
基于改进PSPNet的掩模优化算法
2024-03-08 08:42汤府鑫
兰州工业学院学报 2024年1期
祁 攀,汤府鑫,徐 辉
(安徽理工大学 a.人工智能学院;b.计算机科学与工程学院,安徽 淮南 232001)
集成电路从上个世纪发展至今,制程已经突破个位数来到了5 nm甚至3 nm。巨大的制程提升带来了更强大性能的同时,制造过程中的挑战也随之而来。193 nm的曝光长度远大于工艺节点,掩模优化过程逐渐成为了设计过程中的困难[1]。掩膜优化过程在超大规模集成电路设计和制造中起重要作用,这是一个非常复杂的优化问题,同时,为了克服光刻过程中的衍射相关的模糊,需要分辨率增强的方法[2]。
Huang等人提出了一种综合流程来联合优化工艺窗口和掩模的可印刷性,将掩模多边形的边缘分段切开,通过移动切开的分段来优化多边形,最终提升掩模可印刷性[2-3]。Su等人提出了一种对边缘放置错误自适应权重的模型,在迭代过程中分段采用动态分段方法,对于EPE高度敏感的部分将被进一步分解为更短的分段,从而以更短的时间收敛[4]。Ma等人提出了一个新型框架,能够同时求解版图分解和掩模优化,版图分解和掩模联合优化,拥有了全局视野,这样以获得更大的解空间以及更高质量的掩模[5]。Jiang等人首次提出将掩模优化过程在神经网络上处理,通过主干网络预处理和微调网络细化处理,将掩模质量和周转时间提升显著[6]。Yang等人首次引入生成对抗网络(Generative adversarial network,GAN)到掩模优化领域,将GAN网络中的生成器使用先进的分割网络U-Net代替,使生成阶段能够生成效果较好的掩模[7]。
以上基于学习的方法表明,深度学习的方法较于传统方法,无论是从掩模质量还是从周转时间已有了明显的提升。然而,就掩模质量而言,仍有提升的空间,同时,提升训练时间也是不容忽视的重要因素。基于上述分析,本文提出了一种基于改进PSPNet的掩模优化模型。
1 相关原理
1.1 PSPNet网络
PSPNet网络被提出用于解决语义分割任务[8]。该网络因为金字塔池化层的加入,对图像中每个类别的边缘十分敏感,可以用来分割图像的中不同类别。其网络结果如图1所示。其中ResNet作为常用是特征提取层,残差的加能够很好保存上一层有的特征,在经过卷积过后的特征两者特征融合一并输入到下一层,该网络已被验证能有效的解决特征损失和梯度爆炸等神经网络常见的特征提取问题。金字塔池化是该网络中将经过ResNet提取的特征图,通过不同层级的池化层进行不同的池化操作。不同池化层会将上述特征图池化成大小不一的特征图,输出的特征图类似于金字塔,因此得名金字塔池化层。不同的池化层后的特征图再经过上采样和特征融合与ResNet提取的原始特征图进行融合,得到不同层级的特征图,最后再经过一层卷积层输出结果图案。

图1 PSPNet网络结构
1.2 改进的ResNet网络
本文改进的ResNet网络结构如图2所示。
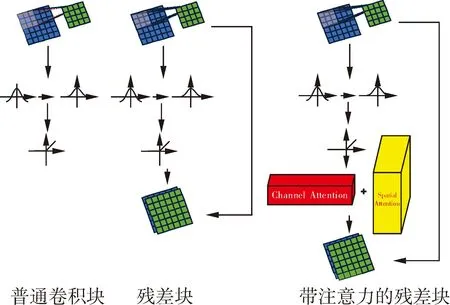
图2 改进的ResNet卷积块
在传统的卷积块中,其中仅包含用于提取特征的卷积层、将数据归一化的BN层和将有用信息提取的ReLU层。经过大量的实验表明,传统神经网络会在网络层数很深时出现网络退化,即层数越深,网络性能下降。为此,ResNet提出残差设计,将上一层的特征原封不动的与当前层的结果融合,这样不同层级之间特征得到了一定程度的保留,形成跳跃连接。这样的做法极大地增加了网络的性能,同时很大程度上避免了网络层数过深带来的梯度爆炸和特征丢失问题。但是当ResNet面对掩模优化任务时,掩模中的特征点分布不均匀,且集中在边缘部分,ResNet的残差设计就不容易提取到部分特征[9]。即使有些特征被保留,但是无效的特征被保留反而使网络变的冗余。加入卷积注意力机制模块则很好地解决了这个问题,它使网络提取特征的同时更加关注掩模的边缘,从而使网络生成高质量的掩模。
1.3 卷积注意力机制模块
在掩模优化任务中,掩模的透光部分并非占掩模版的大部分,恰恰相反,其面积仅占其中的1/5。所以,如何优化每一块掩模,尤其是掩模的边缘,成了框架需要重点关注的区域。ResNet中残差的加入很好地保留了每一层中的特征并传入下一层,但是更加重要的边缘信息没有被提高优先级,很可能被多次卷积后被忽略。因此加入卷积注意力机制模块,通过通道和空间注意力机制相结合,使框架更加关注掩模的边缘,将边缘信息更多的保留下来,便于上采样中重建。
卷积注意力机制模块由通道注意力(Channel Attention,CA)机制和空间注意力(Spatial Attention,SA)机制组成。其中通道注意力机制是将上一层传入的特征图按通道压缩,即将特征图F∈C×H×W都压缩成F∈C×1×1的特征图。使用最大池化和平均池化分别输出2张池化后的特征图,送入共享权重的全连接层。将全连接层的输出进行特征融合并使用Sigmoid函数进行激活形成通道注意力权重,并与上一层传入的特征图相乘输出到下一层空间注意力机制层。空间注意力机制是将上一层通道注意力加权的特征图按空间压缩,即将特征图F∈C×H×W都压缩成F∈1×H×W的特征图。使用最大池化和平均池化分别输出2张池化后特征图,使用特征融合成一张特征图后经过卷积和激活函数形成空间注意力权重,并与通道注意力加权特征图相乘输出到下一层注意力卷积层。卷积注意力机制模块如图3所示。
通道注意力层的输出可以表示为
FCA=WCA*Fin=σ(MLP(AvgPool(Fin))+MLP(MaxPool(Fin)))*Fin,
(1)
式中:σ为Sigmoid函数;MLP为共享全连接层;AvgPool和MaxPool为平均和最大池化。
空间注意力层的输出可以表示为
FSA=WSA*FCA=σ(f7×7([AvgPool(FCA);MaxPool(FCA)]))*FCA,
(2)
式中:f7×7为大小7×7卷积核的卷积层。

图3 卷积注意力机制模块
1.4 像素重组层
在原始的PSPNet网络中,上采样过程使用的是双线性插值,上采样高效的同时,还消除了图片的锯齿问题。但是双线性插值的高频信息损失较多,尤其是对边缘的处理,这极大地影响了掩模优化任务的精度,影响了掩模生成的质量[10]。同时插值法会根据计算插入一些冗余值,也会造成掩模的冗余从而导致性能下降。为此在上采样中加入像素重组层,充当第一部分的上采样,为初步的上采样保留更多的特征。
像素重组层是一种高效的上采样方式,它完全不增加任何冗余。它不像卷积和池化需要提取特征,也不像填充(padding)需要增加可能冗余的0或1,也不需要像插值需要计算周围的数取值给新的像素。它仅需要对特征图进行排列重组。它将每个通道相同位置的像素按某种排列组合至新的特征图,无需其他操作,如图4所示。这种只需要排列的方式提高了上采样的效率,降低了添加冗余像素可能,同时完全保留了特征图中的特征。因此很大程度上提升了生成掩模的质量。
如图4可知,特征图F∈r2×H×W可经过像素重组层变为特征图F∈1×rH×rW。新的特征图保留了原特征图的全部像素信息,为上采样生成掩模提供了极大的帮助。
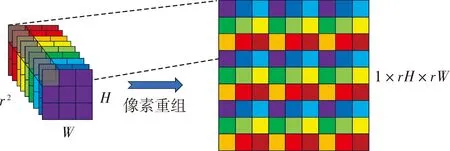
图4 像素重组层
1.5 损失函数
掩模优化任务可以被视作为根据图像生成图像的过程,它将目标布局输入至模型,输出优化好的掩模并与标准掩模进行对比。优化的过程可以认为是尽力将模型输出与标准掩模的每一个像素靠近,是一个回归问题。均方误差(Mean Squared Error,MSE)通常被用来作为回归任务的损失函数。它将图像中的每一个像素点视为一次预测,衡量每个像素点与真实像素点之间的误差的二次方,根据整体图像大小取平均。通过加入平方,也便于在模型中反向传递的求导,根据梯度更新模型参数。均分误差为
(3)
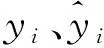
均方误差通常在回归任务中起到良好的效果[11],但是在掩模优化任务中,不仅仅要看整体掩模与标准掩模直接的优化程度,更加关注于掩模的边缘。因此添加DICE损失函数与MSE损失函数联合作为模型的损失函数。DICE损失通常被用来评估两个样本的相似度。DICE损失可以被视作为将预测掩模和真实掩模进行重合,以计算他们重合部分的比值。优化的目标是尽量是让预测掩模与真实掩模重合,使DICE损失变小。
DICE损失为
(4)
式中:ε为极小的数,通常作为平滑系数防止除0错误。
因为DICE损失将预测和真实值同时考虑而非分开,因此DICE损失是区域性损失,即某个像素点的损失和梯度不仅和该点有关,还和该点周围的像素有关,这极大的增加了像素点之间的联系,同时与MSE这种只针对每一个像素点的损失函数区分开来。同时DICE可以改善掩模中的类别不平衡问题[12]。掩模的透光部分只占整体的1/5,具有类别不平衡的特点,使用DICE损失可以处理这样的不平衡问题。
2 实验方案
2.1 实验环境
本实验平台环境为Ubuntu 18.04操作系统,GPU使用NVIDIA RTX3080Ti 12G,在深度学习环境下使用CUDA以及cuDNN图形加速,在PyCharm环境中搭建PyTorch1.11深度学习框架,编译语言使用Python3.8。
2.2 数据集
本文的训练数据集采用由文献[7]作者整理并发布的包含4375对目标布局和标准掩模组成的掩模对。目标布局由ICCAD2013竞赛官方提供代码版本,经过文献[7]整理成图像并发布对应的标准掩模供学术使用。据笔者所知,这是唯一提供给学术界使用的开源掩模优化数据集。测试集采用ICCAD2013竞赛官方提供的10张由不同结构、不同大小组成的掩模。该测试集没有标准掩模。该数据集的详细信息如表1所示。

表1 ICCAD2013数据集详细
2.3 模型评估指标
为了客观地评估模型生成的掩模质量,采用L2均方误差以及工艺变化带(Process Variation Band,PV Band)来衡量生成的掩模质量。将生成的掩模经过光刻模拟软件生成晶圆图像并与目标布局进行对比,得出掩模质量。光刻模拟软件由文献[6]给出。其中L2均方误差为
式中:Z为根据预测掩模生成的晶圆图像;Zt为目标布局。
工艺变化带为在不同光刻条件下晶圆图像的变化,用来衡量掩模对于光刻条件变化的容忍程度。光刻条件刻在光刻模拟软件中调整,生成不同光刻条件的晶圆图像,作差值作为工艺变化带的值。
2.4 实验结果与分析
2.4.1 不同算法对比实验
为了验证本文所提出算法的可行性,本文将不同提取特征网络ResNet26,ResNet38和ResNet50进行对比,并和改进的本方法放在一起对比,对比结果如表2所示。其中的L2和PVB指标均为在10个测试用例上取平均值。基础网络仅使用MSE作为损失函数。为了体现公平,在ResNet26和ResNet38均为同样的卷积块,因此层数为26和38而非传统的18和34层。
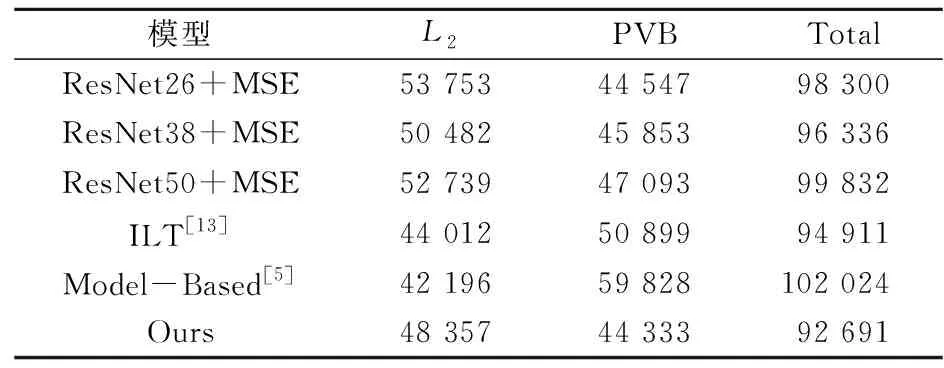
表2 不同模型的性能

(a)ResNet26;(b)ResNet38;(c)ResNet50; (d)ILT;(e)Model-Based;(f)Ours.图5 不同模型生成的掩模
由表2可以看出:该方法相比于ResNet26在L2上提升了10%,在PVB上提升了3%。相比于ResNet38在L2上提升了3%,在PVB上提升了3%。相比于ResNet50在L2上提升了8%,在PVB上提升了5%。相比于当前主流使用的基于模型的掩模优化方法,本文方法相比于ILT提升了2%,相比于Model-Based提升了9%。在图5中,前3张图片来自于逐步增加层数的ResNet。由于掩模优化任务更加关注边缘的处理,虽然ResNet层数增加能有效解决梯度消失问题,但是对于图像生成任务,掩模的质量随着层数下降。而在图5(d)~(e)中,基于模型的方法因为处理边缘不够精细,甚至出现了边缘空洞的情况,会严重影响掩模的制造和晶圆的生成。在本文模型中增加注意力机制,像素重组层和新的DICE损失函数后,模型对边缘的处理更加详细,掩模中边缘的粘连和冗余更少,边缘更加顺滑。从表和图中能看出本文改进模型的有效性。
2.4.2 消融实验
在本模型中,增加了卷积注意力机制模块、像素重组层和DICE损失函数。为了进一步体现不同模块之间组合的效果,通过消融实验进一步证明增加模块的有效性。全部消融实验结果如表3所示。表3中的CBAM代表卷积注意力机制模块,Shuffle代表像素重组层模块,DICE代表DICE损失函数模块。
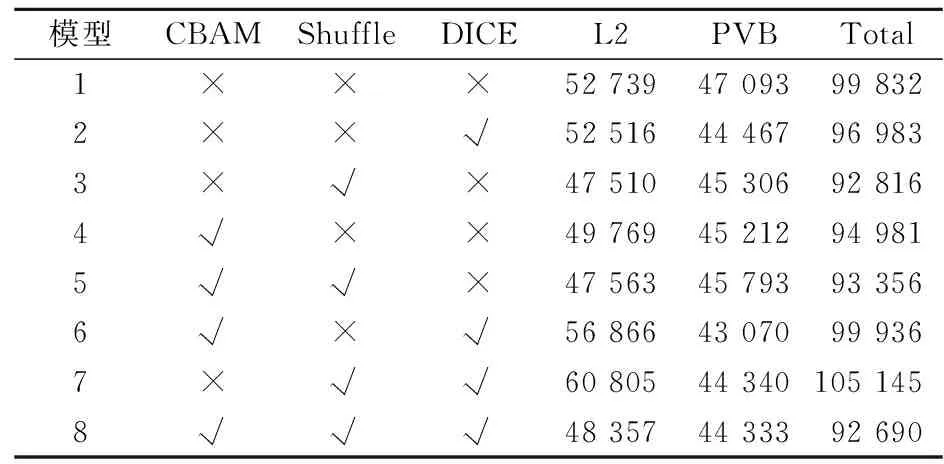
表3 消融实验结果
由表3可以看出,分别加入CBAM、Shuffle、DICE模块的3种模型相比于原模型分别提升了2%、7%和4%。消融实验结果对比见图6,可以看出:加入模块的模型生成的掩模相比于原模型生成的掩模,边缘更加顺滑,拐角处棱角更少,便于制造。在分别加入2组模块的模型中,也都有不同程度的效果。最后,综合3种模块,使掩模质量提升了7.1%,模型生成的掩模最为光滑,拐角处没有粘连,且掩模质量最好。在图6中,根据掩模生成的晶圆图像被列在对应掩模的第二行。在其他的掩模生成的晶圆中,包含例如布局间粘连,布局覆盖过多,布局拐角不平滑等问题。这些问题在最后一个由本文模型所生成的晶圆图像中并没有出现。因此综合掩模质量和晶圆质量,本文模型生成的效果更好。通过消融实验证实了改进后的PSPNet模型能够生成质量更高的掩模。

图6 消融实验结果对比
3 结论
1) 针对掩模优化任务中更加注重边缘区域的优化,本文在PSPNet模型中的提取特征网络ResNet增加卷积注意力机制模块,提高提取特征网络的提取特征能力,更加注重对边缘区域的提取与保留。
2) 针对上采样过程的双线性插值会有冗余信息添加的问题,本文在上采样过程中加入像素重组层,它可以迅速对像素进行重组且不添加任何冗余信息,完整的保留特征的信息。
3) 针对损失函数中仅使用MSE会造成掩模生成质量不高、梯度不便于计算的问题,加入DICE损失函数,使梯度更加顺滑的同时,能让模型更加关注边缘区域的优化,与注意力机制配合一起优化掩模最重要的边缘区域。
4) 由实验结果可知,本文的模型相比于原始模型提升了7.1%,相比于基于模型的提升了至少2%。同时生成的掩模边缘更加顺滑,便于制造,拐角处的粘连更少,掩模质量更优。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
传感器与微系统(2019年7期)2019-06-25
传媒评论(2017年3期)2017-06-13
自然资源遥感(2017年2期)2017-04-27
通信产业报(2016年44期)2017-03-13
光学精密工程(2016年3期)2016-11-07
第二课堂(课外活动版)(2016年2期)2016-10-21
四川师范大学学报(自然科学版)(2015年2期)2015-02-28
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
