应性。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2018年19期)2018-11-14
电子测试(2018年1期)2018-04-18
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
太空探索(2016年5期)2016-07-12
噪声与振动控制(2015年4期)2015-01-01
时代英语·高三(2014年5期)2014-08-26
电测与仪表(2014年15期)2014-04-04
