
基于注意力机制的无监督异常声音检测方法
2024-03-08 08:33李敬兆张金伟
兰州工业学院学报 2024年1期
王 超,李敬兆,张金伟
(安徽理工大学 a.人工智能学院;b.计算机科学与工程学院,安徽 淮南 232001)
传统的异常声音检测通常基于有监督学习,需要事先对大量样本进行标记和分类,才能建立有效的分类模型。然而,工业机器故障率低,异常数据难获取,限制了有监督学习在实际应用中的适用性。
近年来,越来越多的研究人员开始探索基于无监督学习的异常声音检测方法。张晨旭等人使用普通的全连接自编码器对机器异常声音进行检测,取得了一定的效果[1]。万智勇等人则是提出一种双通道自监督编码器,利用双向循环网络和全连接网络提取声音的时序信息和频域信息,再进行融合,以获取更好的音频特征进行异常声音检测[2]。但是基于传统自编码器(Auto Encoder,AE)的异常声音检测方法存在低鲁棒性、特征表达能力差等问题。
针对上述问题,本文提出了一种基于注意力-跳跃自编码器-生成对抗网络的无监督异常声音检测方法ASAE-GAN(Attentional Skip-connected Auto Encoder and Generative Adversarial Network),使用重构能力较强的跳跃自编码器[3]作为生成对抗网络(Generative Adversarial Network,GAN)的生成器。
1 理论基础
1.1 跳跃自编码器
自编码器是一种无监督学习模型,可以用于降维、特征提取和数据生成等任务。跳跃自编码器则是在自编码器的基础上,在编码器与解码器间添加了跳跃连接。跳跃连接能将低层的信息直接传递到高层中,从而提高了特征提取的效率和精度。含跳跃结构的自编码器最早由Ronneberger等人提出,它是一种用于图像分割任务的网络,被称为UNET网络[4]。
跳跃自编码器的目标是最小化输入和重构输出之间的误差。目标函数为
(1)
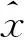
1.2 生成对抗网络
GAN的基本思想是通过生成器和判别器的对抗实现数据生成。生成器从噪声中生成样本,判别器则区分真实样本和生成器生成的样本。GAN的目标是让生成器生成的样本与真实样本的分布尽可能相似,同时让判别器尽可能准确地判断两者之间的区别。GAN的目标函数为
minGmaxDV(D,G)=Ex~Pdata(x)[logD(x)]+
Ez~Pz(z)[log(1-D(G(z)))],
(2)
式中:G为生成器;D为判别器;Pdata(x)是真实数据分布;Pz(z)是噪声分布。
1.3 注意力机制
在传统的神经网络中,每个输入都被视为同等重要,模型无法分辨哪些输入对于任务最关键。注意力机制则可以帮助神经网络聚焦于更重要的数据。
1) 通道间注意力机制。根据输入特征张量中不同通道之间的相关性来调整每个通道的重要性权重,从而自适应地选择对当前任务最为关键的通道。其数学表达式为
(3)
(4)
式中:xj,k为输入特征的第j个通道的第k个位置的值;Wf为通道注意力权重矩阵;g为激活函数;fi为第i个通道的注意力权重;Z为归一化因子;xi为输入特征的第i个通道的值;C为通道数量;y为加权求和后的输出特征。
2) 时间注意力机制。根据序列中不同时间步的信息权重来加权总结输入序列的信息,从而使模型集中关注更重要的时序特征。其数学表达式为
(5)
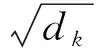
2 本文模型
2.1 模型结构
为了提取更优越的数据特征,本文提出了ASAE-GAN无监督异常声音检测方法。该网络包括生成器和判别器2个主要部分,模型结构见图1。
生成器由1个编码器和1个解码器组成。编码器通过4个卷积操作将输入数据转换为低维特征向量,并在每个卷积操作后引入通道间注意力机制以增强模型的对不同通道进行加权,使得网络可以自适应地选择对当前的任务最关键的通道。其中,卷积核的大小设置为3*3,步长为2*2,填充方式为same,激活函数使用的是LeakyReLU,卷积核数量分别为64、128、256和256。
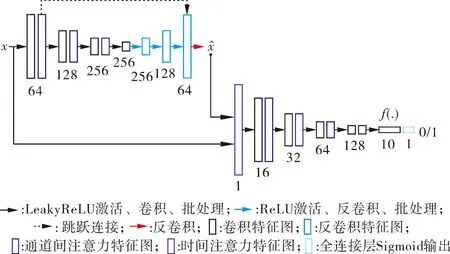
图1 ASAE-GAN模型结构
解码器通过4个反卷积操作将低维特征向量转换为高维数据,利用跳跃连接机制保留了输入数据的细节和特征,提高了模型的准确性和稳定性。其中,卷积核的大小为3*3,步长为2,填充方式为same,激活函数使用的是ReLU,卷积核数量分别为256、128和64,最后一个反卷积的卷积核数量为1,不使用激活函数。
判别器先利用时间注意力机制把输入的特征数据的不同时间步的特征加权,再把加权后的特征向量输入到卷积神经网络中。卷积操作一共5个,前4个卷积操作后,使用通道间注意力机制对通道加权。卷积核的大小都设置为3*3,步长设置为2,数量分别为16、32、64、128和10,激活函数使用ReLU。最后一层使用单神经元的全连接层,激活函数为Sigmoid。
2.2 目标函数
生成器的目标函数为
Ladv=Ex~px[logD(G(x))],
(6)
Lrec=Ex~px||x-G(x)||1,
(7)
Llat=Ex~px||f(x)-f(G(x))||2,
(8)
LG=αLadv+βLrec+γLlat.
(9)
判别器的目标函数为
LD=Ex~px[logD(x)]+Ex~px[log(1-D(G(x)))],
(10)
式中:G为生成器;D为判别器;x是输入数据;f是判别器的潜在特征;Ladv、Lrec和Llat分别是对抗损失、重构损失和潜在损失;LG是生成器的总损失,由对抗损失、重构损失、潜在损失加权组成;α、β、γ分别是它们的权重;LD是判别器的总损失。
3 实验
3.1 数据集
本文实验使用了MIMII数据集[5]中的pump声音数据。该数据集包含了4台机器的正常声音和异常声音样本,每段音频的采样率为16 000 Hz,时长为10 s。这4台机器的ID分别为0、2、4、6。具体数据集信息如表1所示。

表1 pump数据集统计信息 条
3.2 数据预处理
梅尔频率倒谱系数(Mel-Frequency Ceptral Coefficients,MFCC)[6]是声学领域常用的特征。MFCC仿照人类的听觉原理进行建模,将声音信号从时域转换到频域,并提取其中对任务有用的信息。在本研究中,提取原始音频的MFCC特征作为模型的输入。
每个音频样本的时间长度是10 s,提取MFCC时,帧长设为1 138,帧移设为498,窗函数选汉明窗,取前30位系数,最终得到的MFCC特征的形状为(30,320)。为了更充分地利用MFCC特征,按顺序复制每个特征,并将其拼接成形状为(320,320)的特征数据。
然后再对训练集数据的每个特征分别进行标准化处理,避免特征之间的数值差异对模型训练产生负面影响。具体而言,先将每个特征的数据类型转换为单精度浮点数类型,然后计算训练集每个特征的均值和标准差,并使用它们对训练集和测试集的特征进行标准化处理。
3.3 模型训练及相关参数
只使用正常声音提取到的特征进行训练。训练集数据一共训练10代,批处理大小为8。每代训练先训练1次判别器,再训练2次生成器。生成器和判别器的优化器都使用自适应矩估计优化算法(Adaptive Moment Estimation,Adam)。学习率分别为0.001和0.000 1。生成器的损失函数权重分别设置为1、40和1。
3.4 模型测试与评价
训练完模型后,把测试集数据输入模型。保存测试模型时的生成器重构损失与判别器潜在损失。
由于模型的训练只使用了正常样本,模型只学习到了正常样本的数据分布。理想情况下,输入异常样本时,模型不能很好地重构数据,从而使得正常样本与异常样本的重构损失与判别损失的差别足够大。所以使用重构损失与判别损失作为异常分数,异常分数为
S=λrLrec+λlLlat,
(10)
式中:Lrec和Llat分别为生成器的重构损失和判别器潜在特征层的潜在损失;λr和λl则分别为它们所对应的权重系数,本文中取0.1和0.9。
模型的评价指标使用无监督学习常用的评价指标:AUC(Area Under Curve)。AUC被定义为ROC(Receiver Operating Characteristic)曲线下的面积。AUC的取值范围在0.5~1.0之间,AUC越接近1,说明模型性能越高。
3.5 实验结果分析
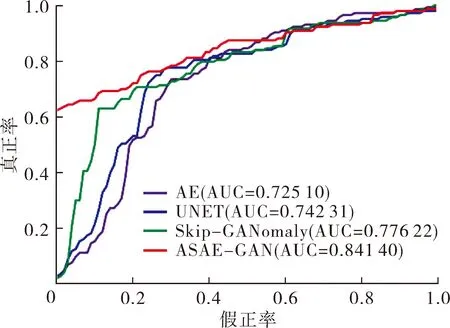
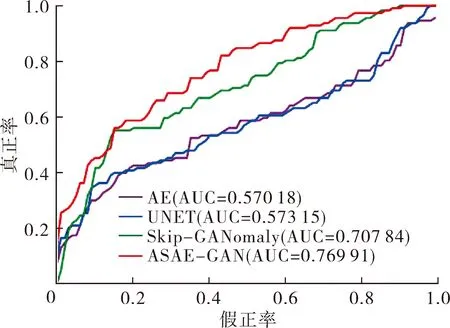
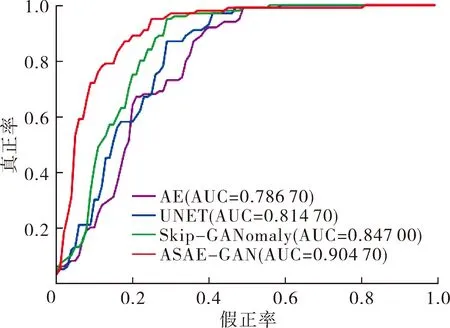
1) 对比试验。本文使用传统的自编码器AE、跳跃自编码器UNET和基于GAN的异常检测模型Skip-GANomaly[7]作为对比方法,实验结果如图2和表2(小数点2位后直接舍去)所示。
图2展示了不同方法在机器0、机器2、机器4和机器6上的ROC曲线。通过观察图2中曲线的相对位置可以发现, ASAE-GAN的ROC曲线均在其余方法的上方,证明ASAE-GAN的性能优于AE、UNET和Skip-GANomaly。
表2是不同方法在机器0、机器2、机器4和机器6上的AUC分数以及它们在全部机器上的平均AUC分数。由表2可以看出:ASAE-GAN的平均AUC分数为82.44%,相比于AE、UNET和Skip-GANomaly分别提升了16.27%、14.23%和6.55%。由此可见,本文所提方法ASAE-GAN具有良好的异常声音检测能力。另外,模型在ID为0和4的异常检测任务中表现较好,但在ID为2和6的异常检测任务中表现一般。这可能因为在ID 为0和4的数据中,异常声音和正常声音的差异较大,而在ID为2和6的数据中,异常声音和正常声音的差异较小,因此需要更加精细的特征提取和模型设计。
(a) 机器0
(b) 机器2
(c) 机器4

(d) 机器6图2 对比试验ROC曲线
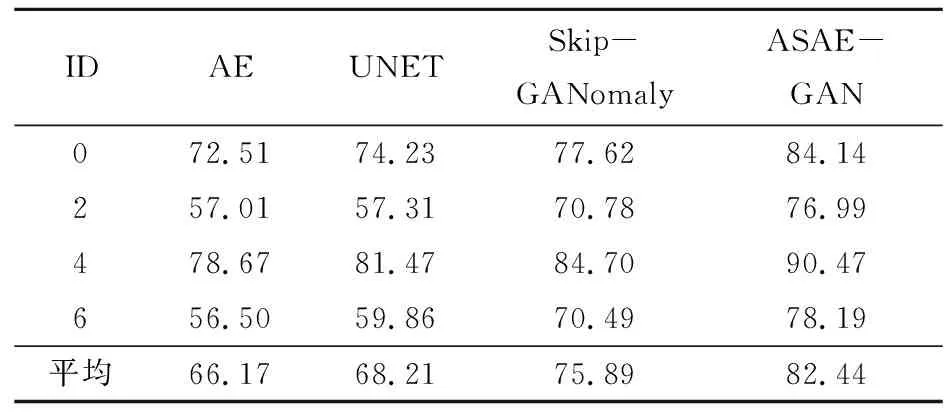
表2 对比实验AUC分数
2) 消融实验。为了验证ASAE-GAN中的通道间注意力机制和时间注意力机制的有效性,本节进行消融实验验证,4种模型结构分别为:① SAE-GAN,该模型生成器使用带跳跃连接的AE,判别器使用卷积神经网络,未添加注意力机制;② CSAE-GAN,该模型在SAE-GAN的基础上,添加了通道间注意力机制;③ TSAE-GAN,该模型在SAE-GAN的基础上,添加了时间注意力机制;④ ASAE-GAN,本文所提模型,在SAE-GAN的基础上,添加了通道间注意力机制和时间注意力机制。
实验结果如表3(小数点2位后直接舍去)所示。

表3 消融实验AUC分数
由表3可知,加入通道间注意力机制的CSAE-GAN比未加入注意力机制的SAE-GAN的平均AUC高了1.34%,表明通道间注意力机制可以使模型能更好地捕捉重要的通道。加入时间注意力机制的TSAE-GAN比未加入注意力机制的SAE-GAN的平均AUC高了2.35%,表明时间注意力机制可以使模型获取到更重要的时序特征。而同时加入了通道间注意力机制和时间注意力机制的ASAE-GAN相比于SAE-GAN、CSAE-GAN和TSAE-GAN的平均AUC分别提高了5.87%、4.53%和3.52%,证明了本文方法可以有效地提高模型的性能。
4 结论
1) 本文方法ASAE-GAN相比较于传统的自编码器AE,平均AUC分数提升了16.27%。
2) 消融实验证明了单独添加通道间注意力机制和时间注意力机制都能有效提升模型性能,同时添加2种注意力机制的效果更好。
3) 在未来的工作中,可以给模型添加长短时记忆网络和其它类型的注意力机制,进一步增强模型的特征表达能力。
猜你喜欢
环球时报(2022-07-13)2022-07-13
小雪花·成长指南(2022年1期)2022-04-09
环球时报(2022-03-14)2022-03-14
电影(2018年8期)2018-09-21
成都信息工程大学学报(2018年3期)2018-08-29
传媒评论(2017年3期)2017-06-13
电子设计工程(2017年20期)2017-02-10
第二课堂(课外活动版)(2016年2期)2016-10-21
电子器件(2015年5期)2015-12-29
小猕猴智力画刊(2015年4期)2015-04-28
