
基于BiViTNet的轻量级驾驶员分心行为检测方法
2024-03-08 05:58高尚兵张莹莹张秦涛
重庆交通大学学报(自然科学版) 2024年2期
高尚兵,张莹莹,王 腾,张秦涛,刘 宇
(1.淮阴工学院 计算机与软件工程学院,江苏 淮安 223003;2.江苏省物联网移动互联网技术工程实验室,江苏 淮安 223001)
0 引 言
全球每年在交通事故中受伤的人数超过1 000万人[1],许多交通事故是分心驾驶导致,中国交通年鉴的统计数据显示,我国大部分的交通事故是由于驾驶员的驾驶行为不当或者行为违规造成的,根据美国高速公路安全管理局(national highway traffic safety administration,NHTSA)发布的调查结果显示,因驾驶员分心而导致的交通事故人员伤亡占死亡人数的64.4%[2]。无论国内外,在驾驶员行车过程中对其行为进行识别都非常重要,识别的实时性和准确性则是辅助驾驶安全的要素之一,可以在一定程度上减少交通事故的发生。因此,驾驶员分心行为检测在自动驾驶领域和计算机视觉方向上都有广阔的研究前景[3]。
尽管驾驶员分心行为识别是人类动作识别[4]的一个通用问题,但是由于驾驶员分心时体态差异细微,目前用于人体动作识别的方法并不适用于驾驶员分心识别。虽然很多研究都致力于对各种分心行为进行检测,且具有一定的效果[5-6],但是大多都采用CNN结构对驾驶员行为进行检测[7],一方面模型较大而且检测精度不高;另一方面通过CNN结构更多提取到的是局部特征,不能全面地检测驾驶员行为,而有些研究者通过加大卷积核尺寸来扩大感受野,这会加重网络负担。
提出了一种基于BiViTNet的驾驶员行为识别方法,具体贡献如下:①大部分的CNN结构为了扩大感受野而选用更大尺寸的卷积核,参数量和计算量也随之成倍地增加,因此笔者提出了双分支并行的轻量级神经网络,将基于CNN的局部特征和基于ViT的全局特征相结合,以增强表示学习;②采用双分支并行结构,CNN Branch和ViT Branch可以最大限度地保留局部特征和全局表示;③为了使网络更贴合实际,数据集来自于交通监管平台的车内多视角监控视频,不仅基于真实的驾驶环境,而且多视角监控相对于单一摄像头所采集的数据而言更加全面。
1 驾驶员分心行为检测方法
驾驶员分心行为检测已经得到了广泛的关注,过去几年研究者已经提出了多种方法。
根据数据采集方式的不同,可以分为接触式传感器识别法和非接触式传感器识别法[8]。接触式传感器识别法需要驾驶员佩戴特殊的设备来采集驾驶员的生理信息和肢体运动状态,这种方法可能会对驾驶员的正常驾驶行为造成一定的干扰。非接触式传感器识别法主要通过相机、压力传感器等来采集数据,分析驾驶员的驾驶状态,这种方法具有良好的部署便利性。采用的是非接触式传感器识别法,通过单目相机采集驾驶数据。
根据所采用的算法不同,可以分为传统机器学习方法和深度学习方法。在之前的研究中,很多研究者通过传统机器学习的方法对驾驶员分心行为进行检测,YAN Chao等[9]通过金字塔方向梯度直方图和随机森林分类器对驾驶员的分心行为进行检测。
近年来,由于卷积神经网络已在多个领域取得了巨大成功,很多研究者也将其用在驾驶员分心行为检测任务上,PENG Xishuai等[10]先通过VGG-19网络从采集的驾驶数据中提取单一时刻的语义信息,再通过LSTM(long short term memory)网络对驾驶员的分心行为进行检测;HU Yaocong等[11]使用多流卷积网络来提取不同尺度的特征,并将这些特征进行融合最后进行分心行为检测。虽然在深度学习方法研究中,有针对全局与局部相融合的方法,但未有人将其用于驾驶员分心行为检测领域。
以上方法虽然都基本可以对驾驶员的分心行为进行检测,但是仍存在一些问题:①所采用的数据集一般来自于实验条件下,跟真实驾驶场景下的数据有一定的误差,所以数据应该尽量贴近真实驾驶环境;②大多数网络的参数量和计算量比较大,很难达到实时检测的要求;③检测的准确率不高也是普遍存在的问题。因此,笔者提出一种能精确识别多种驾驶员分心行为的轻量级神经网络BiViTNet。
2 BiViTNet分心行为识别方法
CNN和Transformer在特征获取方面存在一定的差异,前者具有局部性,而后者具有全局交互特性,将两者结合可以综合局部和全局的视觉表征信息,从而提高网络对特征的学习和表达能力。因此,BiViTNet结合CNN和Transformer,采用双分支并行结构,如图1。
第1个分支采用卷积结构,重点关注局部特征,该分支主要包含3个模块,分别是Stem模块、残差过渡模块和局部感知模块;第2个分支采用ViT结构,双分支在保留局部特征和全局表示的同时进行双向特征交互,最后将两个分支的特征进行融合。特征融合时,采用add函数,让每一维度下的特征信息量增加,这有助于最后的分类。
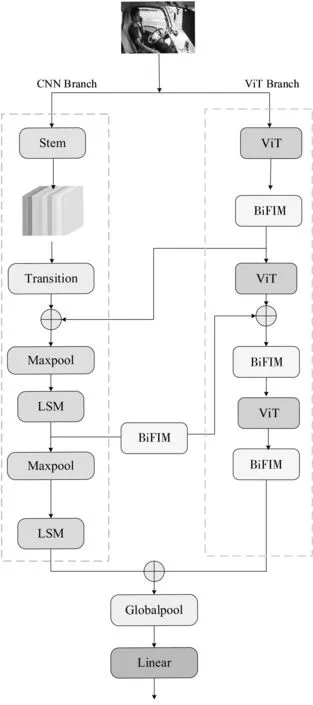
图1 BiViTNet结构Fig.1 Structure of the BiViTNet
2.1 CNN Branch
2.1.1 Stem模块
CNN Branch整体基于特征金字塔架构[12],首先通过Stem模块处理输入,Stem模块主要是用于提取图像的初始局部特征。由于CNN Branch重点关注图像的局部特征,所以不用像其他网络那样为了扩大感受野而采用大卷积核,因此一定程度上减少了参数量。Stem模块均采用3×3的卷积并结合最大池化,将图像大小缩放到原来的1/4。Stem模块的结构如图2。

图2 Stem模块结构Fig.2 Structure of the stem module
2.1.2 残差过渡模块
送入CNN Branch中的图像经过Stem模块处理之后进入Transition模块。为了保证实时性且使参数量和运算成本都尽可能地比较低,Transition模块采用深度可分离卷积,包括逐通道卷积(depthwise convolution)和逐点卷积(pointwise convolution)。
标准卷积的参数量(parameter,Ps)和计算量(Fs)为:
Ps=K2×M×N
(1)
Fs=Ho×Wo×M×K2×N
(2)
深度可分离卷积的参数量(PD)和计算量(FD)为:
PD=K2×M+M×N
(3)
FD=K2×Ho×Wo×M+Ho×Wo×M×N
(4)
所以,标准卷积和深度可分离卷积参数量的比值(P′)和计算量的比值(F)为:
(5)
(6)
式中:Ho和Wo分别为输出特征图的高和宽;M为输入特征图的通道数;K为卷积核尺寸;N为卷积核个数。通过式(5)和式(6)可以看出使用深度可分离卷积代替标准卷积操作,可以显著降低参数量和计算量。
在Transition模块中采用SiLU激活函数。除使用深度可分离卷积外,还采用了残差结构,一方面可以保证长距离的信息不丢失,另一方面也可实现不同层级间的特征交互。Transition模块的结构如图3。
2.1.3 局部感知模块
CNN Branch中的局部感知模块(local sensing module,LSM)主要是为了高效低价地提取图像的局部特征。LSM先使用1×1卷积,将经过最大池化后的特征图从低维空间映射到高维空间中,以提取到更多信息。为了在获取局部特征的同时减少参数量和计算量,LSM也采用深度可分离卷积。
LSM中并未使用更大的卷积核,也没有使用更宽的网络结构,而是简单的单分支结构,这是因为CNN Branch只是用来获取图像的局部特征,只用1×1卷积和3×3卷积搭配就可以完成这一任务,所以不需要通过更大的卷积核或者更宽的网络结构来扩大感受野范围,同时这样也可以降低网络的参数量。CNN Branch不能捕获到的全局信息则通过ViT Branch和双向特征交互模块去弥补。LSM的结构如图4。

图4 LSM结构Fig.4 Structure of the LSM
2.2 ViT Branch
由于CNN Branch为了减少参数量,均采用1×1和3×3的卷积核,感受野比较小,所以ViT Branch建立全局依赖弥补CNN Branch的不足。
ViT是受Transformer的启发[13],将其直接从NLP领域转换到了CV领域。ViT块的结构如图5。ViT Branch的结构如图6。

图5 ViT结构Fig.5 Structure of the ViT

图6 ViT Branch结构Fig.6 Structure of the ViT branch
ViT Branch包含3个ViT块,通过控制每个阶段输入的图像块大小和被划分的图象块大小来获得不同感受野范围的特征信息,每个ViT块的最后并不做分类,而是通过双向特征交互模块(bidirectional feature interaction module,BiFIM)串联接入下一个ViT块,并通过BiFIM模块和ViT结合获得不同层级的语义信息。最后,将ViT Branch和CNN Branch进行特征融合后再进行分类,这样做可以最大限度地保留局部特征和全局表示,并实现局部与全局视觉表征信息的交互,较好地进行驾驶员分心行为检测。
2.3 双向特征交互模块
CNN Branch和ViT Branch之间通过双向特征交互模块BiFIM实现局部特征和全局表示之间的双向融合。BiFIM包括两部分,分别是特征对齐模块(feature alignment module,FAM)和采样模块。由于经过Transformer后的特征维度和卷积后的特征维度不匹配,所以用FAM模块在两种特征维度间互相转换并通过1×1卷积实现通道匹配;同时,还需要上下采样以便于CNN Branch和ViT Branch特征的融合。因此,BiFIM一方面进行特征维度转换以实现ViT块的串联,另一方面在CNN Branch和ViT Branch之间建立双向特征交互。BiFIM的结构如图7。
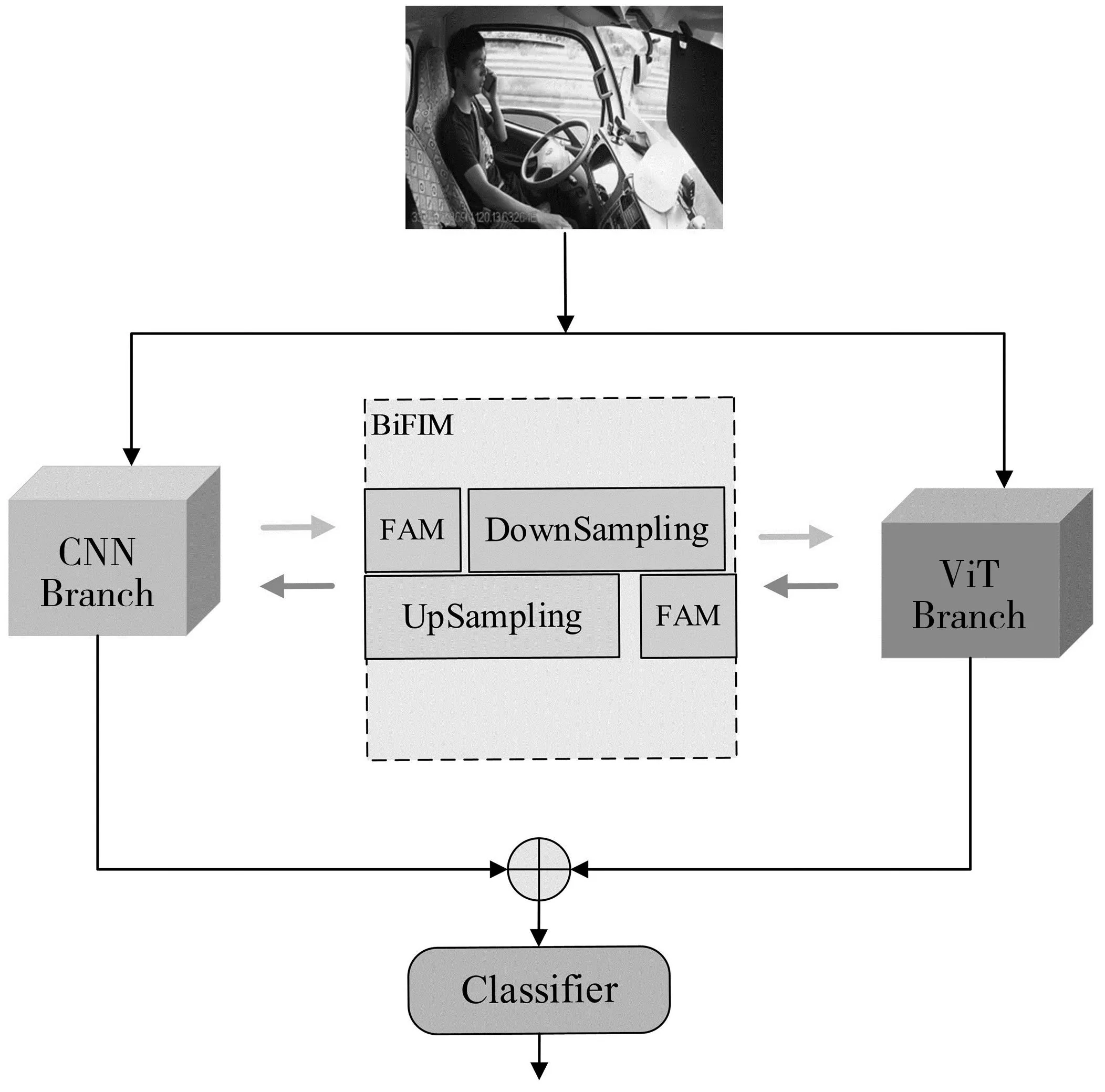
图7 BiFIM结构Fig.7 Structure of the BiFIM
3 实验结果与分析
3.1 数据集与预处理
使用的数据来自实际场景下的车内多视角监控视频,首先,将长监控视频中的分心行为剪辑成短视频,然后对这些短视频逐帧截取,并从中选择代表性的帧,最后对选取出的每一张图片进行分心行为类别标注。在进行数据标注时为了不引起歧义,对于安全驾驶和左顾右盼这两个类别分别人工选取代表性更强的帧进行制作,驾驶员视线保持正前方,操作符合规范的图像标定为正常驾驶;驾驶员视线既不在正前方和左右后视镜,也没有观察路况,而将头探出窗外、低头或向后扭头的图像标定为左顾右盼。笔者所采用的数据集分为5个类别,总共包括43 495张图片,其中训练集和验证集按照7∶3的比例进行划分。图8为驾驶员分心行为数据集的示意图,表1为自建的分心驾驶数据集详细说明。

图8 数据集示意Fig.8 Schematic diagram of the dataset

表1 数据集详细信息Table 1 Details of the dataset
多视角的监控一方面虽然提升了数据的丰富度,相对于单一摄像头所采集的数据更加全面,但是另一方面由于多视角的存在,需要网络从不同的角度去判定同一分心行为,这就要求网络提取更多更全面的特征,也给检测带来了很大挑战。因此,结合CNN和ViT两者的优势,创建两个分支,并在两个分支之间进行不同维度特征的交互以同时关注局部特征和全局特征。以C2打电话为例的多视角监控如图9。

图9 多视角监控Fig.9 Multi-view monitoring
为了加快网络的训练过程,对数据集进行了预处理。首先,将图像的大小统一转换为224×224,然后使用缩放、裁剪、翻转和增减对比度的方法进行数据增强。
3.2 评价指标
为了评价BiViTNet的性能,使用以下4个指标对该网络进行评估,分别是准确率(A)、精度(P)、召回率(R)和F1分数(F1),这4个评价指标的定义为:
(7)
(8)
(9)
(10)
式中:TN、TP、FN和FP分别为真反例、真正例、假反例和假真例。
3.3 实验参数和训练策略
本实验使用的深度学习框架为Python3.8和pytorch 1.10,操作系统为Centos 8.0,GPU为Tesla V100,内存大小16 G。对模型设置动量为0.9,训练批次大小为16,训练轮次为64,初始学习率为0.001,学习率每隔10轮变为原来的0.5,并使用随机梯度下降(SGD)和交叉熵损失函数对网络进行训练,更新网络模型的权重。
3.4 实验结果
BiViTNet网络在训练过程中的训练集和验证集的准确率和损失变化如图10。从图10中可以看出,当训练达到50个迭代次数之后网络开始趋于平缓收敛,在训练的过程中不管是准确率还是损失都没有过拟合;同时在训练过程中,曲线基本上不表现噪声,在整个上升和下降的过程中,除了最开始的3~4次迭代次外总体上表现平滑,这也说明了笔者搭建的BiViTNet模型具有较好的鲁棒性,比较适合进行驾驶员分心检测任务。

图10 训练中的数据变化情况Fig.10 Data changes during training
为了更详细地展示BiViTNet的效果,笔者分别取C0正常驾驶、C1左顾右盼、C2打电话、C3玩手机、C4抽烟这5种分心驾驶行为在4项评价指标上的表现做详细分析,各项指标的数据如表2。

表2 验证BiViTNet的评价指标Table 2 Evaluation index of verifying BiViTNet %
从表2中可以看出,C2类别代表的打电话无论是准确率、精度、召回率还是F1分数都是最高的。C1类别代表的左顾右盼相比于其他类别而言准确率较低,结合表1,可以发现C1类别和C3类别数目相近,因此这与所采集照片的数目关系不大,这可能是由于驾驶员左顾右盼与正常驾驶时的体态差异很小,只有头部微小的扭动而身体其他部分几乎没有区别,多数要通过脸部的变化才能区分,因此十分容易和正常驾驶混淆。
在自建多视角驾驶员数据集的测试集上,采用相同的训练策略,将笔者提出的方法和一些常见的网络模型及方法进行比较。BiViTNet网络与CNN网络和ViT网络对比的实验结果分别如表3和表4。

表3 与CNN系列网络的对比Table 3 Comparison with the CNN series network

表4 与ViT系列网络的对比Table 4 Comparison with the ViT series network
从表3可以看出,与CNN系列网络相比,笔者提出的BiViTNet模型具有一定的优势,相比于CNN系列网络中性能最高的MobileNet模型,笔者所提BiViTNet的准确率达到97.18%,相比于VGG、ResNet-50和DenseNet模型在计算量上有明显的降低,计算量(multiply-accumulate operations,MAdds)更是达到了数量级的下降。
从表4可以看出,相较于经典的ViT模型和CrossViT模型,提出的BiViTNet模型展现出较好的实验效果,ViT Branch的验证准确率达到96.74%,整个模型的验证准确率更高,而且在模型大小和参数量上都有明显的降低,综合性能较好。
为了便于观察各类别的效果,将BiViTNet模型分别与DenseNet模型和CrossViT模型进行更细节的对比,如表5和表6。

表6 与CrossViT详细对比Table 6 The detailed comparison with CrossViT %
从表5和表6的详细对比可以看出,所提的BiViTNet模型在整体效果和各类任务上分别有不同程度的提升,准确率和召回率基本上都有所提高。相较于DenseNet模型,BiViTNet模型补充了全局视觉表征信息;相较于CrossViT模型,BiViTNet模型增强了捕获局部特征的能力。因此,笔者所提模型信息表达更为全面,检测效果也相对更好。单独使用CNN Branch和ViT Branch进行消融实验,效果如表7。

表7 双分支消融对比Table 7 Comparison with dual branch ablation
从表7结果可以看出,两个分支都具有较高的准确率,但是由于实验是在没有任何预训练的基础上进行的,而且数据集的规模也没有特别大,所以ViT Branch的准确率要比CNN Branch略微逊色。由于BiFIM可以强化全局依赖,同时保留全局表示中的局部细节信息,所以通过BiFIM在两个分支之间建立连接后,模型的准确率比单独的任何一个分支都要高。所提出的BiViTNet模型达到了较好的实验效果,准确率达到97.18%。
4 结 语
对于驾驶员分心行为检测的任务,提出了BiViTNet,该网络由两个分支组成,两个分支各自有不同的侧重点,并不断进行双向特征交互,最后对驾驶员的分心行为进行检测。实验结果表明,BiViTN参数量和计算量都较低,准确率达到97.18%,两个分支的结合可以有效地将局部和全局信息进行编码,实现局部与全局视觉表征信息的交互,可以快速准确地进行驾驶员分心行为检测,辅助驾驶员安全行车,同时也为进一步的研究打下了良好的基础。BiViTNet虽然可有效提高检测的准确率,但若是实验数据的背景过于复杂可能会在一定程度上影响检测效果,因此,在保证实时性的前提下,解决上述问题是未来研究工作的重点。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
汽车实用技术(2022年14期)2022-07-30
数学物理学报(2022年2期)2022-04-26
汽车实用技术(2022年4期)2022-03-07
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
金桥(2018年4期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
公民与法治(2016年4期)2016-05-17
